- Технологии баз данных

Содержание
- 2. Технологии баз данных Тема 7. Манипулирование данными в реляционной модели. Реляционная алгебра
- 3. Манипулирование данными в реляционной модели Для манипулирования данными в реляционной модели используются два формальных аппарата: реляционная
- 4. Манипулирование данными в реляционной модели Конкретный язык манипулирования реляционными БД называется реляционно полным, если любой запрос,
- 5. Реляционная алгебра Операции реляционной алгебры определены на множестве отношений и являются замкнутыми относительно этого множества (образуют
- 6. Реляционная алгебра Объединением двух совместимых по типу отношений R и S (R ∪ S) называется отношение
- 7. Реляционная алгебра Пересечением двух совместимых по типу отношений R и S (R ∩ S) называется отношение
- 8. Реляционная алгебра Разностью двух совместимых по типу отношений R и S (R − S) называется отношение
- 9. Реляционная алгебра R1(ФИО, Паспорт, Школа) R2(ФИО, Паспорт, Школа) R3(ФИО, Паспорт, Школа) Список абитуриентов, которые поступали два
- 10. Реляционная алгебра Декартово произведение двух отношений R и S (R × S), определяется как отношение с
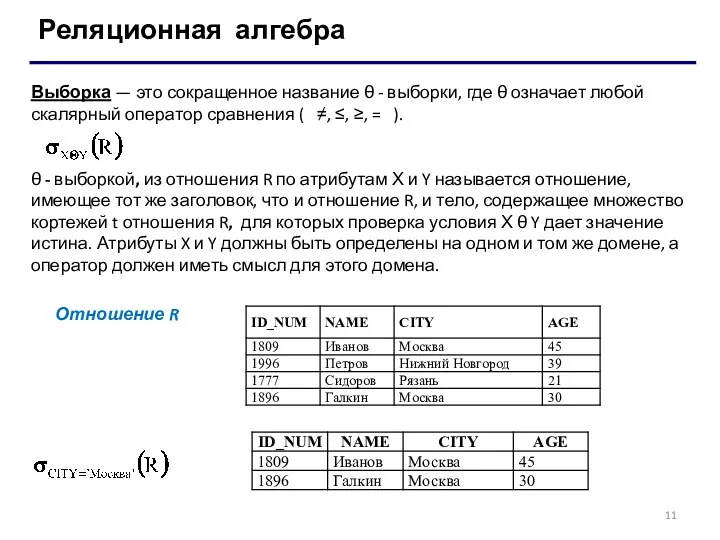
- 11. Реляционная алгебра Выборка — это сокращенное название θ - выборки, где θ означает любой скалярный оператор
- 12. Реляционная алгебра Проекцией отношения R по атрибутам Х, Y,…,Z (P [X, Y,…Z](R)), где каждый из атрибутов
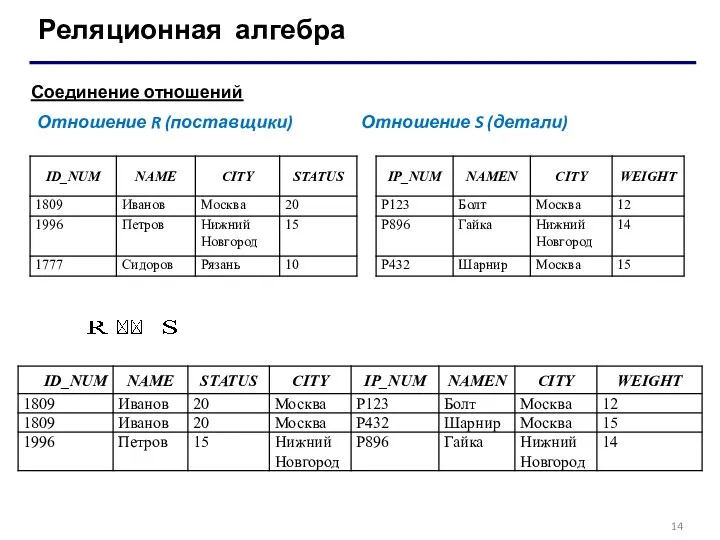
- 13. Реляционная алгебра Соединение отношений — создает новое отношение, каждый кортеж которого является результатом сцепления кортежей операндов
- 14. Реляционная алгебра Соединение отношений Отношение R (поставщики) Отношение S (детали)
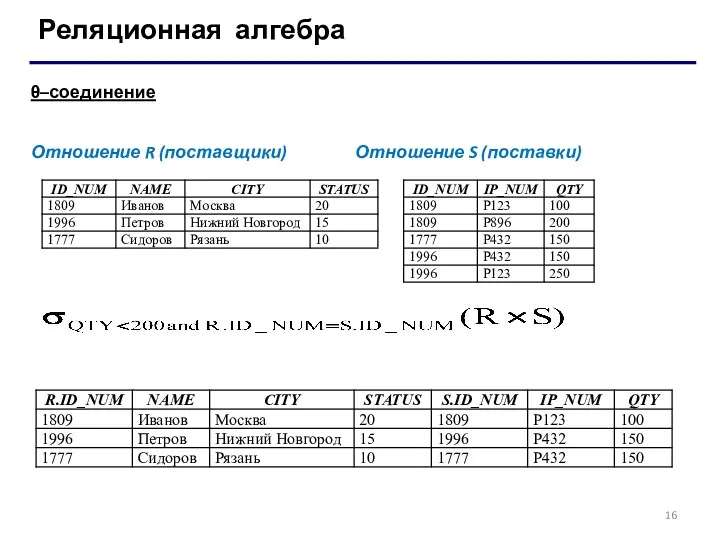
- 15. Реляционная алгебра θ–соединение Пусть отношения R и S не имеют общих имен атрибутов, и θ определяется
- 16. Реляционная алгебра θ–соединение Отношение R (поставщики) Отношение S (поставки)
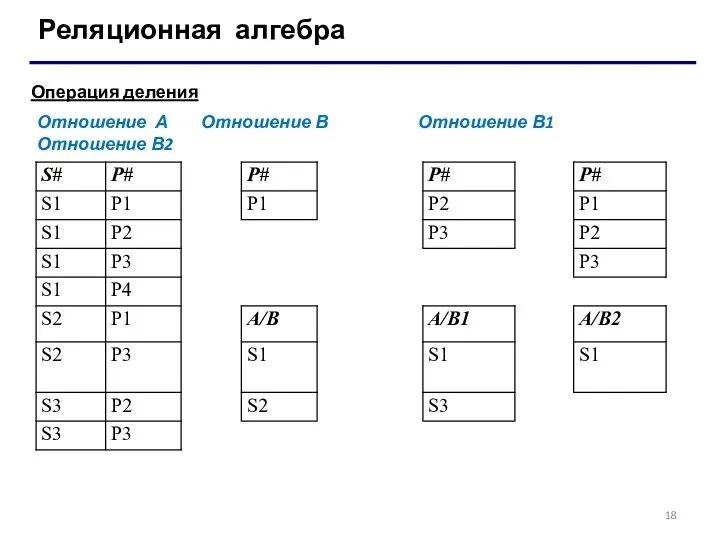
- 17. Реляционная алгебра Операция деления У операции реляционного деления два операнда - бинарное и унарное отношения. Пусть
- 18. Реляционная алгебра Операция деления Отношение А Отношение В Отношение В1 Отношение В2
- 19. Реляционная алгебра R1(ФИО, Дисциплина, Оценка) R2(ФИО, Группа) R3(Группа, Дисциплина) Список студентов сдавших БД на отлично. Список
- 20. Технологии баз данных Тема 8. Манипулирование данными в реляционной модели. Реляционное исчисление
- 21. Реляционное исчисление Реляционное исчисления кортежей (Кодд) Реляционное исчисления доменов (Лякруа и Пиротт ). В логике первого
- 22. Реляционное исчисление с переменными кортежами Областями определения переменных являются отношения базы данных, т.е. допустимым значением каждой
- 23. Реляционное исчисление с переменными кортежами
- 24. Реляционное исчисление с переменными кортежами
- 25. Реляционное исчисление с переменными кортежами R1(ФИО, Дисциплина, Оценка) R2(ФИО, Группа) R3(Группа, Дисциплина)
- 26. Реляционное исчисление с переменными доменами Областями определения переменных являются домены на которых определены атрибуты отношений БД.
- 27. Реляционное исчисление с переменными доменами
- 28. Реляционное исчисление с переменными доменами Правила перехода от переменных кортежей к переменным доменам. Если кортеж арности
- 29. Реляционное исчисление с переменными доменами
- 30. Языки манипулирования данными Реляционная алгебра ISBL (Information Systems Base Language) IBM (Питерли, Англия) экспериментальная система PRTV
- 31. Языки манипулирования данными Реляционное исчисление с кортежами QUEL University of California, Berkeley СУБД Ingres используется с
- 32. Языки манипулирования данными Реляционное исчисление с кортежами POSTQUEL (англ. Postgres Query Language) – первичный язык запросов
- 33. Языки манипулирования данными Реляционное исчисление на домене Query by Example (QBE) "Запрос по образцу" Разработан Мойше
- 34. Языки манипулирования данными Реляционное исчисление на домене Query by Example (QBE) Cоединение таблицы emp с собой
- 35. Языки манипулирования данными Данный способ создания запросов позволяет получить высокую наглядность и не требует указывать алгоритм
- 36. Технологии баз данных Тема 9. SQL
- 37. SQL — Structured Query Language Разработан в 1974 году фирмой IBM для экспериментальной реляционной СУБД System
- 38. SQL — Structured Query Language Используется для: Организация данных. SQL дает пользователю возможность изменять структуру представления
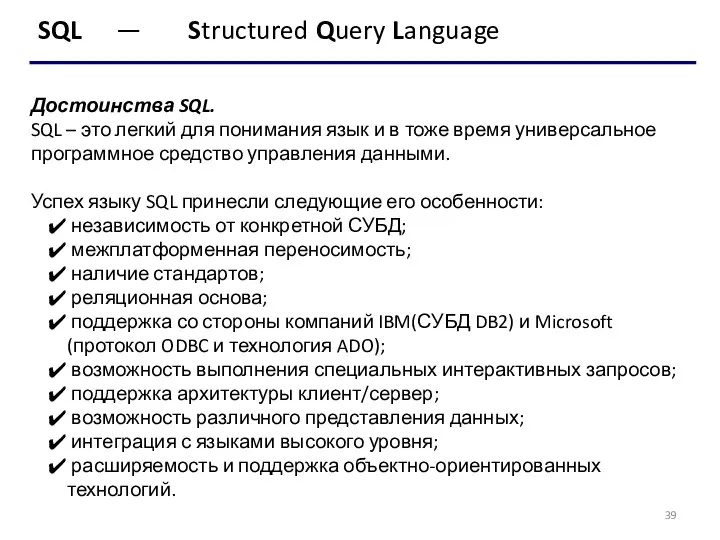
- 39. SQL — Structured Query Language Достоинства SQL. SQL – это легкий для понимания язык и в
- 40. SQL — Structured Query Language Недостатки SQL Несоответствие реляционной модели данных Создатели реляционной модели данных Эдгар
- 41. SQL — Structured Query Language Недостатки SQL Отступления от стандартов Несмотря на наличие международного стандарта SQL,
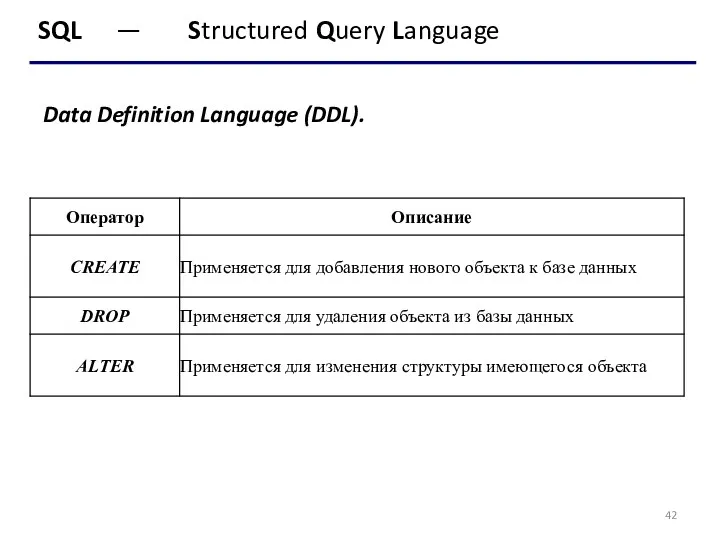
- 42. SQL — Structured Query Language Data Definition Language (DDL).
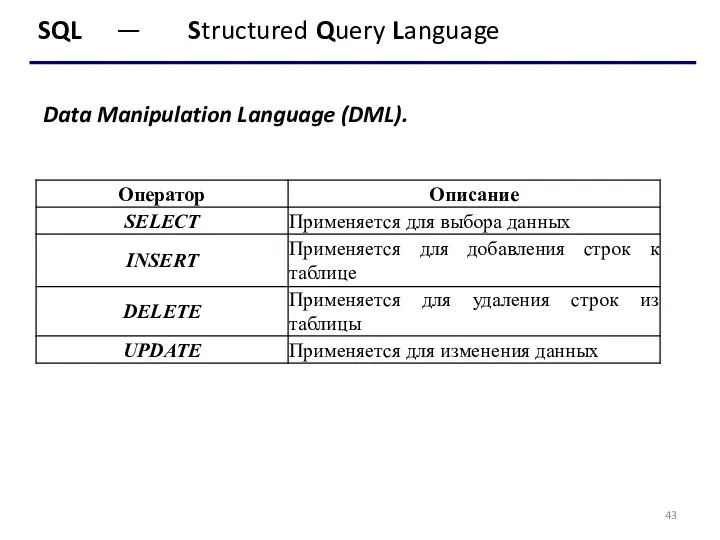
- 43. SQL — Structured Query Language Data Manipulation Language (DML).
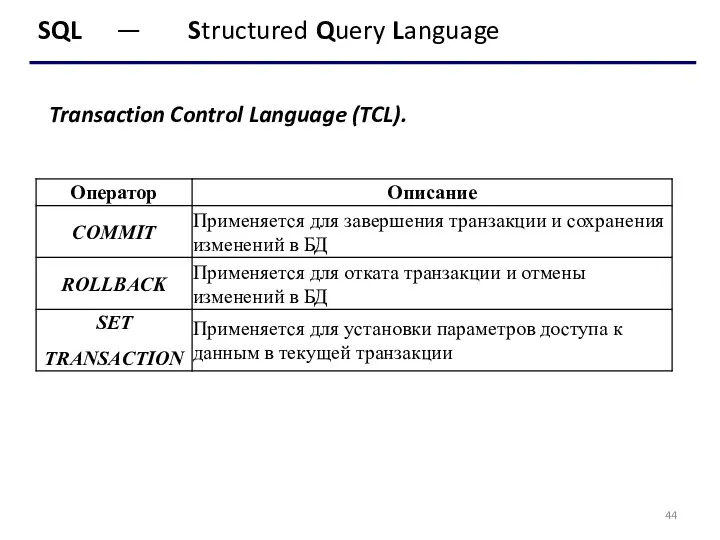
- 44. SQL — Structured Query Language Transaction Control Language (TCL).
- 45. SQL — Structured Query Language Data Control Language (DCL).
- 46. SQL — Structured Query Language SELECT [[ALL] | DISTINCT] [ТОР n [PERCENT]] [WITH TIES] {* |
- 47. SQL — Structured Query Language Этот оператор можно прочитать следующим образом: SELECT (выбрать) — данные из
- 48. SQL — Structured Query Language GROUP BY (группируя по) — указанному перечню столбцов с тем, чтобы
- 49. SQL — Structured Query Language Параметры раздела обозначают следующее: ALL – указывает, что в результат выборки
- 50. SQL — Structured Query Language Параметры раздела обозначают следующее: элемент_SELECT – список столбцов, которые включены в
- 51. Выборка c использованием фразы WHERE Раздел WHERE предназначен для ограничения количества строк, включаемых в результат выборки.
- 52. Выборка c использованием фразы WHERE R1(ФИО, Дисциплина, Оценка) R2(ФИО, Группа) R3(Группа, Дисциплина) SELECT ФИО FROM R2
- 53. Объединение UNION [ALL] Предложение UNION приводит к появлению в результирующем наборе всех строк каждого из запросов.
- 54. Пересечение и разность INTERSECT [ALL] (пересечение) EXCEPT [ALL] (разность В результирующий набор попадают только те строки,
- 55. NULL-значения в выражениях. Как правило, применение NULL-значения в выражении приводит к результату, равному NULL. Например, SELECT
- 56. NULL-значения в выражениях. Функции, специально предназначенные для работы с неопределенными значениями. ISNULL ( , ) преобразует
- 57. NULL-значения в выражениях. SELECT Название, ISNULL(Жанр, ‘Не указан’) as [Жанр книги] FROM Книги WHERE Жанр IS
- 58. Использование BETWEEN BETWEEN … AND … (находится в интервале от ... до ...) можно отобрать строки,
- 59. Использование IN (NOT IN). Задает поиск выражения, включенного или исключенного из списка. Выражение поиска может быть
- 60. Использование LIKE. LIKE определяет, совпадает ли указанная символьная строка с заданным шаблоном. выражение [NOT] LIKE строка_шаблон
- 61. Использование LIKE. SELECT ФИО, Должность, Телефон FROM Сотрудники WHERE Должность LIKE ‘% редактор’ OR Должность =
- 62. Предикат EXISTS [NOT] EXISTS ( ) Предикат EXISTS принимает значение TRUE, если подзапрос содержит любое количество
- 63. Использование ключевых слов SOME (ANY) и ALL с предикатами сравнения SOME | ANY ( ) SOME
- 64. Использование агрегатных функций для подведения итогов. В SQL существует ряд специальных агрегатных (статических) функций. COUNT(столбец) –
- 65. Использование агрегатных функций для подведения итогов. Выражение, определяющее столбец такой таблицы, может быть сколь угодно сложным,
- 66. Агрегатные функции без использования фразы GROUP BY. Если не используется фраза GROUP BY, то в перечень
- 67. Фраза GROUP BY Фраза GROUP BY (группировать по) инициирует перекомпоновку указанной во FROM таблицы по группам,
- 68. Раздел HAVING. Предложение HAVING подобно предложению WHERE, но применимо только к целым группам (то есть к
- 69. Раздел HAVING. SELECT [Номер заказа], count(*) as [Количество позиций] , sum(количество) as [Количество книг] FROM [Состав
- 70. Раздел HAVING. R1(ФИО, Дисциплина, Оценка) R2(ФИО, Группа) R3(Группа, Дисциплина) Найти студентов, имеющих лучший средний балл в
- 71. Раздел HAVING. SELECT [Номер заказа], count(*) as [Количество книг] FROM [Состав заказа] WHERE ISBN IN (
- 72. Обобщенные табличные выражения (СТЕ). Обобщенные табличные выражения (CTE) помогают повысить удобочитаемость (и, таким образом, возможность обслуживания)
- 74. Синтаксис фразы GROUP BY GROUP BY [ALL] [ CUBE | ROLLUP] {[таблица.]столбец [, [таблица.]столбец] …} ALL
- 75. ROLLUP – оператор, который формирует промежуточные итоги для каждого указанного элемента и общий итог.
- 76. CUBE — оператор , который формирует результаты для всех возможных перекрестных вычислений.
- 77. GROUPING SETS – оператор, который формирует результаты нескольких группировок в один набор данных, другими словами, он
- 78. GROUPING – функция Transact-SQL, которая возвращает истину, если указанное выражение является статистическим, и ложь, если выражение
- 79. Выражение CASE Оценка списка условий и возвращение одного из нескольких возможных выражений результатов. Выражение CASE имеет
- 80. IIF Функция IIF в зависимости от результата условного выражения возвращает одно из двух значений. Общая форма
- 81. Соединения «с условием WHERE». Cоединения - это подмножества декартова произведения. SELECT * FROM Клиент, Заказ WHERE
- 82. Операторы соединения в SQL92 CROSS JOIN NATURAL JOIN SPECIFIED JOIN UNION JOIN ON USING INNER JOIN
- 83. Соединения нескольких таблиц, используя JOIN. Существует три основных типа соединения: внутреннее соединение, задаваемое с помощью ключевых
- 84. Внутреннее соединение Во внутреннем соединении возвращаются только те строки, которые соответствуют условию, указанному после ключевого слова
- 85. Левое внешнее соединение. В левом внешнем соединении результатом являются все строки левой таблицы, вне зависимости от
- 86. Правое внешнее соединение. В правом внешнем соединении результатом являются все строки правой таблицы, вне зависимости от
- 87. Полное внешнее соединение. В полном внешнем соединении результатом являются строки обеих таблицы, вне зависимости от того,
- 88. Перекрёстное соединение. В перекрёстном соединении каждая строка из одной таблицы соединяется с каждой строкой из другой
- 89. PIVOT и UNPIVOT SELECT maker, type FROM product; Maker type B PC A PC A PC
- 90. SELECT maker, SUM(CASE type WHEN 'pc' THEN 1 ELSE 0 END) PC, SUM(CASE type WHEN 'laptop'
- 91. SELECT , [first pivoted column] AS , [second pivoted column] AS , ... [last pivoted column]
- 92. SELECT screen, AVG(price) avg_ FROM Laptop GROUP BY screen screen avg_ 11 700.00 12 960.00 1175.00
- 93. trip_no spec info 1100 id_comp 4 1100 Plane Boeing 1100 town_from Rostov 1100 town_to Paris 1100
- 95. Скачать презентацию

Технологии баз данных
Тема 7. Манипулирование данными в реляционной модели. Реляционная алгебра
Технологии баз данных
Тема 7. Манипулирование данными в реляционной модели. Реляционная алгебра

Манипулирование данными в реляционной модели
Для манипулирования данными в реляционной модели используются
Манипулирование данными в реляционной модели
Для манипулирования данными в реляционной модели используются

Манипулирование данными в реляционной модели
Конкретный язык манипулирования реляционными БД называется реляционно
Манипулирование данными в реляционной модели
Конкретный язык манипулирования реляционными БД называется реляционно

Реляционная алгебра
Операции реляционной алгебры определены на множестве отношений и являются замкнутыми
Реляционная алгебра
Операции реляционной алгебры определены на множестве отношений и являются замкнутыми
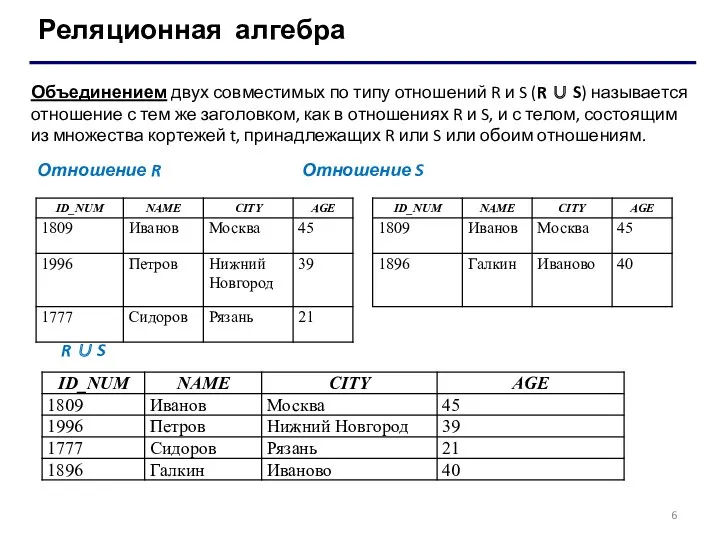
Реляционная алгебра
Объединением двух совместимых по типу отношений R и S (R
Реляционная алгебра
Объединением двух совместимых по типу отношений R и S (R
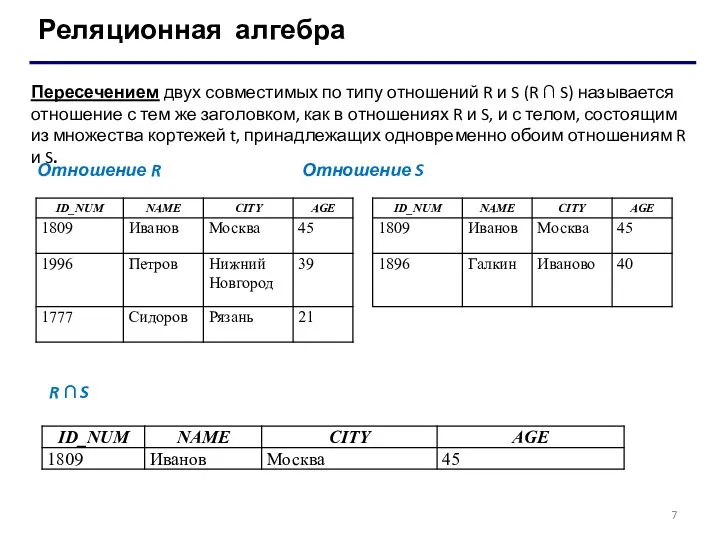
Реляционная алгебра
Пересечением двух совместимых по типу отношений R и S (R
Реляционная алгебра
Пересечением двух совместимых по типу отношений R и S (R
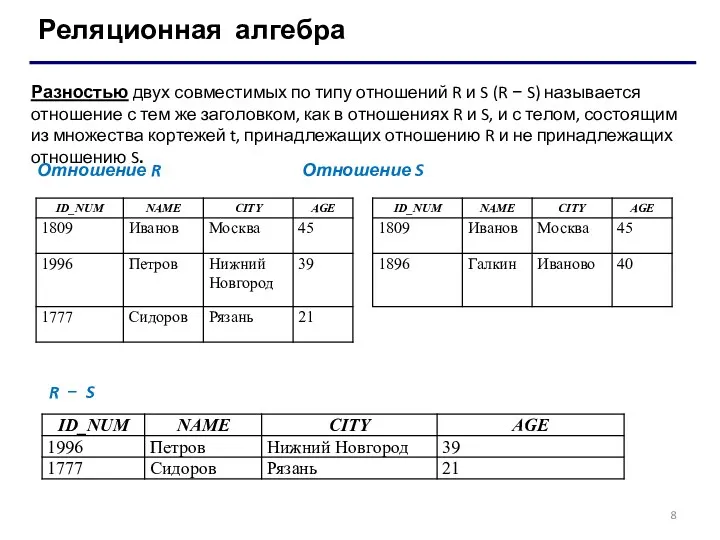
Реляционная алгебра
Разностью двух совместимых по типу отношений R и S (R
Реляционная алгебра
Разностью двух совместимых по типу отношений R и S (R

Реляционная алгебра
R1(ФИО, Паспорт, Школа)
R2(ФИО, Паспорт, Школа)
R3(ФИО, Паспорт, Школа)
Список абитуриентов, которые поступали
Реляционная алгебра
R1(ФИО, Паспорт, Школа)
R2(ФИО, Паспорт, Школа)
R3(ФИО, Паспорт, Школа)
Список абитуриентов, которые поступали
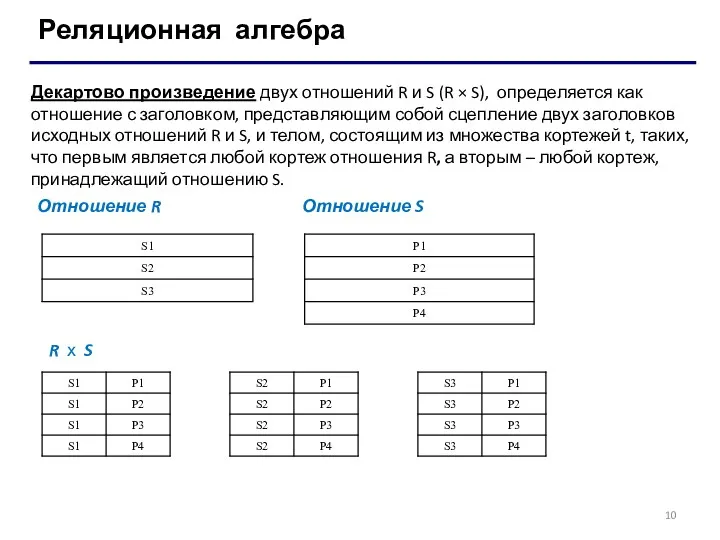
Реляционная алгебра
Декартово произведение двух отношений R и S (R × S),
Реляционная алгебра
Декартово произведение двух отношений R и S (R × S),
Реляционная алгебра
Выборка — это сокращенное название θ - выборки, где θ
Реляционная алгебра
Выборка — это сокращенное название θ - выборки, где θ

Реляционная алгебра
Проекцией отношения R по атрибутам Х, Y,…,Z (P [X, Y,…Z](R)),
Реляционная алгебра
Проекцией отношения R по атрибутам Х, Y,…,Z (P [X, Y,…Z](R)),

Реляционная алгебра
Соединение отношений — создает новое отношение, каждый кортеж которого является
Реляционная алгебра
Соединение отношений — создает новое отношение, каждый кортеж которого является
Реляционная алгебра
Соединение отношений
Отношение R (поставщики) Отношение S (детали)
Реляционная алгебра
Соединение отношений
Отношение R (поставщики) Отношение S (детали)

Реляционная алгебра
θ–соединение
Пусть отношения R и S не имеют общих имен
Реляционная алгебра
θ–соединение
Пусть отношения R и S не имеют общих имен
Реляционная алгебра
θ–соединение
Отношение R (поставщики) Отношение S (поставки)
Реляционная алгебра
θ–соединение
Отношение R (поставщики) Отношение S (поставки)

Реляционная алгебра
Операция деления
У операции реляционного деления два операнда - бинарное и
Реляционная алгебра
Операция деления
У операции реляционного деления два операнда - бинарное и
Реляционная алгебра
Операция деления
Отношение А Отношение В Отношение В1 Отношение В2
Реляционная алгебра
Операция деления
Отношение А Отношение В Отношение В1 Отношение В2

Реляционная алгебра
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
Список студентов сдавших БД на отлично.
Список
Реляционная алгебра
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
Список студентов сдавших БД на отлично.
Список

Технологии баз данных
Тема 8. Манипулирование данными в реляционной модели.
Реляционное
Технологии баз данных
Тема 8. Манипулирование данными в реляционной модели.
Реляционное

Реляционное исчисление
Реляционное исчисления кортежей (Кодд)
Реляционное исчисления доменов (Лякруа и Пиротт
Реляционное исчисление
Реляционное исчисления кортежей (Кодд)
Реляционное исчисления доменов (Лякруа и Пиротт

Реляционное исчисление с переменными кортежами
Областями определения переменных являются отношения базы данных,
Реляционное исчисление с переменными кортежами
Областями определения переменных являются отношения базы данных,

Реляционное исчисление с переменными кортежами
Реляционное исчисление с переменными кортежами

Реляционное исчисление с переменными кортежами
Реляционное исчисление с переменными кортежами

Реляционное исчисление с переменными кортежами
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
Реляционное исчисление с переменными кортежами
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)

Реляционное исчисление с переменными доменами
Областями определения переменных являются домены на которых
Реляционное исчисление с переменными доменами
Областями определения переменных являются домены на которых

Реляционное исчисление с переменными доменами
Реляционное исчисление с переменными доменами

Реляционное исчисление с переменными доменами
Правила перехода от переменных кортежей к переменным
Реляционное исчисление с переменными доменами
Правила перехода от переменных кортежей к переменным

Реляционное исчисление с переменными доменами
Реляционное исчисление с переменными доменами

Языки манипулирования данными
Реляционная алгебра
ISBL (Information Systems Base Language)
IBM (Питерли,
Языки манипулирования данными
Реляционная алгебра
ISBL (Information Systems Base Language)
IBM (Питерли,

Языки манипулирования данными
Реляционное исчисление с кортежами
QUEL University of California, Berkeley
Языки манипулирования данными
Реляционное исчисление с кортежами
QUEL University of California, Berkeley

Языки манипулирования данными
Реляционное исчисление с кортежами
POSTQUEL (англ. Postgres Query Language) –
Языки манипулирования данными
Реляционное исчисление с кортежами
POSTQUEL (англ. Postgres Query Language) –
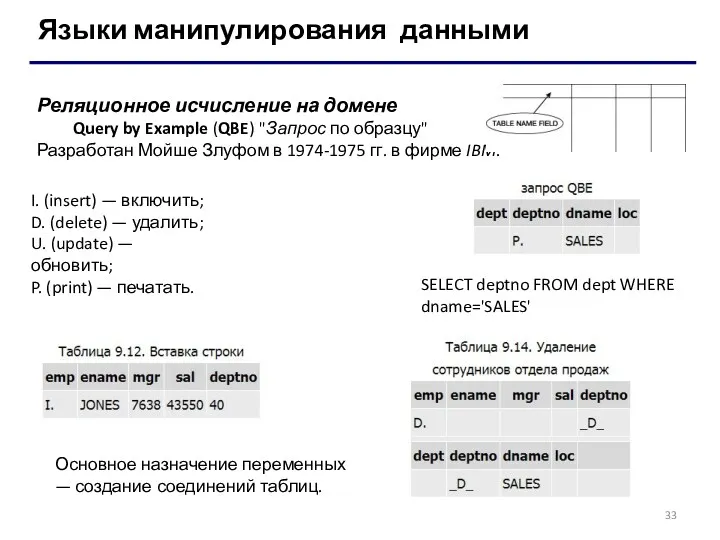
Языки манипулирования данными
Реляционное исчисление на домене
Query by Example (QBE) "Запрос по образцу"
Разработан
Языки манипулирования данными
Реляционное исчисление на домене
Query by Example (QBE) "Запрос по образцу"
Разработан
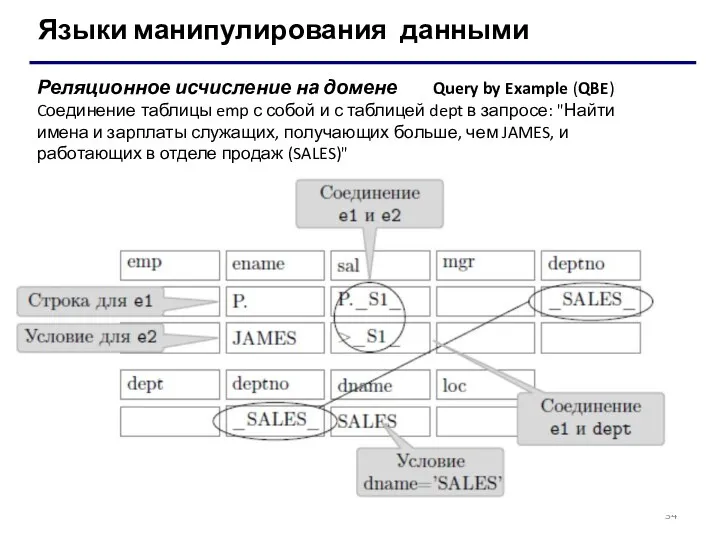
Языки манипулирования данными
Реляционное исчисление на домене Query by Example (QBE)
Cоединение таблицы emp с собой
Языки манипулирования данными
Реляционное исчисление на домене Query by Example (QBE)
Cоединение таблицы emp с собой

Языки манипулирования данными
Данный способ создания запросов позволяет получить высокую наглядность и
Языки манипулирования данными
Данный способ создания запросов позволяет получить высокую наглядность и

Технологии баз данных
Тема 9. SQL
Технологии баз данных
Тема 9. SQL
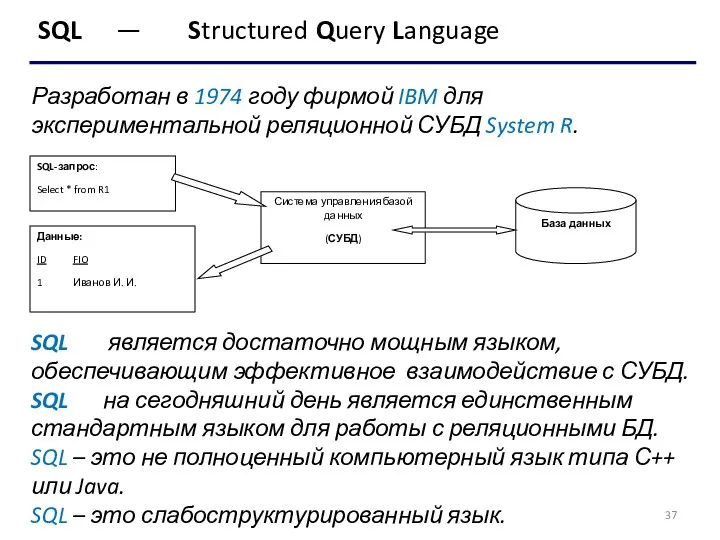
SQL — Structured Query Language
Разработан в 1974 году фирмой IBM для
SQL — Structured Query Language
Разработан в 1974 году фирмой IBM для
SQL — Structured Query Language
Используется для:
Организация данных.
SQL дает пользователю
SQL — Structured Query Language
Используется для:
Организация данных.
SQL дает пользователю
SQL — Structured Query Language
Достоинства SQL.
SQL – это легкий для понимания
SQL — Structured Query Language
Достоинства SQL.
SQL – это легкий для понимания

SQL — Structured Query Language
Недостатки SQL
Несоответствие реляционной модели данных
Создатели реляционной
SQL — Structured Query Language
Недостатки SQL
Несоответствие реляционной модели данных
Создатели реляционной

SQL — Structured Query Language
Недостатки SQL
Отступления от стандартов
Несмотря на наличие международного
SQL — Structured Query Language
Недостатки SQL
Отступления от стандартов
Несмотря на наличие международного
SQL — Structured Query Language
Data Definition Language (DDL).
SQL — Structured Query Language
Data Definition Language (DDL).
SQL — Structured Query Language
Data Manipulation Language (DML).
SQL — Structured Query Language
Data Manipulation Language (DML).
SQL — Structured Query Language
Transaction Control Language (TCL).
SQL — Structured Query Language
Transaction Control Language (TCL).
SQL — Structured Query Language
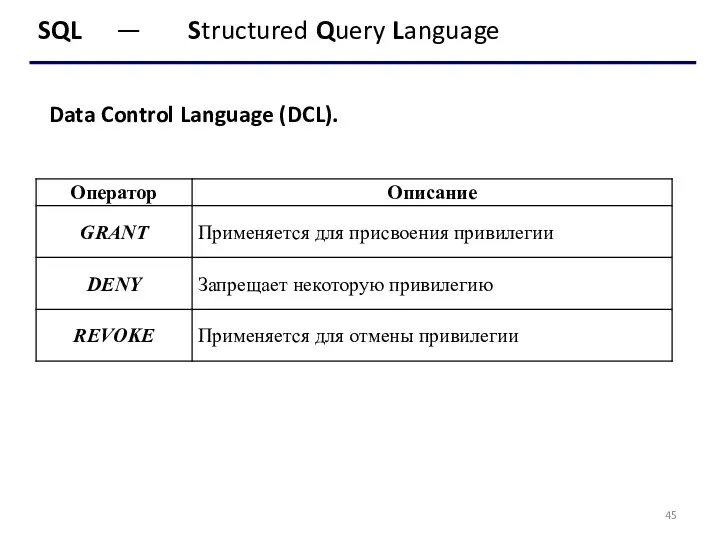
Data Control Language (DCL).
SQL — Structured Query Language
Data Control Language (DCL).
![SQL — Structured Query Language SELECT [[ALL] | DISTINCT] [ТОР](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-45.jpg)
SQL — Structured Query Language
SELECT [[ALL] | DISTINCT] [ТОР n [PERCENT]]
SQL — Structured Query Language
SELECT [[ALL] | DISTINCT] [ТОР n [PERCENT]]

SQL — Structured Query Language
Этот оператор можно прочитать следующим образом:
SELECT (выбрать)
SQL — Structured Query Language
Этот оператор можно прочитать следующим образом:
SELECT (выбрать)
SQL — Structured Query Language
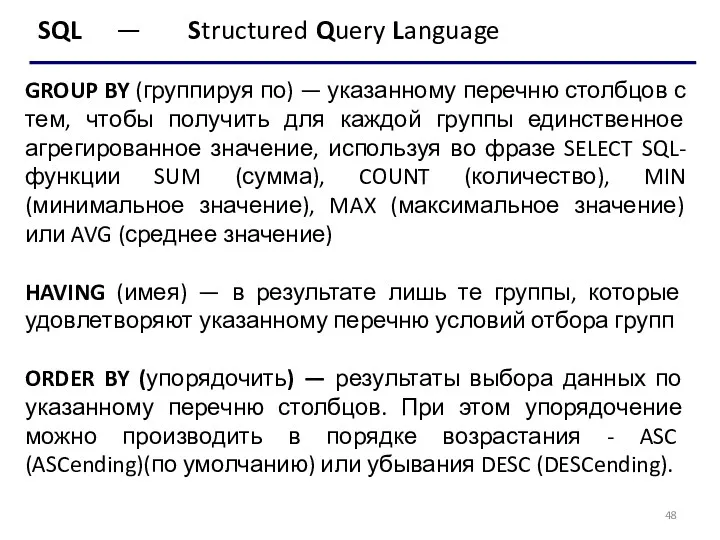
GROUP BY (группируя по) — указанному перечню
SQL — Structured Query Language
GROUP BY (группируя по) — указанному перечню

SQL — Structured Query Language
Параметры раздела обозначают следующее:
ALL – указывает, что
SQL — Structured Query Language
Параметры раздела обозначают следующее:
ALL – указывает, что
SQL — Structured Query Language
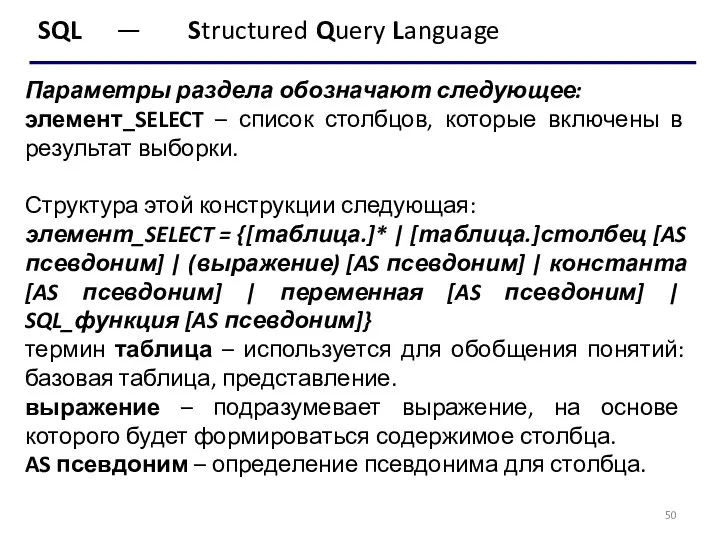
Параметры раздела обозначают следующее:
элемент_SELECT – список столбцов,
SQL — Structured Query Language
Параметры раздела обозначают следующее:
элемент_SELECT – список столбцов,

Выборка c использованием фразы WHERE
Раздел WHERE предназначен для ограничения количества строк,
Выборка c использованием фразы WHERE
Раздел WHERE предназначен для ограничения количества строк,

Выборка c использованием фразы WHERE
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
SELECT ФИО
FROM R2
WHERE
Выборка c использованием фразы WHERE
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
SELECT ФИО
FROM R2
WHERE
![Объединение UNION [ALL] Предложение UNION приводит к появлению в результирующем](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-52.jpg)
Объединение
<запрос 1>
UNION [ALL]
<запрос 2>
Предложение UNION приводит к появлению в результирующем наборе всех
Объединение
<запрос 1>
UNION [ALL]
<запрос 2>
Предложение UNION приводит к появлению в результирующем наборе всех
![Пересечение и разность INTERSECT [ALL] (пересечение) EXCEPT [ALL] (разность В](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-53.jpg)
Пересечение и разность
INTERSECT [ALL] (пересечение)
EXCEPT [ALL] (разность
В результирующий набор попадают только те строки,
Пересечение и разность
INTERSECT [ALL] (пересечение)
EXCEPT [ALL] (разность
В результирующий набор попадают только те строки,
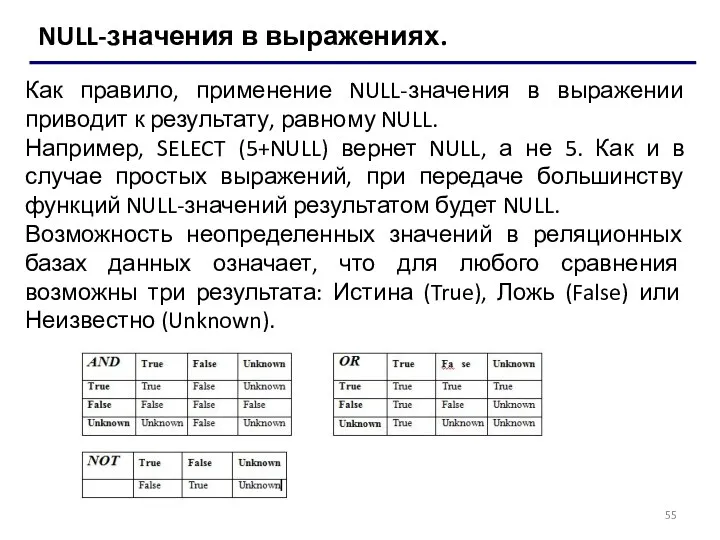
NULL-значения в выражениях.
Как правило, применение NULL-значения в выражении приводит к результату,
NULL-значения в выражениях.
Как правило, применение NULL-значения в выражении приводит к результату,

NULL-значения в выражениях.
Функции, специально предназначенные для работы с неопределенными значениями.
ISNULL
NULL-значения в выражениях.
Функции, специально предназначенные для работы с неопределенными значениями.
ISNULL

NULL-значения в выражениях.
SELECT Название,
ISNULL(Жанр, ‘Не указан’) as [Жанр книги]
FROM Книги
WHERE Жанр IS
NULL-значения в выражениях.
SELECT Название,
ISNULL(Жанр, ‘Не указан’) as [Жанр книги]
FROM Книги
WHERE Жанр IS

Использование BETWEEN
BETWEEN … AND … (находится в интервале от ... до
Использование BETWEEN
BETWEEN … AND … (находится в интервале от ... до

Использование IN (NOT IN).
Задает поиск выражения, включенного или исключенного
из списка.
Использование IN (NOT IN).
Задает поиск выражения, включенного или исключенного
из списка.

Использование LIKE.
LIKE определяет, совпадает ли указанная символьная строка с заданным шаблоном.
Использование LIKE.
LIKE определяет, совпадает ли указанная символьная строка с заданным шаблоном.

Использование LIKE.
SELECT ФИО, Должность, Телефон
FROM Сотрудники
WHERE Должность LIKE ‘% редактор’
OR Должность =
Использование LIKE.
SELECT ФИО, Должность, Телефон
FROM Сотрудники
WHERE Должность LIKE ‘% редактор’
OR Должность =
![Предикат EXISTS [NOT] EXISTS ( ) Предикат EXISTS принимает значение](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-61.jpg)
Предикат EXISTS
[NOT] EXISTS (<табличный подзапрос>)
Предикат EXISTS принимает значение TRUE, если подзапрос содержит любое количество
Предикат EXISTS
[NOT] EXISTS (<табличный подзапрос>)
Предикат EXISTS принимает значение TRUE, если подзапрос содержит любое количество

Использование ключевых слов SOME (ANY) и ALL с предикатами сравнения
<выражение> <оператор
Использование ключевых слов SOME (ANY) и ALL с предикатами сравнения
<выражение> <оператор

Использование агрегатных функций для подведения итогов.
В SQL существует ряд специальных агрегатных
Использование агрегатных функций для подведения итогов.
В SQL существует ряд специальных агрегатных

Использование агрегатных функций для подведения итогов.
Выражение, определяющее столбец такой таблицы, может
Использование агрегатных функций для подведения итогов.
Выражение, определяющее столбец такой таблицы, может

Агрегатные функции без использования фразы GROUP BY.
Если не используется фраза GROUP
Агрегатные функции без использования фразы GROUP BY.
Если не используется фраза GROUP

Фраза GROUP BY
Фраза GROUP BY (группировать по) инициирует перекомпоновку указанной во
Фраза GROUP BY
Фраза GROUP BY (группировать по) инициирует перекомпоновку указанной во

Раздел HAVING.
Предложение HAVING подобно предложению WHERE, но применимо только к целым
Раздел HAVING.
Предложение HAVING подобно предложению WHERE, но применимо только к целым
![Раздел HAVING. SELECT [Номер заказа], count(*) as [Количество позиций] ,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-68.jpg)
Раздел HAVING.
SELECT [Номер заказа],
count(*) as [Количество позиций] ,
sum(количество) as
Раздел HAVING.
SELECT [Номер заказа],
count(*) as [Количество позиций] ,
sum(количество) as

Раздел HAVING.
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
Найти студентов, имеющих лучший средний
балл
Раздел HAVING.
R1(ФИО, Дисциплина, Оценка)
R2(ФИО, Группа)
R3(Группа, Дисциплина)
Найти студентов, имеющих лучший средний
балл
![Раздел HAVING. SELECT [Номер заказа], count(*) as [Количество книг] FROM](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-70.jpg)
Раздел HAVING.
SELECT [Номер заказа], count(*) as [Количество книг]
FROM [Состав заказа]
WHERE
Раздел HAVING.
SELECT [Номер заказа], count(*) as [Количество книг]
FROM [Состав заказа]
WHERE

Обобщенные табличные выражения (СТЕ).
Обобщенные табличные выражения (CTE) помогают повысить удобочитаемость
Обобщенные табличные выражения (СТЕ).
Обобщенные табличные выражения (CTE) помогают повысить удобочитаемость
![Синтаксис фразы GROUP BY GROUP BY [ALL] [ CUBE |](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-73.jpg)
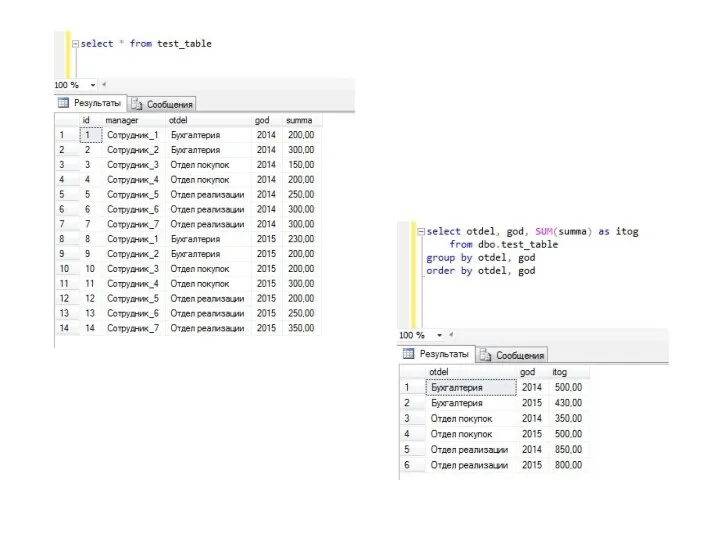
Синтаксис фразы GROUP BY
GROUP BY [ALL] [ CUBE | ROLLUP] {[таблица.]столбец
Синтаксис фразы GROUP BY
GROUP BY [ALL] [ CUBE | ROLLUP] {[таблица.]столбец
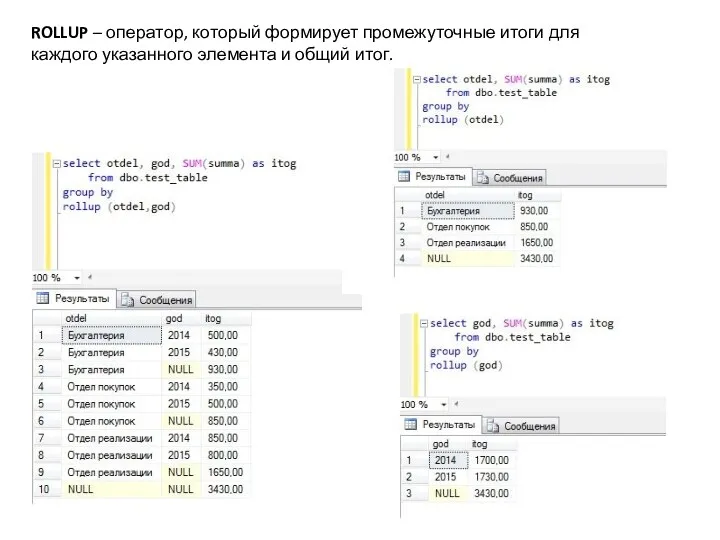
ROLLUP – оператор, который формирует промежуточные итоги для каждого указанного элемента и
ROLLUP – оператор, который формирует промежуточные итоги для каждого указанного элемента и
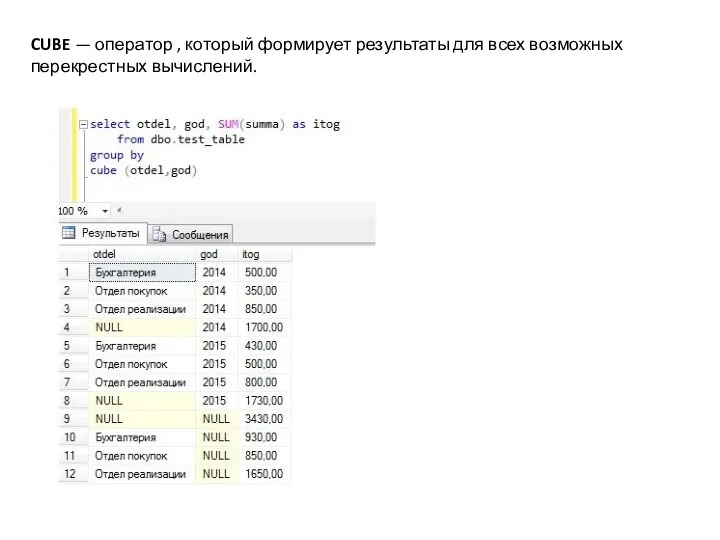
CUBE — оператор , который формирует результаты для всех возможных перекрестных вычислений.
CUBE — оператор , который формирует результаты для всех возможных перекрестных вычислений.
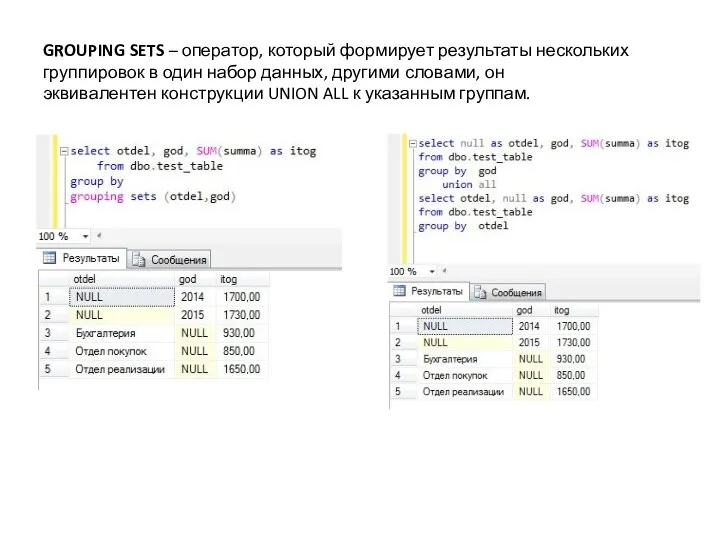
GROUPING SETS – оператор, который формирует результаты нескольких группировок в один набор
GROUPING SETS – оператор, который формирует результаты нескольких группировок в один набор
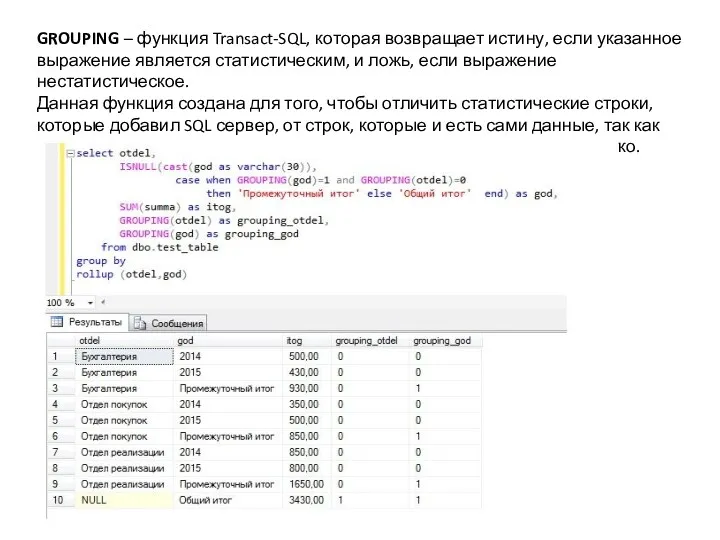
GROUPING – функция Transact-SQL, которая возвращает истину, если указанное выражение является статистическим,
GROUPING – функция Transact-SQL, которая возвращает истину, если указанное выражение является статистическим,

Выражение CASE
Оценка списка условий и возвращение одного из нескольких возможных выражений
Выражение CASE
Оценка списка условий и возвращение одного из нескольких возможных выражений
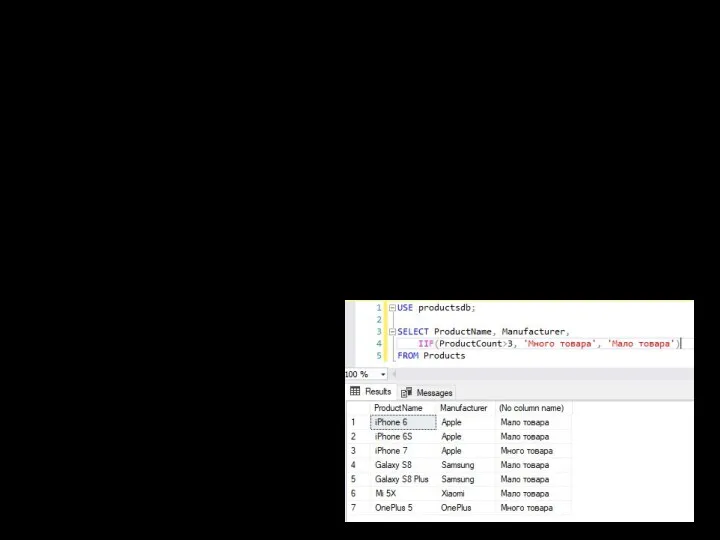
IIF
Функция IIF в зависимости от результата условного выражения возвращает одно из двух значений.
IIF
Функция IIF в зависимости от результата условного выражения возвращает одно из двух значений.

Соединения «с условием WHERE».
Cоединения - это подмножества декартова произведения.
SELECT *
FROM Клиент,
Соединения «с условием WHERE».
Cоединения - это подмножества декартова произведения.
SELECT *
FROM Клиент,
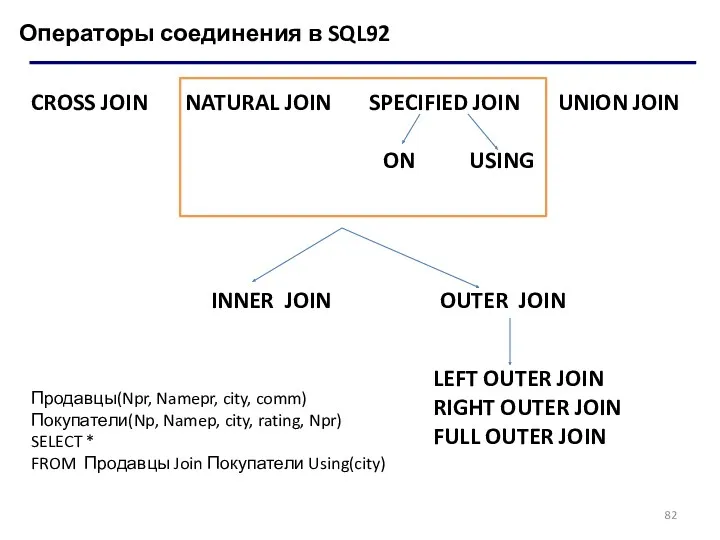
Операторы соединения в SQL92
CROSS JOIN NATURAL JOIN SPECIFIED JOIN UNION JOIN
Операторы соединения в SQL92
CROSS JOIN NATURAL JOIN SPECIFIED JOIN UNION JOIN

Соединения нескольких таблиц, используя JOIN.
Существует три основных типа соединения:
внутреннее соединение,
Соединения нескольких таблиц, используя JOIN.
Существует три основных типа соединения:
внутреннее соединение,
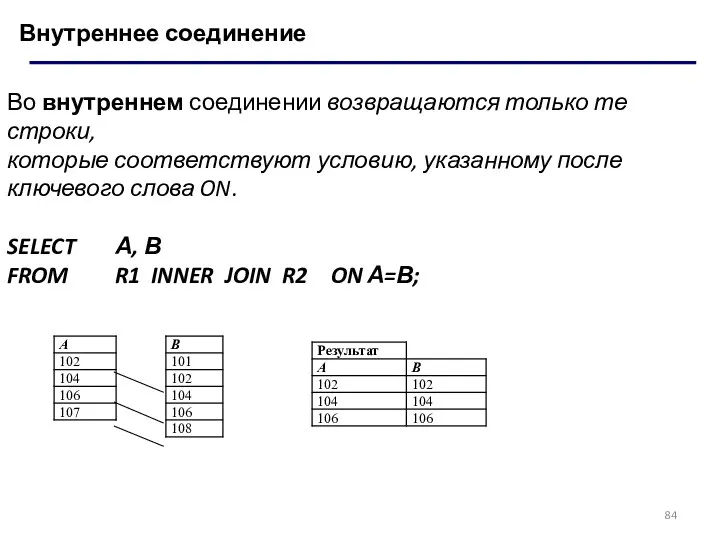
Внутреннее соединение
Во внутреннем соединении возвращаются только те строки,
которые соответствуют условию,
Внутреннее соединение
Во внутреннем соединении возвращаются только те строки,
которые соответствуют условию,

Левое внешнее соединение.
В левом внешнем соединении результатом являются все строки
левой
Левое внешнее соединение.
В левом внешнем соединении результатом являются все строки
левой

Правое внешнее соединение.
В правом внешнем соединении результатом являются все
строки правой
Правое внешнее соединение.
В правом внешнем соединении результатом являются все
строки правой

Полное внешнее соединение.
В полном внешнем соединении результатом являются строки
обеих таблицы,
Полное внешнее соединение.
В полном внешнем соединении результатом являются строки
обеих таблицы,

Перекрёстное соединение.
В перекрёстном соединении каждая строка из одной таблицы
соединяется с
Перекрёстное соединение.
В перекрёстном соединении каждая строка из одной таблицы
соединяется с

PIVOT и UNPIVOT
SELECT maker, type FROM product;
Maker type
B PC
A PC
A PC
E PC
A Printer
D Printer
A
PIVOT и UNPIVOT
SELECT maker, type FROM product;
Maker type
B PC
A PC
A PC
E PC
A Printer
D Printer
A

SELECT maker,
SUM(CASE type WHEN 'pc' THEN 1 ELSE 0 END) PC,
SELECT maker,
SUM(CASE type WHEN 'pc' THEN 1 ELSE 0 END) PC,
![SELECT , [first pivoted column] AS , [second pivoted column]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582888/slide-90.jpg)
SELECT ,
[first pivoted column] AS ,
[second pivoted
SELECT
[first pivoted column] AS
[second pivoted

SELECT screen, AVG(price) avg_ FROM Laptop GROUP BY screen
screen avg_
11
SELECT screen, AVG(price) avg_ FROM Laptop GROUP BY screen
screen avg_
11

trip_no spec info
1100 id_comp 4
1100 Plane Boeing
1100 town_from
trip_no spec info
1100 id_comp 4
1100 Plane Boeing
1100 town_from
 Разработка логической игры Пазлы на платформе UNITY
Разработка логической игры Пазлы на платформе UNITY Introduction to computer systems. Architecture of computer systems. Lecture2
Introduction to computer systems. Architecture of computer systems. Lecture2 Брейн ринг по информатике
Брейн ринг по информатике Готовимся к ЕГЭ. Задание №12. IP-адрес
Готовимся к ЕГЭ. Задание №12. IP-адрес Презентация по информатике Умники и умницы
Презентация по информатике Умники и умницы Модели надежности
Модели надежности Электронный учебник по информатике
Электронный учебник по информатике Виды современных компьютеров (от мощных компьютерных систем, до мини-компьютеров)
Виды современных компьютеров (от мощных компьютерных систем, до мини-компьютеров) Информатика и история развития информационных технологий
Информатика и история развития информационных технологий Логические значения. Ветвление (Delphi)
Логические значения. Ветвление (Delphi) Модели информационных процессов
Модели информационных процессов WEB-дизайн. Эргономика WEB-сайта
WEB-дизайн. Эргономика WEB-сайта HTML: Базові, основні та складні елементи. Лекция 25
HTML: Базові, основні та складні елементи. Лекция 25 Интернет-технологии. Интернет-маркетинг
Интернет-технологии. Интернет-маркетинг Интеллектуальные методы в экономике и бизнесе
Интеллектуальные методы в экономике и бизнесе Навигатор дополнительного образования
Навигатор дополнительного образования Web index report. Аудитория интернет-проектов. Результаты исследования: Март 2016
Web index report. Аудитория интернет-проектов. Результаты исследования: Март 2016 Компьютерные атаки
Компьютерные атаки История связи. Простейшие средства связи
История связи. Простейшие средства связи Информационные технологии
Информационные технологии Алгоритм и его формальное исполнение
Алгоритм и его формальное исполнение Спам. Возникновение, распространение, способы защиты
Спам. Возникновение, распространение, способы защиты Цифровые технологии при съемках фильма Аватар
Цифровые технологии при съемках фильма Аватар Урок Группы клавиш. Основная позиция пальцев на клавиатуре 5 класс
Урок Группы клавиш. Основная позиция пальцев на клавиатуре 5 класс Создание мобильной версии сайта
Создание мобильной версии сайта Объекты и их имена. Признаки объектов. (Урок 1)
Объекты и их имена. Признаки объектов. (Урок 1) Software upgrade guide
Software upgrade guide Внесение данных в информационную систему Мониторинг оказания паллиативной медицинской помощи взрослому населению и детям
Внесение данных в информационную систему Мониторинг оказания паллиативной медицинской помощи взрослому населению и детям