- Искусственные нейронные сети

Содержание
- 2. Что такое нейронные сети Искусственная нейронная сеть —математическая модель, построенная по принципу организации и функционирования биологических
- 3. Какое место занимают нейросети в Computer Science
- 4. Нейронные сети принадлежат к классу алгоритмов, обучающихся с учителем (supervised learning), и решает типовые задачи этого
- 5. Искусственный нейрон
- 6. ИН – формализованная модель биологического нейрона, предложенная в 1943 году У. Маккалоком и У.Питтсом. Он работает
- 7. Линейная Выходы сети являются линейными комбинациями входов Пороговая Эта функция использовалась в оригинальной модели ИН. имеет
- 8. Сигмоида Долгое время считалась функцией, лучше всего описывающей работу нейрона. дифференцируема имеет порог насыщения Tanh дифференцируема
- 9. ReLU (rectified linear unit) В настоящее время самая широко используемая функция активации в силу своей простоты.
- 10. Зачем нужно смещение Замечание: сдвиг b можно также считать отдельным нейроном, на который всегда подается значение
- 11. Слои Слой - совокупность нейронов сети, объединяемых по особенностям их функционирования. В плоскослоистых сетях это группа
- 12. Персептрон y = f(∑w2 f(∑w1 x)) Перцептрон - одна из первых моделей нейронных сетей, предложенная в
- 13. Формальное определение задачи классификации Имеется множество объектов, разделённых некоторым образом на классы. Задано конечное множество объектов,
- 14. Разделяющая гиперплоскость В задаче классификации однослойный персептрон строит в Rn гиперплоскость (или поверхность, если функция активации
- 15. Булевы функции Как пример задачи классификации рассмотрим булевы функции, в которых признаковому описанию, состоящему из значений
- 16. Персептроны, реализующие булевы функции
- 17. Соответствующие разделяющие гиперплоскости
- 18. Проблема XOR Научное сообщество на долгое время потеряла интерес к нейронным сетям после выхода в 1969
- 19. Решение проблемы
- 20. Теорема Колмогорова-Арнольда Любая непрерывная функция любого количества переменных представляется в виде суперпозиции непрерывных функций одной и
- 21. Обучение сети Наиболее распространенный метод обучения нейронной сети – метод обратного распространения ошибки. Он был впервые
- 22. Аналогия для понимания (дельта-правило)
- 23. Аналогия для понимания (дельта-правило)
- 24. Аналогия для понимания (дельта-правило)
- 25. Обучающая выборка Выборка – набор размеченных входных векторов (т.е. таких, для которых известен правильный ответ), по
- 26. Прямой ход
- 27. Функция потерь Функция потерь — функция, по значению которой можно оценить работу сети. Две наиболее часто
- 28. Обратный ход Будем минимизировать функцию потерь методом стохастического градиентного спуска
- 29. «Спуск» по поверхности ошибки
- 30. Гиперпараметры η - шаг обучения. Он является гиперпараметром, то есть он настраиваются вручную до начала обучения.
- 31. wi j влияет на выход сети только как часть суммы Поэтому Рассмотрим, как будут меняться веса
- 32. Sj влияет на общую ошибку только в рамках выхода j-го узла yj (являющегося выходом сети): Поэтому
- 33. Рассмотрим теперь, как будут меняться веса между скрытыми слоями. S j влияет на выход сети через
- 34. Итого: Для последнего слоя: Для внутренних слоев: Для всех:
- 36. Проблемы обучения Паралич сети – сеть перестает обучаться. Переобучение Недообучение Причины: затухающий градиент взрывающийся градиент неправильный
- 37. Контроль обучения Кросс-валидация Регуляризация штраф за большие веса dropout batch norm Работа с обучающей выборкой
- 38. Применения персептрона Распознавание образов и классификация Анализ данных Принятие решений и управление в нейроинформатике в химии
- 39. Когда все поменялось В 2012 году нейросеть впервые выиграла соревнование по распознаванию IMAGENET c 10% отрывом.
- 40. Сверточные нейронные сети Сверточная нейронная сеть (CNN) — специальная архитектура нейронных сетей, предложенная Яном Лекуном в
- 41. Свертка Свертка – операция, применяемая к двум массивам, которая заключается в следующем: фильтр «скользит» по входному
- 42. Двумерная свертка
- 43. Шаг и padding Единичный 0-padding Свертка с шагом 2
- 44. Свертка в нейронных сетях Изображение – это трехмерный тензор (массив), с размерностями: WxHxC. К нему применяется
- 45. Сверточный слой Будем использовать не один, а F фильтров. Сверточный слой принимает на вход тензор WxHxD
- 46. Субдискритизация (pooling) Изображение делится на регионы (напр. квадраты 2х2), и каждый регион заменяется на максимальное значение
- 47. Примеры VGG-16
- 48. Понимание работы CNN Показано, что мозг обрабатывает визуальную информацию иерархически: сначала находят границы, углы, а на
- 49. Deconvolutional network – это сеть, которая интерпретирует CNN, т.е. показывает, какие пиксели повлияли на активацию тех
- 50. Транспонированная свертка Свертка и соответствующая ей транспонированная свертка
- 51. Выучиваемые признаки На рисунке показаны куски изображения, которые больше всего были ответственны за то, чтобы активировать
- 54. Layers 4, 5
- 55. CNN для распознавания звуков и текстов
- 56. Автоэнкодеры Предположим, наша задача не классифицировать картинки, а получить для них какое-то малоразмерное представление. Тогда для
- 57. Автоэнкодер – это специальная архитектура нейросети, состоящая из кодировщика и декодировщика. На месте их стыка образуется
- 58. Скрытое пространство Скрытое пространство – маломерное пространство, в которое кодировщик отображает данные. Его визуализация позволяет получать
- 59. Движение в скрытом пространстве Интересный эффект получается, если подавать на декодировщик значения, полученные при движении от
- 60. Рекуррентные нейронные сети Рекуррентная нейронная сеть (RNN) — архитектура нейронных сетей, где связи между элементами образуют
- 61. Все биологической нейронной сети – рекуррентные RNN моделирует динамическую систему Универсальная теорема аппроксимации говорит, что с
- 62. Сеть Хопфилда Однослойная RNN с пороговой функцией активации. Она моделирует ассоциативную память – она «запоминает» какой-то
- 63. Машина Больцмана Стохастическая аналог сети Хопфилда, придуманный Дж. Хинтоном в 1985г. Для нее определено понятие «энергии»:
- 64. Машина Больцмана обучается алгоритмом имитации обжига: система вычисляет значение энергии в некотором случайном состоянии. Если оно
- 65. Общий случай В общем случае RNN может запоминать некоторый «контекст» на скрытых слоях Для этого она
- 66. Применение RNN Моделирование последовательностей преобразования (напр. из звука в текст) предсказание следующего элемента последовательности (напр. следующего
- 67. Пример использования RNN в задаче машинного перевода
- 68. Вопросы Что такое нейронная сеть и что она моделирует? [1] В чем основная идея метода обратного
- 70. Скачать презентацию

Что такое нейронные сети
Искусственная нейронная сеть —математическая модель, построенная по принципу
Что такое нейронные сети
Искусственная нейронная сеть —математическая модель, построенная по принципу
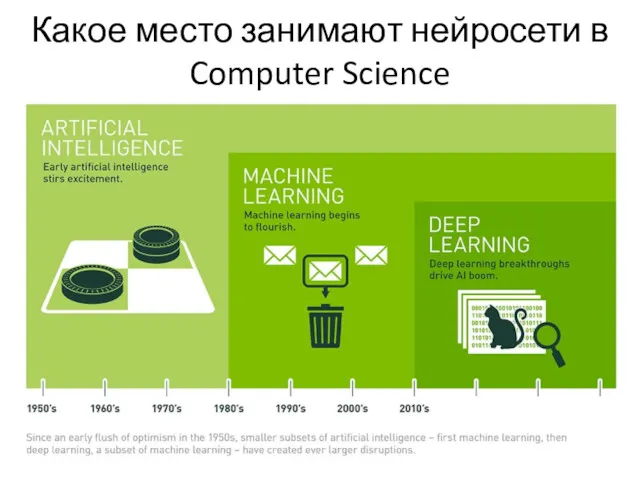
Какое место занимают нейросети в Computer Science
Какое место занимают нейросети в Computer Science
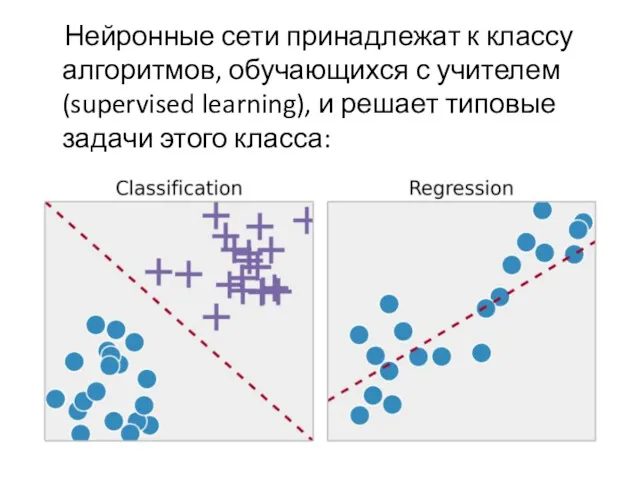
Нейронные сети принадлежат к классу алгоритмов, обучающихся с учителем (supervised
Нейронные сети принадлежат к классу алгоритмов, обучающихся с учителем (supervised
Искусственный нейрон
Искусственный нейрон
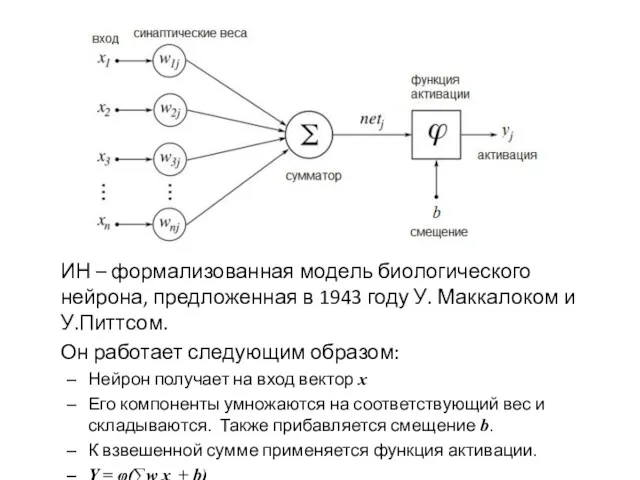
ИН – формализованная модель биологического нейрона, предложенная в 1943 году У.
ИН – формализованная модель биологического нейрона, предложенная в 1943 году У.
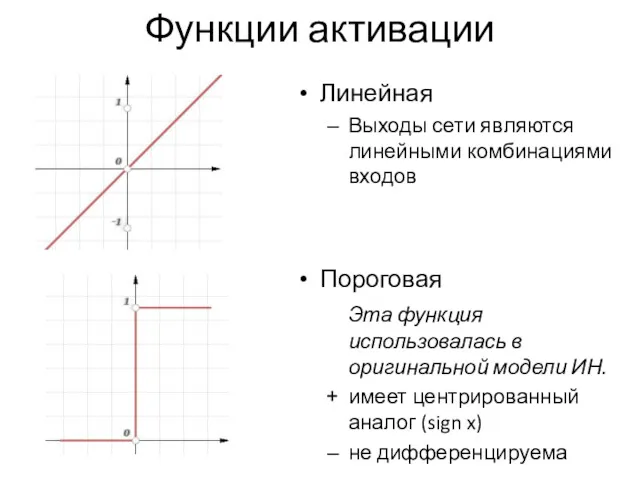
Линейная
Выходы сети являются линейными комбинациями входов
Пороговая
Эта функция использовалась в оригинальной модели
Линейная
Выходы сети являются линейными комбинациями входов
Пороговая
Эта функция использовалась в оригинальной модели
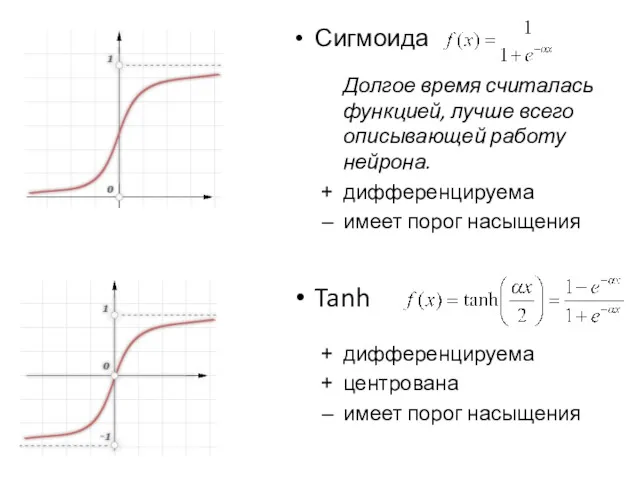
Сигмоида
Долгое время считалась функцией, лучше всего описывающей работу нейрона.
дифференцируема
имеет порог насыщения
Tanh
дифференцируема
центрована
имеет
Сигмоида
Долгое время считалась функцией, лучше всего описывающей работу нейрона.
дифференцируема
имеет порог насыщения
Tanh
дифференцируема
центрована
имеет
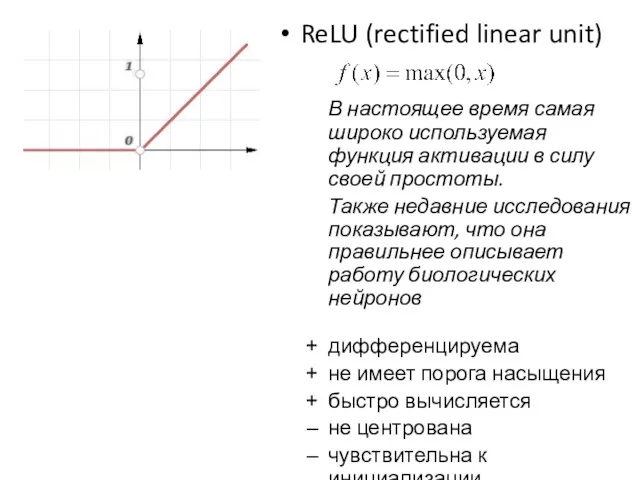
ReLU (rectified linear unit)
В настоящее время самая широко используемая функция активации
ReLU (rectified linear unit)
В настоящее время самая широко используемая функция активации
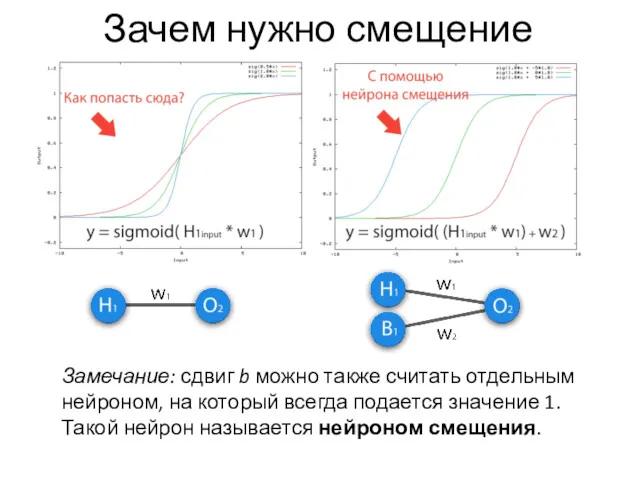
Зачем нужно смещение
Замечание: сдвиг b можно также считать отдельным нейроном, на
Зачем нужно смещение
Замечание: сдвиг b можно также считать отдельным нейроном, на
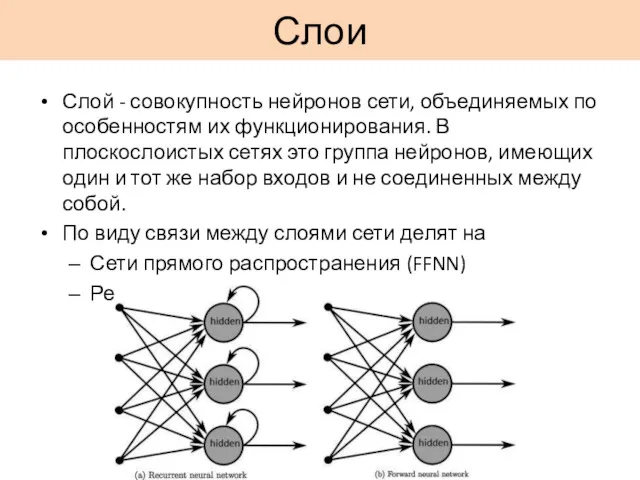
Слои
Слой - совокупность нейронов сети, объединяемых по особенностям их функционирования. В
Слои
Слой - совокупность нейронов сети, объединяемых по особенностям их функционирования. В
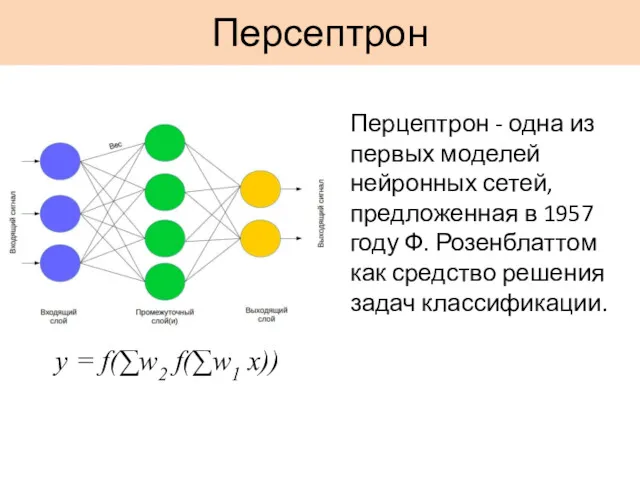
Персептрон
y = f(∑w2 f(∑w1 x))
Перцептрон - одна из первых моделей
Персептрон
y = f(∑w2 f(∑w1 x))
Перцептрон - одна из первых моделей

Формальное определение задачи классификации
Имеется множество объектов, разделённых некоторым образом на классы.
Формальное определение задачи классификации
Имеется множество объектов, разделённых некоторым образом на классы.
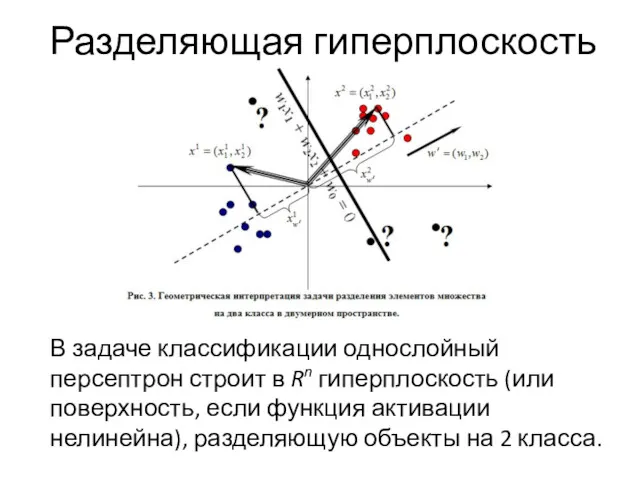
Разделяющая гиперплоскость
В задаче классификации однослойный персептрон строит в Rn гиперплоскость (или
Разделяющая гиперплоскость
В задаче классификации однослойный персептрон строит в Rn гиперплоскость (или

Булевы функции
Как пример задачи классификации рассмотрим булевы функции, в которых признаковому описанию,
Булевы функции
Как пример задачи классификации рассмотрим булевы функции, в которых признаковому описанию,
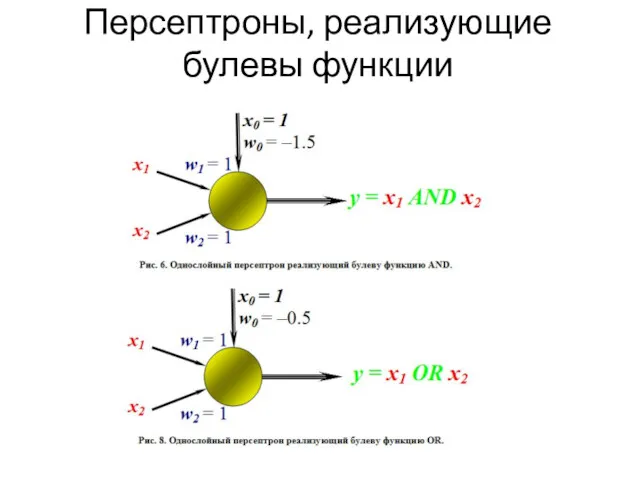
Персептроны, реализующие булевы функции
Персептроны, реализующие булевы функции
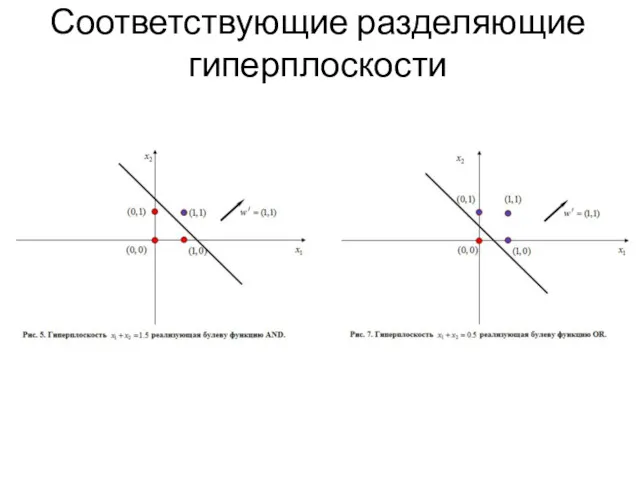
Соответствующие разделяющие гиперплоскости
Соответствующие разделяющие гиперплоскости
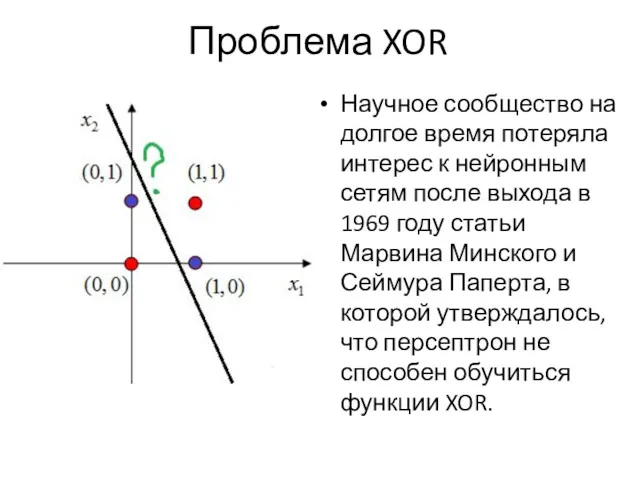
Проблема XOR
Научное сообщество на долгое время потеряла интерес к нейронным сетям
Проблема XOR
Научное сообщество на долгое время потеряла интерес к нейронным сетям
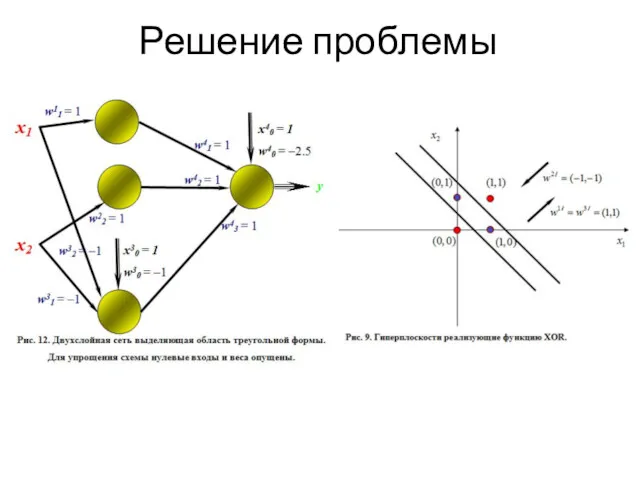
Решение проблемы
Решение проблемы

Теорема Колмогорова-Арнольда
Любая непрерывная функция любого количества переменных представляется в виде суперпозиции
Теорема Колмогорова-Арнольда
Любая непрерывная функция любого количества переменных представляется в виде суперпозиции

Обучение сети
Наиболее распространенный метод обучения нейронной сети – метод обратного распространения
Обучение сети
Наиболее распространенный метод обучения нейронной сети – метод обратного распространения
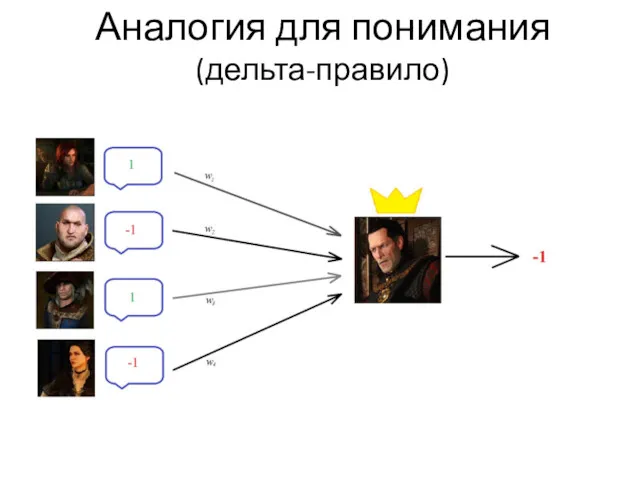
Аналогия для понимания
(дельта-правило)
Аналогия для понимания
(дельта-правило)
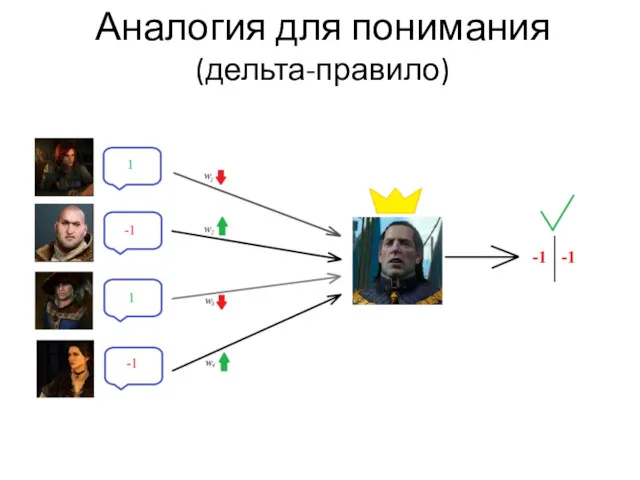
Аналогия для понимания
(дельта-правило)
Аналогия для понимания
(дельта-правило)
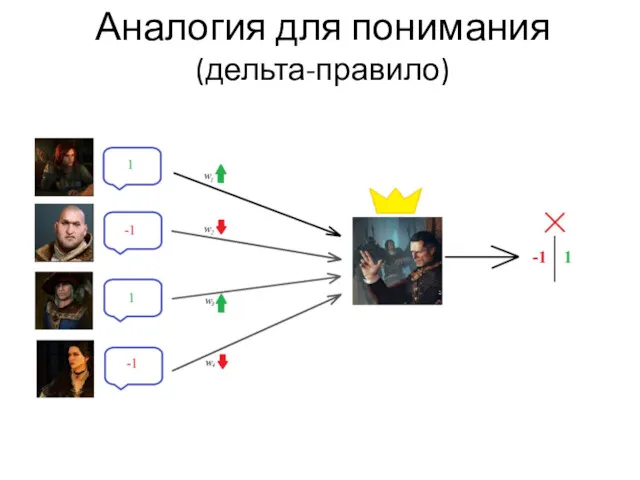
Аналогия для понимания
(дельта-правило)
Аналогия для понимания
(дельта-правило)
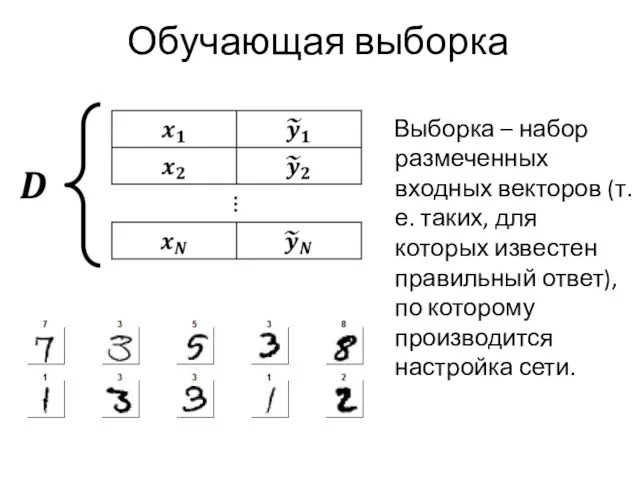
Обучающая выборка
Выборка – набор размеченных входных векторов (т.е. таких, для
Обучающая выборка
Выборка – набор размеченных входных векторов (т.е. таких, для
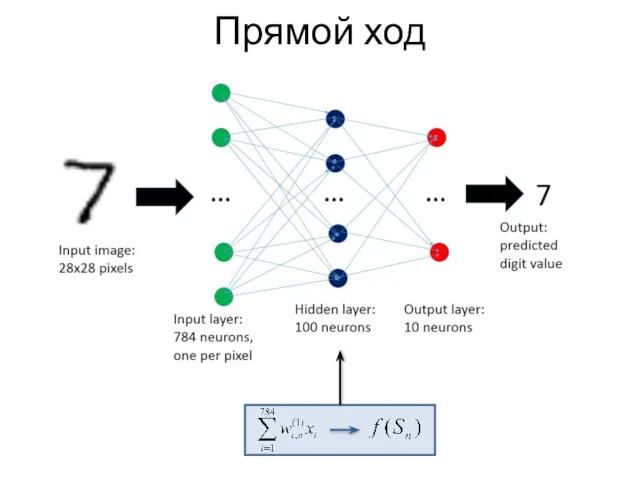
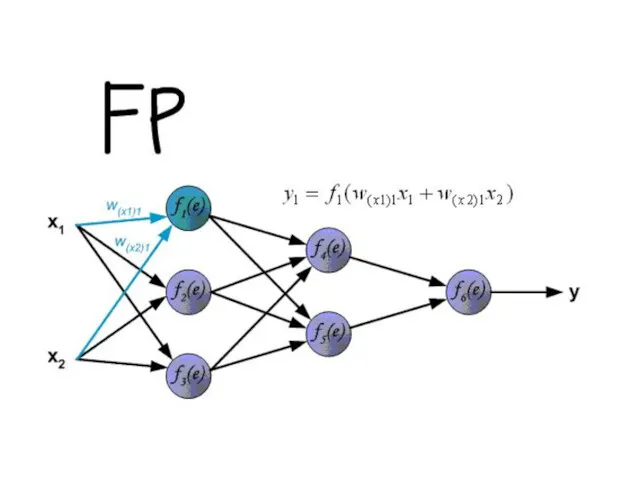
Прямой ход
Прямой ход

Функция потерь
Функция потерь — функция, по значению которой можно оценить работу
Функция потерь
Функция потерь — функция, по значению которой можно оценить работу

Обратный ход
Будем минимизировать функцию потерь
методом стохастического градиентного спуска
Обратный ход
Будем минимизировать функцию потерь
методом стохастического градиентного спуска
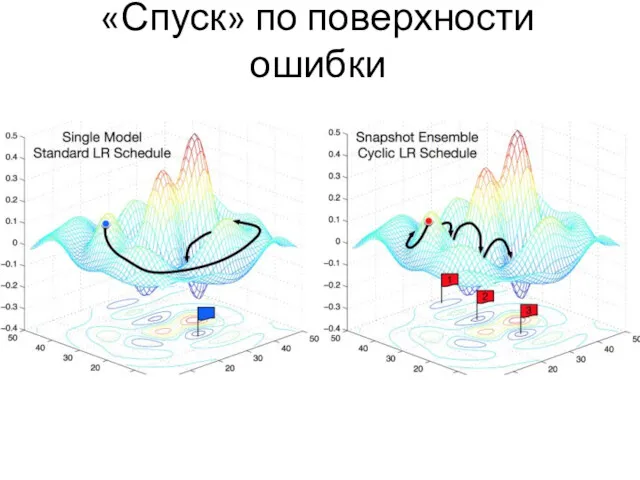
«Спуск» по поверхности ошибки
«Спуск» по поверхности ошибки

Гиперпараметры
η - шаг обучения. Он является гиперпараметром, то есть он настраиваются
Гиперпараметры
η - шаг обучения. Он является гиперпараметром, то есть он настраиваются

wi j влияет на выход сети только как часть суммы
Поэтому
Рассмотрим,
wi j влияет на выход сети только как часть суммы
Поэтому
Рассмотрим,

Sj влияет на общую ошибку только в рамках выхода j-го
Sj влияет на общую ошибку только в рамках выхода j-го

Рассмотрим теперь, как будут меняться веса между скрытыми слоями.
S j
Рассмотрим теперь, как будут меняться веса между скрытыми слоями.
S j
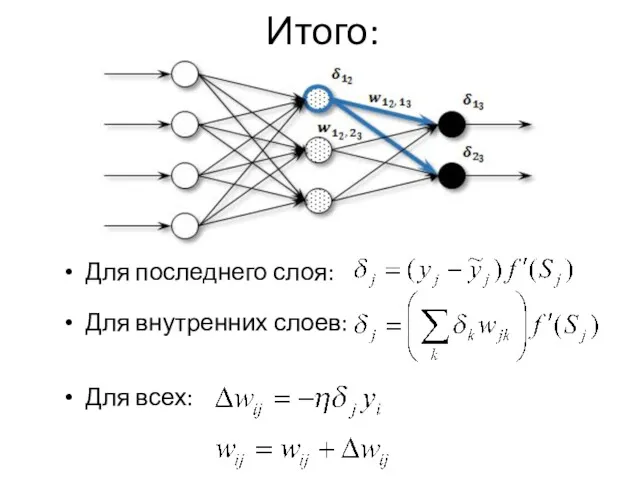
Итого:
Для последнего слоя:
Для внутренних слоев:
Для всех:
Итого:
Для последнего слоя:
Для внутренних слоев:
Для всех:

Проблемы обучения
Паралич сети – сеть перестает обучаться.
Переобучение
Недообучение
Причины:
затухающий градиент
взрывающийся градиент
неправильный
Проблемы обучения
Паралич сети – сеть перестает обучаться.
Переобучение
Недообучение
Причины:
затухающий градиент
взрывающийся градиент
неправильный

Контроль обучения
Кросс-валидация
Регуляризация
штраф за большие веса
dropout
batch norm
Работа с обучающей выборкой
Контроль обучения
Кросс-валидация
Регуляризация
штраф за большие веса
dropout
batch norm
Работа с обучающей выборкой

Применения персептрона
Распознавание образов и классификация
Анализ данных
Принятие решений и управление
в нейроинформатике
в химии
Применения персептрона
Распознавание образов и классификация
Анализ данных
Принятие решений и управление
в нейроинформатике
в химии
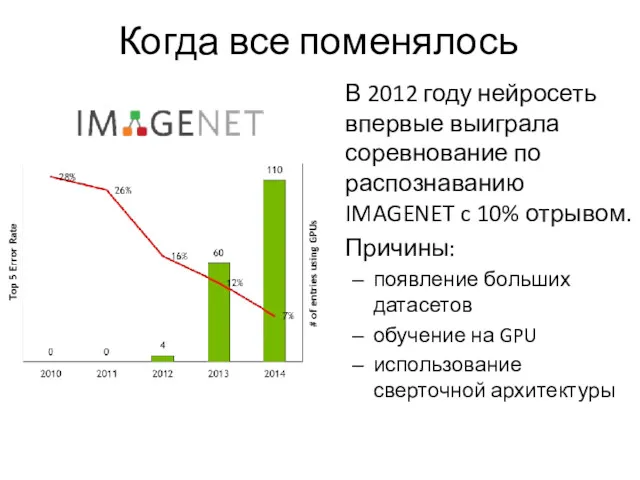
Когда все поменялось
В 2012 году нейросеть впервые выиграла соревнование по распознаванию
Когда все поменялось
В 2012 году нейросеть впервые выиграла соревнование по распознаванию
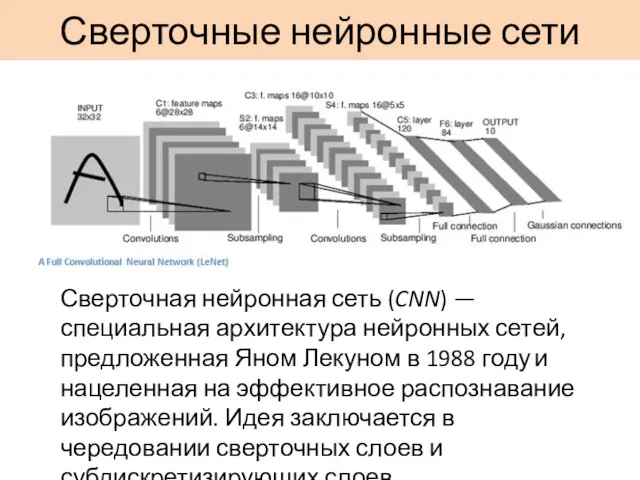
Сверточные нейронные сети
Сверточная нейронная сеть (CNN) — специальная архитектура нейронных сетей, предложенная
Сверточные нейронные сети
Сверточная нейронная сеть (CNN) — специальная архитектура нейронных сетей, предложенная
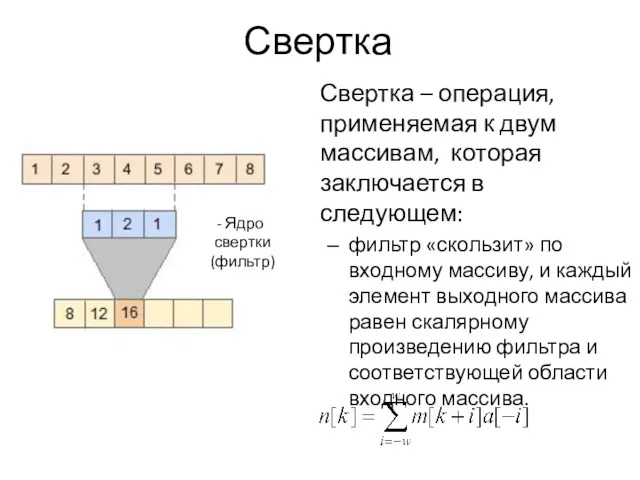
Свертка
Свертка – операция, применяемая к двум массивам, которая заключается в следующем:
фильтр
Свертка
Свертка – операция, применяемая к двум массивам, которая заключается в следующем:
фильтр
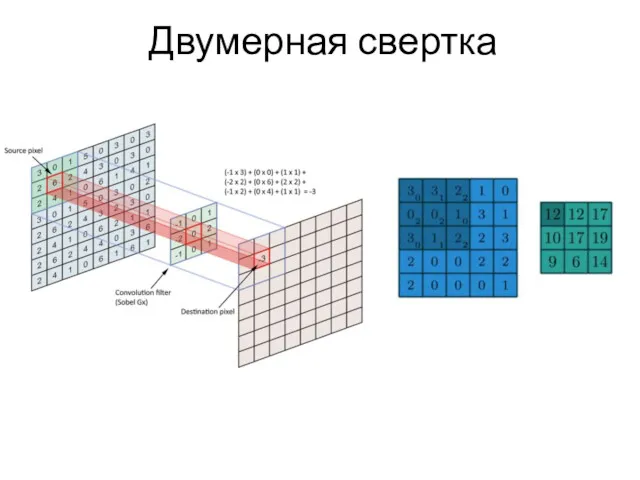
Двумерная свертка
Двумерная свертка
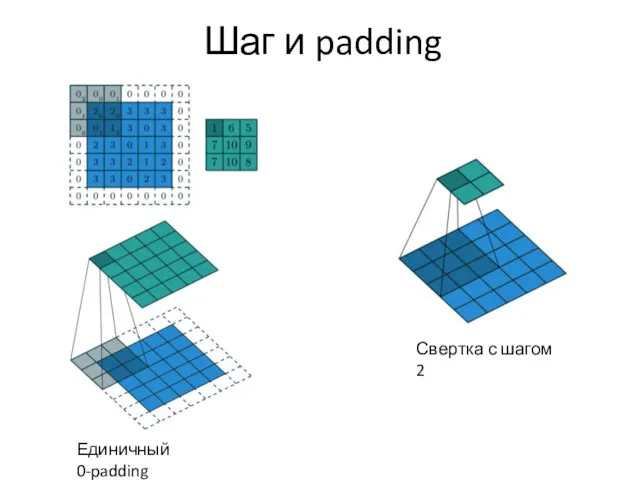
Шаг и padding
Единичный 0-padding
Свертка с шагом 2
Шаг и padding
Единичный 0-padding
Свертка с шагом 2
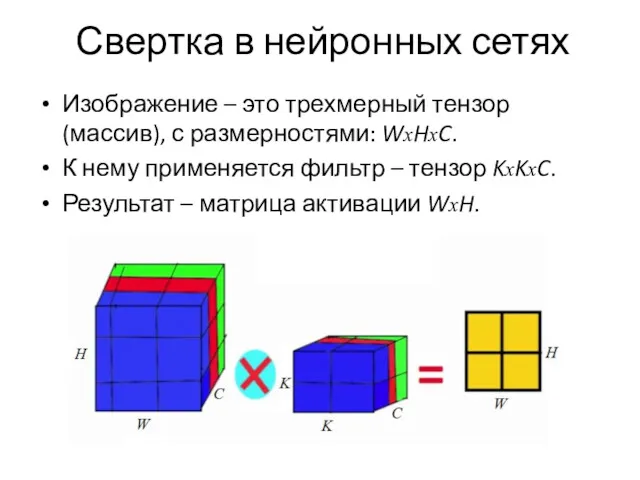
Свертка в нейронных сетях
Изображение – это трехмерный тензор (массив), с размерностями:
Свертка в нейронных сетях
Изображение – это трехмерный тензор (массив), с размерностями:
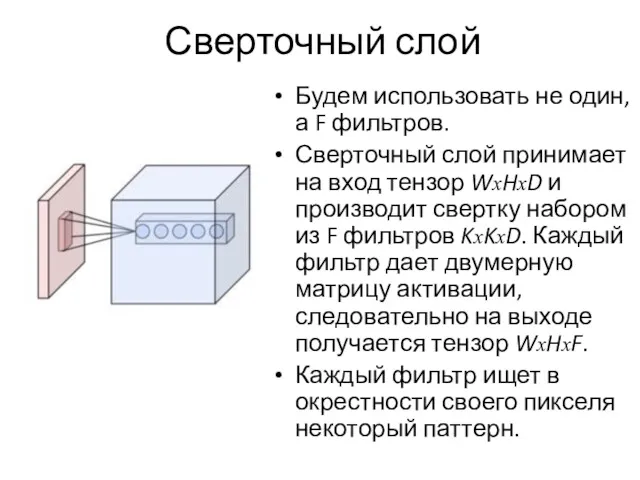
Сверточный слой
Будем использовать не один, а F фильтров.
Сверточный слой принимает
Сверточный слой
Будем использовать не один, а F фильтров.
Сверточный слой принимает
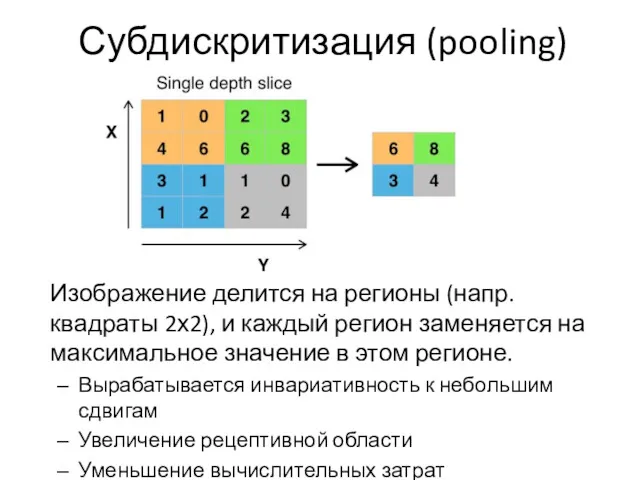
Субдискритизация (pooling)
Изображение делится на регионы (напр. квадраты 2х2), и каждый регион
Субдискритизация (pooling)
Изображение делится на регионы (напр. квадраты 2х2), и каждый регион
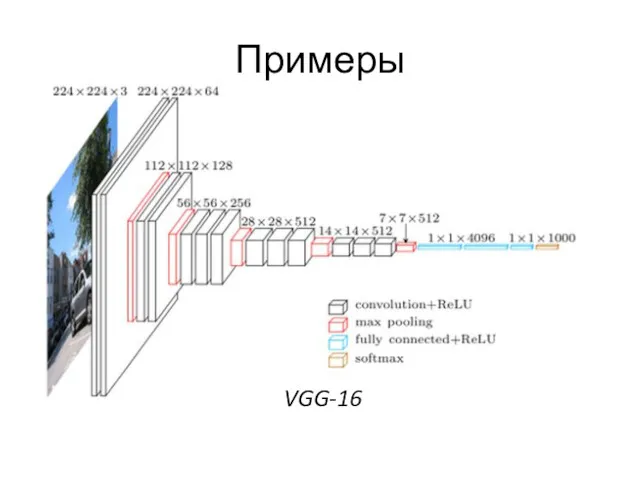
Примеры
VGG-16
Примеры
VGG-16
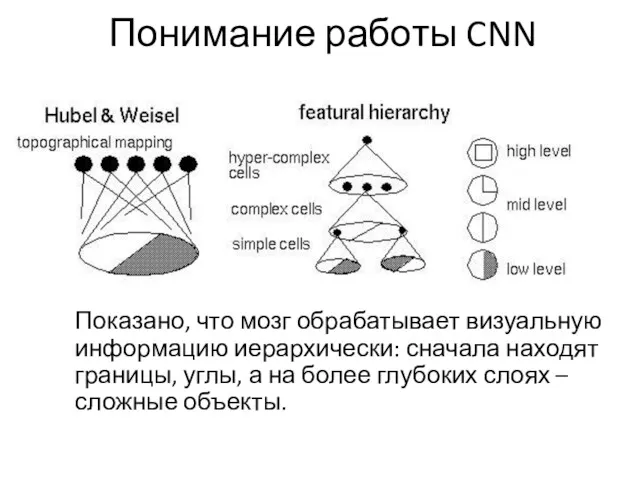
Понимание работы CNN
Показано, что мозг обрабатывает визуальную информацию иерархически: сначала находят
Понимание работы CNN
Показано, что мозг обрабатывает визуальную информацию иерархически: сначала находят
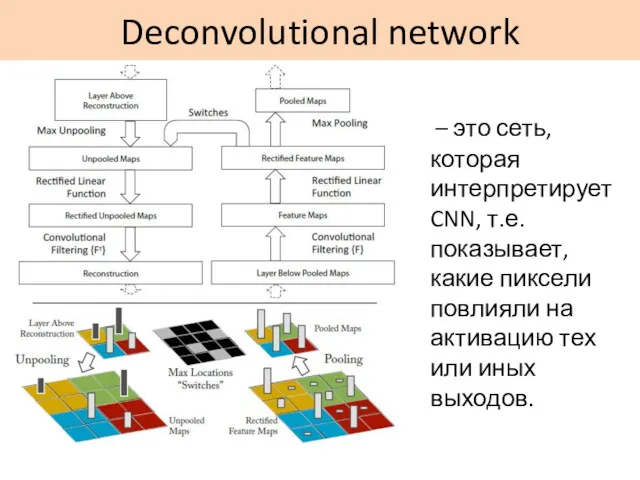
Deconvolutional network
– это сеть, которая интерпретирует CNN, т.е. показывает, какие
Deconvolutional network
– это сеть, которая интерпретирует CNN, т.е. показывает, какие
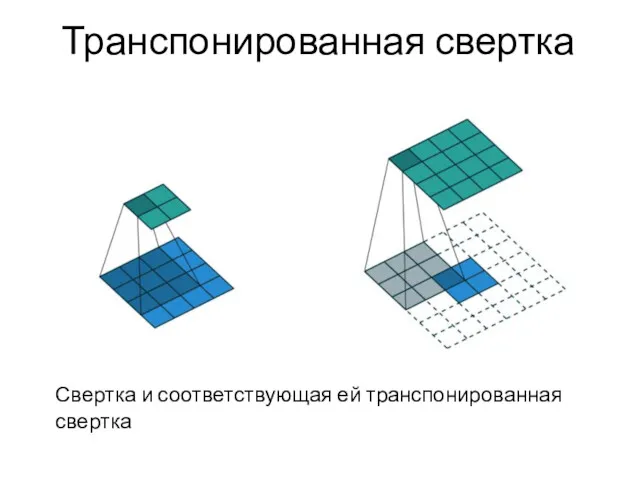
Транспонированная свертка
Свертка и соответствующая ей транспонированная свертка
Транспонированная свертка
Свертка и соответствующая ей транспонированная свертка

Выучиваемые признаки
На рисунке показаны куски изображения, которые больше всего были ответственны
Выучиваемые признаки
На рисунке показаны куски изображения, которые больше всего были ответственны



Layers 4, 5
Layers 4, 5
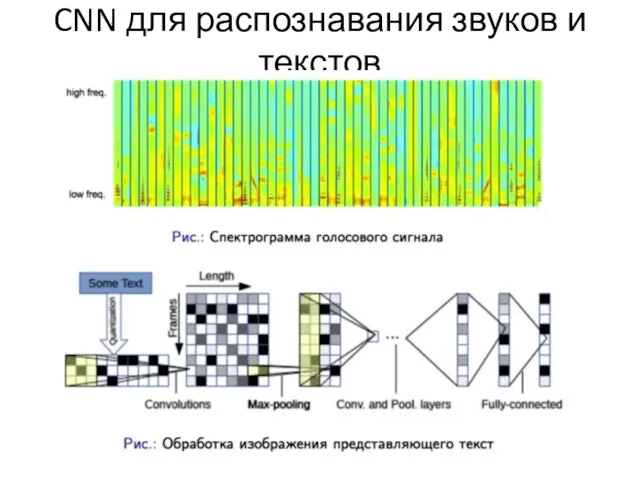
CNN для распознавания звуков и текстов
CNN для распознавания звуков и текстов
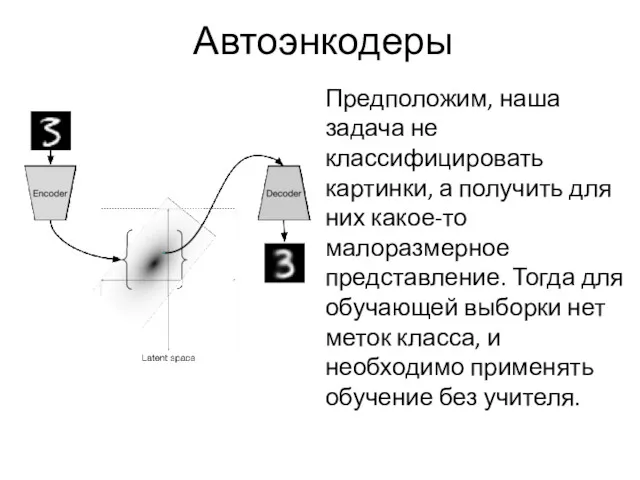
Автоэнкодеры
Предположим, наша задача не классифицировать картинки, а получить для них какое-то
Автоэнкодеры
Предположим, наша задача не классифицировать картинки, а получить для них какое-то
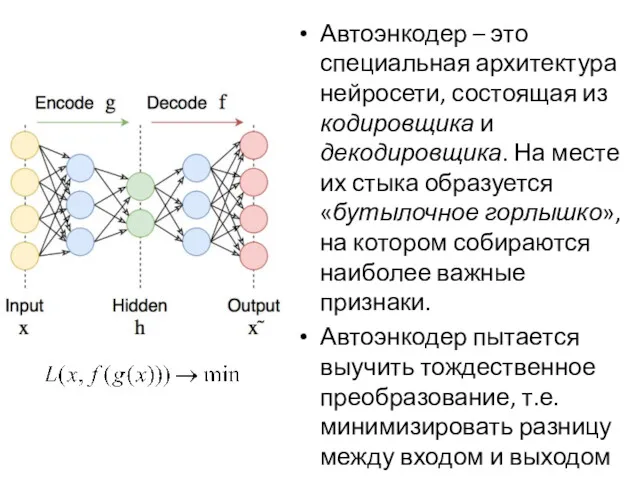
Автоэнкодер – это специальная архитектура нейросети, состоящая из кодировщика и декодировщика.
Автоэнкодер – это специальная архитектура нейросети, состоящая из кодировщика и декодировщика.
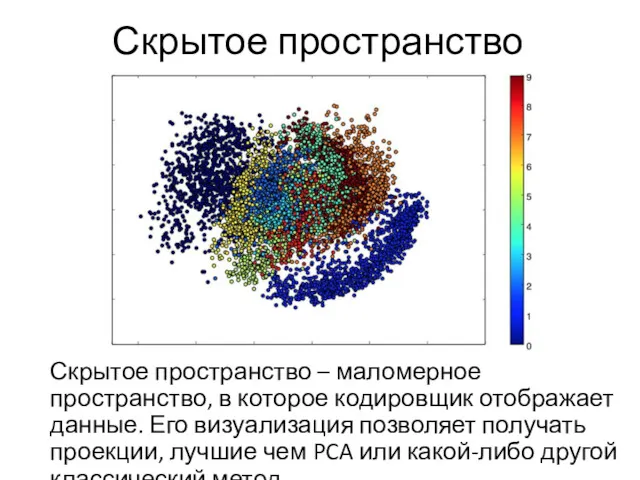
Скрытое пространство
Скрытое пространство – маломерное пространство, в которое кодировщик отображает данные.
Скрытое пространство
Скрытое пространство – маломерное пространство, в которое кодировщик отображает данные.
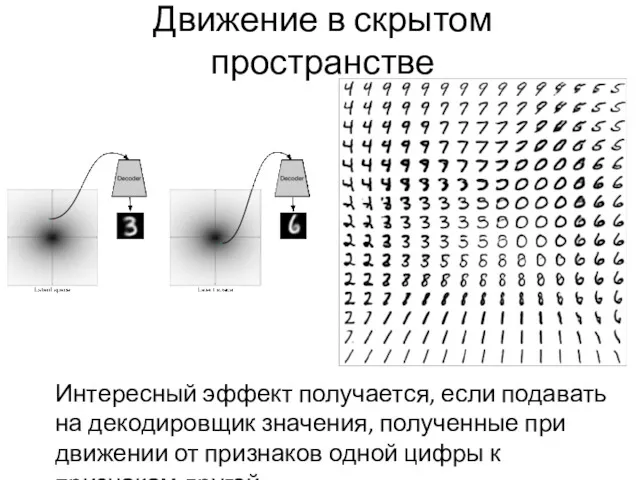
Движение в скрытом пространстве
Интересный эффект получается, если подавать на декодировщик значения,
Движение в скрытом пространстве
Интересный эффект получается, если подавать на декодировщик значения,
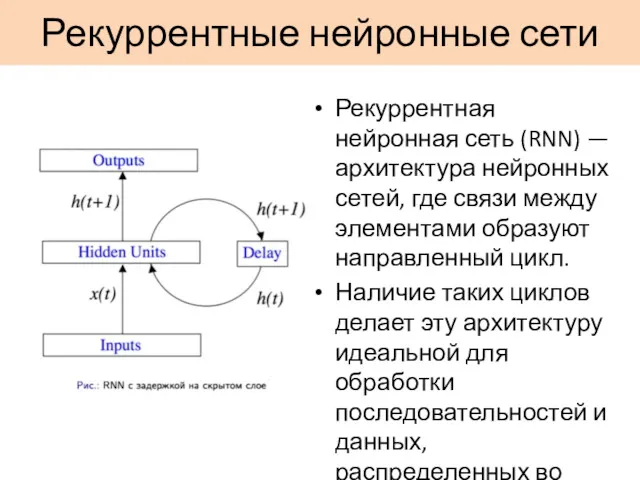
Рекуррентные нейронные сети
Рекуррентная нейронная сеть (RNN) — архитектура нейронных сетей, где
Рекуррентные нейронные сети
Рекуррентная нейронная сеть (RNN) — архитектура нейронных сетей, где

Все биологической нейронной сети – рекуррентные
RNN моделирует динамическую систему
Универсальная теорема
Все биологической нейронной сети – рекуррентные
RNN моделирует динамическую систему
Универсальная теорема
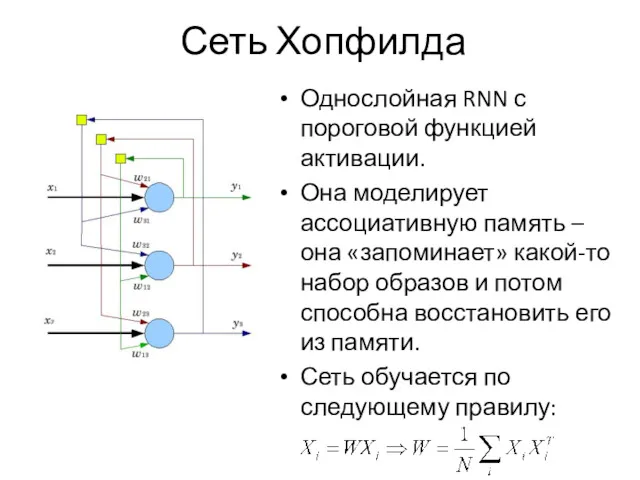
Сеть Хопфилда
Однослойная RNN с пороговой функцией активации.
Она моделирует ассоциативную память
Сеть Хопфилда
Однослойная RNN с пороговой функцией активации.
Она моделирует ассоциативную память
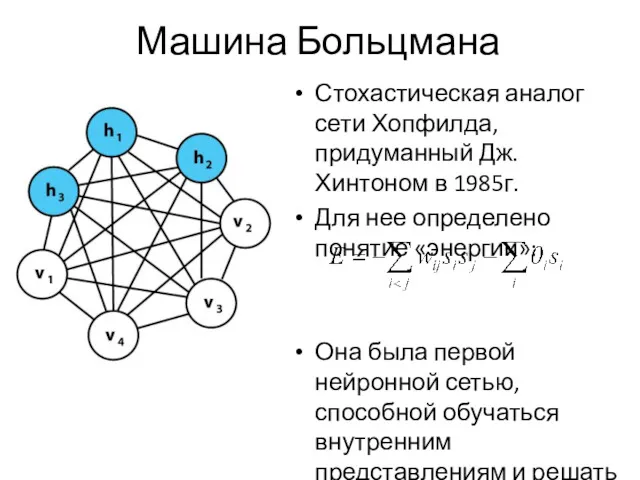
Машина Больцмана
Стохастическая аналог сети Хопфилда, придуманный Дж. Хинтоном в 1985г.
Для нее
Машина Больцмана
Стохастическая аналог сети Хопфилда, придуманный Дж. Хинтоном в 1985г.
Для нее
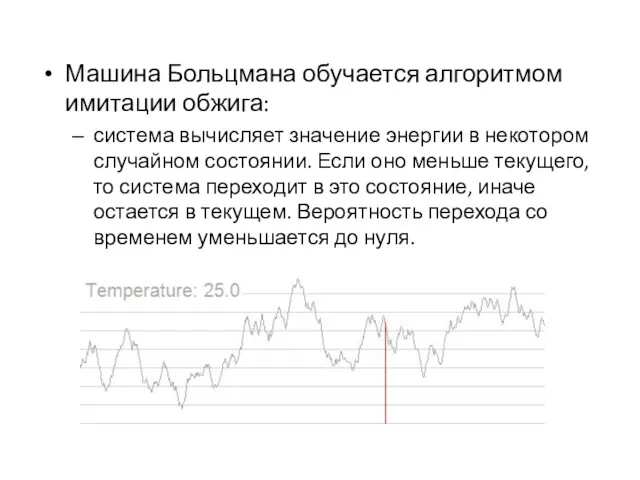
Машина Больцмана обучается алгоритмом имитации обжига:
система вычисляет значение энергии в некотором
Машина Больцмана обучается алгоритмом имитации обжига:
система вычисляет значение энергии в некотором
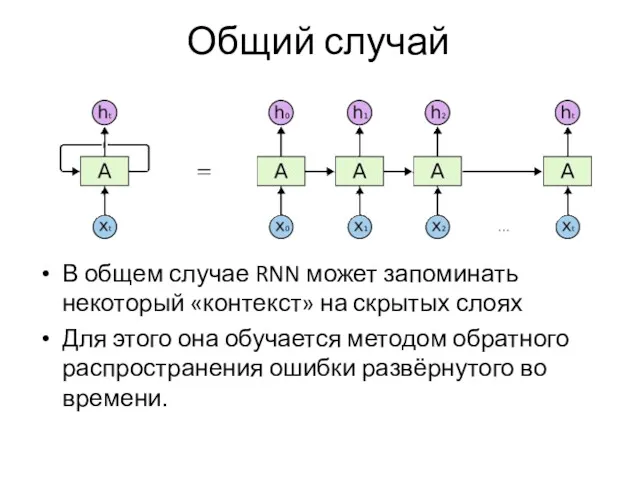
Общий случай
В общем случае RNN может запоминать некоторый «контекст» на скрытых
Общий случай
В общем случае RNN может запоминать некоторый «контекст» на скрытых

Применение RNN
Моделирование последовательностей
преобразования (напр. из звука в текст)
предсказание следующего элемента последовательности
Применение RNN
Моделирование последовательностей
преобразования (напр. из звука в текст)
предсказание следующего элемента последовательности
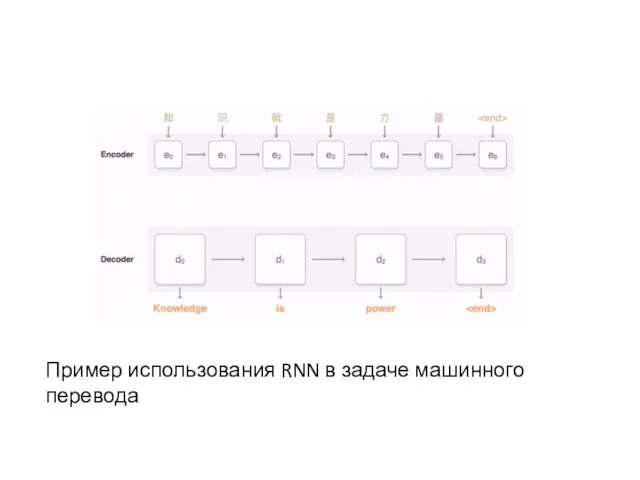
Пример использования RNN в задаче машинного перевода
Пример использования RNN в задаче машинного перевода
![Вопросы Что такое нейронная сеть и что она моделирует? [1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/145617/slide-67.jpg)
Вопросы
Что такое нейронная сеть и что она моделирует? [1]
В чем основная
Вопросы
Что такое нейронная сеть и что она моделирует? [1]
В чем основная
 Видатні інформатики світу
Видатні інформатики світу Дистанционная подготовка к Всероссийской олимпиаде по информатике. Сортировки
Дистанционная подготовка к Всероссийской олимпиаде по информатике. Сортировки Стандартизация программного обеспечения
Стандартизация программного обеспечения Здоровье-сберегающие технологии в предметной деятельности !Информатика и ИКТ
Здоровье-сберегающие технологии в предметной деятельности !Информатика и ИКТ Графические редакторы
Графические редакторы Star-shaped local area network
Star-shaped local area network WEB application security
WEB application security Оператор SELECT. Лекция 6
Оператор SELECT. Лекция 6 Базы данных. Управление данными
Базы данных. Управление данными Настройка контекстной рекламы Яндекс Директ
Настройка контекстной рекламы Яндекс Директ Mass media
Mass media Визуализация. Визуализация больших данных
Визуализация. Визуализация больших данных Разработка десктопного приложения по варианту на языке С# в среде Visual Studio
Разработка десктопного приложения по варианту на языке С# в среде Visual Studio Разработка информационной системы по автоматизации складского учета
Разработка информационной системы по автоматизации складского учета История вычислительной техники
История вычислительной техники Автоматизация библиотечной деятельности - АБИС
Автоматизация библиотечной деятельности - АБИС Урок Алгоритмы с ветвлением 6 класс
Урок Алгоритмы с ветвлением 6 класс Локальна мережа. Гра Допуск
Локальна мережа. Гра Допуск Создание проекта супермаркета в 3D-редакторе SKETCHUP
Создание проекта супермаркета в 3D-редакторе SKETCHUP Системы сбора данных Data Acquisition (DAQ)
Системы сбора данных Data Acquisition (DAQ) Створення БД у режимі майстра
Створення БД у режимі майстра Табличный процессор Microsoft Excel
Табличный процессор Microsoft Excel информационные процессы
информационные процессы Введение. Языки программирования
Введение. Языки программирования Разработка программного продукта Игра Морской бой
Разработка программного продукта Игра Морской бой Unit 02: Computer Systems
Unit 02: Computer Systems Панель керування
Панель керування Web-проектирование. Тема 2. Основы проектирования web-сайта
Web-проектирование. Тема 2. Основы проектирования web-сайта