- Как мы храним большой социальный граф

Содержание
- 2. План доклада Что мы решали с помощью графовых БД Графовые БД Neo4J и Sparksee Настройка и
- 3. Графы везде Применяются во многих сферах: веб-ссылки; маршруты; социальные сети; и т.д. Имеют очень большой объем.
- 4. Графовое хранилище
- 5. Решаемые задачи Загрузка графа Выполнение аналитической операции Догрузка новых данных, в случае их появления
- 6. Аналитические задачи Получить всех соседей вершины (Neighbors) Выполнить обход графа (BFS) Найти кратчайший путь (Shortest path)
- 7. Neo4J Наиболее распространенная Развитое сообщество Высокая функциональность Может быть как серверным приложением, так и встраиваемым Есть
- 8. Особенности Neo4J Все операции только внутри транзакции – правильно и надежно, но медленно и ест много
- 9. BatchInserter Быстрый импорт НЕ отказоустойчивый НЕ потокобезопасный
- 10. Индексирование Новый метод schema.indexFor() – только по атрибутам на вершинах Устаревший метод graphDb.index() – и по
- 11. Memory mapped cache Служит для ускорения I/O Проецирует файлы хранилища в память Каждому файлу свой кэш
- 12. Размеры объектов на диске Cache size = размер объекта * количество объектов
- 13. Настройки memory mapped cache use_memory_mapped_buffers mapped_memory nodestore.db.mapped_memory relationshipstore.db.mapped_memory propertystore.db.mapped_memory и т.д.
- 14. Object cache Хранит в себе объекты для быстрого доступа при обходах графа Вытеснение объектов осуществляет GC
- 15. Типы Object cache
- 16. Sparksee (в прошлом DEX) Заявлена высокая производительность Только встраиваемая Не столь распространенная Сообщество очень маленькое Полностью
- 17. Особенности Sparksee Обязательно задается схема данных Доступ к объекту только по внутреннему идентификатору
- 18. Настройки Sparksee Настройки ребер: Ориентированные Индексированные Типы атрибутов: Обычный Индексированный Уникальный
- 19. Sparksee cache Настройки кэширования минимальны Все новые объекты попадают в кэш SetCacheMaxSize(int megabytes) Если megabytes ==
- 20. Тестовый стенд Intel Xeon E7540 2.0 GHz 64GB DDR3 2x2TB hard drive
- 21. ПО и настройки Neo4J Neo4J 2.1.5 Community Edition Ubuntu 14.04 LTS JVM: -d64 –Xmx40G -XX:+UseParallelGC Batch
- 22. ПО и настройки Sparksee Sparksee 5.1.0 Unlimited licence Windows Server 2008 x64 .NET API Cache size
- 23. Время импорта данных (ч)
- 24. Время обработки графа (с) ~10 миллионов вершин и ~100 миллионов ребер
- 25. Время обработки графа (с) ~50 миллионов вершин и ~500 миллионов ребер
- 26. Выводы Sparksee производительнее Neo4J Высокая производительность графовых БД ограничивается размером памяти Графы размером больше 1 млрд
- 28. Скачать презентацию

План доклада
Что мы решали с помощью графовых БД
Графовые БД Neo4J и
План доклада
Что мы решали с помощью графовых БД
Графовые БД Neo4J и

Графы везде
Применяются во многих сферах:
веб-ссылки;
маршруты;
социальные сети;
и т.д.
Имеют очень большой
Графы везде
Применяются во многих сферах:
веб-ссылки;
маршруты;
социальные сети;
и т.д.
Имеют очень большой
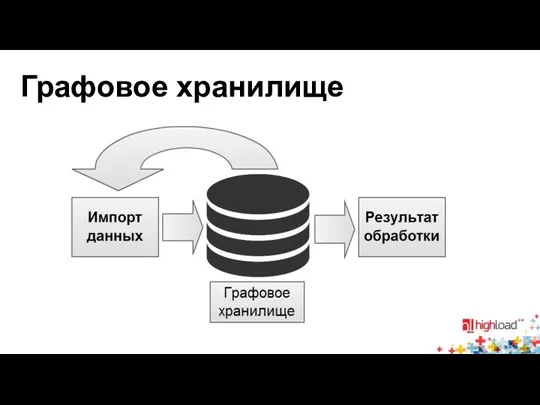
Графовое хранилище
Графовое хранилище

Решаемые задачи
Загрузка графа
Выполнение аналитической операции
Догрузка новых данных, в случае их
Решаемые задачи
Загрузка графа
Выполнение аналитической операции
Догрузка новых данных, в случае их

Аналитические задачи
Получить всех соседей вершины (Neighbors)
Выполнить обход графа (BFS)
Найти кратчайший путь
Аналитические задачи
Получить всех соседей вершины (Neighbors)
Выполнить обход графа (BFS)
Найти кратчайший путь

Neo4J
Наиболее распространенная
Развитое сообщество
Высокая функциональность
Может быть как серверным приложением, так и встраиваемым
Есть
Neo4J
Наиболее распространенная
Развитое сообщество
Высокая функциональность
Может быть как серверным приложением, так и встраиваемым
Есть

Особенности Neo4J
Все операции только внутри транзакции – правильно и надежно, но
Особенности Neo4J
Все операции только внутри транзакции – правильно и надежно, но

BatchInserter
Быстрый импорт
НЕ отказоустойчивый
НЕ потокобезопасный
BatchInserter
Быстрый импорт
НЕ отказоустойчивый
НЕ потокобезопасный

Индексирование
Новый метод schema.indexFor() – только по атрибутам на вершинах
Устаревший метод graphDb.index()
Индексирование
Новый метод schema.indexFor() – только по атрибутам на вершинах
Устаревший метод graphDb.index()

Memory mapped cache
Служит для ускорения I/O
Проецирует файлы хранилища в память
Каждому файлу
Memory mapped cache
Служит для ускорения I/O
Проецирует файлы хранилища в память
Каждому файлу

Размеры объектов на диске
Cache size = размер объекта * количество объектов
Размеры объектов на диске
Cache size = размер объекта * количество объектов

Настройки memory mapped cache
use_memory_mapped_buffers
mapped_memory
nodestore.db.mapped_memory
relationshipstore.db.mapped_memory
propertystore.db.mapped_memory
и т.д.
Настройки memory mapped cache
use_memory_mapped_buffers
mapped_memory
nodestore.db.mapped_memory
relationshipstore.db.mapped_memory
propertystore.db.mapped_memory
и т.д.

Object cache
Хранит в себе объекты для быстрого доступа при обходах графа
Вытеснение
Object cache
Хранит в себе объекты для быстрого доступа при обходах графа
Вытеснение

Типы Object cache
Типы Object cache

Sparksee (в прошлом DEX)
Заявлена высокая производительность
Только встраиваемая
Не столь распространенная
Сообщество очень маленькое
Полностью
Sparksee (в прошлом DEX)
Заявлена высокая производительность
Только встраиваемая
Не столь распространенная
Сообщество очень маленькое
Полностью

Особенности Sparksee
Обязательно задается схема данных
Доступ к объекту только по внутреннему идентификатору
Особенности Sparksee
Обязательно задается схема данных
Доступ к объекту только по внутреннему идентификатору

Настройки Sparksee
Настройки ребер:
Ориентированные
Индексированные
Типы атрибутов:
Обычный
Индексированный
Уникальный
Настройки Sparksee
Настройки ребер:
Ориентированные
Индексированные
Типы атрибутов:
Обычный
Индексированный
Уникальный

Sparksee cache
Настройки кэширования минимальны
Все новые объекты попадают в кэш
SetCacheMaxSize(int megabytes)
Если megabytes
Sparksee cache
Настройки кэширования минимальны
Все новые объекты попадают в кэш
SetCacheMaxSize(int megabytes)
Если megabytes

Тестовый стенд
Intel Xeon E7540 2.0 GHz
64GB DDR3
2x2TB hard drive
Тестовый стенд
Intel Xeon E7540 2.0 GHz
64GB DDR3
2x2TB hard drive

ПО и настройки Neo4J
Neo4J 2.1.5 Community Edition
Ubuntu 14.04 LTS
JVM: -d64 –Xmx40G
ПО и настройки Neo4J
Neo4J 2.1.5 Community Edition
Ubuntu 14.04 LTS
JVM: -d64 –Xmx40G

ПО и настройки Sparksee
Sparksee 5.1.0 Unlimited licence
Windows Server 2008 x64
.NET API
Cache
ПО и настройки Sparksee
Sparksee 5.1.0 Unlimited licence
Windows Server 2008 x64
.NET API
Cache
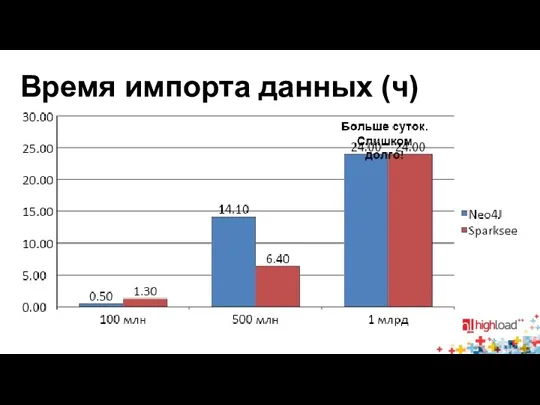
Время импорта данных (ч)
Время импорта данных (ч)
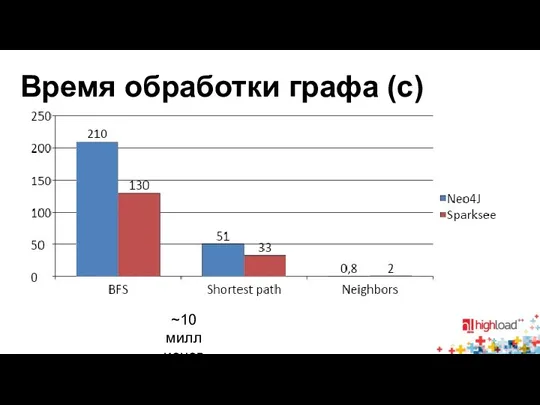
Время обработки графа (с)
~10 миллионов вершин и ~100 миллионов ребер
Время обработки графа (с)
~10 миллионов вершин и ~100 миллионов ребер
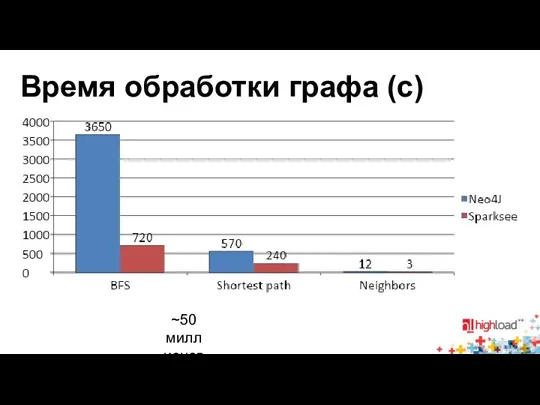
Время обработки графа (с)
~50 миллионов вершин и ~500 миллионов ребер
Время обработки графа (с)
~50 миллионов вершин и ~500 миллионов ребер

Выводы
Sparksee производительнее Neo4J
Высокая производительность графовых БД ограничивается размером памяти
Графы размером больше
Выводы
Sparksee производительнее Neo4J
Высокая производительность графовых БД ограничивается размером памяти
Графы размером больше
 Инструменты распознования текстов и компьютерного перевода. Обработка текстовой информации
Инструменты распознования текстов и компьютерного перевода. Обработка текстовой информации Урок информатики(ФГОС)
Урок информатики(ФГОС) Информационно-технологический модуль. Overflow. Display. Псевдоэлементы 2019
Информационно-технологический модуль. Overflow. Display. Псевдоэлементы 2019 Работа с личным кабинетом
Работа с личным кабинетом презентация к уроку
презентация к уроку Информация. Основные подходы к определению информация. Философские концепции, виды и свойства информации
Информация. Основные подходы к определению информация. Философские концепции, виды и свойства информации Internet network. WiFi network
Internet network. WiFi network Информация – формы и способы ее представления в жизни человека
Информация – формы и способы ее представления в жизни человека Информационные технологии: понятие и виды
Информационные технологии: понятие и виды Аппаратная поддержка взаимоисключений
Аппаратная поддержка взаимоисключений Языки программирования. Основные понятия
Языки программирования. Основные понятия Информационные технологии в юридической деятельности
Информационные технологии в юридической деятельности Функции. Объявление функции
Функции. Объявление функции Алгоритмы и структуры данных. Лекция 1. Основные понятия
Алгоритмы и структуры данных. Лекция 1. Основные понятия устройство ввода информации
устройство ввода информации Применение информационных технологий в преподавании русского языка и литературы
Применение информационных технологий в преподавании русского языка и литературы Виды корпусов
Виды корпусов Презентация Отношения между понятиями 6 класс
Презентация Отношения между понятиями 6 класс Социальные сети. Обзор популярных проектов социальных сетей
Социальные сети. Обзор популярных проектов социальных сетей Знакозмінні ряди. Ознака Лейбніца
Знакозмінні ряди. Ознака Лейбніца Создание автоматизированного рабочего места для технического секретаря приемной комиссии ГБПОУ КК БАК Брюховецкого района
Создание автоматизированного рабочего места для технического секретаря приемной комиссии ГБПОУ КК БАК Брюховецкого района Информационно-коммуникационное обеспечение менеджмента
Информационно-коммуникационное обеспечение менеджмента Пристрої, що використовуються для роботи з повідомленнями
Пристрої, що використовуються для роботи з повідомленнями Основы JDBC (Java DataBase Connectivity)
Основы JDBC (Java DataBase Connectivity) Основные понятия в тестировании. Тестовые артефакты
Основные понятия в тестировании. Тестовые артефакты ELS – regional distributed integrated command and control system. Decision support sys
ELS – regional distributed integrated command and control system. Decision support sys Работа с поисковой строкой
Работа с поисковой строкой Поиск информации в интернете
Поиск информации в интернете