- Implementing ETL with SQL Server Integration Services

Содержание
- 2. •Please turn off the microphone. •If you have questions, ask them in the chat. •Duration: 3
- 3. Agenda ETL PROCESSING 2. ETL PROCESSING WITH SSIS 3. SSIS DATA FLOWS 4. DEPLOYMENT AND TROUBLESHOOTING
- 4. WHAT YOU WILL LEARN Creating an ETL script The design environment Control flows Data sources Data
- 5. Setting Up Your Environment SQL SERVER DATA ENGINE(FREE DEVELOPER EDITION): HTTPS://WWW.MICROSOFT.COM/EN-US/SQL-SERVER/SQL-SERVER-DOWNLOADS SQL SERVER MANAGEMENT STUDIO(SSMS 18.8)
- 6. 1. ETL PROCESSING
- 7. ETL process in typical BI Solution
- 8. ETL is a type of data integration that refers to the three steps (extract, transform, load)
- 9. Why ETL is Important Businesses have relied on the ETL process for many years to get
- 10. DEMO 1. ETL with SCRIPTING
- 11. ETL Tools SQL Server Management Studio SSMS is not designed specifically as a ETL processing application,
- 12. Data Sources and Destinations Files In order for a SSIS package to perform ETL Processing, you
- 13. 2. ETL PROCESSING WITH SSIS
- 14. DEMO 2. SSIS OVERVIEW
- 15. Creating SSIS Project and Packages The Integration Services Project template uses one starter SSIS package that
- 16. The Control Flow Tab The control flow is created by dragging sequence containers and control flow
- 17. The Data Flow Tab Data flows are the only task that have their own tab. Data
- 18. Sequence Containers and Precedent Constraints Sequence Containers are used to group control flow tasks into a
- 19. SSIS Connections Connections are added from the Connection Manager’s Tray. The three most frequently used are
- 20. Configuring Execute SQL Tasks Execute SQL task allows you to run SQL code or stored procedures
- 21. Using Stored Procedures from SSIS When using stored procedures in SSIS you will need to consider
- 22. DEMO 3. Control flows and Data flows. Containers and Precedence constraints Connection Manager. Execute stored procedure
- 23. 3. SSIS DATA FLOWS
- 24. Creating Data Flows Data flows, as the name implies, is an SSIS task in which data
- 25. The OLE DB (Source) Connection Manager Page To use a Data Flow, you will need one
- 26. Data Access Mode Data access mode has the following four options: Table or view: allows you
- 27. Data Flow Paths Data flow paths are represented as arrows. Once the source has been configured,
- 28. Data Destinations You must have an un-configured destination on the designer surface before you can connect
- 29. The (Destination) Connection Manager Page On the Connection Manager page of the Destination Editor, you can
- 30. The Mappings Page The Mappings page allows you to map input columns to destination output columns.
- 31. The (Source and Destination) Error Output Page Errors can be redirected to a separate error output
- 32. Error Flows The Error Output arrow is red. To add an Error Output, begin by adding
- 33. DEMO 4. DATA FLOWS OWERVIEW. DATA FLOW SOURCE. DATA FLOW PATH
- 34. Data Flow Transformations Transformations are the third and final component to consider when working with data
- 35. DEMO 5. Sort, Data conversion, Derived Column.
- 36. Tuning Data Sources SSIS is a powerful tool that can perform many different tasks, but that
- 37. Staging Tables One common part of ETL processing is importing data from text files This can
- 38. 4. DEPLOYMENT AND TROUBLESHOOTING
- 39. Troubleshooting Errors Good ETL creation includes error handling and troubleshooting. Microsoft includes a number of features
- 40. Handling Data Flow Errors with Error Paths Error paths are represented as red connecting lines between
- 41. Troubleshooting Data Flow Issues with Data Viewers Using an Error path to insert errored rows in
- 42. Event Handlers Control flows do not have error paths or data viewers for debugging problems. They
- 43. Logging SSIS Packages SSIS includes an logging feature used to track events on packages, containers, and
- 44. Configuring a Log Provider To configure a Log Provider, you can begin by adding a provider
- 45. Deploying the SSIS Package right-click on the project and select Deploy. start the SSIS deployment wizard
- 46. ETL Automation using SSIS Jobs Normally you will schedule packages so your ETL can run in
- 47. DEMO 6. Troubleshooting and error handling.
- 48. Hometask
- 50. Скачать презентацию

•Please turn off the microphone.
•If you have questions, ask them
•Please turn off the microphone.
•If you have questions, ask them

Agenda
ETL PROCESSING
2. ETL PROCESSING WITH SSIS
3. SSIS DATA FLOWS
4. DEPLOYMENT
Agenda
ETL PROCESSING
2. ETL PROCESSING WITH SSIS
3. SSIS DATA FLOWS
4. DEPLOYMENT

WHAT YOU WILL LEARN
Creating an ETL script
The design environment
Control
Creating an ETL script
The design environment
Control
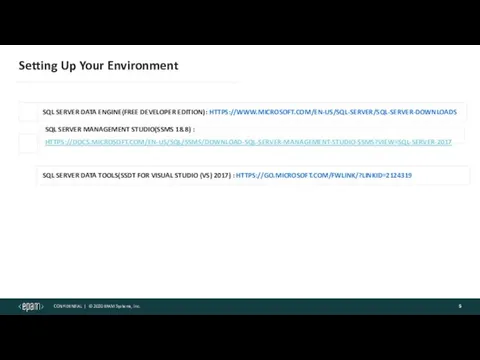
Setting Up Your Environment
SQL SERVER DATA ENGINE(FREE DEVELOPER EDITION): HTTPS://WWW.MICROSOFT.COM/EN-US/SQL-SERVER/SQL-SERVER-DOWNLOADS
SQL SERVER
Setting Up Your Environment
SQL SERVER DATA ENGINE(FREE DEVELOPER EDITION): HTTPS://WWW.MICROSOFT.COM/EN-US/SQL-SERVER/SQL-SERVER-DOWNLOADS
SQL SERVER

1. ETL PROCESSING
1. ETL PROCESSING
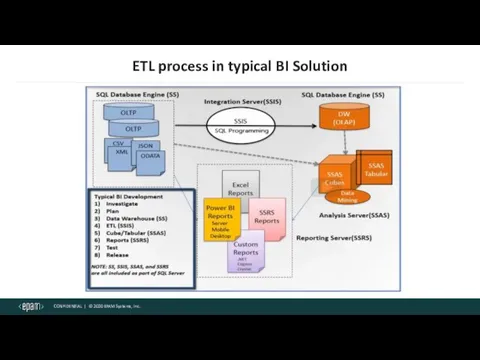
ETL process in typical BI Solution
ETL process in typical BI Solution

ETL is a type of data integration that refers to the
ETL is a type of data integration that refers to the

Why ETL is Important
Businesses have relied on the ETL process for
Why ETL is Important Businesses have relied on the ETL process for

DEMO 1.
ETL with SCRIPTING
DEMO 1.
ETL with SCRIPTING

ETL Tools
SQL Server Management Studio
SSMS is not designed specifically as a
ETL Tools
SQL Server Management Studio
SSMS is not designed specifically as a

Data Sources and Destinations Files
In order for a SSIS package to
Data Sources and Destinations Files
In order for a SSIS package to

2. ETL PROCESSING WITH SSIS
2. ETL PROCESSING WITH SSIS

DEMO 2.
SSIS OVERVIEW
DEMO 2.
SSIS OVERVIEW
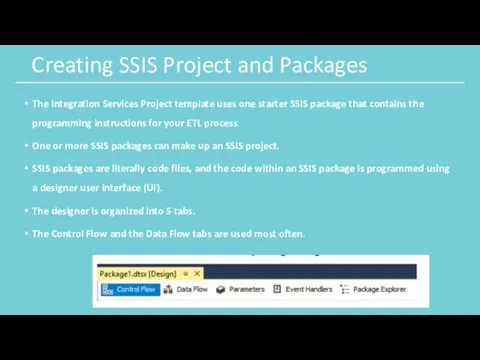
Creating SSIS Project and Packages
The Integration Services Project template uses one
Creating SSIS Project and Packages
The Integration Services Project template uses one
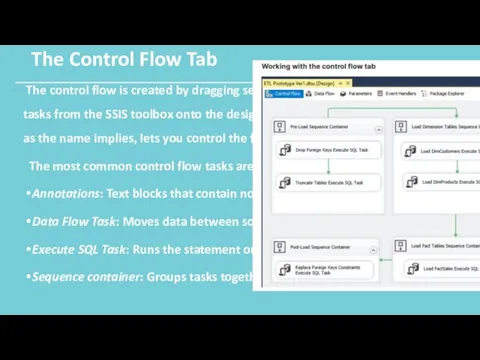
The Control Flow Tab
The control flow is created by dragging
The Control Flow Tab
The control flow is created by dragging
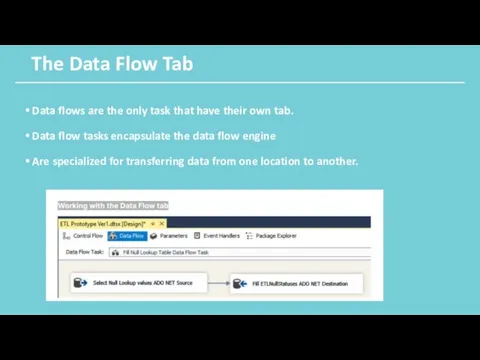
The Data Flow Tab
Data flows are the only task that have
The Data Flow Tab
Data flows are the only task that have
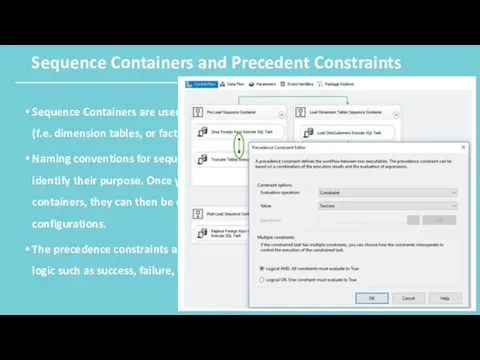
Sequence Containers and Precedent Constraints
Sequence Containers are used to group control
Sequence Containers and Precedent Constraints
Sequence Containers are used to group control
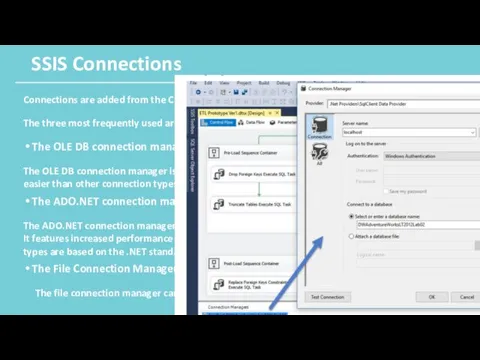
SSIS Connections
Connections are added from the Connection Manager’s Tray.
The three most
SSIS Connections
Connections are added from the Connection Manager’s Tray.
The three most
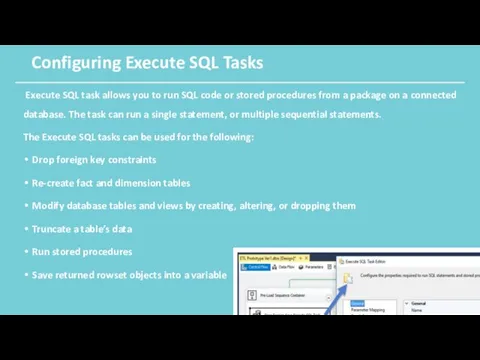
Configuring Execute SQL Tasks
Execute SQL task allows you to run
Configuring Execute SQL Tasks
Execute SQL task allows you to run
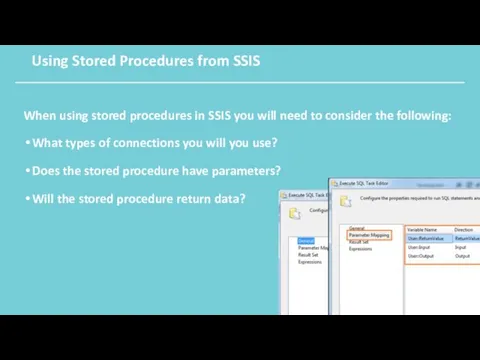
Using Stored Procedures from SSIS
When using stored procedures in SSIS you
Using Stored Procedures from SSIS
When using stored procedures in SSIS you

DEMO 3.
Control flows and Data flows.
Containers and Precedence constraints
Connection Manager.
Execute
DEMO 3. Control flows and Data flows. Containers and Precedence constraints Connection Manager. Execute

3. SSIS DATA FLOWS
3. SSIS DATA FLOWS
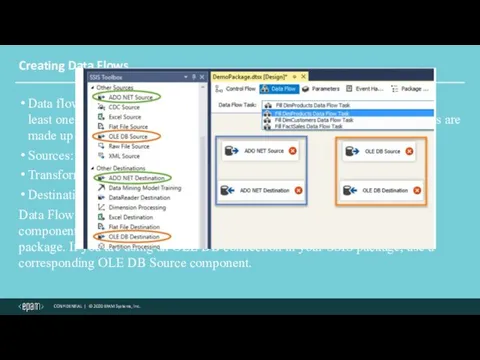
Creating Data Flows
Data flows, as the name implies, is an SSIS
Creating Data Flows
Data flows, as the name implies, is an SSIS
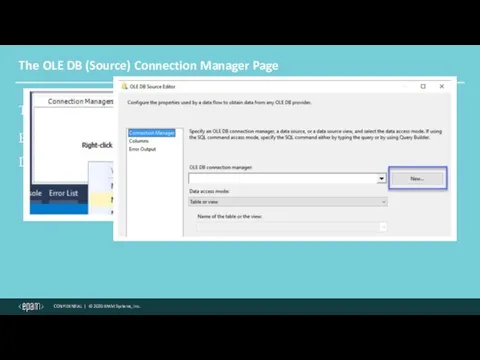
The OLE DB (Source) Connection Manager Page
To use a Data Flow,
The OLE DB (Source) Connection Manager Page
To use a Data Flow,
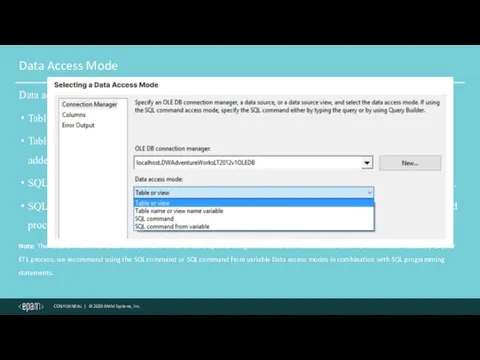
Data Access Mode
Data access mode has the following four options:
Table or
Data Access Mode
Data access mode has the following four options:
Table or
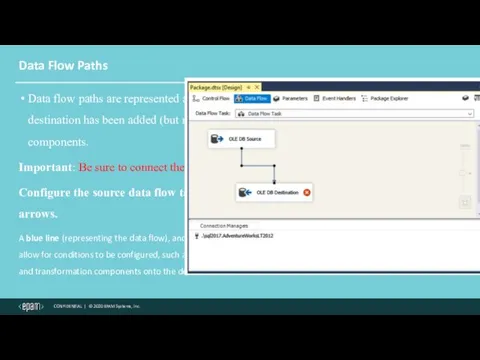
Data Flow Paths
Data flow paths are represented as arrows. Once the
Data Flow Paths
Data flow paths are represented as arrows. Once the
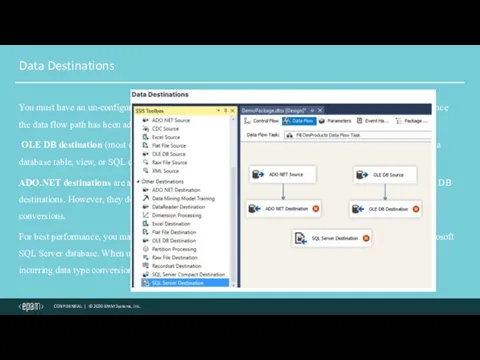
Data Destinations
You must have an un-configured destination on the designer surface
Data Destinations
You must have an un-configured destination on the designer surface
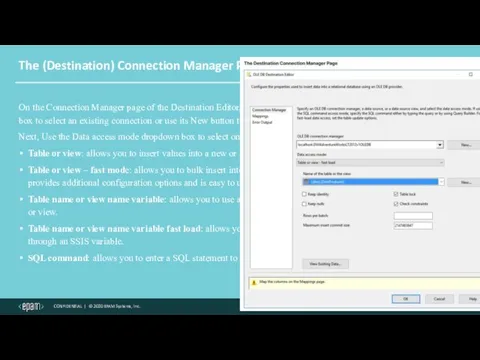
The (Destination) Connection Manager Page
On the Connection Manager page of the
The (Destination) Connection Manager Page
On the Connection Manager page of the
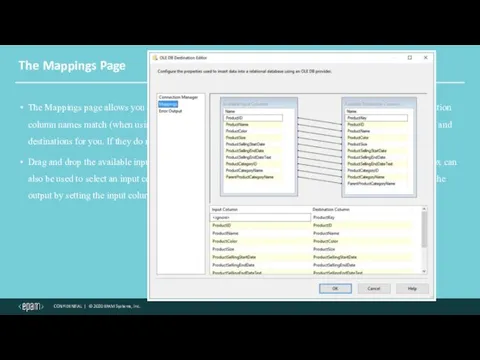
The Mappings Page
The Mappings page allows you to map input columns
The Mappings Page
The Mappings page allows you to map input columns
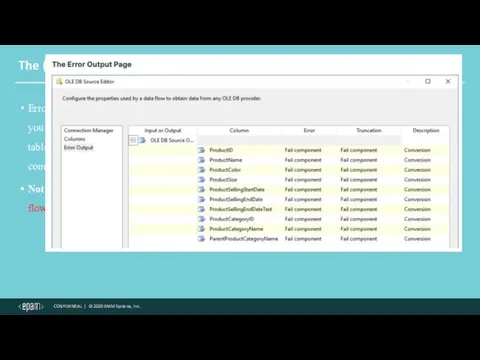
The (Source and Destination) Error Output Page
Errors can be redirected to
The (Source and Destination) Error Output Page
Errors can be redirected to
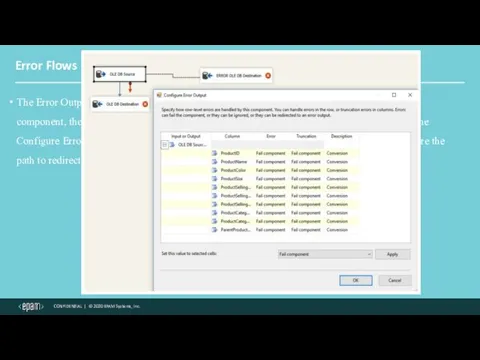
Error Flows
The Error Output arrow is red. To add an Error
Error Flows
The Error Output arrow is red. To add an Error

DEMO 4.
DATA FLOWS OWERVIEW.
DATA FLOW SOURCE.
DATA FLOW PATH
DEMO 4.
DATA FLOWS OWERVIEW.
DATA FLOW SOURCE.
DATA FLOW PATH

Data Flow Transformations
Transformations are the third and final component to consider
Data Flow Transformations
Transformations are the third and final component to consider

DEMO 5.
Sort, Data conversion,
Derived Column.
DEMO 5.
Sort, Data conversion,
Derived Column.

Tuning Data Sources
SSIS is a powerful tool that can perform many
Tuning Data Sources
SSIS is a powerful tool that can perform many
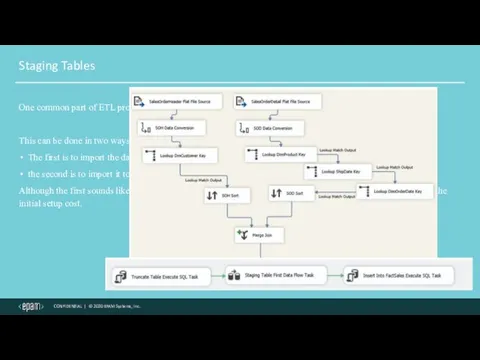
Staging Tables
One common part of ETL processing is importing data from
Staging Tables
One common part of ETL processing is importing data from

4. DEPLOYMENT AND TROUBLESHOOTING
4. DEPLOYMENT AND TROUBLESHOOTING

Troubleshooting Errors
Good ETL creation includes error handling and troubleshooting.
Microsoft
Troubleshooting Errors
Good ETL creation includes error handling and troubleshooting.
Microsoft
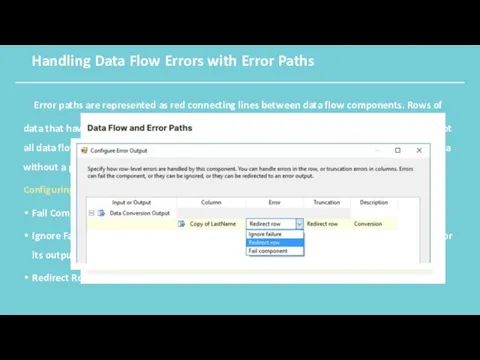
Handling Data Flow Errors with Error Paths
Error paths are represented
Handling Data Flow Errors with Error Paths
Error paths are represented
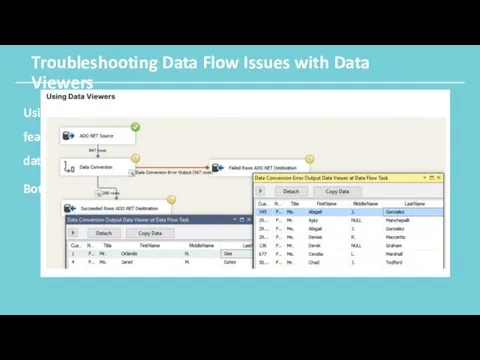
Troubleshooting Data Flow Issues with Data Viewers
Using an Error path to
Troubleshooting Data Flow Issues with Data Viewers
Using an Error path to
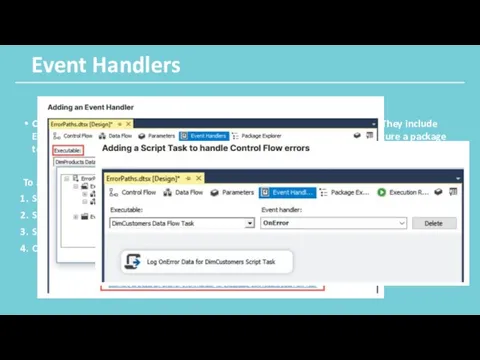
Event Handlers
Control flows do not have error paths or data viewers
Event Handlers
Control flows do not have error paths or data viewers
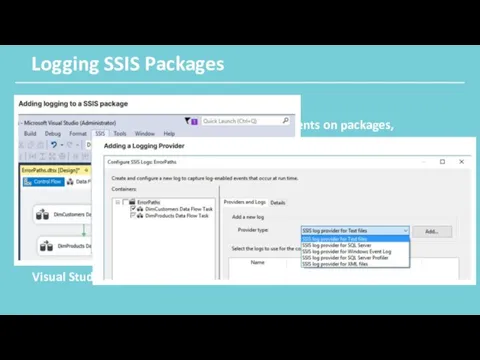
Logging SSIS Packages
SSIS includes an logging feature used to track events
Logging SSIS Packages
SSIS includes an logging feature used to track events
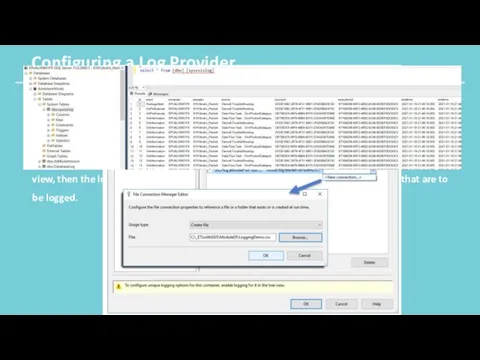
Configuring a Log Provider
To configure a Log Provider, you can begin
Configuring a Log Provider
To configure a Log Provider, you can begin
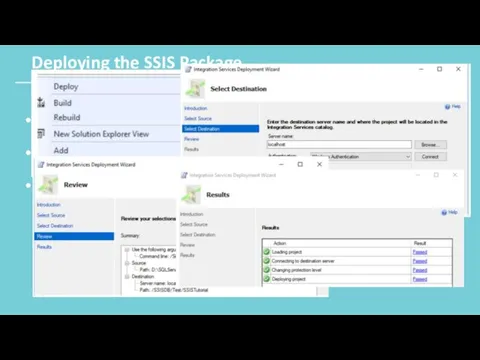
Deploying the SSIS Package
right-click on the project and select Deploy.
start
Deploying the SSIS Package
right-click on the project and select Deploy.
start
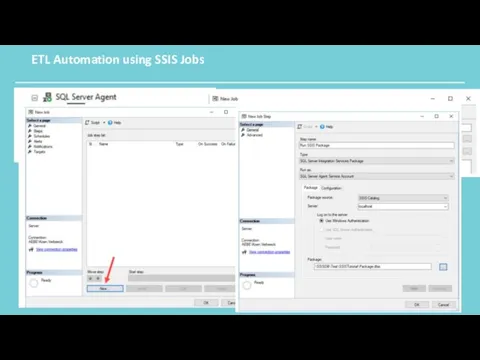
ETL Automation using SSIS Jobs
Normally you will schedule packages so your
ETL Automation using SSIS Jobs
Normally you will schedule packages so your

DEMO 6.
Troubleshooting and error handling.
DEMO 6.
Troubleshooting and error handling.

Hometask
Hometask
 Файл и файловая система. Презентация к уроку. 8 класс.
Файл и файловая система. Презентация к уроку. 8 класс. Применение дистанционных технологий при обучении детей с ОВЗ
Применение дистанционных технологий при обучении детей с ОВЗ Графический дизайн для недизайнера
Графический дизайн для недизайнера Трассировка лучей в играх
Трассировка лучей в играх Сервіси синхронного перекладу відео на англійську мову з використанням штучного інтелекту
Сервіси синхронного перекладу відео на англійську мову з використанням штучного інтелекту Типовое внедрение STORVERK CRM на платформе 1С
Типовое внедрение STORVERK CRM на платформе 1С Циклы Visual Basic
Циклы Visual Basic Задачи Информация 8 класс
Задачи Информация 8 класс Теорія кодів
Теорія кодів CAN та CANOpen. Загальне представлення
CAN та CANOpen. Загальне представлення Средства массовой информации
Средства массовой информации Моделирование как метод познания. Системный подход в моделировании. урок информатики 11 класс Угринович.Н.Д.
Моделирование как метод познания. Системный подход в моделировании. урок информатики 11 класс Угринович.Н.Д. Прием подписки через плагин Подписка в ЕАС ОПС
Прием подписки через плагин Подписка в ЕАС ОПС Программирование разветвляющихся алгоритмов
Программирование разветвляющихся алгоритмов Электронды пошта байланысы. Аударма сөздіктер
Электронды пошта байланысы. Аударма сөздіктер Международная патентная классификация (МПК)
Международная патентная классификация (МПК) Cистемы электронного документооборота
Cистемы электронного документооборота Spring Boot. Spring Data. ORM
Spring Boot. Spring Data. ORM Информация и информационные процессы
Информация и информационные процессы Нахождение минимального и максимального элементов в массиве
Нахождение минимального и максимального элементов в массиве Процессор
Процессор Scopus - поисковая платформа, объединяющая реферативные базы данных
Scopus - поисковая платформа, объединяющая реферативные базы данных Отчёт по практике. Установка и настройка ОС Microsoft Windows 7
Отчёт по практике. Установка и настройка ОС Microsoft Windows 7 Комплекс заданий по освоению графики
Комплекс заданий по освоению графики Информационные системы и технологии в юридической деятельности. Информационные технологии
Информационные системы и технологии в юридической деятельности. Информационные технологии Поколение - Z. Школа Блогеров
Поколение - Z. Школа Блогеров Основні поняття реляційної моделі даних
Основні поняття реляційної моделі даних Вручение РПО (упрощенное вручение)
Вручение РПО (упрощенное вручение)