- Обработка текстовой информации

Содержание
- 2. Введение Обработка текстовой информации – это процесс анализа и преобразования текстовых данных с целью извлечения полезной
- 3. Методы обработки Существует несколько основных методов: токенизация лемматизация стемминг удаление стоп-слов векторизация классификация текста
- 4. Прямой (наивный) поиск: Последовательное сравнение каждой подстроки с шаблоном Поиск строки формально определяется следующим образом. Пусть
- 5. Идея алгоритма: 1. i=1 2. сравнить i-й символ массива T с первым символом массива W 3.
- 6. Условие окончания алгоритма: 1. M подряд сравнений удачны; 2. Cлово не найдено. Недостатки алгоритма: 1. Высокая
- 7. Алгоритм Кнута-Морриса-Пратта (КМП): Префикс-функция для ускорения поиска Улучшенный наивный поиск. Идея КМП-поиска – при каждом несовпадении
- 8. После частичного совпадения начальной части образа W с соответствующими символами строки Т мы фактически знаем пройденную
- 9. Особенности КМП-поиска: Схема КМП-поиска дает подлинный выигрыш только тогда, когда неудаче предшествовало некоторое число совпадений. Лишь
- 10. Алгоритм Бойера-Мура Базируется на идее пропуска части текста, если найдено несоответствие Сравнение символов начинается с конца
- 11. Этот метод не только улучшает обработку самого плохого случая, но и даёт выигрыш в промежуточных ситуациях.
- 12. Токенизация: Процесс разделения текста на слова или другие единицы (токены) Алгоритм токенизации на основе подслов не
- 13. BPE (Кодирование пар байтов) Это простая форма алгоритма сжатия данных, в котором наиболее распространенная пара последовательных
- 14. Предположим, у нас есть данные aaabdaaabac, которые необходимо закодировать (сжать). Чаще всего встречается пара байтов aa,
- 15. Стемминг: Процесс усечения слова до его основы Каждое слово может быть представлено в виде последовательности согласных
- 16. Для удаления распространенных суффиксов применяется более 50 правил, сгруппированных в 5 шагов и несколько подэтапов. Все
- 17. grep: Инструмент командной строки для поиска строк в тексте grep — это швейцарский нож фильтрации строк
- 18. Рассмотрим некоторые опции grep: grep -v выполняет инвертное сопоставление: фильтрует строки, которые не соответствуют шаблону аргументов.
- 19. awk и sed: Инструменты обработки текста в Unix/Linux awk — это чуть больше, чем просто инструмент
- 20. Регулярные выражения: Паттерны для поиска и замены текста. Регулярные выражения — это механизм для поиска и
- 22. Скачать презентацию

Введение
Обработка текстовой информации – это процесс анализа и преобразования текстовых данных
Введение
Обработка текстовой информации – это процесс анализа и преобразования текстовых данных

Методы обработки
Существует несколько основных методов:
токенизация
лемматизация
стемминг
удаление стоп-слов
векторизация
классификация текста
Методы обработки
Существует несколько основных методов:
токенизация
лемматизация
стемминг
удаление стоп-слов
векторизация
классификация текста

Прямой (наивный) поиск:
Последовательное сравнение каждой подстроки с шаблоном
Поиск строки формально
Прямой (наивный) поиск:
Последовательное сравнение каждой подстроки с шаблоном
Поиск строки формально

Идея алгоритма:
1. i=1
2. сравнить i-й символ массива T с первым символом
Идея алгоритма:
1. i=1
2. сравнить i-й символ массива T с первым символом

Условие окончания алгоритма:
1. M подряд сравнений удачны;
2. Cлово не найдено.
Недостатки алгоритма:
1.
Условие окончания алгоритма:
1. M подряд сравнений удачны;
2. Cлово не найдено.
Недостатки алгоритма:
1.

Алгоритм Кнута-Морриса-Пратта (КМП): Префикс-функция для ускорения поиска
Улучшенный наивный поиск.
Идея КМП-поиска –
Алгоритм Кнута-Морриса-Пратта (КМП): Префикс-функция для ускорения поиска
Улучшенный наивный поиск.
Идея КМП-поиска –

После частичного совпадения начальной части образа W с соответствующими символами строки
После частичного совпадения начальной части образа W с соответствующими символами строки

Особенности КМП-поиска:
Схема КМП-поиска дает подлинный выигрыш только тогда, когда неудаче предшествовало
Особенности КМП-поиска:
Схема КМП-поиска дает подлинный выигрыш только тогда, когда неудаче предшествовало

Алгоритм Бойера-Мура
Базируется на идее пропуска части текста, если найдено несоответствие
Сравнение символов
Алгоритм Бойера-Мура
Базируется на идее пропуска части текста, если найдено несоответствие
Сравнение символов
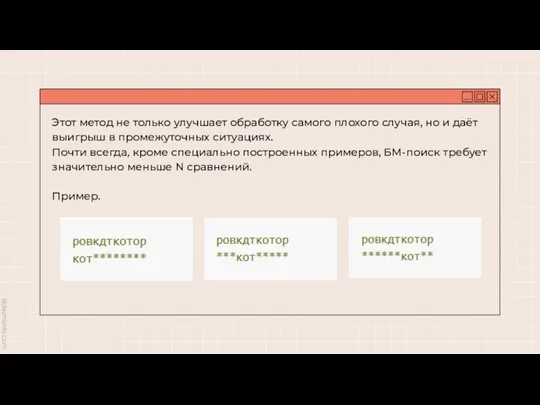
Этот метод не только улучшает обработку самого плохого случая, но и
Этот метод не только улучшает обработку самого плохого случая, но и

Токенизация: Процесс разделения текста на слова или другие единицы (токены)
Алгоритм токенизации
Токенизация: Процесс разделения текста на слова или другие единицы (токены)
Алгоритм токенизации

BPE (Кодирование пар байтов)
Это простая форма алгоритма сжатия данных, в котором
BPE (Кодирование пар байтов)
Это простая форма алгоритма сжатия данных, в котором

Предположим, у нас есть данные aaabdaaabac, которые необходимо закодировать (сжать).
Чаще
Предположим, у нас есть данные aaabdaaabac, которые необходимо закодировать (сжать).
Чаще

Стемминг: Процесс усечения слова до его основы
Каждое слово может быть представлено
Стемминг: Процесс усечения слова до его основы
Каждое слово может быть представлено

Для удаления распространенных суффиксов применяется более 50 правил, сгруппированных в 5
Для удаления распространенных суффиксов применяется более 50 правил, сгруппированных в 5

grep: Инструмент командной строки для поиска строк в тексте
grep — это
grep: Инструмент командной строки для поиска строк в тексте
grep — это

Рассмотрим некоторые опции grep:
grep -v выполняет инвертное сопоставление: фильтрует строки, которые
Рассмотрим некоторые опции grep:
grep -v выполняет инвертное сопоставление: фильтрует строки, которые

awk и sed: Инструменты обработки текста в Unix/Linux
awk — это чуть
awk и sed: Инструменты обработки текста в Unix/Linux
awk — это чуть

Регулярные выражения: Паттерны для поиска и замены текста.
Регулярные выражения — это
Регулярные выражения: Паттерны для поиска и замены текста.
Регулярные выражения — это
 Игровая среда программирования Scratch
Игровая среда программирования Scratch Независимый сервис поиска, заказа и покупки лекарств
Независимый сервис поиска, заказа и покупки лекарств Модели процесса создания программного обеспечения. Лекция 4
Модели процесса создания программного обеспечения. Лекция 4 Информационные ресурсы интернета
Информационные ресурсы интернета Создание единого информационно-образовательного пространства
Создание единого информационно-образовательного пространства Подбор оптимального метода машинного обучения для выявления банковских угроз
Подбор оптимального метода машинного обучения для выявления банковских угроз О создании государственной интегрированной информационной системы управления общественными финансами Электронный бюджет
О создании государственной интегрированной информационной системы управления общественными финансами Электронный бюджет Интернет желісінің ұйымдастыру қағидаттары (принциптері) пайдалану
Интернет желісінің ұйымдастыру қағидаттары (принциптері) пайдалану Лига безопасного интернета и Кибердружина
Лига безопасного интернета и Кибердружина Основы информатики и компьютерный практикум
Основы информатики и компьютерный практикум Розробка web-застосунку для створення односторінкових сайтів
Розробка web-застосунку для створення односторінкових сайтів История развития вычислительной техники
История развития вычислительной техники Формат ввода. Формат вывода. Самостоятельная подготовка
Формат ввода. Формат вывода. Самостоятельная подготовка Лінійні алгоритми. 5 клас. Урок 20
Лінійні алгоритми. 5 клас. Урок 20 Логическое программирование и язык Пролог
Логическое программирование и язык Пролог Beginners guide, для продавцов - консультантов
Beginners guide, для продавцов - консультантов JavaScript. Lesson 6
JavaScript. Lesson 6 Архитектура ИС
Архитектура ИС Линейный вычислительный процесс
Линейный вычислительный процесс Что может SMM и что можем мы. Инстаграм и Вконтакте
Что может SMM и что можем мы. Инстаграм и Вконтакте Object oriented programming. (Lesson 6, part 2)
Object oriented programming. (Lesson 6, part 2) Информационные технологии в профессиональной деятельности
Информационные технологии в профессиональной деятельности Система контроля электропитания Центра
Система контроля электропитания Центра Проблемы изучения информационных технологий в общеобразовательной и профессиональной школе
Проблемы изучения информационных технологий в общеобразовательной и профессиональной школе Работа в информационных системах
Работа в информационных системах Относительные, абсолютные и смешанные ссылки. 9 класс
Относительные, абсолютные и смешанные ссылки. 9 класс Русско-болгарские словари. Болгарский словарь сообщества LingvoKit
Русско-болгарские словари. Болгарский словарь сообщества LingvoKit Автоматизация кофейни
Автоматизация кофейни