- Методы обучения с учителем

Содержание
- 2. Mglearn Учебная библиотека Python pip install mglearn
- 3. Современные методы анализа данных Байесовский классификатор линейный дискриминант Фишера; метод парзеновского окна; разделение смеси вероятностных распределений,
- 4. 3. Методы обучения с учителем Воспользуемся следующими методами машинного обучения: Ближайшего соседа Линейные модели Наивный байесовский
- 5. 3. Методы обучения с учителем Общие правила и термины методов классификации Если классификатор может выдавать точные
- 6. 3. Методы обучения с учителем Пример недообучения / переобучения Спрогнозировать покупку клиентом лодки на основе данных
- 7. 3.1 Используемые наборы данных Искусственные наборы forg и wave библиотеки mglearn: #------------набор данных forge-----------------------генерируем набор данных
- 8. 3.1 Используемые наборы данных Экспериментальные наборы типа Bunch: cancer и Boston Housing библиотеки scikit-learn: #объект Bunch
- 9. 3.2 Метод k-ближайших соседей: корректный выбор числа n Задание2: применительно к набору forge использовать метод k-ближайших
- 10. 3.2 Метод k-ближайших соседей: корректный выбор числа n plt.plot(neighbors_settings, training_accuracy, label="правильность на обучающем наборе") plt.plot(neighbors_settings, test_accuracy,
- 11. 3.3 Регрессия k-ближайших соседей Используем набор wave и обучающую библиотеку mglearn X, y = mglearn.datasets.make_wave(n_samples=40) #
- 12. 3.3 Регрессия k-ближайших соседей Коэффициент детерминации R2 - это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью
- 13. 3.3 Регрессия k-ближайших соседей Пояснения точности при разных n с использованием библиотеки mglearn # пояснение количества
- 14. 3.3 Регрессия k-ближайших соседей Анализ точности при разных n на основе расчета коэффициента детерминации # используем
- 15. 3.3 Регрессия k-ближайших соседей при n=1 каждая точка обучающего набора имеет очевидное влияние на классификацию ⇒
- 16. 3.4 Выводы по алгоритмам k-ближайших соседей Наиболее важные параметры классификатора KNeighbors: количество соседей n, метрика расстояния
- 17. 3.5 Линейные модели регрессии в задачах классификации непрерывных величин Это регрессионные модели, в которых прогнозом является
- 18. 3.5.1 Линейная модель МНК (ordinary least squares, OLS) Модели МНК - самые простые. Для набора wave
- 19. 3.5.1 Линейная модель МНК (ordinary least squares, OLS) Задание6: Разделить исходный массив данных wave (n_samples=60) на
- 20. 3.5.1 Линейная модель МНК (ordinary least squares, OLS) Задание7: Оценить точность классификатора на обучающем и на
- 21. 3.5.2 Линейная модель «гребневая регрессия» (Ridge) Гребневая регрессия = линейная модель регрессии, формула та же. Отличия
- 22. 3.5.2 Линейная модель «гребневая регрессия» (Ridge) Задание9: для набора данных Boston c производными признаками, используя модель
- 23. 3.5.2 Линейная модель «гребневая регрессия» (Ridge) Варьируя коэффициент регуляризации α (параметр alpha), можно регулировать «штраф» ⇒
- 24. 3.5.2 Линейная модель «гребневая регрессия» (Ridge) Анализ влияния объема выборки данных Boston на точности моделей LinearRegression
- 25. 3.5.3 Линейная модель «лассо» (Lasso) Лассо регрессия ≈ гребневая модель регрессии: коэффициенты w1, w1, … выбираются
- 26. 3.5.3 Линейная модель «лассо» (Lasso) Задание10: для набора данных Boston c производными признаками, используя модель Lasso
- 27. 3.5.3 Линейная модель «лассо» (Lasso) # уменьшаем альфа, одновремено увеличиваем max_iter (иначе выдаст предупреждение) lasso001 =
- 28. 3.5.4 Выводы по линейным моделям регрессии в задачах классификации непрерывных величин Когда стоит выбор между Ridge
- 30. Скачать презентацию
Mglearn
Учебная библиотека Python
pip install mglearn
Mglearn
Учебная библиотека Python
pip install mglearn

Современные методы анализа данных
Байесовский классификатор
линейный дискриминант Фишера;
метод парзеновского окна;
разделение смеси вероятностных
Современные методы анализа данных
Байесовский классификатор
линейный дискриминант Фишера;
метод парзеновского окна;
разделение смеси вероятностных

3. Методы обучения с учителем
Воспользуемся следующими методами машинного обучения:
Ближайшего соседа
Линейные модели
Наивный
3. Методы обучения с учителем
Воспользуемся следующими методами машинного обучения:
Ближайшего соседа
Линейные модели
Наивный

3. Методы обучения с учителем
Общие правила и термины методов классификации
Если классификатор
3. Методы обучения с учителем
Общие правила и термины методов классификации
Если классификатор

3. Методы обучения с учителем
Пример недообучения / переобучения
Спрогнозировать покупку клиентом лодки
3. Методы обучения с учителем
Пример недообучения / переобучения
Спрогнозировать покупку клиентом лодки

3.1 Используемые наборы данных
Искусственные наборы forg и wave библиотеки mglearn:
#------------набор данных
3.1 Используемые наборы данных
Искусственные наборы forg и wave библиотеки mglearn:
#------------набор данных

3.1 Используемые наборы данных
Экспериментальные наборы типа Bunch: cancer и Boston Housing
3.1 Используемые наборы данных
Экспериментальные наборы типа Bunch: cancer и Boston Housing

3.2 Метод k-ближайших соседей: корректный выбор числа n
Задание2: применительно к набору
3.2 Метод k-ближайших соседей: корректный выбор числа n
Задание2: применительно к набору

3.2 Метод k-ближайших соседей: корректный выбор числа n
plt.plot(neighbors_settings, training_accuracy, label="правильность на
3.2 Метод k-ближайших соседей: корректный выбор числа n
plt.plot(neighbors_settings, training_accuracy, label="правильность на

3.3 Регрессия k-ближайших соседей
Используем набор wave и обучающую библиотеку mglearn
X, y
3.3 Регрессия k-ближайших соседей
Используем набор wave и обучающую библиотеку mglearn
X, y

3.3 Регрессия k-ближайших соседей
Коэффициент детерминации R2 - это доля дисперсии зависимой
3.3 Регрессия k-ближайших соседей
Коэффициент детерминации R2 - это доля дисперсии зависимой
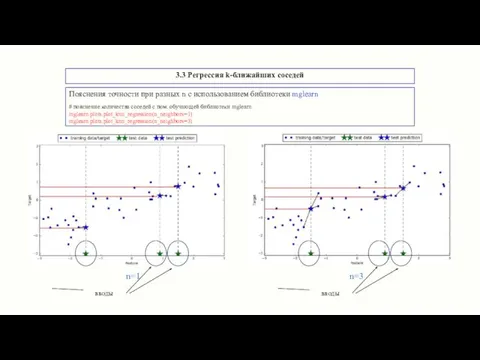
3.3 Регрессия k-ближайших соседей
Пояснения точности при разных n с использованием библиотеки
3.3 Регрессия k-ближайших соседей
Пояснения точности при разных n с использованием библиотеки

3.3 Регрессия k-ближайших соседей
Анализ точности при разных n на основе расчета
3.3 Регрессия k-ближайших соседей
Анализ точности при разных n на основе расчета
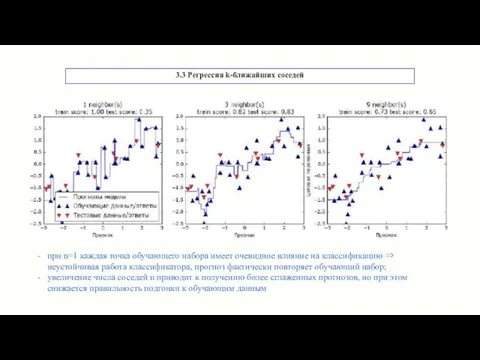
3.3 Регрессия k-ближайших соседей
при n=1 каждая точка обучающего набора имеет очевидное
3.3 Регрессия k-ближайших соседей
при n=1 каждая точка обучающего набора имеет очевидное

3.4 Выводы по алгоритмам k-ближайших соседей
Наиболее важные параметры классификатора KNeighbors:
количество
3.4 Выводы по алгоритмам k-ближайших соседей
Наиболее важные параметры классификатора KNeighbors:
количество

3.5 Линейные модели регрессии в задачах классификации непрерывных величин
Это регрессионные модели,
3.5 Линейные модели регрессии в задачах классификации непрерывных величин
Это регрессионные модели,
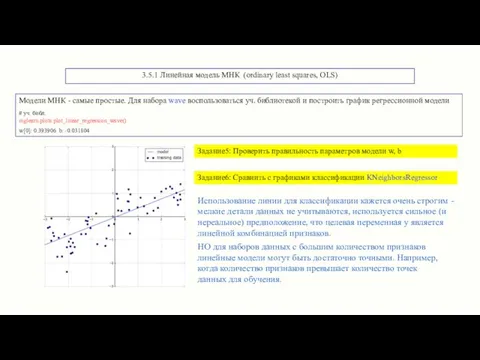
3.5.1 Линейная модель МНК (ordinary least squares, OLS)
Модели МНК - самые
3.5.1 Линейная модель МНК (ordinary least squares, OLS)
Модели МНК - самые

3.5.1 Линейная модель МНК (ordinary least squares, OLS)
Задание6: Разделить исходный массив
3.5.1 Линейная модель МНК (ordinary least squares, OLS)
Задание6: Разделить исходный массив

3.5.1 Линейная модель МНК (ordinary least squares, OLS)
Задание7: Оценить точность классификатора
3.5.1 Линейная модель МНК (ordinary least squares, OLS)
Задание7: Оценить точность классификатора

3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Гребневая регрессия = линейная модель регрессии,
3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Гребневая регрессия = линейная модель регрессии,

3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Задание9: для набора данных Boston c
3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Задание9: для набора данных Boston c

3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Варьируя коэффициент регуляризации α (параметр alpha),
3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Варьируя коэффициент регуляризации α (параметр alpha),

3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Анализ влияния объема выборки данных Boston
3.5.2 Линейная модель «гребневая регрессия» (Ridge)
Анализ влияния объема выборки данных Boston

3.5.3 Линейная модель «лассо» (Lasso)
Лассо регрессия ≈ гребневая модель регрессии:
коэффициенты w1,
3.5.3 Линейная модель «лассо» (Lasso)
Лассо регрессия ≈ гребневая модель регрессии:
коэффициенты w1,

3.5.3 Линейная модель «лассо» (Lasso)
Задание10: для набора данных Boston c производными
3.5.3 Линейная модель «лассо» (Lasso)
Задание10: для набора данных Boston c производными

3.5.3 Линейная модель «лассо» (Lasso)
# уменьшаем альфа, одновремено увеличиваем max_iter (иначе
3.5.3 Линейная модель «лассо» (Lasso)
# уменьшаем альфа, одновремено увеличиваем max_iter (иначе

3.5.4 Выводы по линейным моделям регрессии в задачах классификации непрерывных величин
Когда
3.5.4 Выводы по линейным моделям регрессии в задачах классификации непрерывных величин
Когда
 Основы кибербезопасности. Лекция 4.1. Понятие об источниках и каналах утечки информации; основы технической защиты информации
Основы кибербезопасности. Лекция 4.1. Понятие об источниках и каналах утечки информации; основы технической защиты информации Что такое Dota
Что такое Dota Сравнение двух языков
Сравнение двух языков Разработка программного приложения с пользовательским интерфейсом в С#. Основные элементы
Разработка программного приложения с пользовательским интерфейсом в С#. Основные элементы Проектная деятельность на уроках информатики
Проектная деятельность на уроках информатики Вычисление на компьютере с помощью калькулятора. 5 класс
Вычисление на компьютере с помощью калькулятора. 5 класс Назначение и функции операционных систем. (Лекция 2)
Назначение и функции операционных систем. (Лекция 2) Разработка уроков по теме Сайтостроение
Разработка уроков по теме Сайтостроение Язык программирования JavaScript
Язык программирования JavaScript Операциялық жүйе
Операциялық жүйе 3G technology
3G technology Система управления версиями (VCS)
Система управления версиями (VCS) Информация и её свойства. Информация и информационные процессы. Информатика. 7 класс
Информация и её свойства. Информация и информационные процессы. Информатика. 7 класс Основные задачи администрирования ОС. Системный администратор. Типовые задачи системного администрирования. (Лекция 15)
Основные задачи администрирования ОС. Системный администратор. Типовые задачи системного администрирования. (Лекция 15) Практические навыки организации работы сети
Практические навыки организации работы сети Функциональные возможности Microsoft Office
Функциональные возможности Microsoft Office Соціальна мережа Instagram
Соціальна мережа Instagram Полиморфизм (C#, лекция 3)
Полиморфизм (C#, лекция 3) Десять трендов маркетинга здравоохранения
Десять трендов маркетинга здравоохранения Арифметические действия в различных системах счислениях
Арифметические действия в различных системах счислениях Разработка видеоигры жанра стратегия-roguelike
Разработка видеоигры жанра стратегия-roguelike HDD - плата управления
HDD - плата управления Основы программирования. Типы данных и арифметические операции
Основы программирования. Типы данных и арифметические операции Выполнение работ по профессии Оператор электронно-вычислительных и вычислительных машин
Выполнение работ по профессии Оператор электронно-вычислительных и вычислительных машин Solaris - операционная система для архитектуры SPARC
Solaris - операционная система для архитектуры SPARC Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера Онлайн-переводчики и ГДЗ: помощники или вредители
Онлайн-переводчики и ГДЗ: помощники или вредители Иллюстрированные правила игры. Twilight imperium 3rd edition
Иллюстрированные правила игры. Twilight imperium 3rd edition