- Использование Searchable DataStore для поиска закономерностей

Содержание
- 2. Создаем корпус файлов Создаем ресурс GATE – корпус Наполняем корпус файлами
- 3. Обрабатываем корпус Создаем стандартную последовательность обработки Что позволяет нам не только искать слова, но части речи,
- 4. Создаем индексированную БД При создании индексов тесты м.б. автоматически разбиты на единицы, но чтобы иметь информацию
- 5. У БД есть два вида
- 6. Внимание Если корпус сохранен в одном представлении, нельзя его сохранить в другом
- 7. Простой поиск Слово или фраза для поиска Сколько результатов отображать на одной странице Размер контекста
- 8. Что можно найти
- 9. Теперь чуть сложнее Можно задавать паттерны, как в правилах JAPE Например Вместо not a happy {Token.string=="not"}{Token=="a"}{Token=="happy"}
- 10. Можно экспортировать результаты
- 11. Применение в лабораторной работе 8 Проанализировать частоты встречаемости прилагательных, глаголов и т.д. Проанализировать частоты встречаемости грамматических
- 12. Mutual Information Criteria Делаем два корпуса БД – выбранное настроение и все другие Тогда можно выбрать
- 13. Расчет MIC Встречаемость считается по всей коллекции, а для расчета MIC требуется знать в скольких документах
- 15. Скачать презентацию
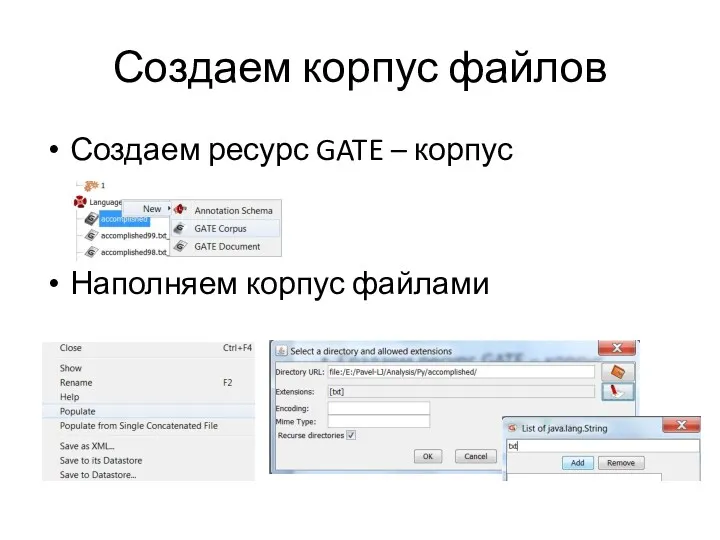
Создаем корпус файлов
Создаем ресурс GATE – корпус
Наполняем корпус файлами
Создаем корпус файлов
Создаем ресурс GATE – корпус
Наполняем корпус файлами

Обрабатываем корпус
Создаем стандартную последовательность обработки
Что позволяет нам не только искать
Обрабатываем корпус
Создаем стандартную последовательность обработки
Что позволяет нам не только искать
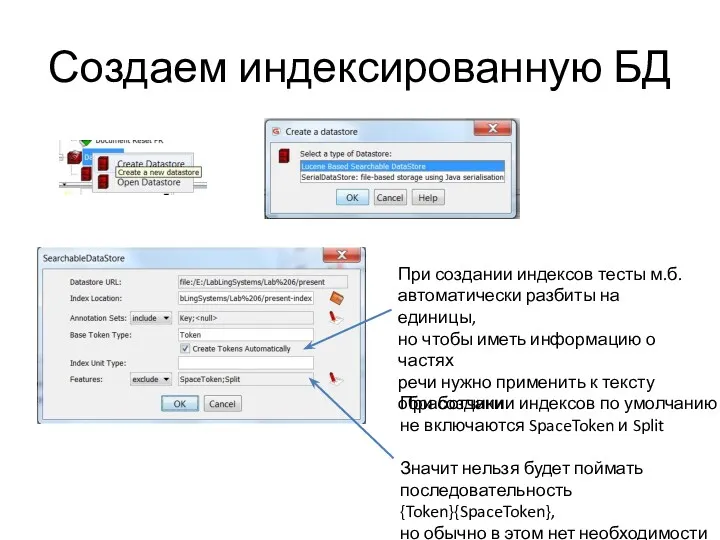
Создаем индексированную БД
При создании индексов тесты м.б.
автоматически разбиты на единицы,
но
Создаем индексированную БД
При создании индексов тесты м.б.
автоматически разбиты на единицы,
но
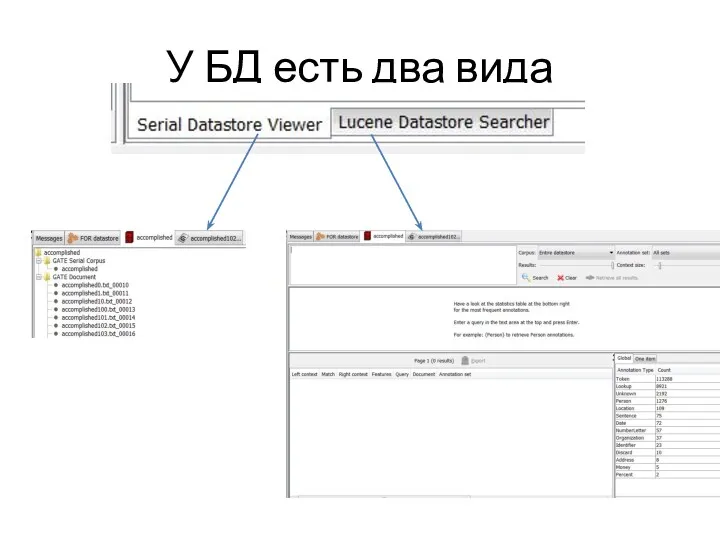
У БД есть два вида
У БД есть два вида
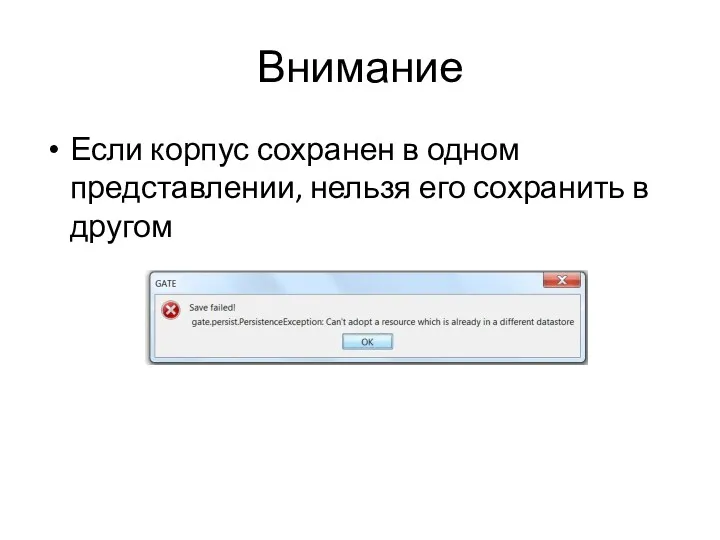
Внимание
Если корпус сохранен в одном представлении, нельзя его сохранить в другом
Внимание
Если корпус сохранен в одном представлении, нельзя его сохранить в другом
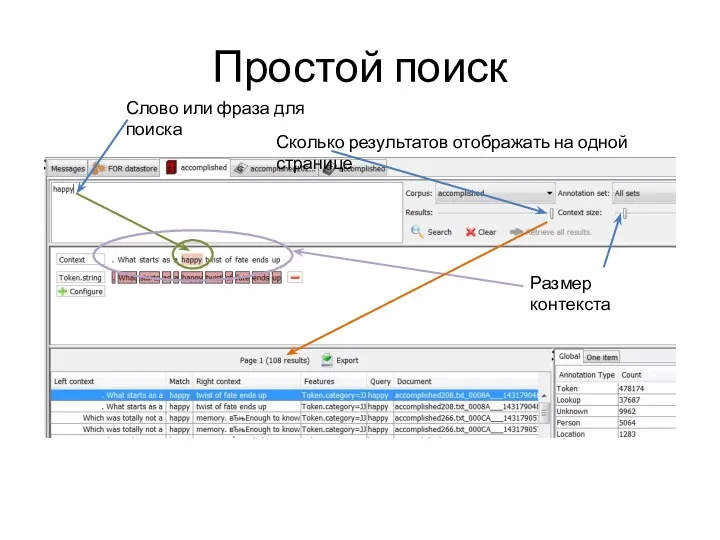
Простой поиск
Слово или фраза для поиска
Сколько результатов отображать на одной
Простой поиск
Слово или фраза для поиска
Сколько результатов отображать на одной
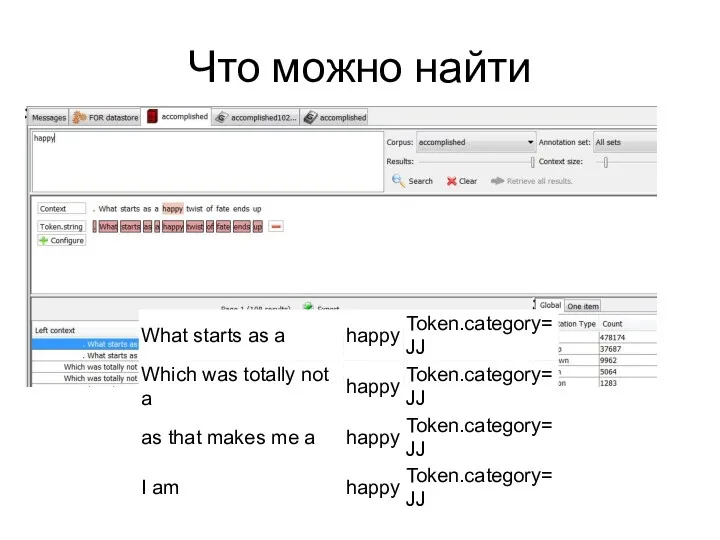
Что можно найти
Что можно найти

Теперь чуть сложнее
Можно задавать паттерны, как в правилах JAPE
Например
Вместо
not a
Теперь чуть сложнее
Можно задавать паттерны, как в правилах JAPE
Например
Вместо
not a
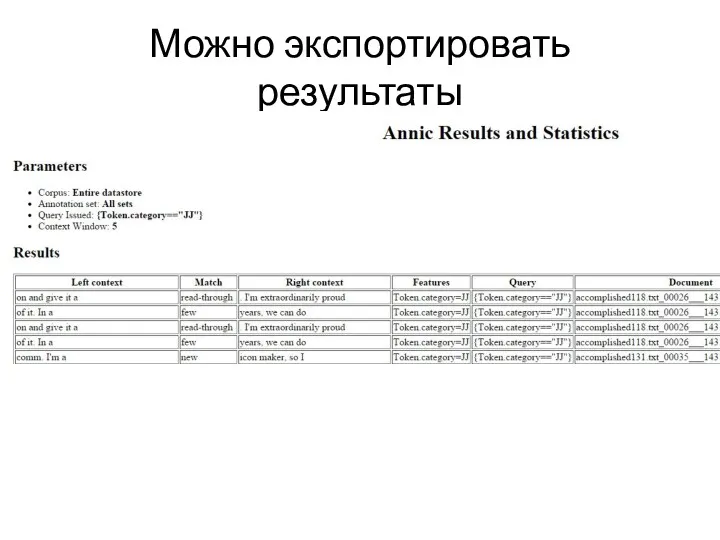
Можно экспортировать результаты
Можно экспортировать результаты

Применение в
лабораторной работе 8
Проанализировать частоты встречаемости прилагательных, глаголов и т.д.
Проанализировать
Применение в
лабораторной работе 8
Проанализировать частоты встречаемости прилагательных, глаголов и т.д.
Проанализировать

Mutual Information Criteria
Делаем два корпуса БД – выбранное настроение и
Mutual Information Criteria
Делаем два корпуса БД – выбранное настроение и

Расчет MIC
Встречаемость считается по всей коллекции, а для расчета MIC требуется
Расчет MIC
Встречаемость считается по всей коллекции, а для расчета MIC требуется
 Браузер - программа для просмотра web-сайтов
Браузер - программа для просмотра web-сайтов Алгоритм работы с программой Photo Booth (авторская работа)
Алгоритм работы с программой Photo Booth (авторская работа) Язык С++: новые возможности. (Лекция 1)
Язык С++: новые возможности. (Лекция 1) Java OOP/OOD concepts
Java OOP/OOD concepts Процессы обработки информации в информационных технологиях
Процессы обработки информации в информационных технологиях Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Місце Юзабіліті в процесі розробки
Місце Юзабіліті в процесі розробки Моя будущая профессия - веб-дизайнер
Моя будущая профессия - веб-дизайнер Multimedia technology. Lecture №11
Multimedia technology. Lecture №11 Системи управління базами даних. Звіти. Призначення та режими роботи зі звітами. Створення звітів
Системи управління базами даних. Звіти. Призначення та режими роботи зі звітами. Створення звітів Знакомство с графическим оператором DRAW
Знакомство с графическим оператором DRAW Текстовый редактор Microsoft Word. Основные возможности и назначение
Текстовый редактор Microsoft Word. Основные возможности и назначение Робота з поштовим клієнтом
Робота з поштовим клієнтом Інформаційні процеси та системи. Роль інформаційних технологій у житті сучасної людини
Інформаційні процеси та системи. Роль інформаційних технологій у житті сучасної людини Многокритериальная оптимизация
Многокритериальная оптимизация Техническое обслуживание, тестирование и аппаратно-программное конфигурирование компьютерного комплекса сотрудника отдела
Техническое обслуживание, тестирование и аппаратно-программное конфигурирование компьютерного комплекса сотрудника отдела Научная электронная библиотека
Научная электронная библиотека Основы алгоритмизации и программирования. Функции. Простые функции
Основы алгоритмизации и программирования. Функции. Простые функции Процессор - основное устройство обработки информации
Процессор - основное устройство обработки информации Как продвигать свой бизнес без сложных настроек
Как продвигать свой бизнес без сложных настроек Кіберзлочинність
Кіберзлочинність Доступ к данным при помощи Entity Framework
Доступ к данным при помощи Entity Framework Текстовый редактор Microsoft Word
Текстовый редактор Microsoft Word מערכות הפעלה
מערכות הפעלה Пользовательский интерфейс и его разновидности
Пользовательский интерфейс и его разновидности Цикл Счетчик в среде NXT Programming
Цикл Счетчик в среде NXT Programming Оператор цикла While. ОТП, 6 класс, урок 2
Оператор цикла While. ОТП, 6 класс, урок 2 Базы данных и SQL. Семинар 5
Базы данных и SQL. Семинар 5