- Основы программирования

Содержание
- 2. Динамические структуры данных Список односвязный Список двусвязный Циклический список Дерево Двоичное дерево Двоичное дерево поиска Графы
- 3. Двоичное дерево поиска Двоичное дерево поиска (англ. binary search tree, BST) — это двоичное дерево, для
- 4. Структура узла дерева struct NodeTree { int data; struct NodeTree * left; struct NodeTree * right;
- 5. Отрабатываем навыки рисования void main() { struct NodeTree node1 = { 1, NULL, NULL }; struct
- 6. Простейшая печать дерева void printTree(struct NodeTree * p) { if (p != NULL) { printTree(p->left); printf("(%d)\n",
- 7. Печать дерева c отображением структуры void printfShift(int shift) { int i; for (i = 0; i
- 8. Добавление элемента в дерево struct NodeTree * addElement(struct NodeTree *p, int value) { if (p ==
- 9. Добавление элемента в дерево void main() { root = addElement(root, 60); root = addElement(root, 40); root
- 10. Добавление элемента в дерево void main() { root = addElement(root, 60); root = addElement(root, 40); root
- 11. Очистка дерева void clearTree(struct NodeTree *p) { if (p != NULL) { clearTree(p->left); clearTree(p->right); free(p); }
- 12. А такой элемент есть в дереве? int contains(struct NodeTree * p, int value) { if (p
- 13. А такой элемент есть в дереве? (2) void main() { root = addElement(root, 60); root =
- 14. Сравнение скорости работы структур данных
- 15. Задача конвертации текста Задача из лекции 13. На входе 2 файла: Файл 1: Файл словаря –
- 16. Текст программы – решение на массиве (1) #define _CRT_SECURE_NO_WARNINGS #include #include #include #include #include
- 17. Текст программы – решение на массиве (2) #define MAX_WORDS 10000 #define MAX_LEN 25 struct Dictionary {
- 18. Текст программы – решение на массиве (3) struct Dictionary * create() { struct Dictionary * dict
- 19. Текст программы – решение на массиве (4) void addWord(struct Dictionary * dict, char * word) {
- 20. Текст программы – решение на массиве (5) int contains(struct Dictionary * dict, char * word) {
- 21. Текст программы – решение на массиве (6) int loadDictionary(struct Dictionary * dict, char * filename) {
- 22. Текст программы – решение на массиве (7) // в цикле для всех строк while (!feof(fin)) {
- 23. Текст программы – решение на массиве (8) int convertTextToHtml( struct Dictionary * dict, char * text_in_filename,
- 24. Текст программы – решение на массиве (9) FILE *fout = fopen(text_out_filename, "wt"); if (fout == NULL)
- 25. Текст программы – решение на массиве (10) char ch; int is_letter = 0; char word[81]; int
- 26. Текст программы – решение на массиве (11) else { // if (!isalpha(ch)) { if (is_letter) {
- 27. Текст программы – решение на массиве (12) } // while ((ch = getc(fin)) != EOF) fclose(fin);
- 28. Текст программы – решение на массиве (13) void main() { long t0, t1, t2; t0 =
- 29. Текст программы – решение на массиве (14) destroy(dict); t2 = clock(); printf("t2 = %f sec \n",
- 30. Тестируем с массивом Alice.txt – 142 800 байт Tolkien.txt – 1 008 639 байт ( Alice.txt
- 31. решение на списке (1) struct Node { char * word; struct Node * next; }; struct
- 32. решение на списке (2) struct Dictionary * create() { struct Dictionary * dict = (struct Dictionary
- 33. решение на списке (3) void addWord(struct Dictionary * dict, char * word) { struct Node *
- 34. решение на списке (4) void destroy(struct Dictionary * dict) { while (dict->first != NULL) { struct
- 35. решение на списке (5) int contains(struct Dictionary * dict, char * word) { struct Node *
- 36. решение на списке (6) void main() { long t0, t1, t2; t0 = clock(); printf("t0 =
- 37. Тестируем со списком Alice.txt – 142 800 байт Tolkien.txt – 1 008 639 байт ( Alice.txt
- 38. решение на дереве (1) struct NodeTree { char * word; struct NodeTree * left; struct NodeTree
- 39. решение на дереве (2) struct Dictionary * create() { struct Dictionary * dict = (struct Dictionary
- 40. решение на дереве (3) struct NodeTree * addElement( struct NodeTree *p, char* word) { int cond;
- 41. решение на дереве (4) else if ((cond = strcmp(word, p->word)) == 0) { // вставляемое слово
- 42. решение на дереве (5) void addWord(struct Dictionary * dict, char * word) { dict->root = addElement(dict->root,
- 43. решение на дереве (6) void clearTree(struct NodeTree *p) { if (p != NULL) { clearTree(p->left); clearTree(p->right);
- 44. решение на дереве (7) int containElement(struct NodeTree * p, char *word) { int cond; if (p
- 45. решение на дереве (8) int contains(struct Dictionary * dict, char * word) { return containElement(dict->root, word);
- 46. решение на дереве (9) void main() { long t0, t1, t2; t0 = clock(); printf("t0 =
- 47. Тестируем с деревом Alice.txt – 142 800 байт Tolkien.txt – 1 008 639 байт ( Alice.txt
- 48. Зависимость времени работы от длины текстового файла Время работы в секундах Alice.txt – 142 800 байт
- 49. Вычислительная сложность алгоритма https://ru.wikipedia.org/wiki/%D0%92%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D1%8C «почистить ковёр пылесосом» требует время, линейно зависящее от его площади – O(N)
- 50. Вычислительная сложность алгоритма Вопрос: Какая зависимость времени обработки от длины файла? Ответ: Линейная зависимость: O(N) O(N)
- 51. Вычислительная сложность поиска Поиск элемента – какая зависимость времени поиска от количества элементов в списке? –
- 52. Вычислительная сложность поиска Поиск в списке: O(N) Поиск в массиве (неотсортированном) : O(N) Поиск в двоичном
- 54. Скачать презентацию

Динамические структуры данных
Список односвязный
Список двусвязный
Циклический список
Дерево
Двоичное дерево
Двоичное дерево поиска
Графы
…
Динамические структуры данных
Список односвязный
Список двусвязный
Циклический список
Дерево
Двоичное дерево
Двоичное дерево поиска
Графы
…

Двоичное дерево поиска
Двоичное дерево поиска (англ. binary search tree, BST) — это двоичное
Двоичное дерево поиска
Двоичное дерево поиска (англ. binary search tree, BST) — это двоичное
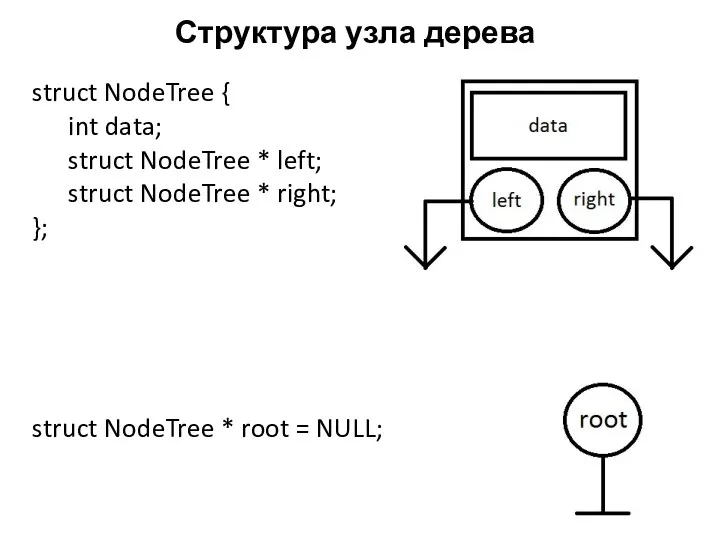
Структура узла дерева
struct NodeTree {
int data;
struct NodeTree * left;
struct NodeTree *
Структура узла дерева
struct NodeTree {
int data;
struct NodeTree * left;
struct NodeTree *
Отрабатываем навыки рисования
void main() {
struct NodeTree node1 = { 1, NULL,
Отрабатываем навыки рисования
void main() {
struct NodeTree node1 = { 1, NULL,

Простейшая печать дерева
void printTree(struct NodeTree * p)
{
if (p != NULL) {
printTree(p->left);
printf("(%d)\n",
Простейшая печать дерева
void printTree(struct NodeTree * p)
{
if (p != NULL) {
printTree(p->left);
printf("(%d)\n",

Печать дерева c отображением структуры
void printfShift(int shift) {
int i;
for (i =
Печать дерева c отображением структуры
void printfShift(int shift) {
int i;
for (i =

Добавление элемента в дерево
struct NodeTree * addElement(struct NodeTree *p, int value)
{
if
Добавление элемента в дерево
struct NodeTree * addElement(struct NodeTree *p, int value)
{
if

Добавление элемента в дерево
void main() {
root = addElement(root, 60);
root = addElement(root,
Добавление элемента в дерево
void main() {
root = addElement(root, 60);
root = addElement(root,

Добавление элемента в дерево
void main() {
root = addElement(root, 60);
root = addElement(root,
Добавление элемента в дерево
void main() {
root = addElement(root, 60);
root = addElement(root,

Очистка дерева
void clearTree(struct NodeTree *p)
{
if (p != NULL) {
clearTree(p->left);
clearTree(p->right);
free(p);
}
}
...
clearTree(root);
root = NULL;
...
Очистка дерева
void clearTree(struct NodeTree *p)
{
if (p != NULL) {
clearTree(p->left);
clearTree(p->right);
free(p);
}
}
...
clearTree(root);
root = NULL;
...

А такой элемент есть в дереве?
int contains(struct NodeTree * p, int
А такой элемент есть в дереве?
int contains(struct NodeTree * p, int

А такой элемент есть в дереве? (2)
void main() {
root = addElement(root,
А такой элемент есть в дереве? (2)
void main() {
root = addElement(root,

Сравнение скорости работы структур данных
Сравнение скорости работы структур данных

Задача конвертации текста
Задача из лекции 13.
На входе 2 файла:
Файл 1:
Задача конвертации текста
Задача из лекции 13.
На входе 2 файла:
Файл 1:

Текст программы – решение на массиве (1)
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include
#include
Текст программы – решение на массиве (1)
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include
#include

Текст программы – решение на массиве (2)
#define MAX_WORDS 10000
#define MAX_LEN 25
struct
Текст программы – решение на массиве (2)
#define MAX_WORDS 10000
#define MAX_LEN 25
struct

Текст программы – решение на массиве (3)
struct Dictionary * create()
{
struct Dictionary
Текст программы – решение на массиве (3)
struct Dictionary * create()
{
struct Dictionary

Текст программы – решение на массиве (4)
void addWord(struct Dictionary * dict,
Текст программы – решение на массиве (4)
void addWord(struct Dictionary * dict,

Текст программы – решение на массиве (5)
int contains(struct Dictionary * dict,
Текст программы – решение на массиве (5)
int contains(struct Dictionary * dict,

Текст программы – решение на массиве (6)
int loadDictionary(struct Dictionary * dict,
Текст программы – решение на массиве (6)
int loadDictionary(struct Dictionary * dict,

Текст программы – решение на массиве (7)
// в цикле для всех
Текст программы – решение на массиве (7)
// в цикле для всех

Текст программы – решение на массиве (8)
int convertTextToHtml(
struct Dictionary * dict,
Текст программы – решение на массиве (8)
int convertTextToHtml(
struct Dictionary * dict,

Текст программы – решение на массиве (9)
FILE *fout = fopen(text_out_filename, "wt");
if
Текст программы – решение на массиве (9)
FILE *fout = fopen(text_out_filename, "wt");
if

Текст программы – решение на массиве (10)
char ch;
int is_letter = 0;
char
Текст программы – решение на массиве (10)
char ch;
int is_letter = 0;
char

Текст программы – решение на массиве (11)
else { // if (!isalpha(ch))
Текст программы – решение на массиве (11)
else { // if (!isalpha(ch))

Текст программы – решение на массиве (12)
} // while ((ch =
Текст программы – решение на массиве (12)
} // while ((ch =

Текст программы – решение на массиве (13)
void main() {
long t0, t1,
Текст программы – решение на массиве (13)
void main() {
long t0, t1,

Текст программы – решение на массиве (14)
destroy(dict);
t2 = clock();
printf("t2 = %f
Текст программы – решение на массиве (14)
destroy(dict);
t2 = clock();
printf("t2 = %f
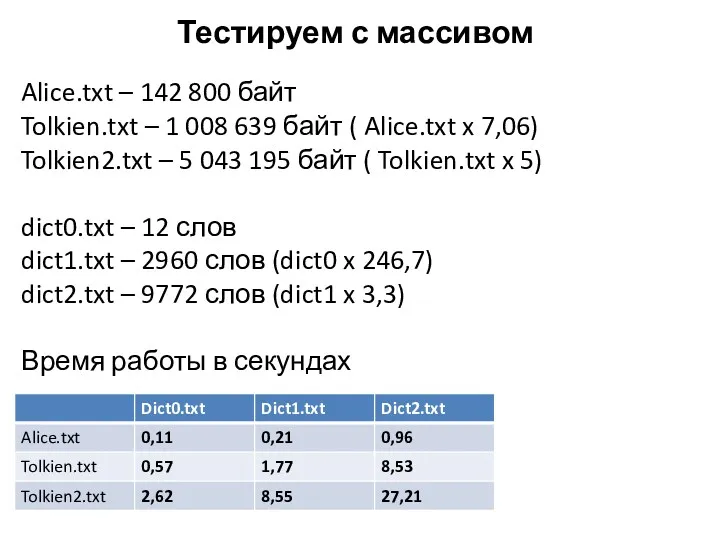
Тестируем с массивом
Alice.txt – 142 800 байт
Tolkien.txt – 1 008 639
Тестируем с массивом
Alice.txt – 142 800 байт
Tolkien.txt – 1 008 639

решение на списке (1)
struct Node {
char * word;
struct Node * next;
};
struct
решение на списке (1)
struct Node {
char * word;
struct Node * next;
};
struct

решение на списке (2)
struct Dictionary * create()
{
struct Dictionary * dict =
решение на списке (2)
struct Dictionary * create()
{
struct Dictionary * dict =

решение на списке (3)
void addWord(struct Dictionary * dict, char * word)
решение на списке (3)
void addWord(struct Dictionary * dict, char * word)

решение на списке (4)
void destroy(struct Dictionary * dict) {
while (dict->first !=
решение на списке (4)
void destroy(struct Dictionary * dict) {
while (dict->first !=

решение на списке (5)
int contains(struct Dictionary * dict, char * word)
{
struct
решение на списке (5)
int contains(struct Dictionary * dict, char * word)
{
struct

решение на списке (6)
void main() {
long t0, t1, t2;
t0 = clock();
printf("t0
решение на списке (6)
void main() {
long t0, t1, t2;
t0 = clock();
printf("t0
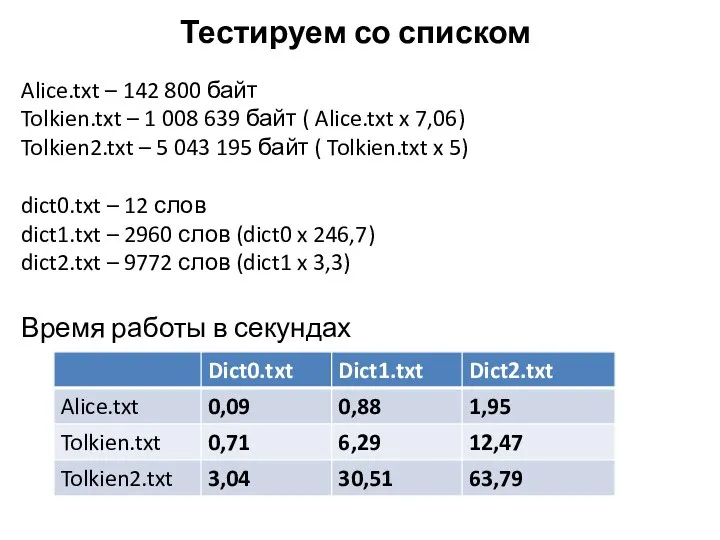
Тестируем со списком
Alice.txt – 142 800 байт
Tolkien.txt – 1 008 639
Тестируем со списком
Alice.txt – 142 800 байт
Tolkien.txt – 1 008 639

решение на дереве (1)
struct NodeTree {
char * word;
struct NodeTree * left;
struct
решение на дереве (1)
struct NodeTree {
char * word;
struct NodeTree * left;
struct

решение на дереве (2)
struct Dictionary * create()
{
struct Dictionary * dict =
решение на дереве (2)
struct Dictionary * create()
{
struct Dictionary * dict =

решение на дереве (3)
struct NodeTree * addElement(
struct NodeTree *p,
char* word)
решение на дереве (3)
struct NodeTree * addElement(
struct NodeTree *p,
char* word)

решение на дереве (4)
else if ((cond = strcmp(word, p->word)) == 0)
решение на дереве (4)
else if ((cond = strcmp(word, p->word)) == 0)

решение на дереве (5)
void addWord(struct Dictionary * dict, char * word)
{
dict->root
решение на дереве (5)
void addWord(struct Dictionary * dict, char * word)
{
dict->root

решение на дереве (6)
void clearTree(struct NodeTree *p)
{
if (p != NULL) {
clearTree(p->left);
clearTree(p->right);
free(p->word);
free(p);
}
}
void
решение на дереве (6)
void clearTree(struct NodeTree *p)
{
if (p != NULL) {
clearTree(p->left);
clearTree(p->right);
free(p->word);
free(p);
}
}
void

решение на дереве (7)
int containElement(struct NodeTree * p, char *word)
{
int cond;
if
решение на дереве (7)
int containElement(struct NodeTree * p, char *word)
{
int cond;
if

решение на дереве (8)
int contains(struct Dictionary * dict, char * word)
{
return
решение на дереве (8)
int contains(struct Dictionary * dict, char * word)
{
return

решение на дереве (9)
void main() {
long t0, t1, t2;
t0 = clock();
printf("t0
решение на дереве (9)
void main() {
long t0, t1, t2;
t0 = clock();
printf("t0
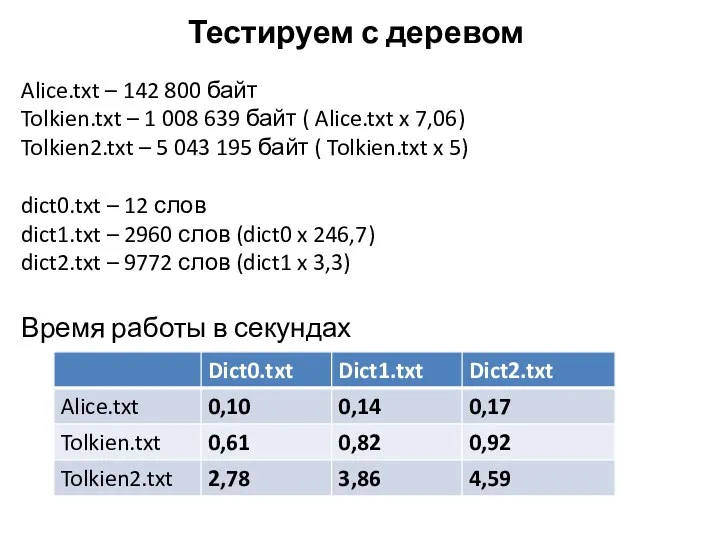
Тестируем с деревом
Alice.txt – 142 800 байт
Tolkien.txt – 1 008 639
Тестируем с деревом
Alice.txt – 142 800 байт
Tolkien.txt – 1 008 639
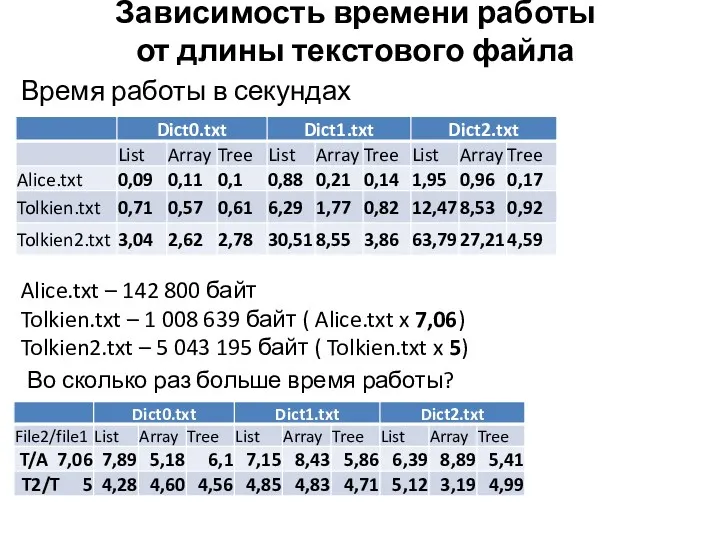
Зависимость времени работы
от длины текстового файла
Время работы в секундах
Alice.txt –
Зависимость времени работы
от длины текстового файла
Время работы в секундах
Alice.txt –

Вычислительная сложность алгоритма
https://ru.wikipedia.org/wiki/%D0%92%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D1%8C
«почистить ковёр пылесосом» требует время, линейно зависящее от его
Вычислительная сложность алгоритма
https://ru.wikipedia.org/wiki/%D0%92%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D1%8C
«почистить ковёр пылесосом» требует время, линейно зависящее от его
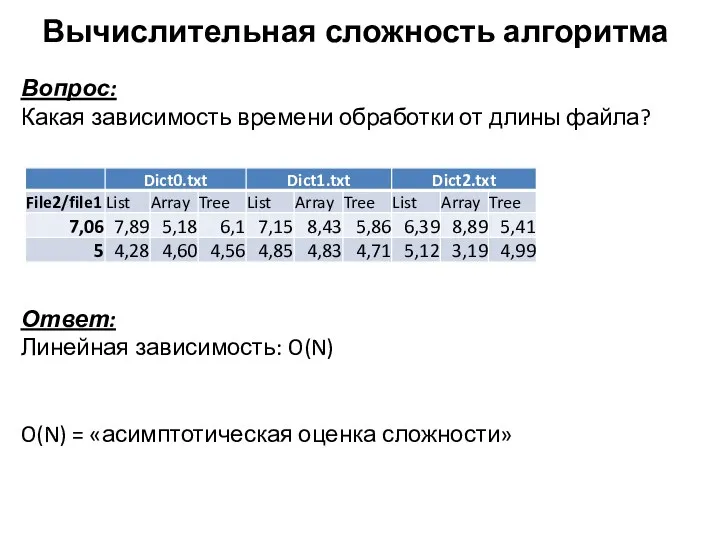
Вычислительная сложность алгоритма
Вопрос:
Какая зависимость времени обработки от длины файла?
Ответ:
Линейная зависимость: O(N)
O(N)
Вычислительная сложность алгоритма
Вопрос:
Какая зависимость времени обработки от длины файла?
Ответ:
Линейная зависимость: O(N)
O(N)

Вычислительная сложность поиска
Поиск элемента
– какая зависимость времени поиска от количества элементов
Вычислительная сложность поиска
Поиск элемента
– какая зависимость времени поиска от количества элементов

Вычислительная сложность поиска
Поиск в списке: O(N)
Поиск в массиве (неотсортированном) : O(N)
Поиск
Вычислительная сложность поиска
Поиск в списке: O(N)
Поиск в массиве (неотсортированном) : O(N)
Поиск
 Линейные алгоритмы обработки целочисленных данных
Линейные алгоритмы обработки целочисленных данных Создание компьютерных публикаций
Создание компьютерных публикаций Анализ дерева решений
Анализ дерева решений Введение в информатику
Введение в информатику Логические выражения. Построение таблиц истинности логических выражений
Логические выражения. Построение таблиц истинности логических выражений Техническое задание по дизайну для продающего сайта
Техническое задание по дизайну для продающего сайта Управление ключами в симметричных криптосистемах. Лекция 6
Управление ключами в симметричных криптосистемах. Лекция 6 Структура программы на языке Python. Операции и переменные. Типы данных
Структура программы на языке Python. Операции и переменные. Типы данных Методика пошуку інформації в науковометричній базі даних Scopus
Методика пошуку інформації в науковометричній базі даних Scopus Макетирование издания
Макетирование издания Девушка за окном. 11 класс
Девушка за окном. 11 класс Текстовый редактор 9 класс
Текстовый редактор 9 класс Кодирование информации. Изучение единиц измерения информации. Носители информации
Кодирование информации. Изучение единиц измерения информации. Носители информации Brining Governance to the clouds. Module 3. Policy-making process
Brining Governance to the clouds. Module 3. Policy-making process Компьютерная игра Tower Defense
Компьютерная игра Tower Defense условия выбора и простые логические выражения
условия выбора и простые логические выражения Testing. Testing types
Testing. Testing types Программные средства компьютерных информационных технологий
Программные средства компьютерных информационных технологий Создание автоматизированной информационной системы для больницы
Создание автоматизированной информационной системы для больницы Шаблон для выполнения задания. Отрасль авиапоставщиков
Шаблон для выполнения задания. Отрасль авиапоставщиков Establish Critical Limits for each CCP (Task 8 / Principle 3)
Establish Critical Limits for each CCP (Task 8 / Principle 3) ITS.ALPR.2. Интеллектуальная система распознавания автомобильных номеров
ITS.ALPR.2. Интеллектуальная система распознавания автомобильных номеров Проблемы виртуального общения
Проблемы виртуального общения Ежемесячная газета МБОУ Красноясыльская средняя общеобразовательная школа Школьная жизнь №5
Ежемесячная газета МБОУ Красноясыльская средняя общеобразовательная школа Школьная жизнь №5 Линейные методы классификации (метод стохастического градиента)
Линейные методы классификации (метод стохастического градиента) Выполнении вызова F(11)
Выполнении вызова F(11) NFT \ Non Fungible Token
NFT \ Non Fungible Token Гейм-дизайн. Знакомство с Construct 2
Гейм-дизайн. Знакомство с Construct 2