- High Performance Deep Learning on Intel Architecture

Содержание
- 2. Bigger Data Better Hardware Smarter Algorithms Fast Evolution of Technology Image: 1000 KB / picture Audio:
- 3. Classical Machine Learning CLASSIFIER SVM Random Forest Naïve Bayes Decision Trees Logistic Regression Ensemble methods Arjun
- 4. Deep learning A method of extracting features at multiple levels of abstraction Features are discovered from
- 5. End-to-End Deep Learning ~60 million parameters But old practices apply: Data Cleaning, Exploration, Data annotation, hyperparameters,
- 6. Automating previously “human” tasks Human Performance 2010 Present ImageNet Error Rate Using Deep Learning 2000 Present
- 7. ( 1 ) Large compute requirements for training Deep Learning Challenges
- 8. ( 2 ) Performance scales with data Deep Learning Challenges
- 9. Scaling is I/O Bound # OF PROCESSORS LEARNING SPEED INDUSTRY STANDARD: COMMUNICATION OVERHEAD = PERFORMANCE CEILING
- 10. Intel Provides the Compute Foundation for DL Deep Learning Frameworks
- 11. INTEL® MKL-DNN
- 12. Deep learning with Intel® MKL-DNN Intel® MKL SW building block to extract maximum performance on Intel®
- 13. Deep learning with Intel® MKL-DNN Intel® MKL-DNN Tech preview, https://01.org/mkl-dnn Demonstrates interfaces and the library structure
- 14. Deep learning with Intel® MKL-DNN Intel® MKL-DNN Programming Model Primitive – any operation (convolution, data format
- 15. Intel® Xeon Phi ™ processor 7250 up to 400x performance increase with Intel Optimized Frameworks compared
- 16. Intel® Xeon Phi ™ processor Knights Mill up to 4x estimated performance improvement over Intel® Xeon
- 17. INTEL® Machine Learning Scaling Library
- 18. Intel® Machine Learning Scaling Library (MLSL) Deep learning abstraction of message-passing implementations. Built on top of
- 19. Intel® Xeon Phi™ Processor 7250 GoogleNet V1 Time-To-Train Scaling Efficiency up to 97% on 32 nodes
- 20. NeON framework
- 21. Neon: DL Framework with Blazing Performance
- 22. Intel® Nervana™ Graph Compiler Intel® Nervana™ Graph Compiler: High-level execution graph for neural networks to enable
- 23. Intel® Nervana™ Graph Compiler as the performance building block… …to accelerate all the latest DL innovations
- 24. INTEL® DEEP Learning SDK
- 25. Increased Productivity Faster Time-to-market for training and inference, Improve model accuracy, Reduce total cost of ownership
- 26. Deep Learning Training Tool Intel® Deep Learning SDK Simplify installation of Intel optimized Deep Learning Frameworks
- 27. Deep Learning Deployment Tool Intel® Deep Learning SDK Unleash fast scoring performance on Intel products while
- 28. Deep Learning Tools for End-to-End Workflow Intel® Deep Learning SDK MKL-DNN Optimized Machine Learning Frameworks Intel
- 29. Leading AI research
- 30. Summary Intel provides highly optimized libraries to accelerate all DL frameworks Intel® Machine Learning Scaling Library
- 31. Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED “AS IS”. NO LICENSE, EXPRESS
- 33. Configuration details BASELINE: Caffe Out Of the Box, Intel® Xeon Phi™ processor 7250 (68 Cores, 1.4
- 34. Configuration details BASELINE: Intel® Xeon Phi™ Processor 7290 (16GB, 1.50 GHz, 72 core) with 192 GB
- 36. Скачать презентацию
Bigger Data
Better Hardware
Smarter Algorithms
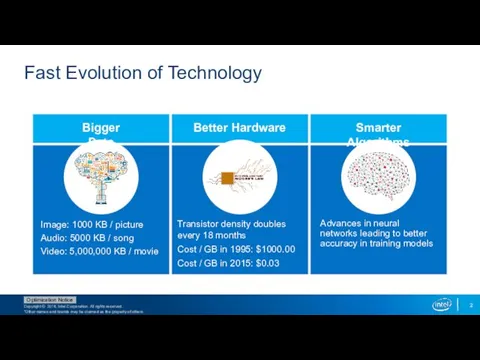
Fast Evolution of Technology
Image: 1000 KB / picture
Audio:
Bigger Data
Better Hardware
Smarter Algorithms
Fast Evolution of Technology
Image: 1000 KB / picture
Audio:

Classical Machine Learning
CLASSIFIER
SVM
Random Forest
Naïve Bayes
Decision Trees
Logistic Regression
Ensemble methods
Arjun
Classical Machine Learning
CLASSIFIER
SVM
Random Forest
Naïve Bayes
Decision Trees
Logistic Regression
Ensemble methods
Arjun

Deep learning
A method of extracting features at multiple levels
of abstraction
Features are
Deep learning
A method of extracting features at multiple levels
of abstraction
Features are
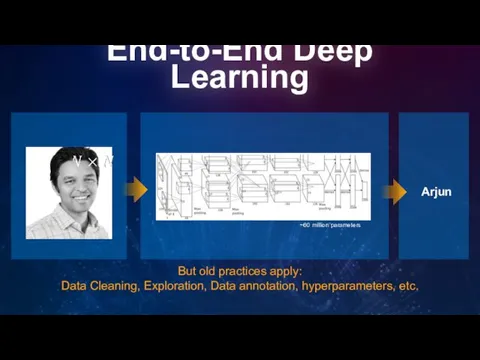
End-to-End Deep Learning
~60 million parameters
But old practices apply:
Data Cleaning, Exploration,
End-to-End Deep Learning
~60 million parameters
But old practices apply:
Data Cleaning, Exploration,

Automating previously “human” tasks
Human
Performance
2010
Present
ImageNet Error Rate
Using Deep Learning
2000
Present
Speech Error Rate
Automating previously “human” tasks
Human
Performance
2010
Present
ImageNet Error Rate
Using Deep Learning
2000
Present
Speech Error Rate

( 1 ) Large compute requirements for training
Deep Learning Challenges
( 1 ) Large compute requirements for training
Deep Learning Challenges

( 2 ) Performance scales with data
Deep Learning Challenges
( 2 ) Performance scales with data
Deep Learning Challenges
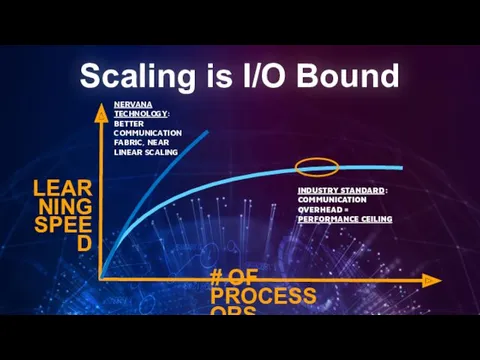
Scaling is I/O Bound
# OF PROCESSORS
LEARNING SPEED
INDUSTRY STANDARD: COMMUNICATION
Scaling is I/O Bound
# OF PROCESSORS
LEARNING SPEED
INDUSTRY STANDARD: COMMUNICATION
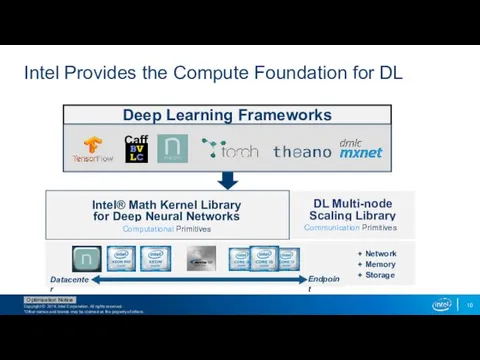
Intel Provides the Compute Foundation for DL
Deep Learning Frameworks
Intel Provides the Compute Foundation for DL
Deep Learning Frameworks

INTEL® MKL-DNN
INTEL® MKL-DNN
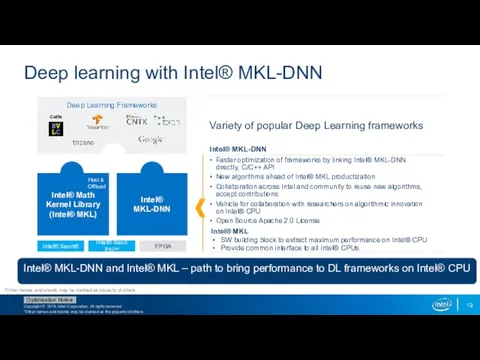
Deep learning with Intel® MKL-DNN
Intel® MKL
SW building block to extract
Deep learning with Intel® MKL-DNN
Intel® MKL
SW building block to extract

Deep learning with Intel® MKL-DNN
Intel® MKL-DNN
Tech preview, https://01.org/mkl-dnn
Demonstrates interfaces and the
Deep learning with Intel® MKL-DNN
Intel® MKL-DNN
Tech preview, https://01.org/mkl-dnn
Demonstrates interfaces and the

Deep learning with Intel® MKL-DNN
Intel® MKL-DNN Programming Model
Primitive – any operation
Deep learning with Intel® MKL-DNN
Intel® MKL-DNN Programming Model
Primitive – any operation
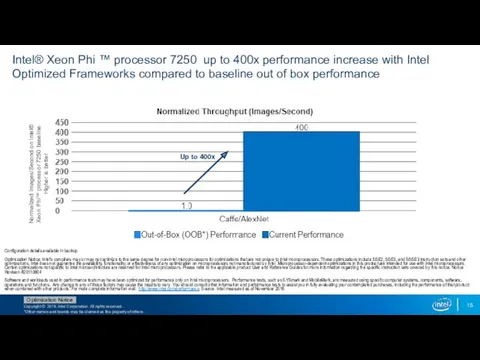
Intel® Xeon Phi ™ processor 7250 up to 400x performance increase
Intel® Xeon Phi ™ processor 7250 up to 400x performance increase
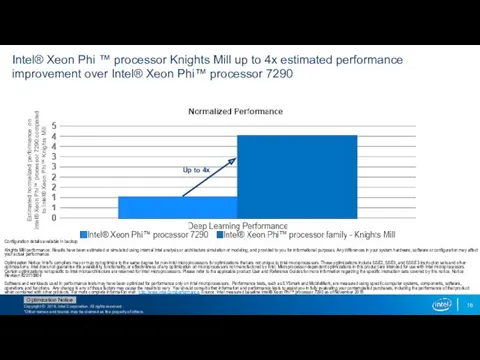
Intel® Xeon Phi ™ processor Knights Mill up to 4x estimated
Intel® Xeon Phi ™ processor Knights Mill up to 4x estimated

INTEL® Machine Learning Scaling Library
INTEL® Machine Learning Scaling Library

Intel® Machine Learning Scaling Library (MLSL)
Deep learning abstraction of message-passing implementations.
Built
Intel® Machine Learning Scaling Library (MLSL)
Deep learning abstraction of message-passing implementations.
Built
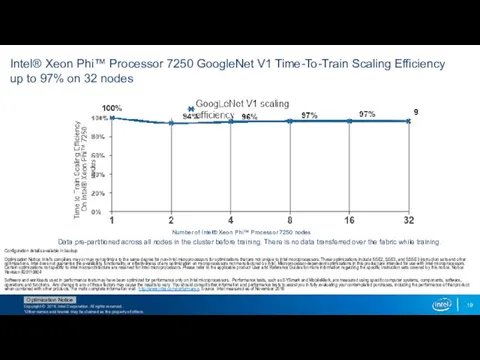
Intel® Xeon Phi™ Processor 7250 GoogleNet V1 Time-To-Train Scaling Efficiency up
Intel® Xeon Phi™ Processor 7250 GoogleNet V1 Time-To-Train Scaling Efficiency up

NeON framework
NeON framework
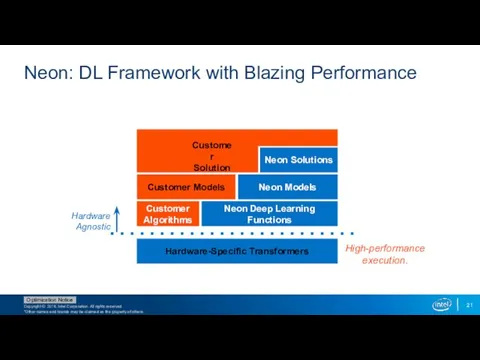
Neon: DL Framework with Blazing Performance
Neon: DL Framework with Blazing Performance
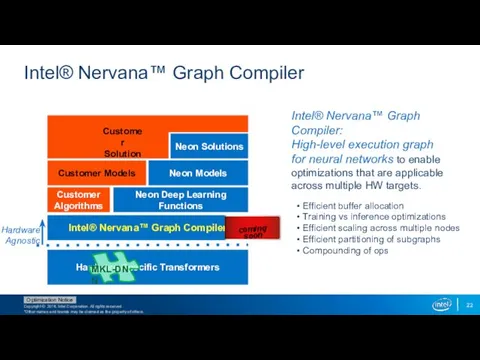
Intel® Nervana™ Graph Compiler
Intel® Nervana™ Graph Compiler:
High-level execution graph
for neural
Intel® Nervana™ Graph Compiler
Intel® Nervana™ Graph Compiler: High-level execution graph for neural

Intel® Nervana™ Graph Compiler as the performance building block…
…to accelerate
Intel® Nervana™ Graph Compiler as the performance building block…
…to accelerate

INTEL® DEEP Learning SDK
INTEL® DEEP Learning SDK

Increased Productivity
Faster Time-to-market for training and inference,
Improve model accuracy,
Reduce total
Increased Productivity
Faster Time-to-market for training and inference,
Improve model accuracy,
Reduce total
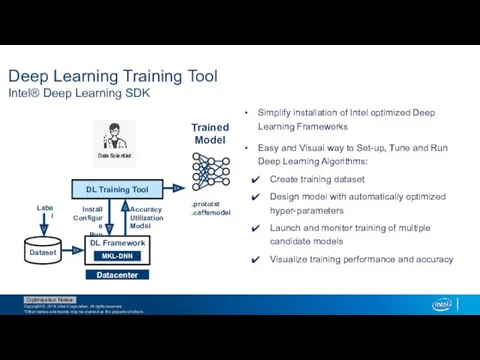
Deep Learning Training Tool
Intel® Deep Learning SDK
Simplify installation of Intel optimized
Deep Learning Training Tool
Intel® Deep Learning SDK
Simplify installation of Intel optimized
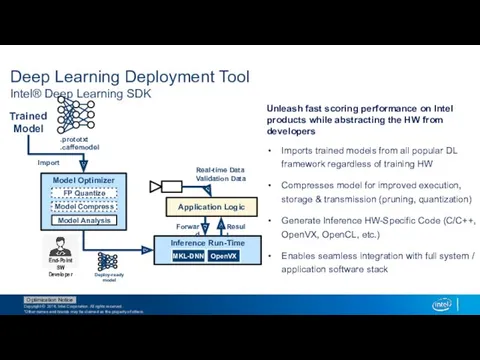
Deep Learning Deployment Tool
Intel® Deep Learning SDK
Unleash fast scoring performance on
Deep Learning Deployment Tool
Intel® Deep Learning SDK
Unleash fast scoring performance on
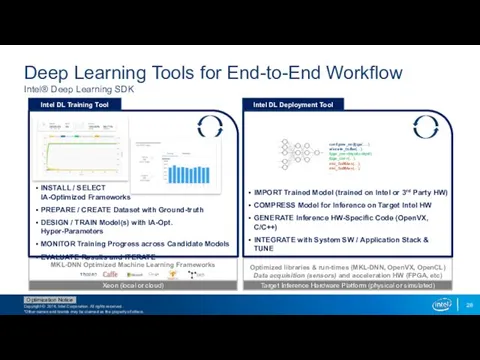
Deep Learning Tools for End-to-End Workflow
Intel® Deep Learning SDK
MKL-DNN Optimized Machine
Deep Learning Tools for End-to-End Workflow
Intel® Deep Learning SDK
MKL-DNN Optimized Machine

Leading AI research
Leading AI research

Summary
Intel provides highly optimized libraries to accelerate all DL frameworks
Intel® Machine
Summary
Intel provides highly optimized libraries to accelerate all DL frameworks
Intel® Machine

Legal Disclaimer & Optimization Notice
INFORMATION IN THIS DOCUMENT IS PROVIDED “AS
Legal Disclaimer & Optimization Notice
INFORMATION IN THIS DOCUMENT IS PROVIDED “AS


Configuration details
BASELINE: Caffe Out Of the Box, Intel® Xeon Phi™ processor
Configuration details
BASELINE: Caffe Out Of the Box, Intel® Xeon Phi™ processor
Configuration details
BASELINE: Intel® Xeon Phi™ Processor 7290 (16GB, 1.50 GHz, 72
Configuration details
BASELINE: Intel® Xeon Phi™ Processor 7290 (16GB, 1.50 GHz, 72
 Работа с файлами в Си-шарп
Работа с файлами в Си-шарп Support Desk Technologies. Общение в чатах
Support Desk Technologies. Общение в чатах Конструктор проекта. Социальный проект Кампус общественных объединений Ставропольского края
Конструктор проекта. Социальный проект Кампус общественных объединений Ставропольского края Алгоритми роботи з об’єктами та величинами. (8 клас)
Алгоритми роботи з об’єктами та величинами. (8 клас) Понятие формы. Элементы управления
Понятие формы. Элементы управления Применение ИКТ в преподавании истории и обществознания. Теория и практика
Применение ИКТ в преподавании истории и обществознания. Теория и практика Табличные информационные модели. Вычислительные таблицы
Табличные информационные модели. Вычислительные таблицы Разработка АРМ менеджера оконного комбината на примере ООО Светоч в среде Delphi 6.0
Разработка АРМ менеджера оконного комбината на примере ООО Светоч в среде Delphi 6.0 Лабораторная работа № 2. Программы с простейшей структурой
Лабораторная работа № 2. Программы с простейшей структурой Информация и измерение информации
Информация и измерение информации презентация по информатике Кодирование числовой информации
презентация по информатике Кодирование числовой информации Состав и структура, функциональные и обеспечивающие подсистемы, жизненный цикл КИС
Состав и структура, функциональные и обеспечивающие подсистемы, жизненный цикл КИС Я, студент. План - проект журналу
Я, студент. План - проект журналу Работа со временем pulsein(), millis(), micros(), delay(), delaymicroseconds()
Работа со временем pulsein(), millis(), micros(), delay(), delaymicroseconds() Носители информации
Носители информации Современная структура и динамика медиасистемы
Современная структура и динамика медиасистемы Основы HTML. Создание сайтов в текстовом редакторе
Основы HTML. Создание сайтов в текстовом редакторе Обзор инструментов обработки Big Data
Обзор инструментов обработки Big Data Разработка информационной системы ООО LITTLE CO
Разработка информационной системы ООО LITTLE CO Буква - строка - текст. Искусство шрифта
Буква - строка - текст. Искусство шрифта Connected Equipment Pack. Настройки тренировки: Оборудование, упражнения и занятия
Connected Equipment Pack. Настройки тренировки: Оборудование, упражнения и занятия Управление процессами. Системы управления
Управление процессами. Системы управления Введение в конфигурирование в системе 1С:Предприятие 8.2 Основные объекты
Введение в конфигурирование в системе 1С:Предприятие 8.2 Основные объекты Компьютерлік желі
Компьютерлік желі ВКонтакте
ВКонтакте SAP CRM Система Управление взаимоотношениями с клиентами
SAP CRM Система Управление взаимоотношениями с клиентами Измерение информации. Семантический подход к измерению количества информации
Измерение информации. Семантический подход к измерению количества информации Презентация: Внешняя память. Средства хранения информации
Презентация: Внешняя память. Средства хранения информации