Виды искусственных нейронных сетей и способы организации их обучения и функционирования. Лекция 17-18 презентация
- Виды искусственных нейронных сетей и способы организации их обучения и функционирования. Лекция 17-18

Содержание
- 2. ПЕРСЕПТРОН Розенблатта Одной из первых искусственных сетей, способных к перцепции (восприятию) и формированию реакции на воспринятый
- 3. Элементарный персептрон Розенблатта
- 4. Обучение сети Обучение сети состоит в подстройке весовых коэффициентов каждого нейрона. Пусть имеется набор пар векторов
- 5. Предложенный Ф.Розенблаттом метод обучения состоит в итерационной подстройке матрицы весов, последовательно уменьшающей ошибку в выходных векторах.
- 7. Используемая на шаге 3 формула учитывает следующие обстоятельства: а) модифицируются только компоненты матрицы весов, отвечающие ненулевым
- 8. Данный метод обучения был назван Ф. Розенблаттом “методом коррекции с обратной передачей сигнала ошибки”. Позднее более
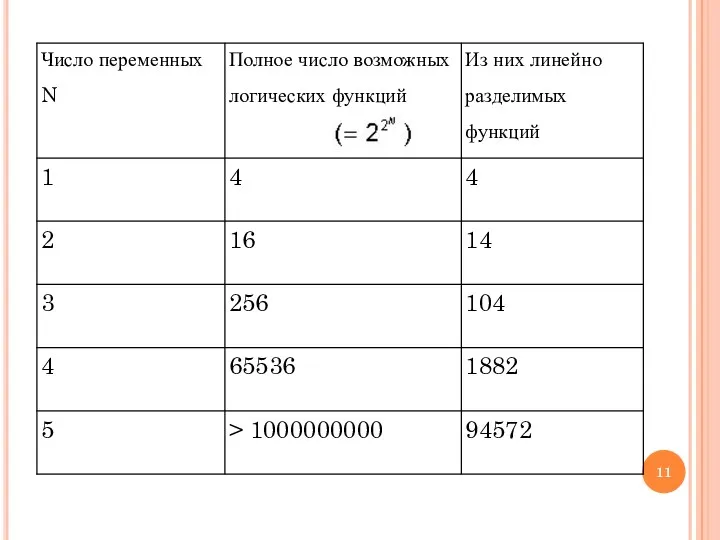
- 9. Элементарный персептрон Розенблатта Однако, как было показано позднее (M.Minsky, S.Papert, 1969), этот вывод оказался неточным: Были
- 10. Белые точки не могут быть отделены одной прямой от черных Требуемая активность нейрона для этого рисунка
- 12. Многослойный персептрон Многослойными персептронами называют нейронные сети прямого распространения. Входной сигнал в таких сетях распространяется в
- 13. Основное прикладное значение этого класса сетей состоит в том, что они могут решать задачу аппроксимации многомерных
- 14. Дискриминатор Скалярный выход нейрона можно использовать в качестве индикатор принадлежности входного вектора к одному из заданных
- 15. Нейрон как линейный дискриминатор Линейно-разделимые и линейно-неразделимые классы
- 16. Определен следующий важный результат в этой области: одного скрытого слоя нейронов с сигмоидальной функцией активации достаточно
- 18. Многослойный персептрон При построении сети на основе нескольких слоев персептронов учитывается следующее: Количество входных и выходных
- 19. Многослойные персептроны Многослойные персептроны успешно применяются для решения разнообразных сложных задач и имеют три следующих отличительных
- 20. метод обратного распространения ошибки Исторически наибольшую трудность на пути к эффективному правилу обучения многослойных персептронов вызывала
- 21. САМООБУЧАЮЩИЕСЯ НЕЙРОСЕТИ Самообучающиеся нейросети - это класс сетей, в котором обучение происходит без учителя, т.е. реализуется
- 22. Длина описания данных пропорциональна разрядности данных (числу бит), определяющей возможное разнообразие принимаемых ими значений, и размерности
- 23. понижение размерности данных с минимальной потерей информации (анализ главных компонент данных, выделение наборов независимых признаков); уменьшение
- 24. Правило Ойа минимизации ошибки обучения сети
- 25. Соревновательное обучение Соревновательное обучение состоит в том, чтобы каждый нейрон был обучен усиливать свой выход и
- 26. Алгорим «Победитель получает все» (WTA) Разновидность соревновательного алгоритма: Веса латеральных связей – т.е. связей в одном
- 27. Распределение нейронной активности "соседей" нейрона – победителя: dist (s, m*) - расстояние между выигравшим нейроном m*
- 28. Нейросетевая парадигма Липпмана-Хемминга, реализующая механизм WTA для решения задачи классификации данных, является моделью с прямой структурой
- 29. Карта самоорганизации Кохонена (Самоорганизующаяся сеть Кохонена) В противоположность хемминговой сети модель Кохонена (T.Kohonen, 1982) выполняет обобщение
- 30. Самоорганизующаяся сеть Кохонена Данная сеть обучается без учителя на основе самоорганизации. По мере обучения вектора весов
- 31. Сеть Кохонена содержит один скрытый слой нейронов. Число входов каждого нейрона равно размерности входного образа. Количество
- 32. Нейронная сеть Кохонена (Kohonen clastering network – KCN) характеризуется следующими свойствами: сеть состоит из одного скрытого
- 33. Модель Хопфилда (J.J.Hopfield, 1982) Модель Хопфилда занимает особое место в ряду нейросетевых моделей: В ней впервые
- 34. РЕКУРЕНТНЫЕ СЕТИ ХОПФИЛДА Сеть Хопфилда получается, если наложить на веса связей в выражении s j =
- 35. Конфигурация сети Хопфилда
- 36. Одно из достоинств симметричной квадратной матрицы связей, характерной для сети Хопфилда, состоит в том, что поведение
- 37. Поведение системы в пространстве состояний напоминает движение шарика, который стремится скатиться в точку минимума некоторого потенциального
- 38. Характер рельефа определяется видом целевой функции Е и формируется в процессе обучения сети. Обучение производится путем
- 39. Главное свойство сети Хопфилда - способность восстанавливать возмущенное состояние равновесия - "вспоминать" искаженные или потерянные биты
- 40. Одна и та же сеть с одними и теми же весами связей может хранить и воспроизводить
- 41. Ассоциативный характер памяти сети Хопфилда качественно отличает ее от обычной, адресной, компьютерной памяти. При использовании ассоциативной
- 42. Преобразование информации рекуррентными нейронными сетями типа сети Хопфилда, минимизирующими энергию, может приводить к появлению в их
- 43. Хотя сети Хопфилда получили применение на практике, им свойственны определенные недостатки, ограничивающие возможности их применения: модель
- 45. Скачать презентацию

ПЕРСЕПТРОН Розенблатта
Одной из первых искусственных сетей, способных к перцепции (восприятию) и
ПЕРСЕПТРОН Розенблатта
Одной из первых искусственных сетей, способных к перцепции (восприятию) и
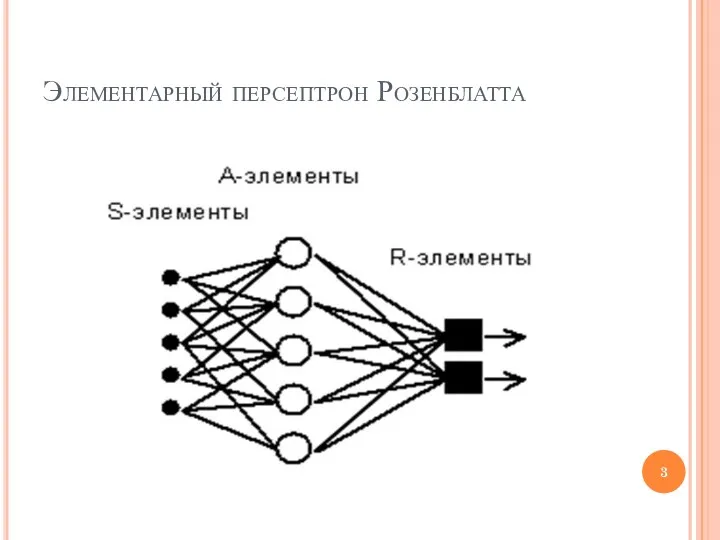
Элементарный персептрон Розенблатта
Элементарный персептрон Розенблатта

Обучение сети
Обучение сети состоит в подстройке весовых коэффициентов каждого нейрона.
Пусть
Обучение сети
Обучение сети состоит в подстройке весовых коэффициентов каждого нейрона.
Пусть

Предложенный Ф.Розенблаттом метод обучения состоит в итерационной подстройке матрицы весов, последовательно
Предложенный Ф.Розенблаттом метод обучения состоит в итерационной подстройке матрицы весов, последовательно

Используемая на шаге 3 формула
учитывает следующие обстоятельства:
а) модифицируются только
Используемая на шаге 3 формула
учитывает следующие обстоятельства:
а) модифицируются только

Данный метод обучения был назван Ф. Розенблаттом “методом коррекции с обратной
Данный метод обучения был назван Ф. Розенблаттом “методом коррекции с обратной

Элементарный персептрон Розенблатта
Однако, как было показано позднее (M.Minsky, S.Papert, 1969), этот
Элементарный персептрон Розенблатта
Однако, как было показано позднее (M.Minsky, S.Papert, 1969), этот
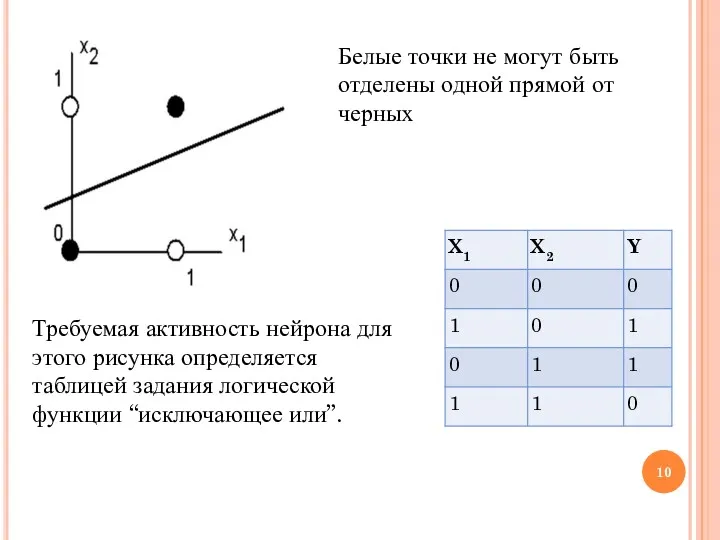
Белые точки не могут быть отделены одной прямой от черных
Требуемая активность
Белые точки не могут быть отделены одной прямой от черных
Требуемая активность

Многослойный персептрон
Многослойными персептронами называют нейронные сети прямого распространения.
Входной сигнал в
Многослойный персептрон
Многослойными персептронами называют нейронные сети прямого распространения.
Входной сигнал в

Основное прикладное значение этого класса сетей состоит в том, что они
Основное прикладное значение этого класса сетей состоит в том, что они

Дискриминатор
Скалярный выход нейрона можно использовать в качестве индикатор принадлежности входного вектора
Дискриминатор
Скалярный выход нейрона можно использовать в качестве индикатор принадлежности входного вектора
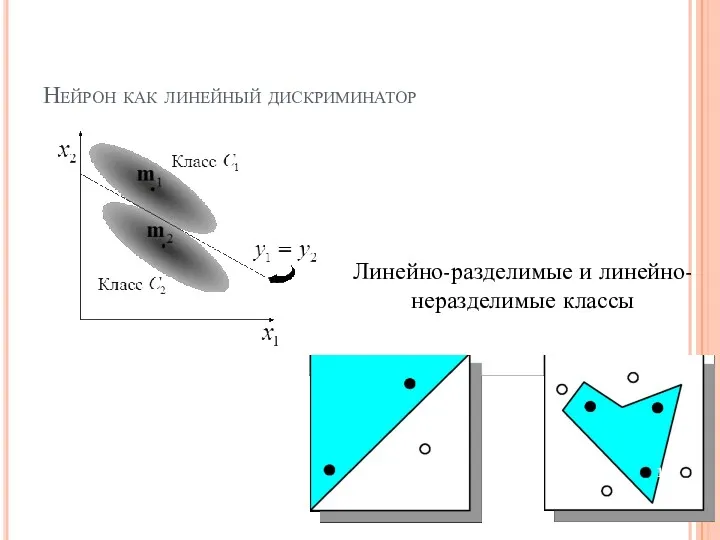
Нейрон как линейный дискриминатор
Линейно-разделимые и линейно-неразделимые классы
Нейрон как линейный дискриминатор
Линейно-разделимые и линейно-неразделимые классы

Определен следующий важный результат в этой области: одного скрытого слоя нейронов
Определен следующий важный результат в этой области: одного скрытого слоя нейронов
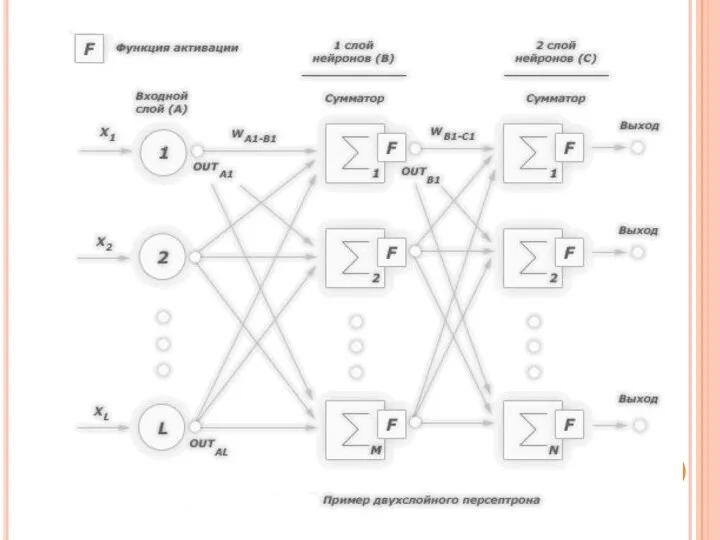

Многослойный персептрон
При построении сети на основе нескольких слоев персептронов учитывается следующее:
Количество
Многослойный персептрон
При построении сети на основе нескольких слоев персептронов учитывается следующее:
Количество

Многослойные персептроны
Многослойные персептроны успешно применяются для решения разнообразных сложных задач
Многослойные персептроны
Многослойные персептроны успешно применяются для решения разнообразных сложных задач

метод обратного распространения ошибки
Исторически наибольшую трудность на пути к эффективному правилу
метод обратного распространения ошибки
Исторически наибольшую трудность на пути к эффективному правилу

САМООБУЧАЮЩИЕСЯ НЕЙРОСЕТИ
Самообучающиеся нейросети - это класс сетей, в котором обучение происходит
САМООБУЧАЮЩИЕСЯ НЕЙРОСЕТИ
Самообучающиеся нейросети - это класс сетей, в котором обучение происходит

Длина описания данных пропорциональна разрядности данных (числу бит), определяющей возможное разнообразие
Длина описания данных пропорциональна разрядности данных (числу бит), определяющей возможное разнообразие

понижение размерности данных с минимальной потерей информации (анализ главных компонент данных,
понижение размерности данных с минимальной потерей информации (анализ главных компонент данных,

Правило Ойа минимизации ошибки обучения сети
Правило Ойа минимизации ошибки обучения сети

Соревновательное обучение
Соревновательное обучение состоит в том, чтобы каждый нейрон был обучен
Соревновательное обучение
Соревновательное обучение состоит в том, чтобы каждый нейрон был обучен

Алгорим «Победитель получает все» (WTA)
Разновидность соревновательного алгоритма:
Веса латеральных связей – т.е.
Алгорим «Победитель получает все» (WTA)
Разновидность соревновательного алгоритма:
Веса латеральных связей – т.е.
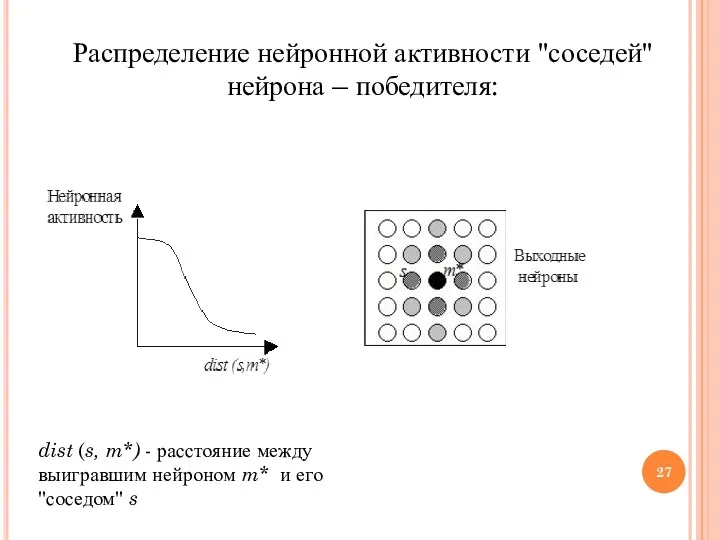
Распределение нейронной активности "соседей" нейрона – победителя:
dist (s, m*) -
Распределение нейронной активности "соседей" нейрона – победителя:
dist (s, m*) -

Нейросетевая парадигма Липпмана-Хемминга, реализующая механизм WTA для решения задачи классификации данных,
Нейросетевая парадигма Липпмана-Хемминга, реализующая механизм WTA для решения задачи классификации данных,

Карта самоорганизации Кохонена
(Самоорганизующаяся сеть Кохонена)
В противоположность хемминговой сети модель Кохонена (T.Kohonen,
Карта самоорганизации Кохонена
(Самоорганизующаяся сеть Кохонена)
В противоположность хемминговой сети модель Кохонена (T.Kohonen,

Самоорганизующаяся сеть Кохонена
Данная сеть обучается без учителя на основе самоорганизации.
По
Самоорганизующаяся сеть Кохонена
Данная сеть обучается без учителя на основе самоорганизации.
По

Сеть Кохонена содержит один скрытый слой нейронов. Число входов каждого нейрона
Сеть Кохонена содержит один скрытый слой нейронов. Число входов каждого нейрона
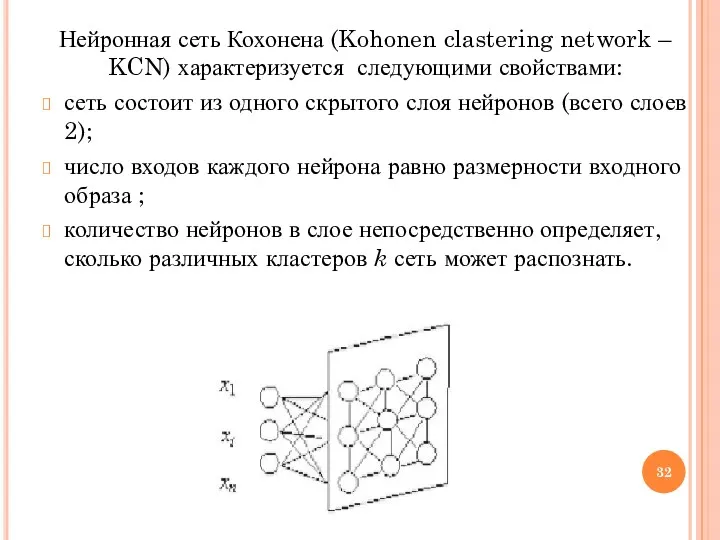
Нейронная сеть Кохонена (Kohonen clastering network – KCN) характеризуется следующими свойствами:
Нейронная сеть Кохонена (Kohonen clastering network – KCN) характеризуется следующими свойствами:

Модель Хопфилда (J.J.Hopfield, 1982)
Модель Хопфилда занимает особое место в ряду
Модель Хопфилда (J.J.Hopfield, 1982)
Модель Хопфилда занимает особое место в ряду

РЕКУРЕНТНЫЕ СЕТИ ХОПФИЛДА
Сеть Хопфилда получается, если наложить на веса связей в
РЕКУРЕНТНЫЕ СЕТИ ХОПФИЛДА
Сеть Хопфилда получается, если наложить на веса связей в
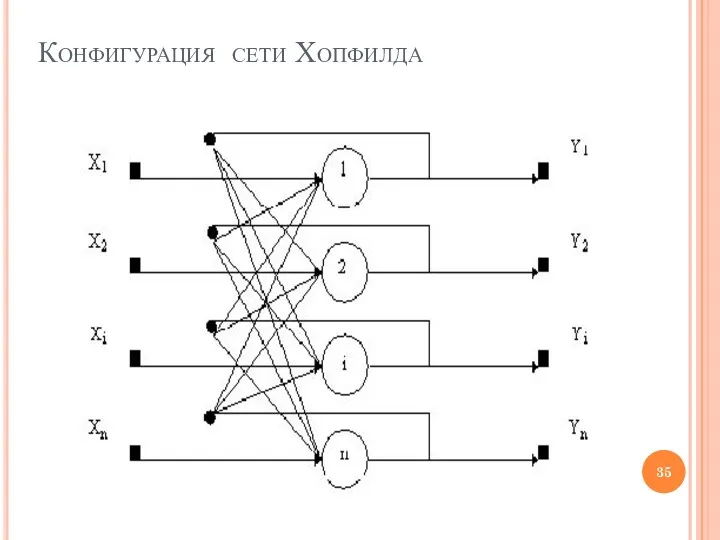
Конфигурация сети Хопфилда
Конфигурация сети Хопфилда

Одно из достоинств симметричной квадратной матрицы связей, характерной для сети Хопфилда,
Одно из достоинств симметричной квадратной матрицы связей, характерной для сети Хопфилда,
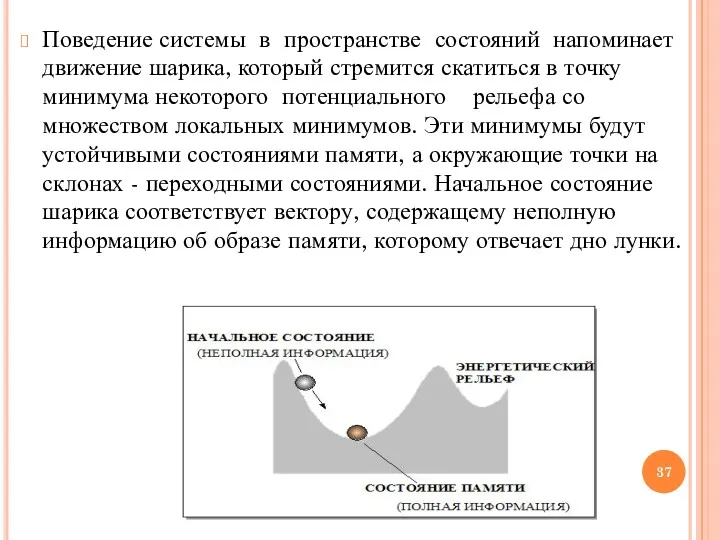
Поведение системы в пространстве состояний напоминает движение шарика, который стремится скатиться
Поведение системы в пространстве состояний напоминает движение шарика, который стремится скатиться

Характер рельефа определяется видом целевой функции Е и формируется в процессе
Характер рельефа определяется видом целевой функции Е и формируется в процессе

Главное свойство сети Хопфилда - способность восстанавливать возмущенное состояние равновесия -
Главное свойство сети Хопфилда - способность восстанавливать возмущенное состояние равновесия -

Одна и та же сеть с одними и теми же весами
Одна и та же сеть с одними и теми же весами

Ассоциативный характер памяти сети Хопфилда качественно отличает ее от обычной, адресной,
Ассоциативный характер памяти сети Хопфилда качественно отличает ее от обычной, адресной,

Преобразование информации рекуррентными нейронными сетями типа сети Хопфилда, минимизирующими энергию, может
Преобразование информации рекуррентными нейронными сетями типа сети Хопфилда, минимизирующими энергию, может

Хотя сети Хопфилда получили применение на практике, им свойственны определенные недостатки,
Хотя сети Хопфилда получили применение на практике, им свойственны определенные недостатки,
 Операторы ввода и вывода в Pascal
Операторы ввода и вывода в Pascal Видеоблоги. Виды видеоблогов
Видеоблоги. Виды видеоблогов Памятка по информационной безопасности
Памятка по информационной безопасности Управление учетными записями пользователей MySQL-сервера
Управление учетными записями пользователей MySQL-сервера Blender (часть 1)
Blender (часть 1) Планирование процессов
Планирование процессов Поняття про мову розмітки, гіпертекстовий документ та його елементи. Поняття тегу й атрибуту, теги форматування шрифтів
Поняття про мову розмітки, гіпертекстовий документ та його елементи. Поняття тегу й атрибуту, теги форматування шрифтів Эко-dream
Эко-dream Представление звуковой информации
Представление звуковой информации 4. Java OOP. 3. Encapsulation
4. Java OOP. 3. Encapsulation Продвижение бизнеса и бренда в социальных сетях
Продвижение бизнеса и бренда в социальных сетях Модели объектов и их назначение
Модели объектов и их назначение Биллинговая система компании Мегафон
Биллинговая система компании Мегафон Тренинг по функциональным возможностям Tableau
Тренинг по функциональным возможностям Tableau Язык программирования D
Язык программирования D Медиабезопасность. Правила безопасного поведения в интернете
Медиабезопасность. Правила безопасного поведения в интернете Коммутаторы и концентраторы. Аппаратура компьютерных сетей
Коммутаторы и концентраторы. Аппаратура компьютерных сетей Презентация Компьютерные сети 10 класс
Презентация Компьютерные сети 10 класс Язык запросов SQL. Язык запросов к данным (DML)
Язык запросов SQL. Язык запросов к данным (DML) Мережева безпека. Інструменти для аналізу трафіка
Мережева безпека. Інструменти для аналізу трафіка Введение в язык программирования РНР
Введение в язык программирования РНР Работа в сети интернет
Работа в сети интернет Introduction to graphs
Introduction to graphs Сервисы компании Такском
Сервисы компании Такском Языки программирования
Языки программирования Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары
Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары Роль информатики и вычислительной техники в обществе. Информация и информационные процессы
Роль информатики и вычислительной техники в обществе. Информация и информационные процессы Развитие редакции 2.0 конфигурации Бухгалтерия государственного учреждения
Развитие редакции 2.0 конфигурации Бухгалтерия государственного учреждения