- Алгоритмы и структуры данных. Алгоритмы сортировки

Содержание
- 2. Сортировка – это процесс упорядочения некоторого множества элементов, на котором определено отношение порядка >, Традиционно различают
- 3. Оценка сложности алгоритма сортировки Алгоритмы сортировки ведут себя по‑разному в различных обстоятельствах. Например, пузырьковая сортировка опережает
- 4. Память – второй параметр, характеризующий эффективность алгоритма. Ряд алгоритмов требует выделения дополнительной памяти под временное хранение
- 5. Общие принципы преобразования данных при использовании алгоритмов сортировки Таблицы указателей При сортировке элементов данных программа перестраивает
- 6. Общие принципы преобразования данных при использовании алгоритмов сортировки Объединение и сжатие ключей В некоторых случаях можно
- 7. Пример. Требуется закодировать строки, состоящие из заглавных латинских букв. Закодируем каждый символ числом по основанию 27
- 8. 1. Сортировка выбором Сортировка выбором (selection sort) — простой алгоритм сортировки, является неустойчивым. На массиве из
- 9. 1. Сортировка выбором Вычислительная сложность алгоритма При поиске i-го наибольшего (наименьшего) элемента алгоритму приходится перебрать n-i
- 10. 1. Сортировка выбором Пример упорядочения по возрастанию
- 11. 2. Сортировка вставкой Идея сортировки вставками: очередная запись вставляется среди ранее отсортированных записей. К i-у шагу
- 12. 2. Сортировка вставкой Метод выбора очередного элемента из исходного массива произволен; может использоваться практически любой алгоритм
- 13. 2. Сортировка вставкой Сортировка вставкой (insertion sort) — алгоритм со сложностью порядка O(n^2). Особенности алгоритма прост
- 14. 2. Сортировка вставкой Пример
- 15. 2. Сортировка вставкой Полное число шагов, которые потребуется выполнить, составляет 1 + 2 + 3 +
- 16. Вставка в связных списках Можно использовать вариант сортировки вставкой для упорядочения элементов не в массиве, а
- 17. 3. Сортировка пузырьком Сортировка простыми обменами, сортировка пузырьком (bubble sort) — простой алгоритм сортировки. Для понимания
- 18. 3. Сортировка пузырьком Пример. Сортировка пузырьком Последовательность чисел представлена вертикально: первый элемент – внизу, последний –
- 19. Усовершенствование алгоритма сортировки пузырьком (переход к шейкерной сортировке) 1.При просмотре массива снизу вверх(от начала к концу
- 20. Усовершенствование алгоритма сортировки пузырьком (переход к шейкерной сортировке) 2. При просмотре массива сверху вниз (от конца
- 21. Усовершенствование алгоритма сортировки пузырьком (переход к шейкерной сортировке) 3.Ограничение проходов массива. После просмотра массива, последние переставленные
- 22. 4. Шейкерная сортировка Сортировка перемешиванием (Шейкерная сортировка) (Cocktail sort) — разновидность пузырьковой сортировки. Анализируя метод пузырьковой
- 23. 4. Шейкерная сортировка Пример. Шейкерная сортировка
- 24. 4. Шейкерная сортировка procedure TForm1.Bubblesort(list1: PlongIntarray; min, max: longint); var i, j, tmp, last_swap: longint; begin
- 25. 4. Шейкерная сортировка begin //куда сдвинуть пузырек tmp:= list1[i-1]; j:=i; repeat list1[j-1]:=list1[j] ; //'погружение’ j:=j+1; if
- 26. 4. Шейкерная сортировка //обновление max max:= last_swap-1; //всплытие last_swap:= max+1; i:=max-1; while i>=min do begin //нахождение
- 27. 4. Шейкерная сортировка list1[j+1]:=tmp; last_swap:=j+1; i:=j-1; end else i:=i-1; end; //конец всплытия //обновление min min:=last_swap+1; end;
- 28. 5. Быстрая сортировка Быстрая сортировка — рекурсивный алгоритм, который использует подход «разделяй и властвуй». Если сортируемый
- 29. 5. Быстрая сортировка Описание рекурсивного алгоритма Пусть текущий подмассив содержит элементы k(left), k(left+1),…, k(right). Полагаем x=k(left),
- 30. 5. Быстрая сортировка Пример. Быстрая сортировка Предполагается, что первый элемент принадлежит первому подмассиву. После разделения на
- 31. 5. Быстрая сортировка Особенности версии алгоритма В качестве разделителя используется первый элемент в списке. После разбиения
- 32. 5. Быстрая сортировка Способы выбора разделяющего элемента 1.Можно использовать элемент из середины списка. Но он может
- 33. 5. Быстрая сортировка Особенности алгоритма быстрой сортировки Если данные имеют небольшой диапазон значений (много дубликатов нескольких
- 34. 5. Быстрая сортировка Быстрая сортировка (quicksort), сортировка Хоара, часто называемая qsort по имени реализации в стандартной
- 35. 5. Быстрая сортировка void Q_sort_help(Iter left, Iter right) { if (right - left auto separator =
- 36. 6. Сортировка слиянием Сортировка слиянием (merge sort) — алгоритм сортировки, который упорядочивает списки (или другие структуры
- 37. 6. Сортировка слиянием Этап слияния Подсписки сливаются во временный массив, и результат копируется в первоначальный список.
- 38. 6. Сортировка слиянием Усовершенствование алгоритма Как и в случае с быстрой сортировкой, можно ускорить выполнение сортировки
- 39. 6. Сортировка слиянием Пример. Рекурсивный алгоритм простого двухпутевого слияния. Используются дополнительные массивы
- 40. 6. Сортировка слиянием Пример. Не рекурсивный алгоритм. Сортировка методом простого двухпутевого (сбалансированного) слияния. Пример. Не рекурсивный
- 41. 6. Сортировка слиянием Рекурсивный алгоритм void my_sort::merge_sort(int l, int r) { int i_mid, i1, i2, i3;
- 42. 6. Сортировка слиянием Рекурсивный алгоритм while (i1 if (arr[i1] { tmp_mas[i3] = arr[i1]; i1++; i3++; }
- 44. Скачать презентацию

Сортировка – это процесс упорядочения некоторого множества элементов, на котором определено
Сортировка – это процесс упорядочения некоторого множества элементов, на котором определено

Оценка сложности алгоритма сортировки
Алгоритмы сортировки ведут себя по‑разному в различных обстоятельствах.
Оценка сложности алгоритма сортировки
Алгоритмы сортировки ведут себя по‑разному в различных обстоятельствах.

Память – второй параметр, характеризующий эффективность алгоритма. Ряд алгоритмов требует выделения
Память – второй параметр, характеризующий эффективность алгоритма. Ряд алгоритмов требует выделения

Общие принципы преобразования данных при использовании алгоритмов сортировки
Таблицы указателей
При сортировке элементов
Общие принципы преобразования данных при использовании алгоритмов сортировки
Таблицы указателей
При сортировке элементов

Общие принципы преобразования данных при использовании алгоритмов сортировки
Объединение и сжатие ключей
В
Общие принципы преобразования данных при использовании алгоритмов сортировки
Объединение и сжатие ключей
В

Пример. Требуется закодировать строки, состоящие из заглавных латинских букв. Закодируем каждый
Пример. Требуется закодировать строки, состоящие из заглавных латинских букв. Закодируем каждый

1. Сортировка выбором
Сортировка выбором (selection sort) — простой алгоритм сортировки, является
1. Сортировка выбором
Сортировка выбором (selection sort) — простой алгоритм сортировки, является

1. Сортировка выбором
Вычислительная сложность алгоритма
При поиске i-го наибольшего (наименьшего) элемента алгоритму
1. Сортировка выбором
Вычислительная сложность алгоритма
При поиске i-го наибольшего (наименьшего) элемента алгоритму
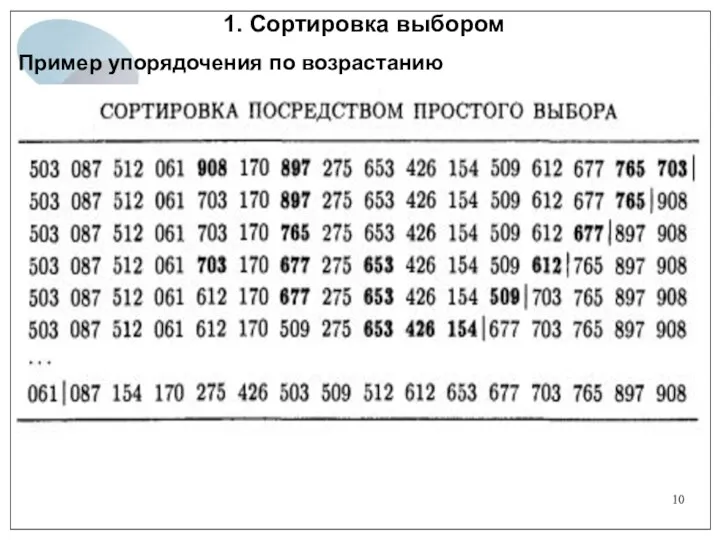
1. Сортировка выбором
Пример упорядочения по возрастанию
1. Сортировка выбором
Пример упорядочения по возрастанию

2. Сортировка вставкой
Идея сортировки вставками:
очередная запись вставляется среди ранее отсортированных
2. Сортировка вставкой
Идея сортировки вставками:
очередная запись вставляется среди ранее отсортированных

2. Сортировка вставкой
Метод выбора очередного элемента из исходного массива произволен; может
2. Сортировка вставкой
Метод выбора очередного элемента из исходного массива произволен; может

2. Сортировка вставкой
Сортировка вставкой (insertion sort) — алгоритм со сложностью порядка
2. Сортировка вставкой
Сортировка вставкой (insertion sort) — алгоритм со сложностью порядка

2. Сортировка вставкой
Пример
2. Сортировка вставкой
Пример

2. Сортировка вставкой
Полное число шагов, которые потребуется выполнить, составляет 1 +
2. Сортировка вставкой
Полное число шагов, которые потребуется выполнить, составляет 1 +

Вставка в связных списках
Можно использовать вариант сортировки вставкой для упорядочения элементов
Вставка в связных списках
Можно использовать вариант сортировки вставкой для упорядочения элементов

3. Сортировка пузырьком
Сортировка простыми обменами, сортировка пузырьком (bubble sort) — простой
3. Сортировка пузырьком
Сортировка простыми обменами, сортировка пузырьком (bubble sort) — простой
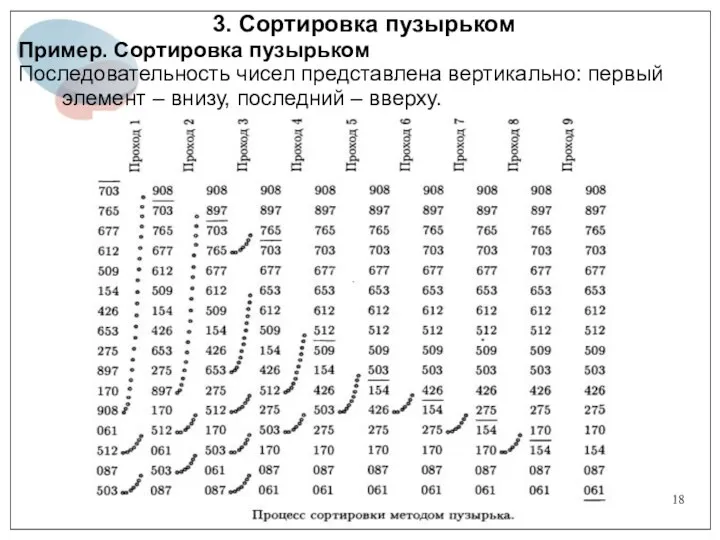
3. Сортировка пузырьком
Пример. Сортировка пузырьком
Последовательность чисел представлена вертикально: первый элемент –
3. Сортировка пузырьком
Пример. Сортировка пузырьком
Последовательность чисел представлена вертикально: первый элемент –

Усовершенствование алгоритма сортировки пузырьком
(переход к шейкерной сортировке)
1.При просмотре массива снизу вверх(от
Усовершенствование алгоритма сортировки пузырьком
(переход к шейкерной сортировке)
1.При просмотре массива снизу вверх(от

Усовершенствование алгоритма сортировки пузырьком (переход к шейкерной сортировке)
2. При просмотре массива
Усовершенствование алгоритма сортировки пузырьком (переход к шейкерной сортировке)
2. При просмотре массива

Усовершенствование алгоритма сортировки пузырьком
(переход к шейкерной сортировке)
3.Ограничение проходов массива. После
Усовершенствование алгоритма сортировки пузырьком
(переход к шейкерной сортировке)
3.Ограничение проходов массива. После

4. Шейкерная сортировка
Сортировка перемешиванием (Шейкерная сортировка) (Cocktail sort) — разновидность пузырьковой
4. Шейкерная сортировка
Сортировка перемешиванием (Шейкерная сортировка) (Cocktail sort) — разновидность пузырьковой

4. Шейкерная сортировка
Пример. Шейкерная сортировка
4. Шейкерная сортировка
Пример. Шейкерная сортировка

4. Шейкерная сортировка
procedure TForm1.Bubblesort(list1: PlongIntarray; min, max: longint);
var
i, j, tmp,
4. Шейкерная сортировка
procedure TForm1.Bubblesort(list1: PlongIntarray; min, max: longint);
var
i, j, tmp,
![4. Шейкерная сортировка begin //куда сдвинуть пузырек tmp:= list1[i-1]; j:=i;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/595372/slide-24.jpg)
4. Шейкерная сортировка
begin
//куда сдвинуть пузырек
tmp:= list1[i-1];
j:=i;
4. Шейкерная сортировка
begin
//куда сдвинуть пузырек
tmp:= list1[i-1];
j:=i;

4. Шейкерная сортировка
//обновление max
max:= last_swap-1;
//всплытие
last_swap:= max+1;
4. Шейкерная сортировка
//обновление max
max:= last_swap-1;
//всплытие
last_swap:= max+1;
![4. Шейкерная сортировка list1[j+1]:=tmp; last_swap:=j+1; i:=j-1; end else i:=i-1; end;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/595372/slide-26.jpg)
4. Шейкерная сортировка
list1[j+1]:=tmp;
last_swap:=j+1;
i:=j-1;
end else
i:=i-1;
end;
4. Шейкерная сортировка
list1[j+1]:=tmp;
last_swap:=j+1;
i:=j-1;
end else
i:=i-1;
end;

5. Быстрая сортировка
Быстрая сортировка — рекурсивный алгоритм, который использует подход «разделяй
5. Быстрая сортировка
Быстрая сортировка — рекурсивный алгоритм, который использует подход «разделяй

5. Быстрая сортировка
Описание рекурсивного алгоритма
Пусть текущий подмассив содержит элементы
k(left), k(left+1),…,
5. Быстрая сортировка
Описание рекурсивного алгоритма
Пусть текущий подмассив содержит элементы
k(left), k(left+1),…,

5. Быстрая сортировка
Пример. Быстрая сортировка
Предполагается, что первый элемент принадлежит первому подмассиву.
5. Быстрая сортировка
Пример. Быстрая сортировка
Предполагается, что первый элемент принадлежит первому подмассиву.

5. Быстрая сортировка
Особенности версии алгоритма
В качестве разделителя используется первый элемент в
5. Быстрая сортировка
Особенности версии алгоритма
В качестве разделителя используется первый элемент в

5. Быстрая сортировка
Способы выбора разделяющего элемента
1.Можно использовать элемент из середины
5. Быстрая сортировка
Способы выбора разделяющего элемента
1.Можно использовать элемент из середины

5. Быстрая сортировка
Особенности алгоритма быстрой сортировки
Если данные имеют небольшой диапазон значений
5. Быстрая сортировка
Особенности алгоритма быстрой сортировки
Если данные имеют небольшой диапазон значений

5. Быстрая сортировка
Быстрая сортировка (quicksort), сортировка Хоара, часто называемая qsort по
5. Быстрая сортировка
Быстрая сортировка (quicksort), сортировка Хоара, часто называемая qsort по

5. Быстрая сортировка
void Q_sort_help(Iter left, Iter right) {
if (right
5. Быстрая сортировка
void Q_sort_help(Iter left, Iter right) {
if (right

6. Сортировка слиянием
Сортировка слиянием (merge sort) — алгоритм сортировки, который упорядочивает
6. Сортировка слиянием
Сортировка слиянием (merge sort) — алгоритм сортировки, который упорядочивает

6. Сортировка слиянием
Этап слияния
Подсписки сливаются во временный массив, и результат
6. Сортировка слиянием
Этап слияния
Подсписки сливаются во временный массив, и результат

6. Сортировка слиянием
Усовершенствование алгоритма
Как и в случае с быстрой сортировкой, можно
6. Сортировка слиянием
Усовершенствование алгоритма
Как и в случае с быстрой сортировкой, можно

6. Сортировка слиянием
Пример. Рекурсивный алгоритм простого двухпутевого слияния. Используются дополнительные массивы
6. Сортировка слиянием
Пример. Рекурсивный алгоритм простого двухпутевого слияния. Используются дополнительные массивы

6. Сортировка слиянием
Пример. Не рекурсивный алгоритм. Сортировка методом простого двухпутевого (сбалансированного)
6. Сортировка слиянием
Пример. Не рекурсивный алгоритм. Сортировка методом простого двухпутевого (сбалансированного)

6. Сортировка слиянием
Рекурсивный алгоритм
void my_sort::merge_sort(int l, int r)
{
int i_mid, i1, i2,
6. Сортировка слиянием
Рекурсивный алгоритм
void my_sort::merge_sort(int l, int r)
{
int i_mid, i1, i2,
![6. Сортировка слиянием Рекурсивный алгоритм while (i1 if (arr[i1] {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/595372/slide-41.jpg)
6. Сортировка слиянием
Рекурсивный алгоритм
while (i1 <= i_mid && i2 <= r)
if
6. Сортировка слиянием
Рекурсивный алгоритм
while (i1 <= i_mid && i2 <= r)
if
 Требования к современным операционным системам (ОС). Функциональные компоненты ОС автономного компьютера
Требования к современным операционным системам (ОС). Функциональные компоненты ОС автономного компьютера Паралельні обчислення на суперкомп’ютері СКІТ
Паралельні обчислення на суперкомп’ютері СКІТ Многообразие схем. Информационные модели на графах. Использование графов при решении задач
Многообразие схем. Информационные модели на графах. Использование графов при решении задач Основы программирования ФИСТ. Двухмерные массивы. Базовые алгоритмы. Лекция 10
Основы программирования ФИСТ. Двухмерные массивы. Базовые алгоритмы. Лекция 10 Возможности и риски информационной среды
Возможности и риски информационной среды Мобильный агент
Мобильный агент Использование информационных технологий для развития познавательного интереса на уроках русского языка и литературы
Использование информационных технологий для развития познавательного интереса на уроках русского языка и литературы Технологии баз данных
Технологии баз данных Высокоуровневые методы информатики и программирования
Высокоуровневые методы информатики и программирования Представление информации, языки, кодирование. История технических способов кодирования
Представление информации, языки, кодирование. История технических способов кодирования Защита информации
Защита информации Одномерные массивы. Алгоритмы циклического сдвига, сжатия.
Одномерные массивы. Алгоритмы циклического сдвига, сжатия. Масштабируемая веб-архитектура и распределенные системы
Масштабируемая веб-архитектура и распределенные системы Устройство компьютера
Устройство компьютера Система программирования PascalABC.NET и электронный задачник Programming Taskbook
Система программирования PascalABC.NET и электронный задачник Programming Taskbook Презентация Структура данных
Презентация Структура данных Базы и банки данных. История развития ВТ и СУБД
Базы и банки данных. История развития ВТ и СУБД Введение в математическую логику
Введение в математическую логику Инструкция по административной панели Momentum
Инструкция по административной панели Momentum Веб-система. Электронное расписание занятий
Веб-система. Электронное расписание занятий Разбор киберспортивной жизни на примере игры League of Legends
Разбор киберспортивной жизни на примере игры League of Legends Этапы развития информационного общества. Развитие технических средств и информационных ресурсов (2)
Этапы развития информационного общества. Развитие технических средств и информационных ресурсов (2) IT - технологии в футболе
IT - технологии в футболе Обзор оборудования и программного обеспечения компании VIPA
Обзор оборудования и программного обеспечения компании VIPA Электронная гимнастика для глаз
Электронная гимнастика для глаз Партицирование данных. Урок 4
Партицирование данных. Урок 4 Сетевые экраны
Сетевые экраны Организация и инструментальные средства информационных технологий управления
Организация и инструментальные средства информационных технологий управления