- Генерация и оптимизация кода

Содержание
- 2. Семантический анализ и подготовка к генерации кода Назначение семантического анализа Полный распознаватель для большинства языков программирования
- 3. на этапе синтаксического разбора в начале этапа подготовки к генерации кода - всякий раз по завершении
- 4. Этапы семантического анализа: - проверка соблюдения в исходной программе семантических соглашений входного языка; - дополнение внутреннего
- 5. Проверка соблюдения во входной программе семантических соглашений входного языка Эта проверка заключается в сопоставлении входных цепочек
- 6. Например, если мы возьмем оператор языка Pascal, имеющий вид a := b + c; то с
- 7. Дополнение внутреннего представления программы Если вернуться к рассмотренному выше элементарному оператору языка Pascal a := b
- 8. Однако разработчик исходной программы может не указывать явно используемые преобразования типов. Тогда необходимые преобразования типов выполняет
- 9. Проверка смысловых норм языков программирования Проверка элементарных смысловых норм языков программирования, напрямую не связанных с входным
- 10. Рассмотрим в качестве примера функцию, представляющую собой фрагмент вход-ной программы на языке C: int f_test(int a)
- 11. Однако если взять аналогичный по смыслу, но синтаксически более сложный фрагмент программы, то картина будет несколько
- 12. Идентификация лексических единиц языков программирования Идентификация переменных, типов, процедур, функций и других лексических единиц языков программирования
- 13. - имена локальных переменных дополняются именами тех блоков (функций, процедур), в которых эти переменные описаны; -
- 14. СОВЕТ Правила, по которым происходит модификация имен, достаточно просты. Их можно выяснить для конкретной версии компилятора
- 15. Распределение памяти Распределение памяти — это процесс, который ставит в соответствие лексическим единицам исходной программы адрес,
- 16. Процесс распределения памяти в современных компиляторах, как правило, работает с относительными, а не с абсолютными (физическими)
- 17. Область памяти в зависимости от ее роли и способа распределения Классификация областей памяти
- 18. Простые и сложные структуры данных. Выравнивание границ данных Распределение памяти для переменных скалярных типов Во всех
- 19. СОВЕТ Размер области памяти каждого скалярного типа данных фиксирован и известен для определенной целевой вычислительной системы.
- 20. Распределение памяти для сложных структур данных Правила распределения памяти под основные виды структур данных: для массивов
- 21. Формулы для вычисления объема памяти : для массивов: V мас = ∏i =1,n(m i )Vэл ,
- 22. Выравнивание границ областей памяти Говоря об объеме памяти, занимаемой различными лексемами языка , следует упомянуть еще
- 23. Статическое и динамическое связывание. Менеджеры памяти Глобальная и локальная память Глобальная область памяти — это область
- 24. Распределение памяти на локальные и глобальные области целиком определяется семантикой входного языка. Только зная смысл синтаксических
- 25. Статическая и динамическая память Динамическая область памяти — это область памяти , размер которой на этапе
- 26. Менеджеры памяти Многие компиляторы объектно-ориентированных языков программирования используют для работы с динамической памятью специальный менеджер памяти
- 27. При создании менеджера памяти разработчики компилятора преследуют две основные цели: сокращается количество обращений результирующей программы к
- 28. Дисплей памяти процедуры (функции). Стековая организация дисплея памяти Понятие дисплея памяти процедуры (функции) Дисплей памяти процедуры
- 29. Стековая организация дисплея памяти процедуры (функции) Стековая организация дисплея памяти процедуры (функции) основана на том, что
- 30. Исключительные ситуации и их обработка Понятие исключительной ситуации (exception) появилось в современных объектно-ориентированных языках программирования. Проблема
- 31. Обработчики исключительных ситуаций За обработку исключительных ситуаций отвечают специальные синтаксические конструкции, предусмотренные в объектно-ориентированных языках программирования.
- 32. Простейший механизм обработки исключительных ситуаций через стек параметров
- 33. Память для типов данных (RTTI-информация) объектно-ориентированных языках программирования существует понятие виртуальных (virtual) функций (или процедур) .
- 34. Взаимосвязь RTTI-таблицы с экземплярами объектов в результирующей программе
- 35. Генерация кода. Методы генерации кода Общие принципы генерации кода. Синтаксически управляемый перевод Принципы генерации объектного кода
- 36. Синтаксически управляемый перевод Чтобы компилятор мог построить код результирующей программы для всей синтаксической конструкции исходной программы,
- 37. Способы внутреннего представления программ Виды внутреннего представления программы Результатом работы синтаксического анализатора на основе КС-грамматики входного
- 38. Синтаксические деревья. Преобразование дерева разбора в дерево операций Алгоритм преобразования дерева семантического разбора в дерево операций
- 39. Шаг 5. Если текущий узел имеет один нижележащий узел (лист дерева), помеченный терминальным символом, обозначающим знак
- 40. Пример дерева операций для языка арифметических выражений
- 41. Многоадресный код с явно именуемым результатом (тетрады) Тетрады представляют собой запись операций в форме из четырех
- 42. Например, выражение A:=B*C+D—B*10, записанное в виде триад, будет иметь вид (B, C) + (^1, D) (B,
- 43. Постфиксная запись операций Постфиксная (обратная польская) запись — очень удобная для вычисления выражений форма записи операций
- 44. Ассемблерный код и машинные команды Машинные команды удобны тем, что при их использовании внутреннее представление программы
- 45. Обратная польская запись операций Обратная польская запись — это постфиксная запись операций. Она была предложена польским
- 46. Вычисление выражений с помощью обратной польской записи Вычисление выражений в обратной польской записи выполняется элементарно просто
- 47. Вычисление выражений в обратной польской записи с использованием стека
- 48. Схема СУ-компиляции для перевода выражений в обратную польскую запись Существует множество алгоритмов , которые позволяют преобразовывать
- 49. Построенная таким образом схема СУ-компиляции для преобразования арифметических выражений в форму обратной польской записи оказывается исключительно
- 50. Оптимизация кода. Основные методы оптимизации Для построения результирующего кода различных синтаксических конструкций входного языка используется метод
- 51. Оптимизация программы — это обработка, связанная с переупорядочиванием и изменением операций в компилируемой программе с целью
- 52. Оптимизацию можно выполнять на любой стадии генерации кода, начиная от завершения синтаксического разбора и вплоть до
- 53. Оптимизация может выполняться для следующих типовых синтаксических конструкций: -линейных участков программы; логических выражений; циклов; -вызовов процедур
- 54. Оптимизация линейных участков программы Линейный участок программы — это выполняемая по порядку последовательность операций, имеющая один
- 55. В общем случае бесполезными могут оказаться не только операции присваивания, но и любые другие операции линейного
- 56. Исключение избыточных вычислений (лишних операций) заключается в нахождении и удалении из объектного кода операций, которые повторно
- 57. Свертка объектного кода Свертка объектного кода — это выполнение во время компиляции тех операций исходной программы,
- 58. Алгоритм свертки триад последовательно просматривает триады линейного участка для каждой триады делает следующее: если операнд есть
- 59. Рассмотрим пример выполнения алгоритма. Пусть фрагмент исходной программы (записанной на языке типа Pascal) имеет вид: I
- 60. Исключение лишних операций Алгоритм исключения лишних операций просматривает операции в порядке их следования. Так же как
- 61. Рассмотрим работу алгоритма на примере: D := D + C*B; A := D + C*B; C
- 62. Видно, что в данном примере некоторые операции вычисляются дважды над одними и теми же операндами, а
- 63. Другие методы оптимизации программ Особенность оптимизации логических выражений заключается в том, что не всегда необходимо полностью
- 64. Не только логические операции могут иметь предопределенный результат. Некоторые математические операции и функции также обладают этим
- 65. Оптимизация передачи параметров в процедуры и функции Данный метод прост в реализации и имеет хорошую аппаратную
- 66. Метод передачи параметров через регистры процессора позволяет разместить все или часть параметров, передаваемых в процедуру или
- 67. Метод подстановки кода функции в вызывающий объектный код (так называемая inline-подстановка) основан на том, что объектный
- 68. Оптимизация циклов Циклом в программе называется любая последовательность участков программы, которая может выполняться повторно. Циклы присущи
- 69. Для оптимизации циклов используются следующие методы: вынесение инвариантных вычислений из циклов; замена операций с индуктивными переменными;
- 70. Замена операций с индуктивными переменными Замена операций с индуктивными переменными заключается в изменении сложных операций с
- 71. Слияние и развертывание циклов Слияние и развертывание циклов предусматривает два различных варианта преобразований: слияния двух вложенных
- 72. Машинно-зависимые методы оптимизации Машинно-зависимые методы оптимизации ориентированы на конкретную архитектуру целевой вычислительной системы, на которой будет
- 73. Распределение регистров процессора Программно-доступных регистров процессора всегда ограниченное количество. Поэтому встает вопрос об их распределении при
- 75. Скачать презентацию

Семантический анализ и подготовка к генерации кода
Назначение семантического анализа
Полный распознаватель для
Семантический анализ и подготовка к генерации кода
Назначение семантического анализа
Полный распознаватель для
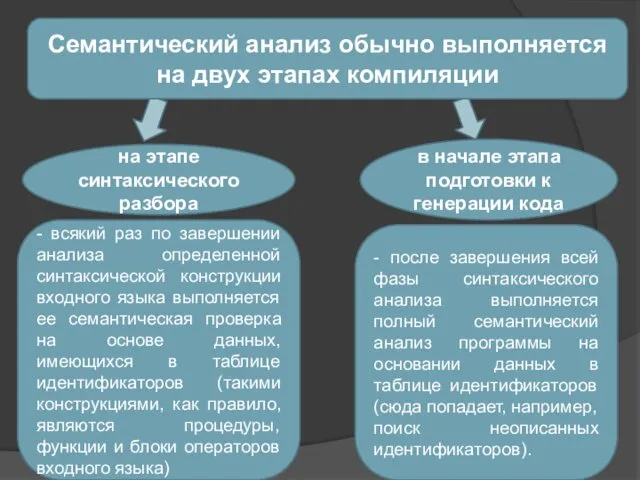
на этапе синтаксического разбора
в начале этапа подготовки к генерации кода
-
на этапе синтаксического разбора
в начале этапа подготовки к генерации кода
-

Этапы семантического анализа:
- проверка соблюдения в исходной программе семантических соглашений
Этапы семантического анализа:
- проверка соблюдения в исходной программе семантических соглашений

Проверка соблюдения во входной программе семантических соглашений входного языка
Эта проверка заключается
Проверка соблюдения во входной программе семантических соглашений входного языка
Эта проверка заключается

Например, если мы возьмем оператор языка Pascal, имеющий вид a :=
Например, если мы возьмем оператор языка Pascal, имеющий вид a :=

Дополнение внутреннего представления программы
Если вернуться к рассмотренному выше элементарному оператору языка
Дополнение внутреннего представления программы
Если вернуться к рассмотренному выше элементарному оператору языка

Однако разработчик исходной программы может не указывать явно используемые преобразования типов.
Однако разработчик исходной программы может не указывать явно используемые преобразования типов.

Проверка смысловых норм языков программирования
Проверка элементарных смысловых норм языков программирования, напрямую
Проверка смысловых норм языков программирования
Проверка элементарных смысловых норм языков программирования, напрямую

Рассмотрим в качестве примера функцию, представляющую собой фрагмент вход-ной программы на
Рассмотрим в качестве примера функцию, представляющую собой фрагмент вход-ной программы на

Однако если взять аналогичный по смыслу, но синтаксически более сложный фрагмент
Однако если взять аналогичный по смыслу, но синтаксически более сложный фрагмент

Идентификация лексических единиц языков программирования
Идентификация переменных, типов, процедур, функций и
Идентификация лексических единиц языков программирования
Идентификация переменных, типов, процедур, функций и

- имена локальных переменных дополняются именами тех блоков (функций, процедур), в
- имена локальных переменных дополняются именами тех блоков (функций, процедур), в

СОВЕТ
Правила, по которым происходит модификация имен, достаточно просты. Их можно
СОВЕТ
Правила, по которым происходит модификация имен, достаточно просты. Их можно

Распределение памяти
Распределение памяти — это процесс, который ставит в соответствие лексическим
Распределение памяти
Распределение памяти — это процесс, который ставит в соответствие лексическим

Процесс распределения памяти в современных компиляторах, как правило, работает с относительными,
Процесс распределения памяти в современных компиляторах, как правило, работает с относительными,
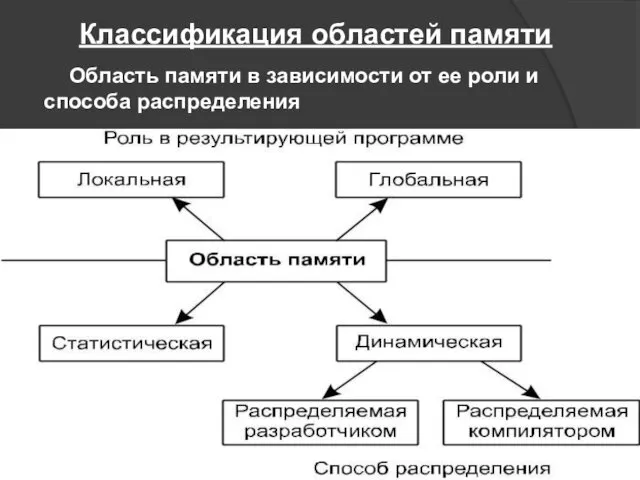
Область памяти в зависимости от ее роли и способа распределения
Классификация областей
Область памяти в зависимости от ее роли и способа распределения
Классификация областей

Простые и сложные структуры данных.
Выравнивание границ данных
Распределение памяти для переменных
Простые и сложные структуры данных.
Выравнивание границ данных
Распределение памяти для переменных

СОВЕТ
Размер области памяти каждого скалярного типа данных фиксирован и известен
СОВЕТ
Размер области памяти каждого скалярного типа данных фиксирован и известен

Распределение памяти для сложных структур данных
Правила распределения памяти под основные виды
Распределение памяти для сложных структур данных
Правила распределения памяти под основные виды

Формулы для вычисления объема памяти :
для массивов: V мас = ∏i =1,n(m
Формулы для вычисления объема памяти :
для массивов: V мас = ∏i =1,n(m

Выравнивание границ областей памяти
Говоря об объеме памяти, занимаемой различными лексемами языка
Выравнивание границ областей памяти
Говоря об объеме памяти, занимаемой различными лексемами языка
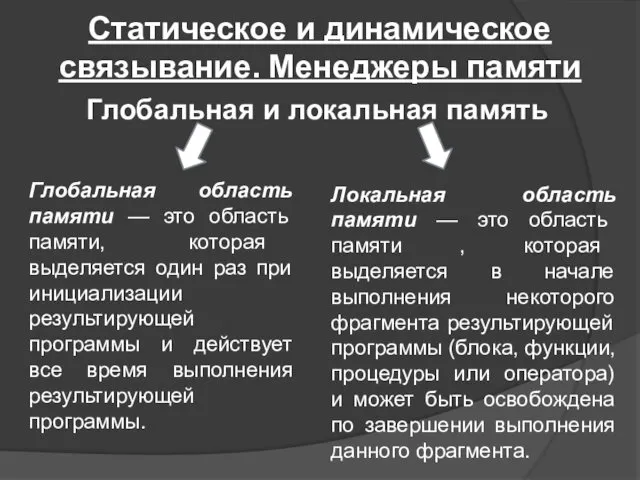
Статическое и динамическое связывание. Менеджеры памяти
Глобальная и локальная память
Глобальная область памяти
Статическое и динамическое связывание. Менеджеры памяти
Глобальная и локальная память
Глобальная область памяти

Распределение памяти на локальные и глобальные области целиком определяется семантикой
Распределение памяти на локальные и глобальные области целиком определяется семантикой

Статическая и динамическая память
Динамическая область памяти — это область памяти ,
Статическая и динамическая память
Динамическая область памяти — это область памяти ,

Менеджеры памяти
Многие компиляторы объектно-ориентированных языков программирования используют для работы с динамической
Менеджеры памяти
Многие компиляторы объектно-ориентированных языков программирования используют для работы с динамической

При создании менеджера памяти разработчики компилятора преследуют две основные цели:
сокращается количество
При создании менеджера памяти разработчики компилятора преследуют две основные цели:
сокращается количество

Дисплей памяти процедуры (функции). Стековая организация дисплея памяти
Понятие дисплея памяти процедуры
Дисплей памяти процедуры (функции). Стековая организация дисплея памяти
Понятие дисплея памяти процедуры

Стековая организация дисплея памяти процедуры (функции)
Стековая организация дисплея памяти процедуры (функции)
Стековая организация дисплея памяти процедуры (функции)
Стековая организация дисплея памяти процедуры (функции)

Исключительные ситуации и их обработка
Понятие исключительной ситуации (exception) появилось в современных
Исключительные ситуации и их обработка
Понятие исключительной ситуации (exception) появилось в современных

Обработчики исключительных ситуаций
За обработку исключительных ситуаций отвечают специальные синтаксические конструкции, предусмотренные
Обработчики исключительных ситуаций
За обработку исключительных ситуаций отвечают специальные синтаксические конструкции, предусмотренные
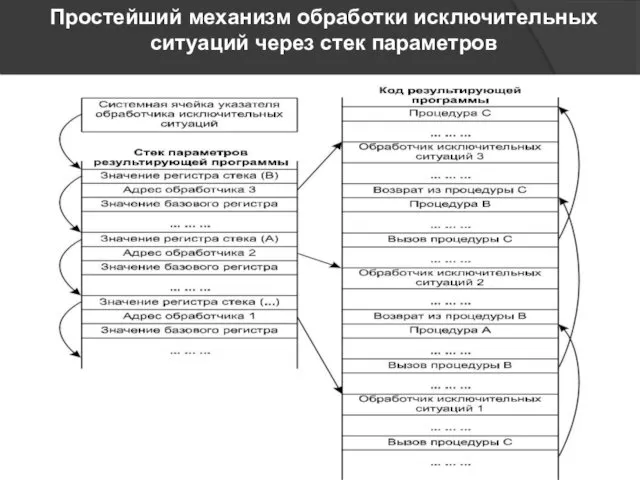
Простейший механизм обработки исключительных ситуаций через стек параметров
Простейший механизм обработки исключительных ситуаций через стек параметров

Память для типов данных (RTTI-информация)
объектно-ориентированных языках программирования существует понятие виртуальных (virtual)
Память для типов данных (RTTI-информация)
объектно-ориентированных языках программирования существует понятие виртуальных (virtual)
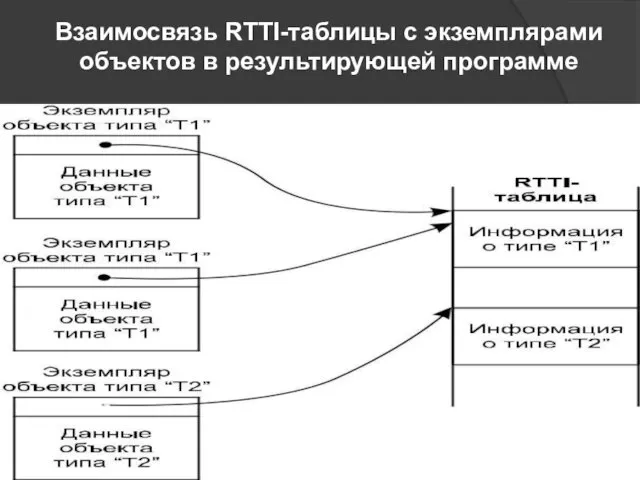
Взаимосвязь RTTI-таблицы с экземплярами объектов в результирующей программе
Взаимосвязь RTTI-таблицы с экземплярами объектов в результирующей программе

Генерация кода. Методы генерации кода
Общие принципы генерации кода. Синтаксически управляемый перевод
Принципы
Генерация кода. Методы генерации кода
Общие принципы генерации кода. Синтаксически управляемый перевод
Принципы

Синтаксически управляемый перевод
Чтобы компилятор мог построить код результирующей программы для всей
Синтаксически управляемый перевод
Чтобы компилятор мог построить код результирующей программы для всей

Способы внутреннего представления программ
Виды внутреннего представления программы
Результатом работы синтаксического анализатора на
Способы внутреннего представления программ
Виды внутреннего представления программы
Результатом работы синтаксического анализатора на

Синтаксические деревья. Преобразование дерева разбора в дерево операций
Алгоритм преобразования дерева семантического
Синтаксические деревья. Преобразование дерева разбора в дерево операций
Алгоритм преобразования дерева семантического

Шаг 5. Если текущий узел имеет один нижележащий узел (лист дерева),
Шаг 5. Если текущий узел имеет один нижележащий узел (лист дерева),
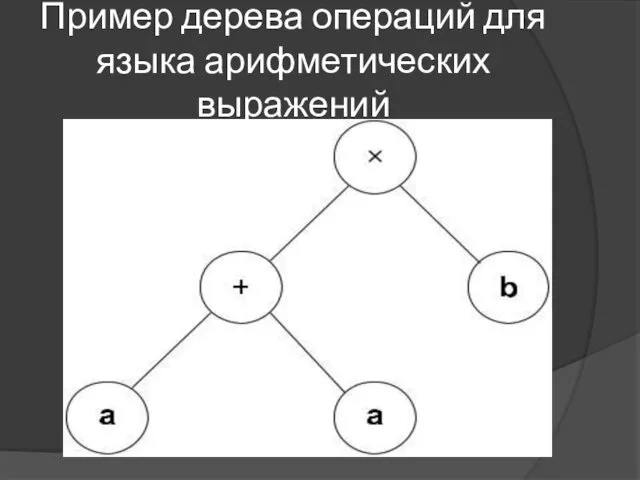
Пример дерева операций для языка арифметических выражений
Пример дерева операций для языка арифметических выражений

Многоадресный код с явно именуемым результатом (тетрады)
Тетрады представляют собой запись
Многоадресный код с явно именуемым результатом (тетрады)
Тетрады представляют собой запись

Например, выражение A:=B*C+D—B*10, записанное в виде триад, будет иметь вид
(B, C)
Например, выражение A:=B*C+D—B*10, записанное в виде триад, будет иметь вид
(B, C)

Постфиксная запись операций
Постфиксная (обратная польская) запись — очень удобная для вычисления
Постфиксная запись операций
Постфиксная (обратная польская) запись — очень удобная для вычисления

Ассемблерный код и машинные команды
Машинные команды удобны тем, что при
Ассемблерный код и машинные команды
Машинные команды удобны тем, что при

Обратная польская запись операций
Обратная польская запись — это постфиксная запись операций.
Обратная польская запись операций
Обратная польская запись — это постфиксная запись операций.

Вычисление выражений с помощью обратной польской записи
Вычисление выражений в обратной польской
Вычисление выражений с помощью обратной польской записи
Вычисление выражений в обратной польской
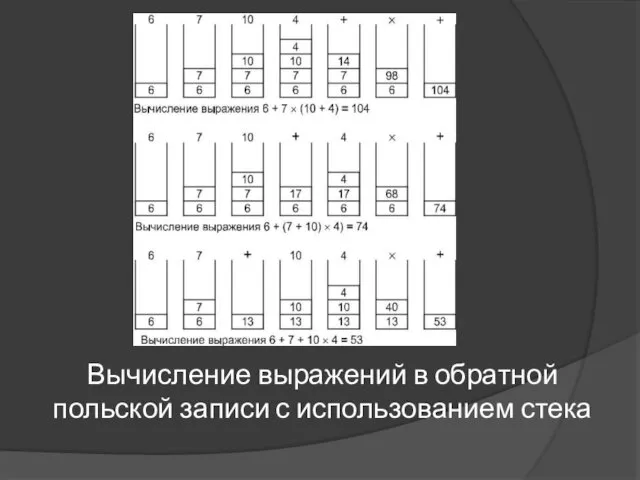
Вычисление выражений в обратной польской записи с использованием стека
Вычисление выражений в обратной польской записи с использованием стека

Схема СУ-компиляции для перевода выражений в обратную польскую запись
Существует множество
Схема СУ-компиляции для перевода выражений в обратную польскую запись
Существует множество

Построенная таким образом схема СУ-компиляции для преобразования арифметических выражений в форму
Построенная таким образом схема СУ-компиляции для преобразования арифметических выражений в форму

Оптимизация кода. Основные методы оптимизации
Для построения результирующего кода различных синтаксических конструкций
Оптимизация кода. Основные методы оптимизации
Для построения результирующего кода различных синтаксических конструкций

Оптимизация программы — это обработка, связанная с переупорядочиванием и изменением операций
Оптимизация программы — это обработка, связанная с переупорядочиванием и изменением операций

Оптимизацию можно выполнять на любой стадии генерации кода, начиная от завершения
Оптимизацию можно выполнять на любой стадии генерации кода, начиная от завершения

Оптимизация может выполняться для следующих типовых синтаксических конструкций:
-линейных участков программы; логических
Оптимизация может выполняться для следующих типовых синтаксических конструкций:
-линейных участков программы; логических

Оптимизация линейных участков программы
Линейный участок программы — это выполняемая по порядку
Оптимизация линейных участков программы
Линейный участок программы — это выполняемая по порядку

В общем случае бесполезными могут оказаться не только операции присваивания, но
В общем случае бесполезными могут оказаться не только операции присваивания, но

Исключение избыточных вычислений (лишних операций) заключается в нахождении и удалении из
Исключение избыточных вычислений (лишних операций) заключается в нахождении и удалении из

Свертка объектного кода
Свертка объектного кода — это выполнение во время компиляции
Свертка объектного кода
Свертка объектного кода — это выполнение во время компиляции

Алгоритм свертки триад последовательно просматривает триады линейного участка для каждой триады
Алгоритм свертки триад последовательно просматривает триады линейного участка для каждой триады

Рассмотрим пример выполнения алгоритма.
Пусть фрагмент исходной программы (записанной на языке типа
Рассмотрим пример выполнения алгоритма.
Пусть фрагмент исходной программы (записанной на языке типа

Исключение лишних операций
Алгоритм исключения лишних операций просматривает операции в порядке их
Исключение лишних операций
Алгоритм исключения лишних операций просматривает операции в порядке их

Рассмотрим работу алгоритма на примере:
D := D + C*B;
A := D
Рассмотрим работу алгоритма на примере:
D := D + C*B;
A := D
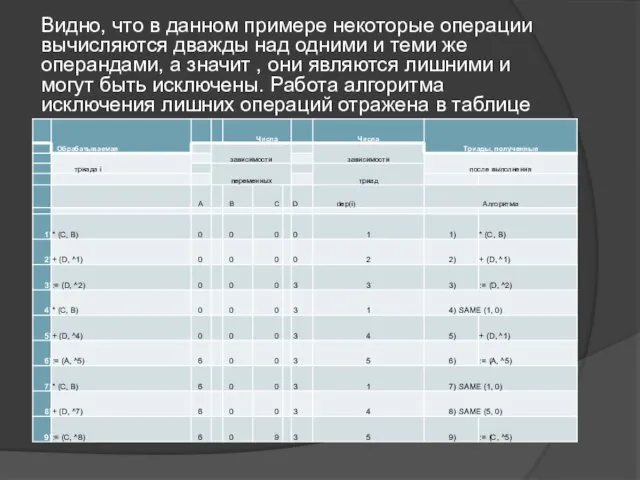
Видно, что в данном примере некоторые операции вычисляются дважды над одними
Видно, что в данном примере некоторые операции вычисляются дважды над одними

Другие методы оптимизации программ
Особенность оптимизации логических выражений заключается в том, что
Другие методы оптимизации программ
Особенность оптимизации логических выражений заключается в том, что

Не только логические операции могут иметь предопределенный результат. Некоторые математические операции
Не только логические операции могут иметь предопределенный результат. Некоторые математические операции

Оптимизация передачи параметров в процедуры и функции
Данный метод прост в реализации
Оптимизация передачи параметров в процедуры и функции
Данный метод прост в реализации

Метод передачи параметров через регистры процессора позволяет разместить все или часть
Метод передачи параметров через регистры процессора позволяет разместить все или часть

Метод подстановки кода функции в вызывающий объектный код (так называемая inline-подстановка)
Метод подстановки кода функции в вызывающий объектный код (так называемая inline-подстановка)

Оптимизация циклов
Циклом в программе называется любая последовательность участков программы, которая может
Оптимизация циклов
Циклом в программе называется любая последовательность участков программы, которая может

Для оптимизации циклов используются следующие методы:
вынесение инвариантных вычислений из циклов;
замена
Для оптимизации циклов используются следующие методы: вынесение инвариантных вычислений из циклов; замена

Замена операций с индуктивными переменными
Замена операций с индуктивными переменными заключается в
Замена операций с индуктивными переменными
Замена операций с индуктивными переменными заключается в

Слияние и развертывание циклов
Слияние и развертывание циклов предусматривает два различных варианта
Слияние и развертывание циклов
Слияние и развертывание циклов предусматривает два различных варианта

Машинно-зависимые методы оптимизации
Машинно-зависимые методы оптимизации ориентированы на конкретную архитектуру целевой вычислительной
Машинно-зависимые методы оптимизации
Машинно-зависимые методы оптимизации ориентированы на конкретную архитектуру целевой вычислительной

Распределение регистров процессора
Программно-доступных регистров процессора всегда ограниченное количество. Поэтому встает вопрос
Распределение регистров процессора
Программно-доступных регистров процессора всегда ограниченное количество. Поэтому встает вопрос
 Сервисы для создания презентаций
Сервисы для создания презентаций Организация защиты информации в локальной сети компании ООО MAN Truck and Bus Rus
Организация защиты информации в локальной сети компании ООО MAN Truck and Bus Rus Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма
Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма Модифицированный симплекс метод
Модифицированный симплекс метод Исполнители алгоритмов
Исполнители алгоритмов Python.Основы Циклы While. For. Лекция 3.2
Python.Основы Циклы While. For. Лекция 3.2 Що таке джинса
Що таке джинса Feed back
Feed back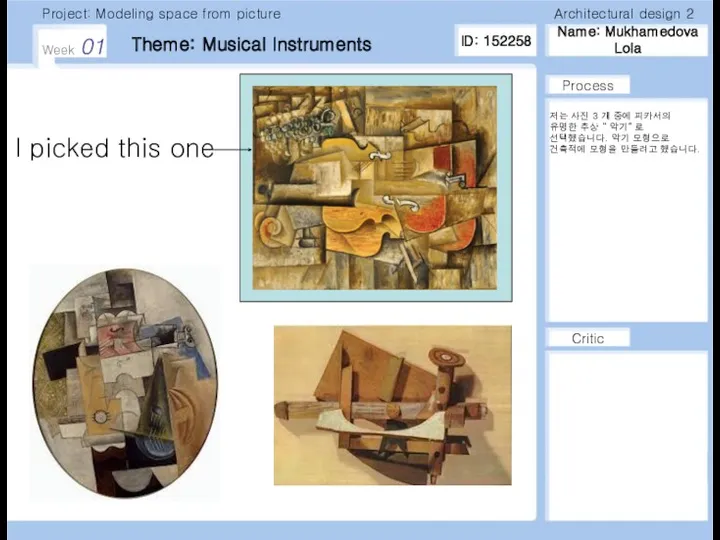 Modeling space from picture. Musical instruments
Modeling space from picture. Musical instruments Урок на тему Единицы измерения информации 6 класс
Урок на тему Единицы измерения информации 6 класс Зачем человек приходит в этот мир?
Зачем человек приходит в этот мир? Защита от несанкционированного доступа к информации
Защита от несанкционированного доступа к информации Цифровое фото и видео
Цифровое фото и видео Transition headline. Let’s start with the first set of slides
Transition headline. Let’s start with the first set of slides Графический интерфейс. Библиотека Tkinter
Графический интерфейс. Библиотека Tkinter Строковый и символьный тип данных
Строковый и символьный тип данных Виртуальные экскурсии: технологии создания
Виртуальные экскурсии: технологии создания Google. История создания
Google. История создания Криптография. История развития и базовые знания
Криптография. История развития и базовые знания Модель ISO/OSI
Модель ISO/OSI Научно-техническая и патентная информация Часть 2
Научно-техническая и патентная информация Часть 2 Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары
Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары Телеграмм-бот по игре Dota
Телеграмм-бот по игре Dota Подпрограммы в авс pascal
Подпрограммы в авс pascal Інформаційна система Ідентифікації шляхом розпізнавання обличчя
Інформаційна система Ідентифікації шляхом розпізнавання обличчя Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16)
Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16) Протоколы распределения ключей
Протоколы распределения ключей Сбор данных
Сбор данных