- Базы данных, банки данных, история развития СУБД (лекция 1)

Содержание
- 2. ВВЕДЕНИЕ Социальные сети, мобильные устройства, показатели разного рода оборудования, всевозможная бизнес-информация, научные исследования — источники формирования
- 3. ВВЕДЕНИЕ За минуту Google обрабатывает около 2 миллионов поисковых запросов и отдает пользователям 72 часа видео
- 4. ВВЕДЕНИЕ Все предприятия осуществляют свою деятельность и/или управляют процессами производства с помощью информационных технологий, информационных систем.
- 5. АВТОМАТИЗИРОВАННЫЕ СИСТЕМЫ Под автоматизированной системой обработки информации (АС) мы будем понимать совокупность: 1. средств вычислительной техники;
- 6. Основные понятия и определения Основной формой организации информационных массивов в ИС являются базы данных. База данных
- 7. Примеры современных ИС ИС «Бюро кредитных историй клиентов банка». Банковские системы, системы торговых расчетов в супермаркетах,
- 8. Проверка штрафов ГИБДД на GIBDD.RU
- 9. ПРИОРИТЕТ НА БЛИЖАЙШИЕ ГОДЫ В РАЗВИТИИ ИС Поддержка обработки и хранения больших массивов данных. Развитие видеоаналитики
- 10. ТЕНДЕНЦИИ РАЗВИТИЯ ИТ Большие затраты на техническое обслуживание систем хранения и обработки данных заставляют компании искать
- 11. ТЕНДЕНЦИИ РАЗВИТИЯ ИТ Сегодня ежедневно генерируется так много данных, что по ним можно достаточно точно составить
- 12. ОСОБЕННОСТИ СОВРЕМЕННЫХ АИС Терабайтные объёмы данных. Разнородность и сильная связанность между собой данных. Требования к производительности
- 13. ВВЕДЕНИЕ В БД
- 14. Банк данных - это система специальным образом организованных баз данных, программных, технических, языковых, организационно-методических средств, предназначенных
- 15. Банк данных (БнД) Информационная компонента Программные средства Языковые средства БнД Технические средства БнД Организационно-методические средства БнД
- 17. Основу базы знаний составляют факты и правила. Данные - это отдельные факты, характеризующие объекты, процессы и
- 18. ИНФОРМАЦИОННОЕ ОБЕСПЕЧЕНИЕ ЭКСПЕРТНОЙ СИСТЕМЫ База данных - предназначена для хранения исходных и промежуточных данных решаемой в
- 19. Типовая структура экспертных систем
- 20. СТРУКТУРА БАЗЫ ЗНАНИЙ Болезнь_1, p, j, py, pn, 999, Болезнь_2, p, j, py, pn, 999, P
- 21. Обеспечивают интерфейс пользователей разных категорий с банком данных. В настоящее время используются языковые средства - табличный
- 22. ЯЗЫК SQL Structured Query Language (SQL)— это непроцедурный язык, используемый для формулировки запросов к данным в
- 23. Запросы к БД Расписание Москва - Киев на вечернее время Выбрать Номер_рейса, Дни_недели, Время_вылета из таблицы
- 24. РАЗВИТИЕ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ И СУБД Развитие вычислительной техники происходило в двух основных направлениях. Первое направление -
- 25. РАЗВИТИЕ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ Второе направление - это использование средств ВТ в автоматических или автоматизированных информационных системах.
- 26. СУБД Система управления базами данных (СУБД) — совокупность программных, технических и языковых средств общего или специального
- 27. СУБД СУБД обеспечивает физическую и логическую независимость прикладной программы от данных. В современной СУБД можно выделить
- 28. КРИТЕРИИ, ПО КОТОРЫМ ВЫБИРАЮТ СУБД производительность, безопасность, масштабируемость, обновляемость, уровень техподдержки, работа с очень большими данными,
- 29. DB-Engines учитывает факторы: 1. Количество упоминаний о продукте в Сети, оцениваемое по результатам поисковых запросов (Google
- 30. ПОПУЛЯРНОСТЬ СУБД
- 31. ПОПУЛЯРНОСТЬ СУБД
- 32. ПОПУЛЯРНОСТЬ СУБД
- 33. По данным сайта DB-Engines, приводящего рейтинги различных СУБД, нынешнее соотношение популярности коммерческих и открытых СУБД составляет
- 34. СРАВНЕНИЕ СУБД – мнение экспертов Для роста производительности СУБД в Oracle используются технологии поколоночного хранения, процедуры
- 35. СРАВНЕНИЕ СУБД Аргументом в пользу PostgreSQL является наличие российских разработчиков, которые входят в международную команду разработчиков,
- 36. POSTGRESQL
- 37. ИСТОРИЯ РАЗВИТИЯ СУБД 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM.
- 38. ИСТОРИЯ РАЗВИТИЯ СУБД Этапы в развитии направления по обработке данных: Базы данных на больших ЭВМ: все
- 39. ИСТОРИЯ РАЗВИТИЯ СУБД поддерживаются языки низкого уровня манипулирования данными; значительная роль отводится администрированию данных; проводятся работы
- 40. ИСТОРИЯ РАЗВИТИЯ СУБД Эпоха персональных компьютеров: компьютеры стали доступнее, СУБД рассчитаны в основном на монопольный доступ,
- 41. ИСТОРИЯ РАЗВИТИЯ СУБД После процесса "персонализации" начался обратный процесс — интеграция. Множится количество локальных сетей, встает
- 42. ИСТОРИЯ РАЗВИТИЯ СУБД Распределенные базы данных: поддержка многопользовательской работы с БД и децентрализованного хранения данных потребовали
- 43. ДАЛЬНЕЙШИЕ ПЕРСПЕКТИВЫ РАЗВИТИЯ Появился интернет. Отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной
- 44. ТОПОЛОГИЯ АРХИТЕКТУРЫ ТЕЛЕОБРАБОТКИ Один компьютер соединен с несколькими "неинтеллектуальными" терминалами. СУБД и сама БД размещается и
- 45. АРХИТЕКТУРА ФАЙЛОВОГО СЕРВЕРА Системы данного типа функционируют в рамках локальных вычислительных сетей. Одна машина выделена в
- 46. АРХИТЕКТУРА ФАЙЛОВОГО СЕРВЕРА Недостатки: Большой объем сетевого трафика. Производительность такой системы падает, если требуется интенсивный одновременный
- 47. АРХИТЕКТУРА “КЛИЕНТ/СЕРВЕР” Клиент-серверные системы. В этой структуре один из компьютеров, имеющий самый большой объем памяти и
- 48. СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР” Клиент: - Принимает и проверяет синтаксис введенного пользователем запроса; -
- 49. СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР” Основные достоинства централизованной архитектуры - простота администрирования и защиты информации.
- 50. СХЕМА ПОСТРОЕНИЯ СИСТЕМ С ТРЕХУРОВНЕВОЙ АРХИТЕКТУРОЙ Один из компьютеров, имеющий самый большой объем памяти и наиболее
- 51. СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР” Тонкий клиент - система, имеющая минимум программных и аппаратных средств,
- 52. ИСТОРИЯ РАЗВИТИЯ СУБД Файловые системы были первой попыткой компьютеризировать ручные картотеки. Ручные картотеки позволяют успешно справляться
- 53. ИСТОРИЯ РАЗВИТИЯ СУБД Файловые системы - набор прикладных программ, которые выполняют для пользователей некоторые операции, например
- 54. ОГРАНИЧЕНИЯ, ПРИСУЩИЕ ФАЙЛОВЫМ СИСТЕМАМ: Разделение и изоляция данных. Дублирование данных. Зависимость от данных. Несовместимость файлов. Фиксированные
- 55. ПРЕИМУЩЕСТВА СУБД Контроль за избыточностью данных. Непротиворечивость данных. Больше полезной информации при том же объеме хранимых
- 56. ПРЕИМУЩЕСТВА СУБД Возможность нахождения компромисса при противоречивых требованиях. Повышение доступности данных и их готовности к работе.
- 57. НЕДОСТАТКИ СУБД Сложность. Размер. Стоимость СУБД. Дополнительные затраты на аппаратное обеспечение. Затраты на преобразование. Производительность. Более
- 58. ОСНОВНЫЕ КОМПОНЕНТЫ СИСТЕМЫ ЗАЩИТЫ БАЗ ДАННЫХ 1) физическая защита ПК и носителей информации; 2)опознавание (аутентификация) пользователей
- 60. Скачать презентацию

ВВЕДЕНИЕ
Социальные сети, мобильные устройства, показатели разного рода оборудования, всевозможная бизнес-информация, научные
ВВЕДЕНИЕ
Социальные сети, мобильные устройства, показатели разного рода оборудования, всевозможная бизнес-информация, научные

ВВЕДЕНИЕ
За минуту Google обрабатывает около 2 миллионов поисковых запросов и отдает
ВВЕДЕНИЕ
За минуту Google обрабатывает около 2 миллионов поисковых запросов и отдает

ВВЕДЕНИЕ
Все предприятия осуществляют свою деятельность и/или управляют процессами производства с помощью
ВВЕДЕНИЕ
Все предприятия осуществляют свою деятельность и/или управляют процессами производства с помощью

АВТОМАТИЗИРОВАННЫЕ СИСТЕМЫ
Под автоматизированной системой обработки информации (АС) мы будем понимать совокупность:
1.
АВТОМАТИЗИРОВАННЫЕ СИСТЕМЫ
Под автоматизированной системой обработки информации (АС) мы будем понимать совокупность:
1.

Основные понятия и определения
Основной формой организации информационных массивов в ИС являются
Основные понятия и определения
Основной формой организации информационных массивов в ИС являются

Примеры современных ИС
ИС «Бюро кредитных историй клиентов банка».
Банковские системы, системы торговых
Примеры современных ИС
ИС «Бюро кредитных историй клиентов банка».
Банковские системы, системы торговых
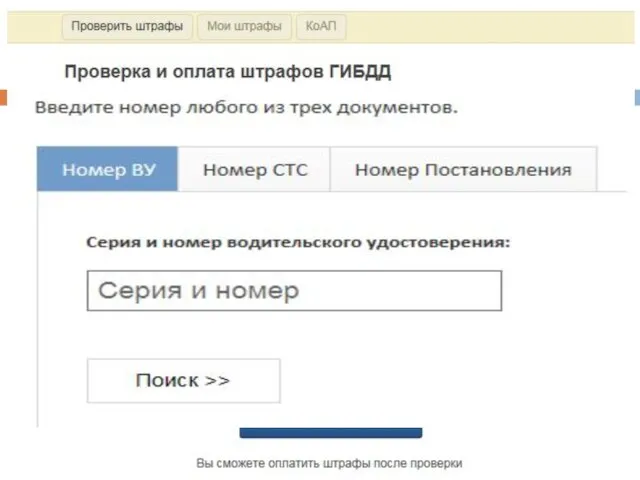
Проверка штрафов ГИБДД на GIBDD.RU
Проверка штрафов ГИБДД на GIBDD.RU

ПРИОРИТЕТ НА БЛИЖАЙШИЕ ГОДЫ В РАЗВИТИИ ИС
Поддержка обработки и хранения больших массивов
ПРИОРИТЕТ НА БЛИЖАЙШИЕ ГОДЫ В РАЗВИТИИ ИС
Поддержка обработки и хранения больших массивов

ТЕНДЕНЦИИ РАЗВИТИЯ ИТ
Большие затраты на техническое обслуживание систем хранения и обработки
ТЕНДЕНЦИИ РАЗВИТИЯ ИТ
Большие затраты на техническое обслуживание систем хранения и обработки

ТЕНДЕНЦИИ РАЗВИТИЯ ИТ
Сегодня ежедневно генерируется так много данных, что по ним
ТЕНДЕНЦИИ РАЗВИТИЯ ИТ
Сегодня ежедневно генерируется так много данных, что по ним

ОСОБЕННОСТИ СОВРЕМЕННЫХ АИС
Терабайтные объёмы данных.
Разнородность и сильная связанность между собой данных.
Требования
ОСОБЕННОСТИ СОВРЕМЕННЫХ АИС
Терабайтные объёмы данных.
Разнородность и сильная связанность между собой данных.
Требования
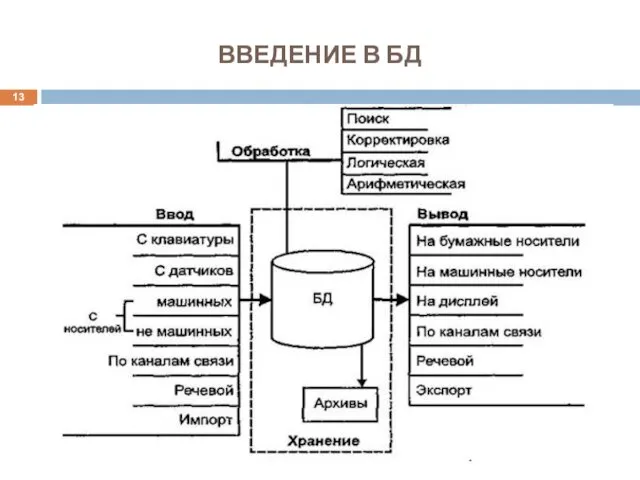
ВВЕДЕНИЕ В БД
ВВЕДЕНИЕ В БД

Банк данных - это система специальным образом организованных баз данных, программных,
Банк данных - это система специальным образом организованных баз данных, программных,
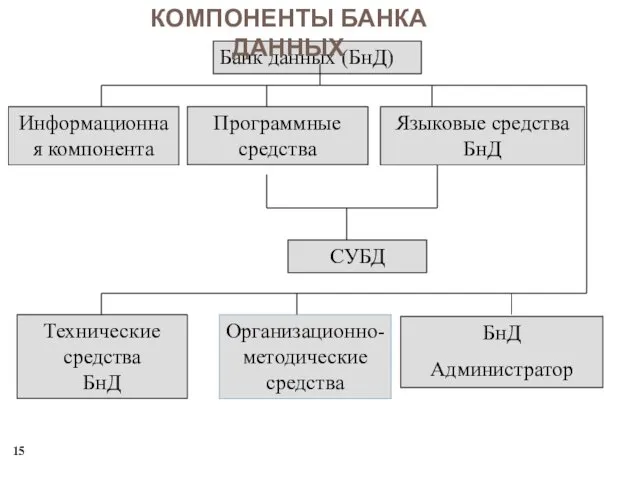
Банк данных (БнД)
Информационная компонента
Программные средства
Языковые средства БнД
Технические средства БнД
Организационно-методические средства
БнД
Банк данных (БнД)
Информационная компонента
Программные средства
Языковые средства БнД
Технические средства БнД
Организационно-методические средства
БнД


Основу базы знаний составляют факты и правила.
Данные - это отдельные факты,
Основу базы знаний составляют факты и правила.
Данные - это отдельные факты,

ИНФОРМАЦИОННОЕ ОБЕСПЕЧЕНИЕ ЭКСПЕРТНОЙ СИСТЕМЫ
База данных - предназначена для хранения исходных и
ИНФОРМАЦИОННОЕ ОБЕСПЕЧЕНИЕ ЭКСПЕРТНОЙ СИСТЕМЫ
База данных - предназначена для хранения исходных и
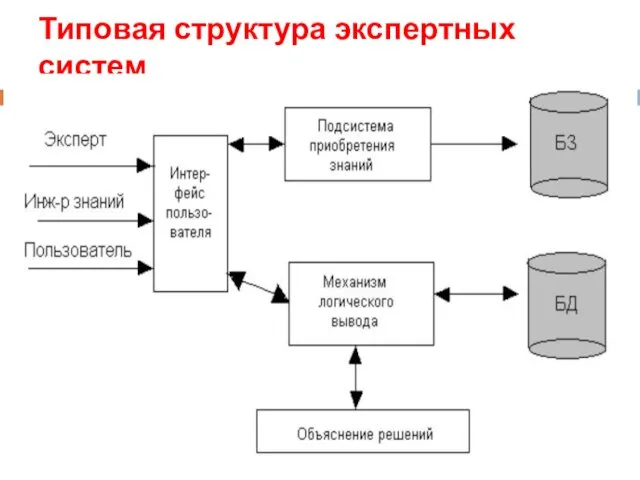
Типовая структура экспертных систем
Типовая структура экспертных систем

СТРУКТУРА БАЗЫ ЗНАНИЙ
Болезнь_1, p, j, py, pn, 999,
Болезнь_2, p, j, py,
СТРУКТУРА БАЗЫ ЗНАНИЙ
Болезнь_1, p, j, py, pn, 999,
Болезнь_2, p, j, py,

Обеспечивают интерфейс пользователей разных категорий с банком данных.
В настоящее время используются
Обеспечивают интерфейс пользователей разных категорий с банком данных.
В настоящее время используются

ЯЗЫК SQL
Structured Query Language (SQL)— это непроцедурный язык, используемый для формулировки
ЯЗЫК SQL
Structured Query Language (SQL)— это непроцедурный язык, используемый для формулировки

Запросы к БД
Расписание Москва - Киев на вечернее время
Выбрать Номер_рейса, Дни_недели,
Запросы к БД
Расписание Москва - Киев на вечернее время Выбрать Номер_рейса, Дни_недели,

РАЗВИТИЕ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ И СУБД
Развитие вычислительной техники происходило в двух основных
РАЗВИТИЕ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ И СУБД
Развитие вычислительной техники происходило в двух основных

РАЗВИТИЕ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ
Второе направление - это использование средств ВТ в автоматических
РАЗВИТИЕ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ
Второе направление - это использование средств ВТ в автоматических

СУБД
Система управления базами данных (СУБД) — совокупность программных, технических и языковых средств
СУБД
Система управления базами данных (СУБД) — совокупность программных, технических и языковых средств

СУБД
СУБД обеспечивает физическую и логическую независимость прикладной программы от данных.
В современной
СУБД
СУБД обеспечивает физическую и логическую независимость прикладной программы от данных.
В современной

КРИТЕРИИ, ПО КОТОРЫМ ВЫБИРАЮТ СУБД
производительность,
безопасность,
масштабируемость,
обновляемость,
уровень техподдержки,
работа
КРИТЕРИИ, ПО КОТОРЫМ ВЫБИРАЮТ СУБД
производительность,
безопасность,
масштабируемость,
обновляемость,
уровень техподдержки,
работа

DB-Engines учитывает факторы:
1. Количество упоминаний о продукте в Сети, оцениваемое по результатам поисковых запросов
DB-Engines учитывает факторы:
1. Количество упоминаний о продукте в Сети, оцениваемое по результатам поисковых запросов
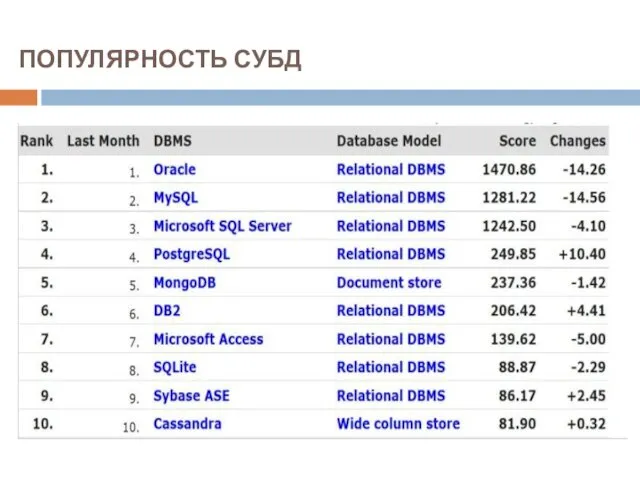
ПОПУЛЯРНОСТЬ СУБД
ПОПУЛЯРНОСТЬ СУБД
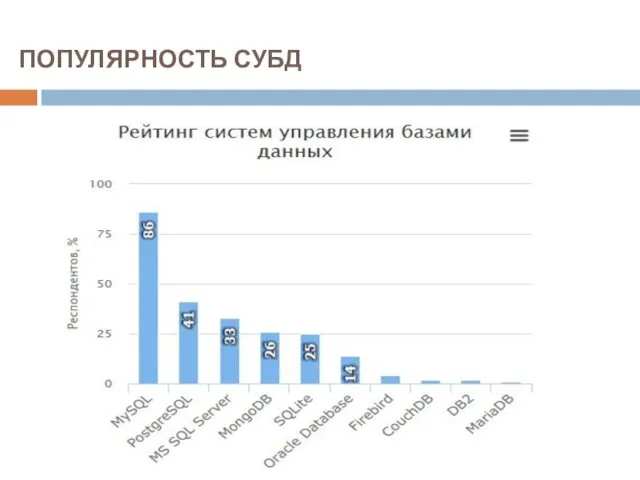
ПОПУЛЯРНОСТЬ СУБД
ПОПУЛЯРНОСТЬ СУБД
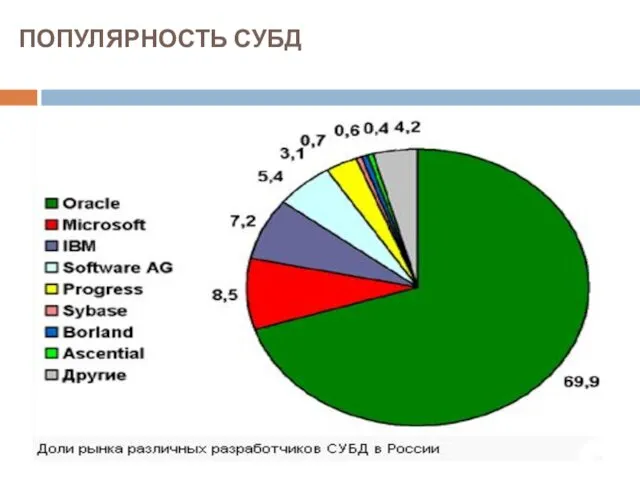
ПОПУЛЯРНОСТЬ СУБД
ПОПУЛЯРНОСТЬ СУБД

По данным сайта DB-Engines, приводящего рейтинги различных СУБД, нынешнее соотношение популярности коммерческих
По данным сайта DB-Engines, приводящего рейтинги различных СУБД, нынешнее соотношение популярности коммерческих

СРАВНЕНИЕ СУБД – мнение экспертов
Для роста производительности СУБД в Oracle используются
СРАВНЕНИЕ СУБД – мнение экспертов
Для роста производительности СУБД в Oracle используются
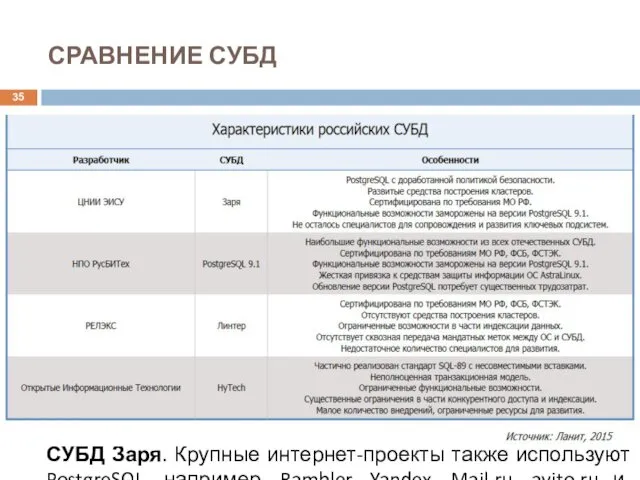
СРАВНЕНИЕ СУБД
Аргументом в пользу PostgreSQL является наличие российских разработчиков, которые входят
СРАВНЕНИЕ СУБД
Аргументом в пользу PostgreSQL является наличие российских разработчиков, которые входят

POSTGRESQL
POSTGRESQL

ИСТОРИЯ РАЗВИТИЯ СУБД
1968 году была введена в эксплуатацию первая промышленная СУБД
ИСТОРИЯ РАЗВИТИЯ СУБД
1968 году была введена в эксплуатацию первая промышленная СУБД

ИСТОРИЯ РАЗВИТИЯ СУБД
Этапы в развитии направления по обработке данных:
Базы данных на
ИСТОРИЯ РАЗВИТИЯ СУБД
Этапы в развитии направления по обработке данных:
Базы данных на

ИСТОРИЯ РАЗВИТИЯ СУБД
поддерживаются языки низкого уровня манипулирования данными;
значительная роль отводится администрированию
ИСТОРИЯ РАЗВИТИЯ СУБД
поддерживаются языки низкого уровня манипулирования данными;
значительная роль отводится администрированию

ИСТОРИЯ РАЗВИТИЯ СУБД
Эпоха персональных компьютеров:
компьютеры стали доступнее, СУБД рассчитаны в
ИСТОРИЯ РАЗВИТИЯ СУБД
Эпоха персональных компьютеров:
компьютеры стали доступнее, СУБД рассчитаны в

ИСТОРИЯ РАЗВИТИЯ СУБД
После процесса "персонализации" начался обратный процесс — интеграция. Множится
ИСТОРИЯ РАЗВИТИЯ СУБД
После процесса "персонализации" начался обратный процесс — интеграция. Множится

ИСТОРИЯ РАЗВИТИЯ СУБД
Распределенные базы данных:
поддержка многопользовательской работы с БД и децентрализованного
ИСТОРИЯ РАЗВИТИЯ СУБД
Распределенные базы данных:
поддержка многопользовательской работы с БД и децентрализованного

ДАЛЬНЕЙШИЕ ПЕРСПЕКТИВЫ РАЗВИТИЯ
Появился интернет.
Отпадает необходимость использования специализированного клиентского программного
ДАЛЬНЕЙШИЕ ПЕРСПЕКТИВЫ РАЗВИТИЯ
Появился интернет.
Отпадает необходимость использования специализированного клиентского программного
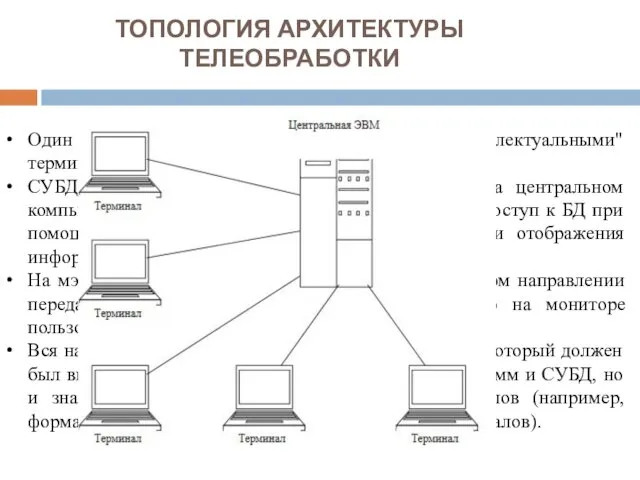
ТОПОЛОГИЯ АРХИТЕКТУРЫ ТЕЛЕОБРАБОТКИ
Один компьютер соединен с несколькими "неинтеллектуальными" терминалами.
СУБД и сама
ТОПОЛОГИЯ АРХИТЕКТУРЫ ТЕЛЕОБРАБОТКИ
Один компьютер соединен с несколькими "неинтеллектуальными" терминалами.
СУБД и сама

АРХИТЕКТУРА ФАЙЛОВОГО СЕРВЕРА
Системы данного типа функционируют в рамках локальных вычислительных сетей.
Одна
АРХИТЕКТУРА ФАЙЛОВОГО СЕРВЕРА
Системы данного типа функционируют в рамках локальных вычислительных сетей.
Одна

АРХИТЕКТУРА ФАЙЛОВОГО СЕРВЕРА
Недостатки:
Большой объем сетевого трафика.
Производительность такой системы падает,
АРХИТЕКТУРА ФАЙЛОВОГО СЕРВЕРА
Недостатки:
Большой объем сетевого трафика.
Производительность такой системы падает,

АРХИТЕКТУРА “КЛИЕНТ/СЕРВЕР”
Клиент-серверные системы. В этой структуре один из компьютеров, имеющий самый
АРХИТЕКТУРА “КЛИЕНТ/СЕРВЕР”
Клиент-серверные системы. В этой структуре один из компьютеров, имеющий самый

СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР”
Клиент:
- Принимает и проверяет синтаксис
СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР”
Клиент:
- Принимает и проверяет синтаксис

СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР”
Основные достоинства централизованной архитектуры - простота
СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР”
Основные достоинства централизованной архитектуры - простота
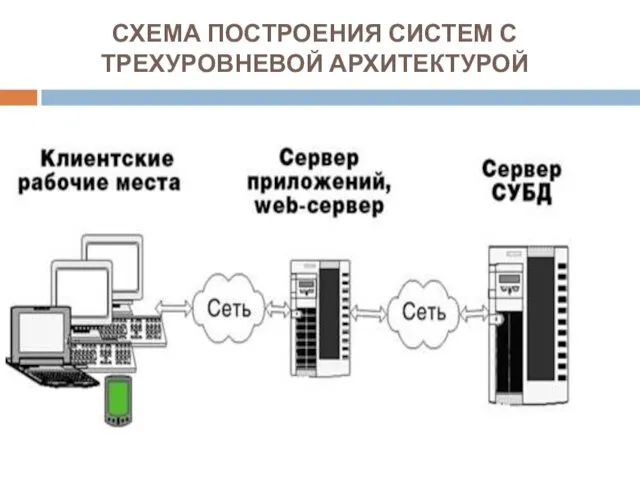
СХЕМА ПОСТРОЕНИЯ СИСТЕМ С ТРЕХУРОВНЕВОЙ АРХИТЕКТУРОЙ
Один из компьютеров, имеющий самый
СХЕМА ПОСТРОЕНИЯ СИСТЕМ С ТРЕХУРОВНЕВОЙ АРХИТЕКТУРОЙ
Один из компьютеров, имеющий самый

СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР”
Тонкий клиент - система, имеющая минимум
СХЕМА ПОСТРОЕНИЯ СИСТЕМ С АРХИТЕКТУРОЙ “КЛИЕНТ/СЕРВЕР”
Тонкий клиент - система, имеющая минимум

ИСТОРИЯ РАЗВИТИЯ СУБД
Файловые системы были первой попыткой компьютеризировать ручные картотеки.
Ручные
ИСТОРИЯ РАЗВИТИЯ СУБД
Файловые системы были первой попыткой компьютеризировать ручные картотеки.
Ручные

ИСТОРИЯ РАЗВИТИЯ СУБД
Файловые системы - набор прикладных программ, которые выполняют для
ИСТОРИЯ РАЗВИТИЯ СУБД
Файловые системы - набор прикладных программ, которые выполняют для

ОГРАНИЧЕНИЯ, ПРИСУЩИЕ ФАЙЛОВЫМ СИСТЕМАМ:
Разделение и изоляция данных.
Дублирование данных.
Зависимость от данных.
Несовместимость файлов.
Фиксированные
ОГРАНИЧЕНИЯ, ПРИСУЩИЕ ФАЙЛОВЫМ СИСТЕМАМ:
Разделение и изоляция данных.
Дублирование данных.
Зависимость от данных.
Несовместимость файлов.
Фиксированные

ПРЕИМУЩЕСТВА СУБД
Контроль за избыточностью данных.
Непротиворечивость данных.
Больше полезной информации при том же
ПРЕИМУЩЕСТВА СУБД
Контроль за избыточностью данных.
Непротиворечивость данных.
Больше полезной информации при том же

ПРЕИМУЩЕСТВА СУБД
Возможность нахождения компромисса при противоречивых требованиях.
Повышение доступности данных и их
ПРЕИМУЩЕСТВА СУБД
Возможность нахождения компромисса при противоречивых требованиях.
Повышение доступности данных и их

НЕДОСТАТКИ СУБД
Сложность.
Размер.
Стоимость СУБД.
Дополнительные затраты на аппаратное обеспечение.
Затраты на преобразование.
Производительность.
Более серьезные последствия
НЕДОСТАТКИ СУБД
Сложность.
Размер.
Стоимость СУБД.
Дополнительные затраты на аппаратное обеспечение.
Затраты на преобразование.
Производительность.
Более серьезные последствия

ОСНОВНЫЕ КОМПОНЕНТЫ СИСТЕМЫ ЗАЩИТЫ БАЗ ДАННЫХ
1) физическая защита ПК и
ОСНОВНЫЕ КОМПОНЕНТЫ СИСТЕМЫ ЗАЩИТЫ БАЗ ДАННЫХ
1) физическая защита ПК и
 Электронные российские учебники
Электронные российские учебники Коммуникация без провокации, или этика общения в социальных сетях
Коммуникация без провокации, или этика общения в социальных сетях Этика и философия искусственного интеллекта
Этика и философия искусственного интеллекта HTML - язык разметки гипертекста
HTML - язык разметки гипертекста Инструмент морф. ЗD модели
Инструмент морф. ЗD модели Тип String (java)
Тип String (java) Хранение, отбор и сортировка информации в базах данных. Лекция 19
Хранение, отбор и сортировка информации в базах данных. Лекция 19 Базы данных. Основное определение. Классификация БД
Базы данных. Основное определение. Классификация БД Проектирование информационных систем. (Лекция 10)
Проектирование информационных систем. (Лекция 10) Профессия мастер по обработке цифровой информации
Профессия мастер по обработке цифровой информации Imagine Cup. Мастер-класс по C# от MSP
Imagine Cup. Мастер-класс по C# от MSP Ашық сабақ. Интернет
Ашық сабақ. Интернет презентация к уроку информатика 6 класс Как образуются понятия
презентация к уроку информатика 6 класс Как образуются понятия БД И СУБД. Обобщение
БД И СУБД. Обобщение Сравнительный анализ дизайна интернет-сайтов
Сравнительный анализ дизайна интернет-сайтов Photo challenge: How to make and choose event photos for official Social Networks
Photo challenge: How to make and choose event photos for official Social Networks Компьютерная графика
Компьютерная графика Разработка и использование стиля. Форматирование символов, абзацев и заголовков Word 2007
Разработка и использование стиля. Форматирование символов, абзацев и заголовков Word 2007 Введение в web-программирование
Введение в web-программирование Использование информационных технологий в обучении биологии
Использование информационных технологий в обучении биологии Organizational communication. Netiquette
Organizational communication. Netiquette Апаратне забезпечення ПК
Апаратне забезпечення ПК Графические форматы
Графические форматы Гипермәтіндік белгілеулердің принциптері
Гипермәтіндік белгілеулердің принциптері Биологические модели
Биологические модели Возможные цели и задачи присутствия ТИК в социальных сетях
Возможные цели и задачи присутствия ТИК в социальных сетях Основные информационные процессы
Основные информационные процессы Разработка мультимедийного сопровождения для оценки недвижимого имущества
Разработка мультимедийного сопровождения для оценки недвижимого имущества