- Линейные модели регрессии в задачах дискретной классификации

Содержание
- 2. 3.6 Линейные модели регрессии в задачах дискретной классификации Рассчитываемая оценка является непрерывной величиной. К ней применяется
- 3. 3.6.1 Бинарная классификация Наиболее распространенные: логистическая регрессия (logistic regression), реализованная в классе linear_model.LogisticRegression; линейный метод опорных
- 4. 3.6.1 Бинарная классификация Границы принятия решений отделяют 2 области: область значений, классифицированных как класс 1 (верхняя
- 5. 3.6.1 Бинарная классификация # зависимость работы классификатора лин. SVM от параметра регуляризации С mglearn.plots.plot_linear_svc_regularization() Сильно регуляризованная
- 6. 3.6.1 Бинарная классификация Для высокоразмерных наборов данных линейные модели становятся сложными и существует высокая вероятность переобучения.
- 7. 3.6.1 Бинарная классификация По умолчанию используется L2 регуляризация. (!) Регуляризация L1 позволяет отобрать признаки по важности
- 8. 3.6.2 Множественная классификация Способ расширения алгоритма бинарной классификации до случаев мультиклассовой классификации называется «один против всех»
- 9. 3.6.2 Множественная классификация Применим к двумерному массиву данных, где каждый класс задается гауссовским распределением: X, y
- 10. 3.6.2 Множественная классификация Визуализация границ принятия решений, полученных на трех бинарных классификаторах. # исп. L1 регуляризац
- 11. 3.6.3 Выводы по линейным моделям регрессии в задачах дискретной классификации Основные параметры линейных моделей: параметр регуляризации
- 12. 3.6.3 Выводы по линейным моделям регрессии в задачах дискретной классификации Рекомендации: Цепочки функций (method chaining) Method
- 13. 3.7 Наивные байесовские классификаторы Наивные байесовские классификаторы рассматривают каждый признак отдельно: рассчитываются статистические характеристики признаков Виды
- 14. 3.7 Наивные байесовские классификаторы Классификатор BernoulliNB подсчитывает ненулевые частоты признаков по каждому классу: # Здесь 4
- 15. 3.7 Наивные байесовские классификаторы MultinomialNB и GaussianNB считают иные статистические параметры каждого признака для каждого класса:
- 16. 3.7 Наивные байесовские классификаторы Наивные байесовские модели разделяют многие преимущества и недостатки линейных моделей. Достоинства: быстро
- 17. 3.8 Деревья решений Лист (leaf) Т.Е. Деревья можно использовать для решения задач классификации и дискретных, и
- 18. Пример: методика построения По сути - задаются вопросы и выстраивается иерархия правил «если… то», приводящая к
- 19. 3.8.1 Деревья решений в задаче дискретной классификации Первый прогон (тест). «тест» здесь ≠ тестовая выборка! Разделение
- 20. 3.8.1 Деревья решений в задаче дискретной классификации Прогон 2. Разделение отдельно каждого узла по вертикали. Наиболее
- 21. 3.8.1 Деревья решений в задаче дискретной классификации Рекурсивный процесс прогонов строит в итоге бинарное дерево решений.
- 22. 3.8.1 Деревья решений в задаче дискретной классификации Прогноз для нового ввода: находится область разбиения пространства, к
- 23. 3.8.1 Деревья решений в задаче дискретной классификации Граница принятия решений фокусируется на отдельных точках-выбросах: Стратегии от
- 24. 3.8.1 Деревья решений в задаче дискретной классификации Пример предварительной обрезки для набора Breast Cancer. Задание13: Загрузить
- 25. 3.8.1 Деревья решений в задаче дискретной классификации Ограничение глубины дерева уменьшает переобучение. Это приводит к более
- 26. 3.8.1 Деревья решений в задаче дискретной классификации print("Важности признаков:\n{}".format(tree.feature_importances_)) Визуализация дерева, анализ важности признаков Для визуализации
- 27. 3.8.1 Деревья решений в задаче дискретной классификации Визуализация дерева, анализ важности признаков # или для удобства
- 28. 3.8.2 Деревья решений в задаче классификации regression В библиотеке scikit-learn деревья решений для regression реализованы в
- 29. 3.8.2 Деревья решений в задаче классификации regression Пример: прогноз цен на период после 2000 года. Сравнение
- 30. 3.8.2 Деревья решений в задаче классификации regression Пример: прогноз цен на период после 2000 года. Сравнение
- 31. 3.8.2 Деревья решений в задаче классификации regression Сравнение прогнозов с реальными данными data_train = ram_prices[ram_prices.date plt.semilogy(data_train.date,
- 33. Скачать презентацию

3.6 Линейные модели регрессии в задачах дискретной классификации
Рассчитываемая оценка является непрерывной
3.6 Линейные модели регрессии в задачах дискретной классификации
Рассчитываемая оценка является непрерывной

3.6.1 Бинарная классификация
Наиболее распространенные:
логистическая регрессия (logistic regression), реализованная в классе linear_model.LogisticRegression;
3.6.1 Бинарная классификация
Наиболее распространенные:
логистическая регрессия (logistic regression), реализованная в классе linear_model.LogisticRegression;

3.6.1 Бинарная классификация
Границы принятия решений отделяют 2 области: область значений, классифицированных
3.6.1 Бинарная классификация
Границы принятия решений отделяют 2 области: область значений, классифицированных

3.6.1 Бинарная классификация
# зависимость работы классификатора лин. SVM от параметра регуляризации
3.6.1 Бинарная классификация
# зависимость работы классификатора лин. SVM от параметра регуляризации

3.6.1 Бинарная классификация
Для высокоразмерных наборов данных линейные модели становятся сложными и
3.6.1 Бинарная классификация
Для высокоразмерных наборов данных линейные модели становятся сложными и

3.6.1 Бинарная классификация
По умолчанию используется L2 регуляризация.
(!) Регуляризация L1 позволяет
3.6.1 Бинарная классификация
По умолчанию используется L2 регуляризация.
(!) Регуляризация L1 позволяет

3.6.2 Множественная классификация
Способ расширения алгоритма бинарной классификации до случаев мультиклассовой классификации
3.6.2 Множественная классификация
Способ расширения алгоритма бинарной классификации до случаев мультиклассовой классификации

3.6.2 Множественная классификация
Применим к двумерному массиву данных, где каждый класс задается
3.6.2 Множественная классификация
Применим к двумерному массиву данных, где каждый класс задается

3.6.2 Множественная классификация
Визуализация границ принятия решений, полученных на трех бинарных классификаторах.
#
3.6.2 Множественная классификация
Визуализация границ принятия решений, полученных на трех бинарных классификаторах.
#

3.6.3 Выводы по линейным моделям регрессии в задачах дискретной классификации
Основные параметры
3.6.3 Выводы по линейным моделям регрессии в задачах дискретной классификации
Основные параметры

3.6.3 Выводы по линейным моделям регрессии в задачах дискретной классификации
Рекомендации:
Цепочки
3.6.3 Выводы по линейным моделям регрессии в задачах дискретной классификации
Рекомендации:
Цепочки

3.7 Наивные байесовские классификаторы
Наивные байесовские классификаторы рассматривают каждый признак отдельно:
рассчитываются
3.7 Наивные байесовские классификаторы
Наивные байесовские классификаторы рассматривают каждый признак отдельно:
рассчитываются

3.7 Наивные байесовские классификаторы
Классификатор BernoulliNB подсчитывает ненулевые частоты признаков по каждому
3.7 Наивные байесовские классификаторы
Классификатор BernoulliNB подсчитывает ненулевые частоты признаков по каждому

3.7 Наивные байесовские классификаторы
MultinomialNB и GaussianNB считают иные статистические параметры каждого
3.7 Наивные байесовские классификаторы
MultinomialNB и GaussianNB считают иные статистические параметры каждого

3.7 Наивные байесовские классификаторы
Наивные байесовские модели разделяют многие преимущества и недостатки
3.7 Наивные байесовские классификаторы
Наивные байесовские модели разделяют многие преимущества и недостатки
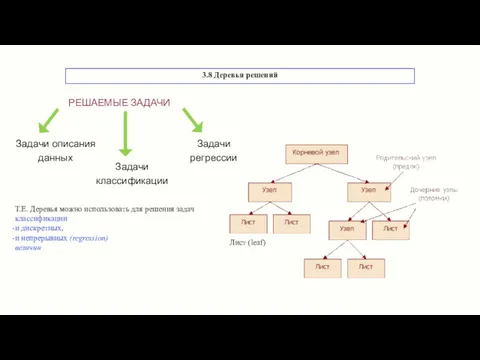
3.8 Деревья решений
Лист (leaf)
Т.Е. Деревья можно использовать для решения задач
3.8 Деревья решений
Лист (leaf)
Т.Е. Деревья можно использовать для решения задач
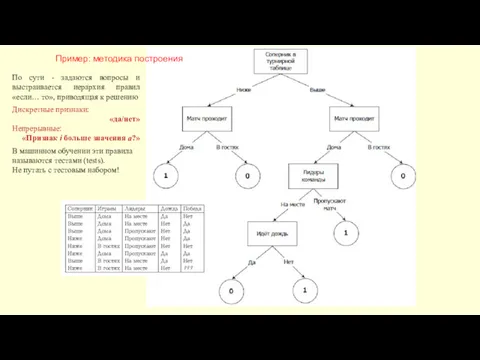
Пример: методика построения
По сути - задаются вопросы и выстраивается иерархия правил
Пример: методика построения
По сути - задаются вопросы и выстраивается иерархия правил
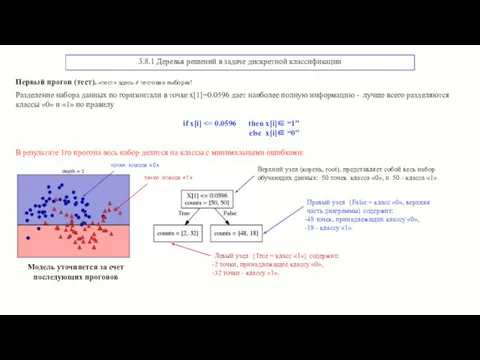
3.8.1 Деревья решений в задаче дискретной классификации
Первый прогон (тест). «тест» здесь
3.8.1 Деревья решений в задаче дискретной классификации
Первый прогон (тест). «тест» здесь
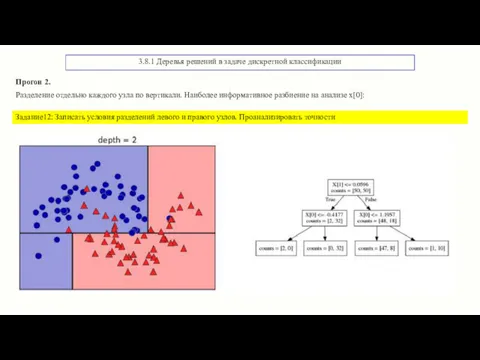
3.8.1 Деревья решений в задаче дискретной классификации
Прогон 2.
Разделение отдельно каждого узла
3.8.1 Деревья решений в задаче дискретной классификации
Прогон 2.
Разделение отдельно каждого узла

3.8.1 Деревья решений в задаче дискретной классификации
Рекурсивный процесс прогонов строит в
3.8.1 Деревья решений в задаче дискретной классификации
Рекурсивный процесс прогонов строит в
3.8.1 Деревья решений в задаче дискретной классификации
Прогноз для нового ввода:
находится область
3.8.1 Деревья решений в задаче дискретной классификации
Прогноз для нового ввода:
находится область
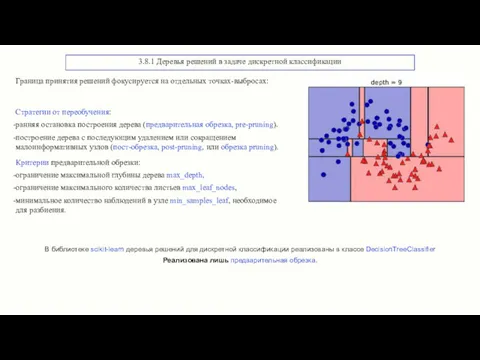
3.8.1 Деревья решений в задаче дискретной классификации
Граница принятия решений фокусируется на
3.8.1 Деревья решений в задаче дискретной классификации
Граница принятия решений фокусируется на

3.8.1 Деревья решений в задаче дискретной классификации
Пример предварительной обрезки для набора
3.8.1 Деревья решений в задаче дискретной классификации
Пример предварительной обрезки для набора

3.8.1 Деревья решений в задаче дискретной классификации
Ограничение глубины дерева уменьшает переобучение.
3.8.1 Деревья решений в задаче дискретной классификации
Ограничение глубины дерева уменьшает переобучение.

3.8.1 Деревья решений в задаче дискретной классификации
print("Важности признаков:\n{}".format(tree.feature_importances_))
Визуализация дерева, анализ
3.8.1 Деревья решений в задаче дискретной классификации
print("Важности признаков:\n{}".format(tree.feature_importances_))
Визуализация дерева, анализ

3.8.1 Деревья решений в задаче дискретной классификации
Визуализация дерева, анализ важности признаков
#
3.8.1 Деревья решений в задаче дискретной классификации
Визуализация дерева, анализ важности признаков
#
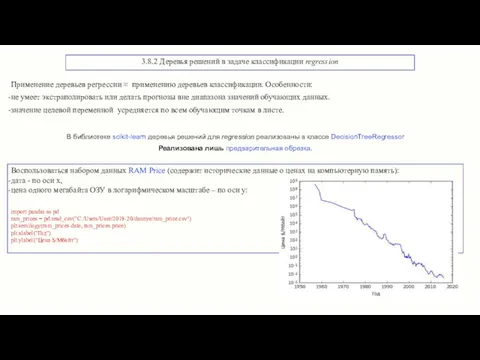
3.8.2 Деревья решений в задаче классификации regression
В библиотеке scikit-learn деревья решений
3.8.2 Деревья решений в задаче классификации regression
В библиотеке scikit-learn деревья решений

3.8.2 Деревья решений в задаче классификации regression
Пример: прогноз цен на период
3.8.2 Деревья решений в задаче классификации regression
Пример: прогноз цен на период

3.8.2 Деревья решений в задаче классификации regression
Пример: прогноз цен на период
3.8.2 Деревья решений в задаче классификации regression
Пример: прогноз цен на период
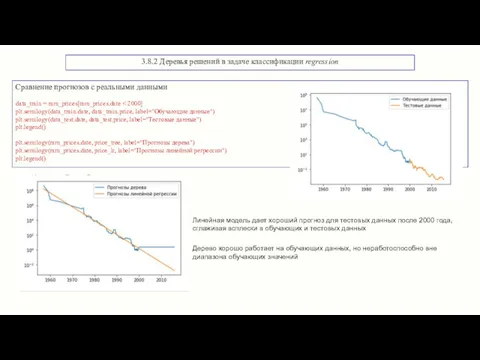
3.8.2 Деревья решений в задаче классификации regression
Сравнение прогнозов с реальными данными
data_train
3.8.2 Деревья решений в задаче классификации regression
Сравнение прогнозов с реальными данными
data_train
 Шагающие роботы
Шагающие роботы Квантовый компьютер: вчера, сегодня, завтра
Квантовый компьютер: вчера, сегодня, завтра Вольтметр с усреднением значений отсчетов
Вольтметр с усреднением значений отсчетов Модели информационной защиты. Модели информационных нарушителей. (Глава 3. Часть 2)
Модели информационной защиты. Модели информационных нарушителей. (Глава 3. Часть 2) Алгоритм и его формальное исполнение
Алгоритм и его формальное исполнение Представление чисел в компьютере.
Представление чисел в компьютере. Данная и новая информация текста
Данная и новая информация текста Основные информационные процессы
Основные информационные процессы Компютерное моделирование
Компютерное моделирование Компьютерные сети
Компьютерные сети Методы анализа КС на РС. Задачи. Основные методы. Многозначная логика
Методы анализа КС на РС. Задачи. Основные методы. Многозначная логика Рейтинг мобильных приложений
Рейтинг мобильных приложений Ввод-вывод. (Тема 16)
Ввод-вывод. (Тема 16) STL Algorithm
STL Algorithm Журналистика в современном социокультурном пространстве
Журналистика в современном социокультурном пространстве Программирование на языке QBasic
Программирование на языке QBasic Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Операции над файлами. Язык программирования Basic
Операции над файлами. Язык программирования Basic LSMW Material data load using BAPI
LSMW Material data load using BAPI Доказательство правильности программ. Структурное программирование
Доказательство правильности программ. Структурное программирование Кибернетика. Её основные понятия и результаты
Кибернетика. Её основные понятия и результаты Тестирование защиты программного обеспечения. Тема 2.10
Тестирование защиты программного обеспечения. Тема 2.10 Компьютер, как универсальное устройство для работы с информацией
Компьютер, как универсальное устройство для работы с информацией Компьютер и компьютерные технологии обучения (КТО)
Компьютер и компьютерные технологии обучения (КТО) Арифметические и логические основы работы компьютера
Арифметические и логические основы работы компьютера Блокировка интернет страниц через официальный сайт Роскомнадзора
Блокировка интернет страниц через официальный сайт Роскомнадзора Медицинский личный кабинет
Медицинский личный кабинет Передача информации в древние времена и сегодня
Передача информации в древние времена и сегодня