- Data Mining - интеллектуальный анализ данных

Содержание
- 2. Что такое Data Mining? В литературе переводится по-разному Добыча данных (калька) Интеллектуальный анализ данных (а бывает
- 3. Независимо от перевода смысл одинаков (в большинстве случаев): Это средство превратить данные в знания Мало прока
- 4. Почему мы сегодня говорим о технологии Data Mining? За последние два десятилетия реляционные БД на предприятиях
- 5. Data Mining переводится как "добыча" или "раскопка данных". Нередко рядом с Data Mining встречаются слова "обнаружение
- 6. Данные имеют неограниченный объем Данные являются разнородными (количественными, качественными, текстовыми) Результаты должны быть конкретны и понятны
- 10. Data Mining - это процесс выделения из данных неявной и неструктурированной информации и представления ее в
- 11. Три принципа в основе DM Иными словами, Data Mining – это анализ данных с целью отыскания
- 12. Задачи Data Mining
- 13. 1. Классификация (Classification) Наиболее простая и распространенная задача Data Mining. В результате решения задачи классификации обнаруживаются
- 14. 2. Кластеризация (Clustering) Кластеризация является логическим продолжением идеи классификации. Это задача более сложная, особенность кластеризации заключается
- 15. 3. Ассоциация (Associations) В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в
- 16. 4. Последовательность (Sequence), или последовательная ассоциация (sequential association) Последовательность позволяет найти временные закономерности между транзакциями. Задача
- 17. Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю. Эту задачу Data Mining также
- 18. 5.Прогнозирование (Forecasting) В результате решения задачи прогнозирования на основе особенностей исторических данных оцениваются пропущенные или же
- 19. 6. Определение отклонений или выбросов (Deviation Detection), анализ отклонений или выбросов Цель решения данной задачи -
- 20. 7. Оценивание (Estimation) Задача оценивания сводится к предсказанию непрерывных значений признака. 8. Анализ связей (Link Analysis)
- 21. Классификация задач Data Mining Согласно классификации по стратегиям, задачи Data Mining подразделяются на следующие группы: ·
- 22. Применение Data Mining для решения бизнес-задач. Основные направления: банковское дело, финансы, страхование, CRM, производство, телекоммуникации, электронная
- 23. Банковское дело Задача привлечения новых клиентов банка Другие задачи сегментации клиентов Задача управления ликвидностью банка Задача
- 24. Страхование Электронная коммерция
- 25. Основные задачи Data Mining в промышленном производстве : · комплексный системный анализ производственных ситуаций; · краткосрочный
- 26. Вот список задач фондового рынка, которые можно решать при помощи технологии Data Mining : · прогнозирование
- 27. Web Mining Web Mining можно перевести как "добыча данных в Web". Здесь можно выделить два основных
- 28. Web Content Mining В этом направлении, в свою очередь, выделяют два подхода: подход, основанный на агентах,
- 29. Подход, основанный на агентах (Agent Based Approach), включает такие системы: · интеллектуальные поисковые агенты (Intelligent Search
- 30. Примеры систем интеллектуальных агентов поиска: · Harvest (Brown и др., 1994), · FAQ-Finder (Hammond и др.,
- 31. Подход, основанный на базах данных (Database Approach), включает системы: · многоуровневые базы данных; · системы web-запросов
- 32. Примеры систем web-запросов: · W3QL (Konopnicki и Shmueli, 1995), · WebLog (Lakshmanan и др., 1996), ·
- 33. Второе направление Web Usage Mining подразумевает обнаружение закономерностей в действиях пользователя Web-узла или их группы. Анализируется
- 34. Анализируется также, какие группы пользователей можно выделить среди общего их числа на основе истории просмотра Web-узла.
- 35. Плюсы и минусы Web Usage Mining Плюсы Web Usage Mining имеет ряд преимуществ, что делает эту
- 36. Минусы Самый критикуемый этический вопрос, связанный с Web Usage Mining, является вопрос о вторжении в частную
- 37. Задачи Web Mining можно подразделить на такие категории: · Предварительная обработка данных для Web Mining. ·
- 38. Text Mining Text Mining охватывает новые методы для выполнения семантического анализа текстов, информационного поиска и управления.
- 39. Извлечение понятий Ответ на запросы Тематическое индексирование Поиск по ключевым словам
- 40. Call Mining Среди разработчиков новой технологии Call Mining ("добыча" и анализ звонков) - компании CallMiner, Nexidia,
- 44. 1. Свободный поиск (Discovery) На стадии свободного поиска осуществляется исследование набора данных с целью поиска скрытых
- 46. "Если возраст 700 условных единиц, то в 75% случаев соискатель ищет работу программиста" или "Если возраст
- 47. Описанные действия, в рамках стадии свободного поиска, выполняются при помощи : · индукции правил условной логики
- 48. 2. Прогностическое моделирование (Predictive Modeling)
- 49. Зная, что соискатель ищет руководящую работу и его стаж > 15 лет, на 65 % можно
- 50. 3. Анализ исключений (forensic analysis)
- 51. Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов
- 53. Статистические пакеты Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также
- 54. Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Большинство методов,
- 55. Пакеты прикладных программ "Статистические методы анализа» МЕЗОЗАВР - "Статистические методы анализа временных рядов" МЕЗОЗАВР-ЭКОНОМЕТРИКА САНИ -
- 57. Деревья решений (decision trees) Деревья решения являются одним из наиболее популярных подходов к решению задач Data
- 58. Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает зависимость этой переменной от независимых
- 60. Они создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО..." (if-then), имеющую вид дерева. Для принятия решения,
- 61. В рассмотренном примере решается задача бинарной классификации, т.е. создается дихотомическая классификационная модель. Пример демонстрирует работу так
- 63. Как мы видим, внутренние узлы дерева (возраст, наличие недвижимости, доход и образование) являются атрибутами описанной выше
- 64. Преимущества деревьев решений Интуитивность деревьев решений Точность моделей Быстрый процесс обучения.
- 65. Алгоритмы На сегодняшний день существует большое число алгоритмов, реализующих деревья решений: CART, C4.5, CHAID, CN2, NewId,
- 66. Алгоритм CART Алгоритм CART (Classification and Regression Tree), как видно из названия, решает задачи классификации и
- 67. Другие особенности алгоритма CART: функция оценки качества разбиения; механизм отсечения дерева; алгоритм обработки пропущенных значений; построение
- 68. Алгоритм C4.5 Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у узла. Данный алгоритм может
- 69. Для работы алгоритма C4.5 необходимо соблюдение следующих требований: Каждая запись набора данных должна быть ассоциирована с
- 70. Последняя версия алгоритма - алгоритм C4.8 - реализована в инструменте Weka как J4.8 (Java). Коммерческая реализация
- 71. Алгоритмы построения деревьев решений различаются следующими характеристиками: вид расщепления - бинарное (binary), множественное (multi-way) критерии расщепления
- 72. Большинство систем Data mining используют метод деревьев решений. Самыми известными являются: See5/С5.0 (RuleQuest, Австралия), Clementine (Integral
- 75. Метод опорных векторов Метод опорных векторов (Support Vector Machine - SVM) относится к группе граничных методов.
- 76. Метод опорных векторов Плоскость (plane) решения разделяет объекты с разной классовой принадлежностью.
- 77. Метод отыскивает образцы, находящиеся на границах между двумя классами, т.е. опорные вектора
- 78. Опорными векторами называются объекты множества, лежащие на границах областей. Классификация считается хорошей, если область между границами
- 79. Задачу можно сформулировать как поиск функции f(x), принимающей значения меньше нуля для векторов одного класса и
- 80. В результате решения задачи, т.е. построения SVM-модели, найдена функция, принимающая значения меньше нуля для векторов одного
- 81. Алгоритмы ограниченного перебора Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска
- 82. WizWhy Наиболее ярким современным представителем этого подхода является система WizWhy предприятия WizSoft. Хотя автор системы Абрахам
- 84. WizWhy обнаруживает и математические, и логические закономерности. Допустим, что вам известны погода, температура воздуха, настроение сослуживцев
- 85. WizWhy может стать незаменимым инструментом аналитика. Очевидны возможности ее применения в геологии, в медицинской диагностике, социальных
- 86. Прецедент - это описание ситуации в сочетании с подробным указанием действий, предпринимаемых в данной ситуации.
- 87. Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев Идея систем рассуждений по аналогии (Case
- 88. Подход, основанный на прецедентах, условно можно поделить на следующие этапы: сбор подробной информации о поставленной задаче;
- 89. Преимущества метода Простота использования полученных результатов. Решения не уникальны для конкретной ситуации, возможно их использование для
- 90. Недостатки метода "ближайшего соседа" Данный метод не создает каких-либо моделей или правил, обобщающих предыдущий опыт, -
- 91. Классификация объектов множества при разном значении параметра k
- 92. Байесовская сеть (или байесова сеть, байесовская сеть доверия, англ. Bayesian network, belief network) — графическая вероятностная
- 93. Предположим, что может быть две причины, по которым трава может стать мокрой (GRASS WET): сработала дождевальная
- 95. Модель может ответить на такие вопросы как «Какова вероятность того, что прошел дождь, если трава мокрая?»
- 96. Свойства наивной классификации: Использование всех переменных и определение всех зависимостей между ними. Наличие двух предположений относительно
- 97. Отмечают такие достоинства байесовских сетей как метода Data Mining в модели определяются зависимости между всеми переменными,
- 98. Наивно-байесовский подход имеет следующие недостатки: перемножать условные вероятности корректно только тогда, когда все входные переменные действительно
- 99. Нейронные сети Это большой класс систем, архитектура которых имеет аналогию с построением нервной ткани из нейронов.
- 100. Классификация нейронных сетей Одна из возможных классификаций нейронных сетей - по направленности связей. Нейронные сети бывают
- 101. 2. Сети с обратными связями Сети Хопфилда (задачи ассоциативной памяти). Сети Кохонена (задачи кластерного анализа). Особенностью
- 102. Другая классификация нейронных сетей: сети прямого распространения и рекуррентные сети. 1. Сети прямого распространения Персептроны. Сеть
- 103. 2. Рекуррентные сети. Характерная особенность таких сетей - наличие блоков динамической задержки и обратных связей, что
- 104. Нейронные сети могут обучаться с учителем или без него. При обучении с учителем для каждого обучающего
- 105. Выбор структуры нейронной сети Существуют принципы, которыми следует руководствоваться при разработке новой конфигурации: возможности сети возрастают
- 106. Карты Кохонена В результате работы алгоритма получаются следующие карты: карта входов нейронов — визуализирует внутреннюю структуру
- 107. Карты Кохонена Задачи, решаемые при помощи карт Кохонена Самоорганизующиеся карты могут использоваться для решения таких задач,
- 108. Разведочный анализ данных. Сеть Кохонена способна распознавать кластеры в данных, а также устанавливать близость классов. Таким
- 109. Обнаружение новых явлений. Сеть Кохонена распознает кластеры в обучающих данных и относит все данные к тем
- 110. Карты Кохонена Самоорганизующаяся карта состоит из компонентов, называемых узлами или нейронами. Их количество задаётся аналитиком. Каждый
- 112. Карты Кохонена Изначально известна размерность входных данных, по ней некоторым образом строится первоначальный вариант карты. В
- 117. В результате работы алгоритма получаются следующие карты: карта входов нейронов — визуализирует внутреннюю структуру входных данных
- 120. Методы кластерного анализа. Иерархические методы Задачи кластерного анализа можно объединить в следующие группы: Разработка типологии или
- 123. Методы кластерного анализа Методы кластерного анализа можно разделить на две группы: иерархические; неиерархические. Каждая из групп
- 124. Иерархические методы кластерного анализа Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или
- 125. Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA) Эти методы являются логической противоположностью агломеративным методам. В начале
- 128. Методы поиска ассоциативных правил Ассоциативное правило имеет вид: "Из события A следует событие B". В результате
- 129. Алгоритм AIS. Первый алгоритм поиска ассоциативных правил, называвшийся AIS (предложенный Agrawal, Imielinski and Swami) был разработан
- 130. Алгоритм SETM Создание этого алгоритма было мотивировано желанием использовать язык SQL для вычисления часто встречающихся наборов
- 131. Неудобство алгоритмов AIS и SETM - излишнее генерирование и подсчет слишком многих кандидатов, которые в результате
- 132. Формирование кандидатов (candidate generation) - этап, на котором алгоритм, сканируя базу данных, создает множество i-элементных кандидатов
- 134. В зависимости от размера самого длинного часто встречающегося набора алгоритм Apriori сканирует базу данных определенное количество
- 135. AprioriHybrid Анализ времени работы алгоритмов Apriori и AprioriTid показывает, что в более ранних проходах Apriori добивается
- 136. Один из них - алгоритм DHP, также называемый алгоритмом хеширования (J. Park, M. Chen and P.
- 137. Системы для визуализации многомерных данных К способам визуального или графического представления данных относят графики, диаграммы, таблицы,
- 138. Традиционные методы визуализации могут находить следующее применение: представлять пользователю информацию в наглядном виде; компактно описывать закономерности,
- 139. Методы визуализации Методы визуализации, в зависимости от количества используемых измерений, принято классифицировать на две группы: представление
- 140. В соответствии с количеством измерений представления это могут быть следующие способы: одномерное (univariate) измерение, или 1-D
- 141. При использовании двух- и трехмерного представления информации пользователь имеет возможность увидеть закономерности набора данных: его кластерную
- 142. Представление данных в 4 х измерениях Представления информации в четырехмерном и более измерениях недоступны для человеческого
- 146. Основные принципы компоновки визуальных средств представления информации: Принцип лаконичности. Принцип обобщения и унификации. Принцип акцента на
- 149. Скачать презентацию

Что такое Data Mining?
В литературе переводится по-разному
Добыча данных (калька)
Интеллектуальный анализ данных
Что такое Data Mining?
В литературе переводится по-разному
Добыча данных (калька)
Интеллектуальный анализ данных

Независимо от перевода смысл одинаков (в большинстве случаев):
Это средство превратить данные
Независимо от перевода смысл одинаков (в большинстве случаев):
Это средство превратить данные

Почему мы сегодня говорим о технологии Data Mining?
За последние два десятилетия
Почему мы сегодня говорим о технологии Data Mining?
За последние два десятилетия

Data Mining переводится как "добыча" или "раскопка данных". Нередко рядом с
Data Mining переводится как "добыча" или "раскопка данных". Нередко рядом с

Данные имеют неограниченный объем
Данные являются разнородными (количественными,
качественными, текстовыми)
Результаты
Данные имеют неограниченный объем
Данные являются разнородными (количественными,
качественными, текстовыми)
Результаты
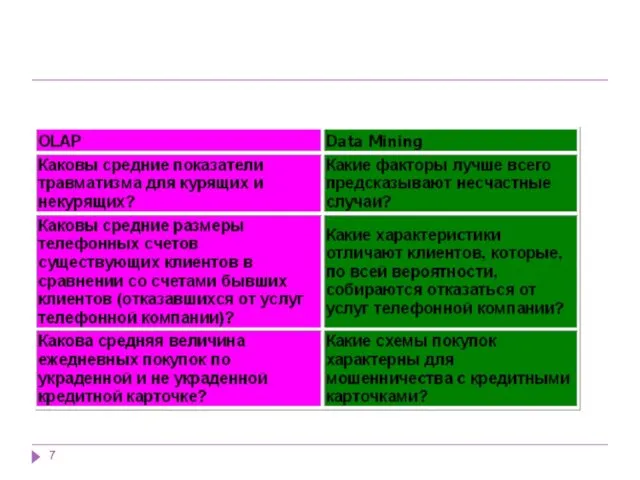
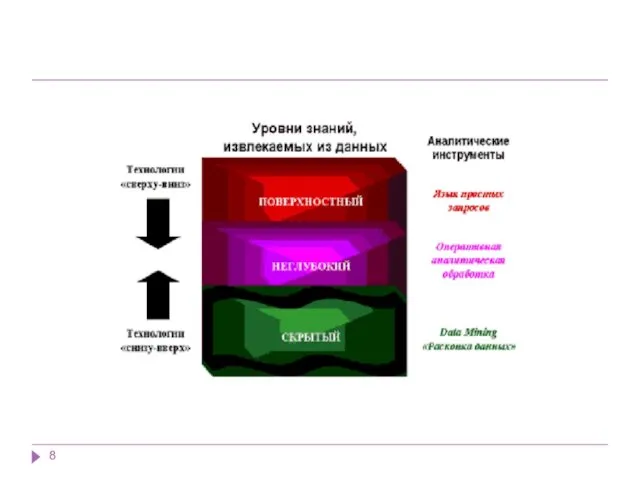


Data Mining - это процесс выделения из данных неявной и неструктурированной
Data Mining - это процесс выделения из данных неявной и неструктурированной

Три принципа в основе DM
Иными словами, Data Mining – это анализ
Три принципа в основе DM
Иными словами, Data Mining – это анализ

Задачи Data Mining
Задачи Data Mining

1. Классификация (Classification)
Наиболее простая и распространенная задача Data Mining.
В результате
1. Классификация (Classification)
Наиболее простая и распространенная задача Data Mining.
В результате

2. Кластеризация (Clustering)
Кластеризация является логическим продолжением идеи классификации.
Это задача более
2. Кластеризация (Clustering)
Кластеризация является логическим продолжением идеи классификации.
Это задача более

3. Ассоциация (Associations)
В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности
3. Ассоциация (Associations)
В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности

4. Последовательность (Sequence), или последовательная ассоциация (sequential association)
Последовательность позволяет найти временные
4. Последовательность (Sequence), или последовательная ассоциация (sequential association)
Последовательность позволяет найти временные

Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю.
Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю.

5.Прогнозирование (Forecasting)
В результате решения задачи прогнозирования на основе особенностей исторических данных
5.Прогнозирование (Forecasting)
В результате решения задачи прогнозирования на основе особенностей исторических данных

6. Определение отклонений или выбросов (Deviation Detection), анализ отклонений или
выбросов
Цель решения
6. Определение отклонений или выбросов (Deviation Detection), анализ отклонений или
выбросов
Цель решения

7. Оценивание (Estimation)
Задача оценивания сводится к предсказанию непрерывных значений признака.
8. Анализ
7. Оценивание (Estimation)
Задача оценивания сводится к предсказанию непрерывных значений признака.
8. Анализ

Классификация задач Data Mining
Согласно классификации по стратегиям, задачи Data Mining подразделяются
Классификация задач Data Mining
Согласно классификации по стратегиям, задачи Data Mining подразделяются

Применение Data Mining для решения бизнес-задач.
Основные направления: банковское дело,
Применение Data Mining для решения бизнес-задач.
Основные направления: банковское дело,

Банковское дело
Задача привлечения новых клиентов банка
Другие задачи сегментации клиентов
Задача управления ликвидностью
Банковское дело
Задача привлечения новых клиентов банка
Другие задачи сегментации клиентов
Задача управления ликвидностью

Страхование
Электронная коммерция
Страхование
Электронная коммерция

Основные задачи Data Mining в промышленном производстве :
· комплексный системный анализ
Основные задачи Data Mining в промышленном производстве :
· комплексный системный анализ

Вот список задач фондового рынка, которые можно решать при помощи технологии
Вот список задач фондового рынка, которые можно решать при помощи технологии

Web Mining
Web Mining можно перевести как "добыча данных в Web".
Здесь
Web Mining
Web Mining можно перевести как "добыча данных в Web".
Здесь

Web Content Mining
В этом направлении, в свою очередь, выделяют два подхода:
Web Content Mining
В этом направлении, в свою очередь, выделяют два подхода:

Подход, основанный на агентах (Agent Based Approach), включает такие системы:
· интеллектуальные
Подход, основанный на агентах (Agent Based Approach), включает такие системы:
· интеллектуальные

Примеры систем интеллектуальных агентов поиска:
· Harvest (Brown и др., 1994),
· FAQ-Finder
Примеры систем интеллектуальных агентов поиска:
· Harvest (Brown и др., 1994),
· FAQ-Finder

Подход, основанный на базах данных (Database Approach), включает системы:
· многоуровневые базы
Подход, основанный на базах данных (Database Approach), включает системы:
· многоуровневые базы

Примеры систем web-запросов:
· W3QL (Konopnicki и Shmueli, 1995),
· WebLog (Lakshmanan и
Примеры систем web-запросов:
· W3QL (Konopnicki и Shmueli, 1995),
· WebLog (Lakshmanan и

Второе направление Web Usage Mining подразумевает обнаружение закономерностей в действиях пользователя
Второе направление Web Usage Mining подразумевает обнаружение закономерностей в действиях пользователя

Анализируется также, какие группы пользователей можно выделить среди общего их числа
Анализируется также, какие группы пользователей можно выделить среди общего их числа

Плюсы и минусы Web Usage Mining
Плюсы
Web Usage Mining имеет ряд преимуществ,
Плюсы и минусы Web Usage Mining
Плюсы
Web Usage Mining имеет ряд преимуществ,

Минусы
Самый критикуемый этический вопрос, связанный с Web Usage Mining, является вопрос
Минусы
Самый критикуемый этический вопрос, связанный с Web Usage Mining, является вопрос

Задачи Web Mining можно подразделить на такие категории:
· Предварительная обработка данных
Задачи Web Mining можно подразделить на такие категории:
· Предварительная обработка данных

Text Mining
Text Mining охватывает новые методы для выполнения семантического анализа текстов,
Text Mining
Text Mining охватывает новые методы для выполнения семантического анализа текстов,

Извлечение понятий
Ответ на запросы
Тематическое индексирование
Поиск по ключевым словам
Извлечение понятий
Ответ на запросы
Тематическое индексирование
Поиск по ключевым словам

Call Mining
Среди разработчиков новой технологии Call Mining ("добыча" и анализ звонков)
Call Mining
Среди разработчиков новой технологии Call Mining ("добыча" и анализ звонков)




1. Свободный поиск (Discovery)
На стадии свободного поиска осуществляется исследование набора данных
1. Свободный поиск (Discovery)
На стадии свободного поиска осуществляется исследование набора данных


"Если возраст < 20 лет и желаемый уровень вознаграждения > 700
"Если возраст < 20 лет и желаемый уровень вознаграждения > 700

Описанные действия, в рамках стадии свободного поиска, выполняются при помощи :
·
Описанные действия, в рамках стадии свободного поиска, выполняются при помощи :
·

2. Прогностическое моделирование (Predictive Modeling)
2. Прогностическое моделирование (Predictive Modeling)

Зная, что соискатель ищет руководящую работу и его стаж > 15
Зная, что соискатель ищет руководящую работу и его стаж > 15

3. Анализ исключений (forensic analysis)
3. Анализ исключений (forensic analysis)

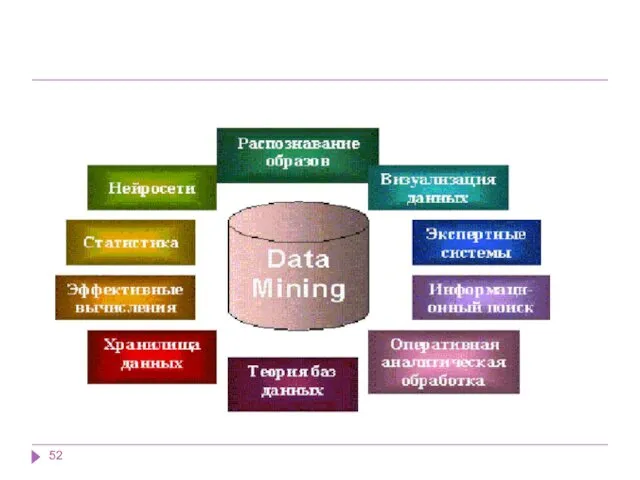
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений

Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с
Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с

Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение

Пакеты прикладных программ "Статистические методы анализа»
МЕЗОЗАВР - "Статистические методы анализа временных
Пакеты прикладных программ "Статистические методы анализа»
МЕЗОЗАВР - "Статистические методы анализа временных


Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов
Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов

Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает
Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает
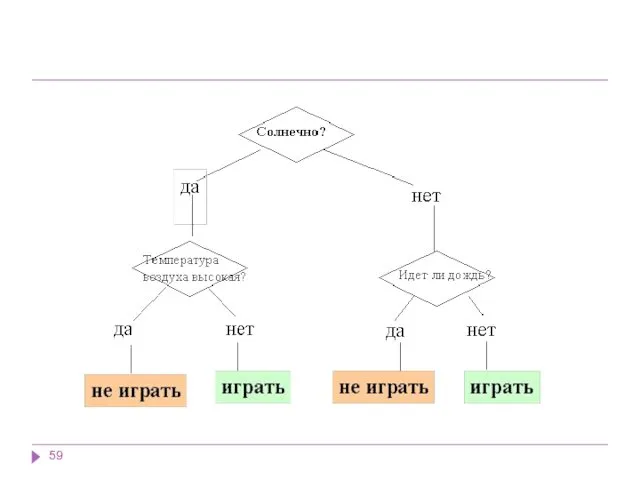

Они создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО..." (if-then), имеющую
Они создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО..." (if-then), имеющую

В рассмотренном примере решается задача бинарной классификации, т.е. создается дихотомическая классификационная
В рассмотренном примере решается задача бинарной классификации, т.е. создается дихотомическая классификационная
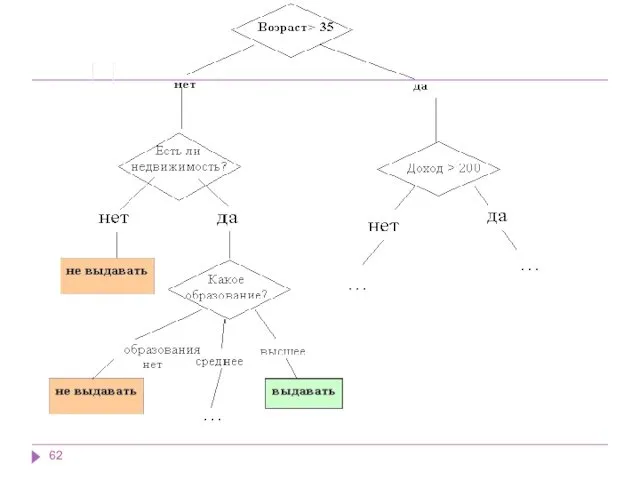

Как мы видим, внутренние узлы дерева (возраст, наличие недвижимости, доход и
Как мы видим, внутренние узлы дерева (возраст, наличие недвижимости, доход и

Преимущества деревьев решений
Интуитивность деревьев решений
Точность моделей
Быстрый процесс обучения.
Преимущества деревьев решений
Интуитивность деревьев решений
Точность моделей
Быстрый процесс обучения.

Алгоритмы
На сегодняшний день существует большое число алгоритмов, реализующих деревья решений:
CART,
Алгоритмы
На сегодняшний день существует большое число алгоритмов, реализующих деревья решений:
CART,

Алгоритм CART
Алгоритм CART (Classification and Regression Tree), как видно из названия,
Алгоритм CART
Алгоритм CART (Classification and Regression Tree), как видно из названия,

Другие особенности алгоритма CART:
функция оценки качества разбиения;
механизм отсечения дерева;
алгоритм обработки пропущенных
Другие особенности алгоритма CART:
функция оценки качества разбиения;
механизм отсечения дерева;
алгоритм обработки пропущенных

Алгоритм C4.5
Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у
Алгоритм C4.5
Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у

Для работы алгоритма C4.5 необходимо соблюдение следующих требований:
Каждая запись набора данных
Для работы алгоритма C4.5 необходимо соблюдение следующих требований:
Каждая запись набора данных

Последняя версия алгоритма - алгоритм C4.8 - реализована в инструменте Weka
Последняя версия алгоритма - алгоритм C4.8 - реализована в инструменте Weka

Алгоритмы построения деревьев решений различаются следующими характеристиками:
вид расщепления - бинарное (binary),
Алгоритмы построения деревьев решений различаются следующими характеристиками:
вид расщепления - бинарное (binary),

Большинство систем Data mining используют метод деревьев решений.
Самыми известными являются:
Большинство систем Data mining используют метод деревьев решений.
Самыми известными являются:


Метод опорных векторов
Метод опорных векторов (Support Vector Machine - SVM) относится
Метод опорных векторов
Метод опорных векторов (Support Vector Machine - SVM) относится

Метод опорных векторов
Плоскость (plane) решения разделяет объекты с разной классовой принадлежностью.
Метод опорных векторов
Плоскость (plane) решения разделяет объекты с разной классовой принадлежностью.
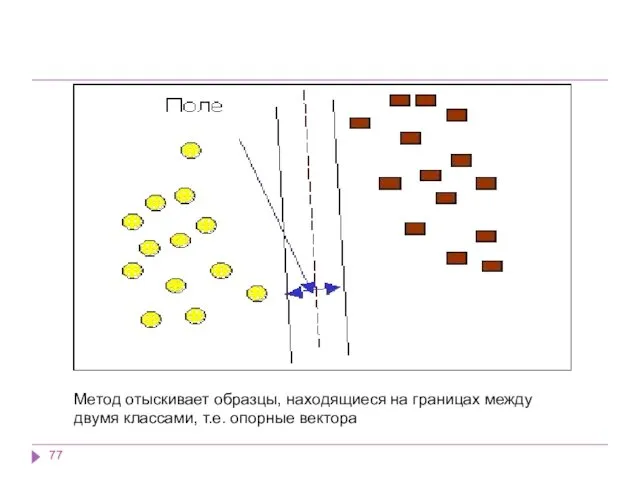
Метод отыскивает образцы, находящиеся на границах между двумя классами, т.е. опорные
Метод отыскивает образцы, находящиеся на границах между двумя классами, т.е. опорные
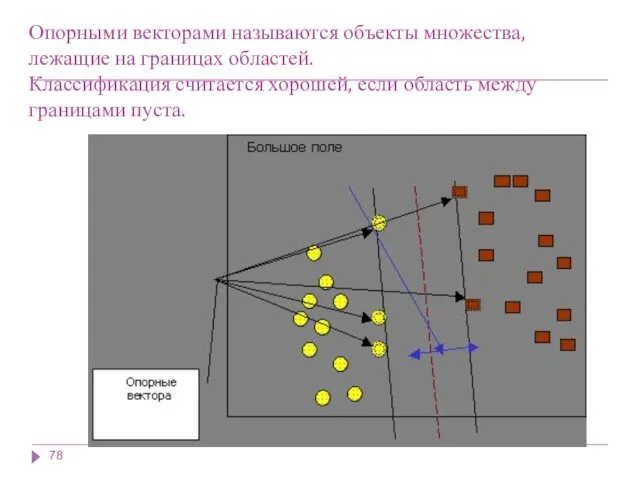
Опорными векторами называются объекты множества, лежащие на границах областей.
Классификация считается хорошей,
Опорными векторами называются объекты множества, лежащие на границах областей. Классификация считается хорошей,

Задачу можно сформулировать как поиск функции f(x), принимающей значения меньше нуля
Задачу можно сформулировать как поиск функции f(x), принимающей значения меньше нуля
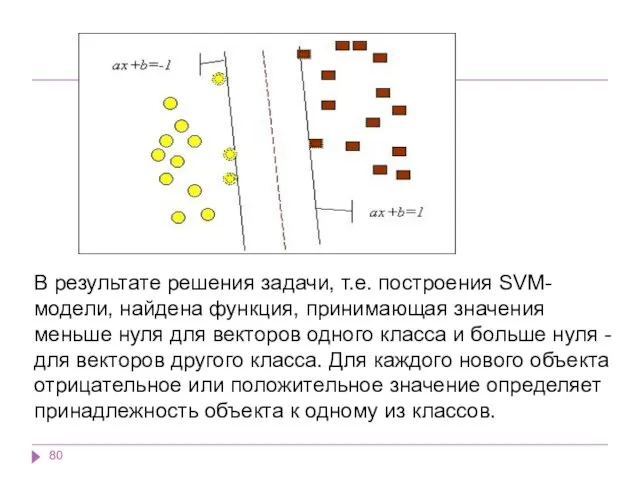
В результате решения задачи, т.е. построения SVM-модели, найдена функция, принимающая значения
В результате решения задачи, т.е. построения SVM-модели, найдена функция, принимающая значения

Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов
Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов

WizWhy
Наиболее ярким современным представителем этого подхода является система WizWhy предприятия WizSoft.
WizWhy
Наиболее ярким современным представителем этого подхода является система WizWhy предприятия WizSoft.

WizWhy обнаруживает и математические, и логические закономерности. Допустим, что вам известны
WizWhy обнаруживает и математические, и логические закономерности. Допустим, что вам известны

WizWhy может стать незаменимым инструментом аналитика. Очевидны возможности ее применения в
WizWhy может стать незаменимым инструментом аналитика. Очевидны возможности ее применения в

Прецедент - это описание ситуации в сочетании с подробным указанием действий,
Прецедент - это описание ситуации в сочетании с подробным указанием действий,

Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев
Идея систем
Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев
Идея систем

Подход, основанный на прецедентах, условно можно поделить на следующие этапы:
сбор подробной
Подход, основанный на прецедентах, условно можно поделить на следующие этапы:
сбор подробной

Преимущества метода
Простота использования полученных результатов.
Решения не уникальны для конкретной ситуации, возможно
Преимущества метода
Простота использования полученных результатов.
Решения не уникальны для конкретной ситуации, возможно

Недостатки метода "ближайшего соседа"
Данный метод не создает каких-либо моделей или правил,
Недостатки метода "ближайшего соседа"
Данный метод не создает каких-либо моделей или правил,
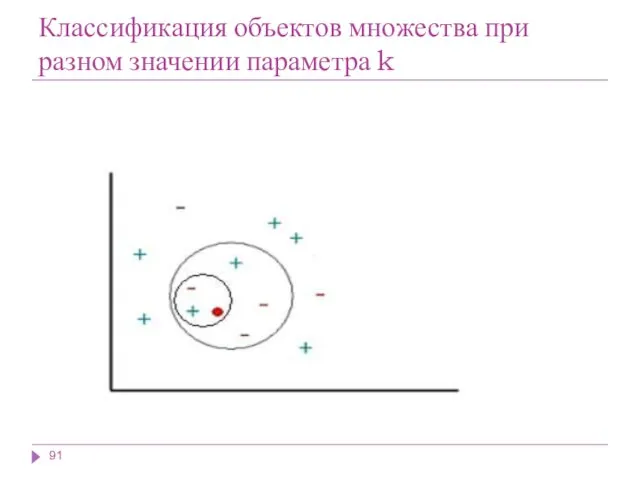
Классификация объектов множества при разном значении параметра k
Классификация объектов множества при разном значении параметра k

Байесовская сеть (или байесова сеть, байесовская сеть доверия, англ. Bayesian network, belief
Байесовская сеть (или байесова сеть, байесовская сеть доверия, англ. Bayesian network, belief

Предположим, что может быть две причины, по которым трава может стать
Предположим, что может быть две причины, по которым трава может стать
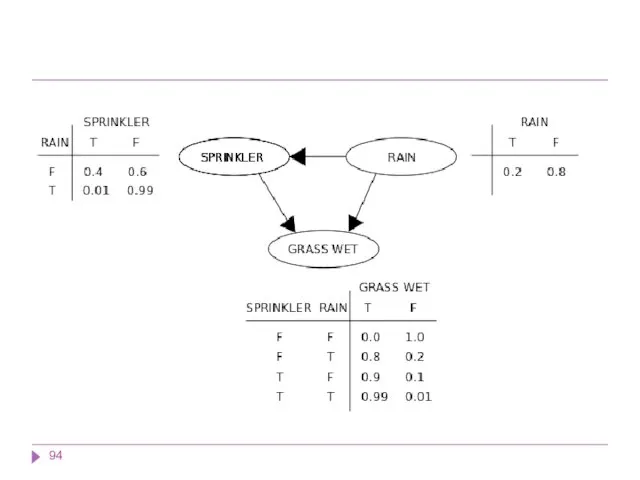

Модель может ответить на такие вопросы как «Какова вероятность того, что
Модель может ответить на такие вопросы как «Какова вероятность того, что

Свойства наивной классификации:
Использование всех переменных и определение всех зависимостей между ними.
Наличие
Свойства наивной классификации:
Использование всех переменных и определение всех зависимостей между ними.
Наличие

Отмечают такие достоинства байесовских сетей как метода Data Mining
в модели определяются
Отмечают такие достоинства байесовских сетей как метода Data Mining
в модели определяются

Наивно-байесовский подход имеет следующие недостатки:
перемножать условные вероятности корректно только тогда, когда
Наивно-байесовский подход имеет следующие недостатки:
перемножать условные вероятности корректно только тогда, когда

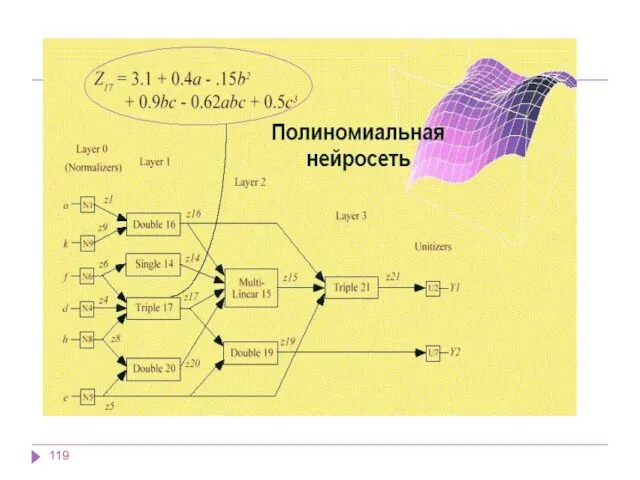
Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию с построением
Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию с построением

Классификация нейронных сетей
Одна из возможных классификаций нейронных сетей - по направленности
Классификация нейронных сетей
Одна из возможных классификаций нейронных сетей - по направленности

2. Сети с обратными связями
Сети Хопфилда (задачи ассоциативной памяти).
Сети Кохонена (задачи
2. Сети с обратными связями
Сети Хопфилда (задачи ассоциативной памяти).
Сети Кохонена (задачи

Другая классификация нейронных сетей: сети прямого распространения и рекуррентные сети.
1. Сети
Другая классификация нейронных сетей: сети прямого распространения и рекуррентные сети.
1. Сети

2. Рекуррентные сети.
Характерная особенность таких сетей - наличие блоков динамической
2. Рекуррентные сети.
Характерная особенность таких сетей - наличие блоков динамической

Нейронные сети могут обучаться с учителем или без него.
При обучении с
Нейронные сети могут обучаться с учителем или без него.
При обучении с

Выбор структуры нейронной сети
Существуют принципы, которыми следует руководствоваться при разработке новой
Выбор структуры нейронной сети
Существуют принципы, которыми следует руководствоваться при разработке новой

Карты Кохонена
В результате работы алгоритма получаются следующие карты:
карта входов нейронов — визуализирует
Карты Кохонена
В результате работы алгоритма получаются следующие карты: карта входов нейронов — визуализирует

Карты Кохонена
Задачи, решаемые при помощи карт Кохонена
Самоорганизующиеся карты могут использоваться для
Карты Кохонена
Задачи, решаемые при помощи карт Кохонена
Самоорганизующиеся карты могут использоваться для

Разведочный анализ данных.
Сеть Кохонена способна распознавать кластеры в данных, а также
Разведочный анализ данных.
Сеть Кохонена способна распознавать кластеры в данных, а также

Обнаружение новых явлений.
Сеть Кохонена распознает кластеры в обучающих данных и относит
Обнаружение новых явлений.
Сеть Кохонена распознает кластеры в обучающих данных и относит

Карты Кохонена
Самоорганизующаяся карта состоит из компонентов, называемых узлами или нейронами. Их
Карты Кохонена
Самоорганизующаяся карта состоит из компонентов, называемых узлами или нейронами. Их
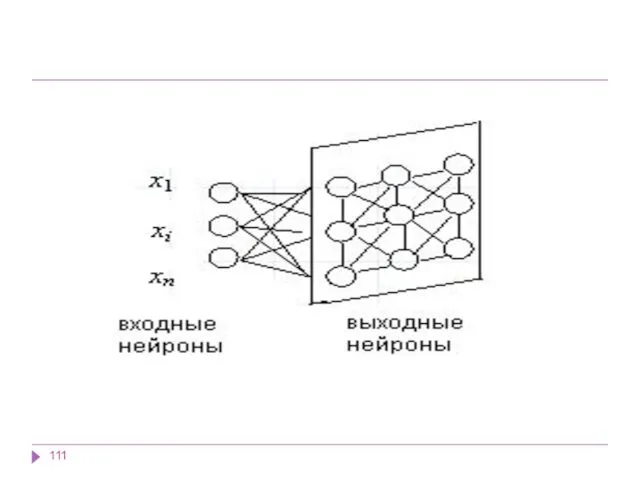

Карты Кохонена
Изначально известна размерность входных данных, по ней некоторым образом строится
Карты Кохонена
Изначально известна размерность входных данных, по ней некоторым образом строится
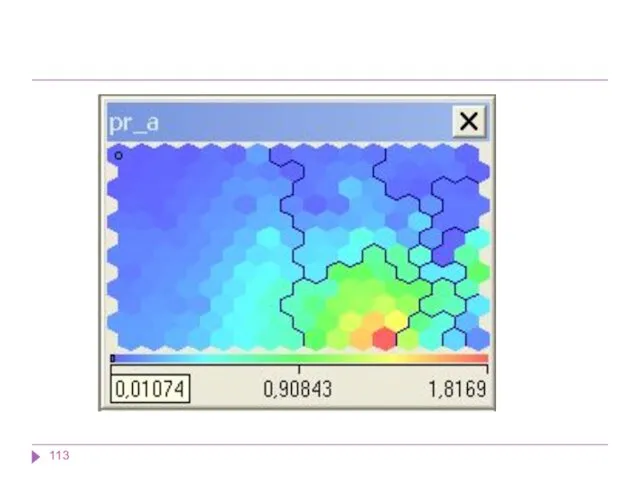
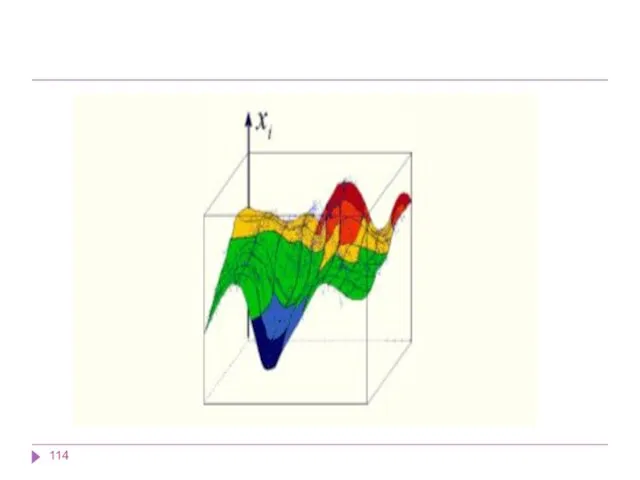
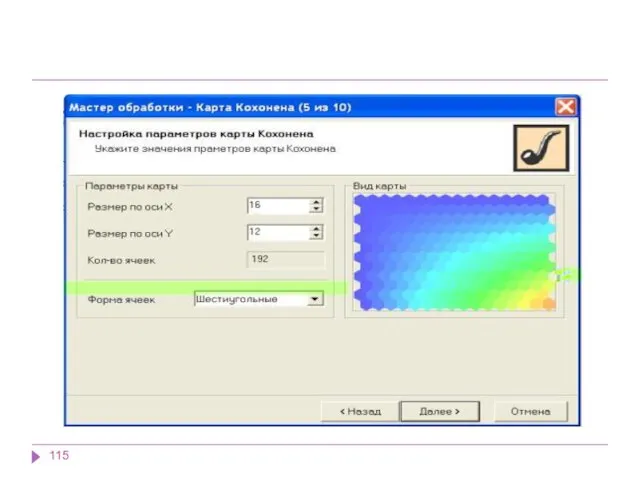
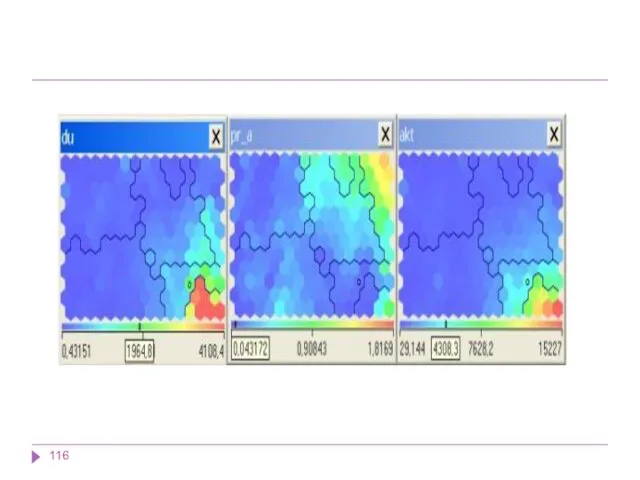

В результате работы алгоритма получаются следующие карты:
карта входов нейронов — визуализирует внутреннюю
В результате работы алгоритма получаются следующие карты: карта входов нейронов — визуализирует внутреннюю
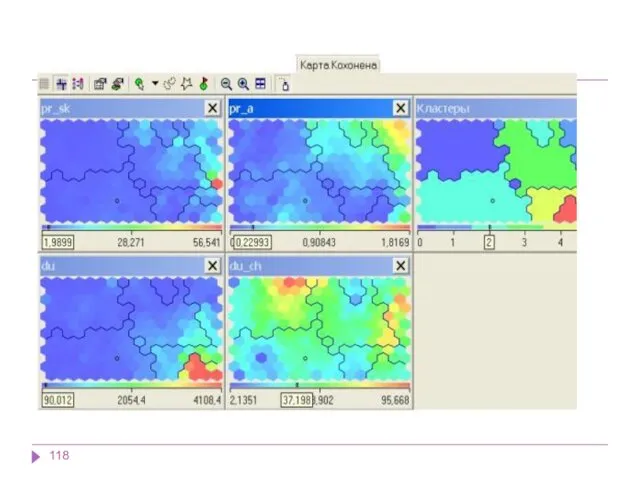

Методы кластерного анализа. Иерархические методы
Задачи кластерного анализа можно объединить в следующие
Методы кластерного анализа. Иерархические методы
Задачи кластерного анализа можно объединить в следующие
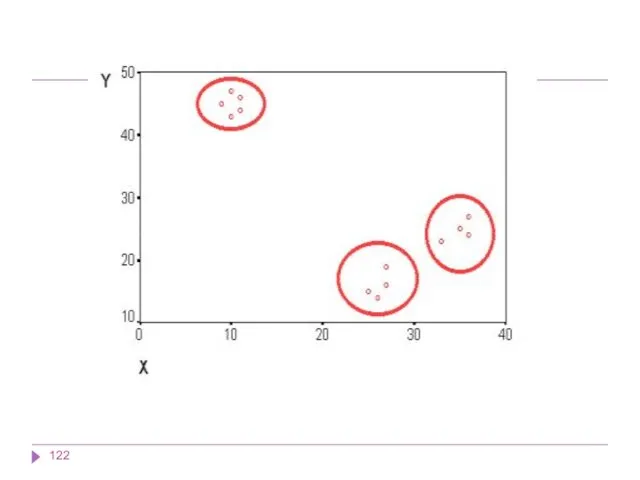

Методы кластерного анализа
Методы кластерного анализа можно разделить на две группы:
иерархические;
неиерархические.
Каждая из
Методы кластерного анализа
Методы кластерного анализа можно разделить на две группы:
иерархические;
неиерархические.
Каждая из

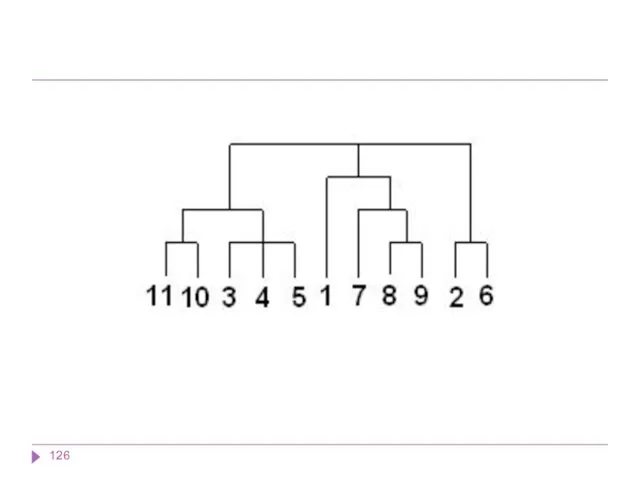
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном объединении меньших
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном объединении меньших

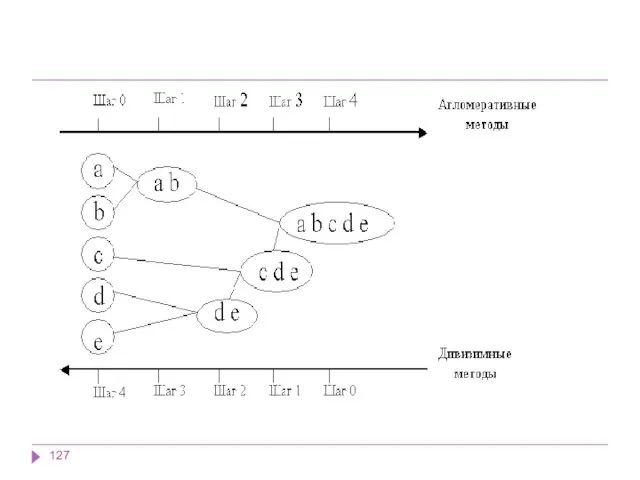
Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA)
Эти методы являются логической противоположностью
Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA)
Эти методы являются логической противоположностью

Методы поиска ассоциативных правил
Ассоциативное правило имеет вид: "Из события A следует
Методы поиска ассоциативных правил
Ассоциативное правило имеет вид: "Из события A следует

Алгоритм AIS.
Первый алгоритм поиска ассоциативных правил, называвшийся AIS (предложенный Agrawal, Imielinski
Алгоритм AIS.
Первый алгоритм поиска ассоциативных правил, называвшийся AIS (предложенный Agrawal, Imielinski

Алгоритм SETM
Создание этого алгоритма было мотивировано желанием использовать язык SQL для
Алгоритм SETM
Создание этого алгоритма было мотивировано желанием использовать язык SQL для

Неудобство алгоритмов AIS и SETM - излишнее генерирование и подсчет слишком
Неудобство алгоритмов AIS и SETM - излишнее генерирование и подсчет слишком

Формирование кандидатов (candidate generation) - этап, на котором алгоритм, сканируя базу
Формирование кандидатов (candidate generation) - этап, на котором алгоритм, сканируя базу
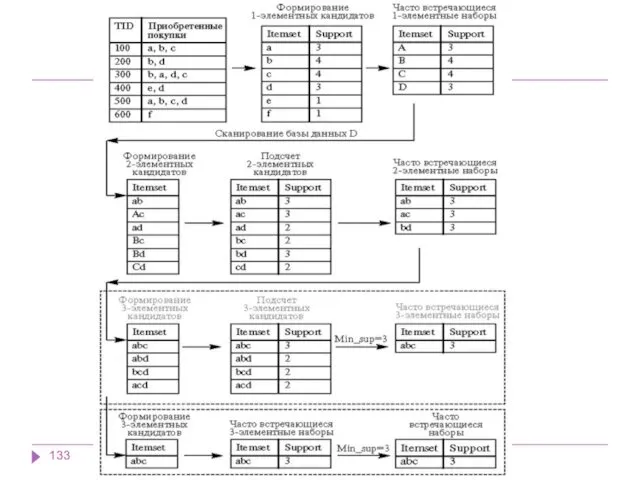

В зависимости от размера самого длинного часто встречающегося набора алгоритм Apriori
В зависимости от размера самого длинного часто встречающегося набора алгоритм Apriori

AprioriHybrid
Анализ времени работы алгоритмов Apriori и AprioriTid показывает, что в более
AprioriHybrid
Анализ времени работы алгоритмов Apriori и AprioriTid показывает, что в более

Один из них - алгоритм DHP, также называемый алгоритмом хеширования (J.
Один из них - алгоритм DHP, также называемый алгоритмом хеширования (J.

Системы для визуализации многомерных данных
К способам визуального или графического представления данных
Системы для визуализации многомерных данных
К способам визуального или графического представления данных

Традиционные методы визуализации могут находить следующее применение:
представлять пользователю информацию в наглядном
Традиционные методы визуализации могут находить следующее применение:
представлять пользователю информацию в наглядном

Методы визуализации
Методы визуализации, в зависимости от количества используемых измерений, принято классифицировать
Методы визуализации
Методы визуализации, в зависимости от количества используемых измерений, принято классифицировать

В соответствии с количеством измерений представления это могут быть следующие способы:
одномерное
В соответствии с количеством измерений представления это могут быть следующие способы:
одномерное

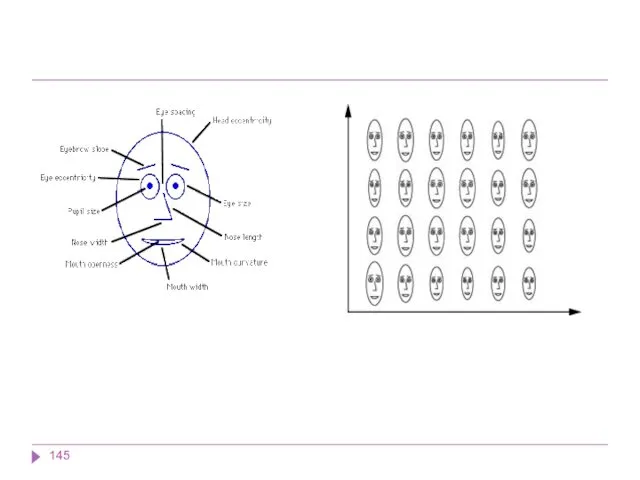
При использовании двух- и трехмерного представления информации пользователь имеет возможность увидеть
При использовании двух- и трехмерного представления информации пользователь имеет возможность увидеть

Представление данных в 4 х измерениях
Представления информации в четырехмерном и более
Представление данных в 4 х измерениях
Представления информации в четырехмерном и более
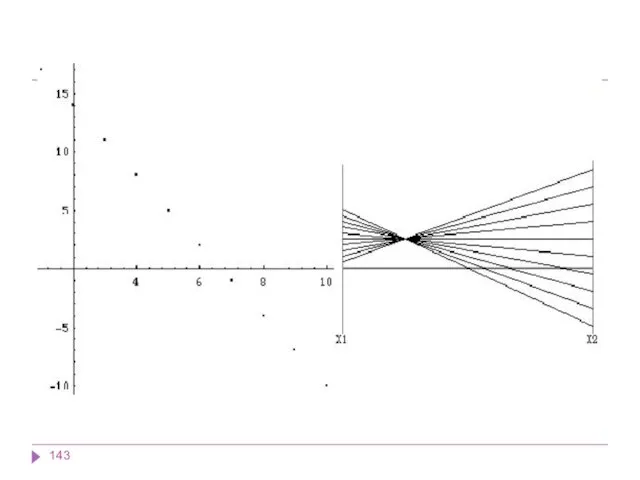


Основные принципы компоновки визуальных средств представления информации:
Принцип лаконичности.
Принцип обобщения и унификации.
Принцип
Основные принципы компоновки визуальных средств представления информации:
Принцип лаконичности.
Принцип обобщения и унификации.
Принцип
 Інтерфейси програмних засобів. Результати дослідження
Інтерфейси програмних засобів. Результати дослідження Библиографическое описание документа: оформление списка к научной работе
Библиографическое описание документа: оформление списка к научной работе Методика визуализации учебной информации
Методика визуализации учебной информации Технология разработки программного обеспечения (вторая часть). Порождающие шаблоны проектирования ПО
Технология разработки программного обеспечения (вторая часть). Порождающие шаблоны проектирования ПО Программирование (C++)
Программирование (C++) Методы и средства защиты компьютерной информации
Методы и средства защиты компьютерной информации Кодирование и шифрование данных
Кодирование и шифрование данных Хотите стать миллионером?
Хотите стать миллионером? Представление данных в ЭВМ
Представление данных в ЭВМ Книги PascalABC.NET. Современное программирование
Книги PascalABC.NET. Современное программирование Изменение и удаление данных. Изменение данных в таблицах
Изменение и удаление данных. Изменение данных в таблицах Пошук найкоротшого шляху. Графи
Пошук найкоротшого шляху. Графи Презентация Применение ИКТ в работе с педагогами
Презентация Применение ИКТ в работе с педагогами Разработка игры на платформе Ren’Py
Разработка игры на платформе Ren’Py Разбор задания № 15 КИМ ГИА-2012
Разбор задания № 15 КИМ ГИА-2012 Создание сети электронных магазинов
Создание сети электронных магазинов Facebook - социальная сеть
Facebook - социальная сеть Введение в Arduino
Введение в Arduino Мобильные технологии в обучении иностранного языка
Мобильные технологии в обучении иностранного языка Основные модели представления данных
Основные модели представления данных Cоставные части программы, локальные и глобальные переменные. Функции
Cоставные части программы, локальные и глобальные переменные. Функции Компьютер как средство автоматизации информационных процессов
Компьютер как средство автоматизации информационных процессов 9 класс. Повторение. Решение задач
9 класс. Повторение. Решение задач Архитектура ЭВМ. Основы операционных систем
Архитектура ЭВМ. Основы операционных систем Построение сборки редуктора
Построение сборки редуктора Портал государственных и муниципальных услуг
Портал государственных и муниципальных услуг Życie w sieci - SpołecznoścI internetowe
Życie w sieci - SpołecznoścI internetowe Обзор веб-ресурсов по веб-дизайну и веб-разработке
Обзор веб-ресурсов по веб-дизайну и веб-разработке