- Нейронные сети

Содержание
- 4. Глубокое обучение особый раздел машинного обучения: делает упор на анализ последовательных слоев (или уровней) все более
- 5. Представления, полученные алгоритмом глубокого обучения
- 6. Задачи, решаемые глубокими нейронными сетями классификация изображений на уровне человека; распознавание речи на уровне человека; распознавание
- 7. Методика глубокого обучения имеет две важные характеристики: Поэтапно, послойно конструирует все более сложные представления. Исследует промежуточные
- 8. Нейрон человека
- 9. Модель искусственного нейрона
- 10. Функция активации – функция, которая принимает на вход результат сумматора и выполняет некое преобразование, чтобы превратить
- 11. Функции активации Функция единичного скачка (она же функция Хэвисайда) где х – взвешенная сумма входных параметров.
- 12. Функции активации где θ – заданный порог, S – взвешенная сумма входных параметров.
- 13. Функции активации Сигмоидальная функция (она же логистическая функция) где х – взвешенная сумма входных параметров.
- 14. Функции активации ReLU (rectified linear units) Преимущества является хорошим аппроксиматором – подходит для любой функции. создает
- 15. Классификация нейронных сетей По типу распространения сигнала нейронные сети можно разделить на: нейронные сети с прямым
- 16. Классификация нейронных сетей Сети с прямым распространением сигнала решают множество задач классификации и регрессии на табличных
- 17. Классификация нейронных сетей Необходимость в рекуррентных нейронных сетях возникает при решении таких задач, когда требуется владеть
- 18. Классификация нейронных сетей Однослойной считается нейронная сеть, имеющая лишь входной и выходной слой, без наличия скрытых
- 19. Обучение нейронной сети Сила нейронных сетей в обучении весов связей между нейронами. В ходе множества итераций
- 20. Обучение с учителем
- 21. Обучение без учителя кластеризация – задача разбиения выборки на N (число кластеров может задаваться заранее, а
- 22. Обучение с подкреплением модель не имеет информации о системе, но при этом может производить некие действия,
- 23. Другие подходы к обучению полное обучение (пакетный метод) – подход, при котором все обучающие данные подаются
- 24. Библиотеки для обучения нейронной сети TensorFlow Базовый язык С++, но имеет API для Python. Разработан Google.
- 25. Библиотеки для обучения нейронной сети CNTK Базовый язык С++. Поддерживает API для С++, С#, Python, Java.
- 26. Распознавание предметов одежды Полносвязная нейронная сеть прямого распространения – Fully Connected Feed-Forward Neural Networks, FNN Как
- 27. Распознавание предметов одежды Недостатки: У данной архитектуры слишком быстро с ростом числа входных данных растет число
- 28. Анализ набора данных с точки зрения дальнейшего построения нейронной сети Изображения 100х100 пикселей, значения 0-255, RGB
- 29. Базовые объекты и параметры объектов глубоких нейронных сетей в TensorFlow tensorflow.keras.models.Sequential – это базовая модель нейронной
- 31. Базовые объекты и параметры объектов глубоких нейронных сетей в TensorFlow
- 32. Нейронные сети для анализа изображений Полносвязная нейронная сеть Каждый нейрон входного слоя связан с каждым пикселем
- 33. Сверточные нейронные сети
- 34. Сверточные нейронные сети
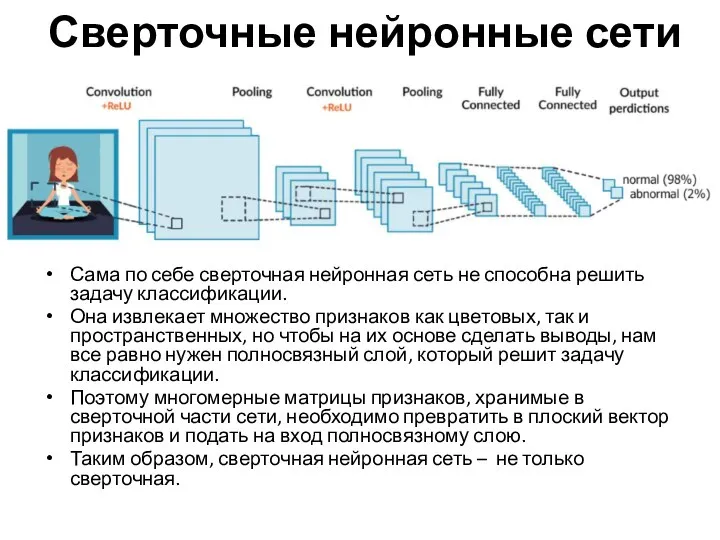
- 35. Сверточные нейронные сети Сама по себе сверточная нейронная сеть не способна решить задачу классификации. Она извлекает
- 36. Сверточные нейронные сети
- 37. Сверточная нейронная сеть Каждый нейрон входного слоя связан лишь с пикселями, попадающими в его диапазон (9,
- 38. Обработка естественного языка Предварительная обработка текста, необходимо: привести текст к единому регистру; в зависимости от задачи
- 39. Архитектуры нейронных сетей языка сверточные одномерные нейронные сети (CNN 1D), работающие по принципу двумерных сверточных сетей,
- 40. Архитектуры нейронных сетей языка Модели векторных представлений слов и документов можно разделить на три блока: частотный
- 41. Частотный подход Основан на подходе Bag of words («мешок слов»): Находим все уникальные слова в тексте.
- 42. Частотный подход Нейронная сеть должна получать на вход последовательности одной длины. Подходы для решения: One Hot
- 43. Частотный подход OHE представляет из себя разреженный вектор, в котором стоят 0 на позициях тех слов
- 44. Тематическое моделирование Семантическое моделирование текстов. делим тексты на разные кластеры, но «мягко». каждое слово может определять
- 45. Тематическое моделирование К данной группе методов относятся: вероятностный латентно семантический анализ (PLSA, Probabilistic latent semantic analysis).
- 47. DALL-E 2 (2022) • Генерировать изображения по текстовому описанию на английском языке; • «Дорисовать» картину, расширив
- 48. Imaginary soundscape (2018) https://imaginarysoundscape.net/ Озвучивать случайное место на земле на Google Map; Озвучивать изображения.
- 49. Autodraw https://www.autodraw.com/ Как пользоваться: интерфейс сервиса напоминает упрощенный Paint. Из кнопок есть кисть, автокисть, текст, заполнение,
- 50. Kandinsky 2.1 https://editor.fusionbrain.ai/ Kandinsky 2.1 – новейшая разработка от Сбера, способная генерировать уникальные изображения на основе
- 51. TurboText https://turbotext.pro/ Нейросеть TurboText тоже помогает в работе с текстами. Она может написать любую статью, содержательные
- 52. Sketch Metademolab https://sketch.metademolab.com/ сервис, который позволяет оживлять детские рисунки. Находится в бесплатном онлайн-доступе для всех желающих.
- 54. Скачать презентацию
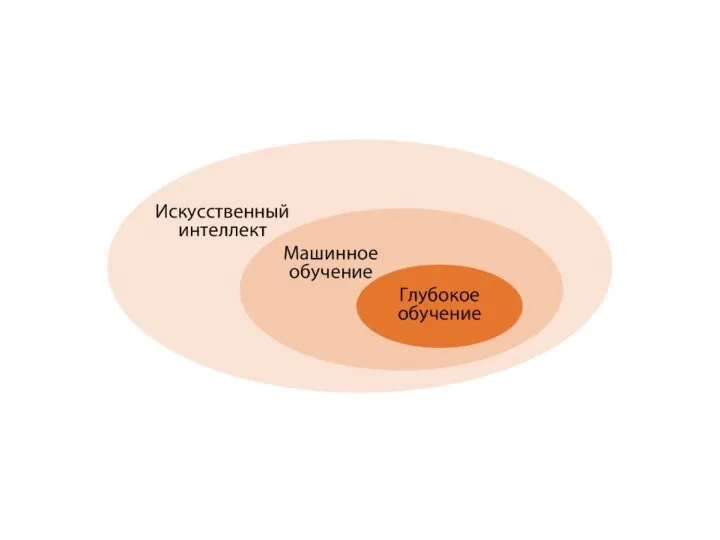
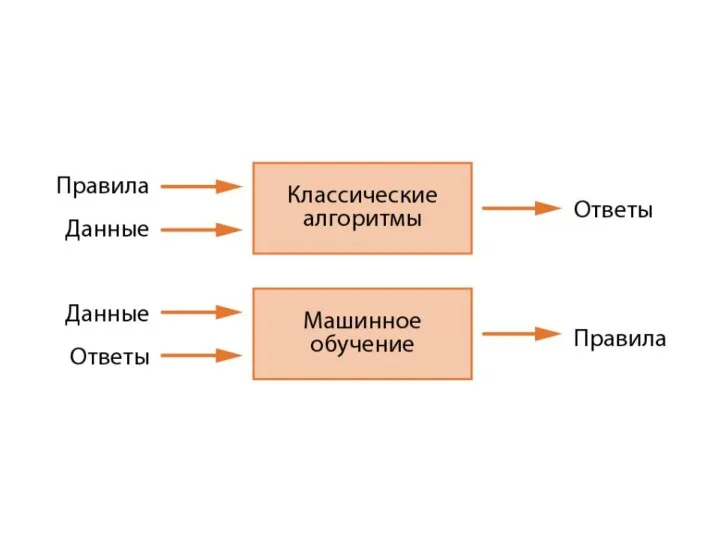

Глубокое обучение
особый раздел машинного обучения: делает упор на анализ последовательных слоев
Глубокое обучение
особый раздел машинного обучения: делает упор на анализ последовательных слоев
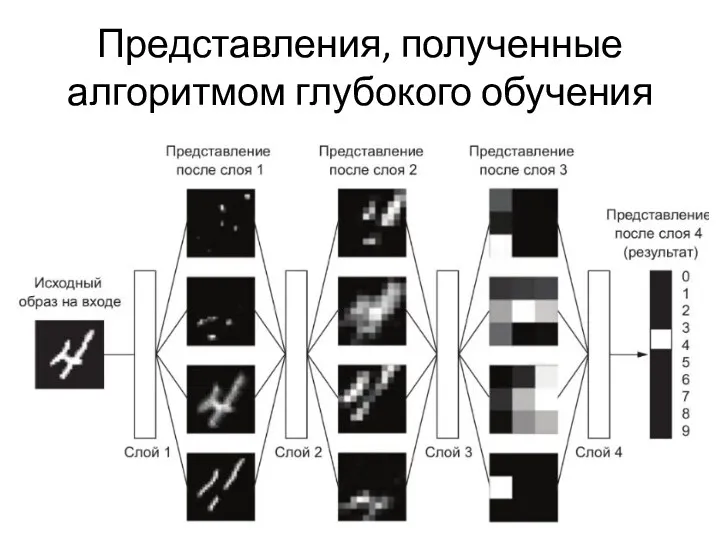
Представления, полученные алгоритмом глубокого обучения
Представления, полученные алгоритмом глубокого обучения

Задачи, решаемые глубокими нейронными сетями
классификация изображений на уровне человека;
распознавание речи на
Задачи, решаемые глубокими нейронными сетями
классификация изображений на уровне человека;
распознавание речи на

Методика глубокого обучения
имеет две важные характеристики:
Поэтапно, послойно конструирует все более
Методика глубокого обучения
имеет две важные характеристики:
Поэтапно, послойно конструирует все более
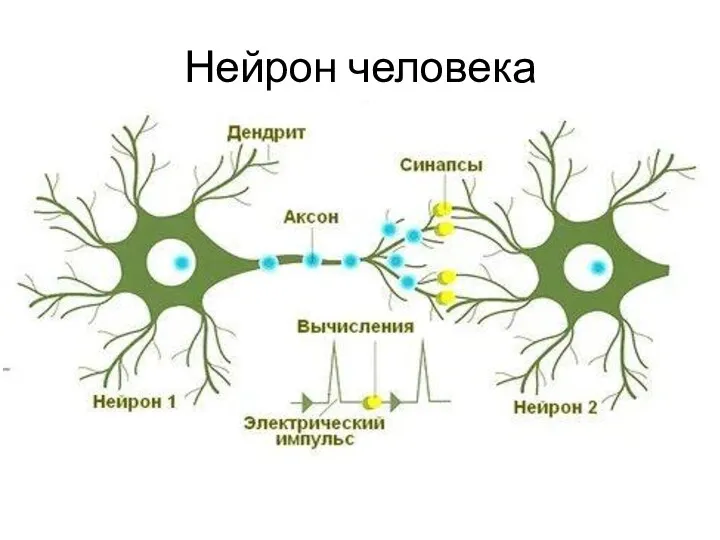
Нейрон человека
Нейрон человека
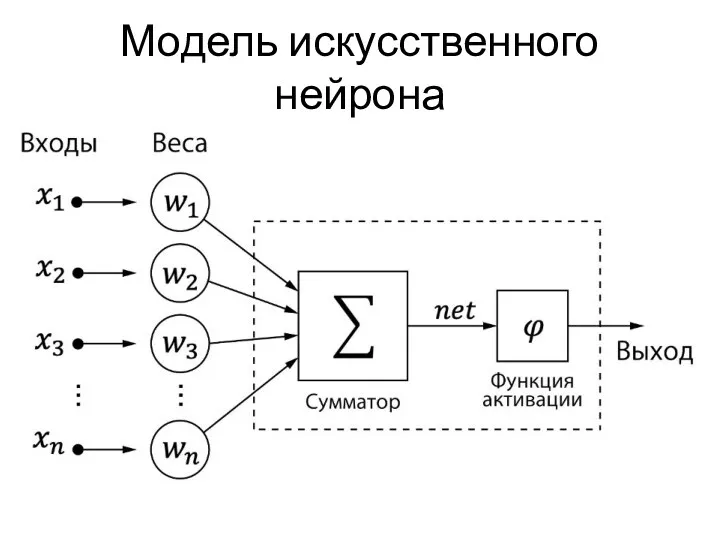
Модель искусственного нейрона
Модель искусственного нейрона

Функция активации – функция, которая принимает на вход результат сумматора и выполняет некое
Функция активации – функция, которая принимает на вход результат сумматора и выполняет некое

Функции активации
Функция единичного скачка (она же функция Хэвисайда)
где х – взвешенная сумма входных
Функции активации
Функция единичного скачка (она же функция Хэвисайда)
где х – взвешенная сумма входных

Функции активации
где θ – заданный порог, S – взвешенная сумма входных параметров.
Функции активации
где θ – заданный порог, S – взвешенная сумма входных параметров.
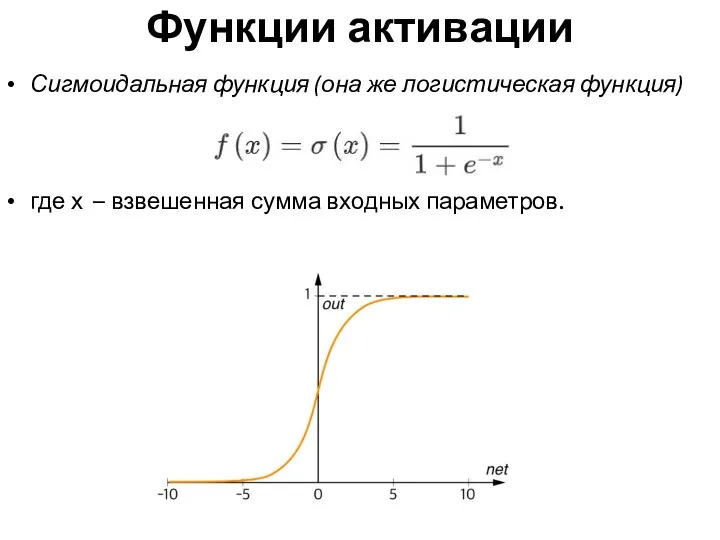
Функции активации
Сигмоидальная функция (она же логистическая функция)
где х – взвешенная сумма входных
Функции активации
Сигмоидальная функция (она же логистическая функция)
где х – взвешенная сумма входных

Функции активации
ReLU (rectified linear units)
Преимущества
является хорошим аппроксиматором – подходит для
Функции активации
ReLU (rectified linear units)
Преимущества
является хорошим аппроксиматором – подходит для

Классификация нейронных сетей
По типу распространения сигнала нейронные сети можно разделить на:
нейронные
Классификация нейронных сетей
По типу распространения сигнала нейронные сети можно разделить на:
нейронные
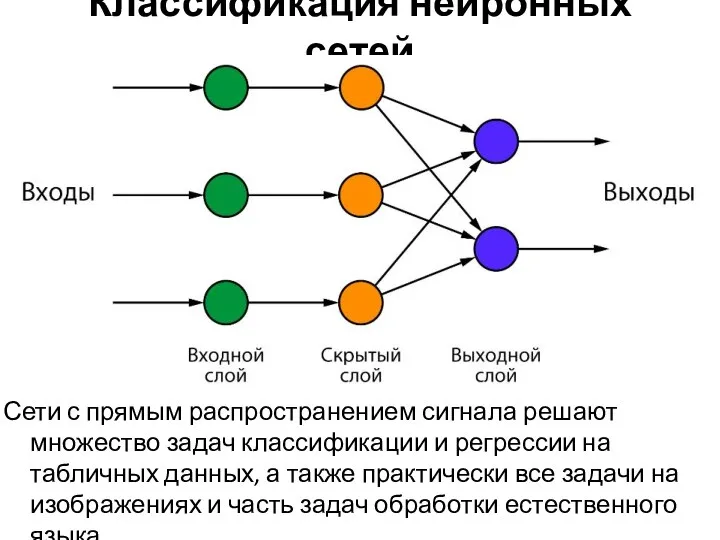
Классификация нейронных сетей
Сети с прямым распространением сигнала решают множество задач классификации
Классификация нейронных сетей
Сети с прямым распространением сигнала решают множество задач классификации
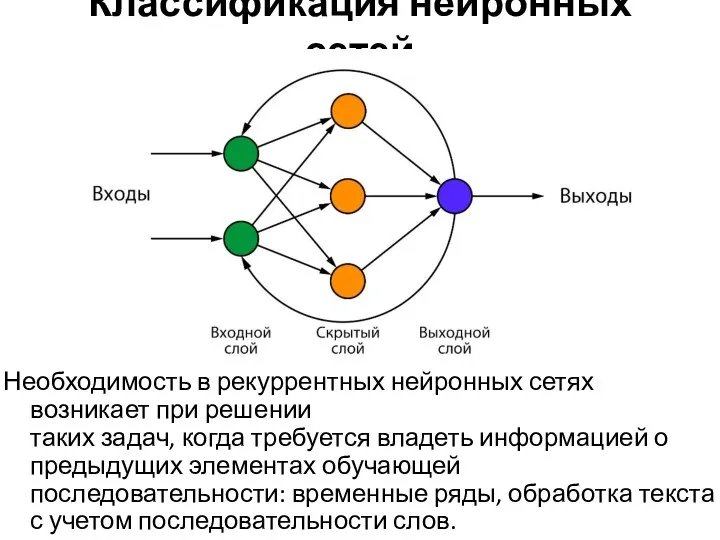
Классификация нейронных сетей
Необходимость в рекуррентных нейронных сетях возникает при решении таких задач, когда требуется владеть
Классификация нейронных сетей
Необходимость в рекуррентных нейронных сетях возникает при решении таких задач, когда требуется владеть

Классификация нейронных сетей
Однослойной считается нейронная сеть, имеющая лишь входной и выходной
Классификация нейронных сетей
Однослойной считается нейронная сеть, имеющая лишь входной и выходной

Обучение нейронной сети
Сила нейронных сетей в обучении весов связей между нейронами.
Обучение нейронной сети
Сила нейронных сетей в обучении весов связей между нейронами.
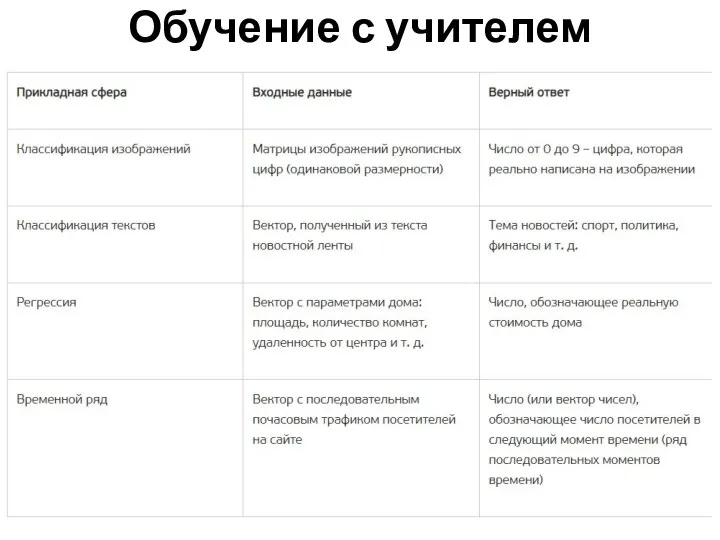
Обучение с учителем
Обучение с учителем

Обучение без учителя
кластеризация – задача разбиения выборки на N (число кластеров может задаваться
Обучение без учителя
кластеризация – задача разбиения выборки на N (число кластеров может задаваться

Обучение с подкреплением
модель не имеет информации о системе, но при этом
Обучение с подкреплением
модель не имеет информации о системе, но при этом

Другие подходы к обучению
полное обучение (пакетный метод) – подход, при котором
Другие подходы к обучению
полное обучение (пакетный метод) – подход, при котором

Библиотеки для обучения нейронной сети
TensorFlow
Базовый язык С++, но имеет API
Библиотеки для обучения нейронной сети
TensorFlow
Базовый язык С++, но имеет API

Библиотеки для обучения нейронной сети
CNTK
Базовый язык С++. Поддерживает API для С++,
Библиотеки для обучения нейронной сети
CNTK
Базовый язык С++. Поддерживает API для С++,
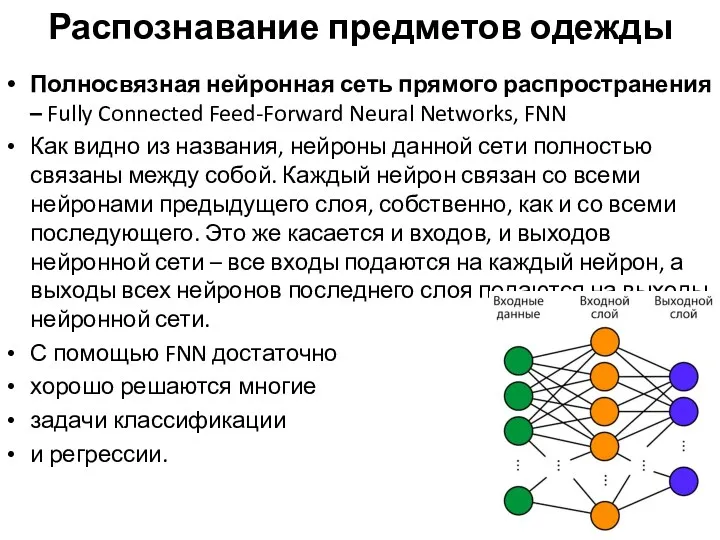
Распознавание предметов одежды
Полносвязная нейронная сеть прямого распространения – Fully Connected Feed-Forward
Распознавание предметов одежды
Полносвязная нейронная сеть прямого распространения – Fully Connected Feed-Forward

Распознавание предметов одежды
Недостатки:
У данной архитектуры слишком быстро с ростом числа входных
Распознавание предметов одежды
Недостатки:
У данной архитектуры слишком быстро с ростом числа входных

Анализ набора данных с точки зрения дальнейшего построения нейронной сети
Изображения 100х100
Анализ набора данных с точки зрения дальнейшего построения нейронной сети
Изображения 100х100

Базовые объекты и параметры объектов глубоких нейронных сетей в TensorFlow
tensorflow.keras.models.Sequential – это
Базовые объекты и параметры объектов глубоких нейронных сетей в TensorFlow
tensorflow.keras.models.Sequential – это


Базовые объекты и параметры объектов глубоких нейронных сетей в TensorFlow
Базовые объекты и параметры объектов глубоких нейронных сетей в TensorFlow

Нейронные сети для анализа изображений
Полносвязная нейронная сеть
Каждый нейрон входного слоя связан
Нейронные сети для анализа изображений
Полносвязная нейронная сеть
Каждый нейрон входного слоя связан
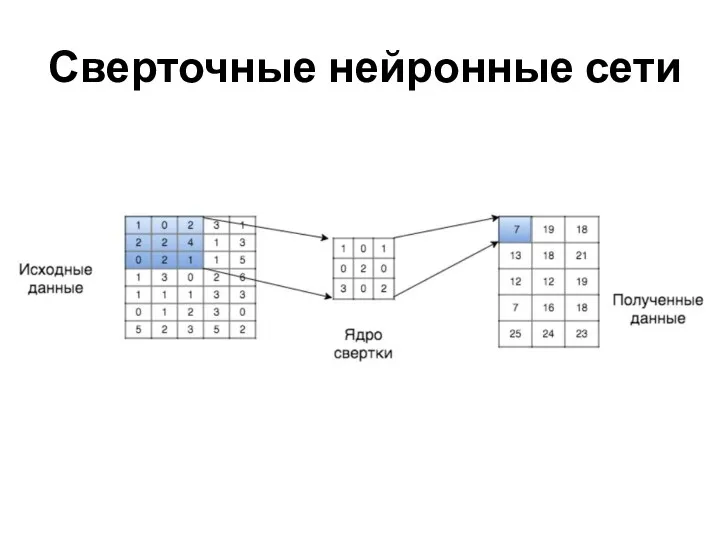
Сверточные нейронные сети
Сверточные нейронные сети
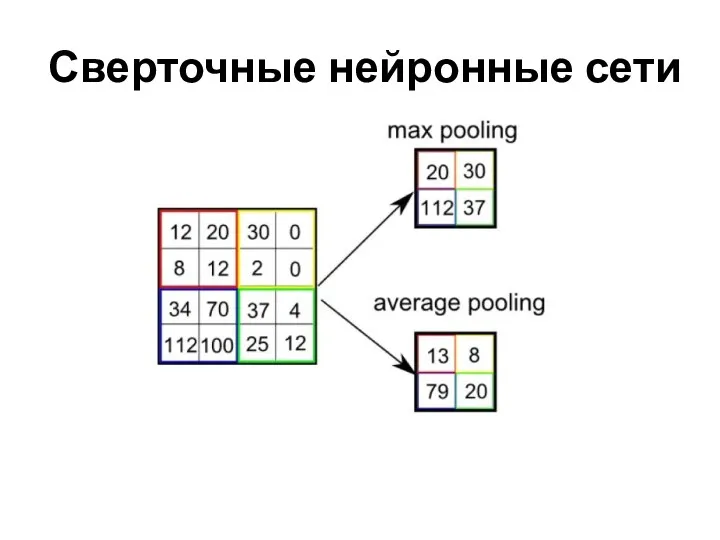
Сверточные нейронные сети
Сверточные нейронные сети
Сверточные нейронные сети
Сама по себе сверточная нейронная сеть не способна решить
Сверточные нейронные сети
Сама по себе сверточная нейронная сеть не способна решить

Сверточные нейронные сети
Сверточные нейронные сети

Сверточная нейронная сеть
Каждый нейрон входного слоя связан лишь с пикселями, попадающими
Сверточная нейронная сеть
Каждый нейрон входного слоя связан лишь с пикселями, попадающими

Обработка естественного языка
Предварительная обработка текста, необходимо:
привести текст к единому регистру;
в зависимости
Обработка естественного языка
Предварительная обработка текста, необходимо:
привести текст к единому регистру;
в зависимости

Архитектуры нейронных сетей языка
сверточные одномерные нейронные сети (CNN 1D), работающие по принципу
Архитектуры нейронных сетей языка
сверточные одномерные нейронные сети (CNN 1D), работающие по принципу

Архитектуры нейронных сетей языка
Модели векторных представлений слов и документов можно разделить
Архитектуры нейронных сетей языка
Модели векторных представлений слов и документов можно разделить

Частотный подход
Основан на подходе Bag of words («мешок слов»):
Находим все уникальные слова в
Частотный подход
Основан на подходе Bag of words («мешок слов»):
Находим все уникальные слова в

Частотный подход
Нейронная сеть должна получать на вход последовательности одной длины.
Подходы
Частотный подход
Нейронная сеть должна получать на вход последовательности одной длины.
Подходы

Частотный подход
OHE представляет из себя разреженный вектор, в котором стоят 0 на
Частотный подход
OHE представляет из себя разреженный вектор, в котором стоят 0 на

Тематическое моделирование
Семантическое моделирование текстов.
делим тексты на разные кластеры, но «мягко».
Тематическое моделирование
Семантическое моделирование текстов.
делим тексты на разные кластеры, но «мягко».

Тематическое моделирование
К данной группе методов относятся:
вероятностный латентно семантический анализ (PLSA, Probabilistic
Тематическое моделирование
К данной группе методов относятся:
вероятностный латентно семантический анализ (PLSA, Probabilistic


DALL-E 2 (2022)
• Генерировать изображения по текстовому описанию на английском языке;
• «Дорисовать» картину,
DALL-E 2 (2022)
• Генерировать изображения по текстовому описанию на английском языке;
• «Дорисовать» картину,

Imaginary soundscape (2018)
https://imaginarysoundscape.net/
Озвучивать случайное место на земле на Google Map;
Озвучивать изображения.
Imaginary soundscape (2018)
https://imaginarysoundscape.net/
Озвучивать случайное место на земле на Google Map;
Озвучивать изображения.
Autodraw
https://www.autodraw.com/
Как пользоваться: интерфейс сервиса напоминает упрощенный Paint. Из кнопок есть кисть,
Autodraw
https://www.autodraw.com/
Как пользоваться: интерфейс сервиса напоминает упрощенный Paint. Из кнопок есть кисть,

Kandinsky 2.1
https://editor.fusionbrain.ai/
Kandinsky 2.1 – новейшая разработка от Сбера, способная генерировать уникальные
Kandinsky 2.1
https://editor.fusionbrain.ai/
Kandinsky 2.1 – новейшая разработка от Сбера, способная генерировать уникальные

TurboText
https://turbotext.pro/
Нейросеть TurboText тоже помогает в работе с текстами. Она может написать
TurboText
https://turbotext.pro/
Нейросеть TurboText тоже помогает в работе с текстами. Она может написать

Sketch Metademolab
https://sketch.metademolab.com/
сервис, который позволяет оживлять детские рисунки.
Находится в бесплатном
Sketch Metademolab
https://sketch.metademolab.com/
сервис, который позволяет оживлять детские рисунки.
Находится в бесплатном
 Компьютерные вирусы. Типы, виды, пути заражения
Компьютерные вирусы. Типы, виды, пути заражения Основные правила безопасности интернета
Основные правила безопасности интернета Информатика пә ніне тақырыбында: модем
Информатика пә ніне тақырыбында: модем Триггеры в презентации. Применение. Создание слайдов с триггерами
Триггеры в презентации. Применение. Создание слайдов с триггерами Управление отношениями с клиентами. Исследование информационных технологий
Управление отношениями с клиентами. Исследование информационных технологий A binary Hopfield neural network
A binary Hopfield neural network Принципы организации VPN
Принципы организации VPN Cover title
Cover title Построение базы данных
Построение базы данных Списки. Односпрямований (однозв'язний) список. Друк (перегляд) однозв’язного списку
Списки. Односпрямований (однозв'язний) список. Друк (перегляд) однозв’язного списку Средства массовой информации (СМИ) и их роль в современном обществе
Средства массовой информации (СМИ) и их роль в современном обществе Апаратне забезпечення інформаційних систем. Історія розвитку обчислювальної техніки. (Урок 4)
Апаратне забезпечення інформаційних систем. Історія розвитку обчислювальної техніки. (Урок 4) Задача 20.1
Задача 20.1 Онлайн конференции, анкетирование, дистанционные курсы, интернет-олимпиады, компьютерное тестирование
Онлайн конференции, анкетирование, дистанционные курсы, интернет-олимпиады, компьютерное тестирование Программирование на языке ассемблер. Система команд процессора
Программирование на языке ассемблер. Система команд процессора Системы счисления. Методы перевода чисел из одной системы в другую
Системы счисления. Методы перевода чисел из одной системы в другую Маршрутизация. Вставка
Маршрутизация. Вставка Социальные сети
Социальные сети Android 6 Расширенная интерактивность
Android 6 Расширенная интерактивность Как работать в системе АИС Путевка
Как работать в системе АИС Путевка Государственая система научно-технической информации. (Лекция 2)
Государственая система научно-технической информации. (Лекция 2) Компания IT-Center
Компания IT-Center Инструкция по поиску информации в базе данных Springer
Инструкция по поиску информации в базе данных Springer Язык программирования Pascal
Язык программирования Pascal Сетевые атаки
Сетевые атаки Профилактика интернет-рисков и угроз жизни детей и подростков
Профилактика интернет-рисков и угроз жизни детей и подростков Бұлттық технологиялар
Бұлттық технологиялар Программирование на языке Python
Программирование на языке Python