Конфигурации микросервисной архитектуры, шина данных, протоколы сообщений между сервисами. Лекция 4.1 презентация
- Конфигурации микросервисной архитектуры, шина данных, протоколы сообщений между сервисами. Лекция 4.1

Содержание
- 2. Виды архитектуры Простейший и популярный вариант архитекту-ры – монолитная. Каждый начинал с неё, и здесь нет
- 3. Проблемы: -отказоустойчивость; -горизонтальное масштабирование; -применение одной технологии или языка и невыгодность переписывать огромный монолит; -сложность рефакторинга
- 4. Второй по популярности вид архитектуры – па-ра монолитов, микс из монолита и сервисов или даже микросервисов.
- 5. Это частично решает проблемы отказоустойчивос-ти, масштабируемости и одного стека технологий. Сервис-ориентированная архи- тектура предусматривает модульность разра-ботки
- 6. Сервисно-ориентированная архитектура
- 7. Микросервисная архитектура – не новая идея, а раз-новидность сервис-ориентированной архитектуры. Микросервисная архитектура наследует от SOA изо-ляцию
- 8. Следующее преимущество – протоколы обнаружения сервисов. Наглядная разница коммуникаций сервис-ориентированной и микросервисной архитектуры: у последней нет
- 9. Выбор протоколов общения зависит от программис-та. Например, вы используете REST для публичных запросов и RPC через
- 10. Разделяют микросервисы с точки зрения либо бизнеса, либо программиста для переисполь-зования. Но мешают этому две вещи:
- 11. Пример разделения сервисов
- 12. Достоинства и недостатки микросервисной архитектуры: Как в любой распределённой архитектуре, по-лучим накладные расходы на коммуникацию. Концепция
- 13. Отказоустойчивость: Часто её определяют как «падение одного сервиса не отражается других». Представьте, падает Audit, а Wallet
- 14. А как же запросы по RPC, которые Wallet продолжает слать? Необходимо программно предусмотреть ситу-ацию, когда Audit
- 15. Или другая ситуация: падает микросервис авториза-ции, через который ходят другие. Чтобы продолжать обрабатывать запросы, добавляют код
- 16. Стандартный процесс разработки – кодинг, тестиро-вание и развёртывание – в микросервисной архитек-туре выглядит иначе. Первые два
- 17. Локально разработчик проводит юнит-тестирование, где вместо ответов микросервисов будут mock-объек-ты. Ещё понадобятся функциональные тесты, например, для
- 18. Тестирование микросервисов
- 19. Микросервисная архитектура делает компо-ненты независимыми при разработке и раз-вёртывании, чего не было в монолите. Микросервисы используются
- 20. Контроль зависимостей Трудно сопроводить и поддерживать 50 проектов с 50 репозиториями, если вдруг обнаружится проблема безопасности,
- 21. Контроль зависимостей
- 22. Базы данных Поскольку базы данных в микросервисной архитек-туре изолированные, вы используете разные их виды одновременно и
- 23. Вот возможные решения проблемы: -храните одно и то же значение в двух микросерви-сах, но появляются трудности
- 24. Внутренняя коммуникация в микросервисной архитектуре Для общения микросервисам нужен контракт: протокол и валидация данных. С последним
- 25. В качестве протоколов используют Protocol Buffers, FlatBuffers, Apache Thrift. Сначала вы пишете пред-метно-ориентированный язык, отдаёте это
- 26. Организация работы в команде Команды делят по технологиям и следят за их разме-рами (не более 7–8
- 27. Устройство микросервисов Микросервисы состоят из трёх слоёв: небольших об-работчиков, бизнес-логики и мапперов данных. В сервисном слое
- 28. Последовательность выполнения запроса
- 29. Заключение Принимайте решение об использовании микросер-висной архитектуры, только чётко осознав и взвесив все достоинства и недостатки.
- 30. Необходимость использования Шины Данных (Enterprise Service Bus, ESB) По мере развития любой компании появляются новые бизнес-процессы,
- 31. Многообразие IT систем на предприятии
- 32. В начале 2000 годов на рынке программного обеспе-чения стали появляться решения, сформировавшие кластер под названием Сервисная
- 33. Enterprise Service Bus (ESB)
- 34. Архитектура ESB строится на 3 компонентах: -набор коннекторов; -очередь сообщений; -платформа. Коннекторы используются для подключения к
- 35. Платформа обеспечивает связь коннекторов с оче-редью, а также организацию асинхронной передачи информации между источниками и приемниками
- 36. К основным преимуществам современных ESB-решений относятся: -широкий набор коннекторов и масштабируемость решения; -гибкая маршрутизация данных; -гарантированная
- 37. К настоящему времени на рынке представлено более двух десятков шин данных, однако наибольшее распространение получили следующие
- 38. Red hat JBoss Developer Studio
- 39. Внедрение Шины Данных в IT-ландшафт организации позволяет не только структурировать, привести к еди-ному стандарту и упростить
- 40. Протоколы сообщений между сервисами В каждой отрасли бизнеса, каждой компании, исполь-зуется разнообразнейшее ПО. За десятилетия сущест-вования
- 41. Веб-сервисы (или веб-службы) — это технология, поз-воляющая системам обмениваться данными друг с другом через сетевое подключение.
- 42. Самые известные способы реализации веб-сервисов: -XML-RPC (XML Remote Procedure Call) — протокол удаленного вызова процедур с
- 43. SOAP SOAP (Simple Object Access Protocol) — Данные передаются в формате XML. Преимущества: -отраслевой стандарт по
- 44. Любое сообщение в протоколе SOAP — это XML доку-мент, состоящий из следующих элементов (тегов): Envelope. Корневой
- 45. Пример SOAP запроса
- 46. Пример SOAP ответа
- 47. REST REST (Representational State Transfer) — на самом деле архитектурный стиль, а не протокол. В отличие
- 48. REST не использует конвертацию данных при переда-че, данные передаются в исходном виде — это снижа-ет нагрузку
- 49. Использование этих методов позволяет реализовать типичный CRUD (Create/Read/Update/Delete) для любой информации. Но это лишь соглашение: часто
- 50. Преимущества: -простота реализации; -экономичность в плане ресурсов; -не требует программных надстроек (json_decode есть почти в каждом
- 51. Пример REST запроса
- 52. Пример REST ответа
- 53. SOAP используется в крупных корпоративных систе-мах со сложной логикой, когда требуются четкие стандарты, подкрепленные временем. XML-RPC
- 54. ЛЕКЦИЯ 4_2. ОРКЕСТРАЦИЯ, ОБНАРУЖЕ-НИЕ МИКРОСЕРВИСОВ, K&S. Оркестровка представляет собой единый централизованный исполняемый бизнес-процесс (Orchestrator), который координиру-ет
- 55. В сервис-ориентированной архитектуре оркестровка сервисов реализуется согласно стандарту Business Process Execution Language (WS-BPEL). ... Хореография описывает
- 56. Оркестровка относится к исполняемому процессу, а хореография позволяет отслеживать последова-тельности сообщений его участников На рисунке в
- 57. Оркестровка относится к исполняемому бизнес-про-цессу, который может взаимодействовать с внешни-ми и внутренними Web-сервисами. Взаимодействия на основе
- 58. Системы обнаружения сервисов автоматизируют процесс, позволяя получить ответ на вопрос, где ра-ботает нужный сервис, и изменить
- 59. На сегодня существует несколько решений, реализу-ющих хранение информации об инфраструктуре, — как относительно сложных, использующих key/value-хранилище
- 60. Стандарты оркестровки и хореографии должны удовлетворять ряду технических требований, обеспечивающих разработку бизнес-процессов с привлечением Web-сервисов. Эти
- 61. Во-первых, для обеспечения надежности и универ-сальности, необходимых современным вычислитель-ным средам, важна возможность асинхронного обра-щения к сервису.
- 62. Кроме обработки ошибок и тайм-аутов оркестрован-ные Web-сервисы должны гарантировать доступность ресурсов при выполнении длительных распределен-ных транзакций.
- 63. В-третьих, оркестровка Web-сервисов должна быть динамичной, гибкой и адаптивной, чтобы отвечать изменяющимся потребностям бизнеса. Достижению гибкости
- 64. Если в традиционных вариантах сервис-ориентиро-ванной архитектуры модули могут быть сами по себе достаточно сложными программными системами,
- 65. Свойства, характерные для микросервисной архи-тектуры: – модули можно легко заменить в любое время: акцент на простоту,
- 66. -модули могут быть реализованы с использованием различных языков программирования, фреймвор-ков, связующего программного обеспечения, выпол-няться в различных
- 67. Наиболее популярная среда для выполнения микро-сервисов — системы управления контейнеризован-ными приложениями (такие как Kubernetes и её
- 68. В последнее время получили развитие альтернатив-ные подходы к созданию веб-сервисов, основанные на архитектурном стиле REST («RESTful-веб-серви-сов»).
- 69. Технология работы процессно-ориентированной аналитической системы.
- 70. От микросервисного монолита к оркестратору Когда компании решают разделить монолит на микросервисы, в большинстве случаев они
- 71. Четыре этапа перехода от монолита к микросервисам
- 72. Этап №1. Монолит 1.1 Характеристики Обычно монолитную архитектуру можно описать так: -Единая точка разработки и деплоя;
- 73. Монолитное приложение
- 74. Как перейти на следующий этап В основе процесса выделения микросервисов лежит вынесение бизнес-задач из монолита в
- 75. Постепенно у вас образуется набор из микросерви-сов, где каждый отвечает лишь за свою бизнес-задачу
- 76. Этап №2. Микросервисный монолит Характеристики Все части монолита стали независимыми микросер-висами и эти микросервисы должны общаться
- 77. Получается, что все части монолита распались на микросервисы, а их обратно соединили паутиной синхронных и асинхронных
- 78. Проблемы -Прямые связи между микросервисами усложняют анализ проблем. Например, запрос может пройти че-рез 5 микросервисов, прежде,
- 79. -Архитектуру сложно понять и, чем больше сервисов вы добавляете, тем запутанней всё становится. В це-лом, добавление
- 80. Как перейти на следующий этап Основные идеи: локализовать точки интеграции и контролировать все потоки данных. Чтобы
- 81. Этап №3. Микросервисы Характеристики Микросервисы ничего не знают о существовании друг друга: работают со своей базой
- 82. Становится заметна главная черта хорошей архитек-туры: сложность системы растет линейно с увеличе-нием количества микросервисов.
- 83. Проблемы На этом этапе сложные технические задачи решены, поэтому начинаются проблемы на уровне бизнес-задач: Среди сотен
- 84. Бизнес хочет увидеть лес за деревьями, чтобы пони-мать, какие есть детали и как из них можно
- 85. Тем, кто решают двигаться дальше: Изучите концепцию Citizen Integrator. Для наглядного примера заведите себе пару процессов
- 87. Переход к заключительному этапу
- 88. Этап №4. Оркестратор бизнес-сервисов Характеристики Оркестратор бизнес-сервисов обычно является визу-альной платформой, где соединяются сервисы, выс-тавляются триггеры
- 89. На этом этапе можете решить задачу создания продукта в визуальном редакторе. Если нужных "квадратиков" не хватает,
- 90. Создание нового продукта
- 91. Проблемы -Создание, внедрение и развитие оркестратора бизнес-процессов является дорогим удовольствием. -Если ослабить архитектурный контроль, оркестратор может
- 92. Эти четыре этапа показывают естественный ход вещей: - Вначале приложение небольшое и решает одну бизнес-задачу. Со
- 93. При первой попытке разделить монолит многие ко-манды не готовы к возрастающей сложности. Монолит делится на много
- 94. Когда сложности решаются, получается стройная и масштабируемая архитектура. Добавление новых микросервисов линейно повышает сложность. На последнем
- 95. Kubernetes (K8s) – это программное обеспечение для автоматизации развёртывания, масштабирова-ния и управления контейнеризированными прило-жениями. Поддерживает основные
- 96. Kubernetes необходим для непрерывной интегра-ции и поставки программного обеспечения (CI/CD, Continuos Integration/ Continuos Delivery), что соответ-ствует
- 97. Однако, если необходим сложный порядок запуска большого количества таких контейнеров (от несколь-ких тысяч), как это бывает
- 98. АРХИТЕКТУРА КУБЕРНЕТИС Kubernetes устроен по принципу master/slave, когда ведущим элементом является подсистема управления кластером, а некоторые
- 99. Также на узлах развернуты поды (pods) — базовые модули управления и запуска приложений, состоя-щие из одного
- 100. Помимо подов, на ведомых узлах также работают следующие компоненты Kubernetes: -Kube-proxy – комбинация сетевого прокси-серве-ра и
- 101. Управление подами реализуется через АPI Kubernetes, интерфейс командной строки (Kubectl) или специали-зированные контроллеры (controllers) – процессы,
- 102. На ведущем компоненте (master) работают следу-ющие элементы: -Etcd - легковесная распределённая NoSQL-СУБД класса «ключ-значение», которая отвечает
- 103. -Планировщик (scheduler), который регулирует рас-пределение нагрузки по узлам, выбирая узел выпол-нения для конкретного пода в зависимости
- 104. Архитектура Kubernetes
- 105. В Kubernetes контейнер – это программный компо-нент самого низкого уровня абстракции. Для меж-процессного взаимодействия нескольких контей-неров
- 106. Что особенно важно для Big Data проектов, Kubelet – компонент Kubernetes, работающий на уз-лах, автоматически обеспечивает
- 107. Аналогично HDFS, наиболее популярной распреде-ленной файловой системе для Big Data-решений, реализованной в Apache Hadoop, в кластере
- 108. Принципы работы Kubernetes
- 109. ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ КУБЕРНЕТИС Поскольку K8s предназначен для управления мно-жеством контейнеризированных микросервисов, не-удивительно, что эта технология приносит
- 110. В связи с цифровизацией предприятий и распрост-ранением DevOps-подхода, спрос на владение Kubernetes растет и в отечественных
- 111. Docker — программное обеспечение для автоматиза-ции развёртывания и управления приложениями в средах с поддержкой контейнеризации, контейнери-затор
- 112. С появлением Open Container Initiative начался пере-ход от монолитной к модульной архитектуре. Разрабатывается и поддерживается одноимённой
- 113. Docker на физическом Linux-сервере
- 114. Программное обеспечение функционирует в среде Linux с ядром, поддерживающим контрольные группы и изоляцию пространств имён (namespaces);
- 117. Скачать презентацию

Виды архитектуры
Простейший и популярный вариант архитекту-ры – монолитная. Каждый начинал с неё,
Виды архитектуры
Простейший и популярный вариант архитекту-ры – монолитная. Каждый начинал с неё,

Проблемы:
-отказоустойчивость;
-горизонтальное масштабирование;
-применение одной технологии или языка и невыгодность переписывать огромный монолит;
-сложность
Проблемы:
-отказоустойчивость;
-горизонтальное масштабирование;
-применение одной технологии или языка и невыгодность переписывать огромный монолит;
-сложность
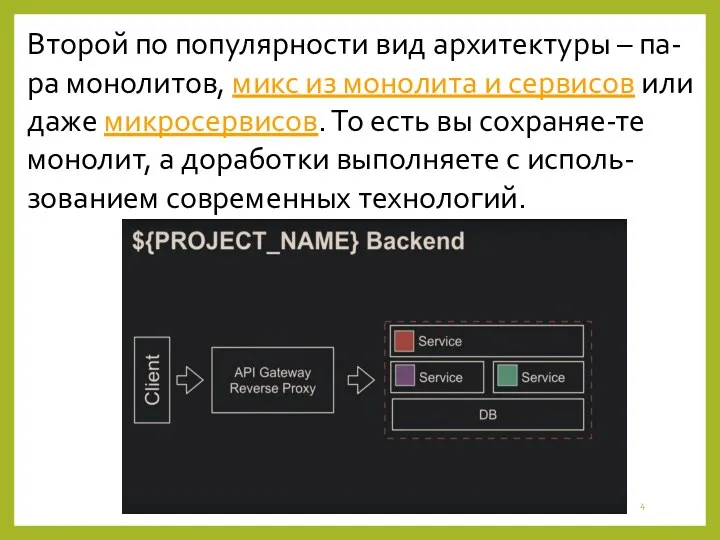
Второй по популярности вид архитектуры – па-ра монолитов, микс из монолита и
Второй по популярности вид архитектуры – па-ра монолитов, микс из монолита и

Это частично решает проблемы отказоустойчивос-ти, масштабируемости и одного стека технологий.
Сервис-ориентированная архи-
тектура предусматривает
Это частично решает проблемы отказоустойчивос-ти, масштабируемости и одного стека технологий. Сервис-ориентированная архи- тектура предусматривает
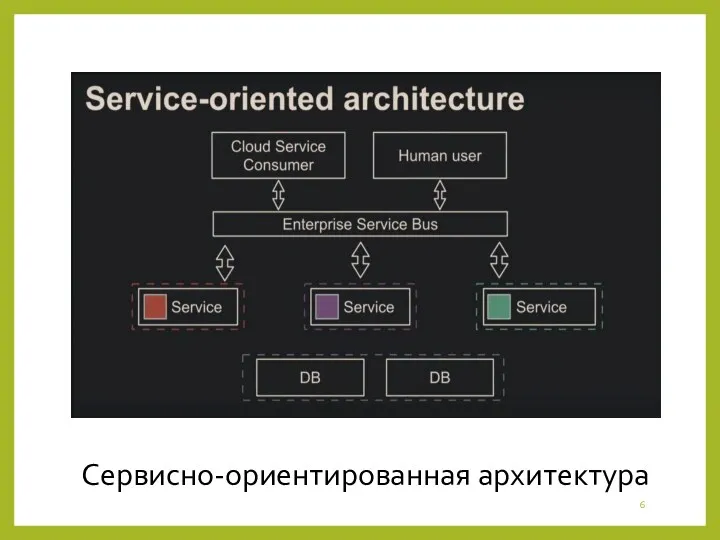
Сервисно-ориентированная архитектура
Сервисно-ориентированная архитектура

Микросервисная архитектура – не новая идея, а раз-новидность сервис-ориентированной архитектуры.
Микросервисная архитектура
Микросервисная архитектура – не новая идея, а раз-новидность сервис-ориентированной архитектуры.
Микросервисная архитектура
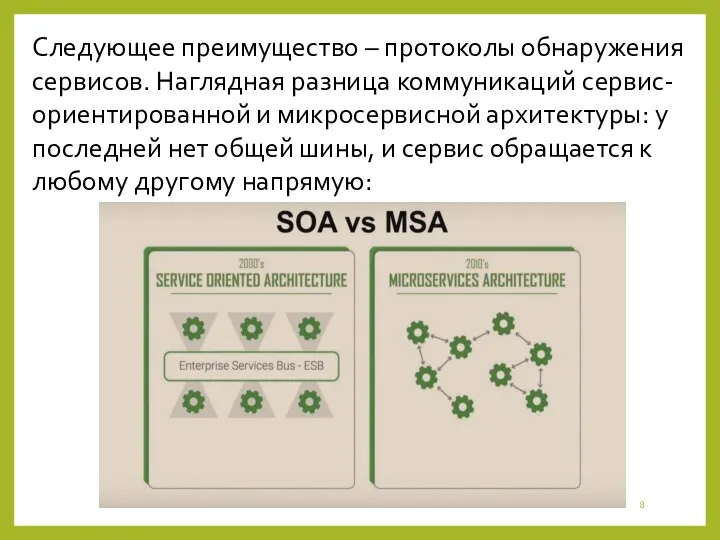
Следующее преимущество – протоколы обнаружения сервисов. Наглядная разница коммуникаций сервис-ориентированной и микросервисной
Следующее преимущество – протоколы обнаружения сервисов. Наглядная разница коммуникаций сервис-ориентированной и микросервисной
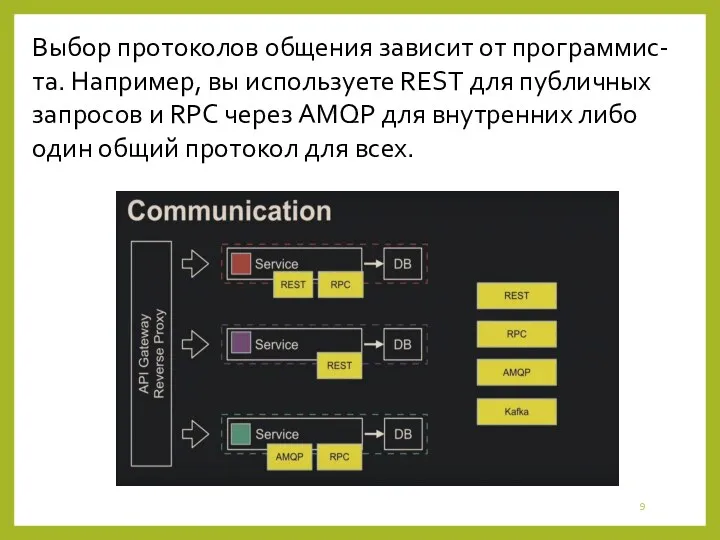
Выбор протоколов общения зависит от программис-та. Например, вы используете REST для
Выбор протоколов общения зависит от программис-та. Например, вы используете REST для

Разделяют микросервисы с точки зрения либо бизнеса, либо программиста для переисполь-зования.
Разделяют микросервисы с точки зрения либо бизнеса, либо программиста для переисполь-зования.
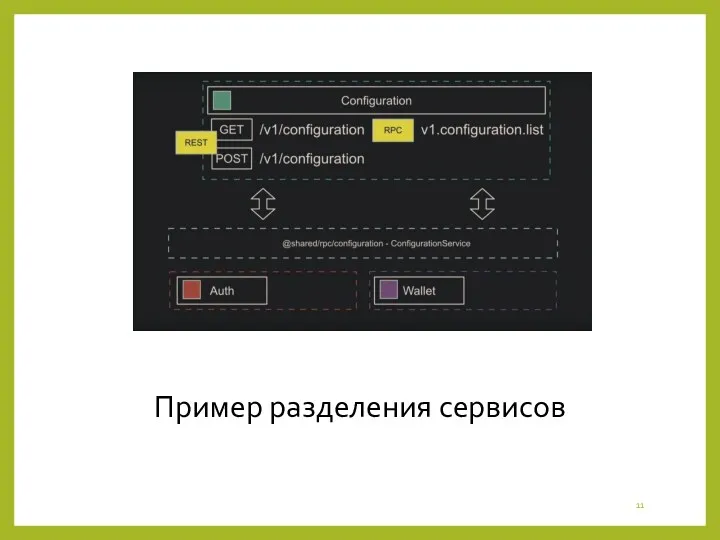
Пример разделения сервисов
Пример разделения сервисов

Достоинства и недостатки микросервисной архитектуры:
Как в любой распределённой архитектуре, по-лучим накладные
Достоинства и недостатки микросервисной архитектуры:
Как в любой распределённой архитектуре, по-лучим накладные
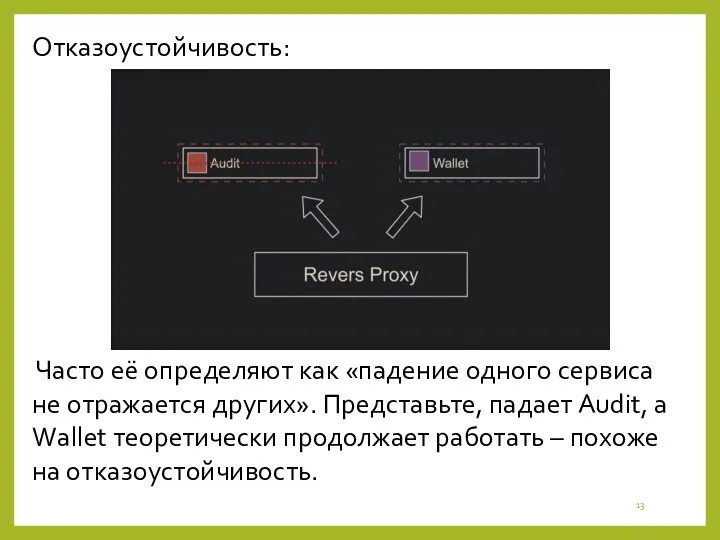
Отказоустойчивость:
Часто её определяют как «падение одного сервиса не отражается других».
Отказоустойчивость:
Часто её определяют как «падение одного сервиса не отражается других».
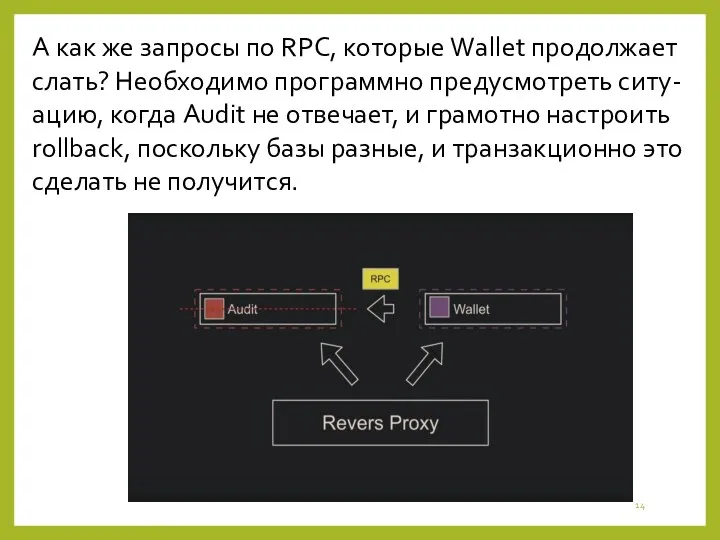
А как же запросы по RPC, которые Wallet продолжает слать? Необходимо программно предусмотреть
А как же запросы по RPC, которые Wallet продолжает слать? Необходимо программно предусмотреть
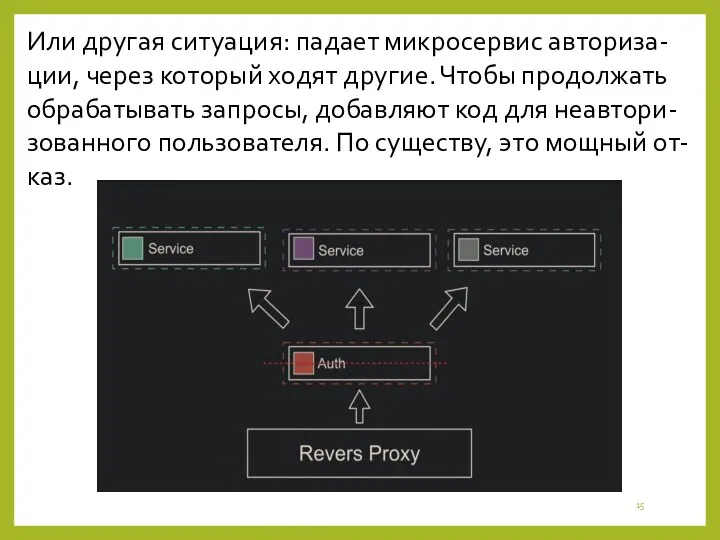
Или другая ситуация: падает микросервис авториза-ции, через который ходят другие. Чтобы
Или другая ситуация: падает микросервис авториза-ции, через который ходят другие. Чтобы
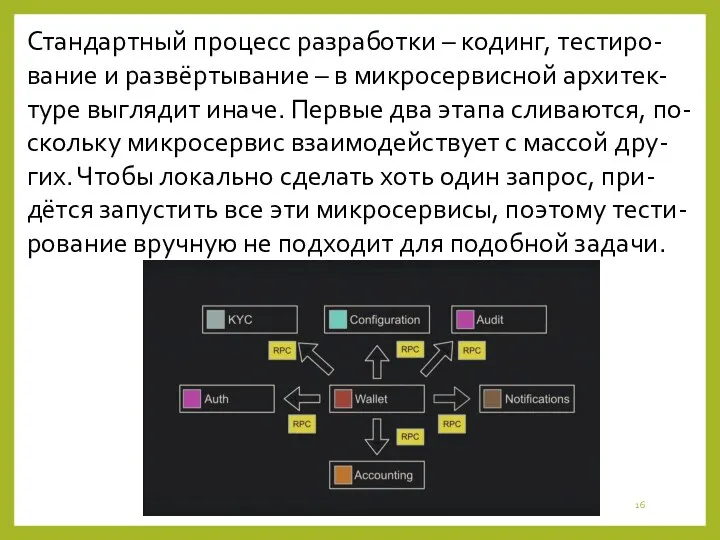
Стандартный процесс разработки – кодинг, тестиро-вание и развёртывание – в микросервисной
Стандартный процесс разработки – кодинг, тестиро-вание и развёртывание – в микросервисной

Локально разработчик проводит юнит-тестирование, где вместо ответов микросервисов будут mock-объек-ты.
Ещё
Локально разработчик проводит юнит-тестирование, где вместо ответов микросервисов будут mock-объек-ты.
Ещё

Тестирование микросервисов
Тестирование микросервисов

Микросервисная архитектура делает компо-ненты независимыми при разработке и раз-вёртывании, чего не
Микросервисная архитектура делает компо-ненты независимыми при разработке и раз-вёртывании, чего не

Контроль зависимостей
Трудно сопроводить и поддерживать 50 проектов с 50 репозиториями, если
Контроль зависимостей
Трудно сопроводить и поддерживать 50 проектов с 50 репозиториями, если

Контроль зависимостей
Контроль зависимостей

Базы данных
Поскольку базы данных в микросервисной архитек-туре изолированные, вы используете разные
Базы данных
Поскольку базы данных в микросервисной архитек-туре изолированные, вы используете разные

Вот возможные решения проблемы:
-храните одно и то же значение в двух
Вот возможные решения проблемы:
-храните одно и то же значение в двух

Внутренняя коммуникация в микросервисной архитектуре
Для общения микросервисам нужен контракт: протокол и
Внутренняя коммуникация в микросервисной архитектуре
Для общения микросервисам нужен контракт: протокол и
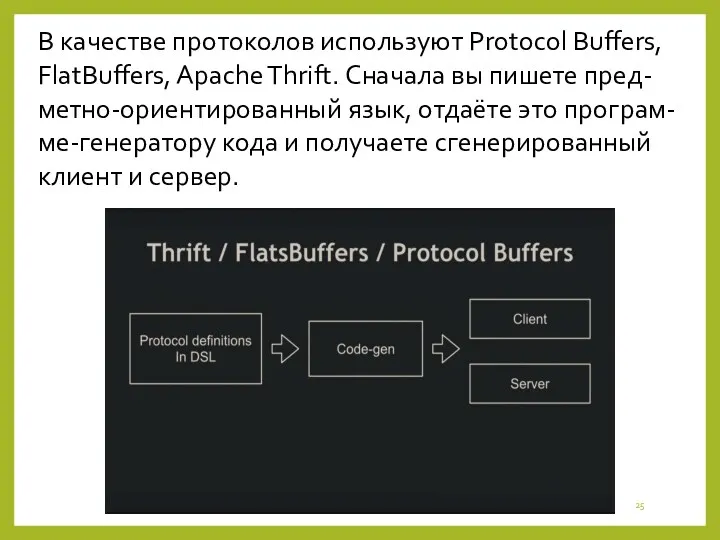
В качестве протоколов используют Protocol Buffers, FlatBuffers, Apache Thrift. Сначала вы
В качестве протоколов используют Protocol Buffers, FlatBuffers, Apache Thrift. Сначала вы

Организация работы в команде
Команды делят по технологиям и следят за их
Организация работы в команде
Команды делят по технологиям и следят за их

Устройство микросервисов
Микросервисы состоят из трёх слоёв: небольших об-работчиков, бизнес-логики и мапперов
Устройство микросервисов
Микросервисы состоят из трёх слоёв: небольших об-работчиков, бизнес-логики и мапперов
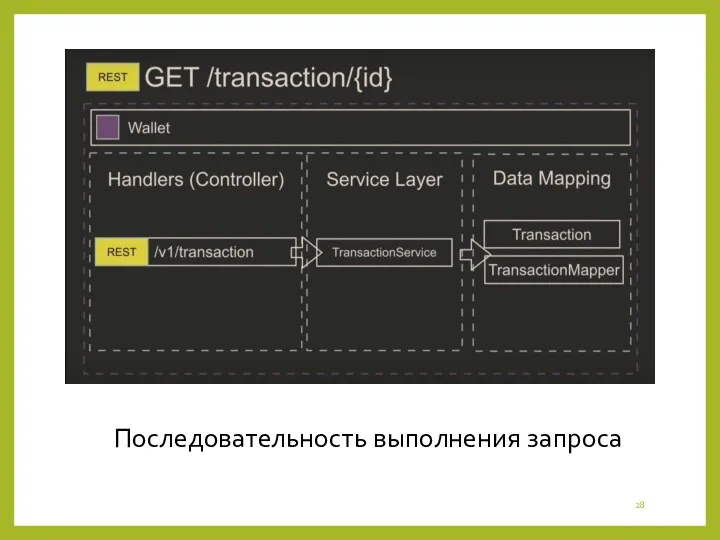
Последовательность выполнения запроса
Последовательность выполнения запроса

Заключение
Принимайте решение об использовании микросер-висной архитектуры, только чётко осознав и взвесив
Заключение
Принимайте решение об использовании микросер-висной архитектуры, только чётко осознав и взвесив

Необходимость использования Шины Данных
(Enterprise Service Bus, ESB)
По мере развития любой компании
Необходимость использования Шины Данных
(Enterprise Service Bus, ESB)
По мере развития любой компании
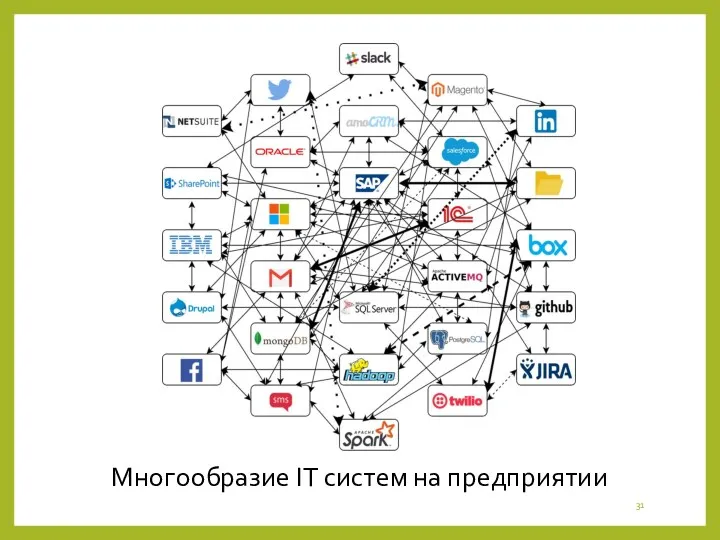
Многообразие IT систем на предприятии
Многообразие IT систем на предприятии

В начале 2000 годов на рынке программного обеспе-чения стали появляться решения,
В начале 2000 годов на рынке программного обеспе-чения стали появляться решения,
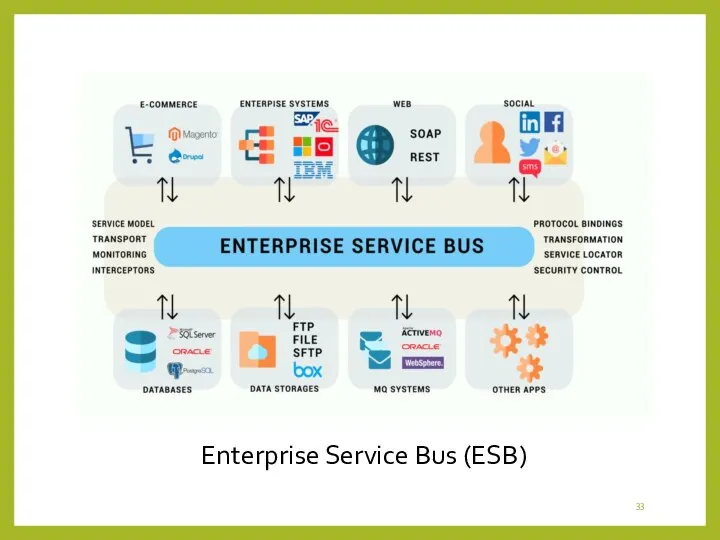
Enterprise Service Bus (ESB)
Enterprise Service Bus (ESB)

Архитектура ESB строится на 3 компонентах:
-набор коннекторов;
-очередь сообщений;
-платформа.
Коннекторы используются для подключения
Архитектура ESB строится на 3 компонентах:
-набор коннекторов;
-очередь сообщений;
-платформа.
Коннекторы используются для подключения

Платформа обеспечивает связь коннекторов с оче-редью, а также организацию асинхронной передачи
Платформа обеспечивает связь коннекторов с оче-редью, а также организацию асинхронной передачи

К основным преимуществам современных ESB-решений относятся:
-широкий набор коннекторов и масштабируемость решения;
-гибкая
К основным преимуществам современных ESB-решений относятся:
-широкий набор коннекторов и масштабируемость решения;
-гибкая

К настоящему времени на рынке представлено более двух десятков шин данных,
К настоящему времени на рынке представлено более двух десятков шин данных,
Red hat JBoss Developer Studio
Red hat JBoss Developer Studio

Внедрение Шины Данных в IT-ландшафт организации позволяет не только структурировать, привести
Внедрение Шины Данных в IT-ландшафт организации позволяет не только структурировать, привести

Протоколы сообщений между сервисами
В каждой отрасли бизнеса, каждой компании, исполь-зуется разнообразнейшее
Протоколы сообщений между сервисами
В каждой отрасли бизнеса, каждой компании, исполь-зуется разнообразнейшее

Веб-сервисы (или веб-службы) — это технология, поз-воляющая системам обмениваться данными друг
Веб-сервисы (или веб-службы) — это технология, поз-воляющая системам обмениваться данными друг

Самые известные способы реализации веб-сервисов:
-XML-RPC (XML Remote Procedure Call) — протокол
Самые известные способы реализации веб-сервисов:
-XML-RPC (XML Remote Procedure Call) — протокол

SOAP
SOAP (Simple Object Access Protocol) — Данные передаются в формате XML.
Преимущества:
-отраслевой
SOAP
SOAP (Simple Object Access Protocol) — Данные передаются в формате XML.
Преимущества:
-отраслевой

Любое сообщение в протоколе SOAP — это XML доку-мент, состоящий из
Любое сообщение в протоколе SOAP — это XML доку-мент, состоящий из

Пример SOAP запроса
Пример SOAP запроса

Пример SOAP ответа
Пример SOAP ответа

REST
REST (Representational State Transfer) — на самом деле архитектурный стиль, а
REST
REST (Representational State Transfer) — на самом деле архитектурный стиль, а

REST не использует конвертацию данных при переда-че, данные передаются в исходном
REST не использует конвертацию данных при переда-че, данные передаются в исходном

Использование этих методов позволяет реализовать типичный CRUD (Create/Read/Update/Delete) для любой информации.
Использование этих методов позволяет реализовать типичный CRUD (Create/Read/Update/Delete) для любой информации.

Преимущества:
-простота реализации;
-экономичность в плане ресурсов;
-не требует программных надстроек (json_decode есть почти
Преимущества:
-простота реализации;
-экономичность в плане ресурсов;
-не требует программных надстроек (json_decode есть почти

Пример REST запроса
Пример REST запроса

Пример REST ответа
Пример REST ответа

SOAP используется в крупных корпоративных систе-мах со сложной логикой, когда требуются
SOAP используется в крупных корпоративных систе-мах со сложной логикой, когда требуются

ЛЕКЦИЯ 4_2. ОРКЕСТРАЦИЯ, ОБНАРУЖЕ-НИЕ МИКРОСЕРВИСОВ, K&S.
Оркестровка представляет собой единый централизованный исполняемый бизнес-процесс
ЛЕКЦИЯ 4_2. ОРКЕСТРАЦИЯ, ОБНАРУЖЕ-НИЕ МИКРОСЕРВИСОВ, K&S.
Оркестровка представляет собой единый централизованный исполняемый бизнес-процесс

В сервис-ориентированной архитектуре оркестровка сервисов реализуется согласно стандарту Business Process Execution
В сервис-ориентированной архитектуре оркестровка сервисов реализуется согласно стандарту Business Process Execution
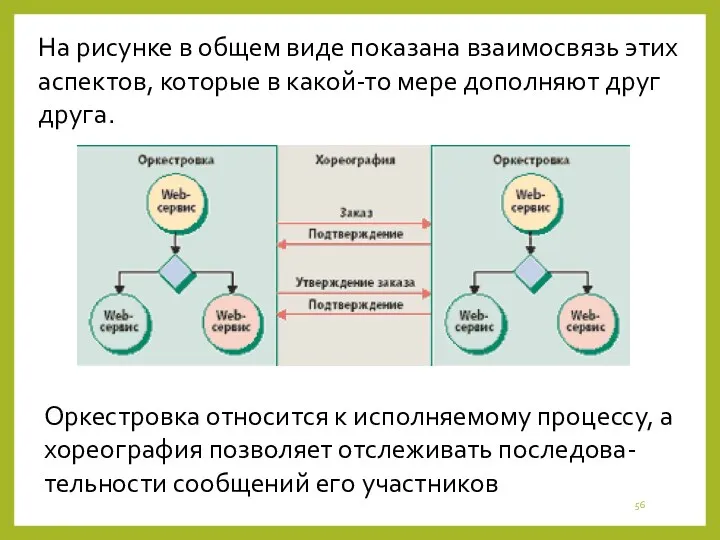
Оркестровка относится к исполняемому процессу, а хореография позволяет отслеживать последова-тельности сообщений
Оркестровка относится к исполняемому процессу, а хореография позволяет отслеживать последова-тельности сообщений

Оркестровка относится к исполняемому бизнес-про-цессу, который может взаимодействовать с внешни-ми и
Оркестровка относится к исполняемому бизнес-про-цессу, который может взаимодействовать с внешни-ми и

Системы обнаружения сервисов автоматизируют процесс, позволяя получить ответ на вопрос, где
Системы обнаружения сервисов автоматизируют процесс, позволяя получить ответ на вопрос, где

На сегодня существует несколько решений, реализу-ющих хранение информации об инфраструктуре, —
На сегодня существует несколько решений, реализу-ющих хранение информации об инфраструктуре, —

Стандарты оркестровки и хореографии должны удовлетворять ряду технических требований, обеспечивающих разработку
Стандарты оркестровки и хореографии должны удовлетворять ряду технических требований, обеспечивающих разработку

Во-первых, для обеспечения надежности и универ-сальности, необходимых современным вычислитель-ным средам, важна
Во-первых, для обеспечения надежности и универ-сальности, необходимых современным вычислитель-ным средам, важна

Кроме обработки ошибок и тайм-аутов оркестрован-ные Web-сервисы должны гарантировать доступность ресурсов
Кроме обработки ошибок и тайм-аутов оркестрован-ные Web-сервисы должны гарантировать доступность ресурсов

В-третьих, оркестровка Web-сервисов должна быть динамичной, гибкой и адаптивной, чтобы отвечать
В-третьих, оркестровка Web-сервисов должна быть динамичной, гибкой и адаптивной, чтобы отвечать

Если в традиционных вариантах сервис-ориентиро-ванной архитектуры модули могут быть сами по
Если в традиционных вариантах сервис-ориентиро-ванной архитектуры модули могут быть сами по

Свойства, характерные для микросервисной архи-тектуры:
– модули можно легко заменить в
Свойства, характерные для микросервисной архи-тектуры:
– модули можно легко заменить в

-модули могут быть реализованы с использованием различных языков программирования, фреймвор-ков, связующего
-модули могут быть реализованы с использованием различных языков программирования, фреймвор-ков, связующего

Наиболее популярная среда для выполнения микро-сервисов — системы управления контейнеризован-ными приложениями
Наиболее популярная среда для выполнения микро-сервисов — системы управления контейнеризован-ными приложениями

В последнее время получили развитие альтернатив-ные подходы к созданию веб-сервисов, основанные
В последнее время получили развитие альтернатив-ные подходы к созданию веб-сервисов, основанные
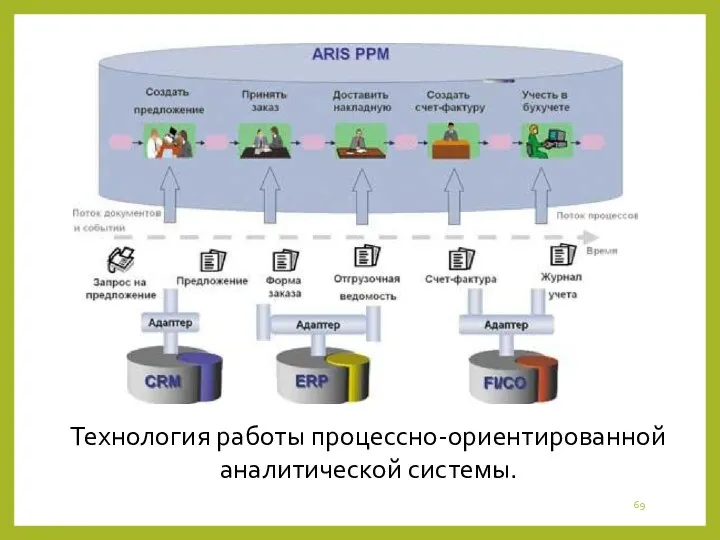
Технология работы процессно-ориентированной аналитической системы.
Технология работы процессно-ориентированной аналитической системы.

От микросервисного монолита к оркестратору
Когда компании решают разделить монолит на микросервисы,
От микросервисного монолита к оркестратору
Когда компании решают разделить монолит на микросервисы,
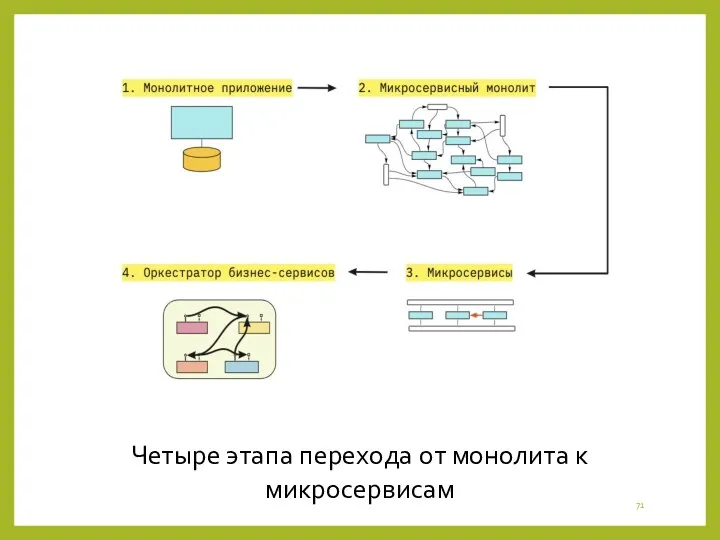
Четыре этапа перехода от монолита к микросервисам
Четыре этапа перехода от монолита к микросервисам

Этап №1. Монолит
1.1 Характеристики
Обычно монолитную архитектуру можно описать так:
-Единая точка разработки
Этап №1. Монолит
1.1 Характеристики
Обычно монолитную архитектуру можно описать так:
-Единая точка разработки
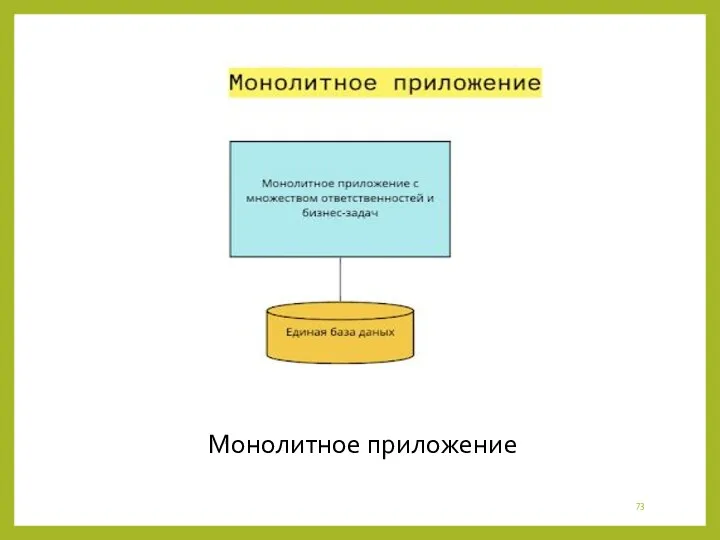
Монолитное приложение
Монолитное приложение

Как перейти на следующий этап
В основе процесса выделения микросервисов лежит вынесение
Как перейти на следующий этап
В основе процесса выделения микросервисов лежит вынесение
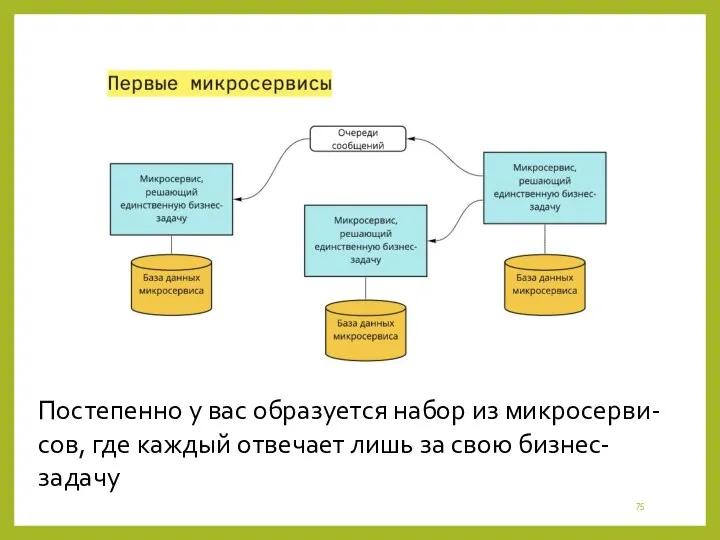
Постепенно у вас образуется набор из микросерви-сов, где каждый отвечает лишь
Постепенно у вас образуется набор из микросерви-сов, где каждый отвечает лишь

Этап №2. Микросервисный монолит
Характеристики
Все части монолита стали независимыми микросер-висами и эти
Этап №2. Микросервисный монолит
Характеристики
Все части монолита стали независимыми микросер-висами и эти
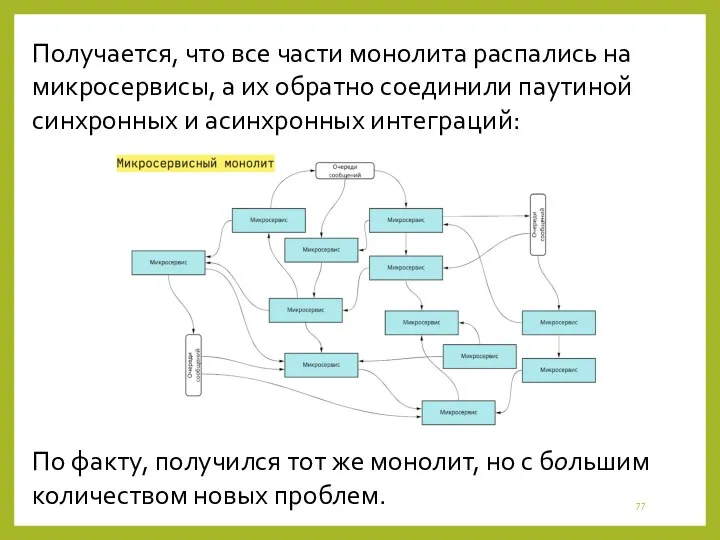
Получается, что все части монолита распались на микросервисы, а их обратно
Получается, что все части монолита распались на микросервисы, а их обратно

Проблемы
-Прямые связи между микросервисами усложняют анализ проблем. Например, запрос может пройти
Проблемы
-Прямые связи между микросервисами усложняют анализ проблем. Например, запрос может пройти

-Архитектуру сложно понять и, чем больше сервисов вы добавляете, тем запутанней
-Архитектуру сложно понять и, чем больше сервисов вы добавляете, тем запутанней

Как перейти на следующий этап
Основные идеи: локализовать точки интеграции и контролировать
Как перейти на следующий этап
Основные идеи: локализовать точки интеграции и контролировать

Этап №3. Микросервисы
Характеристики
Микросервисы ничего не знают о существовании друг друга: работают
Этап №3. Микросервисы
Характеристики
Микросервисы ничего не знают о существовании друг друга: работают
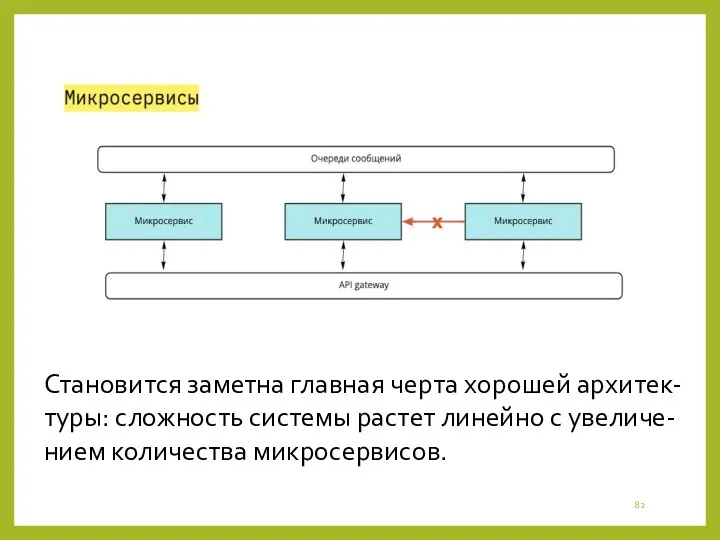
Становится заметна главная черта хорошей архитек-туры: сложность системы растет линейно с
Становится заметна главная черта хорошей архитек-туры: сложность системы растет линейно с

Проблемы
На этом этапе сложные технические задачи решены, поэтому начинаются проблемы на
Проблемы
На этом этапе сложные технические задачи решены, поэтому начинаются проблемы на

Бизнес хочет увидеть лес за деревьями, чтобы пони-мать, какие есть детали
Бизнес хочет увидеть лес за деревьями, чтобы пони-мать, какие есть детали

Тем, кто решают двигаться дальше:
Изучите концепцию Citizen Integrator. Для наглядного примера заведите
Тем, кто решают двигаться дальше:
Изучите концепцию Citizen Integrator. Для наглядного примера заведите
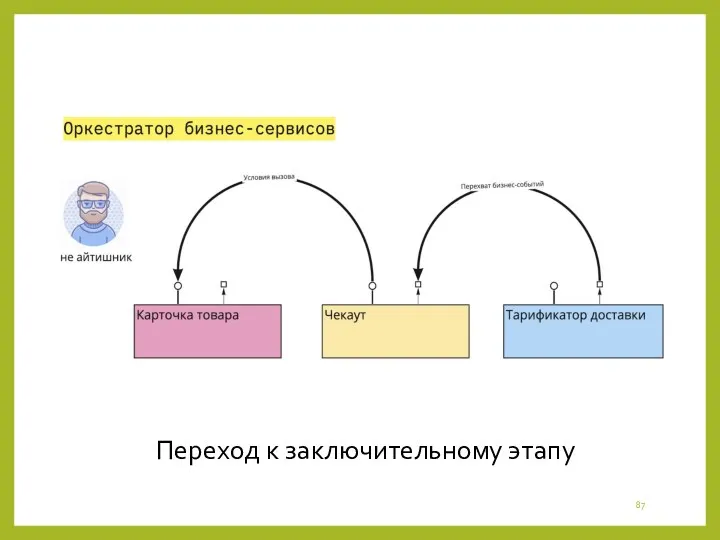
Переход к заключительному этапу
Переход к заключительному этапу

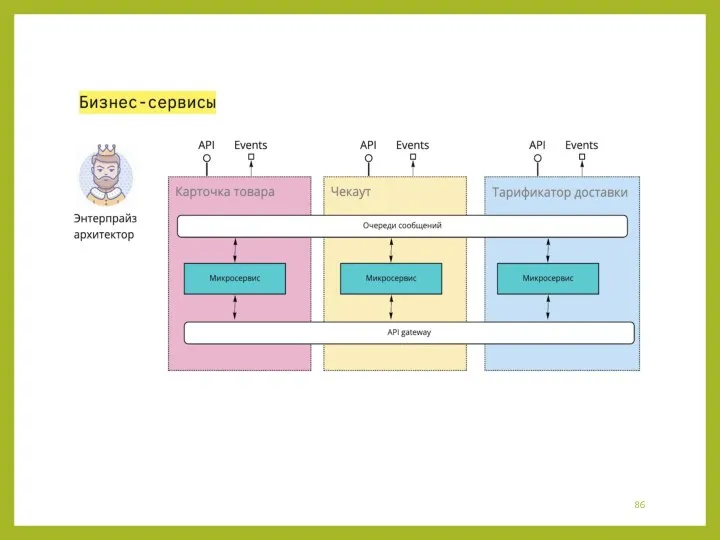
Этап №4. Оркестратор бизнес-сервисов
Характеристики
Оркестратор бизнес-сервисов обычно является визу-альной платформой, где соединяются
Этап №4. Оркестратор бизнес-сервисов
Характеристики
Оркестратор бизнес-сервисов обычно является визу-альной платформой, где соединяются

На этом этапе можете решить задачу создания продукта в визуальном редакторе.
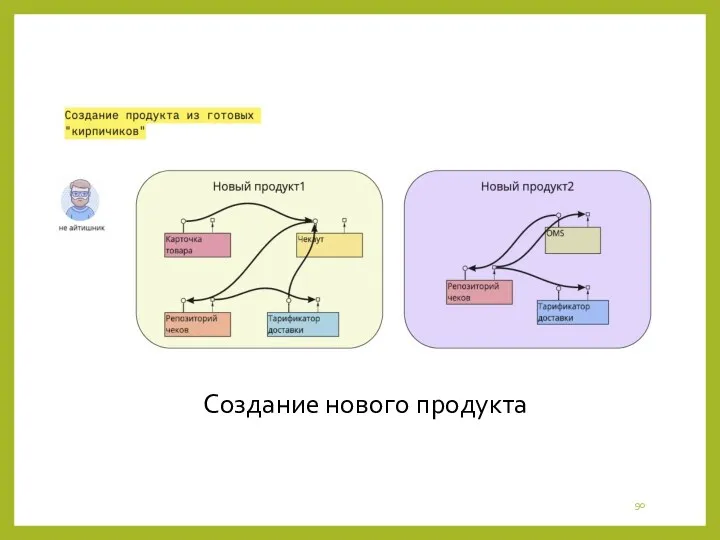
Создание нового продукта
Создание нового продукта

Проблемы
-Создание, внедрение и развитие оркестратора бизнес-процессов является дорогим удовольствием.
-Если ослабить архитектурный
Проблемы
-Создание, внедрение и развитие оркестратора бизнес-процессов является дорогим удовольствием.
-Если ослабить архитектурный

Эти четыре этапа показывают естественный ход вещей:
- Вначале приложение небольшое и
- Вначале приложение небольшое и

При первой попытке разделить монолит многие ко-манды не готовы к возрастающей
При первой попытке разделить монолит многие ко-манды не готовы к возрастающей

Когда сложности решаются, получается стройная и масштабируемая архитектура. Добавление новых микросервисов
Когда сложности решаются, получается стройная и масштабируемая архитектура. Добавление новых микросервисов

Kubernetes (K8s) – это программное обеспечение для автоматизации развёртывания, масштабирова-ния и управления
Kubernetes (K8s) – это программное обеспечение для автоматизации развёртывания, масштабирова-ния и управления

Kubernetes необходим для непрерывной интегра-ции и поставки программного обеспечения (CI/CD, Continuos Integration/
Kubernetes необходим для непрерывной интегра-ции и поставки программного обеспечения (CI/CD, Continuos Integration/

Однако, если необходим сложный порядок запуска большого количества таких контейнеров (от
Однако, если необходим сложный порядок запуска большого количества таких контейнеров (от

АРХИТЕКТУРА КУБЕРНЕТИС
Kubernetes устроен по принципу master/slave, когда ведущим элементом является подсистема управления
АРХИТЕКТУРА КУБЕРНЕТИС
Kubernetes устроен по принципу master/slave, когда ведущим элементом является подсистема управления

Также на узлах развернуты поды (pods) — базовые модули управления и запуска приложений, состоя-щие
Также на узлах развернуты поды (pods) — базовые модули управления и запуска приложений, состоя-щие

Помимо подов, на ведомых узлах также работают следующие компоненты Kubernetes:
-Kube-proxy – комбинация сетевого прокси-серве-ра и балансировщика
Помимо подов, на ведомых узлах также работают следующие компоненты Kubernetes:
-Kube-proxy – комбинация сетевого прокси-серве-ра и балансировщика

Управление подами реализуется через АPI Kubernetes, интерфейс командной строки (Kubectl) или специали-зированные контроллеры (controllers) –
Управление подами реализуется через АPI Kubernetes, интерфейс командной строки (Kubectl) или специали-зированные контроллеры (controllers) –

На ведущем компоненте (master) работают следу-ющие элементы:
-Etcd - легковесная распределённая NoSQL-СУБД класса «ключ-значение», которая
На ведущем компоненте (master) работают следу-ющие элементы:
-Etcd - легковесная распределённая NoSQL-СУБД класса «ключ-значение», которая

-Планировщик (scheduler), который регулирует рас-пределение нагрузки по узлам, выбирая узел выпол-нения
-Планировщик (scheduler), который регулирует рас-пределение нагрузки по узлам, выбирая узел выпол-нения
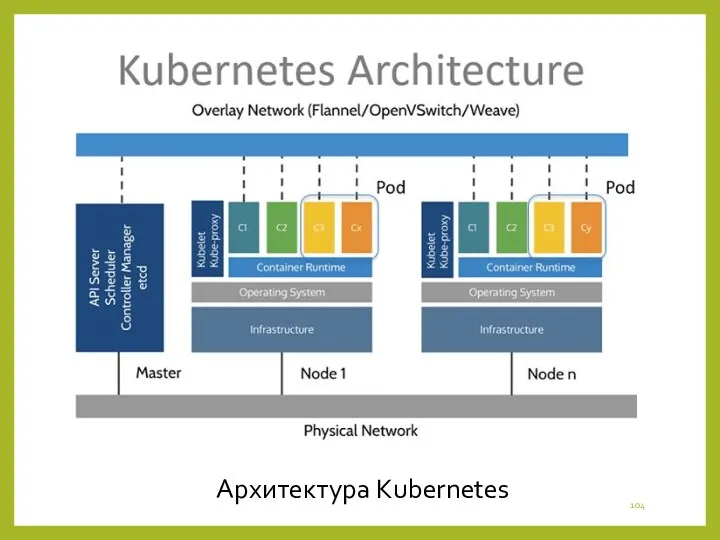
Архитектура Kubernetes
Архитектура Kubernetes

В Kubernetes контейнер – это программный компо-нент самого низкого уровня абстракции.
В Kubernetes контейнер – это программный компо-нент самого низкого уровня абстракции.

Что особенно важно для Big Data проектов,
Kubelet – компонент Kubernetes,
Что особенно важно для Big Data проектов,
Kubelet – компонент Kubernetes,

Аналогично HDFS, наиболее популярной распреде-ленной файловой системе для Big Data-решений, реализованной в
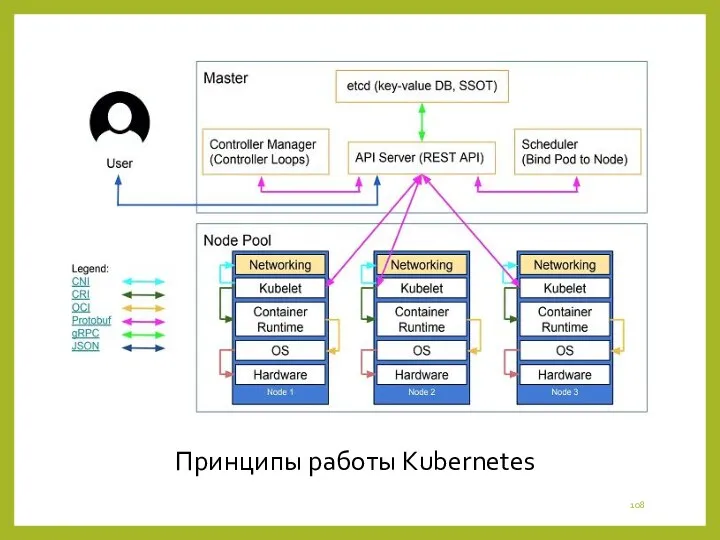
Принципы работы Kubernetes
Принципы работы Kubernetes

ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ КУБЕРНЕТИС
Поскольку K8s предназначен для управления мно-жеством контейнеризированных микросервисов, не-удивительно,
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ КУБЕРНЕТИС
Поскольку K8s предназначен для управления мно-жеством контейнеризированных микросервисов, не-удивительно,

В связи с цифровизацией предприятий и распрост-ранением DevOps-подхода, спрос на владение
В связи с цифровизацией предприятий и распрост-ранением DevOps-подхода, спрос на владение

Docker — программное обеспечение для автоматиза-ции развёртывания и управления приложениями в средах
Docker — программное обеспечение для автоматиза-ции развёртывания и управления приложениями в средах

С появлением Open Container Initiative начался пере-ход от монолитной к модульной
С появлением Open Container Initiative начался пере-ход от монолитной к модульной
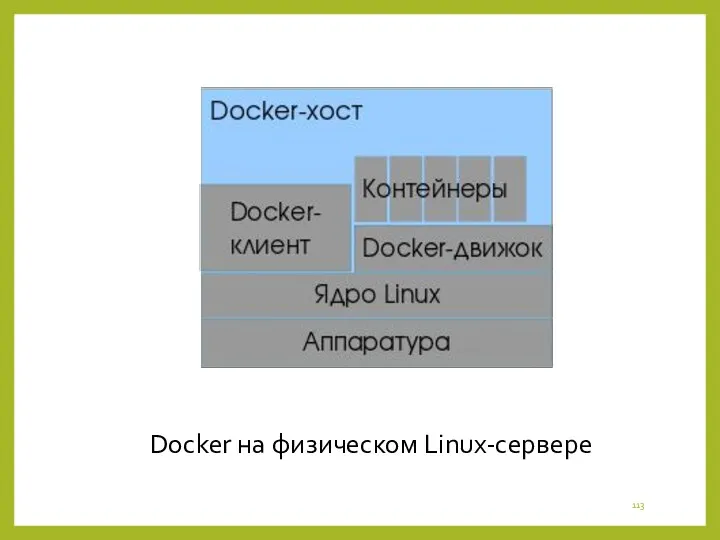
Docker на физическом Linux-сервере
Docker на физическом Linux-сервере

Программное обеспечение функционирует в среде Linux с ядром, поддерживающим контрольные группы и изоляцию
Программное обеспечение функционирует в среде Linux с ядром, поддерживающим контрольные группы и изоляцию

 Сервисы для создания презентаций
Сервисы для создания презентаций Организация защиты информации в локальной сети компании ООО MAN Truck and Bus Rus
Организация защиты информации в локальной сети компании ООО MAN Truck and Bus Rus Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма
Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма Модифицированный симплекс метод
Модифицированный симплекс метод Исполнители алгоритмов
Исполнители алгоритмов Python.Основы Циклы While. For. Лекция 3.2
Python.Основы Циклы While. For. Лекция 3.2 Що таке джинса
Що таке джинса Feed back
Feed back Modeling space from picture. Musical instruments
Modeling space from picture. Musical instruments Урок на тему Единицы измерения информации 6 класс
Урок на тему Единицы измерения информации 6 класс Зачем человек приходит в этот мир?
Зачем человек приходит в этот мир? Защита от несанкционированного доступа к информации
Защита от несанкционированного доступа к информации Цифровое фото и видео
Цифровое фото и видео Transition headline. Let’s start with the first set of slides
Transition headline. Let’s start with the first set of slides Графический интерфейс. Библиотека Tkinter
Графический интерфейс. Библиотека Tkinter Строковый и символьный тип данных
Строковый и символьный тип данных Виртуальные экскурсии: технологии создания
Виртуальные экскурсии: технологии создания Google. История создания
Google. История создания Криптография. История развития и базовые знания
Криптография. История развития и базовые знания Модель ISO/OSI
Модель ISO/OSI Научно-техническая и патентная информация Часть 2
Научно-техническая и патентная информация Часть 2 Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары
Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары Телеграмм-бот по игре Dota
Телеграмм-бот по игре Dota Подпрограммы в авс pascal
Подпрограммы в авс pascal Інформаційна система Ідентифікації шляхом розпізнавання обличчя
Інформаційна система Ідентифікації шляхом розпізнавання обличчя Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16)
Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16) Протоколы распределения ключей
Протоколы распределения ключей Сбор данных
Сбор данных