Лекція 1/7. Відношення порядку, впорядкування таблиць та використання двійкового пошуку для вибірки даних презентация
- Лекція 1/7. Відношення порядку, впорядкування таблиць та використання двійкового пошуку для вибірки даних

Содержание
- 2. Відношення порядку Впорядкування таблиць за ключовими полями стає можливим лише у випадку впорядкування кодів кожного з
- 3. Узагальнення відношень порядку В найбільш загальному випадку ключі таблиць можуть включати декілька полів, в тому числі
- 4. Функції порівняння // порівняння рядків за відношенням нерівності int neqKey(struct recrd* el, struct keyStr kArg) {return
- 5. Приклад порівняння рядків на мові Асемблера Процедура порівняння рядків за відношенням порядку на мові С та
- 6. Двійковий пошук // вибірка за двійковим пошуком struct recrd*selBin (struct keyStr kArg,// ключ аргументу пошуку struct
- 7. Підсумки До найбільш поширених базових методів роботи з таблицями належать пошук за прямою адресою, лінійний пошук
- 9. Скачать презентацию

Відношення порядку
Впорядкування таблиць за ключовими полями стає можливим лише у випадку
Відношення порядку
Впорядкування таблиць за ключовими полями стає можливим лише у випадку

Узагальнення відношень порядку
В найбільш загальному випадку ключі таблиць можуть включати декілька
Узагальнення відношень порядку
В найбільш загальному випадку ключі таблиць можуть включати декілька

Функції порівняння
// порівняння рядків за відношенням нерівності
int neqKey(struct recrd* el,
Функції порівняння
// порівняння рядків за відношенням нерівності
int neqKey(struct recrd* el,

Приклад порівняння рядків на мові Асемблера
Процедура порівняння рядків за відношенням порядку
Приклад порівняння рядків на мові Асемблера
Процедура порівняння рядків за відношенням порядку

Двійковий пошук
// вибірка за двійковим пошуком
struct recrd*selBin (struct keyStr kArg,// ключ
Двійковий пошук
// вибірка за двійковим пошуком
struct recrd*selBin (struct keyStr kArg,// ключ

Підсумки
До найбільш поширених базових методів роботи з таблицями належать пошук за
Підсумки
До найбільш поширених базових методів роботи з таблицями належать пошук за
 Контроль качества построения 3Д сетки и осреднения скважинных данных на сетку
Контроль качества построения 3Д сетки и осреднения скважинных данных на сетку Основы теории журналистики
Основы теории журналистики Безопасный интернет
Безопасный интернет Управление ресурсами предприятия (ERP)
Управление ресурсами предприятия (ERP) Проектирование АСУ. Комплекс подсистем технической подготовки производства
Проектирование АСУ. Комплекс подсистем технической подготовки производства Представление графических данных. Форматы графических данных
Представление графических данных. Форматы графических данных Створення ігрових комп’ютерних програм на прикладі гри Монополія
Створення ігрових комп’ютерних програм на прикладі гри Монополія Игра Blade & Soul
Игра Blade & Soul Сравнительный анализ операционных систем Windows и Mac OS
Сравнительный анализ операционных систем Windows и Mac OS Алгоритм ветвление
Алгоритм ветвление Настройка рабочей станции с доступом в интернет по технологии Wi-Fi
Настройка рабочей станции с доступом в интернет по технологии Wi-Fi Электронные таблицы
Электронные таблицы Формирование математических способностей учащихся через развитие логического мышления
Формирование математических способностей учащихся через развитие логического мышления Создание текстовых документов на компьютере. Обработка текстовой информации. Информатика. 7 класс
Создание текстовых документов на компьютере. Обработка текстовой информации. Информатика. 7 класс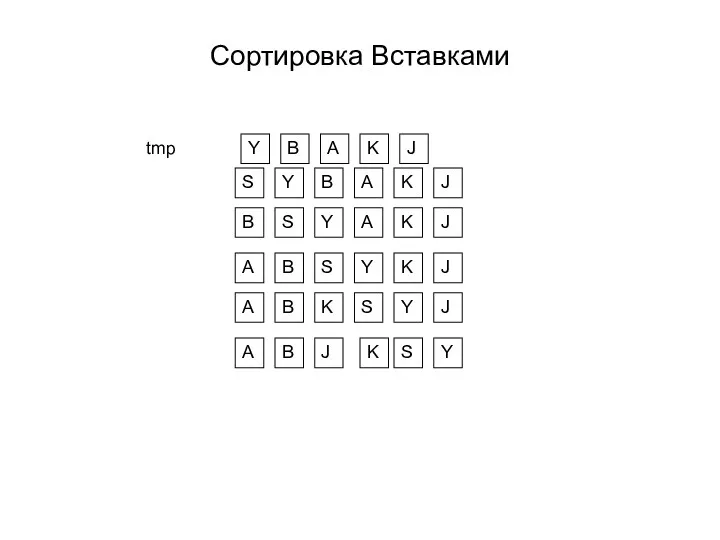 Виды сортировок
Виды сортировок Этапы моделирования
Этапы моделирования Информационные технологии обучения персонала. Состав базы данных для определения потребности в обучении:
Информационные технологии обучения персонала. Состав базы данных для определения потребности в обучении: Конспекты уроков 10 класс (1 четверть)
Конспекты уроков 10 класс (1 четверть) Покрокова інструкція зі створення відеокліпа за допомогою програми MS Windows Movie Maker
Покрокова інструкція зі створення відеокліпа за допомогою програми MS Windows Movie Maker Первое поколение ЭВМ (1948-1958)
Первое поколение ЭВМ (1948-1958) Презентация Блок-схемы. Линейные алгоритмы
Презентация Блок-схемы. Линейные алгоритмы Структурное программирование в Step7
Структурное программирование в Step7 Цифровое портфолио
Цифровое портфолио Организация службы IP-телефонии
Организация службы IP-телефонии Java input output-library
Java input output-library Возврат не день в день. Розница. Карта
Возврат не день в день. Розница. Карта Применение ИКТ на уроках музыки
Применение ИКТ на уроках музыки Программа CorelDRAW
Программа CorelDRAW