- Булевий пошук. Лекція 1

Содержание
- 2. INFORMATION RETRIEVAL (IR) Інформаційний пошук – що це таке? Інформаційний пошук (IR) – це процес пошуку
- 3. INFORMATION RETRIEVAL (IR) Додаткові задачі IR : навігація по колекції документів фільтрація документів кластеризація класифікація
- 4. INFORMATION RETRIEVAL (IR) Класифікація систем інформаційного пошуку за масштабом: WEB – пошук Системи корпоративного, відомчого і
- 5. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Як приклад візьмемо зібрання творів Шекспіра. Припустимо, ми хочемо визначити в якому творі
- 6. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Самий простий спосіб – «в лоб», послідовний перегляд всіх документів (linear scanning) Часто
- 7. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Але дуже часто необхідно дещо більше: Інколи необхідно швидко обробити велику колекцію документів
- 8. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Для того, що б уникнути послідовного перебору текстів при виконанні кожного запиту, необхідно
- 9. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ МАТРИЦЯ ІНЦИДЕНТНОСТІ «ТЕРМІН-ДОКУМЕНТ»
- 10. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Для обробки запиту «Brutus AND Caesar AND NOT Calpurnia» ми беремо вектор для
- 11. МОДЕЛЬ БУЛЕВОГО ПОШУКУ Модель булевого пошуку – це модель інформаційного пошуку, в ході якої можна оброблювати
- 12. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Розглянемо більш реальний приклад. Ми маємо N=1 мільйон документів. Документ – будь, який
- 13. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Наша мета – розробити систему, що виконує пошук за довільним запитом (ad hoc
- 14. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Тепер ми вже не можемо скласти матрицю «термін-документ» наївним чином. Матриця розміром 500К
- 15. ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ Ця ідея є основною по відношенню до першої важливої концепції інформаційного пошуку –
- 16. ІНВЕРТОВАНИЙ ІНДЕКС (ІНВЕРТОВАНИЙ ФАЙЛ) Основна ідея: Спочатку ми записуємо в пам’ять словник термінів (vocabulary або lexicon).
- 17. ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС Для того, що б отримати виграш в швидкості необхідно побудувати інвертований
- 18. ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС Уявимо, що перших три етапи виконані. Розглянемо процес створення інвертованого індексу
- 19. ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС Вихідною інформацією для індексування є список нормалізованих лексем для кожного документу,
- 21. ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС Така структура інвертованого індексу майже не має конкурентів, оскільки є найбільш
- 22. ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС В результаті ми «платимо» за зберігання словника і списків словопозицій. Списки
- 23. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Як відбувається обробка запитів за допомогою інвертованого індексу і базової моделі булевого пошуку?
- 24. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Ця обробка зводиться до наступного. 1. Виявляємо термін Brutus в словнику. 2. Знаходимо
- 25. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Операція перетину (intersection) є надзвичайно важливою. Існує простий і ефективний метод перетину списку
- 26. ОБРОБКА БУЛЕВИХ ЗАПИТІВ
- 27. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Цей підхід можна узагальнити для обробки і більш складних запитів (Brutus OR Caesar)
- 28. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Оптимізація запиту - це вибір такого способу організації обробки запиту, щоб можна було
- 29. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Розглянемо запит, що складається з t термінів, об'єднаних операцією AND. Наприклад: Brutus AND
- 30. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Розглянемо тепер оптимізацію запитів більш загального вигляду. (Madding AND crowd) AND (ignoble OR
- 31. ОБРОБКА БУЛЕВИХ ЗАПИТІВ Однак у багатьох простих ситуаціях запити є виключно кон'юнкція термінів. Це пояснюється або
- 32. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Альтернативою моделі булевого пошуку є моделі пошуку з ранжируванням
- 33. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Незважаючи на десятиліття академічних досліджень переваг ранжованого пошуку, системи,
- 34. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Суворі логічні вирази з термінами з неупорядкованими результатами накладають
- 35. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Приклад Комерційна служба булевого пошуку: Westlaw. Westlaw (http://www.westlaw.com/) -
- 36. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Розглянемо кілька прикладів булевих запитів в системі Westlaw. Інформаційні
- 37. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Зверніть увагу на довгий і точний запит і використання
- 38. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Багато користувачів, особливо професіонали, надають перевагу булевому пошуку. Такі
- 39. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Ми розглянули структуру і процес створення базового інвертованого індексу,
- 40. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ Перерахуємо наші побажання: 1. Ми хотіли б краще визначати
- 41. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ 2. Часто хотілося б мати можливість знаходити складені слова
- 42. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ 3. Модель булевого пошуку дозволяє лише визначити наявність або
- 43. ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ 4. У відповідь на булеві запити просто повертається (невпорядкована)
- 45. Скачать презентацию

INFORMATION RETRIEVAL (IR)
Інформаційний пошук – що це таке?
Інформаційний пошук (IR) –
INFORMATION RETRIEVAL (IR)
Інформаційний пошук – що це таке?
Інформаційний пошук (IR) –

INFORMATION RETRIEVAL (IR)
Додаткові задачі IR :
навігація по колекції документів
фільтрація документів
кластеризація
класифікація
INFORMATION RETRIEVAL (IR)
Додаткові задачі IR :
навігація по колекції документів
фільтрація документів
кластеризація
класифікація

INFORMATION RETRIEVAL (IR)
Класифікація систем інформаційного пошуку за масштабом:
WEB – пошук
Системи корпоративного,
INFORMATION RETRIEVAL (IR)
Класифікація систем інформаційного пошуку за масштабом:
WEB – пошук
Системи корпоративного,

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Як приклад візьмемо зібрання творів Шекспіра.
Припустимо, ми хочемо визначити
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Як приклад візьмемо зібрання творів Шекспіра.
Припустимо, ми хочемо визначити

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Самий простий спосіб – «в лоб», послідовний перегляд всіх
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Самий простий спосіб – «в лоб», послідовний перегляд всіх

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Але дуже часто необхідно дещо більше:
Інколи необхідно швидко обробити
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Але дуже часто необхідно дещо більше:
Інколи необхідно швидко обробити

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Для того, що б уникнути послідовного перебору текстів при
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Для того, що б уникнути послідовного перебору текстів при
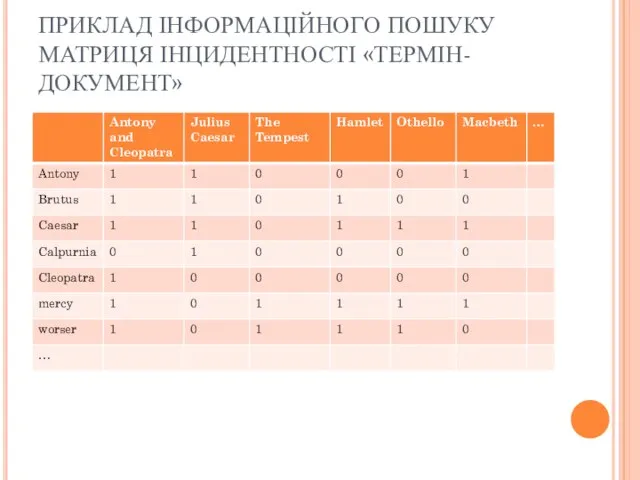
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
МАТРИЦЯ ІНЦИДЕНТНОСТІ «ТЕРМІН-ДОКУМЕНТ»
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
МАТРИЦЯ ІНЦИДЕНТНОСТІ «ТЕРМІН-ДОКУМЕНТ»

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Для обробки запиту «Brutus AND Caesar AND NOT Calpurnia»
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Для обробки запиту «Brutus AND Caesar AND NOT Calpurnia»

МОДЕЛЬ БУЛЕВОГО ПОШУКУ
Модель булевого пошуку – це модель інформаційного пошуку, в
МОДЕЛЬ БУЛЕВОГО ПОШУКУ
Модель булевого пошуку – це модель інформаційного пошуку, в

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Розглянемо більш реальний приклад.
Ми маємо N=1 мільйон документів.
Документ –
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Розглянемо більш реальний приклад.
Ми маємо N=1 мільйон документів.
Документ –

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Наша мета – розробити систему, що виконує пошук за
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Наша мета – розробити систему, що виконує пошук за

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Тепер ми вже не можемо скласти матрицю «термін-документ» наївним
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Тепер ми вже не можемо скласти матрицю «термін-документ» наївним

ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Ця ідея є основною по відношенню до першої важливої
ПРИКЛАД ІНФОРМАЦІЙНОГО ПОШУКУ
Ця ідея є основною по відношенню до першої важливої

ІНВЕРТОВАНИЙ ІНДЕКС (ІНВЕРТОВАНИЙ ФАЙЛ)
Основна ідея:
Спочатку ми записуємо в пам’ять словник термінів
ІНВЕРТОВАНИЙ ІНДЕКС (ІНВЕРТОВАНИЙ ФАЙЛ)
Основна ідея:
Спочатку ми записуємо в пам’ять словник термінів

ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Для того, що б отримати виграш в
ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Для того, що б отримати виграш в

ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Уявимо, що перших три етапи виконані.
Розглянемо процес
ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Уявимо, що перших три етапи виконані.
Розглянемо процес

ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Вихідною інформацією для індексування є список нормалізованих
ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Вихідною інформацією для індексування є список нормалізованих
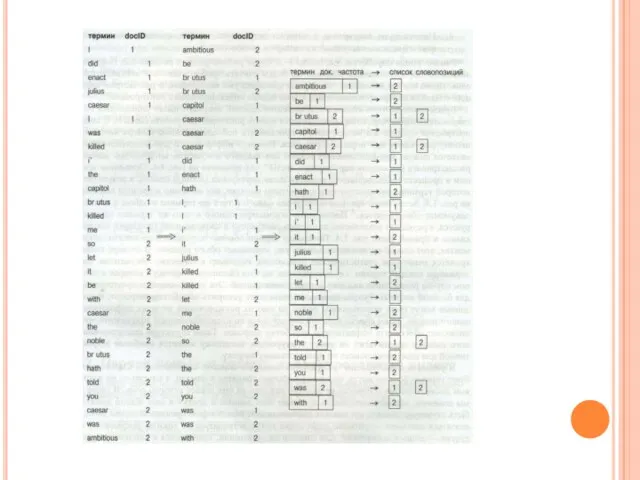

ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Така структура інвертованого індексу майже не має
ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
Така структура інвертованого індексу майже не має

ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
В результаті ми «платимо» за зберігання словника
ПЕРША СПРОБА СТВОРИТИ ІНВЕРТОВАНИЙ ІНДЕКС
В результаті ми «платимо» за зберігання словника

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Як відбувається обробка запитів за допомогою інвертованого індексу і
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Як відбувається обробка запитів за допомогою інвертованого індексу і

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Ця обробка зводиться до наступного.
1. Виявляємо термін Brutus в
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Ця обробка зводиться до наступного.
1. Виявляємо термін Brutus в

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Операція перетину (intersection) є надзвичайно важливою.
Існує простий і ефективний
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Операція перетину (intersection) є надзвичайно важливою.
Існує простий і ефективний

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
ОБРОБКА БУЛЕВИХ ЗАПИТІВ

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Цей підхід можна узагальнити для обробки і більш складних
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Цей підхід можна узагальнити для обробки і більш складних

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Оптимізація запиту - це вибір такого способу організації обробки
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Оптимізація запиту - це вибір такого способу організації обробки

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Розглянемо запит, що складається з t термінів, об'єднаних операцією
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Розглянемо запит, що складається з t термінів, об'єднаних операцією

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Розглянемо тепер оптимізацію запитів більш загального вигляду.
(Madding AND crowd)
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Розглянемо тепер оптимізацію запитів більш загального вигляду.
(Madding AND crowd)

ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Однак у багатьох простих ситуаціях запити є виключно кон'юнкція
ОБРОБКА БУЛЕВИХ ЗАПИТІВ
Однак у багатьох простих ситуаціях запити є виключно кон'юнкція

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Альтернативою моделі булевого пошуку є
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Альтернативою моделі булевого пошуку є

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Незважаючи на десятиліття академічних досліджень
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Незважаючи на десятиліття академічних досліджень

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Суворі логічні вирази з термінами
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Суворі логічні вирази з термінами

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Приклад Комерційна служба булевого пошуку:
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Приклад Комерційна служба булевого пошуку:

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Розглянемо кілька прикладів булевих запитів
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Розглянемо кілька прикладів булевих запитів

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Зверніть увагу на довгий і
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Зверніть увагу на довгий і

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Багато користувачів, особливо професіонали, надають
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Багато користувачів, особливо професіонали, надають

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Ми розглянули структуру і процес
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Ми розглянули структуру і процес

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Перерахуємо наші побажання:
1. Ми хотіли
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
Перерахуємо наші побажання:
1. Ми хотіли

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
2. Часто хотілося б мати
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
2. Часто хотілося б мати

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
3. Модель булевого пошуку дозволяє
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
3. Модель булевого пошуку дозволяє

ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
4. У відповідь на булеві
ПОРІВНЯННЯ РОЗШИРЕНОЇ БУЛЕВОЇ МОДЕЛІ І РАНЖОВАНОГО ПОШУКУ
4. У відповідь на булеві
 История создания электронной почты
История создания электронной почты Алгоритмы с ветвлениями, 6 класс
Алгоритмы с ветвлениями, 6 класс Создание базы данных в Microsoft Access 2007 с помощью шаблонов и конструктора таблиц
Создание базы данных в Microsoft Access 2007 с помощью шаблонов и конструктора таблиц Кодирование звука и видео
Кодирование звука и видео Проект Создание ЭОР учителю с помощью некоторых сервисов
Проект Создание ЭОР учителю с помощью некоторых сервисов Презентация к уроку Носители информации (3 класс)
Презентация к уроку Носители информации (3 класс) Внедрение системы управления бизнес-процессами на предприятии
Внедрение системы управления бизнес-процессами на предприятии Введение в информатику: понятие об информации и информационных процессах. Информатика как наука
Введение в информатику: понятие об информации и информационных процессах. Информатика как наука Моя безопасность в информационном веке (классный час)
Моя безопасность в информационном веке (классный час) Основы работы в Adobe Photoshop
Основы работы в Adobe Photoshop Functions of Computers
Functions of Computers Представление об организации баз данных и системах управления базами данных
Представление об организации баз данных и системах управления базами данных Виртуальные экскурсии: технологии создания
Виртуальные экскурсии: технологии создания Сеть и облачные технологии
Сеть и облачные технологии Сайт о компьютерной игре. Посадочная и регистрационная страницы
Сайт о компьютерной игре. Посадочная и регистрационная страницы Сети обмена данными
Сети обмена данными Інструменти пошуку в Інтернеті
Інструменти пошуку в Інтернеті Моделирование, как метод познания. Типы информационных моделей
Моделирование, как метод познания. Типы информационных моделей Возможности использования Intel Perceptual Computing SDK в игровых приложениях (Лекция 6)
Возможности использования Intel Perceptual Computing SDK в игровых приложениях (Лекция 6) Практика в ООО Норд Хаус
Практика в ООО Норд Хаус Презентация Понятие алгоритма. Исполнители алгоритма. Свойства алгоритма.
Презентация Понятие алгоритма. Исполнители алгоритма. Свойства алгоритма. Формы мышления. Логика
Формы мышления. Логика Обзор веб-ресурсов по веб-дизайну и веб-разработке
Обзор веб-ресурсов по веб-дизайну и веб-разработке ЕАС ОПС Реализация лотерейных билетов и выплата выигрышей
ЕАС ОПС Реализация лотерейных билетов и выплата выигрышей Стандарты разработки и документирования программных средств
Стандарты разработки и документирования программных средств Алгоритм создания рабочей программы
Алгоритм создания рабочей программы Системи управління базами даних Access
Системи управління базами даних Access Теория автоматического управления
Теория автоматического управления