- Лекция 8. Основы администрирования Hadoop

Содержание
- 2. План Установка Hadoop Администрирование MapReduce Администрирование HDFS
- 3. Установка Hadoop Операционные системы: Linux (продуктивные системы и разработка) Windows (только для разработки) Unix (официально не
- 4. Дистрибутивы Hadoop Дистрибутивы: Apache http://hadoop.apache.org/ Yahoo! http://developer.yahoo.com/hadoop/distribution/ Cloudera http://www.cloudera.com/hadoop/ В курсе используется дистрибутив Apache Дистрибутивы Yahoo!
- 5. Режимы работы Hadoop Локальный Все задачи выполняются на одной машине, данные хранятся в локальной файловой системе
- 6. Локальная установка Установить Java 1.6 (желательно от Sun) Скачать дистрибутив Hadoop Распаковать дистрибутив В конфигурационном файле
- 7. Karmasphere Studio Альтернативный вариант локальной установки для рабочего места разработчика: Установка Karmasphere Studio Karmasphere Studio включает
- 8. Псевдо-распределенный режим Особенности локального режима: Задачи Hadoop запускаются в рамках одного процесса Java Данные берутся и
- 9. Установка в псевдо-распределенном режиме Выполнить все действия локальной установки Настроить доступ на локальную машину по SSH
- 10. Конфигурационные файлы Дистрибутив Hadoop состоит из трех компонентов: Core (или Common) – общие компоненты HDFS MapReduce
- 11. Конфигурационные файлы В конфигурационных файлах прописываются только параметры, специфичные для данной установки Значения по умолчанию содержатся
- 12. Формат конфигурационных файлов Конфигурационный файл включает свойства, состоящие из имени и значения Используется формат xml Пример:
- 13. Конфигурационные файлы для псевдо-распределенного режима
- 14. Назначение свойств fs.default.name Адрес узла имен файловой системы HDFS по умолчанию dfs.replication Фактор репликации, количество копий
- 15. Установка в псевдо-распределенном режиме Форматирование HDFS: bin/hadoop namenode –format Запуск Hadoop: bin/start-all.sh Проверка работоспособности через Web-интерфейс:
- 16. Установка кластера Небольшой кластер, до 10 узлов Более крупным кластерам нужна дополнительная настройка
- 17. Кластер Hadoop
- 18. Кластер Hadoop Узлы кластера Hadoop: Сервер имен (NameNode), Master Сервер запуска задач (JobTracker), Master Рабочие серверы
- 19. Установка кластера На всех узлах: Синхронизировать время, например по NTP Установить Java Скачать и распаковать дистрибутив
- 20. Запуск команд на узлах Часто требуется запустить одинаковые команды на всех узлах кластера Hadoop для этой
- 21. Создание каталогов для HDFS HDFS по умолчанию хранит данные во временном каталоге (/tmp в Linux) Данные
- 22. Конфигурационные файлы
- 23. Назначение свойств hadoop.tmp.dir Адрес временного каталога Hadoop dfs.name.dir Каталог для хранения метаданных HDFS dfs.data.dir Каталог для
- 24. Установка кластера Заполненные конфигурационные файлы необходимо скопировать на все серверы кластера Форматирование HDFS: $ bin/hadoop namenode
- 25. Запуск и остановка кластера Запуск кластера Hadoop: $ bin/start-all.sh Запускается NameNode, JobTracker и на каждом узле
- 26. Журнальные файлы Hadoop записывает журналы в каталог logs Журналы ведутся отдельно для NameNode, JobTracker, DataNode и
- 27. Администрирование HDFS Просмотр статуса Проверка целостности файловой системы Управление репликацией Балансировка RackAwareness
- 28. Средства администрирования HDFS Командная строка: $ bin/hadoop dfsadmin Web: http://dfs-master:50070
- 29. Состояние HDFS $ bin/hadoop dfsadmin -report Configured Capacity: 708349218816 (659.7 GB) Present Capacity: 668208627712 (622.32 GB)
- 30. Состояние HDFS
- 31. Проверка целостности HDFS Целостность файловой системы: Файлы не повреждены Блоки не потеряны Присутствует необходимое количество копий
- 32. Управление репликацией Репликация – создание нескольких копий блоков на разных машинах Фактор репликации – количество копий
- 33. Балансировка Балансировка – равномерное распределение блоков данных по серверам Причины нарушения баланса: Добавление или удаление узлов
- 34. RackAwareness RackAwareness – способность HDFS «понимать», в каком «шкафу» находятся серверы кластера и создавать копии блока
- 35. RackAwareness Имя «шкафа» Hadoop определяет по IP-адресу сервера Для определения имени «шкафа» Hadoop вызывает внешний скрипт:
- 36. Итоги Установка Hadoop: Локальный режим Псевдо-распределенный режим Кластер Администрирование Hadoop Администрирование HDFS
- 37. Дополнительные материалы Hadoop Single Node Setup http://hadoop.apache.org/common/docs/stable/single_node_setup.html Hadoop Cluster Setup http://hadoop.apache.org/common/docs/stable/cluster_setup.html Hadoop Commands Guide http://hadoop.apache.org/common/docs/stable/commands_manual.html HDFS
- 39. Скачать презентацию

План
Установка Hadoop
Администрирование MapReduce
Администрирование HDFS
План
Установка Hadoop
Администрирование MapReduce
Администрирование HDFS

Установка Hadoop
Операционные системы:
Linux (продуктивные системы и разработка)
Windows (только для разработки)
Unix (официально
Установка Hadoop
Операционные системы:
Linux (продуктивные системы и разработка)
Windows (только для разработки)
Unix (официально

Дистрибутивы Hadoop
Дистрибутивы:
Apache http://hadoop.apache.org/
Yahoo! http://developer.yahoo.com/hadoop/distribution/
Cloudera http://www.cloudera.com/hadoop/
В курсе используется дистрибутив
Дистрибутивы Hadoop
Дистрибутивы:
Apache http://hadoop.apache.org/
Yahoo! http://developer.yahoo.com/hadoop/distribution/
Cloudera http://www.cloudera.com/hadoop/
В курсе используется дистрибутив

Режимы работы Hadoop
Локальный
Все задачи выполняются на одной машине, данные хранятся в
Режимы работы Hadoop
Локальный
Все задачи выполняются на одной машине, данные хранятся в

Локальная установка
Установить Java 1.6 (желательно от Sun)
Скачать дистрибутив Hadoop
Распаковать дистрибутив
В конфигурационном
Локальная установка
Установить Java 1.6 (желательно от Sun)
Скачать дистрибутив Hadoop
Распаковать дистрибутив
В конфигурационном

Karmasphere Studio
Альтернативный вариант локальной установки для рабочего места разработчика:
Установка Karmasphere Studio
Karmasphere
Karmasphere Studio
Альтернативный вариант локальной установки для рабочего места разработчика:
Установка Karmasphere Studio
Karmasphere

Псевдо-распределенный режим
Особенности локального режима:
Задачи Hadoop запускаются в рамках одного процесса Java
Данные
Псевдо-распределенный режим
Особенности локального режима:
Задачи Hadoop запускаются в рамках одного процесса Java
Данные

Установка в псевдо-распределенном режиме
Выполнить все действия локальной установки
Настроить доступ на локальную
Установка в псевдо-распределенном режиме
Выполнить все действия локальной установки
Настроить доступ на локальную

Конфигурационные файлы
Дистрибутив Hadoop состоит из трех компонентов:
Core (или Common) – общие
Конфигурационные файлы
Дистрибутив Hadoop состоит из трех компонентов:
Core (или Common) – общие

Конфигурационные файлы
В конфигурационных файлах прописываются только параметры, специфичные для данной установки
Значения
Конфигурационные файлы
В конфигурационных файлах прописываются только параметры, специфичные для данной установки
Значения

Формат конфигурационных файлов
Конфигурационный файл включает свойства, состоящие из имени и значения
Используется
Формат конфигурационных файлов
Конфигурационный файл включает свойства, состоящие из имени и значения
Используется

Конфигурационные файлы для псевдо-распределенного режима
Конфигурационные файлы для псевдо-распределенного режима

Назначение свойств
fs.default.name
Адрес узла имен файловой системы HDFS по умолчанию
dfs.replication
Фактор репликации, количество
Назначение свойств
fs.default.name
Адрес узла имен файловой системы HDFS по умолчанию
dfs.replication
Фактор репликации, количество

Установка в псевдо-распределенном режиме
Форматирование HDFS:
bin/hadoop namenode –format
Запуск Hadoop:
bin/start-all.sh
Проверка работоспособности через Web-интерфейс:
HDFS:
Установка в псевдо-распределенном режиме
Форматирование HDFS:
bin/hadoop namenode –format
Запуск Hadoop:
bin/start-all.sh
Проверка работоспособности через Web-интерфейс:
HDFS:

Установка кластера
Небольшой кластер, до 10 узлов
Более крупным кластерам нужна дополнительная настройка
Установка кластера
Небольшой кластер, до 10 узлов
Более крупным кластерам нужна дополнительная настройка
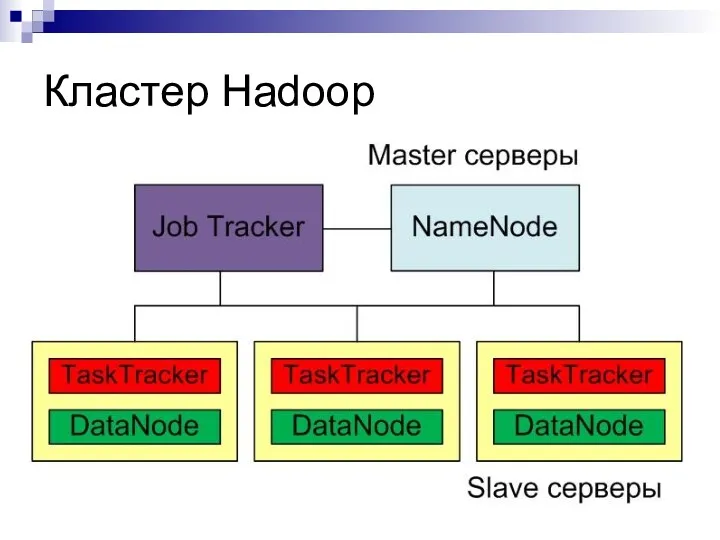
Кластер Hadoop
Кластер Hadoop

Кластер Hadoop
Узлы кластера Hadoop:
Сервер имен (NameNode), Master
Сервер запуска задач (JobTracker),
Кластер Hadoop
Узлы кластера Hadoop:
Сервер имен (NameNode), Master
Сервер запуска задач (JobTracker),

Установка кластера
На всех узлах:
Синхронизировать время, например по NTP
Установить Java
Скачать и распаковать
Установка кластера
На всех узлах:
Синхронизировать время, например по NTP
Установить Java
Скачать и распаковать

Запуск команд на узлах
Часто требуется запустить одинаковые команды на всех узлах
Запуск команд на узлах
Часто требуется запустить одинаковые команды на всех узлах

Создание каталогов для HDFS
HDFS по умолчанию хранит данные во временном каталоге
Создание каталогов для HDFS
HDFS по умолчанию хранит данные во временном каталоге

Конфигурационные файлы
Конфигурационные файлы

Назначение свойств
hadoop.tmp.dir
Адрес временного каталога Hadoop
dfs.name.dir
Каталог для хранения метаданных HDFS
dfs.data.dir
Каталог для хранения
Назначение свойств
hadoop.tmp.dir
Адрес временного каталога Hadoop
dfs.name.dir
Каталог для хранения метаданных HDFS
dfs.data.dir
Каталог для хранения

Установка кластера
Заполненные конфигурационные файлы необходимо скопировать на все серверы кластера
Форматирование HDFS:
$
Установка кластера
Заполненные конфигурационные файлы необходимо скопировать на все серверы кластера
Форматирование HDFS:
$

Запуск и остановка кластера
Запуск кластера Hadoop:
$ bin/start-all.sh
Запускается NameNode, JobTracker и на
Запуск и остановка кластера
Запуск кластера Hadoop:
$ bin/start-all.sh
Запускается NameNode, JobTracker и на

Журнальные файлы
Hadoop записывает журналы в каталог logs
Журналы ведутся отдельно для NameNode,
Журнальные файлы
Hadoop записывает журналы в каталог logs
Журналы ведутся отдельно для NameNode,

Администрирование HDFS
Просмотр статуса
Проверка целостности файловой системы
Управление репликацией
Балансировка
RackAwareness
Администрирование HDFS
Просмотр статуса
Проверка целостности файловой системы
Управление репликацией
Балансировка
RackAwareness

Средства администрирования HDFS
Командная строка:
$ bin/hadoop dfsadmin
Web:
http://dfs-master:50070
Средства администрирования HDFS
Командная строка:
$ bin/hadoop dfsadmin
Web:
http://dfs-master:50070
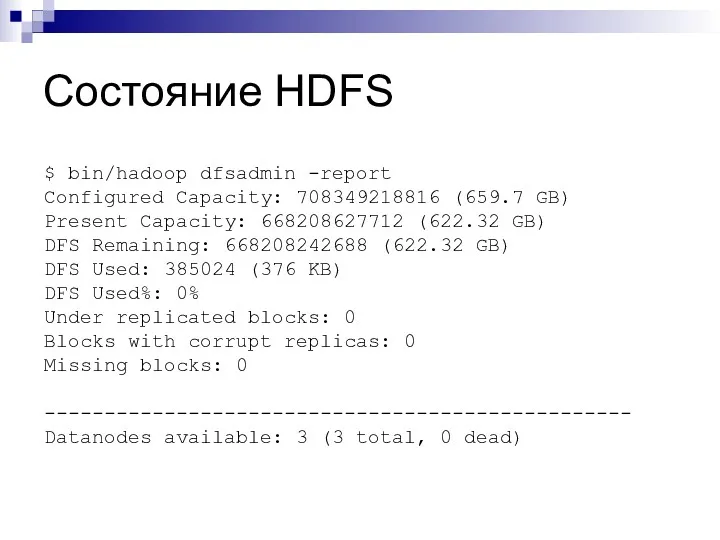
Состояние HDFS
$ bin/hadoop dfsadmin -report
Configured Capacity: 708349218816 (659.7 GB)
Present Capacity: 668208627712
Состояние HDFS
$ bin/hadoop dfsadmin -report
Configured Capacity: 708349218816 (659.7 GB)
Present Capacity: 668208627712
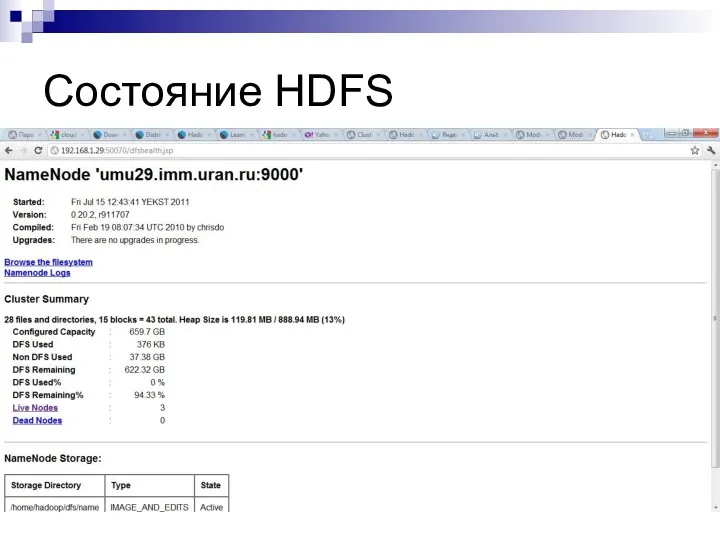
Состояние HDFS
Состояние HDFS

Проверка целостности HDFS
Целостность файловой системы:
Файлы не повреждены
Блоки не потеряны
Присутствует необходимое количество
Проверка целостности HDFS
Целостность файловой системы:
Файлы не повреждены
Блоки не потеряны
Присутствует необходимое количество

Управление репликацией
Репликация – создание нескольких копий блоков на разных машинах
Фактор репликации
Управление репликацией
Репликация – создание нескольких копий блоков на разных машинах
Фактор репликации

Балансировка
Балансировка – равномерное распределение блоков данных по серверам
Причины нарушения баланса:
Добавление или
Балансировка
Балансировка – равномерное распределение блоков данных по серверам
Причины нарушения баланса:
Добавление или

RackAwareness
RackAwareness – способность HDFS «понимать», в каком «шкафу» находятся серверы кластера
RackAwareness
RackAwareness – способность HDFS «понимать», в каком «шкафу» находятся серверы кластера

RackAwareness
Имя «шкафа» Hadoop определяет по IP-адресу сервера
Для определения имени «шкафа» Hadoop
RackAwareness
Имя «шкафа» Hadoop определяет по IP-адресу сервера
Для определения имени «шкафа» Hadoop

Итоги
Установка Hadoop:
Локальный режим
Псевдо-распределенный режим
Кластер
Администрирование Hadoop
Администрирование HDFS
Итоги
Установка Hadoop:
Локальный режим
Псевдо-распределенный режим
Кластер
Администрирование Hadoop
Администрирование HDFS

Дополнительные материалы
Hadoop Single Node Setup
http://hadoop.apache.org/common/docs/stable/single_node_setup.html
Hadoop Cluster Setup
http://hadoop.apache.org/common/docs/stable/cluster_setup.html
Hadoop Commands Guide
http://hadoop.apache.org/common/docs/stable/commands_manual.html
Дополнительные материалы
Hadoop Single Node Setup
http://hadoop.apache.org/common/docs/stable/single_node_setup.html
Hadoop Cluster Setup
http://hadoop.apache.org/common/docs/stable/cluster_setup.html
Hadoop Commands Guide
http://hadoop.apache.org/common/docs/stable/commands_manual.html
 Тестирование и тестировщики. Категории программных ошибок
Тестирование и тестировщики. Категории программных ошибок Wi-Fi. Обзор физического уровня
Wi-Fi. Обзор физического уровня Измерение информации
Измерение информации Моделирование и формализация. Моделирование как метод познания
Моделирование и формализация. Моделирование как метод познания Программная инженерия. Программное обеспечение (Software)
Программная инженерия. Программное обеспечение (Software) Елементи для введення даних: текстове поле, прапорець, випадаючий список
Елементи для введення даних: текстове поле, прапорець, випадаючий список Системы счисления. Двоичная система счисления
Системы счисления. Двоичная система счисления Современные направления в развитии информационного обеспечения логистики
Современные направления в развитии информационного обеспечения логистики Межпроцессное взаимодействие. Синхронизация потоков с использованием объектов ядра Windows 2000+
Межпроцессное взаимодействие. Синхронизация потоков с использованием объектов ядра Windows 2000+ Использование особенностей ИСР для создания пользовательского интерфейса
Использование особенностей ИСР для создания пользовательского интерфейса Файловые системы. Операции с файлами
Файловые системы. Операции с файлами Основы трехмерного моделирования в САПР КОМПАС - 3D
Основы трехмерного моделирования в САПР КОМПАС - 3D PostgreSQL. День 2
PostgreSQL. День 2 Oracle Transportation Management Manual for customs broker Manual for Plant
Oracle Transportation Management Manual for customs broker Manual for Plant Обработка целых чисел. Программирование на языке Python
Обработка целых чисел. Программирование на языке Python Компьютерная графика
Компьютерная графика Вредоносные программы. Методы профилактики и защиты
Вредоносные программы. Методы профилактики и защиты Проектирование информационных систем. (Лекция 10)
Проектирование информационных систем. (Лекция 10) Java.SE.01. Java fundamentals. Введение в язык java. Типы данных, переменные, операторы. Простейшие классы и объекты
Java.SE.01. Java fundamentals. Введение в язык java. Типы данных, переменные, операторы. Простейшие классы и объекты Информационные модели
Информационные модели Задачи по теме: Запросы и логические отношения
Задачи по теме: Запросы и логические отношения Качественные методы обработки данных
Качественные методы обработки данных Программирование на языке высокого уровня Паскаль
Программирование на языке высокого уровня Паскаль Сетевые технологии
Сетевые технологии Сравнительный анализ программ Аutocad и Компас-3d
Сравнительный анализ программ Аutocad и Компас-3d Правила техники безопасности в кабинете информатики
Правила техники безопасности в кабинете информатики DeepLight
DeepLight Условия выбора и сложные логические выражения. 9 класс
Условия выбора и сложные логические выражения. 9 класс