- Базы данных и SQL. Лекция 19 часть 2

Содержание
- 2. Повторим изученное на прошлом занятии Что такое первичный и ссылочный ключ? Что такое Реляционная база данных?
- 3. Что будем изучать сегодня Связывание сущностей 1:1 и 1: многим Обеспечение целостности Джоины Объединение (union) Minus
- 4. В этой презентации мы попробуем понять, как связывать таблицы друг с другом, но изначально необходимо определиться
- 5. 2. «Один-ко-многим» (1:М) - любому экземпляру сущности А соответствует 0, 1 или несколько экземпляров сущности В,
- 6. 3. «Многие-ко-многим» - любому экземпляру сущности А соответствует 0, 1 или несколько экземпляров сущности В, и
- 7. Обеспечение целостности В теории баз данных целостность данных означает корректность данных и их непротиворечивость. Обычно, она
- 8. Чтобы обеспечить целостность, работа с данными должна производиться с учетом нижеперечисленных правил: 1. Невозможно ввести в
- 9. JOIN Переходим непосредственно к коду. Наша задача – научиться связывать несколько таблиц в рамках одного запроса.
- 10. Inner Join Обратите внимание на диаграмму множеств. Внутреннее соединение INNER JOIN производит выборку только тех записей,
- 11. LEFT OUTER JOIN Левостороннее внешнее соединение LEFT OUTER JOIN производит полный выбор записей из таблицы, содержащейся
- 12. RIGHT OUTER JOIN Правостороннее внешнее соединение действует по аналогии с LEFT JOIN’ом. RIGHT OUTER JOIN производит
- 13. FULL OUTER JOIN Полное внешнее соединение FULL OUTER JOIN производит выборку множества всех записей из таблицы
- 14. CROSS JOIN Также существует выборка перекрестного соединения (называемое ещё декартовым произведением), - CROSS JOIN, с перебором
- 15. Работа со множествами Прежде чем начать описание функций и их свойств в SQL, работающих со множествами
- 16. Объединение. UNION Объединением двух множеств A и B называется множество, содержащее в себе все элементы исходных
- 17. Как выглядит объединение множеств на языке SQL: (SELECT * FROM sales2005) UNION (SELECT * FROM sales2006);
- 18. Разность. MINUS или EXCEPT Разность двух множеств — это операция, результатом которой является множество, в которое
- 19. Как выглядит разность множеств на языке SQL (версия для СУБД MS SQL Server): (SELECT person FROM
- 20. Агрегаты Очень часто в языке SQL ставятся задачи выделения по набору данных максимальных, минимальных или иных
- 21. Агрегаты Список функций, который входит в стандарт SQL: COUNT – функция возвращает количество элементов в группе
- 22. Группировка Выражение GROUP BY используется для определения групп выходных строк, к которым могут применяться агрегатные функции
- 23. Группировка Следует иметь в виду, что для GROUP BY все значения NULL трактуются как равные, то
- 24. Функция COUNT(*) Функция COUNT(*) возвращает количество элементов в группе. Сюда входят NULL и повторяющиеся значения. Например:
- 25. Функция COUNT(*) Функция COUNT(DISTINCT имя_поля) оценивает значения в поле для каждой строки в группе и возвращает
- 26. SUM Возвращает сумму всех, либо только уникальных (при наличии DISTINCT), значений в выражении. Функция SUM может
- 27. AVG Возвращает среднее арифметическое группы значений. Пустые множества NULL пропускаются. Функция AVG() вычисляет среднее арифметическое набора
- 28. MAX() – возвращает максимальное значение выражения. MIN() – возвращает минимальное значение выражения. NULL пропускается для обеих
- 29. Важный момент: большой плюс агрегатов состоит в том, что, в рамках одного запроса, вы можете вызвать
- 30. HAVING — необязательный (опциональный) параметр оператора SELECT для указания условия на результат агрегатных функций (MAX, SUM,
- 31. Исходя из изученных нами положений, выведем общий синтаксис запроса: SELECT [DISTINCT] {список_вывода_через_запятую | *} FROM таблица_1
- 32. Что изучили сегодня Связывание сущностей 1:1 и 1: многим Обеспечение целостности Для чего используем Джоины? Объединение
- 34. Скачать презентацию

Повторим изученное на прошлом занятии
Что такое первичный и ссылочный ключ?
Что такое
Повторим изученное на прошлом занятии
Что такое первичный и ссылочный ключ?
Что такое

Что будем изучать сегодня
Связывание сущностей 1:1 и 1: многим
Обеспечение целостности
Джоины
Объединение (union)
Minus
Что будем изучать сегодня
Связывание сущностей 1:1 и 1: многим
Обеспечение целостности
Джоины
Объединение (union)
Minus

В этой презентации мы попробуем понять, как связывать таблицы друг с
В этой презентации мы попробуем понять, как связывать таблицы друг с

2. «Один-ко-многим» (1:М) - любому экземпляру сущности А соответствует 0, 1
2. «Один-ко-многим» (1:М) - любому экземпляру сущности А соответствует 0, 1

3. «Многие-ко-многим» - любому экземпляру сущности А соответствует 0, 1 или
3. «Многие-ко-многим» - любому экземпляру сущности А соответствует 0, 1 или

Обеспечение целостности
В теории баз данных целостность данных означает корректность данных и
Обеспечение целостности
В теории баз данных целостность данных означает корректность данных и

Чтобы обеспечить целостность, работа с данными должна производиться с учетом нижеперечисленных
Чтобы обеспечить целостность, работа с данными должна производиться с учетом нижеперечисленных

JOIN
Переходим непосредственно к коду. Наша задача – научиться связывать несколько таблиц
JOIN
Переходим непосредственно к коду. Наша задача – научиться связывать несколько таблиц
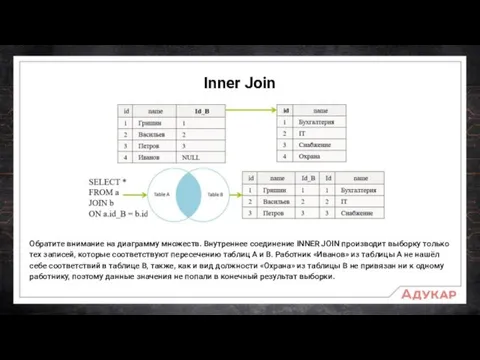
Inner Join
Обратите внимание на диаграмму множеств. Внутреннее соединение INNER JOIN производит
Inner Join
Обратите внимание на диаграмму множеств. Внутреннее соединение INNER JOIN производит

LEFT OUTER JOIN
Левостороннее внешнее соединение LEFT OUTER JOIN производит полный выбор
LEFT OUTER JOIN
Левостороннее внешнее соединение LEFT OUTER JOIN производит полный выбор

RIGHT OUTER JOIN
Правостороннее внешнее соединение действует по аналогии с LEFT
RIGHT OUTER JOIN
Правостороннее внешнее соединение действует по аналогии с LEFT

FULL OUTER JOIN
Полное внешнее соединение FULL OUTER JOIN производит выборку множества
FULL OUTER JOIN
Полное внешнее соединение FULL OUTER JOIN производит выборку множества

CROSS JOIN
Также существует выборка перекрестного соединения (называемое ещё декартовым произведением), -
CROSS JOIN
Также существует выборка перекрестного соединения (называемое ещё декартовым произведением), -

Работа со множествами
Прежде чем начать описание функций и их свойств
Прежде чем начать описание функций и их свойств

Объединение. UNION
Объединением двух множеств A и B называется множество, содержащее в
Объединение. UNION
Объединением двух множеств A и B называется множество, содержащее в
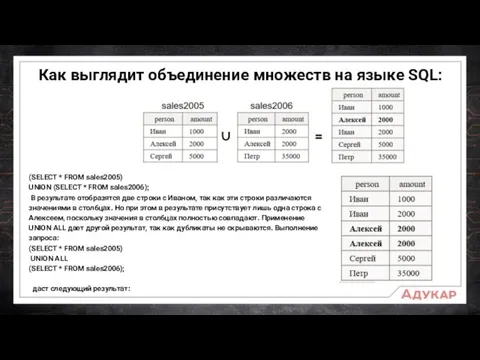
Как выглядит объединение множеств на языке SQL:
(SELECT * FROM sales2005)
UNION
Как выглядит объединение множеств на языке SQL:
(SELECT * FROM sales2005)
UNION

Разность. MINUS или EXCEPT
Разность двух множеств — это операция, результатом которой
Разность. MINUS или EXCEPT
Разность двух множеств — это операция, результатом которой

Как выглядит разность множеств на языке SQL (версия для СУБД MS
Как выглядит разность множеств на языке SQL (версия для СУБД MS

Агрегаты
Очень часто в языке SQL ставятся задачи выделения по набору данных
Агрегаты
Очень часто в языке SQL ставятся задачи выделения по набору данных

Агрегаты
Список функций, который входит в стандарт SQL:
COUNT – функция возвращает
Агрегаты
Список функций, который входит в стандарт SQL:
COUNT – функция возвращает

Группировка
Выражение GROUP BY используется для определения групп выходных строк, к которым
Группировка
Выражение GROUP BY используется для определения групп выходных строк, к которым

Группировка
Следует иметь в виду, что для GROUP BY все значения NULL
Группировка
Следует иметь в виду, что для GROUP BY все значения NULL

Функция COUNT(*)
Функция COUNT(*) возвращает количество элементов в группе. Сюда входят NULL
Функция COUNT(*)
Функция COUNT(*) возвращает количество элементов в группе. Сюда входят NULL

Функция COUNT(*)
Функция COUNT(DISTINCT имя_поля) оценивает значения в поле для каждой строки
Функция COUNT(*)
Функция COUNT(DISTINCT имя_поля) оценивает значения в поле для каждой строки

SUM
Возвращает сумму всех, либо только уникальных (при наличии DISTINCT), значений в
SUM
Возвращает сумму всех, либо только уникальных (при наличии DISTINCT), значений в

AVG
Возвращает среднее арифметическое группы значений. Пустые множества NULL пропускаются. Функция AVG()
AVG
Возвращает среднее арифметическое группы значений. Пустые множества NULL пропускаются. Функция AVG()

MAX() – возвращает максимальное значение выражения.
MIN() – возвращает минимальное значение
MAX() – возвращает максимальное значение выражения.
MIN() – возвращает минимальное значение

Важный момент: большой плюс агрегатов состоит в том, что, в рамках
Важный момент: большой плюс агрегатов состоит в том, что, в рамках

HAVING — необязательный (опциональный) параметр оператора SELECT для указания условия на
HAVING — необязательный (опциональный) параметр оператора SELECT для указания условия на

Исходя из изученных нами положений, выведем общий синтаксис запроса:
SELECT [DISTINCT]
Исходя из изученных нами положений, выведем общий синтаксис запроса:
SELECT [DISTINCT]

Что изучили сегодня
Связывание сущностей 1:1 и 1: многим
Обеспечение целостности
Для чего используем
Что изучили сегодня
Связывание сущностей 1:1 и 1: многим
Обеспечение целостности
Для чего используем
 Обработка символьной информации в TurboPascal (задачи, часть 3)
Обработка символьной информации в TurboPascal (задачи, часть 3) HTML. Создание Веб-страниц
HTML. Создание Веб-страниц Знакомство с с Unity2D. Занятие 1
Знакомство с с Unity2D. Занятие 1 Архитектура персонального компьютера
Архитектура персонального компьютера Программный комплекс для гидравлических расчетов. Возможности HydroSys
Программный комплекс для гидравлических расчетов. Возможности HydroSys Основы алгоритмизации
Основы алгоритмизации Структура электронных таблиц
Структура электронных таблиц Химико-технологические системы как объекты моделирования
Химико-технологические системы как объекты моделирования Web-проектирование. Тема 2. Основы проектирования web-сайта
Web-проектирование. Тема 2. Основы проектирования web-сайта Программирование на Python. Урок 8. Создаем gameplay
Программирование на Python. Урок 8. Создаем gameplay Архитектура персонального компьютера
Архитектура персонального компьютера Ақпараттық жүйелер ұғымы. Ақпараттық жүйелердің құрылымы
Ақпараттық жүйелер ұғымы. Ақпараттық жүйелердің құрылымы Тезаурус Анти-спам. Антивирусная программа
Тезаурус Анти-спам. Антивирусная программа Шрифт. Гарнитура
Шрифт. Гарнитура Представление числовой информации с помощью систем счисления
Представление числовой информации с помощью систем счисления Информационные технологии в профессиональной деятельности. Тема 1. Лекция 1-2
Информационные технологии в профессиональной деятельности. Тема 1. Лекция 1-2 Проект по розробці універсального додатку АнтиМат
Проект по розробці універсального додатку АнтиМат Итоговый урок-игра по информатике во 2 классе
Итоговый урок-игра по информатике во 2 классе Інтернет мережа
Інтернет мережа Java basics. Unit testing frameworks. Junit and testNG
Java basics. Unit testing frameworks. Junit and testNG Введение в программирование (язык C, лекция 1)
Введение в программирование (язык C, лекция 1) Сущность программной инженерии. Программное обеспечение. Свойства ПО (лекция 1)
Сущность программной инженерии. Программное обеспечение. Свойства ПО (лекция 1) Основы языка SQL
Основы языка SQL Технология мультимедиа
Технология мультимедиа Тактирование приложений
Тактирование приложений Принципы построения компьютеров. Архитектура компьютера
Принципы построения компьютеров. Архитектура компьютера Virtual reality
Virtual reality Моя профессия - библиотекарь
Моя профессия - библиотекарь