- Кружок по искусственному интеллекту. Семинар 2

Содержание
- 2. Обучение с учителем Логистическая регрессия Обучение но основе решающих деревьев Random Forest К –ближайших соседей
- 3. Логистическая регрессия Логистическая регрессия –это линейная модель бинарной классификации.
- 4. Логистическая функция (сигмоида)
- 5. Логистическая регрессия
- 6. Логистическая регрессия функции стоимости
- 7. Переобучение
- 8. Переобучение
- 9. Смещение (bias) и разброс (variance) Разброс (variance) - дисперсия ответов алгоритмов Da Cмещение (bias) – матожидание
- 10. Смещение (bias) и разброс (variance)
- 11. Переобучение
- 12. Регуляризация Регуляризация - метод для обработки коллинеарности (высокой корреляции среди признаков), фильтрации шума из данных и
- 13. Регуляризация L2 L1
- 14. Решающие деревья
- 15. Максимизация прироста информации
- 16. Меры неоднородности Энтропия Мера неоднородности Джини Ошибка классификации
- 17. Random Forest (Случайный лес) 1 шаг. Случайным образом выбрать n образцов с возвратом. ( извлечь бутсрап-выборку)
- 18. K –ближайших соседей
- 20. Скачать презентацию

Обучение с учителем
Логистическая регрессия
Обучение но основе решающих деревьев
Random Forest
К –ближайших соседей
Обучение с учителем
Логистическая регрессия
Обучение но основе решающих деревьев
Random Forest
К –ближайших соседей

Логистическая регрессия
Логистическая регрессия –это линейная модель бинарной классификации.
Логистическая регрессия
Логистическая регрессия –это линейная модель бинарной классификации.
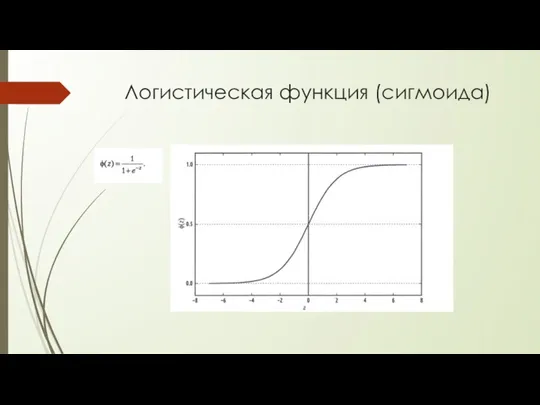
Логистическая функция (сигмоида)
Логистическая функция (сигмоида)
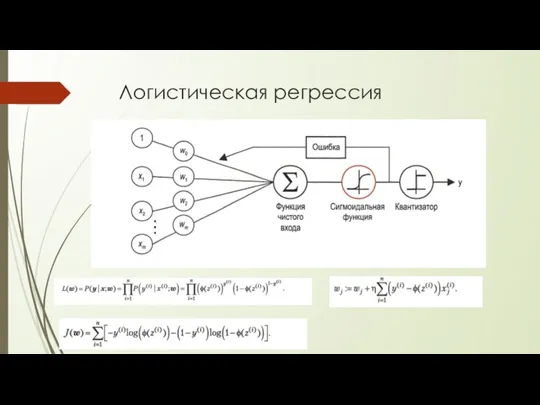
Логистическая регрессия
Логистическая регрессия
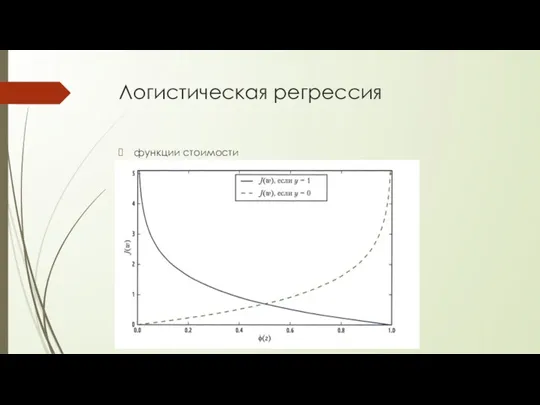
Логистическая регрессия
функции стоимости
Логистическая регрессия
функции стоимости
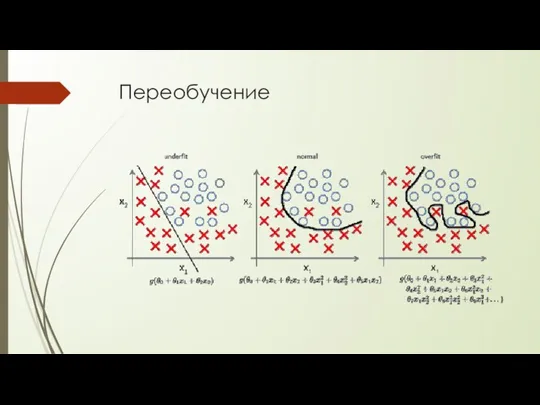
Переобучение
Переобучение
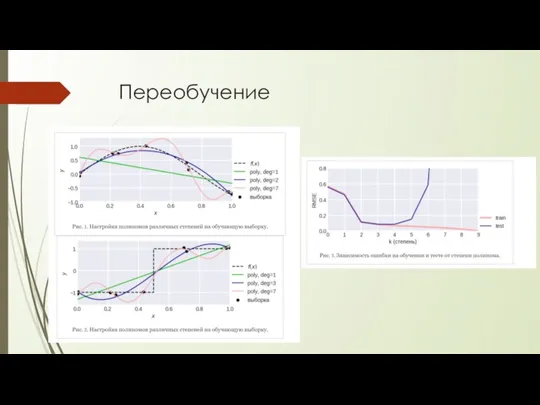
Переобучение
Переобучение

Смещение (bias) и разброс (variance)
Разброс (variance) - дисперсия ответов алгоритмов Da
Cмещение (bias)
Смещение (bias) и разброс (variance)
Разброс (variance) - дисперсия ответов алгоритмов Da
Cмещение (bias)

Смещение (bias) и разброс (variance)
Смещение (bias) и разброс (variance)
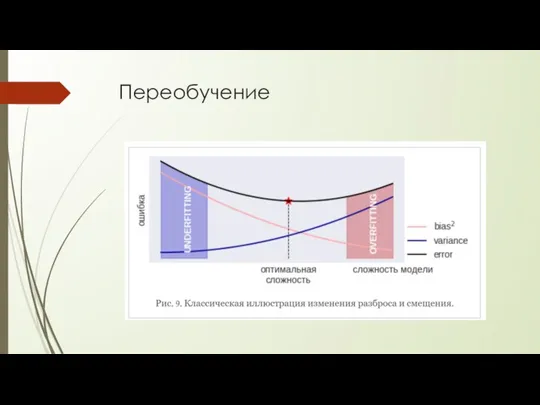
Переобучение
Переобучение

Регуляризация
Регуляризация - метод для обработки коллинеарности (высокой корреляции среди признаков), фильтрации
Регуляризация
Регуляризация - метод для обработки коллинеарности (высокой корреляции среди признаков), фильтрации
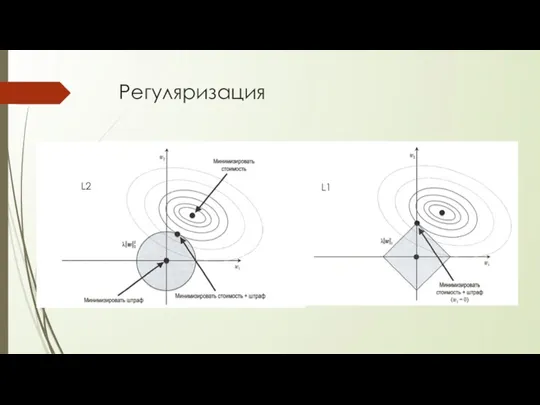
Регуляризация
L2
L1
Регуляризация
L2
L1
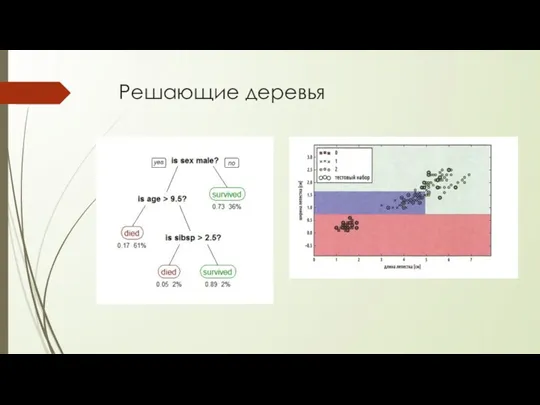
Решающие деревья
Решающие деревья

Максимизация прироста информации
Максимизация прироста информации

Меры неоднородности
Энтропия
Мера неоднородности Джини
Ошибка классификации
Меры неоднородности
Энтропия
Мера неоднородности Джини
Ошибка классификации

Random Forest (Случайный лес)
1 шаг. Случайным образом выбрать n образцов с
Random Forest (Случайный лес)
1 шаг. Случайным образом выбрать n образцов с
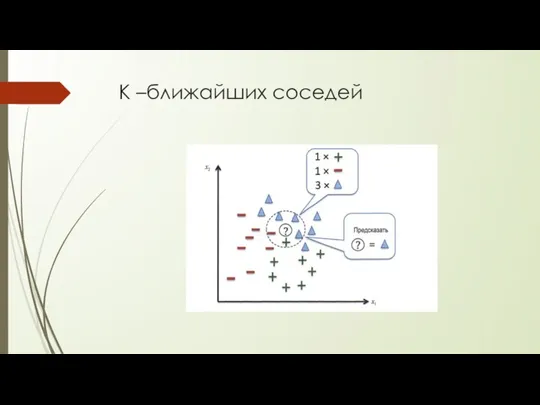
K –ближайших соседей
K –ближайших соседей
 Медиа. Понятие, содержание, классификация
Медиа. Понятие, содержание, классификация Компонент TStringGrid
Компонент TStringGrid Алгоритм. Свойства алгоритма. Исполнители
Алгоритм. Свойства алгоритма. Исполнители Безпека в Інтернеті
Безпека в Інтернеті Разработка системы для поддержки процесса сертификации программной продукции
Разработка системы для поддержки процесса сертификации программной продукции Базы данных. Информационные систем. Тема 1. Информационные системы
Базы данных. Информационные систем. Тема 1. Информационные системы MS Word - мәтіндік редакторы
MS Word - мәтіндік редакторы Информационные технологии в металлургии. Лекция 2
Информационные технологии в металлургии. Лекция 2 Текстовый редактор Microsoft WORD
Текстовый редактор Microsoft WORD Computer ergonomics
Computer ergonomics Создание интерактивного плаката Салют Победы в Scratch
Создание интерактивного плаката Салют Победы в Scratch Программное обеспечение ПК. 7 класс
Программное обеспечение ПК. 7 класс Сетевые модели OSI и IEEE Project 802
Сетевые модели OSI и IEEE Project 802 Презентация к методической разработке
Презентация к методической разработке Исполнитель Робот. СКИ, обстановка
Исполнитель Робот. СКИ, обстановка Всероссийская акция Час кода
Всероссийская акция Час кода Основы программирования. Лекция № 2
Основы программирования. Лекция № 2 Алгоритми. Складність алгоритмів. Алгоритм бінарного пошуку
Алгоритми. Складність алгоритмів. Алгоритм бінарного пошуку Технологии обработки графических образов. Лекция 6
Технологии обработки графических образов. Лекция 6 Встраивание музыки в документы
Встраивание музыки в документы Мультемедиялық тенологияларды ң оқу үдеріснде пайдалану
Мультемедиялық тенологияларды ң оқу үдеріснде пайдалану Презентация команды NFC для Ритейла
Презентация команды NFC для Ритейла Знакомство с Сибелиус
Знакомство с Сибелиус Общение в Интернете в реальном времени
Общение в Интернете в реальном времени Основы HTML и CSS
Основы HTML и CSS ПЯВУ. Основы программирования. Лекция 4. Типы текстовых данных
ПЯВУ. Основы программирования. Лекция 4. Типы текстовых данных Інтерактивне керування потоком автотранспорту з ситуаційного центру
Інтерактивне керування потоком автотранспорту з ситуаційного центру Проектирование информационных систем
Проектирование информационных систем