- Динамические структуры данных. Односвязные и двусвязные списки

Содержание
- 2. Динамические структуры Односвязные (однонаправленные) списки Двусвязные (двунаправленные) списки
- 3. Динамические структуры данных Строение: набор узлов, объединенных с помощью ссылок. Как устроен узел: Типы структур: списки
- 4. Когда нужны списки? Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать в другой файл в
- 5. Что такое список: пустая структура – это список; список – это начальный узел (голова) и связанный
- 6. Что нужно уметь делать со списком? Создать новый узел. Добавить узел: в начало списка; в конец
- 7. Создание узла PNode CreateNode ( char NewWord[] ) { PNode NewNode = new Node; strcpy(NewNode->word, NewWord);
- 8. Добавление узла в начало списка 1) Установить ссылку нового узла на голову списка: NewNode->next = Head;
- 9. Добавление узла после заданного 1) Установить ссылку нового узла на узел, следующий за p: NewNode->next =
- 10. Задача: сделать что-нибудь хорошее с каждым элементом списка. Алгоритм: установить вспомогательный указатель q на голову списка;
- 11. Добавление узла в конец списка Задача: добавить новый узел в конец списка. Алгоритм: найти последний узел
- 12. Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя! Решение: найти предыдущий узел q (проход
- 13. Добавление узла перед заданным (II) Задача: вставить узел перед заданным без поиска предыдущего. Алгоритм: поменять местами
- 14. Поиск слова в списке Задача: найти в списке заданное слово или определить, что его нет. Функция
- 15. Куда вставить новое слово? Задача: найти узел, перед которым нужно вставить, заданное слово, так чтобы в
- 16. Удаление узла void DeleteNode ( PNode &Head, PNode p ) { PNode q = Head; if
- 17. Удаление узла void DeleteNode ( PNode &Head, PNode p ) { PNode q = Head; if
- 18. Алфавитно-частотный словарь Алгоритм: открыть файл на чтение; прочитать слово: если файл закончился (n!=1), то перейти к
- 20. Что надо уметь делать со списком?
- 22. Создать новый узел. Добавить узел: в начало списка; в конец списка; после заданного узла; до заданного
- 23. СТЕК Стек – это линейный список, в котором все включения и исключения (и обычно всякий доступ)
- 25. Пример. Ввести с клавиатуры 10 чисел, записав их в стек. Вывести содержимое стека и очистить память.
- 29. Очередь – это линейный список, в один конец которого добавляются элементы, а с другого конца исключаются,
- 30. Пример. Ввести с клавиатуры 10 чисел, записав их в очередь. Вывести содержимое очереди и очистить память.
- 33. Двусвязные списки Структура узла: struct Node { char word[40]; // слово int count; // счетчик повторений
- 34. Двусвязные списки При добавлении нового узла NewNode в начало списка надо 1) установить ссылку next узла
- 35. 2) установить ссылку prev бывшего первого узла (если он существовал) на NewNode; Двусвязные списки
- 36. 3) установить голову списка на новый узел; 4) если в списке не было ни одного элемента,
- 37. Двусвязные списки
- 38. Добавление узла после заданного Дан адрес NewNode нового узла и адрес p одного из существующих узлов
- 39. Если узел p – не последний, то операция вставки выполняется в два этапа: 1) установить ссылки
- 40. Добавление узла после заданного (добавление после выполняется аналогично)
- 41. Поиск узла в списке Проход по двусвязному списку может выполняться в двух направлениях – от головы
- 42. Проход по списку в от головы списка Алгоритм: установить вспомогательный указатель q на голову списка; если
- 43. ... PNode q = Head; // начали с головы while ( q != NULL ) {
- 44. Проход по списку от хвоста к голове списка Алгоритм: установить вспомогательный указатель q на хвост списка;
- 45. PNode q = Tail; // начали с хвоста while ( q != NULL ) { //
- 46. Удаление узла
- 48. Циклические списки Иногда список (односвязный или двусвязный) замыкают в кольцо. Указатель next последнего элемента указывает на
- 49. Дано число N и N целых чисел. Создать циклический односвязный линейный список, в который поместить все
- 52. Вывести значение N-го элемента кольцевого списка. Считать, что счет начинается с первого элемента и продолжается по
- 54. Скачать презентацию

Динамические структуры
Односвязные (однонаправленные) списки
Двусвязные (двунаправленные) списки
Динамические структуры
Односвязные (однонаправленные) списки
Двусвязные (двунаправленные) списки
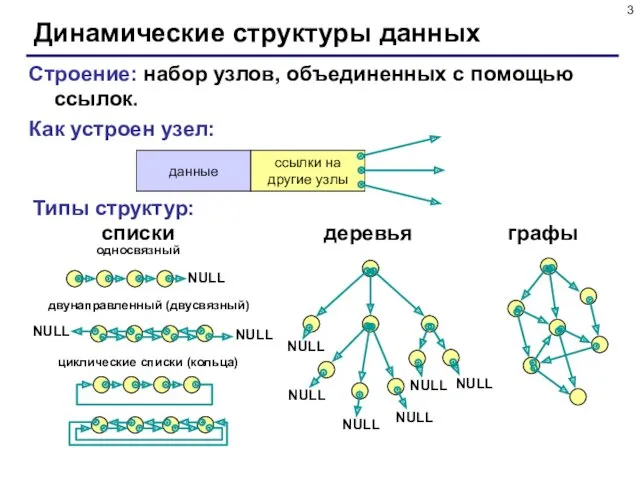
Динамические структуры данных
Строение: набор узлов, объединенных с помощью ссылок.
Как устроен узел:
Типы
Динамические структуры данных
Строение: набор узлов, объединенных с помощью ссылок.
Как устроен узел:
Типы

Когда нужны списки?
Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать
Когда нужны списки?
Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать
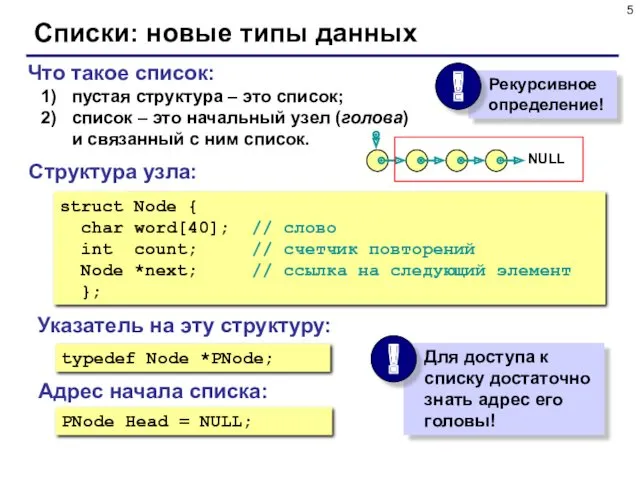
Что такое список:
пустая структура – это список;
список – это начальный узел
Что такое список:
пустая структура – это список;
список – это начальный узел

Что нужно уметь делать со списком?
Создать новый узел.
Добавить узел:
в начало списка;
в
Что нужно уметь делать со списком?
Создать новый узел.
Добавить узел:
в начало списка;
в
![Создание узла PNode CreateNode ( char NewWord[] ) { PNode](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/92025/slide-6.jpg)
Создание узла
PNode CreateNode ( char NewWord[] )
{
PNode NewNode = new
Создание узла
PNode CreateNode ( char NewWord[] )
{
PNode NewNode = new
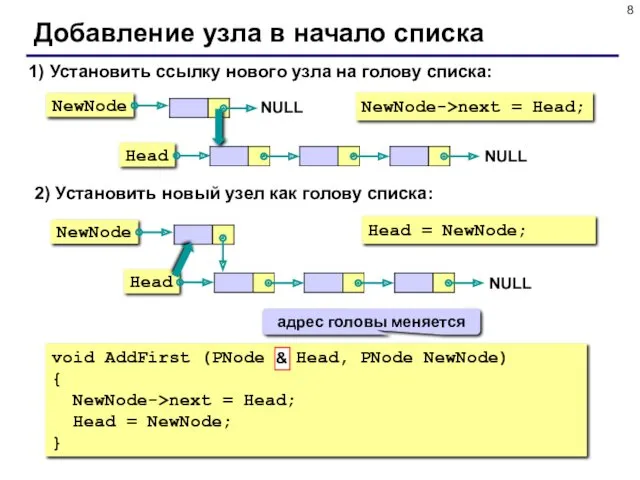
Добавление узла в начало списка
1) Установить ссылку нового узла на голову
Добавление узла в начало списка
1) Установить ссылку нового узла на голову
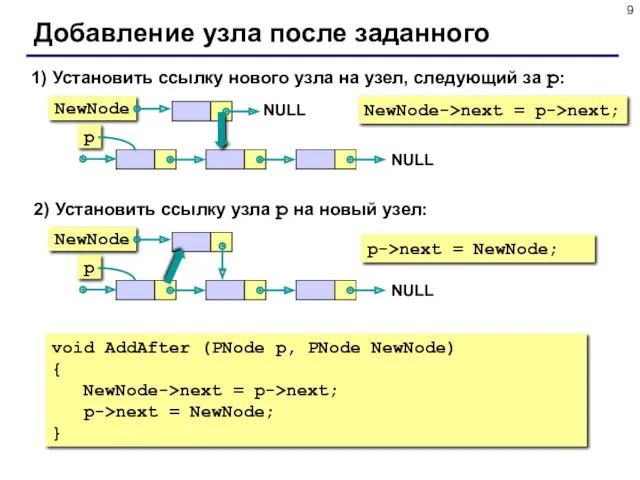
Добавление узла после заданного
1) Установить ссылку нового узла на узел, следующий
Добавление узла после заданного
1) Установить ссылку нового узла на узел, следующий
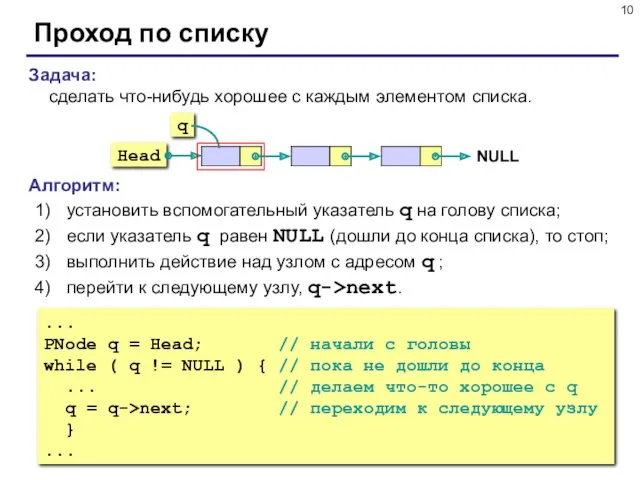
Задача:
сделать что-нибудь хорошее с каждым элементом списка.
Алгоритм:
установить вспомогательный указатель q
Задача:
сделать что-нибудь хорошее с каждым элементом списка.
Алгоритм:
установить вспомогательный указатель q

Добавление узла в конец списка
Задача: добавить новый узел в конец списка.
Алгоритм:
найти
Добавление узла в конец списка
Задача: добавить новый узел в конец списка.
Алгоритм:
найти
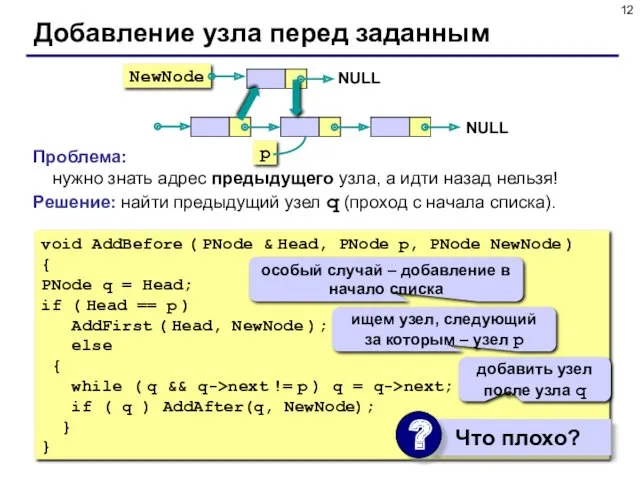
Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя!
Решение: найти
Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя!
Решение: найти
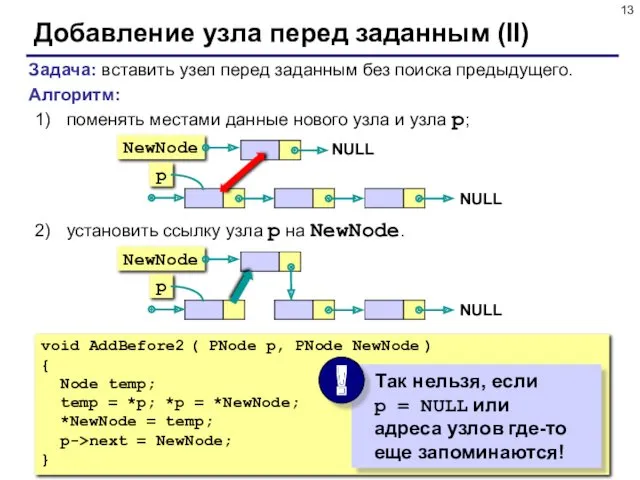
Добавление узла перед заданным (II)
Задача: вставить узел перед заданным без поиска
Добавление узла перед заданным (II)
Задача: вставить узел перед заданным без поиска
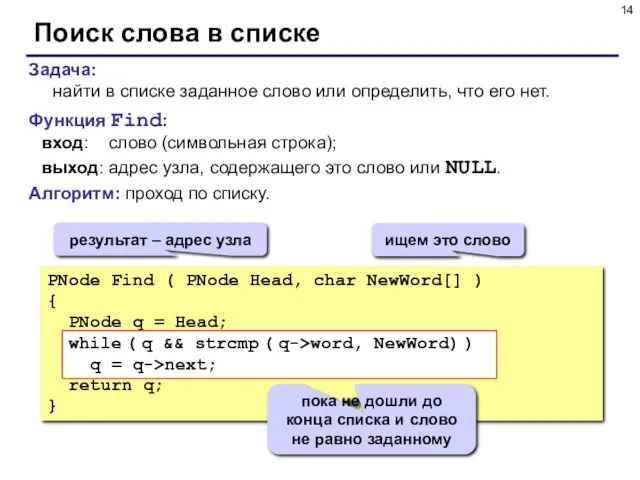
Поиск слова в списке
Задача:
найти в списке заданное слово или определить,
Поиск слова в списке
Задача: найти в списке заданное слово или определить,

Куда вставить новое слово?
Задача:
найти узел, перед которым нужно вставить, заданное
Куда вставить новое слово?
Задача: найти узел, перед которым нужно вставить, заданное
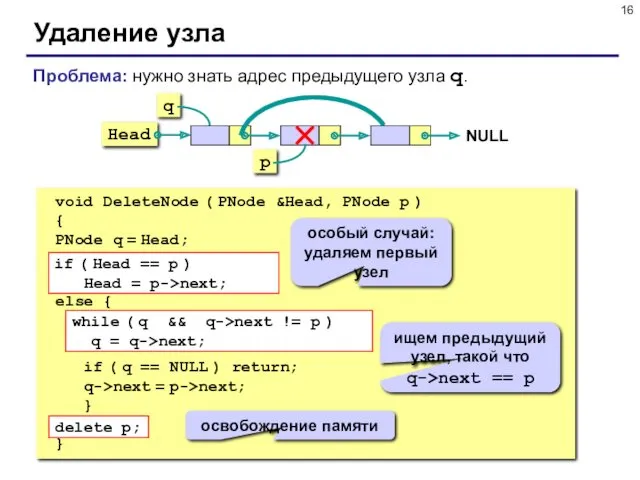
Удаление узла
void DeleteNode ( PNode &Head, PNode p )
{
PNode q =
Удаление узла
void DeleteNode ( PNode &Head, PNode p )
{
PNode q =
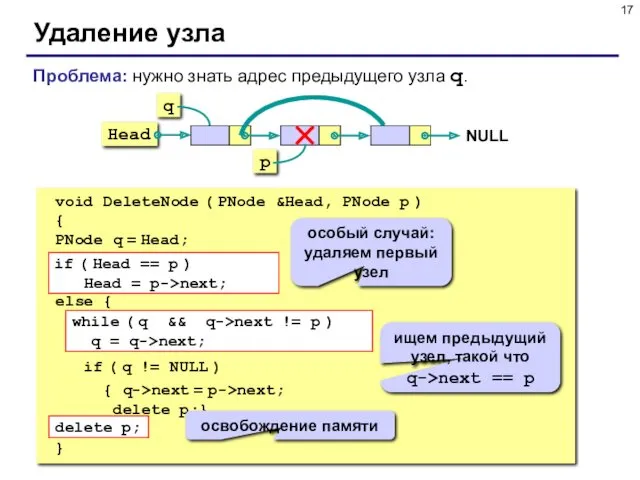
Удаление узла
void DeleteNode ( PNode &Head, PNode p )
{
PNode q =
Удаление узла
void DeleteNode ( PNode &Head, PNode p )
{
PNode q =

Алфавитно-частотный словарь
Алгоритм:
открыть файл на чтение;
прочитать слово:
если файл закончился (n!=1), то перейти
Алфавитно-частотный словарь
Алгоритм:
открыть файл на чтение;
прочитать слово:
если файл закончился (n!=1), то перейти


Что надо уметь делать со списком?
Что надо уметь делать со списком?


Создать новый узел.
Добавить узел:
в начало списка;
в конец списка;
после заданного узла;
до заданного
Создать новый узел.
Добавить узел:
в начало списка;
в конец списка;
после заданного узла;
до заданного

СТЕК
Стек – это линейный список, в котором все включения и исключения
СТЕК
Стек – это линейный список, в котором все включения и исключения

Пример. Ввести с клавиатуры 10 чисел, записав их в стек. Вывести
Пример. Ввести с клавиатуры 10 чисел, записав их в стек. Вывести




Очередь – это линейный список, в один конец которого добавляются элементы,
Очередь – это линейный список, в один конец которого добавляются элементы,

Пример. Ввести с клавиатуры 10 чисел, записав их в очередь. Вывести
Пример. Ввести с клавиатуры 10 чисел, записав их в очередь. Вывести


![Двусвязные списки Структура узла: struct Node { char word[40]; //](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/92025/slide-32.jpg)
Двусвязные списки
Структура узла:
struct Node {
char word[40]; // слово
int count;
Двусвязные списки
Структура узла:
struct Node {
char word[40]; // слово
int count;

Двусвязные списки
При добавлении нового узла NewNode в начало списка надо
1) установить
Двусвязные списки
При добавлении нового узла NewNode в начало списка надо
1) установить
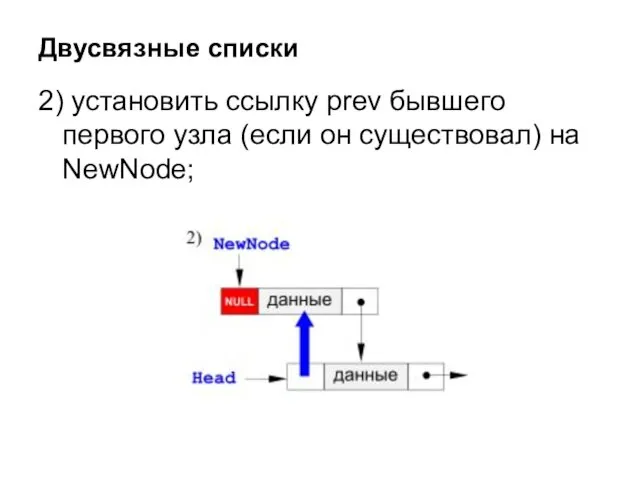
2) установить ссылку prev бывшего первого узла (если он существовал) на
2) установить ссылку prev бывшего первого узла (если он существовал) на
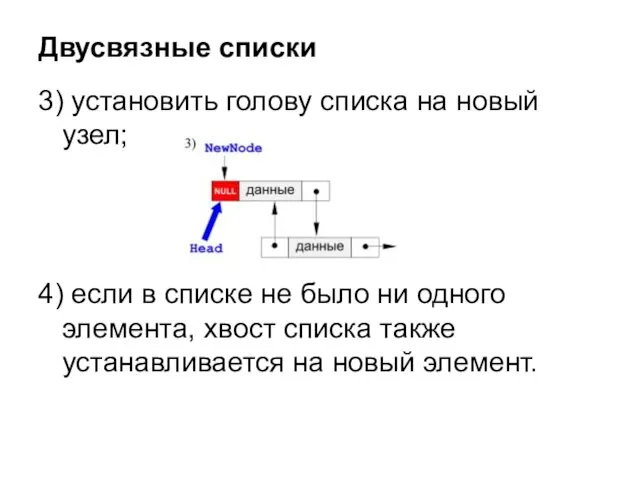
3) установить голову списка на новый узел;
4) если в списке не
3) установить голову списка на новый узел;
4) если в списке не
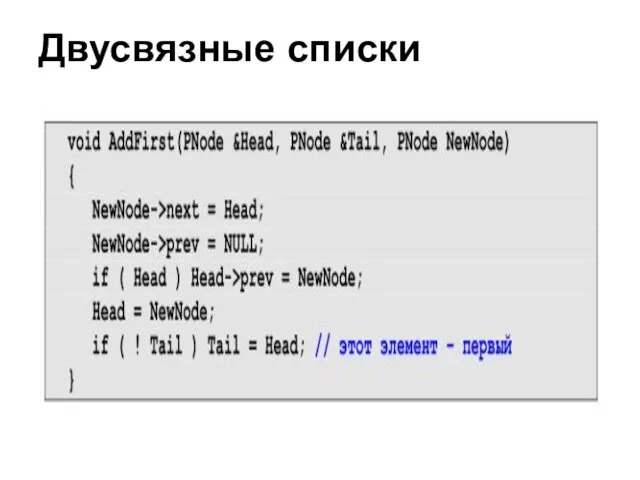
Двусвязные списки
Двусвязные списки

Добавление узла после заданного
Дан адрес NewNode нового узла и адрес p
Добавление узла после заданного
Дан адрес NewNode нового узла и адрес p
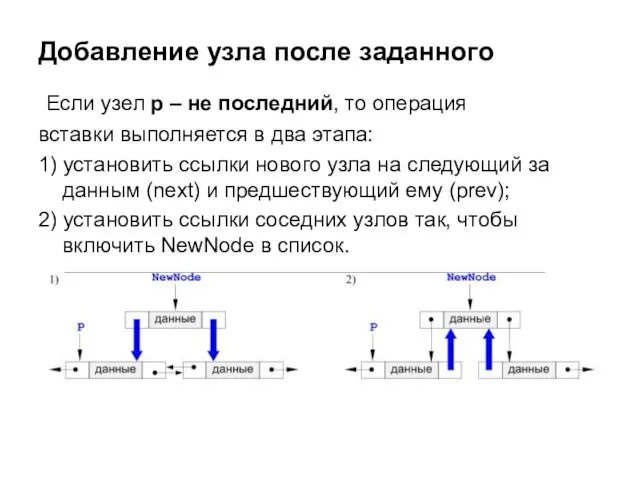
Если узел p – не последний, то операция
вставки выполняется в
Если узел p – не последний, то операция
вставки выполняется в

Добавление узла после заданного
(добавление после выполняется аналогично)
Добавление узла после заданного
(добавление после выполняется аналогично)

Поиск узла в списке
Проход по двусвязному списку может выполняться в двух
Поиск узла в списке
Проход по двусвязному списку может выполняться в двух

Проход по списку в от головы списка
Алгоритм:
установить вспомогательный указатель q на
Проход по списку в от головы списка
Алгоритм:
установить вспомогательный указатель q на

...
PNode q = Head; // начали с головы
while ( q
...
PNode q = Head; // начали с головы
while ( q

Проход по списку от хвоста к голове списка
Алгоритм:
установить вспомогательный указатель q
Проход по списку от хвоста к голове списка
Алгоритм:
установить вспомогательный указатель q

PNode q = Tail; // начали с хвоста
while ( q !=
PNode q = Tail; // начали с хвоста
while ( q !=

Удаление узла
Удаление узла


Циклические списки
Иногда список (односвязный или двусвязный) замыкают в кольцо.
Указатель next
Циклические списки
Иногда список (односвязный или двусвязный) замыкают в кольцо.
Указатель next

Дано число N и N целых чисел. Создать циклический односвязный линейный
Дано число N и N целых чисел. Создать циклический односвязный линейный



Вывести значение N-го элемента кольцевого списка. Считать, что счет начинается с
Вывести значение N-го элемента кольцевого списка. Считать, что счет начинается с
 Локальные и глобальные сети ЭВМ
Локальные и глобальные сети ЭВМ Набор и редактирование текста
Набор и редактирование текста Основы СУБД в ACCESS
Основы СУБД в ACCESS Interpreter- is a professional specialist participating in the conversation and in all activities
Interpreter- is a professional specialist participating in the conversation and in all activities Презентация по математике
Презентация по математике Присоединение Крыма к Российской Федерации: контент-анализ российских печатных СМИ
Присоединение Крыма к Российской Федерации: контент-анализ российских печатных СМИ Онлайн-марафон Ты больше, чем ты думаешь
Онлайн-марафон Ты больше, чем ты думаешь Автоматизация блока выделения изопентановой фракции. Топливное производство
Автоматизация блока выделения изопентановой фракции. Топливное производство Контроль пропускної здатності корпоративної комп'ютерної мережі засобами NMS моделі ISO
Контроль пропускної здатності корпоративної комп'ютерної мережі засобами NMS моделі ISO Школьная медиатека. Перспективы развития библиотек в школах России
Школьная медиатека. Перспективы развития библиотек в школах России Архитектура базы данных
Архитектура базы данных СУБД
СУБД Кодирование звуковой информации
Кодирование звуковой информации Алгоритм доклада на защиту городских медицинских округов в муниципальных образованиях МОДЕЛЬ ГОРОД
Алгоритм доклада на защиту городских медицинских округов в муниципальных образованиях МОДЕЛЬ ГОРОД Электронные таблицы. Обработка числовой информации в электронных таблицах. Информатика. 9 класс
Электронные таблицы. Обработка числовой информации в электронных таблицах. Информатика. 9 класс Технологии проектирования компьютерных систем. Формы имен. (Лекция 5)
Технологии проектирования компьютерных систем. Формы имен. (Лекция 5) Регистр
Регистр Мобильные сети GSM. (Лекция 11)
Мобильные сети GSM. (Лекция 11) Изображения и формы в HTML. (Тема 5)
Изображения и формы в HTML. (Тема 5) Базы данных. Основные понятия
Базы данных. Основные понятия Cluster analysis. (Lecture 6-8)
Cluster analysis. (Lecture 6-8) История Вконтакте
История Вконтакте Введение в анализ данных
Введение в анализ данных Объектно-ориентированное программирование как инструмент для моделирования транспортных процессов
Объектно-ориентированное программирование как инструмент для моделирования транспортных процессов Набор. Правила набора
Набор. Правила набора Файловые архивы
Файловые архивы Информационное общество его информационные ресурсы
Информационное общество его информационные ресурсы Programmalaşdyrma diliniň grafiki mümkinçilikleri (nokat, kesim, töwerek, gönüburçluk)
Programmalaşdyrma diliniň grafiki mümkinçilikleri (nokat, kesim, töwerek, gönüburçluk)