- Методы анализа данных (лекция 1)

Содержание
- 2. Лекция 1 Интеллектуальный анализ данных Понятие интеллектуального анализа данных соответствует широко распространенному термину Data Mining, который
- 3. Состав рынка интеллектуальных технологий Содержит набор программных продуктов следующих классов: - средства построения хранилищ данных (Data
- 4. Данные обеспечивают получение информации, поддерживающую решения Информационная пирамида Уровень бизнеса
- 5. Набор данных и их атрибутов Данные представляют собой факты, текст, графики, картинки, звуки, аналоговые или цифровые
- 6. Задачи Data Mining Задачи подразделяются по типам производимой информации: - классификация, прогнозирование. В результате решения задачи
- 7. Основы анализа данных Описательная статистика, включающая технологии сбора и суммирования количественных данных, используется для превращения массы
- 8. Корреляционный анализ Корреляционный анализ применяется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде.
- 9. Последовательность этапов регрессионного анализа При помощи регрессионного анализа можно получить конкретные сведения о том, какую форму
- 10. Задачи, решаемые регрессионным анализом При помощи регрессионного анализа возможно решение задачи прогнозирования и классификации. Основные задачи
- 11. Прогнозирование Прогнозирование – установление функциональной зависимости между зависимыми и независимыми переменными. Целью прогнозирования является предсказание будущих
- 12. Задача кластеризации Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры, или классы). Кластер можно
- 13. Иерархический алгоритм кластерного анализа
- 14. Факторный анализ Факторный анализ – это метод, применяемый для изучения взаимосвязей между значениями переменных. Факторный анализ
- 15. Задача визуализации В результате использования визуализации создается графический образ данных. К способам визуального или графического представления
- 16. Этапы интеллектуального анализа Процесс интеллектуального анализа и обработки данных состоит из следующих шести этапов: отбор данных,
- 17. Инструментальные средства анализа данных Инструменты Data Mining во многих случаях рассматриваются как составная часть BI-платформ, в
- 19. Скачать презентацию

Лекция 1 Интеллектуальный анализ данных
Понятие интеллектуального анализа данных соответствует
Лекция 1 Интеллектуальный анализ данных
Понятие интеллектуального анализа данных соответствует

Состав рынка интеллектуальных технологий
Содержит набор программных продуктов следующих классов:
Состав рынка интеллектуальных технологий
Содержит набор программных продуктов следующих классов:
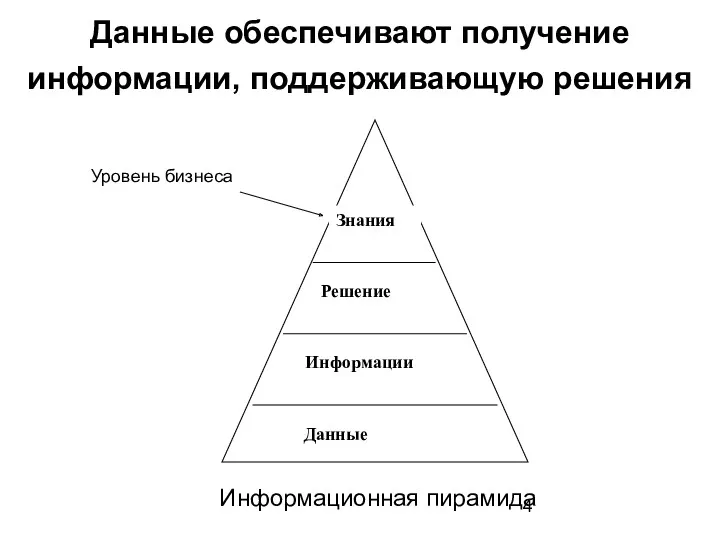
Данные обеспечивают получение информации, поддерживающую решения
Информационная пирамида
Уровень бизнеса
Данные обеспечивают получение информации, поддерживающую решения
Информационная пирамида
Уровень бизнеса

Набор данных и их атрибутов
Данные представляют собой факты, текст,
Набор данных и их атрибутов
Данные представляют собой факты, текст,

Задачи Data Mining
Задачи подразделяются по типам производимой информации:
-
Задачи Data Mining
Задачи подразделяются по типам производимой информации:
-

Основы анализа данных
Описательная статистика, включающая технологии сбора и суммирования количественных
Основы анализа данных
Описательная статистика, включающая технологии сбора и суммирования количественных
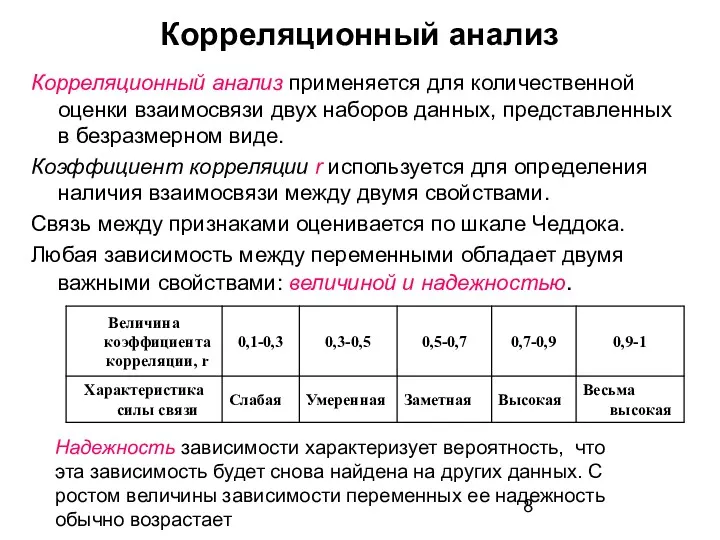
Корреляционный анализ
Корреляционный анализ применяется для количественной оценки взаимосвязи двух наборов
Корреляционный анализ
Корреляционный анализ применяется для количественной оценки взаимосвязи двух наборов

Последовательность этапов регрессионного анализа
При помощи регрессионного анализа можно получить конкретные
Последовательность этапов регрессионного анализа
При помощи регрессионного анализа можно получить конкретные

Задачи, решаемые регрессионным анализом
При помощи регрессионного анализа возможно решение задачи прогнозирования
Задачи, решаемые регрессионным анализом
При помощи регрессионного анализа возможно решение задачи прогнозирования

Прогнозирование
Прогнозирование – установление функциональной зависимости между зависимыми и независимыми переменными.
Прогнозирование
Прогнозирование – установление функциональной зависимости между зависимыми и независимыми переменными.

Задача кластеризации
Кластеризация предназначена для разбиения совокупности объектов на однородные группы
Задача кластеризации
Кластеризация предназначена для разбиения совокупности объектов на однородные группы

Иерархический алгоритм кластерного анализа
Иерархический алгоритм кластерного анализа

Факторный анализ
Факторный анализ – это метод, применяемый для изучения взаимосвязей между
Факторный анализ
Факторный анализ – это метод, применяемый для изучения взаимосвязей между
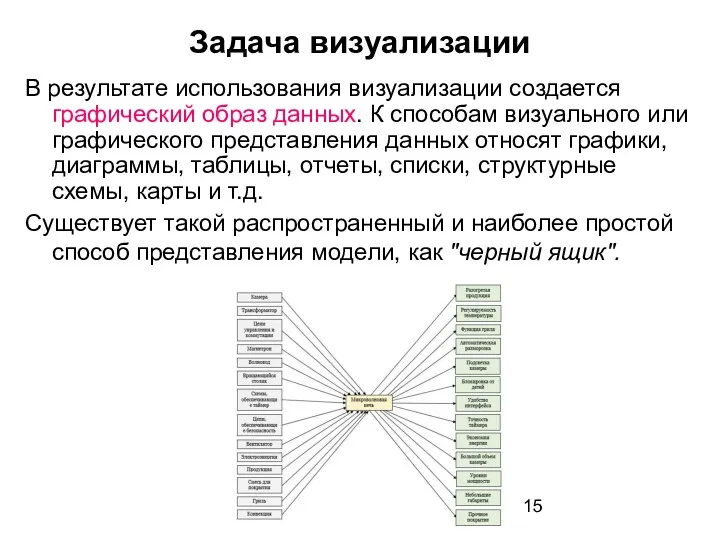
Задача визуализации
В результате использования визуализации создается графический образ данных. К
Задача визуализации
В результате использования визуализации создается графический образ данных. К

Этапы интеллектуального анализа
Процесс интеллектуального анализа и обработки данных состоит из
Этапы интеллектуального анализа
Процесс интеллектуального анализа и обработки данных состоит из

Инструментальные средства анализа данных
Инструменты Data Mining во многих случаях рассматриваются
Инструментальные средства анализа данных
Инструменты Data Mining во многих случаях рассматриваются
 Логическое программирование (Prolog)
Логическое программирование (Prolog) Организация ввода и вывода данных. Начала программирования
Организация ввода и вывода данных. Начала программирования Техническое задание для создания сайта. Описание структуры
Техническое задание для создания сайта. Описание структуры Материалы к обсуждению Искусственный интеллект: онтологический и социальный аспекты
Материалы к обсуждению Искусственный интеллект: онтологический и социальный аспекты разработка сети широкополосного доступа в селе Нылга, Увинского района по технологии GPON
разработка сети широкополосного доступа в селе Нылга, Увинского района по технологии GPON Автоматизированные и автоматические системы управления
Автоматизированные и автоматические системы управления Персональный компьютер: устройство и принцип работы
Персональный компьютер: устройство и принцип работы Introduction to Java Web
Introduction to Java Web Устав команды поддержки
Устав команды поддержки Многоуровневые ИВС и эталонная модель взаимосвязи открытых систем. Занятие 05, 06
Многоуровневые ИВС и эталонная модель взаимосвязи открытых систем. Занятие 05, 06 Онлайн-марафон Ты больше, чем ты думаешь
Онлайн-марафон Ты больше, чем ты думаешь Программирование на алгоритмическом языке (7 класс)
Программирование на алгоритмическом языке (7 класс) Формирование информационной культуры школьника в рамках реализации концепции развития информационно-библиотечных центров
Формирование информационной культуры школьника в рамках реализации концепции развития информационно-библиотечных центров Сервис Личный кабинет. Федерация дзюдо
Сервис Личный кабинет. Федерация дзюдо Списки в Python
Списки в Python Система коммунального автомониторинга управления и телеметрии. Фотопрезентация
Система коммунального автомониторинга управления и телеметрии. Фотопрезентация Introduction of the ILS/VOR/DME
Introduction of the ILS/VOR/DME Глобальная сеть. Адресация в Интернете. Протоколы обмена и передачи данных
Глобальная сеть. Адресация в Интернете. Протоколы обмена и передачи данных Обзор вариантов установки программ
Обзор вариантов установки программ Измерение информации
Измерение информации Информатикадан ашық сабақ
Информатикадан ашық сабақ Основы программирования (ОП)
Основы программирования (ОП) Библиотека. История библиотек
Библиотека. История библиотек Cerberus Mouse FW update SOP
Cerberus Mouse FW update SOP Объектно-ориентированное программирование. Механизмы рефлексии. (Занятие 9)
Объектно-ориентированное программирование. Механизмы рефлексии. (Занятие 9) Антивирус Касперского
Антивирус Касперского Правила безопасности в Интернете
Правила безопасности в Интернете Программирование на языке Python. Алгоритм и его свойства
Программирование на языке Python. Алгоритм и его свойства