- Корпусная лингвистика

Содержание
- 2. ПОНЯТИЕ КОРПУСНОЙ ЛИНГВИСТИКИ Корпусная лингвистика - раздел языкознания, занимающийся разработкой, созданием и использованием текстовых корпусов с
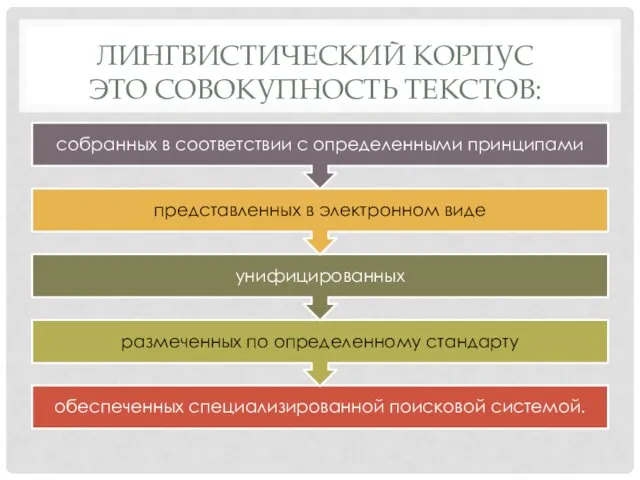
- 3. ЛИНГВИСТИЧЕСКИЙ КОРПУС ЭТО СОВОКУПНОСТЬ ТЕКСТОВ:
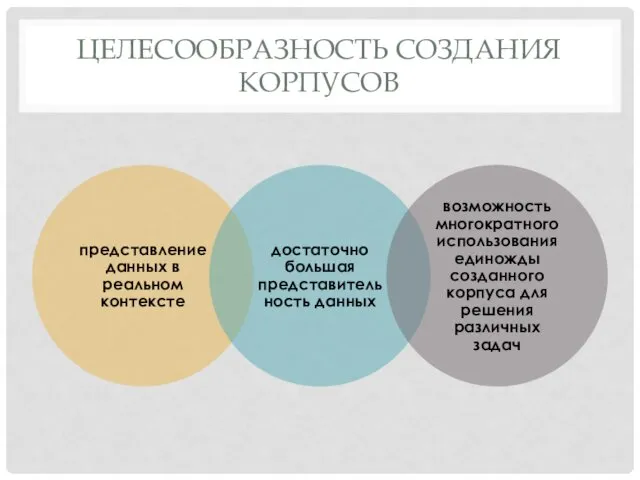
- 4. ЦЕЛЕСООБРАЗНОСТЬ СОЗДАНИЯ КОРПУСОВ
- 5. ОБЪЕКТ И ПРЕДМЕТ КОРПУСНОЙ ЛИНГВИСТИКИ
- 6. ЦЕЛЬ КОРПУСНОЙ ЛИНГВИСТИКИ - ИССЛЕДОВАНИЕ ЕСТЕСТВЕННОГО ИСПОЛЬЗОВАНИЯ ЯЗЫКА Задачи: Сбор текстов с определенной целью Их машинная
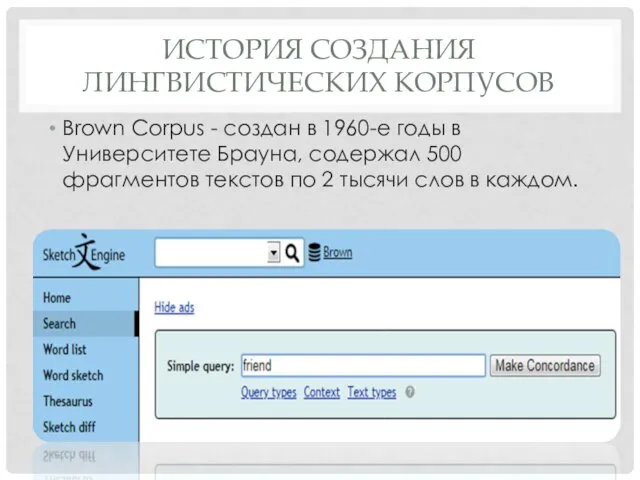
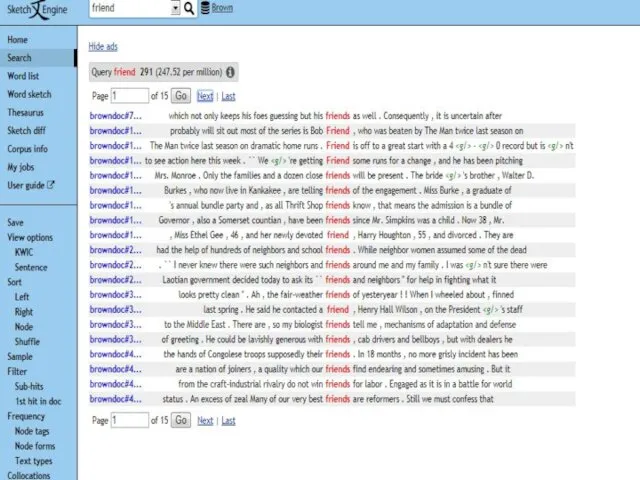
- 7. ИСТОРИЯ СОЗДАНИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ Brown Corpus - создан в 1960-е годы в Университете Брауна, содержал 500
- 10. ИСТОРИЯ СОЗДАНИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ 1970 годы - частотный словарь русского языка Л.Н. Засориной, 1 миллион слов
- 12. Скачать презентацию

ПОНЯТИЕ КОРПУСНОЙ ЛИНГВИСТИКИ
Корпусная лингвистика - раздел языкознания, занимающийся разработкой, созданием и
ПОНЯТИЕ КОРПУСНОЙ ЛИНГВИСТИКИ
Корпусная лингвистика - раздел языкознания, занимающийся разработкой, созданием и
ЛИНГВИСТИЧЕСКИЙ КОРПУС
ЭТО СОВОКУПНОСТЬ ТЕКСТОВ:
ЛИНГВИСТИЧЕСКИЙ КОРПУС
ЭТО СОВОКУПНОСТЬ ТЕКСТОВ:
ЦЕЛЕСООБРАЗНОСТЬ СОЗДАНИЯ КОРПУСОВ
ЦЕЛЕСООБРАЗНОСТЬ СОЗДАНИЯ КОРПУСОВ

ОБЪЕКТ И ПРЕДМЕТ КОРПУСНОЙ ЛИНГВИСТИКИ
ОБЪЕКТ И ПРЕДМЕТ КОРПУСНОЙ ЛИНГВИСТИКИ

ЦЕЛЬ КОРПУСНОЙ ЛИНГВИСТИКИ - ИССЛЕДОВАНИЕ ЕСТЕСТВЕННОГО ИСПОЛЬЗОВАНИЯ ЯЗЫКА
Задачи:
Сбор текстов с определенной
ЦЕЛЬ КОРПУСНОЙ ЛИНГВИСТИКИ - ИССЛЕДОВАНИЕ ЕСТЕСТВЕННОГО ИСПОЛЬЗОВАНИЯ ЯЗЫКА
Задачи:
Сбор текстов с определенной
ИСТОРИЯ СОЗДАНИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ
Brown Corpus - создан в 1960-е годы в
ИСТОРИЯ СОЗДАНИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ
Brown Corpus - создан в 1960-е годы в


ИСТОРИЯ СОЗДАНИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ
1970 годы - частотный словарь русского языка Л.Н.
ИСТОРИЯ СОЗДАНИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ
1970 годы - частотный словарь русского языка Л.Н.
 Інтерфейси програмних засобів. Результати дослідження
Інтерфейси програмних засобів. Результати дослідження Библиографическое описание документа: оформление списка к научной работе
Библиографическое описание документа: оформление списка к научной работе Методика визуализации учебной информации
Методика визуализации учебной информации Технология разработки программного обеспечения (вторая часть). Порождающие шаблоны проектирования ПО
Технология разработки программного обеспечения (вторая часть). Порождающие шаблоны проектирования ПО Программирование (C++)
Программирование (C++) Методы и средства защиты компьютерной информации
Методы и средства защиты компьютерной информации Кодирование и шифрование данных
Кодирование и шифрование данных Хотите стать миллионером?
Хотите стать миллионером? Представление данных в ЭВМ
Представление данных в ЭВМ Книги PascalABC.NET. Современное программирование
Книги PascalABC.NET. Современное программирование Изменение и удаление данных. Изменение данных в таблицах
Изменение и удаление данных. Изменение данных в таблицах Пошук найкоротшого шляху. Графи
Пошук найкоротшого шляху. Графи Презентация Применение ИКТ в работе с педагогами
Презентация Применение ИКТ в работе с педагогами Разработка игры на платформе Ren’Py
Разработка игры на платформе Ren’Py Разбор задания № 15 КИМ ГИА-2012
Разбор задания № 15 КИМ ГИА-2012 Создание сети электронных магазинов
Создание сети электронных магазинов Facebook - социальная сеть
Facebook - социальная сеть Введение в Arduino
Введение в Arduino Мобильные технологии в обучении иностранного языка
Мобильные технологии в обучении иностранного языка Основные модели представления данных
Основные модели представления данных Cоставные части программы, локальные и глобальные переменные. Функции
Cоставные части программы, локальные и глобальные переменные. Функции Компьютер как средство автоматизации информационных процессов
Компьютер как средство автоматизации информационных процессов 9 класс. Повторение. Решение задач
9 класс. Повторение. Решение задач Архитектура ЭВМ. Основы операционных систем
Архитектура ЭВМ. Основы операционных систем Построение сборки редуктора
Построение сборки редуктора Портал государственных и муниципальных услуг
Портал государственных и муниципальных услуг Życie w sieci - SpołecznoścI internetowe
Życie w sieci - SpołecznoścI internetowe Обзор веб-ресурсов по веб-дизайну и веб-разработке
Обзор веб-ресурсов по веб-дизайну и веб-разработке