- Big Data. Революция в области хранения и обработки данных

Содержание
- 2. Что же такое BIG DATA? Big Data — это наборы данных такого объема, что традиционные инструменты
- 3. 3 Volume Variety Velocity Volume Реально большие объемы данных в физическом смысле Variety Слабо структурированные и
- 4. 4 Интернет и мобильные технологии Twitter 175 млн твит сообщений в день Facebook 300 млн фото
- 5. 5 Основные технологии анализа в BigData MapReduce - это фреймворк для вычисления некоторых наборов распределенных задач
- 6. 6 Методы анализа используемые в BigData Уникальность подхода больших данных заключается в агрегировании огромного объема неструктурированной
- 7. Производительность при обработке больших объемов данных можно повысить различными способами: Оборудование: многопроцессорные системы, ОЗУ большой емкости,
- 8. Комбинирование моделей Пропуская через «сито» моделей можно отсеивать информацию, для анализа которой бесполезны сложные алгоритмы. Для
- 9. Очень часто оптимальной стратегией анализа является не разработка одной сложной модели, а построение нескольких моделей на
- 10. Для обработки больших объемов данных нет необходимости перерабатывать всю информацию. Модели можно строить на относительно небольших
- 11. 11 Самые продвинутые отрасли BigData 01 03 Маркетинг Сегментация рынка Моделирование приобретения и оттока клиентов Рекомендательные
- 13. Скачать презентацию

Что же такое BIG DATA?
Big Data — это наборы данных такого
Что же такое BIG DATA?
Big Data — это наборы данных такого
3
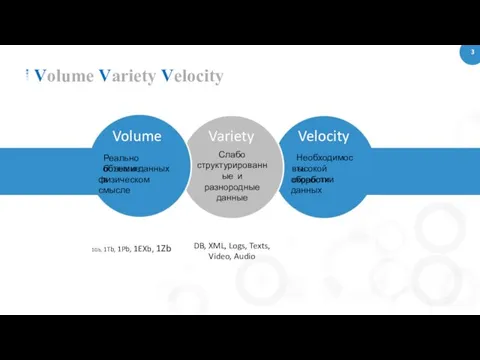
Volume Variety Velocity
Volume
Реально большие
объемы данных в
физическом смысле
Variety
Слабо
структурированные и разнородные данные
Velocity
Необходимость
высокой скорости
обработки
3
Volume Variety Velocity
Volume
Реально большие
объемы данных в
физическом смысле
Variety
Слабо
структурированные и разнородные данные
Velocity
Необходимость
высокой скорости
обработки

4
Интернет и мобильные технологии
Twitter 175 млн твит сообщений в день
Facebook 300 млн
4
Интернет и мобильные технологии
Twitter 175 млн твит сообщений в день
Facebook 300 млн

5
Основные технологии анализа в BigData
MapReduce - это фреймворк для вычисления некоторых
5
Основные технологии анализа в BigData
MapReduce - это фреймворк для вычисления некоторых

6
Методы анализа используемые в BigData
Уникальность подхода больших данных заключается в агрегировании
6
Методы анализа используемые в BigData
Уникальность подхода больших данных заключается в агрегировании

Производительность при обработке больших объемов данных можно повысить различными способами:
Оборудование:
Производительность при обработке больших объемов данных можно повысить различными способами:
Оборудование:
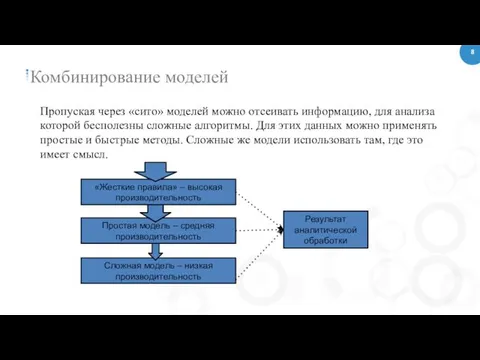
Комбинирование моделей
Пропуская через «сито» моделей можно отсеивать информацию, для анализа которой
Комбинирование моделей
Пропуская через «сито» моделей можно отсеивать информацию, для анализа которой
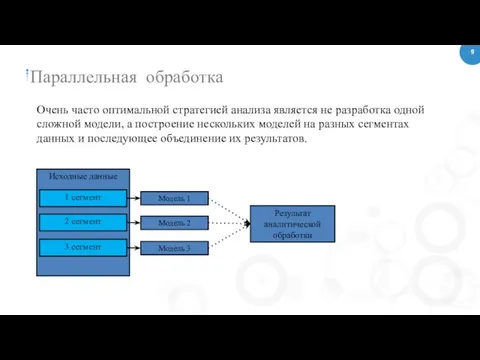
Очень часто оптимальной стратегией анализа является не разработка одной сложной модели,
Очень часто оптимальной стратегией анализа является не разработка одной сложной модели,

Для обработки больших объемов данных нет необходимости перерабатывать всю информацию. Модели
Для обработки больших объемов данных нет необходимости перерабатывать всю информацию. Модели

11
Самые продвинутые отрасли BigData
01
03
Маркетинг
Сегментация рынка
Моделирование
приобретения и оттока клиентов
Рекомендательные системы
Анализ соц.медиа
Финансы
Медицина
02
Детектирование аномального
11
Самые продвинутые отрасли BigData
01
03
Маркетинг
Сегментация рынка
Моделирование
приобретения и оттока клиентов
Рекомендательные системы
Анализ соц.медиа
Финансы
Медицина
02
Детектирование аномального
 Формирование информационных ресурсов в бизнес-аналитике
Формирование информационных ресурсов в бизнес-аналитике Salome & Code_Aster достойная замена платным пакетам МКЭ
Salome & Code_Aster достойная замена платным пакетам МКЭ Основы языка HTML
Основы языка HTML Бизнес в Instagram
Бизнес в Instagram Метод интервью в социологических исследованиях
Метод интервью в социологических исследованиях Презентация к уроку Файлы и файловая система
Презентация к уроку Файлы и файловая система IDP for Machine Learning
IDP for Machine Learning Автоматизация обучения, оценки и развития персонала. Программные продукты и решения компании WebSoft
Автоматизация обучения, оценки и развития персонала. Программные продукты и решения компании WebSoft Программируемые логические контроллеры Simatic. Инженерная среда Simatic TIA-portal. Step-7 V12 Pro
Программируемые логические контроллеры Simatic. Инженерная среда Simatic TIA-portal. Step-7 V12 Pro Подходы к понятию информации и измерение информации
Подходы к понятию информации и измерение информации Мультимедиа
Мультимедиа Путешествие в страну Информатика. 5 класс
Путешествие в страну Информатика. 5 класс Java. Разработка графического интерфейса
Java. Разработка графического интерфейса Поиск информации в интернете
Поиск информации в интернете Решение логических задач
Решение логических задач Fullstack разработка. Использование блочной верстки. Лекция 4
Fullstack разработка. Использование блочной верстки. Лекция 4 Графические редакторы
Графические редакторы Ашманов Игорь Станиславович
Ашманов Игорь Станиславович MATLAB ортасында матрицалармен жұмыс
MATLAB ортасында матрицалармен жұмыс Лексика языка Java
Лексика языка Java Ввод и редактирование документа. Ввод текста
Ввод и редактирование документа. Ввод текста Персональный компьютер
Персональный компьютер Проектирование систем автоматизации. Проектная компоновка УВК. (Модуль 5)
Проектирование систем автоматизации. Проектная компоновка УВК. (Модуль 5) Перевод целых чисел из десятичной системы счисления в любую другую систему счисления А10→Ах
Перевод целых чисел из десятичной системы счисления в любую другую систему счисления А10→Ах Создание сайта с помощью языка гипертекстовой разметки HTML ( самый крупный) до ( самый мелкий).Заголовок страницы целесообразно выделить самым крупным шрифтом: Моя страничка Выравнивание Принято, чтобы заголовок на странице находился по центру, для э
Создание сайта с помощью языка гипертекстовой разметки HTML ( самый крупный) до ( самый мелкий).Заголовок страницы целесообразно выделить самым крупным шрифтом: Моя страничка Выравнивание Принято, чтобы заголовок на странице находился по центру, для э Спеціалізовані мови програмування Python
Спеціалізовані мови програмування Python Программирование на языке Python. § 54. Введение в язык Python
Программирование на языке Python. § 54. Введение в язык Python Технология программировния. Файлы
Технология программировния. Файлы