- Data mining - основные понятия и задачи

Содержание
- 2. Уровни информации исходные данные – необработанные массивы данных, получаемые в результате наблюдения за некой динамической системой
- 3. Определения Data Mining Извлечение, сбор данных, добыча данных (еще используют Information Retrieval или IR); Извлечение знаний,
- 4. Применение Data Mining
- 5. Задачи, решаемые Data Mining Классификация — отнесение входного вектора (объекта, события, наблюдения) к одному из заранее
- 6. CRoss Industry Standard Process for Data Mining (CRISP-DM)
- 7. CRoss Industry Standard Process for Data Mining (CRISP-DM)
- 9. Скачать презентацию

Уровни информации
исходные данные – необработанные массивы данных, получаемые в результате наблюдения
Уровни информации
исходные данные – необработанные массивы данных, получаемые в результате наблюдения

Определения Data Mining
Извлечение, сбор данных, добыча данных (еще используют Information Retrieval
Определения Data Mining
Извлечение, сбор данных, добыча данных (еще используют Information Retrieval
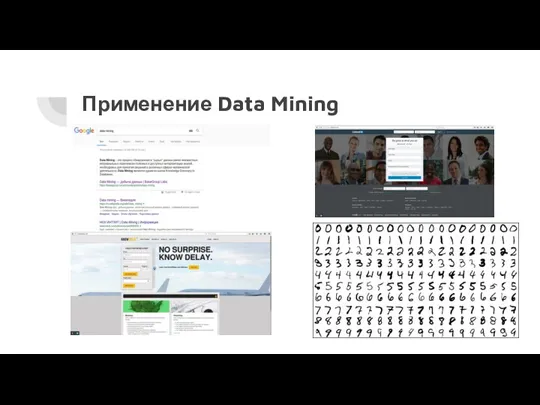
Применение Data Mining
Применение Data Mining

Задачи, решаемые Data Mining
Классификация — отнесение входного вектора (объекта, события, наблюдения)
Задачи, решаемые Data Mining
Классификация — отнесение входного вектора (объекта, события, наблюдения)
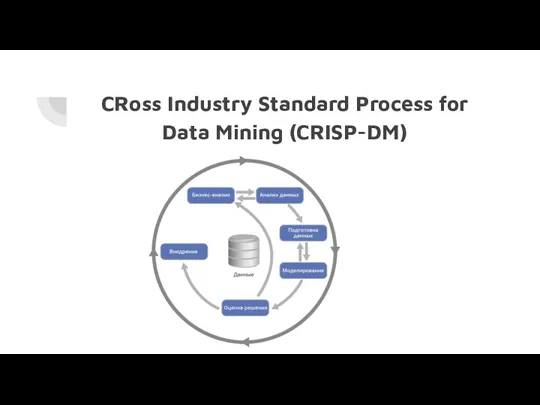
CRoss Industry Standard Process for Data Mining (CRISP-DM)
CRoss Industry Standard Process for Data Mining (CRISP-DM)

CRoss Industry Standard Process for Data Mining (CRISP-DM)
CRoss Industry Standard Process for Data Mining (CRISP-DM)
 ВКР: Основные характеристики технологии PON
ВКР: Основные характеристики технологии PON Методологические принципы построения автоматизированных систем (лекция 1)
Методологические принципы построения автоматизированных систем (лекция 1) Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Об’єкт event. Обробка подій
Об’єкт event. Обробка подій Захист від клавіатурних шпигунів. (Лекція 1.2)
Захист від клавіатурних шпигунів. (Лекція 1.2) Криптографічний захист інформації. Захист електронного листування за допомогою системи PGP
Криптографічний захист інформації. Захист електронного листування за допомогою системи PGP Разработчик видеоигр
Разработчик видеоигр Объектные привилегии
Объектные привилегии Метод проектов-инновационная педагогическая технология, фактор повышения качества образования
Метод проектов-инновационная педагогическая технология, фактор повышения качества образования Определение понятия проектирование. (Лекция 4)
Определение понятия проектирование. (Лекция 4) Бағдарламалық жасақтаманың жалпы құру түсініктемесі. Лекция 13
Бағдарламалық жасақтаманың жалпы құру түсініктемесі. Лекция 13 Модель специалиста библиотечно-информационной сферы
Модель специалиста библиотечно-информационной сферы Понятие модели. Назначение и свойства моделей
Понятие модели. Назначение и свойства моделей AVT. Audiovisual Translation
AVT. Audiovisual Translation What is a computer?
What is a computer? Информатизация образования в современных условиях
Информатизация образования в современных условиях Операционная система Linux. Знакомство с операционной системой
Операционная система Linux. Знакомство с операционной системой Кодирование звуковой информации
Кодирование звуковой информации Сетевые структуры в современной мировой политике. Сетевой терроризм
Сетевые структуры в современной мировой политике. Сетевой терроризм An Introduction to Computer Networking
An Introduction to Computer Networking Измерение информации. Семантический подход к измерению количества информации
Измерение информации. Семантический подход к измерению количества информации Подготовка к ГИА (часть А1). Умение оценивать количественные параметры информационных объектов. Задача 1
Подготовка к ГИА (часть А1). Умение оценивать количественные параметры информационных объектов. Задача 1 Разработка и реализация базы данных Телефонная станция
Разработка и реализация базы данных Телефонная станция Analiza și modelarea funcționalități jocului Leaguie of legends
Analiza și modelarea funcționalități jocului Leaguie of legends Типы данных
Типы данных Системы искусственного интелекта
Системы искусственного интелекта Кодирование информации
Кодирование информации Умный Дом
Умный Дом