- Лексер. Парсер. (Часть 2)

Содержание
- 2. Фронтэнд Машинно независимые оптимизации Код генерация + машинно зависимые оптимизации Этапы компиляции
- 3. Лексический анализатор (лексер) Синтаксический анализатор (парсер) Семантический анализатор Генерация промежуточного представления Этапы фронтэнда
- 4. Схема работы Исходный код Лексер Парсер Символьная таблица Токен Следующий Семантический анализ
- 5. Лексер формирует последовательности входных символов в лексемы и отправляет токены парсеру. Лексема – минимальная единица языка,
- 6. Обрабатываемые лексером и парсером последовательности символов и лексем напрямую зависят от спецификации языка. Необходим способ описания
- 7. Алфавит – множество символов, используемых в языке Терминальный символ - символ из алфавита Нетерминальный символ –
- 8. Тип 0: неограниченные Тип 1: контекстно-зависимые / неукорачивающие Тип 2: контекстно-свободные Тип 3: регулярные: праволинейные/леволинейные Классификация
- 9. Регулярные грамматики: праволинейные (A → w, A → wB, A,B ∈ N, w ∈ T*) леволинейные
- 10. Тип 0 (неограниченные): естественные языки: Русский Английский Тип 2 (контекстно-свободные): большинство языков программирования: Java С++ Тип
- 11. Тип 2 контекстно – свободная грамматика: может быть описана с помощью конечного автомата с магазинной памятью
- 12. Недетерминированный Детерминированный Строгие определения. Конечные автоматы с магазинной памятью.
- 13. Нисходящий анализ Метод рекурсивного спуска (парсер с возвратом) Предиктивный анализатор (предсказывающий анализатор) (LL анализатор) Восходящий анализ
- 14. id + id * id Дерево разбора
- 15. Дерево разбора строится сверху вниз, слева направо Токены от лексера рассматриваются в порядке поступления Метод рекурсивного
- 16. Каждому нетерминалу соответствует процедура, в которую жёстко зашиты продукции данного нетерминала Процедура последовательно сравнивает пришедшие токены
- 17. Пример применения метода рекурсивного спуска
- 18. Грамматика жёстко зашита в алгоритм. В последующих алгоритмах на основании грамматики строятся таблицы Алгоритм выполняется за
- 19. Идея – убрать откатывание. По каждому символу должно быть изначально ясно куда переходим. Преобразование грамматики Удаление
- 20. Удаление левой рекурсии Левая факторизация Предиктивный анализатор
- 21. Пример преобразования грамматики: Предиктивный анализатор
- 22. Определение множества FIRST FIRST(a), a∈(N⋃T)* - множество терминалов или ℇ, с которых может начинаться а. Построение
- 23. Определение множества FOLLOW FOLLOW(A), A∈N – множества терминалов, которые могут появиться сразу за А, включая концевой
- 24. Пример построения FIRST, FOLLOW Предиктивный анализ
- 25. Построение таблицы Предиктивный анализ
- 26. Пример построения таблицы Предиктивный анализ
- 27. Предиктивный анализ, разбор
- 28. Предиктивный анализ, пример
- 29. Строим дерево разбора начиная с листьев Для большинства языков программирования можно построить LR грамматику Наиболее общий
- 30. Построение LR(1) анализатора 1. Пополнение грамматики 2. Построение канонической системы множеств допустимых LR(1)-ситуаций 3. Построение таблицы
- 31. Пополнение грамматики Добавим новое правило S' → S, и сделаем S' аксиомой грамматики. Допуск имеет место
- 32. Каноническая система множеств Вначале имеется множество I0 с конфигурацией анализатора S' → .S, $ К этой
- 33. Пример
- 34. Построение Goto Eсли в канонической системе множеств есть переход из Ii в Ij по символу A,
- 35. Построение action Если есть переход по терминалу a из состояния Ii в состояние Ij, то Action(Ii,
- 36. Пример
- 37. Восходящий анализ, разбор
- 38. Восходящий анализ, пример
- 39. Баланс скобок {…{…(…)…(((…))…)…}…(…}…} Верность выражений “+” между expr Обрабатываемые ошибки
- 41. Скачать презентацию

Фронтэнд
Машинно независимые оптимизации
Код генерация + машинно зависимые оптимизации
Этапы компиляции
Фронтэнд
Машинно независимые оптимизации
Код генерация + машинно зависимые оптимизации
Этапы компиляции

Лексический анализатор (лексер)
Синтаксический анализатор (парсер)
Семантический анализатор
Генерация промежуточного представления
Этапы фронтэнда
Лексический анализатор (лексер)
Синтаксический анализатор (парсер)
Семантический анализатор
Генерация промежуточного представления
Этапы фронтэнда
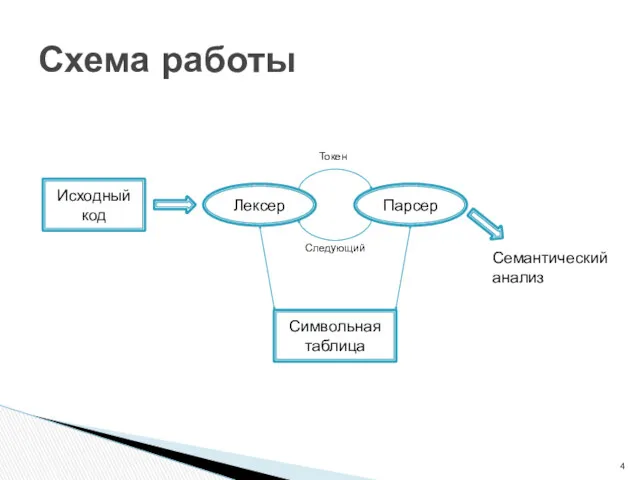
Схема работы
Исходный код
Лексер
Парсер
Символьная таблица
Токен
Следующий
Семантический
анализ
Схема работы
Исходный код
Лексер
Парсер
Символьная таблица
Токен
Следующий
Семантический
анализ

Лексер формирует последовательности входных символов в лексемы и отправляет токены парсеру.
Лексема
Лексер формирует последовательности входных символов в лексемы и отправляет токены парсеру.
Лексема

Обрабатываемые лексером и парсером последовательности символов и лексем напрямую зависят от
Обрабатываемые лексером и парсером последовательности символов и лексем напрямую зависят от

Алфавит – множество символов, используемых в языке
Терминальный символ - символ из
Алфавит – множество символов, используемых в языке
Терминальный символ - символ из

Тип 0: неограниченные
Тип 1: контекстно-зависимые / неукорачивающие
Тип 2: контекстно-свободные
Тип 3: регулярные:
Тип 0: неограниченные
Тип 1: контекстно-зависимые / неукорачивающие
Тип 2: контекстно-свободные
Тип 3: регулярные:

Регулярные грамматики:
праволинейные (A → w, A → wB, A,B ∈ N,
Регулярные грамматики:
праволинейные (A → w, A → wB, A,B ∈ N,

Тип 0 (неограниченные): естественные языки:
Русский
Английский
Тип 2 (контекстно-свободные): большинство языков программирования:
Java
С++
Тип 3:
Тип 0 (неограниченные): естественные языки:
Русский
Английский
Тип 2 (контекстно-свободные): большинство языков программирования:
Java
С++
Тип 3:

Тип 2 контекстно – свободная грамматика:
может быть описана с помощью конечного
Тип 2 контекстно – свободная грамматика:
может быть описана с помощью конечного

Недетерминированный
Детерминированный
Строгие определения. Конечные автоматы с магазинной памятью.
Недетерминированный
Детерминированный
Строгие определения. Конечные автоматы с магазинной памятью.

Нисходящий анализ
Метод рекурсивного спуска (парсер с возвратом)
Предиктивный анализатор (предсказывающий анализатор) (LL
Нисходящий анализ
Метод рекурсивного спуска (парсер с возвратом)
Предиктивный анализатор (предсказывающий анализатор) (LL
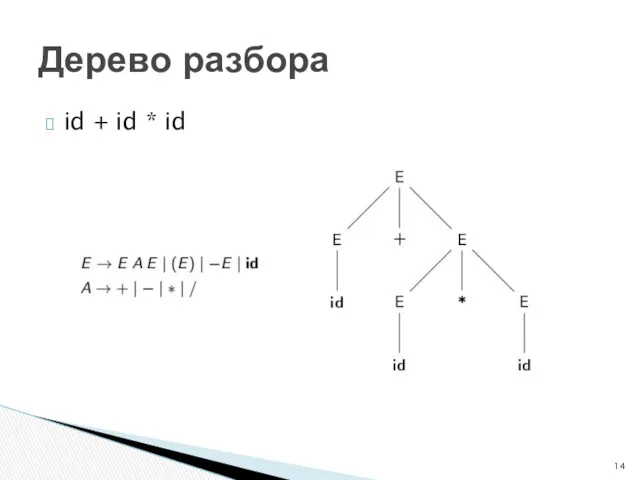
id + id * id
Дерево разбора
id + id * id
Дерево разбора

Дерево разбора строится сверху вниз, слева направо
Токены от лексера рассматриваются в
Дерево разбора строится сверху вниз, слева направо
Токены от лексера рассматриваются в

Каждому нетерминалу соответствует процедура, в которую жёстко зашиты продукции данного нетерминала
Процедура
Каждому нетерминалу соответствует процедура, в которую жёстко зашиты продукции данного нетерминала
Процедура
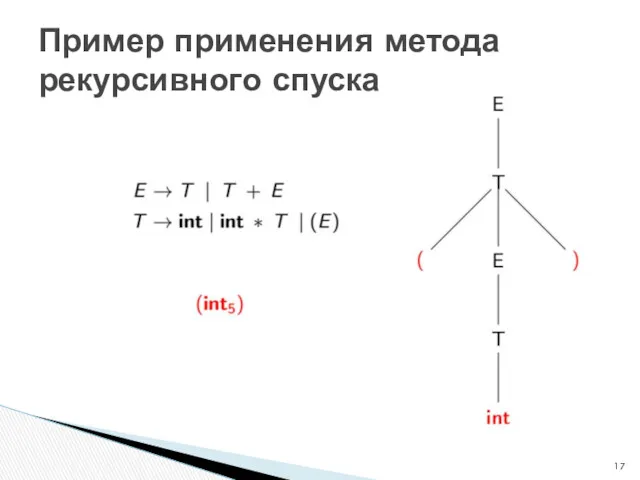
Пример применения метода рекурсивного спуска
Пример применения метода рекурсивного спуска

Грамматика жёстко зашита в алгоритм. В последующих алгоритмах на основании грамматики
Грамматика жёстко зашита в алгоритм. В последующих алгоритмах на основании грамматики

Идея – убрать откатывание. По каждому символу должно быть изначально ясно
Идея – убрать откатывание. По каждому символу должно быть изначально ясно
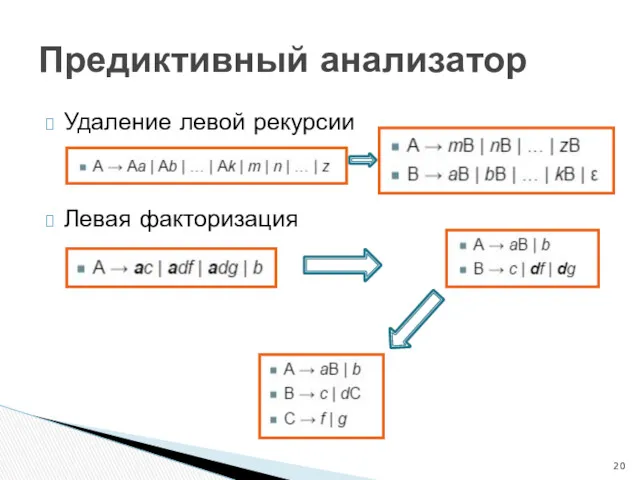
Удаление левой рекурсии
Левая факторизация
Предиктивный анализатор
Удаление левой рекурсии
Левая факторизация
Предиктивный анализатор

Пример преобразования
грамматики:
Предиктивный анализатор
Пример преобразования
грамматики:
Предиктивный анализатор

Определение множества FIRST
FIRST(a), a∈(N⋃T)* - множество терминалов или ℇ, с которых
Определение множества FIRST
FIRST(a), a∈(N⋃T)* - множество терминалов или ℇ, с которых

Определение множества FOLLOW
FOLLOW(A), A∈N – множества терминалов, которые могут появиться сразу
Определение множества FOLLOW
FOLLOW(A), A∈N – множества терминалов, которые могут появиться сразу

Пример построения FIRST, FOLLOW
Предиктивный анализ
Пример построения FIRST, FOLLOW
Предиктивный анализ

Построение таблицы
Предиктивный анализ
Построение таблицы
Предиктивный анализ

Пример построения таблицы
Предиктивный анализ
Пример построения таблицы
Предиктивный анализ

Предиктивный анализ, разбор
Предиктивный анализ, разбор
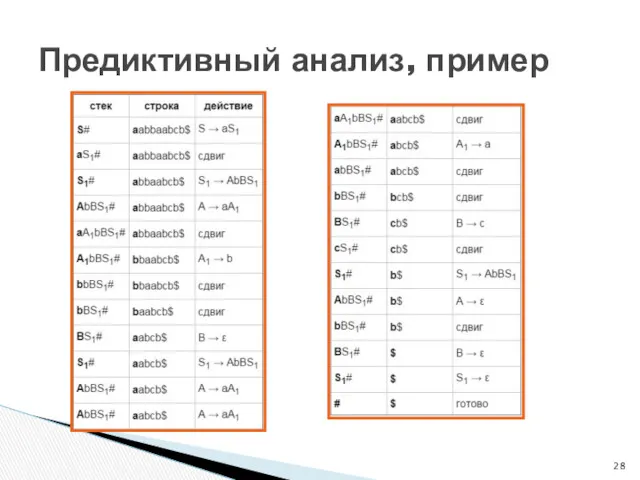
Предиктивный анализ, пример
Предиктивный анализ, пример

Строим дерево разбора начиная с листьев
Для большинства языков программирования можно построить
Строим дерево разбора начиная с листьев
Для большинства языков программирования можно построить

Построение LR(1) анализатора
1. Пополнение грамматики
2. Построение канонической системы множеств допустимых LR(1)-ситуаций
3.
Построение LR(1) анализатора
1. Пополнение грамматики
2. Построение канонической системы множеств допустимых LR(1)-ситуаций
3.

Пополнение грамматики
Добавим новое правило S' → S, и сделаем S' аксиомой
Пополнение грамматики
Добавим новое правило S' → S, и сделаем S' аксиомой

Каноническая система множеств
Вначале имеется множество I0 с конфигурацией анализатора S' → .S,
Каноническая система множеств
Вначале имеется множество I0 с конфигурацией анализатора S' → .S,
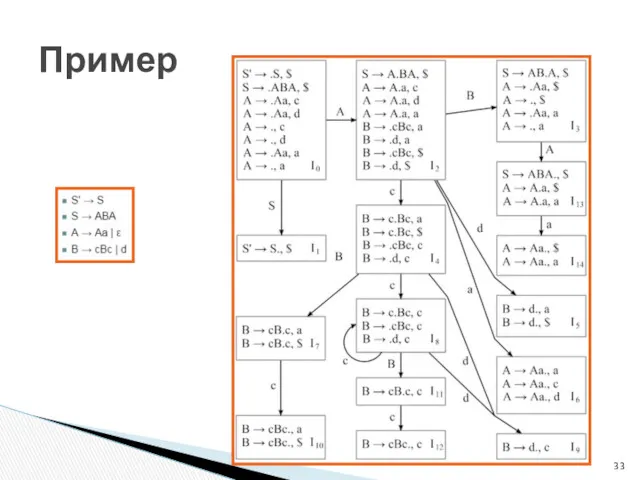
Пример
Пример

Построение Goto
Eсли в канонической системе множеств есть переход из Ii в Ij по символу A,
Построение Goto
Eсли в канонической системе множеств есть переход из Ii в Ij по символу A,

Построение action
Если есть переход по терминалу a из состояния Ii в состояние
Построение action
Если есть переход по терминалу a из состояния Ii в состояние

Пример
Пример

Восходящий анализ, разбор
Восходящий анализ, разбор

Восходящий анализ, пример
Восходящий анализ, пример

Баланс скобок {…{…(…)…(((…))…)…}…(…}…}
Верность выражений “+” между expr
Обрабатываемые ошибки
Баланс скобок {…{…(…)…(((…))…)…}…(…}…}
Верность выражений “+” между expr
Обрабатываемые ошибки
 Развитие вычислительной техники и архитектура персонального компьютера. (Лекция 2)
Развитие вычислительной техники и архитектура персонального компьютера. (Лекция 2) Организация RAID массивов
Организация RAID массивов Информационные системы менеджмента
Информационные системы менеджмента Расчет параметров полнодоступных систем РИ с ожиданием
Расчет параметров полнодоступных систем РИ с ожиданием Алгоритм распознавания цифр в речи
Алгоритм распознавания цифр в речи Научно-техническая информация
Научно-техническая информация Happy New Year! By Slidesgo. Here is where your presentation begins
Happy New Year! By Slidesgo. Here is where your presentation begins Університетське інтернет-телебачення
Університетське інтернет-телебачення Работа с файлами. Аргументы командной строки
Работа с файлами. Аргументы командной строки ЕЦУР: основные проблемы у ОМСУ и их решение
ЕЦУР: основные проблемы у ОМСУ и их решение Табличные виды данных. Одномерный массив
Табличные виды данных. Одномерный массив Бүгінгі күнгі Visual Basic және Delphi программалары
Бүгінгі күнгі Visual Basic және Delphi программалары Интеллектуальные информационные системы. (Лекция 1)
Интеллектуальные информационные системы. (Лекция 1) Интернет-этикет сетикет или по-другому нетикет
Интернет-этикет сетикет или по-другому нетикет Сравнение нотаций ВS с ARIS и BPMN 2022
Сравнение нотаций ВS с ARIS и BPMN 2022 PAYPASS. Инструкция проведений операций на POS-терминале. ЗАО КРЕДИТ ЕВРОПА БАНК
PAYPASS. Инструкция проведений операций на POS-терминале. ЗАО КРЕДИТ ЕВРОПА БАНК Свойства логических операций
Свойства логических операций Дистанционные методы исследования. Обработка данных MODIS в ENVI
Дистанционные методы исследования. Обработка данных MODIS в ENVI Параллельное программирование
Параллельное программирование Комп’ютерна дискретна математика. Відношення та їх властивості. (Лекція 3)
Комп’ютерна дискретна математика. Відношення та їх властивості. (Лекція 3) Инструкция по поиску информации в базе данных zbMATH
Инструкция по поиску информации в базе данных zbMATH Компьютерная графика. Классификации, характеристики и примеры
Компьютерная графика. Классификации, характеристики и примеры Мессенджеры и приложения как новый вид прессы
Мессенджеры и приложения как новый вид прессы Кунделик. Единая образовательная сеть
Кунделик. Единая образовательная сеть ძებნის ორობითი ხეები
ძებნის ორობითი ხეები SMM и контент-маркетинг
SMM и контент-маркетинг Разработка проекта обучающего web-сайта по информационным технологиям. Курсовая работа
Разработка проекта обучающего web-сайта по информационным технологиям. Курсовая работа Обработка и передача информации
Обработка и передача информации