- Основные понятия языка. Лекция 2

Содержание
- 2. 1. Состав языка. Алфавит, лексемы, константы Язык программирования можно уподобить очень примитивному иностранному языку с жесткими
- 3. Существует множество различных кодировок символов. Например, в Windows часто используется кодировка ANSI, а конкретно – СР1251.
- 4. Лексема (token – часто это слово ленятся переводить и пишут просто «токен») – это минимальная единица
- 5. Препроцессором называется предварительная стадия компиляции, на которой формируется окончательный вид исходного текста программы. Например, с помощью
- 6. Идентификаторы Имена в программах служат той же цели, что и имена в мире людей, – чтобы
- 7. Имена даются элементам программы, к которым требуется обращаться: переменным, типам, константам, методам, меткам и т. д.
- 8. 1. В нотации Паскаля каждое слово, составляющее идентификатор, начинается с прописной буквы, например, MaxLength, MyFuzzyShooshpanchik. 2.
- 9. Ключевые слова Ключевые слова – это зарезервированные идентификаторы, которые имеют специальное значение для компилятора. Их можно
- 10. Таблица 1 – Ключевые слова C#
- 11. Разделители используются для разделения или, наоборот, группирования элементов. Примеры разделителей: скобки, точка, запятая. Перечислим все знаки
- 12. Таблица 2 – Константы в C#
- 13. Примечание – квадратные скобки при описании означают необязательность заключенной в них конструкции. Рассмотрим константы табл. 2
- 14. Логических литералов всего два. Они широко используются в качестве признаков наличия или отсутствия чего-либо. Целые литералы
- 15. Когда компилятор распознает константу, он отводит ей место в памяти в соответствии с ее видом и
- 16. Управляющей последовательностью, или простой escape-последовательностью, называют определенный символ, предваряемый обратной косой чертой. Управляющая последовательность интерпретируется как
- 17. Символ, представленный в виде шестнадцатеричного кода, начинается с префикса \0х, за которым следует код символа. Числовое
- 18. Пример 2. Если внутри строки требуется использовать кавычку, ее предваряют косой чертой, по которой компилятор отличает
- 19. Строка может быть пустой (записывается парой смежных двойных кавычек ""), пустая символьная константа недопустима. Константа null
- 20. 2. Типы данных Данные, с которыми работает программа, хранятся в оперативной памяти. Естественно, что компилятору необходимо
- 21. Память, в которой хранятся данные во время выполнения программы, делится на две области: - стек (stack);
- 22. Различные классификации типов данных C# Для данных статического типа память выделяется в момент объявления, при этом
- 23. Если же программист определяет собственный тип данных, он описывает его характеристики и сам дает ему имя,
- 24. Как видно из таблицы, существуют несколько вариантов представления целых и вещественных величин. Программист выбирает тип каждой
- 25. Целые типы, а также символьный, вещественные и финансовый типы можно объединить под названием арифметических типов. Внутреннее
- 26. Конечно, в этом примере не учтены система счисления и другие особенности. Все вещественные типы могут представлять
- 27. Любой встроенный тип C# соответствует стандартному классу библиотеки .NET, определенному в пространстве имен System. Везде, где
- 28. Типы литералов. Как уже говорилось, величин, не имеющих типа, не существует. Поэтому литералы (константы) тоже имеют
- 29. Примечание – Встроенные типы выделены полужирным шрифтом, простые типы подчеркнуты Типы nullable введены в версию C#
- 30. Хранение в памяти величин значимого и ссылочного типов Рисунок иллюстрирует разницу между величинами значимого и ссылочного
- 31. Упаковка и распаковка Для того чтобы величины ссылочного и значимого типов могли использоваться совместно, необходимо иметь
- 33. Скачать презентацию

1. Состав языка. Алфавит, лексемы, константы
Язык программирования можно уподобить очень
1. Состав языка. Алфавит, лексемы, константы
Язык программирования можно уподобить очень

Существует множество различных кодировок символов.
Например, в Windows часто используется кодировка
Существует множество различных кодировок символов.
Например, в Windows часто используется кодировка

Лексема (token – часто это слово ленятся переводить и пишут просто
Лексема (token – часто это слово ленятся переводить и пишут просто

Препроцессором называется предварительная стадия компиляции, на которой формируется окончательный вид исходного
Препроцессором называется предварительная стадия компиляции, на которой формируется окончательный вид исходного

Идентификаторы
Имена в программах служат той же цели, что и имена в
Идентификаторы
Имена в программах служат той же цели, что и имена в

Имена даются элементам программы, к которым требуется обращаться: переменным, типам, константам,
Имена даются элементам программы, к которым требуется обращаться: переменным, типам, константам,

1. В нотации Паскаля каждое слово, составляющее идентификатор, начинается с прописной
1. В нотации Паскаля каждое слово, составляющее идентификатор, начинается с прописной

Ключевые слова
Ключевые слова – это зарезервированные идентификаторы, которые имеют специальное значение
Ключевые слова
Ключевые слова – это зарезервированные идентификаторы, которые имеют специальное значение
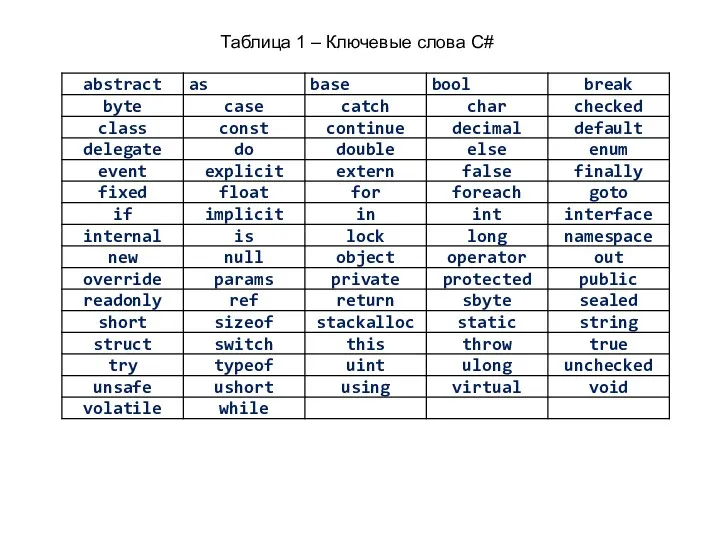
Таблица 1 – Ключевые слова C#
Таблица 1 – Ключевые слова C#

Разделители используются для разделения или, наоборот, группирования элементов.
Примеры разделителей: скобки,
Разделители используются для разделения или, наоборот, группирования элементов.
Примеры разделителей: скобки,

Таблица 2 – Константы в C#
Таблица 2 – Константы в C#

Примечание – квадратные скобки при описании означают необязательность заключенной в них
Примечание – квадратные скобки при описании означают необязательность заключенной в них

Логических литералов всего два. Они широко используются в качестве признаков наличия
Логических литералов всего два. Они широко используются в качестве признаков наличия

Когда компилятор распознает константу, он отводит ей место в памяти в
Когда компилятор распознает константу, он отводит ей место в памяти в
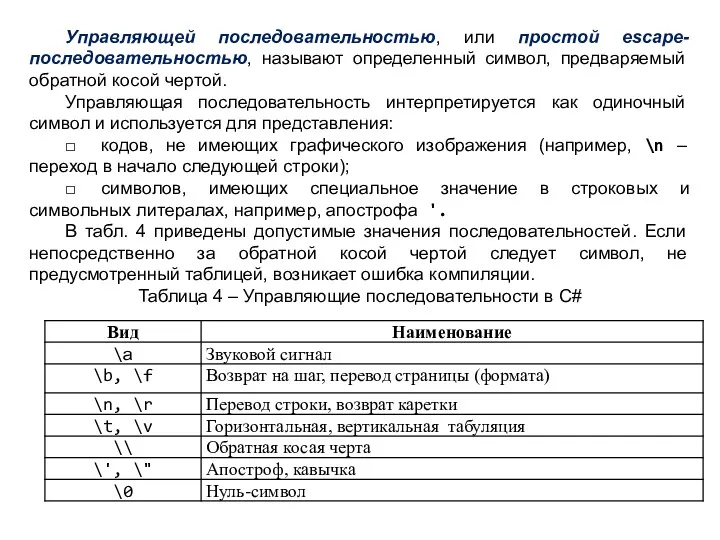
Управляющей последовательностью, или простой escape-последовательностью, называют определенный символ, предваряемый обратной косой
Управляющей последовательностью, или простой escape-последовательностью, называют определенный символ, предваряемый обратной косой

Символ, представленный в виде шестнадцатеричного кода, начинается с префикса \0х, за
Символ, представленный в виде шестнадцатеричного кода, начинается с префикса \0х, за

Пример 2. Если внутри строки требуется использовать кавычку, ее предваряют косой
Пример 2. Если внутри строки требуется использовать кавычку, ее предваряют косой

Строка может быть пустой (записывается парой смежных двойных кавычек ""), пустая
Строка может быть пустой (записывается парой смежных двойных кавычек ""), пустая

2. Типы данных
Данные, с которыми работает программа, хранятся в оперативной памяти.
2. Типы данных
Данные, с которыми работает программа, хранятся в оперативной памяти.

Память, в которой хранятся данные во время выполнения программы, делится на
Память, в которой хранятся данные во время выполнения программы, делится на
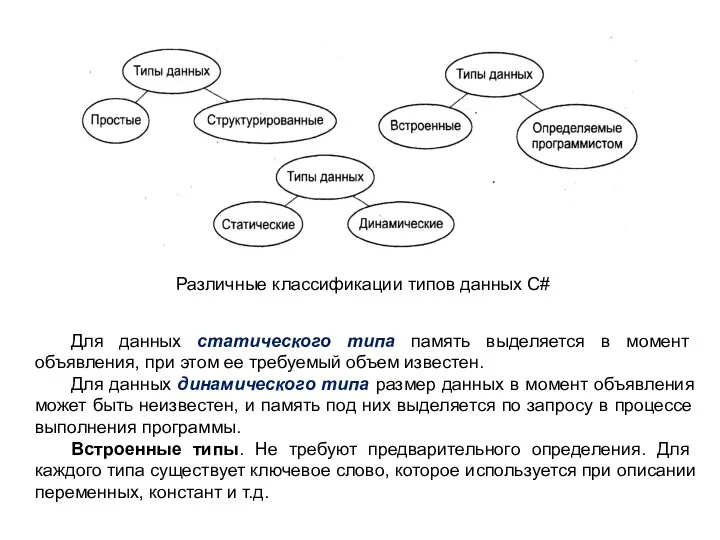
Различные классификации типов данных C#
Для данных статического типа память выделяется в
Различные классификации типов данных C#
Для данных статического типа память выделяется в
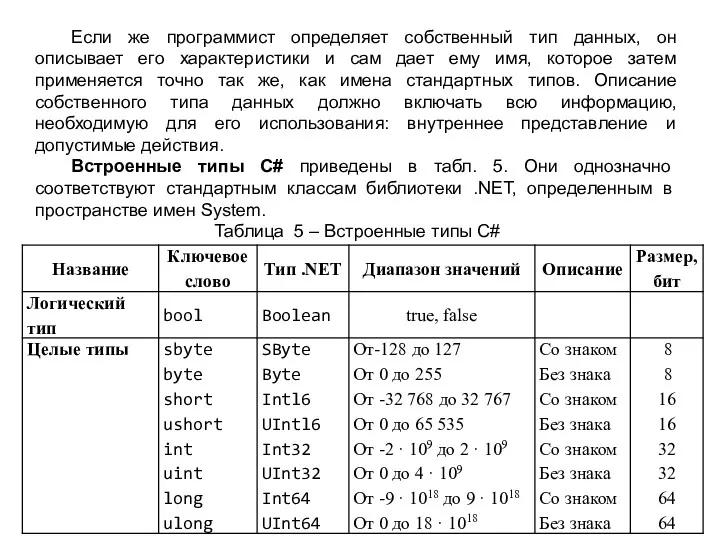
Если же программист определяет собственный тип данных, он описывает его характеристики
Если же программист определяет собственный тип данных, он описывает его характеристики
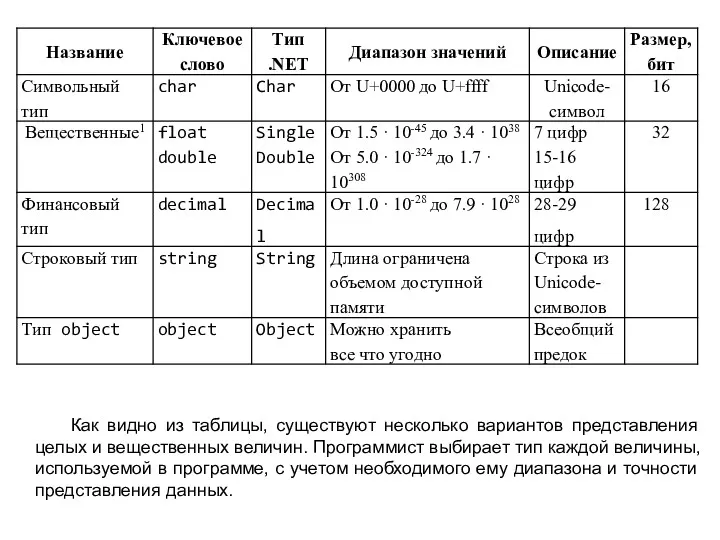
Как видно из таблицы, существуют несколько вариантов представления целых и вещественных
Как видно из таблицы, существуют несколько вариантов представления целых и вещественных

Целые типы, а также символьный, вещественные и финансовый типы можно объединить
Целые типы, а также символьный, вещественные и финансовый типы можно объединить

Конечно, в этом примере не учтены система счисления и другие особенности.
Все
Конечно, в этом примере не учтены система счисления и другие особенности.
Все

Любой встроенный тип C# соответствует стандартному классу библиотеки .NET, определенному в
Любой встроенный тип C# соответствует стандартному классу библиотеки .NET, определенному в

Типы литералов. Как уже говорилось, величин, не имеющих типа, не существует.
Типы литералов. Как уже говорилось, величин, не имеющих типа, не существует.
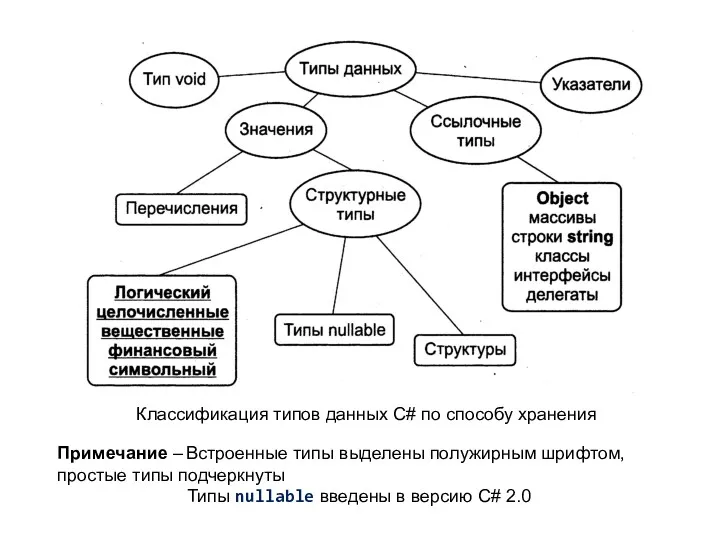
Примечание – Встроенные типы выделены полужирным шрифтом,
простые типы подчеркнуты
Типы
Примечание – Встроенные типы выделены полужирным шрифтом,
простые типы подчеркнуты
Типы
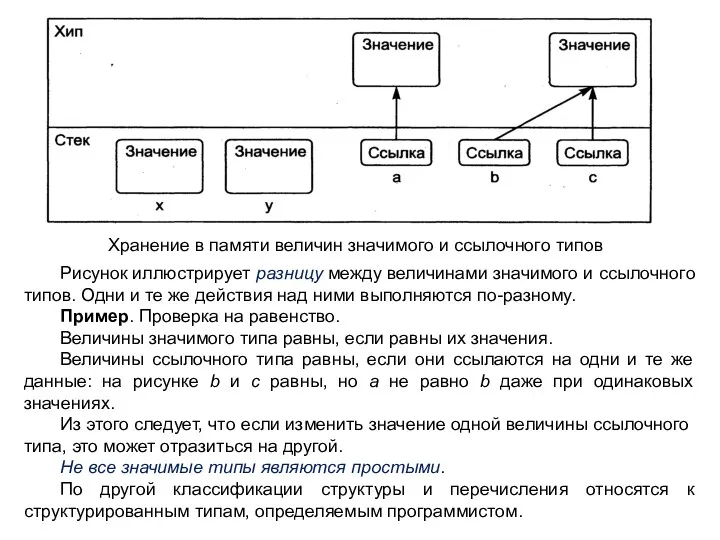
Хранение в памяти величин значимого и ссылочного типов
Рисунок иллюстрирует разницу между
Хранение в памяти величин значимого и ссылочного типов
Рисунок иллюстрирует разницу между

Упаковка и распаковка
Для того чтобы величины ссылочного и значимого типов могли
Упаковка и распаковка
Для того чтобы величины ссылочного и значимого типов могли
 Браузеры
Браузеры Путешествие в страну Компьютерная графика
Путешествие в страну Компьютерная графика Алгоритмизация и программирование. Пример написания программы в среде Visual Studio
Алгоритмизация и программирование. Пример написания программы в среде Visual Studio Триггеры в MS SQL Server
Триггеры в MS SQL Server Презентация 7 класс Типы таблиц
Презентация 7 класс Типы таблиц Кодирование информации
Кодирование информации Web design. Перехід від Web 1.0 до Web 2.0
Web design. Перехід від Web 1.0 до Web 2.0 Запуск в эксплуатацию системы ARIA SOHO
Запуск в эксплуатацию системы ARIA SOHO Интернет. История. Структура. Сервисы
Интернет. История. Структура. Сервисы Решение задач на компьютере. Алгоритмизация и программирование
Решение задач на компьютере. Алгоритмизация и программирование урок по теме: Использование анимации в PowerPoint (11 класс)
урок по теме: Использование анимации в PowerPoint (11 класс) АРМ Метролог
АРМ Метролог Виды искусственных нейронных сетей и способы организации их обучения и функционирования. Лекция 17-18
Виды искусственных нейронных сетей и способы организации их обучения и функционирования. Лекция 17-18 Интерфейсы передачи данных
Интерфейсы передачи данных Программирование (Python)
Программирование (Python) Логические основы компьютера. Базовые логические элементы. Построение логических схем
Логические основы компьютера. Базовые логические элементы. Построение логических схем Организация процесса тестирования программного обеспечения
Организация процесса тестирования программного обеспечения Структура управляющей программы и ее формат (03)
Структура управляющей программы и ее формат (03) Компьютерная сеть (Computer Network)
Компьютерная сеть (Computer Network) Создание коллажа в программе Photoshop
Создание коллажа в программе Photoshop Что такое пост
Что такое пост Базовые информационные технологии: компьютерные сети телекоммуникационные технологии, интернет-технологии (DHTML)
Базовые информационные технологии: компьютерные сети телекоммуникационные технологии, интернет-технологии (DHTML) Кодирование графической информации
Кодирование графической информации Краткая инструкция о том, как за 1 час поставить себе цель и сдвинуться с мёртвой точки
Краткая инструкция о том, как за 1 час поставить себе цель и сдвинуться с мёртвой точки Вредоносные программы и антивирусные программы
Вредоносные программы и антивирусные программы Пошук матеріалів в Інтернеті та їх оцінювання
Пошук матеріалів в Інтернеті та їх оцінювання Средства представления и записи алгоритмов. Блок – схемы.Виды алгоритмических структур. Линейный алгоритм
Средства представления и записи алгоритмов. Блок – схемы.Виды алгоритмических структур. Линейный алгоритм Интерактивный задачник Комбинаторные задачи к учебному пособию Л.Л. Босовой Занимательные задачи по информатике
Интерактивный задачник Комбинаторные задачи к учебному пособию Л.Л. Босовой Занимательные задачи по информатике