Лекція 1/10. Організація хеш-пошуку як узагальнення вибірки за прямою адресою, вибір хеш-функцій та розв’язання колізій презентация
- Лекція 1/10. Організація хеш-пошуку як узагальнення вибірки за прямою адресою, вибір хеш-функцій та розв’язання колізій

Содержание
- 2. Передумови виникнення методів пошуку за хеш-функціями гранично висока швидкість пошуку за прямою адресою; необхідність надмірно великого
- 3. Вибірка за прямою адресою // функція вибірки за прямою адресою на мові С/C++ struct recrd* selNmb(struct
- 4. Використання хеш-функції як узагаль-нення пошуку за прямою адресою давати детерміновані результати для кожного значення аргументу; обмеження
- 5. Методи розрахунку хеш-функцій метод залишку, за яким h(Аi) = Аi mod N, де N – велике
- 6. Вставки на мові Асемблера для розрахунку хеш-функцій // hash-функція за формулою як вставка на Асемблері unsigned
- 7. Структура елементів хеш-таблиць і хеш-індексів
- 8. Колізії та їх розв'язання Рехешування лінійним пошуком вільного місця біля обчисленої хеш-адреси, найбільш відоме і найменш
- 9. Алгоритм хеш-пошуку з розв'язанням колізій Початок Обчислення хеш-функції Перевірка аргументу Перевірка зайнятості Рехешування Результат успішний Формування
- 10. Приклад програми розв'язання колізій на мові С/C++ рехешування лінійним пошуком // розв'язання колізій unsigned hColRes (struct
- 11. Визначення якості hash-функцій Дослідження якості та ефективності hash-функцій спирається на визначенні критеріїв для: - Статистики рівномірності
- 12. БАГАТОСЕГМЕНТНІ ТАБЛИЦІ ТА ІНДЕКСИ Багатосегментні таблиці є найбільш загальним варіантом побудови таблиць і індексів, які повинні
- 13. ВИМОГИ УНІКАЛЬНОСТІ КЛЮЧІВ В БАГАТОСЕГМЕНТНИХ ТАБЛИЦЯХ Здебільшого таблиці в системних прог-рамах працюють за вимоги унікальності ключів
- 15. Скачать презентацию

Передумови виникнення методів пошуку за хеш-функціями
гранично висока швидкість пошуку за прямою
Передумови виникнення методів пошуку за хеш-функціями
гранично висока швидкість пошуку за прямою

Вибірка за прямою адресою
// функція вибірки за прямою адресою на мові
Вибірка за прямою адресою
// функція вибірки за прямою адресою на мові

Використання хеш-функції як узагаль-нення пошуку за прямою адресою
давати детерміновані результати для
Використання хеш-функції як узагаль-нення пошуку за прямою адресою
давати детерміновані результати для

Методи розрахунку хеш-функцій
метод залишку, за яким h(Аi) = Аi mod N,
Методи розрахунку хеш-функцій
метод залишку, за яким h(Аi) = Аi mod N,

Вставки на мові Асемблера для розрахунку хеш-функцій
// hash-функція за формулою як
Вставки на мові Асемблера для розрахунку хеш-функцій
// hash-функція за формулою як

Структура елементів
хеш-таблиць і хеш-індексів
Структура елементів
хеш-таблиць і хеш-індексів

Колізії та їх розв'язання
Рехешування лінійним пошуком вільного місця біля обчисленої хеш-адреси,
Колізії та їх розв'язання
Рехешування лінійним пошуком вільного місця біля обчисленої хеш-адреси,
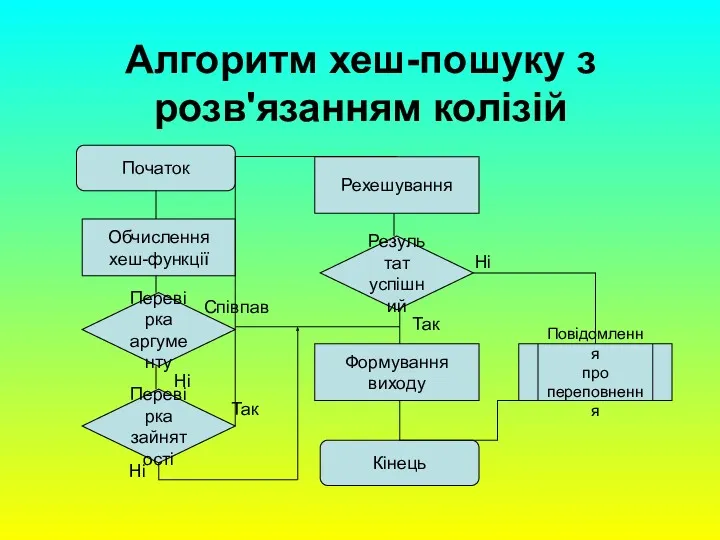
Алгоритм хеш-пошуку з розв'язанням колізій
Початок
Обчислення
хеш-функції
Перевірка
аргументу
Перевірка
зайнятості
Рехешування
Результат
успішний
Формування
виходу
Кінець
Повідомлення
про
переповнення
Так
Співпав
Ні
Так
Ні
Ні
Алгоритм хеш-пошуку з розв'язанням колізій
Початок
Обчислення
хеш-функції
Перевірка
аргументу
Перевірка
зайнятості
Рехешування
Результат
успішний
Формування
виходу
Кінець
Повідомлення
про
переповнення
Так
Співпав
Ні
Так
Ні
Ні

Приклад програми розв'язання колізій на мові С/C++ рехешування лінійним пошуком
// розв'язання
Приклад програми розв'язання колізій на мові С/C++ рехешування лінійним пошуком
// розв'язання

Визначення якості hash-функцій
Дослідження якості та ефективності hash-функцій спирається на визначенні критеріїв
Визначення якості hash-функцій
Дослідження якості та ефективності hash-функцій спирається на визначенні критеріїв

БАГАТОСЕГМЕНТНІ ТАБЛИЦІ ТА ІНДЕКСИ
Багатосегментні таблиці є найбільш загальним варіантом побудови
БАГАТОСЕГМЕНТНІ ТАБЛИЦІ ТА ІНДЕКСИ
Багатосегментні таблиці є найбільш загальним варіантом побудови

ВИМОГИ УНІКАЛЬНОСТІ КЛЮЧІВ В БАГАТОСЕГМЕНТНИХ ТАБЛИЦЯХ
Здебільшого таблиці в системних прог-рамах працюють
ВИМОГИ УНІКАЛЬНОСТІ КЛЮЧІВ В БАГАТОСЕГМЕНТНИХ ТАБЛИЦЯХ
Здебільшого таблиці в системних прог-рамах працюють
 Команды ОС. Диалог ОС с пользователем
Команды ОС. Диалог ОС с пользователем Дельфи ортасында бағдарламалау
Дельфи ортасында бағдарламалау Векторный графический редактор Open office.org Draw
Векторный графический редактор Open office.org Draw Язык UML. Диаграммы деятельности. Варианты использования
Язык UML. Диаграммы деятельности. Варианты использования Интервью
Интервью Запуск в эксплуатацию системы ARIA SOHO
Запуск в эксплуатацию системы ARIA SOHO Использование инновационных технологий на основе дидактической реконструкции материала
Использование инновационных технологий на основе дидактической реконструкции материала Добро пожаловать в мотивационую программу территориальных управляющих
Добро пожаловать в мотивационую программу территориальных управляющих Работа с одаренными детьми на уроке информатики
Работа с одаренными детьми на уроке информатики Принципы машинного обучения, нейронных сетей
Принципы машинного обучения, нейронных сетей Викторина Предметы
Викторина Предметы Базы данных
Базы данных Логическое программирование
Логическое программирование Путешествие по клавиатуре. Урок-игра
Путешествие по клавиатуре. Урок-игра Форматирование текстового документа. Форматирование символов и абзацев
Форматирование текстового документа. Форматирование символов и абзацев Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары
Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары Образ здания и его назначение
Образ здания и его назначение Разработка прогнозной модели качества приборов на основе нейросетевой модели
Разработка прогнозной модели качества приборов на основе нейросетевой модели Информационная модель лечебно-диагностического процесса
Информационная модель лечебно-диагностического процесса Состав и методы теоретических исследований
Состав и методы теоретических исследований Основные устройства компьютера
Основные устройства компьютера Задания по параллельному программированию
Задания по параллельному программированию Библиографический и информационный поиск
Библиографический и информационный поиск Microsoft Word мәтінді мәтінді форматтау
Microsoft Word мәтінді мәтінді форматтау Лекция 5. Случайные процессы
Лекция 5. Случайные процессы Двовимірні масиви
Двовимірні масиви Операционная система FreeBSD
Операционная система FreeBSD Тактирование приложений
Тактирование приложений