- Параллельное и многопоточное программирование. OpenMP. (Лекция 6)

Содержание
- 2. OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Дает
- 3. Интерфейс OpenMP задуман как стандарт параллельного программирования для многопроцессорных систем с общей памятью (SMP, ccNUMA, …)
- 4. Модель OpenMP мощный, но в тоже время компактный Стандарт de-facto для программирования систем с общей памятью
- 5. Быть стандартом для различных архитектур и платформ с распределенной памятью Дать простой, но ограниченный набор директив
- 6. BUS SMP системы
- 7. Все потоки имеют доступ к глобальной разделяемой памяти Данные могут быть разделяемые и приватные Разделяемые данные
- 8. Использование потоков (общее адресное пространство) Пульсирующий (“вилочный”, fork-join) параллелизм Обзор технологии OpenMP Принцип организации параллелизма Параллельные
- 9. Модель выполнения OpenMP
- 10. Модель выполнения OpenMP Здесь по умолчанию происходит синхронизация. Главная нить не выйдет, пока не сработают остальные.
- 11. Терминология OpenMP Team := Master + Workers Параллельный регион — блок кода, который всеми потоками исполняется
- 12. Ещё чуть терминологии Важные элементы OpenMP: Функции Директивы Клаузы
- 13. Параллелизация цикла с помощью OpenMP omp parallel shared(a,b) #pragma { #pragma omp for private(i) for(i=0; i
- 14. Функции Функции OpenMP носят скорее вспомогательный характер, так как реализация параллельности осуществляется за счет использования директив.
- 15. Директивы Конструкция #pragma в языке Си/Си++ используется для задания дополнительных указаний компилятору. С помощью этих конструкций
- 16. Директива omp Использование специальной ключевой директивы «omp» указывает на то, что команды относятся к OpenMP. Таким
- 17. Директива parallel Самой главной можно пожалуй назвать директиву parallel. Она создает параллельный регион для следующего за
- 18. Формат записи директив и клауз OpenMP #pragma omp имя_директивы [clause,…] #pragma omp parallel default(shared)private(beta,pi) Формат записи
- 19. Пример Чтобы продемонстрировать запуск нескольких потоков, распечатаем в распараллеливаемом блоке текст: #pragma omp parallel { printf(“OpenMP
- 20. Директива for Рассмотренный нами выше пример демонстрирует наличие параллельности, но сам по себе он бессмыслен. Теперь
- 21. Директива for Для того, чтобы распараллелить цикл нам необходимо использовать директиву разделения работы «for». Директива #pragma
- 22. Директива for Можно использовать сокращенную запись, комбинируя несколько директив в одну управляющую строку. Приведенный выше код
- 23. Некоторые функции OpenMP omp_get_thread_num(); - возвращает номер нити типом int. Вне параллельной секции всегда вернёт 0
- 24. Последовательный код void main(){ double x[1000]; for(i=0; i } } Параллельный код void main(){ double x[1000];
- 25. Условие reduction - Пример ● Пример: omp parallel #pragma { sum) private(i) shared(x, i #pragma for
- 27. Скачать презентацию

OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си,
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си,
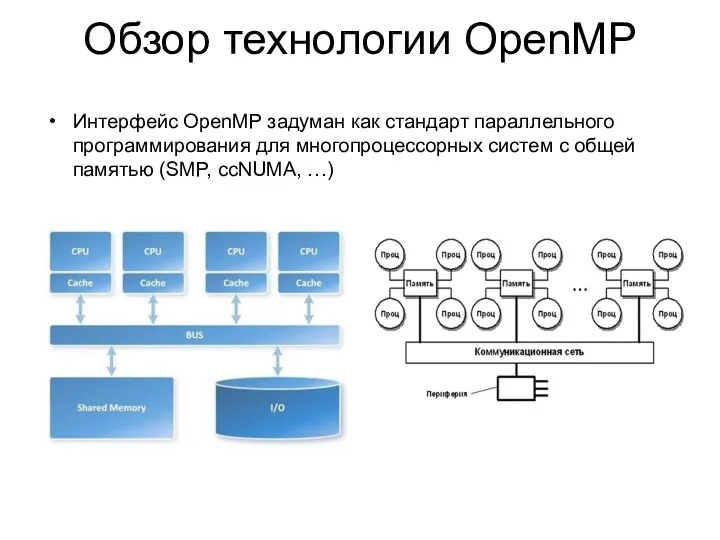
Интерфейс OpenMP задуман как стандарт параллельного программирования для многопроцессорных систем с
Интерфейс OpenMP задуман как стандарт параллельного программирования для многопроцессорных систем с

Модель OpenMP мощный, но в тоже время компактный
Стандарт de-facto для программирования систем
Модель OpenMP мощный, но в тоже время компактный
Стандарт de-facto для программирования систем

Быть стандартом для различных архитектур и платформ с распределенной памятью
Дать простой,
Быть стандартом для различных архитектур и платформ с распределенной памятью
Дать простой,
BUS
SMP системы
BUS
SMP системы
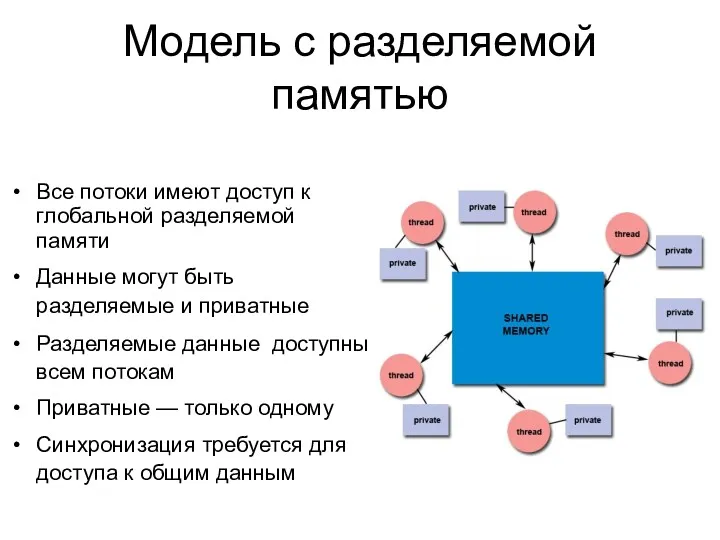
Все потоки имеют доступ к глобальной разделяемой памяти
Данные могут быть разделяемые
Все потоки имеют доступ к глобальной разделяемой памяти
Данные могут быть разделяемые
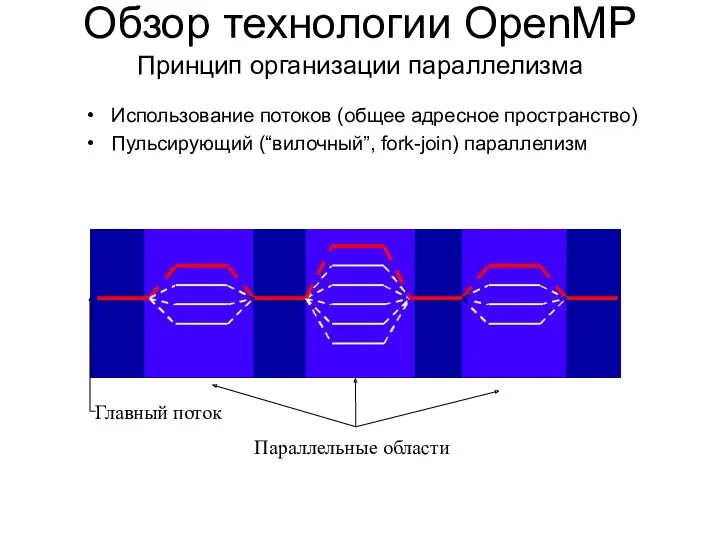
Использование потоков (общее адресное пространство)
Пульсирующий (“вилочный”, fork-join) параллелизм
Обзор технологии OpenMP
Принцип организации
Использование потоков (общее адресное пространство)
Пульсирующий (“вилочный”, fork-join) параллелизм
Обзор технологии OpenMP Принцип организации
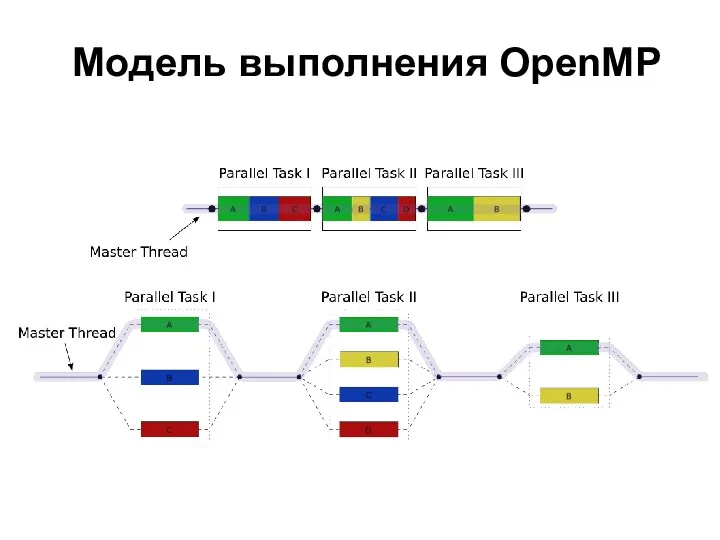
Модель выполнения OpenMP
Модель выполнения OpenMP
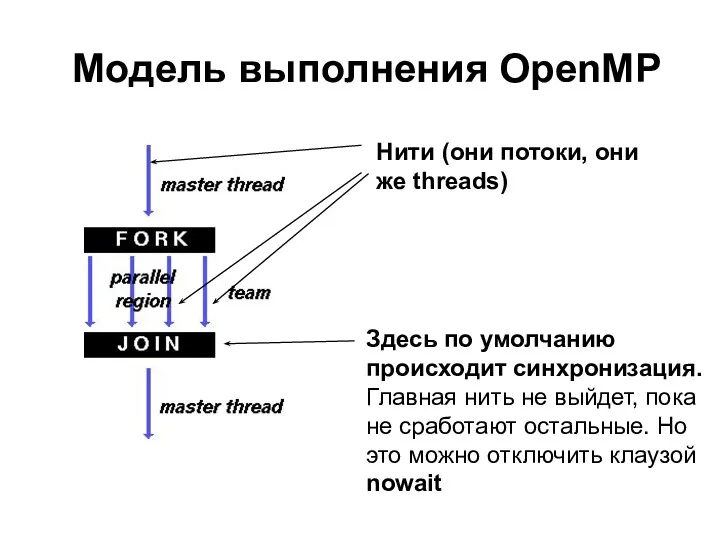
Модель выполнения OpenMP
Здесь по умолчанию происходит синхронизация. Главная нить не выйдет,
Модель выполнения OpenMP
Здесь по умолчанию происходит синхронизация. Главная нить не выйдет,

Терминология
OpenMP Team := Master + Workers
Параллельный регион — блок кода, который
Терминология
OpenMP Team := Master + Workers
Параллельный регион — блок кода, который

Ещё чуть терминологии
Важные элементы OpenMP:
Функции
Директивы
Клаузы
Ещё чуть терминологии
Важные элементы OpenMP:
Функции
Директивы
Клаузы
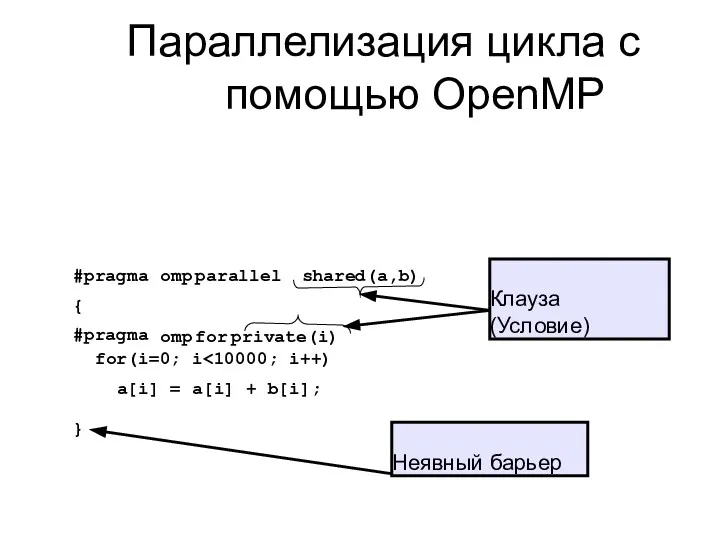
Параллелизация цикла с помощью OpenMP
omp parallel
shared(a,b)
#pragma
{
#pragma
omp for private(i)
for(i=0; i<10000; i++) a[i] = a[i] +
Параллелизация цикла с помощью OpenMP
omp parallel
shared(a,b)
#pragma
{
#pragma
omp for private(i)
for(i=0; i<10000; i++) a[i] = a[i] +

Функции
Функции OpenMP носят скорее вспомогательный характер, так как реализация параллельности осуществляется
Функции
Функции OpenMP носят скорее вспомогательный характер, так как реализация параллельности осуществляется

Директивы
Конструкция #pragma в языке Си/Си++ используется для задания дополнительных указаний компилятору.
Директивы
Конструкция #pragma в языке Си/Си++ используется для задания дополнительных указаний компилятору.

Директива omp
Использование специальной ключевой директивы «omp» указывает на то, что команды
Директива omp
Использование специальной ключевой директивы «omp» указывает на то, что команды

Директива parallel
Самой главной можно пожалуй назвать директиву parallel. Она создает параллельный
Директива parallel
Самой главной можно пожалуй назвать директиву parallel. Она создает параллельный
![Формат записи директив и клауз OpenMP #pragma omp имя_директивы [clause,…]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/267181/slide-17.jpg)
Формат записи директив и клауз OpenMP
#pragma omp имя_директивы [clause,…]
#pragma
Формат записи директив и клауз OpenMP
#pragma omp имя_директивы [clause,…]
#pragma

Пример
Чтобы продемонстрировать запуск нескольких потоков, распечатаем в распараллеливаемом блоке текст:
#pragma omp
Пример
Чтобы продемонстрировать запуск нескольких потоков, распечатаем в распараллеливаемом блоке текст:
#pragma omp

Директива for
Рассмотренный нами выше пример демонстрирует наличие параллельности, но сам по
Директива for
Рассмотренный нами выше пример демонстрирует наличие параллельности, но сам по

Директива for
Для того, чтобы распараллелить цикл нам необходимо использовать директиву разделения
Директива for
Для того, чтобы распараллелить цикл нам необходимо использовать директиву разделения

Директива for
Можно использовать сокращенную запись, комбинируя несколько директив в одну управляющую
Директива for
Можно использовать сокращенную запись, комбинируя несколько директив в одну управляющую

Некоторые функции OpenMP
omp_get_thread_num(); - возвращает номер нити типом int. Вне параллельной
Некоторые функции OpenMP
omp_get_thread_num(); - возвращает номер нити типом int. Вне параллельной
![Последовательный код void main(){ double x[1000]; for(i=0; i } }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/267181/slide-23.jpg)
Последовательный код
void main(){ double x[1000];
for(i=0; i<1000; i++){ calc_smth(&x[i]);
}
}
Параллельный код
void main(){ double
void main(){ double x[1000];
for(i=0; i<1000; i++){ calc_smth(&x[i]);
}
}
Параллельный код
void main(){ double

Условие reduction - Пример
●
Пример:
omp parallel
#pragma
{
sum) private(i)
shared(x, i<10000; i++)
#pragma for for(i=0;
sum =
sum + x[i];
●
●
}
Нужна осторожность при
Условие reduction - Пример
●
Пример:
omp parallel
#pragma
{
sum) private(i)
shared(x, i<10000; i++)
#pragma for for(i=0;
sum =
sum + x[i];
●
●
}
Нужна осторожность при
 Инструкция по доступу к онлайн курсам на сайте
Инструкция по доступу к онлайн курсам на сайте Системы программного управления промышленными установками
Системы программного управления промышленными установками SOHO TPNA 3 Диапазон наполнитель
SOHO TPNA 3 Диапазон наполнитель Department day
Department day Проектирование интерфейса оконного приложения с использованием элементов управления
Проектирование интерфейса оконного приложения с использованием элементов управления Моделирование как метод познания3
Моделирование как метод познания3 Лекция№7. Хранение данных в Android-приложениях
Лекция№7. Хранение данных в Android-приложениях Программирование на Python. Урок 14. Групповая разработка. Создание классов. Автомобили
Программирование на Python. Урок 14. Групповая разработка. Создание классов. Автомобили Центры обработки данных (ЦОД)
Центры обработки данных (ЦОД) Информационное общество. Теория и реальность
Информационное общество. Теория и реальность Символьные данные и строки. Лекция 15а-15б
Символьные данные и строки. Лекция 15а-15б Объединение компьютеров в локальную компьютерную сеть. Организация работы пользователей в локальных компьютерных сетях
Объединение компьютеров в локальную компьютерную сеть. Организация работы пользователей в локальных компьютерных сетях Human–computer interaction
Human–computer interaction Ты, я и информатика. Викторина. 7 класс
Ты, я и информатика. Викторина. 7 класс Медиапаспорт международного женского журнала Cosmopolitan
Медиапаспорт международного женского журнала Cosmopolitan Типы данных в языке С, которые может создать пользователь
Типы данных в языке С, которые может создать пользователь Информатика. Введение и общие положения
Информатика. Введение и общие положения Средства представления и записи алгоритмов. Блок-схемы. Виды алгоритмических структур. Линейный алгоритм
Средства представления и записи алгоритмов. Блок-схемы. Виды алгоритмических структур. Линейный алгоритм Поиск простых чисел. PascalABC, FreePascal
Поиск простых чисел. PascalABC, FreePascal Логикалық функциялар
Логикалық функциялар Вычислительные машины, системы и сети. Лекция 8. Тема 11. Выбор конфигурации компьютера
Вычислительные машины, системы и сети. Лекция 8. Тема 11. Выбор конфигурации компьютера Контент-план от Дамира Халилова
Контент-план от Дамира Халилова Компьютер обретает разум. Исторический журнал
Компьютер обретает разум. Исторический журнал Как GC освобождает память
Как GC освобождает память Перевод чисел в различные системы счисления
Перевод чисел в различные системы счисления Нейронные сети. Лекция 3+
Нейронные сети. Лекция 3+ Основы информационной безопасности. Организационные меры обеспечения ИБ. (Тема 2)
Основы информационной безопасности. Организационные меры обеспечения ИБ. (Тема 2) Информатика 10 класс тема Информация, информационные процессы и измерение информации
Информатика 10 класс тема Информация, информационные процессы и измерение информации