- Подбор оптимального метода машинного обучения для выявления банковских угроз

Содержание
- 2. Введение В настоящее время на теневых форумах происходит активная купля/продажа дебетовых карт Одна из распространенных схем
- 3. Постановка задачи Исходные данные Выборка постов теневых форумов тематики “Торговля пластиковыми картами”, сформированная на основе парсинга
- 4. Схема выявления постов по угрозе БД - хранение сырых данных теневых форумов Парсинг контента теневых форумов
- 5. Исходные данные
- 6. Разметка данных Разметка данных требует привлечения асессоров. Асессор - человек, знающий предметную область угроз, способный, читая
- 7. Предобработка данных Удаление английских символов Удаление символов разметки Удаление цифр и остальных символов, не являющихся русскими
- 8. Обработка данных Реализация классификатора включает реализацию компонентов: Индексатор текстов Токенизация текстов Нормализация слов Стемминг Лемматизация Взвешивание
- 9. Обучение классификатора Выбранные модели Логистическая регрессия Метод опорных векторов Наивный Байесовский классификатор Метод ближайших соседей Разделение
- 10. Оценка результатов обучения Accuracy (Доля правильных ответов) = (TP+TN)/(TP+TN+FP+FN) Precision (Точность) = TP/(TP+FP) Recall (Полнота) =
- 11. Оценка результатов обучения
- 12. Важность признаков Топ первых 30-признаков, по мнению Метода Опорных Векторов (SVM):
- 14. Скачать презентацию

Введение
В настоящее время на теневых форумах происходит активная купля/продажа дебетовых карт
Одна
Введение
В настоящее время на теневых форумах происходит активная купля/продажа дебетовых карт
Одна

Постановка задачи
Исходные данные
Выборка постов теневых форумов тематики “Торговля пластиковыми картами”, сформированная
Постановка задачи
Исходные данные
Выборка постов теневых форумов тематики “Торговля пластиковыми картами”, сформированная
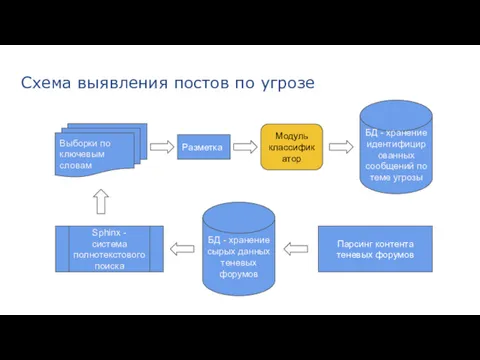
Схема выявления постов по угрозе
БД - хранение сырых данных теневых форумов
Парсинг
Схема выявления постов по угрозе
БД - хранение сырых данных теневых форумов
Парсинг

Исходные данные
Исходные данные

Разметка данных
Разметка данных требует привлечения асессоров.
Асессор - человек, знающий предметную
Разметка данных
Разметка данных требует привлечения асессоров.
Асессор - человек, знающий предметную

Предобработка данных
Удаление английских символов
Удаление символов разметки
Удаление цифр и остальных символов, не
Предобработка данных
Удаление английских символов
Удаление символов разметки
Удаление цифр и остальных символов, не

Обработка данных
Реализация классификатора включает реализацию компонентов:
Индексатор текстов
Токенизация текстов
Нормализация слов
Стемминг
Лемматизация
Взвешивание слов
Включение n-грамм
Счетчик
Обработка данных
Реализация классификатора включает реализацию компонентов:
Индексатор текстов
Токенизация текстов
Нормализация слов
Стемминг
Лемматизация
Взвешивание слов
Включение n-грамм
Счетчик

Обучение классификатора
Выбранные модели
Логистическая регрессия
Метод опорных векторов
Наивный Байесовский классификатор
Метод ближайших соседей
Разделение выборки
Обучающая
Обучение классификатора
Выбранные модели
Логистическая регрессия
Метод опорных векторов
Наивный Байесовский классификатор
Метод ближайших соседей
Разделение выборки
Обучающая
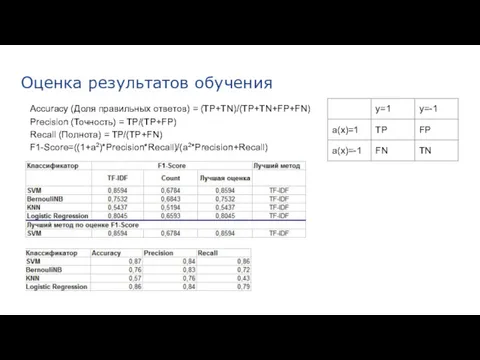
Оценка результатов обучения
Accuracy (Доля правильных ответов) = (TP+TN)/(TP+TN+FP+FN)
Precision (Точность) = TP/(TP+FP)
Recall
Оценка результатов обучения
Accuracy (Доля правильных ответов) = (TP+TN)/(TP+TN+FP+FN)
Precision (Точность) = TP/(TP+FP)
Recall
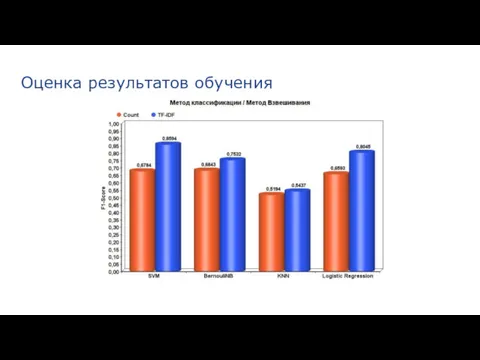
Оценка результатов обучения
Оценка результатов обучения
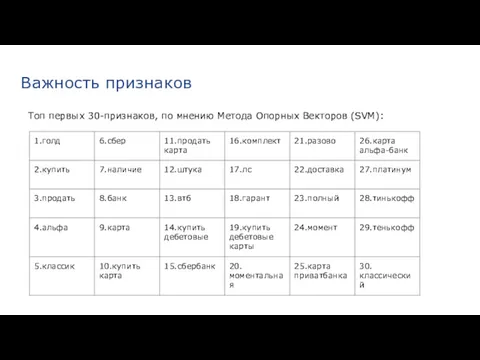
Важность признаков
Топ первых 30-признаков, по мнению Метода Опорных Векторов (SVM):
Важность признаков
Топ первых 30-признаков, по мнению Метода Опорных Векторов (SVM):
 Технологии анализа данных
Технологии анализа данных Microsoft PowerPoint
Microsoft PowerPoint Створення розкладу
Створення розкладу Информационные технологии в государственном управлении. Тема 10
Информационные технологии в государственном управлении. Тема 10 Компьютерные переводчики Технология обработки текстовой информации
Компьютерные переводчики Технология обработки текстовой информации Запросы-действия или запросы, вносящие изменения
Запросы-действия или запросы, вносящие изменения Adobe Photoshop графикалық редакторы
Adobe Photoshop графикалық редакторы 1С-Рарус: Амбулатория. Решение для медицинских организаций на базе 1С:Предприятие 8
1С-Рарус: Амбулатория. Решение для медицинских организаций на базе 1С:Предприятие 8 Компьютерная графика. Графический редактор Paint. 5 класс
Компьютерная графика. Графический редактор Paint. 5 класс Системный подход в моделировании. Типы информационных моделей
Системный подход в моделировании. Типы информационных моделей Коммутация каналов, коммутация пакетов. Постоянная и динамическая коммутация сети
Коммутация каналов, коммутация пакетов. Постоянная и динамическая коммутация сети Шифры сложной замены
Шифры сложной замены MS Excel Табличный процесс. MS Excel: возможности, достоинства и недостатки
MS Excel Табличный процесс. MS Excel: возможности, достоинства и недостатки Использование однострочных функций для настройки вывода
Использование однострочных функций для настройки вывода KEY test file
KEY test file Принципы комплектования библиотечного фонда
Принципы комплектования библиотечного фонда Фактчекинк: алгоритмы и способы проверки информации
Фактчекинк: алгоритмы и способы проверки информации Простые и сложные логические выражения. Презентация.
Простые и сложные логические выражения. Презентация. Основы языка программирования. Язык С#
Основы языка программирования. Язык С# Заливка цветом. Другие операции
Заливка цветом. Другие операции Тема 2. Тестирование ПО. Основные понятия и определения
Тема 2. Тестирование ПО. Основные понятия и определения Растровая графика – рисование в Paint
Растровая графика – рисование в Paint Теоретические основы процесса проектирования ИС. (Лекция 1)
Теоретические основы процесса проектирования ИС. (Лекция 1) Технология баз данных в системах поддержки принятия решений
Технология баз данных в системах поддержки принятия решений Хранение информации и её носители. Запись информации на носители
Хранение информации и её носители. Запись информации на носители Динамическая маршрутизация. Протокол OSPF
Динамическая маршрутизация. Протокол OSPF Масиви. Одновимірні масиви
Масиви. Одновимірні масиви Учимся читать. График учебного процесса и учебный план
Учимся читать. График учебного процесса и учебный план