- Хранение и предварительная обработка больших наборов данных с помощью Tensor Flow

Содержание
- 2. План занятия Что такое big data? Примеры информационных систем построенных на Big Data Архитектура информационных систем
- 3. Большие данные вокруг нас
- 4. 1. Что такое Большие данные (Big Data)?
- 5. Большие данные вокруг нас Когда данные информационной системы становятся большими? Чем отличается обработка больших данных? Почему
- 6. ВАЖНО! Big Data (Большие данные ) – это данные характеризуемые несколькими особенностей: Объём (Volume); Поступление и
- 7. Big data : объём данных (Volume) Объём данных в абсолютных значениях сильно зависит от времени и
- 8. Обратите внимание! Big data : объём данных (Volume) Но так ли важен объём? С ростом объёма
- 9. Big data : Поступление и обработка новых данных (Velocity) Переход от носителей к центрам обработки данных
- 10. Big data : Разнородность данных (Variety) Разнородность данных (Variety) подразумевает формат и комплексность данных. Данные могут
- 11. Большие данные: Ценность и достоверность (Value and Veracity) Как правило, под достоверностью принято понимать правдивость набора
- 12. 1. Когда данные информационной системы становятся большими? 2. Чем отличается обработка больших данных? 3. Почему Big
- 13. 2. Примеры систем основанных на больших данных
- 14. Какие системы основаны на Big Data? Можно ли считать любую автоматизированную информационную систему, системой работающей с
- 15. Автоматизированные информационные системы, которые основаны на больших данных
- 16. Big data в цифровом контенте: Netflix Компания Netflix использует большие данные для прогнозирования потребительского спроса при
- 17. Big data в цифровом контенте: Netflix
- 18. Big data в банковском секторе: Сбербанк "Количество платежей по банковским картам уже превышает 1 миллиард операций
- 19. Big data в банковском секторе: Сбербанк А на сколько просто собрать подобного рода статистику по данным
- 20. Данные о геноме человека Стоимость секвенирования человеческого генома по логарифмической шкале. Резкий скачок графика стоимости вниз
- 21. Данные о геноме человека Исследования генома совершило революцию в медицинских услугах. Обработка данных генома становится крайне
- 22. Другие применения больших данных
- 23. Для каких ИС большие данные имеют смысл? Технологии больших данных дают максимальную эффективность в случае, если
- 24. Основные задачи, решаемые при помощи больших данных Технологические Распределенное хранение данных (данных которые не могут храниться
- 25. 1.Приведите основные отличительные особенности систем в которых предпочтительно использовать технологии больших данных? 2. Приведите 5 своих
- 26. 3. Архитектура информационных систем обрабатывающих большие данные
- 27. Архитектура информационных систем построенных на Big Data Что такое распределенная информационная система? Чем отличаются распределенные информационные
- 28. Данные в информационных системах К сожалению часто данные в информационных системах имеют низкий уровень структурированности/упорядоченности/обработки. Данные
- 29. Apache Hadoop Apache Hadoop – это развивающаяся платформа с открытым исходным кодом (open-source software) обеспечивающий надёжность,
- 30. Классическая Client-Server архитектура
- 31. Архитектура HDFS Репликация по - умолчанию на 3 узла Ведомые узлы (slaves Datanodes) Блоки Ведущий узел
- 32. Архитектура HDFS Описание архитектуры HDFS Apache Hadoop основана на архитектуре ведущий-ведомый (master-slave). Каждый кластер HDFS содержит
- 33. Архитектура HDFS Отказоустойчивость архитектуры HDFS В случае падения одного из DataNode, блок документа загружается из другого
- 34. Apache Hadoop решения и аналоги Apache Spark - это единый аналитический движок (программный продукт) обработки больших
- 35. 1. Что такое принцип ведущий-ведомый(master-slave)? 2.Что такое HDFS? 3. Что используется в качестве единицы информации в
- 36. 4. Алгоритмы обработки больших данных
- 37. А как использовать преимущества больших данных? Эволюция средств хранения, обработки и использования данных безусловно улучшает качество
- 38. Программное обеспечение для обработки больших данных Если учесть, что большие данные хранятся в распределенных системах, то
- 39. Программное обеспечение для обработки больших данных MapReduce – определяет процесс обработки данных который делится на 3
- 40. Схема работы принципа MapReduce MapReduce – определяет процесс обработки данных который делится на 3 ключевые операции:
- 41. Программное обеспечение для обработки больших данных В общем виде как часто бывает операции подхода MapReduce выглядят
- 42. Программное обеспечение для обработки больших данных В общем виде как часто бывает операции подхода MapReduce выглядят
- 43. Программное обеспечение для обработки больших данных В общем виде как часто бывает операции подхода MapReduce выглядят
- 44. Программное обеспечение для обработки больших данных Звучит как очень сложное решение для простой задачи. Но такова
- 45. 1. Какие 3 операции входят в принцип MapReduce? 2.Почему нельзя использовать SQL-запрос для получения агрегированных показателей
- 46. 5. Использование языка Python в обработке больших данных
- 47. Библиотеки языка Python Именно с изучения «питона» начинают свой путь в программировании начинающие пользователи, а профессионалы
- 48. Pandas - библиотека для обработки и анализа данных. Она предоставляет структуры данных, такие как DataFrame и
- 49. Matplotlib - библиотека для создания различных видов графиков и визуализации данных в Python. Она предоставляет широкий
- 50. NumPy - библиотека для работы с массивами и матрицами, предоставляя высокоэффективные операции над ними. Она является
- 51. SciPy - библиотека для выполнения научных и технических вычислений в Python. Она предоставляет функционал поверх NumPy,
- 52. Фреймворк TensorFlow представляет собой инструмент относительно легкого уровня сложности, который обеспечивает быстрое создание нейронных сетей различных
- 53. Задача: построить нейронную сеть, которая будет по картинке классифицировать цифру Создание простой нейронной сети
- 54. Шаг 1 – импортирование библиотеки TensorFlow Создание простой нейронной сети
- 55. Шаг 2 – загрузка набора данных для обучения и тестирования Исходные данные: база данных MNIST —
- 56. Шаг 3 – построение модели и определение архитектуры нейронной сети Создание простой нейронной сети
- 57. Шаг 4 – компиляция модели и выбор функции потерь, оптимизатор и метрики Создание простой нейронной сети
- 58. Шаг 5 – обучение модели, загружаем данные в модель и проводим обучение Создание простой нейронной сети
- 59. Шаг 6 – оценка модели Создание простой нейронной сети
- 60. Создание простой нейронной сети Итогом является модель нейронной сети, которая может определить рукописную цифру с точностью
- 61. Самостоятельная работа В рамках выполнения первого задания для слушателей без активных навыков разработки программного обеспечения. Необходимо
- 62. Если навыков разработки программного обеспечения нет. 1.1 Задача сформировать понимание работы распределенных вычислений. Необходимо выполнить групповое
- 63. 1. Документация Apache Hadoop - https://hadoop.apache.org/docs/stable/ 2. Видео материалы по работе архитектуры HDFS - https://www.youtube.com/c/DataflairWS/videos (English)
- 64. 8. Язык программирования Python - https://www.python.org/ 9. Библиотека Pandas - https://pandas.pydata.org/ 10. Библиотека Matplotlib - https://matplotlib.org/
- 66. Скачать презентацию
План занятия
Что такое big data?
Примеры информационных систем построенных на Big Data
Архитектура
План занятия
Что такое big data?
Примеры информационных систем построенных на Big Data
Архитектура

Большие данные вокруг нас
Большие данные вокруг нас

1. Что такое Большие данные (Big Data)?
1. Что такое Большие данные (Big Data)?

Большие данные вокруг нас
Когда данные информационной системы становятся большими?
Чем отличается обработка
Большие данные вокруг нас
Когда данные информационной системы становятся большими?
Чем отличается обработка

ВАЖНО!
Big Data (Большие данные ) – это данные характеризуемые несколькими особенностей:
Объём
ВАЖНО!
Big Data (Большие данные ) – это данные характеризуемые несколькими особенностей:
Объём

Big data : объём данных (Volume)
Объём данных в абсолютных значениях сильно
Big data : объём данных (Volume)
Объём данных в абсолютных значениях сильно

Обратите внимание!
Big data : объём данных (Volume)
Но так ли важен объём?
С
Обратите внимание!
Big data : объём данных (Volume)
Но так ли важен объём?
С

Big data : Поступление и обработка новых данных (Velocity)
Переход от носителей
Big data : Поступление и обработка новых данных (Velocity)
Переход от носителей

Big data : Разнородность данных (Variety)
Разнородность данных (Variety) подразумевает формат и
Big data : Разнородность данных (Variety)
Разнородность данных (Variety) подразумевает формат и

Большие данные: Ценность и достоверность (Value and Veracity)
Как правило, под достоверностью
Большие данные: Ценность и достоверность (Value and Veracity)
Как правило, под достоверностью

1. Когда данные информационной системы становятся большими?
2. Чем отличается обработка больших
1. Когда данные информационной системы становятся большими?
2. Чем отличается обработка больших

2. Примеры систем основанных на больших данных
2. Примеры систем основанных на больших данных

Какие системы основаны на Big Data?
Можно ли считать любую автоматизированную информационную
Какие системы основаны на Big Data?
Можно ли считать любую автоматизированную информационную
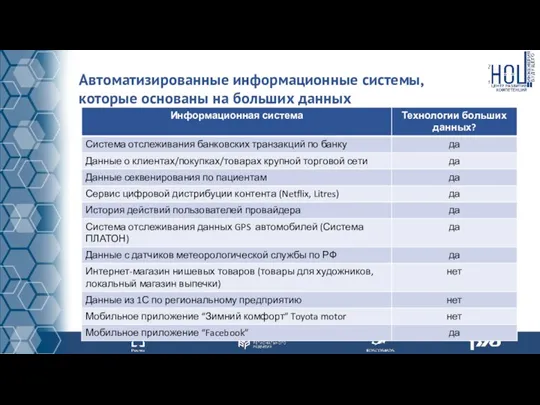
Автоматизированные информационные системы, которые основаны на больших данных
Автоматизированные информационные системы, которые основаны на больших данных

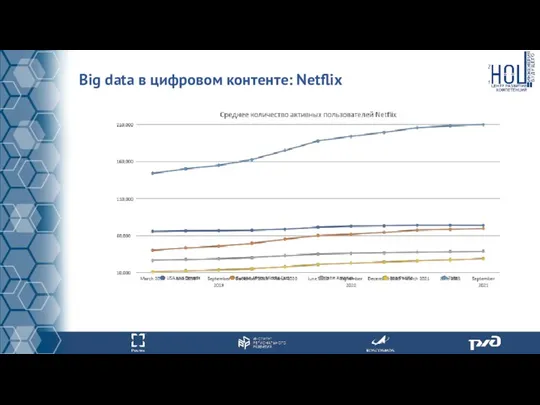
Big data в цифровом контенте: Netflix
Компания Netflix использует большие данные для
Big data в цифровом контенте: Netflix
Компания Netflix использует большие данные для
Big data в цифровом контенте: Netflix
Big data в цифровом контенте: Netflix

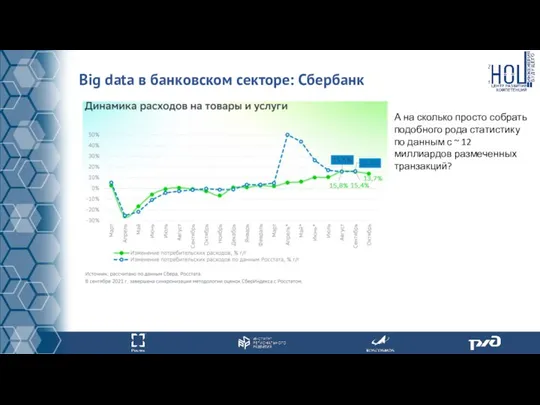
Big data в банковском секторе: Сбербанк
"Количество платежей по банковским картам уже превышает
Big data в банковском секторе: Сбербанк
"Количество платежей по банковским картам уже превышает
Big data в банковском секторе: Сбербанк
А на сколько просто собрать подобного
Big data в банковском секторе: Сбербанк
А на сколько просто собрать подобного
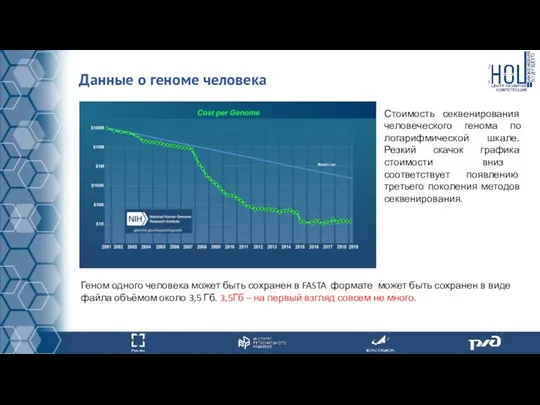
Данные о геноме человека
Стоимость секвенирования человеческого генома по логарифмической шкале. Резкий
Данные о геноме человека
Стоимость секвенирования человеческого генома по логарифмической шкале. Резкий

Данные о геноме человека
Исследования генома совершило революцию в медицинских услугах. Обработка
Данные о геноме человека
Исследования генома совершило революцию в медицинских услугах. Обработка

Другие применения больших данных
Другие применения больших данных

Для каких ИС большие данные имеют смысл?
Технологии больших данных дают
Для каких ИС большие данные имеют смысл?
Технологии больших данных дают

Основные задачи, решаемые при помощи больших данных
Технологические
Распределенное хранение данных (данных
Основные задачи, решаемые при помощи больших данных
Технологические
Распределенное хранение данных (данных

1.Приведите основные отличительные особенности систем в которых предпочтительно использовать технологии больших
1.Приведите основные отличительные особенности систем в которых предпочтительно использовать технологии больших

3. Архитектура информационных систем обрабатывающих
большие данные
3. Архитектура информационных систем обрабатывающих
большие данные

Архитектура информационных систем построенных на Big Data
Что такое распределенная информационная система?
Чем
Архитектура информационных систем построенных на Big Data
Что такое распределенная информационная система?
Чем

Данные в информационных системах
К сожалению часто данные в информационных системах имеют
Данные в информационных системах
К сожалению часто данные в информационных системах имеют

Apache Hadoop
Apache Hadoop – это развивающаяся платформа с открытым исходным кодом
Apache Hadoop
Apache Hadoop – это развивающаяся платформа с открытым исходным кодом
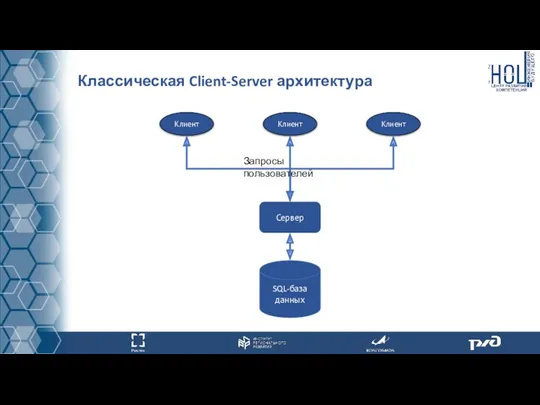
Классическая Client-Server архитектура
Классическая Client-Server архитектура
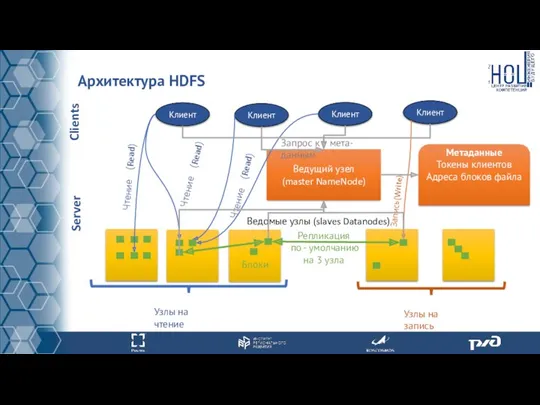
Архитектура HDFS
Репликация
по - умолчанию
на 3 узла
Ведомые узлы (slaves Datanodes)
Блоки
Ведущий узел
Архитектура HDFS
Репликация
по - умолчанию
на 3 узла
Ведомые узлы (slaves Datanodes)
Блоки
Ведущий узел

Архитектура HDFS
Описание архитектуры HDFS
Apache Hadoop основана на архитектуре ведущий-ведомый (master-slave). Каждый
Архитектура HDFS
Описание архитектуры HDFS
Apache Hadoop основана на архитектуре ведущий-ведомый (master-slave). Каждый

Архитектура HDFS
Отказоустойчивость архитектуры HDFS
В случае падения одного из DataNode, блок документа
Архитектура HDFS
Отказоустойчивость архитектуры HDFS
В случае падения одного из DataNode, блок документа

Apache Hadoop решения и аналоги
Apache Spark - это единый аналитический движок
Apache Hadoop решения и аналоги
Apache Spark - это единый аналитический движок

1. Что такое принцип ведущий-ведомый(master-slave)?
2.Что такое HDFS?
3. Что используется в
1. Что такое принцип ведущий-ведомый(master-slave)?
2.Что такое HDFS?
3. Что используется в

4. Алгоритмы обработки больших данных
4. Алгоритмы обработки больших данных
А как использовать преимущества больших данных?
Эволюция средств хранения, обработки и
А как использовать преимущества больших данных?
Эволюция средств хранения, обработки и

Программное обеспечение для обработки больших данных
Если учесть, что большие данные хранятся
Программное обеспечение для обработки больших данных
Если учесть, что большие данные хранятся

Программное обеспечение для обработки больших данных
MapReduce – определяет процесс обработки данных
Программное обеспечение для обработки больших данных
MapReduce – определяет процесс обработки данных
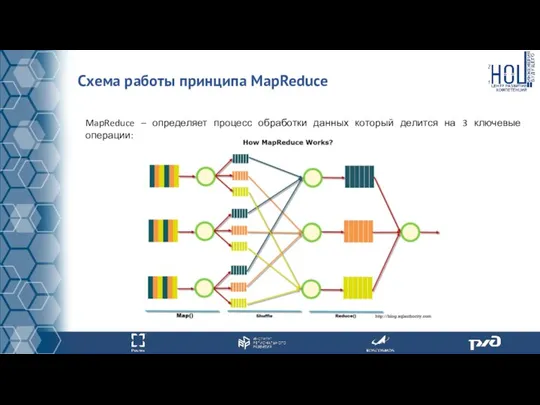
Схема работы принципа MapReduce
MapReduce – определяет процесс обработки данных который делится
Схема работы принципа MapReduce
MapReduce – определяет процесс обработки данных который делится

Программное обеспечение для обработки больших данных
В общем виде как часто бывает
Программное обеспечение для обработки больших данных
В общем виде как часто бывает

Программное обеспечение для обработки больших данных
В общем виде как часто бывает
Программное обеспечение для обработки больших данных
В общем виде как часто бывает

Программное обеспечение для обработки больших данных
В общем виде как часто бывает
Программное обеспечение для обработки больших данных
В общем виде как часто бывает

Программное обеспечение для обработки больших данных
Звучит как очень сложное решение для
Программное обеспечение для обработки больших данных
Звучит как очень сложное решение для

1. Какие 3 операции входят в принцип MapReduce?
2.Почему нельзя использовать SQL-запрос
1. Какие 3 операции входят в принцип MapReduce?
2.Почему нельзя использовать SQL-запрос

5. Использование языка Python в обработке больших данных
5. Использование языка Python в обработке больших данных

Библиотеки языка Python
Именно с изучения «питона» начинают свой путь в программировании начинающие пользователи,
Библиотеки языка Python
Именно с изучения «питона» начинают свой путь в программировании начинающие пользователи,

Pandas - библиотека для обработки и анализа данных. Она предоставляет структуры
Pandas - библиотека для обработки и анализа данных. Она предоставляет структуры

Matplotlib - библиотека для создания различных видов графиков и визуализации данных
Matplotlib - библиотека для создания различных видов графиков и визуализации данных

NumPy - библиотека для работы с массивами и матрицами, предоставляя высокоэффективные
NumPy - библиотека для работы с массивами и матрицами, предоставляя высокоэффективные

SciPy - библиотека для выполнения научных и технических вычислений в Python.
SciPy - библиотека для выполнения научных и технических вычислений в Python.

Фреймворк TensorFlow представляет собой инструмент относительно легкого уровня сложности, который обеспечивает
Фреймворк TensorFlow представляет собой инструмент относительно легкого уровня сложности, который обеспечивает
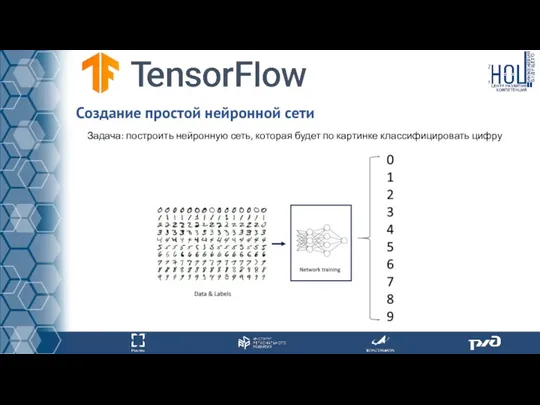
Задача: построить нейронную сеть, которая будет по картинке классифицировать цифру
Создание простой
Задача: построить нейронную сеть, которая будет по картинке классифицировать цифру
Создание простой
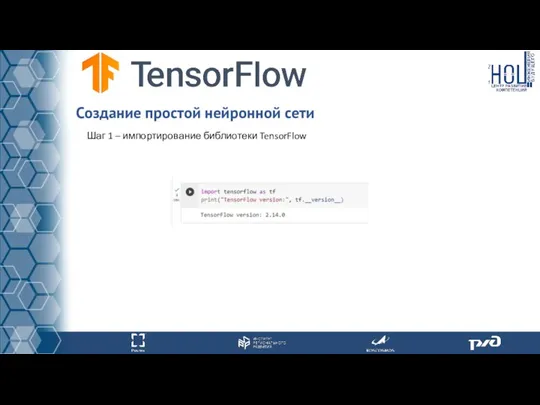
Шаг 1 – импортирование библиотеки TensorFlow
Создание простой нейронной сети
Шаг 1 – импортирование библиотеки TensorFlow
Создание простой нейронной сети
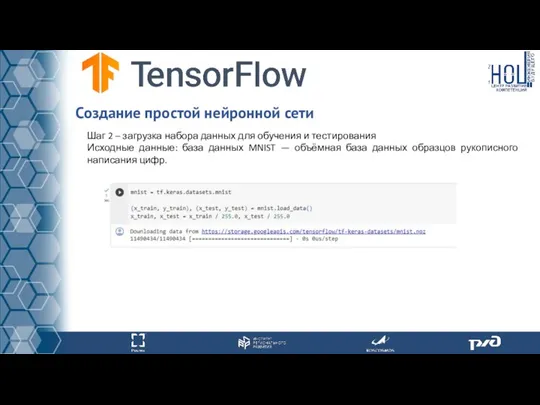
Шаг 2 – загрузка набора данных для обучения и тестирования
Исходные данные:
Шаг 2 – загрузка набора данных для обучения и тестирования
Исходные данные:

Шаг 3 – построение модели и определение архитектуры нейронной сети
Создание простой
Шаг 3 – построение модели и определение архитектуры нейронной сети
Создание простой
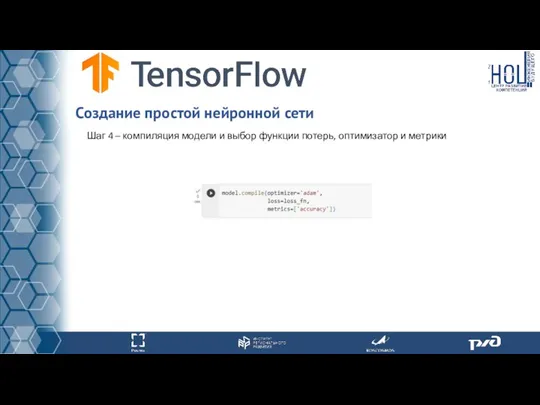
Шаг 4 – компиляция модели и выбор функции потерь, оптимизатор и
Шаг 4 – компиляция модели и выбор функции потерь, оптимизатор и

Шаг 5 – обучение модели, загружаем данные в модель и проводим
Шаг 5 – обучение модели, загружаем данные в модель и проводим
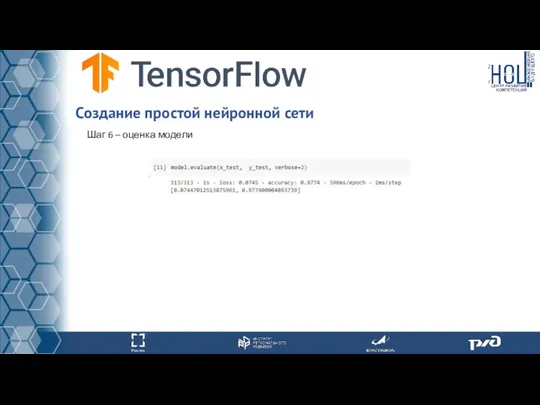
Шаг 6 – оценка модели
Создание простой нейронной сети
Шаг 6 – оценка модели
Создание простой нейронной сети

Создание простой нейронной сети
Итогом является модель нейронной сети, которая может определить
Создание простой нейронной сети
Итогом является модель нейронной сети, которая может определить
Самостоятельная работа
В рамках выполнения первого задания для слушателей без активных навыков
Самостоятельная работа
В рамках выполнения первого задания для слушателей без активных навыков

Если навыков разработки программного обеспечения нет.
1.1 Задача сформировать понимание работы распределенных
Если навыков разработки программного обеспечения нет.
1.1 Задача сформировать понимание работы распределенных

1. Документация Apache Hadoop - https://hadoop.apache.org/docs/stable/
2. Видео материалы по работе архитектуры
1. Документация Apache Hadoop - https://hadoop.apache.org/docs/stable/
2. Видео материалы по работе архитектуры

8. Язык программирования Python - https://www.python.org/
9. Библиотека Pandas - https://pandas.pydata.org/
10. Библиотека
8. Язык программирования Python - https://www.python.org/
9. Библиотека Pandas - https://pandas.pydata.org/
10. Библиотека
 Социализация сети интернет
Социализация сети интернет Визуализация. Лекция 1
Визуализация. Лекция 1 Курс ЧПУ. Геометрические ядра CAD-систем. Обменные форматы между CAD и CAM системами
Курс ЧПУ. Геометрические ядра CAD-систем. Обменные форматы между CAD и CAM системами Почему люди идут на работу в интернет
Почему люди идут на работу в интернет Как сочинять газетные заголовки и писать лиды
Как сочинять газетные заголовки и писать лиды Java. Введение. Лекция 1.1
Java. Введение. Лекция 1.1 Правила набора, форматирования текста и верстки. Методическое пособие
Правила набора, форматирования текста и верстки. Методическое пособие Order of placing an order
Order of placing an order Особенности оформления учебной компьютерной презентации
Особенности оформления учебной компьютерной презентации Практическая работа Устройства компьютера. Адрес клетки
Практическая работа Устройства компьютера. Адрес клетки Программирование разветвляющихся алгоритмов
Программирование разветвляющихся алгоритмов Информатика. Отчет по лабораторным работам за семестр
Информатика. Отчет по лабораторным работам за семестр Состав объектов
Состав объектов Основы информатики и компьютерный практикум. ОС Windows. Текстовый процессор Word
Основы информатики и компьютерный практикум. ОС Windows. Текстовый процессор Word Техническая система. Лекция 4
Техническая система. Лекция 4 Faylovaya_struktura
Faylovaya_struktura Организация специального технического обеспечения действий и применения ГИК. Лекция №08
Организация специального технического обеспечения действий и применения ГИК. Лекция №08 Назначение и возможности языка PHP. Переменные, константы и типы данных РНР. Лекция №1
Назначение и возможности языка PHP. Переменные, константы и типы данных РНР. Лекция №1 Массивы и структуры в MASM
Массивы и структуры в MASM Элементы теории алгоритмов
Элементы теории алгоритмов AVL trees. (Lecture 8)
AVL trees. (Lecture 8) Базы данных
Базы данных Анализ вечернего выпуска новостей
Анализ вечернего выпуска новостей Урок информатики по теме Моделирование геометрических объектов в программе QCAD (9 класс)
Урок информатики по теме Моделирование геометрических объектов в программе QCAD (9 класс) Sony Bravia R5. Инструкция по настройке Fork плеера
Sony Bravia R5. Инструкция по настройке Fork плеера Применение методов машинного обучения в обработке больших данных
Применение методов машинного обучения в обработке больших данных Складання та виконання лінійних алгоритмів опрацювання величин в навчальному середовищі програмування. Урок 31
Складання та виконання лінійних алгоритмів опрацювання величин в навчальному середовищі програмування. Урок 31 Сценарии в HTML, язык JavaScript
Сценарии в HTML, язык JavaScript