Национальный исследовательский нижегородский государственный университет им. Н.И. Лобачевского презентация
- Национальный исследовательский нижегородский государственный университет им. Н.И. Лобачевского

Содержание
- 2. Параллельное программирование с использованием OpenMP
- 3. Содержание Основы Подходы к разработке многопоточных программ Состав OpenMP Модель выполнения Модель памяти Создание потоков Формирование
- 4. Содержание Способы распределения работы между потоками Распараллеливание циклов Распараллеливание циклов с редукцией Векторизация threadprivate-данные Функциональный параллелизм
- 5. ОСНОВЫ Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г.
- 6. Подходы к разработке многопоточных программ Использование библиотеки потоков (POSIX, Windows Threads, ...) Использование возможностей языка программирования
- 7. Пример: вычисление числа π Значение π может быть вычислено через интеграл Для вычисления определенного интеграла можно
- 8. Пример программы на C++ int num_steps = 100000000; double step; double Pi() { double x, sum
- 9. Пример программы на Windows Threads… #include int num_steps = 100000000; double step; const int NUM_THREADS =
- 10. Пример программы на Windows Threads int main() { int i; double pi = 0; DWORD threadID;
- 11. Пример программы на C++ Threads… #include #include int num_steps = 100000000; double step; const int NUM_THREADS
- 12. Пример программы на C++ Threads int main() { int i; double pi = 0; std::thread threads[NUM_THREADS]
- 13. Пример программы на OpenMP int main() { int num_steps = 100000000; const int NUM_THREADS = 4;
- 14. Структура OpenMP Компоненты: Набор директив компилятора. Библиотека функций. Набор переменных окружения. Изложение материала будет проводиться на
- 15. Модель выполнения «Пульсирующий» (fork-join) параллелизм. *Источник: http://en.wikipedia.org/wiki/OpenMP Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020
- 16. Модель памяти Рассматривается модель стандартов до OpenMP 4.0 (до появления поддержки гетерогенного программирования) В OpenMP-программе два
- 17. СОЗДАНИЕ ПОТОКОВ Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г.
- 18. Формирование параллельной области Формат директивы parallel : #pragma omp parallel [clause ...] structured_block Возможные параметры (clauses):
- 19. Формирование параллельной области Директива parallel (основная директива OpenMP): Когда основной поток выполнения достигает директивы parallel ,
- 20. Пример использования директивы… #include void main() { int nthreads; // Создание параллельной области #pragma omp parallel
- 21. Пример использования директивы Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. Примечание: Порядок вывода
- 22. Установка количества потоков Способы задания (по убыванию старшинства) Параметр директивы: num_threads(N) Функция установки числа потоков: omp_set_num_threads(N)
- 23. Определение времени выполнения параллельной программы Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. double
- 24. Управление областью видимости Управление областью видимости обеспечивается при помощи параметров директив: shared, default private firstprivate lastprivate
- 25. Параметр shared Параметр shared определяет список переменных, которые будут общими для всех потоков параллельной области. #pragma
- 26. Параметр private Параметр private определяет список переменных, которые будут локальными для каждого потока. #pragma omp parallel
- 27. Пример использования директивы private Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. #include void
- 28. Параметр firstprivate Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием инициализируются значениями исходных переменных.
- 29. Параметр lastprivate Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются в исходных переменных после
- 30. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. БИБЛИОТЕКА ФУНКЦИЙ
- 31. Функции управления выполнением… Задать число потоков в параллельных областях void omp_set_num_threads(int num_threads) Вернуть число потоков в
- 32. Функции управления выполнением… Вернуть номер потока в параллельной области int omp_get_thread_num(void) Вернуть число процессоров, доступных приложению
- 33. Вложенный параллелизм Включить/выключить вложенный параллелизм int omp_set_nested(int) Вернуть, включен ли вложенный параллелизм int omp_get_nested(void) Параллельное программирование
- 34. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. ПРИВЯЗКА ПОТОКОВ
- 35. Параметр proc_bind У директивы parallel в стандарте 4.0 был добавлен параметр proc_bind, определяющий способы «привязки» потоков
- 36. Параметр proc_bind Формат параметра proc_bind #pragma omp parallel proc_bind(master | close | spread) close Распределить потоки
- 37. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. СПОСОБЫ РАСПРЕДЕЛЕНИЯ РАБОТЫ МЕЖДУ ПОТОКАМИ
- 38. Директивы распределения вычислений между потоками Существует 3 директивы для распределения вычислений в параллельной области: for –
- 39. Распараллеливание циклов Формат директивы for: #pragma omp for [clause ...] for loop Основные параметры: private(list) firstprivate(list)
- 40. Пример использования директивы for #include #define CHUNK 100 #define NMAX 1000 void main() { int i,
- 41. Директива for. Параметр schedule static – итерации делятся на блоки по chunk итераций и статически разделяются
- 42. Пример использования директивы for #include #define CHUNK 100 #define NMAX 1000 void main() { int i,
- 43. Объединение директив parallel и for/sections #include #define CHUNK 100 #define NMAX 1000 void main() { int
- 44. Распараллеливание циклов с редукцией Параметр reduction определяет список переменных, для которых выполняется операция редукции. reduction (operator:
- 45. Пример использования параметра reduction #include void main() { int i, n, chunk; float a[100], b[100], result;
- 46. Правила записи параметра reduction Возможный формат записи выражения: x = x op expr x = expr
- 47. Векторизация цикла… Директива simd – «просьба» компилятору векторизовать нижеследующий(-ие) цикл(-ы) Формат директивы simd #pragma omp simd
- 48. Векторизация цикла Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. #pragma simd #pragma omp
- 49. Директива threadprivate… Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. const int Size =
- 50. Директива threadprivate Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. printf("\n"); for (i =
- 51. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. СИНХРОНИЗАЦИЯ
- 52. Директива master Директива master определяет фрагмент кода, который должен быть выполнен только основным потоком Все остальные
- 53. Директива barrier Директива barrier определяет точку синхронизации, которую должны достигнуть все потоки для продолжения вычислений (директива
- 54. Директива single Директива single определяет фрагмент кода, который должен быть выполнен только одним потоком (любым) Один
- 55. Директива critical… Директива critical определяет фрагмент кода, который должен выполняться только одним потоком в каждый текущий
- 56. Директива critical Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. #include main() { int
- 57. Директива atomic Директива atomic определяет переменную, операция с которой (чтение/запись) должна быть выполнена как неделимая Формат
- 58. Директива atomic Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. #include main() { int
- 59. Функции управления замками… В качестве замков используются переменные типа omp_lock_t. Инициализировать замок void omp_init_lock(omp_lock_t *lock) Удалить
- 60. Функции управления замками Захватить замок, если он свободен, иначе ждать освобождения void omp_set_lock(omp_lock_t *lock) Освободить захваченный
- 61. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2020 г. ПЕРЕМЕННЫЕ ОКРУЖЕНИЯ
- 62. Функции управления выполнением… OMP_SCHEDULE – определяет способ распределения итераций в цикле, если в директиве for использована
- 64. Скачать презентацию

Параллельное программирование с использованием OpenMP
Параллельное программирование с использованием OpenMP

Содержание
Основы
Подходы к разработке многопоточных программ
Состав OpenMP
Модель выполнения
Модель памяти
Создание потоков
Формирование параллельной области
Задание числа потоков
Управление областью видимости
Библиотека функций
Привязка потоков
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,
Содержание
Основы
Подходы к разработке многопоточных программ
Состав OpenMP
Модель выполнения
Модель памяти
Создание потоков
Формирование параллельной области
Задание числа потоков
Управление областью видимости
Библиотека функций
Привязка потоков
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,

Содержание
Способы распределения работы между потоками
Распараллеливание циклов
Распараллеливание циклов с редукцией
Векторизация
threadprivate-данные
Функциональный параллелизм (sections)
Механизм задач
Синхронизация
Вложенный параллелизм
Переменные окружения
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
Содержание
Способы распределения работы между потоками
Распараллеливание циклов
Распараллеливание циклов с редукцией
Векторизация
threadprivate-данные
Функциональный параллелизм (sections)
Механизм задач
Синхронизация
Вложенный параллелизм
Переменные окружения
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.

ОСНОВЫ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
ОСНОВЫ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.

Подходы к разработке многопоточных
программ
Использование библиотеки потоков
(POSIX, Windows Threads, ...)
Использование возможностей языка программирования
(C++ 11, …)
Использование технологии ПП
(OpenMP, TBB, ...)
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
Подходы к разработке многопоточных
программ
Использование библиотеки потоков
(POSIX, Windows Threads, ...)
Использование возможностей языка программирования
(C++ 11, …)
Использование технологии ПП
(OpenMP, TBB, ...)
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
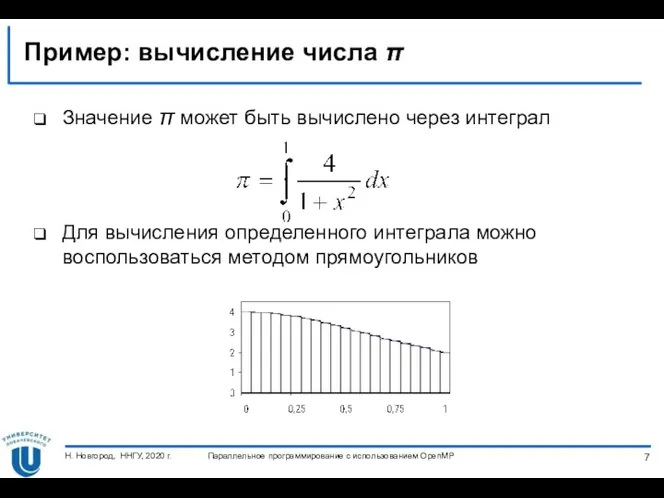
Пример: вычисление числа π
Значение π может быть вычислено через интеграл
Для вычисления
Пример: вычисление числа π
Значение π может быть вычислено через интеграл
Для вычисления
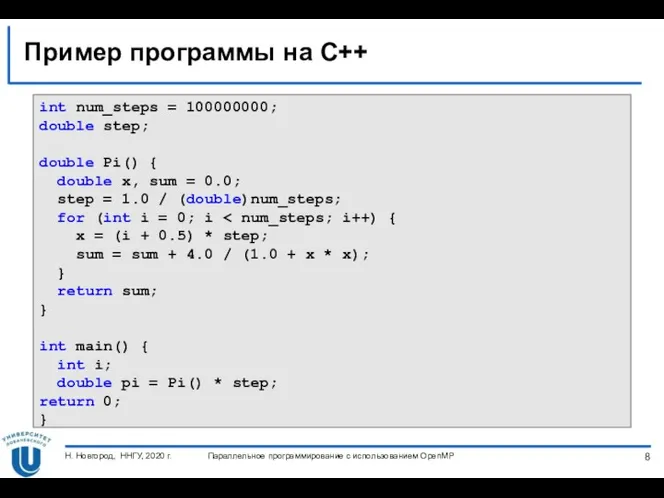
Пример программы на C++
int num_steps = 100000000;
double step;
double Pi() {
double x, sum =
Пример программы на C++
int num_steps = 100000000;
double step;
double Pi() {
double x, sum =
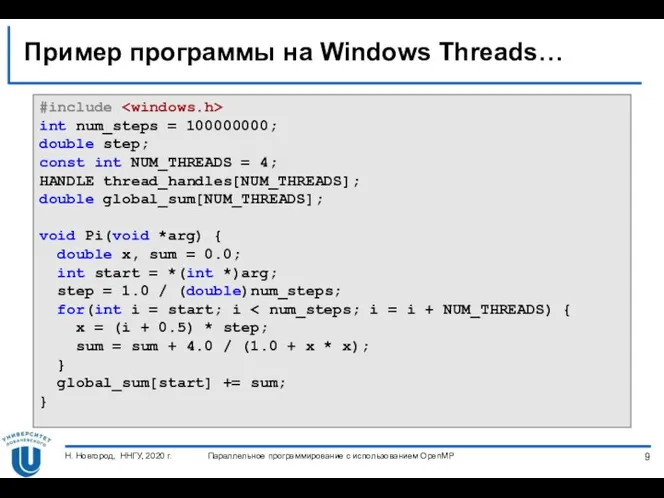
Пример программы на Windows Threads…
#include
int num_steps = 100000000;
double step;
const int NUM_THREADS = 4;
HANDLE thread_handles[NUM_THREADS];
double
Пример программы на Windows Threads…
#include
int num_steps = 100000000;
double step;
const int NUM_THREADS = 4;
HANDLE thread_handles[NUM_THREADS];
double

Пример программы на Windows Threads
int main() {
int i;
double pi = 0;
DWORD threadID;
Пример программы на Windows Threads
int main() {
int i;
double pi = 0;
DWORD threadID;

Пример программы на C++ Threads…
#include
#include
int num_steps = 100000000;
double step;
const int NUM_THREADS = 4;
double
Пример программы на C++ Threads…
#include
#include
int num_steps = 100000000;
double step;
const int NUM_THREADS = 4;
double

Пример программы на C++ Threads
int main()
{
int i;
double pi = 0;
std::thread threads[NUM_THREADS] =
Пример программы на C++ Threads
int main()
{
int i;
double pi = 0;
std::thread threads[NUM_THREADS] =
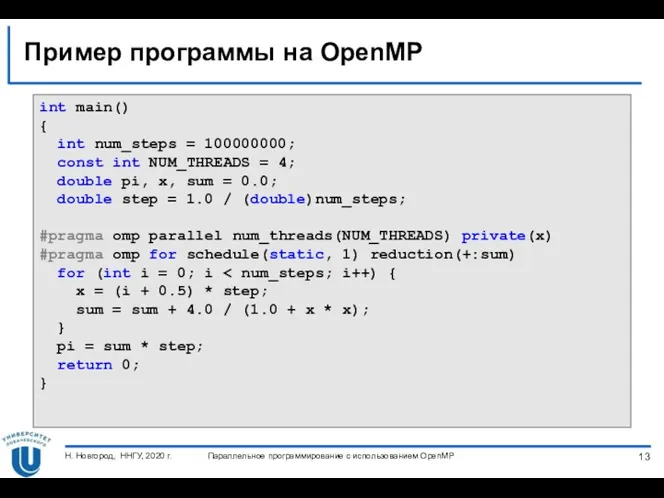
Пример программы на OpenMP
int main()
{
int num_steps = 100000000;
const int NUM_THREADS = 4;
Пример программы на OpenMP
int main()
{
int num_steps = 100000000;
const int NUM_THREADS = 4;

Структура OpenMP
Компоненты:
Набор директив компилятора.
Библиотека функций.
Набор переменных окружения.
Изложение материала будет проводиться на
Структура OpenMP
Компоненты:
Набор директив компилятора.
Библиотека функций.
Набор переменных окружения.
Изложение материала будет проводиться на
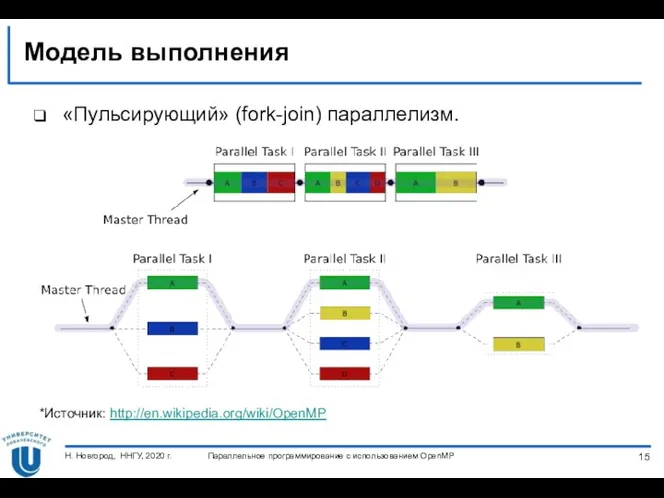
Модель выполнения
«Пульсирующий» (fork-join) параллелизм.
*Источник: http://en.wikipedia.org/wiki/OpenMP
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,
Модель выполнения
«Пульсирующий» (fork-join) параллелизм.
*Источник: http://en.wikipedia.org/wiki/OpenMP
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,

Модель памяти
Рассматривается модель стандартов до OpenMP 4.0
(до появления поддержки гетерогенного программирования)
В OpenMP-программе два типа памяти: private и shared
Принадлежность конкретной переменной одному из типов
памяти определяется:
местом объявления,
правилами умолчания,
параметрами директив.
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
Модель памяти
Рассматривается модель стандартов до OpenMP 4.0
(до появления поддержки гетерогенного программирования)
В OpenMP-программе два типа памяти: private и shared
Принадлежность конкретной переменной одному из типов
памяти определяется:
местом объявления,
правилами умолчания,
параметрами директив.
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.

СОЗДАНИЕ ПОТОКОВ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
СОЗДАНИЕ ПОТОКОВ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.

Формирование параллельной области
Формат директивы parallel :
#pragma omp parallel [clause ...]
structured_block
Возможные
Формирование параллельной области
Формат директивы parallel :
#pragma omp parallel [clause ...]
structured_block
Возможные

Формирование параллельной области
Директива parallel (основная директива OpenMP):
Когда основной поток выполнения достигает
Формирование параллельной области
Директива parallel (основная директива OpenMP):
Когда основной поток выполнения достигает

Пример использования директивы…
#include
void main() {
int nthreads;
// Создание
Пример использования директивы…
#include
void main() {
int nthreads;
// Создание
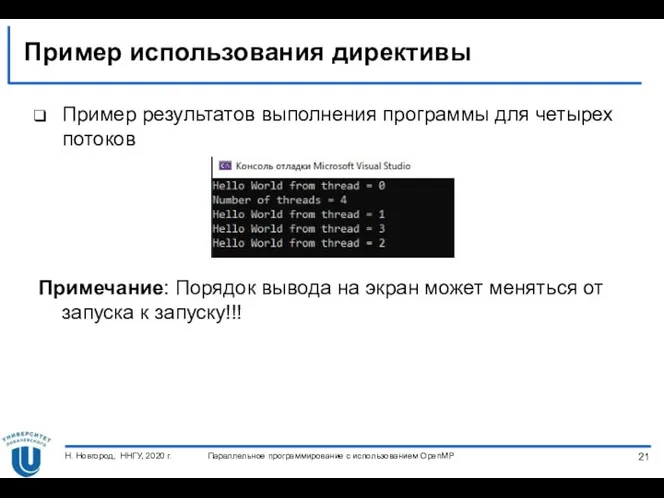
Пример использования директивы
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
Примечание:
Пример использования директивы
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
Примечание:

Установка количества потоков
Способы задания (по убыванию старшинства)
Параметр директивы:
num_threads(N)
Функция установки числа потоков:
Установка количества потоков
Способы задания (по убыванию старшинства)
Параметр директивы:
num_threads(N)
Функция установки числа потоков:

Определение времени выполнения параллельной программы
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,
Определение времени выполнения параллельной программы
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,

Управление областью видимости
Управление областью видимости обеспечивается при помощи параметров директив:
shared, default
private
firstprivate
lastprivate
Параметры
Управление областью видимости
Управление областью видимости обеспечивается при помощи параметров директив:
shared, default
private
firstprivate
lastprivate
Параметры

Параметр shared
Параметр shared определяет список переменных, которые будут общими для всех
Параметр shared
Параметр shared определяет список переменных, которые будут общими для всех

Параметр private
Параметр private определяет список переменных, которые будут локальными для каждого
Параметр private
Параметр private определяет список переменных, которые будут локальными для каждого

Пример использования директивы private
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020
Пример использования директивы private
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020

Параметр firstprivate
Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием
Параметр firstprivate
Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием

Параметр lastprivate
Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются
Параметр lastprivate
Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
БИБЛИОТЕКА ФУНКЦИЙ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
БИБЛИОТЕКА ФУНКЦИЙ

Функции управления выполнением…
Задать число потоков в параллельных областях
void omp_set_num_threads(int num_threads)
Вернуть число
Функции управления выполнением…
Задать число потоков в параллельных областях
void omp_set_num_threads(int num_threads)
Вернуть число

Функции управления выполнением…
Вернуть номер потока в параллельной области
int omp_get_thread_num(void)
Вернуть число процессоров,
Функции управления выполнением…
Вернуть номер потока в параллельной области
int omp_get_thread_num(void)
Вернуть число процессоров,

Вложенный параллелизм
Включить/выключить вложенный параллелизм
int omp_set_nested(int)
Вернуть, включен ли вложенный параллелизм
int omp_get_nested(void)
Параллельное программирование
Вложенный параллелизм
Включить/выключить вложенный параллелизм
int omp_set_nested(int)
Вернуть, включен ли вложенный параллелизм
int omp_get_nested(void)
Параллельное программирование

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
ПРИВЯЗКА ПОТОКОВ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
ПРИВЯЗКА ПОТОКОВ

Параметр proc_bind
У директивы parallel в стандарте 4.0 был добавлен параметр proc_bind,
Параметр proc_bind
У директивы parallel в стандарте 4.0 был добавлен параметр proc_bind,

Параметр proc_bind
Формат параметра proc_bind
#pragma omp parallel proc_bind(master | close | spread)
Параметр proc_bind
Формат параметра proc_bind
#pragma omp parallel proc_bind(master | close | spread)

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
СПОСОБЫ РАСПРЕДЕЛЕНИЯ РАБОТЫ МЕЖДУ ПОТОКАМИ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
СПОСОБЫ РАСПРЕДЕЛЕНИЯ РАБОТЫ МЕЖДУ ПОТОКАМИ

Директивы распределения вычислений между потоками
Существует 3 директивы для распределения вычислений в
Директивы распределения вычислений между потоками
Существует 3 директивы для распределения вычислений в
![Распараллеливание циклов Формат директивы for: #pragma omp for [clause ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/224523/slide-38.jpg)
Распараллеливание циклов
Формат директивы for:
#pragma omp for [clause ...]
for loop
Основные
Распараллеливание циклов
Формат директивы for:
#pragma omp for [clause ...]
for loop
Основные

Пример использования директивы for
#include
#define CHUNK 100
#define NMAX 1000
Пример использования директивы for
#include
#define CHUNK 100
#define NMAX 1000

Директива for. Параметр schedule
static – итерации делятся на блоки по chunk
Директива for. Параметр schedule
static – итерации делятся на блоки по chunk

Пример использования директивы for
#include
#define CHUNK 100
#define NMAX 1000
Пример использования директивы for
#include
#define CHUNK 100
#define NMAX 1000

Объединение директив parallel и for/sections
#include
#define CHUNK 100
#define NMAX
Объединение директив parallel и for/sections
#include
#define CHUNK 100
#define NMAX

Распараллеливание циклов с редукцией
Параметр reduction определяет список переменных, для которых выполняется
Распараллеливание циклов с редукцией
Параметр reduction определяет список переменных, для которых выполняется

Пример использования параметра reduction
#include
void main() {
int i, n,
Пример использования параметра reduction
#include
void main() {
int i, n,

Правила записи параметра reduction
Возможный формат записи выражения:
x = x op expr
x
Правила записи параметра reduction
Возможный формат записи выражения:
x = x op expr
x

Векторизация цикла…
Директива simd – «просьба» компилятору векторизовать нижеследующий(-ие) цикл(-ы)
Формат директивы simd
#pragma
Векторизация цикла…
Директива simd – «просьба» компилятору векторизовать нижеследующий(-ие) цикл(-ы)
Формат директивы simd
#pragma
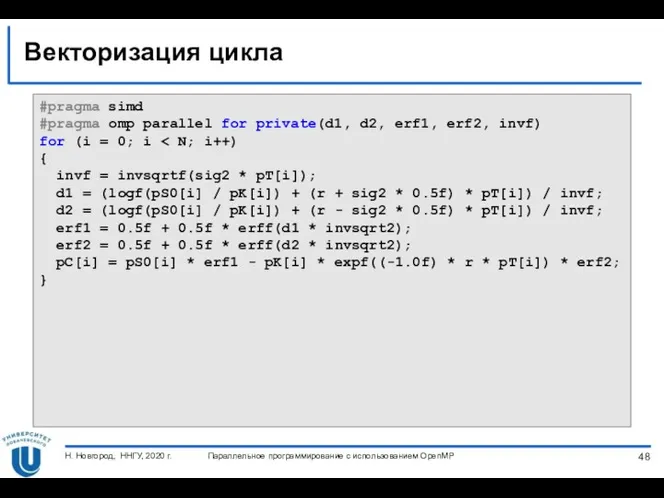
Векторизация цикла
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
#pragma simd
#pragma
Векторизация цикла
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
#pragma simd
#pragma
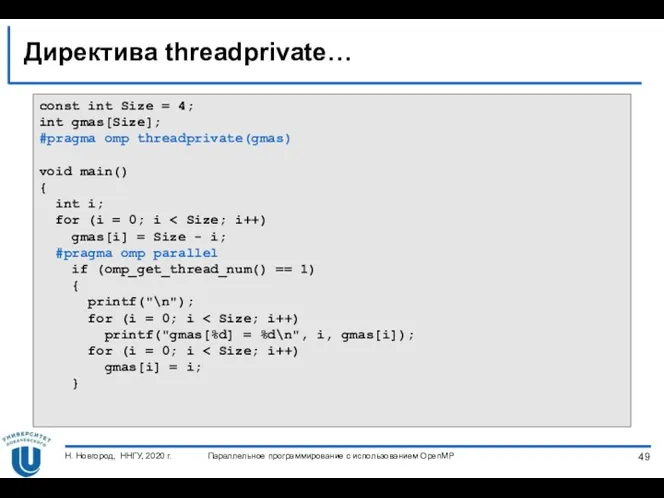
Директива threadprivate…
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
const int
Директива threadprivate…
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
const int

Директива threadprivate
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
printf("\n");
Директива threadprivate
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
printf("\n");

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
СИНХРОНИЗАЦИЯ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
СИНХРОНИЗАЦИЯ

Директива master
Директива master определяет фрагмент кода, который должен быть выполнен только
Директива master
Директива master определяет фрагмент кода, который должен быть выполнен только

Директива barrier
Директива barrier определяет точку синхронизации, которую должны достигнуть все потоки
Директива barrier
Директива barrier определяет точку синхронизации, которую должны достигнуть все потоки

Директива single
Директива single определяет фрагмент кода, который должен быть выполнен только
Директива single
Директива single определяет фрагмент кода, который должен быть выполнен только

Директива critical…
Директива critical определяет фрагмент кода, который должен выполняться только одним
Директива critical…
Директива critical определяет фрагмент кода, который должен выполняться только одним
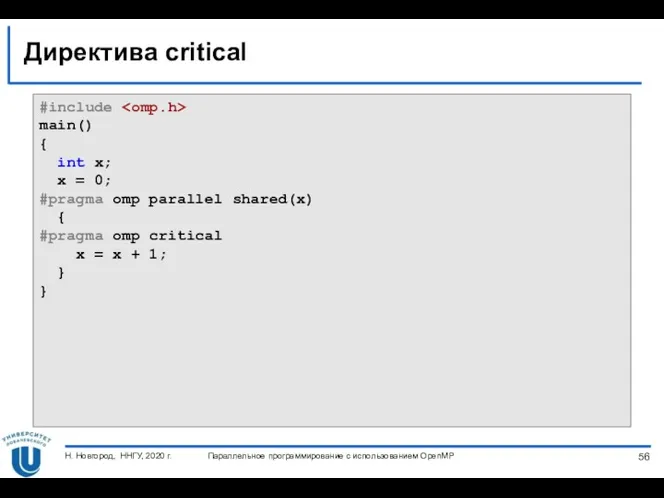
Директива critical
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
#include
Директива critical
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
#include

Директива atomic
Директива atomic определяет переменную, операция с которой (чтение/запись) должна быть
Директива atomic
Директива atomic определяет переменную, операция с которой (чтение/запись) должна быть
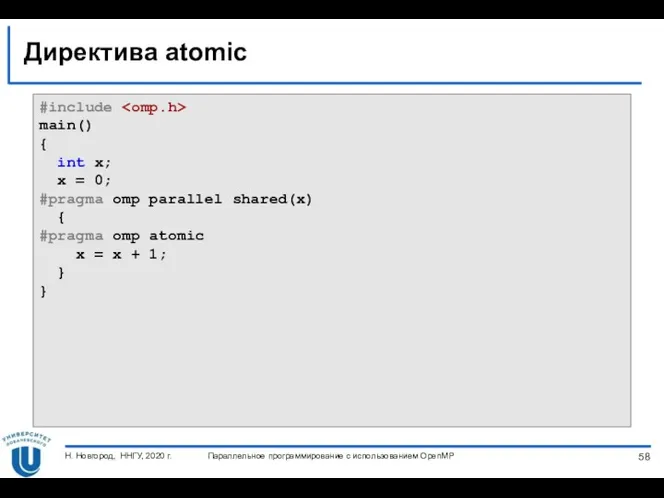
Директива atomic
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
#include
Директива atomic
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
#include

Функции управления замками…
В качестве замков используются переменные типа omp_lock_t.
Инициализировать замок
void omp_init_lock(omp_lock_t
Функции управления замками…
В качестве замков используются переменные типа omp_lock_t.
Инициализировать замок
void omp_init_lock(omp_lock_t

Функции управления замками
Захватить замок, если он свободен, иначе ждать освобождения
void omp_set_lock(omp_lock_t
Функции управления замками
Захватить замок, если он свободен, иначе ждать освобождения
void omp_set_lock(omp_lock_t

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
ПЕРЕМЕННЫЕ ОКРУЖЕНИЯ
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2020 г.
ПЕРЕМЕННЫЕ ОКРУЖЕНИЯ

Функции управления выполнением…
OMP_SCHEDULE – определяет способ распределения итераций в цикле, если
Функции управления выполнением…
OMP_SCHEDULE – определяет способ распределения итераций в цикле, если
 Масиви
Масиви Программное обеспечение компьютера. Операционная система.
Программное обеспечение компьютера. Операционная система. Ветвление и циклы в КУМИРе
Ветвление и циклы в КУМИРе Инструмент Scribble
Инструмент Scribble Информационные технологии в менеджменте (для подготовки к контрольной)
Информационные технологии в менеджменте (для подготовки к контрольной) Мир моиx увлечений: “Dota 2”
Мир моиx увлечений: “Dota 2” Основы трехмерного моделирования в Компас 3D
Основы трехмерного моделирования в Компас 3D Технология информационно-справочной работы с документами
Технология информационно-справочной работы с документами Вычислительная техника
Вычислительная техника Презентация по дисциплине: Информационные технологии на тему: Поиск информации
Презентация по дисциплине: Информационные технологии на тему: Поиск информации Разработка урока по теме Безопасный интернет
Разработка урока по теме Безопасный интернет Электронные таблицы. Обработка числовой информации в электронных таблицах
Электронные таблицы. Обработка числовой информации в электронных таблицах техника безопасности
техника безопасности Оптимальное планирование в MS Excel
Оптимальное планирование в MS Excel Инструкция по оплате курсов от онлайн-центра Sattarovfamily
Инструкция по оплате курсов от онлайн-центра Sattarovfamily Защита персональных данных. Угрозы в области технической защиты информации. Оценка рисков
Защита персональных данных. Угрозы в области технической защиты информации. Оценка рисков Информационные системы моделирования логистических бизнес-процессов. Лекция 6
Информационные системы моделирования логистических бизнес-процессов. Лекция 6 Simulation examples
Simulation examples Repeat until
Repeat until Общие понятия и классификация баз данных
Общие понятия и классификация баз данных Тематический библиографический список, как одна из форм библиографических пособий малых форм
Тематический библиографический список, как одна из форм библиографических пособий малых форм Introduction to Google Maps
Introduction to Google Maps Інформаційні технології. Історія розвитку комп’ютерів. (Лекція 1)
Інформаційні технології. Історія розвитку комп’ютерів. (Лекція 1) Использование операций целочисленной арифметики в задачах ЕГЭ по информатике
Использование операций целочисленной арифметики в задачах ЕГЭ по информатике Коллектив разработчиков. Лидер
Коллектив разработчиков. Лидер Администрирование Windows Server 2012 R2. Безопасность
Администрирование Windows Server 2012 R2. Безопасность Normalisation. Describe relational databases and their use
Normalisation. Describe relational databases and their use SAP CRM Система Управление взаимоотношениями с клиентами
SAP CRM Система Управление взаимоотношениями с клиентами