- Параллельное программирование

Содержание
- 2. Задачи курса Параллельное программирование – путь к созданию приложений, направленных на обработку больших объемов данных Применение
- 3. Структура курса 1 Схемы параллельных взаимодействующих процессов. Моделирование с и анализ взаимодействующих процессов 2 Эффективные вычислительные
- 4. Зачем нам нужно параллельное программирование? Моделирование образования белка: нужно 10**25 операций, что займет на одноядерном ПК
- 5. Зачем нам нужно параллельное программирование? Моделирование образования белка: нужно 10**25 операций, что займет на одноядерном ПК
- 6. Зачем нам нужно параллельное программирование? Моделирование образования белка: нужно 10**25 операций, что займет на одноядерном ПК
- 7. Зачем нам нужно параллельное программирование? Дейкстра : „To put it quite bluntly: as long as there
- 8. Схемы взаимодействующих процессов -
- 9. Процесс 1, 4 - выполняет взаимодействие 2, 3 – входы (принимает взаимодействие) 3 – простой вход
- 10. Процесс 1, 3 - по некоторым причинам процесс может не выполнять взаимодействие
- 11. Процесс Процесс X, начав ожидание по входу 3 и не дождавшись его , через некоторое время
- 12. Процесс Процесс Y, начав вызов 1 и не дождавшись приема взаимодействия, через некоторое время прекращает ожидание
- 13. пример Посетитель: 1 -дал официанту заказ 2 – ждет еду Повар : 1 – ждет заказ
- 14. Пример зависания системы Посетитель: 2 – ждет еду, не дождавшись идет к повару (3) Повар :
- 15. Диаграмма последовательности – линии жизни
- 16. Диаграмма состояний Синтаксис состояния = название + деятельность Синтаксис дуги = событие [условие] / действие.
- 17. Плавательные дорожки
- 18. Эффективные алгоритмы параллельного программирования -
- 19. Закон Амдала T - время работы программы при однопоточном выполнении P - часть кода осталась последовательной
- 20. Проблемы параллельного программирования Хотя основная трудоёмкость жизненного цикла программ связана с тестированием и отладкой программ, это
- 21. Проблемы при параллельном выполнении Выделение порций работ, которые могут быть выполнены параллельно Гонки данных Взаимная блокировка
- 22. Синхронизация и обмен данными Синхронизация — это процесс, при помощи которого два или более программных потока
- 23. Мертвая блокировка (Deadlock) Мертвая блокировка происходит тогда, когда поток заблокирован в ожидании ресурса другого потока, который
- 24. Балансировка и масштабируемость Балансировка нагрузки — распределение работы между несколькими программными потоками так, чтобы все они
- 25. Пример гонки данных int i = 0; // переменная, видимая из двух потоков //код в теле
- 26. Пример гонки данных
- 27. Уровни распараллеливания Распараллелить решение задачи можно на нескольких уровнях. Классификация методов деления достаточна условна и служит
- 28. Классификация методов распараллеливания алгоритмов
- 29. (1)Распараллеливание на уровне задач Независимость решаемых подзадач (параллельно работают : обработка файлов, компиляция в VS, paint…)
- 30. (2) Распараллеливание на уровне передачи сообщений Приложение состоит из набора процессов с различными адресными пространствами, каждый
- 31. Пример: Островная модель генетического алгоритма Исходная популяция делится на несколько частей, каждая из которых развивается обособленно
- 32. Островная модель генетического алгоритма Островная модель не просто предоставляет способ распараллеливания вычислений, но и имеет преимущество
- 33. Зернистость при реализации системы на уровне передачи сообщений Зернистость – это мера отношения количества вычислений, сделанных
- 34. (3) Распараллеливание на уровне разделяемой памяти Приложение состоит из набора нитей исполнения, использующих разделяемые переменные и
- 35. (4) Распараллеливание на уровне данных (декомпозиция по данным) Применение одной и той же операции к элементу
- 36. (4a) Частный случай распараллеливания по данным – геометрический параллелизм 1- необходимо передавать данные получаемые на границах
- 37. (5) Распараллеливание на уровне алгоритмов (функциональная декомпозиция) Распараллеливание отдельных процедур и алгоритмов ( примеры: алгоритмы параллельной
- 38. (5) Рапараллеливание по операциям Поиск минимального элемента в массиве – разбиение задачи по операциям, сложность O(1).
- 39. (7) Параллелизм на уровне инструкций Осуществляется на уровне параллельной обработки процессором нескольких инструкций (конвейеры команд, предсказание
- 40. Параллельные алгоритмы и их анализ Dependency Graphs – граф зависимостей Mapping – отображение графа зависимостей на
- 41. Анализ распараллеливания алгоритма на зависимости между данными по операциям Вершины графа зависимости – фрагмент вычислений Ребра
- 42. Декомпозиция по данным Умножение матрицы на вектор – декомпозиция на N задач, где N – число
- 43. Пример декомпозиции по данным: Блочно независимые вычисления Пример – анализ зависимости операндов и построение бинарного дерева
- 44. Ленточный алгоритм умножения матриц O(2N^3/p) В процессе вычислений i-ый процессор умножает i- ый горизонтальный блок на
- 45. Метод сдваивания (задача свертки – reduce problem) Найти произведение a1*a2*…*a8 Уровень 0 a1 a2 a3 a4
- 46. Метод сдваивания (задача свертки – reduce problem)
- 47. Чет - нечетная сортировка Шаг 1 –сортировка a[i] и a[i+1] Шаг 2 –сортировка a[i+1] и a[i+2]
- 48. Чет - нечетная сортировка
- 49. Обработка списков за log2N (пример – найти свой номер от конца) Подготовка: myNumber = 1; Шаг
- 50. Обработку списков за log2N модифицируем для массивов (задача сканирования - Scan) Считаем A [i] – сумма
- 51. Обработка деревьев как списков
- 52. Обработка деревьев как списков за log2N Преобразуем дерево в список длины 3*N Обрабатываем список за O(log2(N*(3*N))
- 53. Обработка деревьев как списков за log2N dataA = +1 dataB = 0 dataC = -1 Глубина
- 54. Задачи на графах – минимальное остовное дерево (алгоритм Прима – последовательная реализация) 1- выбирается произвольный начальный
- 55. Задачи на графах – минимальное остовное дерево (алгоритм Прима – параллельная реализация) 1- выбирается произвольный начальный
- 56. Задачи на графах – минимальное остовное дерево (алгоритм Прима) Красный – остов, зеленый – кайма, желтый
- 57. Задачи на графах – поиск кратчайшего пути 1 – строится матрица D[N][N] связности графа 2 –
- 58. Параллельный алгоритм вычисления рекурсии Реализация рекурсии – каскадные алгоритмы. Пример – вычисление суммы S[i] = S[i-2
- 59. Проблемы компьютерного зрения Сегментация изображений – выделение областей, представляющие собой целые объекты или их крупные элементы
- 60. Потоки : создание и барьеры .
- 61. Создание потока static HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpsa, //параметры защиты // NULL – атрибуты защиты по умолчанию
- 62. Пример – описание тела потока struct Param{int start, fin, indexResult;}; // передаваемые потоку параметры int data[MAXN];
- 63. Пример – создание двух потоков int main (){ HANDLE threadFirst, threadSecond; DWORD dwNetThreadIdFirst, dwNetThreadIdSecond; int len=MAXN;
- 64. Барьер Барьер - метод синхронизации, при помощи которого потоки из одного набора поддерживают взаимодействие. При помощи
- 65. Барьер WaitForMultipleObjects(k, threadProducer, true, INFINITE); //ждем завершения всех потоков в //массиве threadProducer, Или for(inti=0; i WaitForSingleObjects(threadProducer
- 66. Параллельное программирование в Visual Studio 2017 (Библиотека параллельных шаблонов PPL)
- 67. Возможности PPL Предоставляет универсальные безопасные алгоритмы и контейнеры, работающие параллельно: Параллелизм задач: работает поверх ThreadPool для
- 68. Параллельные алгоритмы Алгоритм parallel_for Алгоритм parallel_for_each Алгоритм parallel_invoke Алгоритмы parallel_transform и parallel_reduce Алгоритм parallel_transform Алгоритм parallel_reduce
- 69. Лабораторная работа 2 «Параллельные вычислительные алгоритмы» Написать программу для последовательного алгоритма Вычислить теоретическую временную сложность последовательного
- 70. Литература по дисциплине Эхтер Ш., Робертс Дж. Многоядерное программирование. – СПб.: Питер. 2010 Рихтер Дж. Widows
- 72. Скачать презентацию

Задачи курса
Параллельное программирование – путь к созданию приложений, направленных на обработку
Задачи курса
Параллельное программирование – путь к созданию приложений, направленных на обработку

Структура курса
1 Схемы параллельных взаимодействующих процессов. Моделирование с и анализ взаимодействующих
Структура курса
1 Схемы параллельных взаимодействующих процессов. Моделирование с и анализ взаимодействующих

Зачем нам нужно параллельное программирование?
Моделирование образования белка: нужно 10**25 операций, что
Зачем нам нужно параллельное программирование?
Моделирование образования белка: нужно 10**25 операций, что

Зачем нам нужно параллельное программирование?
Моделирование образования белка: нужно 10**25 операций, что
Зачем нам нужно параллельное программирование?
Моделирование образования белка: нужно 10**25 операций, что

Зачем нам нужно параллельное программирование?
Моделирование образования белка: нужно 10**25 операций, что
Зачем нам нужно параллельное программирование?
Моделирование образования белка: нужно 10**25 операций, что

Зачем нам нужно параллельное программирование?
Дейкстра :
„To put it quite bluntly:
Зачем нам нужно параллельное программирование?
Дейкстра :
„To put it quite bluntly:

Схемы взаимодействующих процессов
-
Схемы взаимодействующих процессов
-
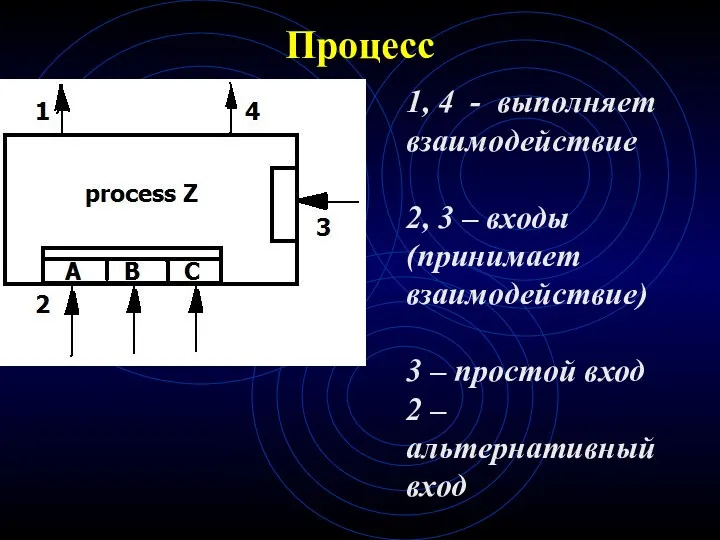
Процесс
1, 4 - выполняет взаимодействие
2, 3 – входы (принимает взаимодействие)
3 –
Процесс
1, 4 - выполняет взаимодействие
2, 3 – входы (принимает взаимодействие)
3 –
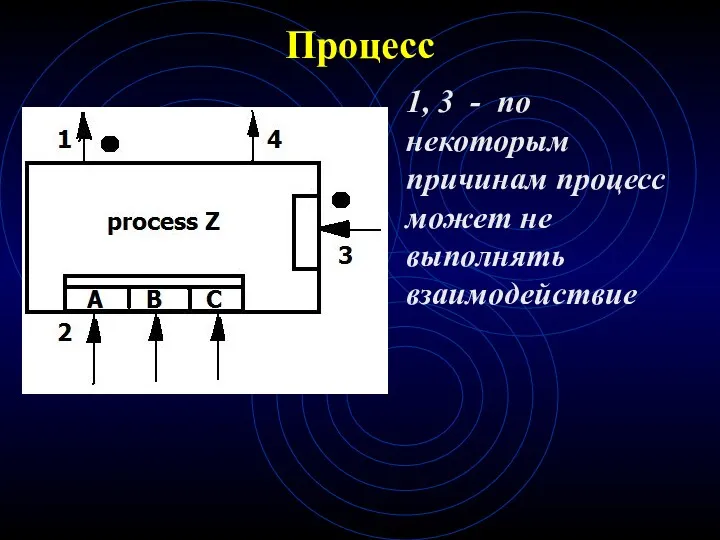
Процесс
1, 3 - по некоторым причинам процесс может не выполнять взаимодействие
Процесс
1, 3 - по некоторым причинам процесс может не выполнять взаимодействие
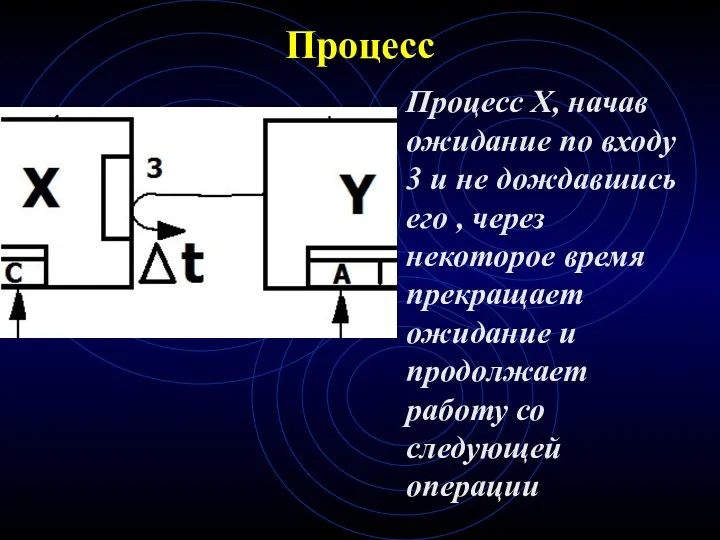
Процесс
Процесс X, начав ожидание по входу 3 и не дождавшись его
Процесс
Процесс X, начав ожидание по входу 3 и не дождавшись его
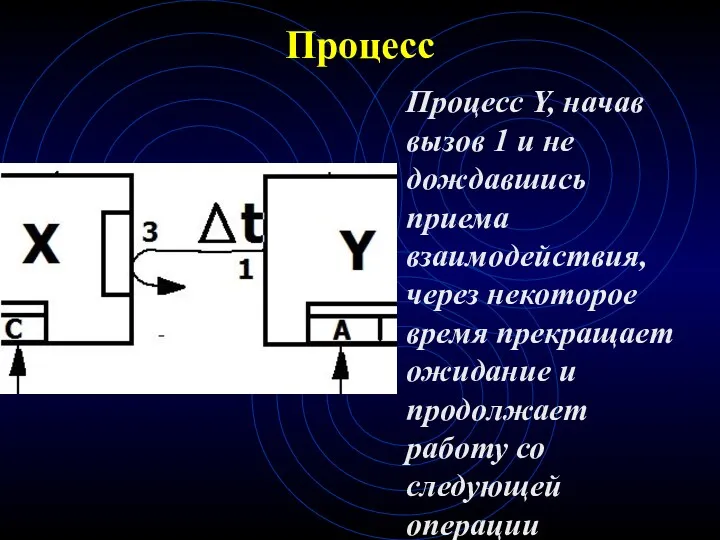
Процесс
Процесс Y, начав вызов 1 и не дождавшись приема взаимодействия, через
Процесс
Процесс Y, начав вызов 1 и не дождавшись приема взаимодействия, через
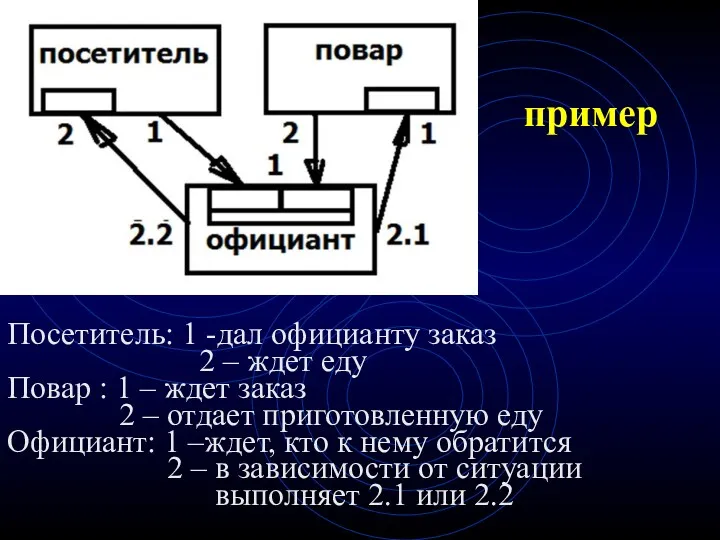
пример
Посетитель: 1 -дал официанту заказ
2 – ждет еду
Повар : 1
пример
Посетитель: 1 -дал официанту заказ
2 – ждет еду
Повар : 1
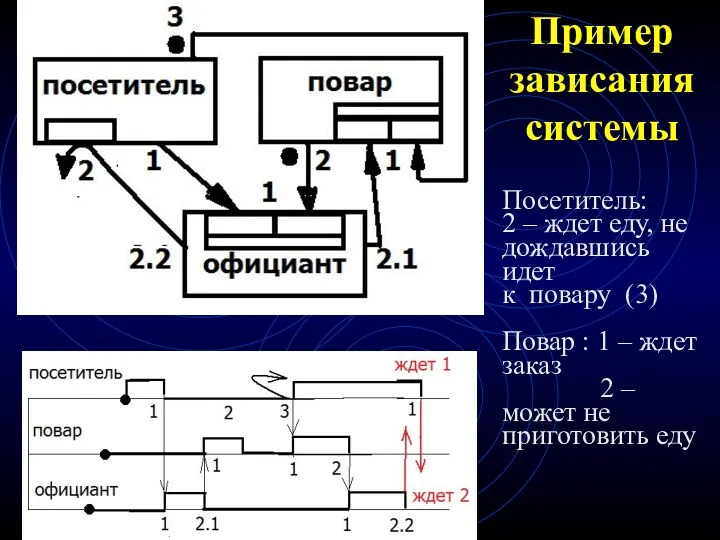
Пример зависания системы
Посетитель:
2 – ждет еду, не дождавшись идет к
Пример зависания системы
Посетитель:
2 – ждет еду, не дождавшись идет к
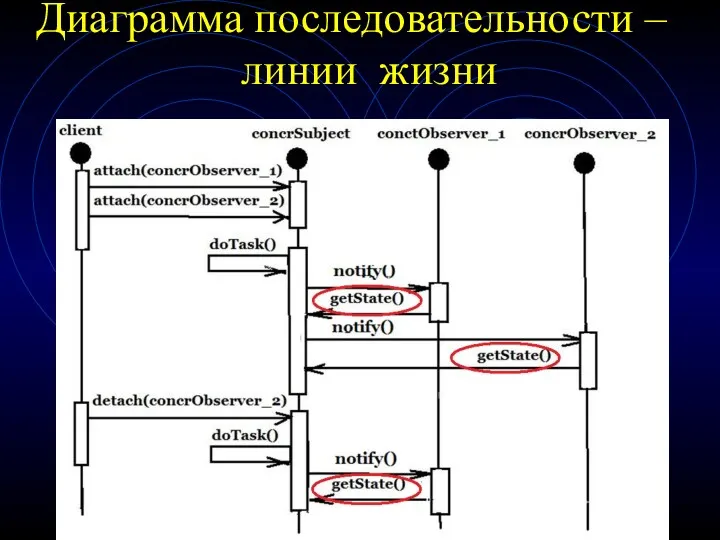
Диаграмма последовательности – линии жизни
Диаграмма последовательности – линии жизни
![Диаграмма состояний Синтаксис состояния = название + деятельность Синтаксис дуги = событие [условие] / действие.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/212814/slide-15.jpg)
Диаграмма состояний
Синтаксис состояния = название + деятельность
Синтаксис дуги =
Диаграмма состояний
Синтаксис состояния = название + деятельность
Синтаксис дуги =
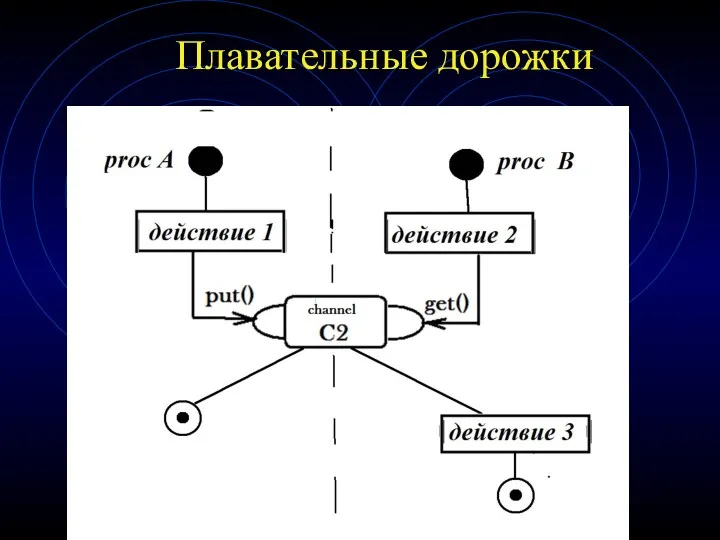
Плавательные дорожки
Плавательные дорожки

Эффективные алгоритмы параллельного программирования
-
Эффективные алгоритмы параллельного программирования
-
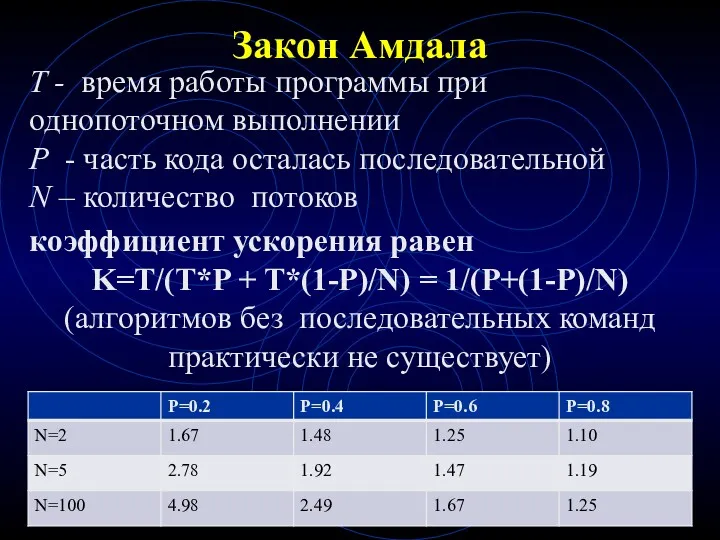
Закон Амдала
T - время работы программы при однопоточном выполнении
P - часть
Закон Амдала
T - время работы программы при однопоточном выполнении
P - часть

Проблемы параллельного программирования
Хотя основная трудоёмкость жизненного цикла программ связана с тестированием
Проблемы параллельного программирования
Хотя основная трудоёмкость жизненного цикла программ связана с тестированием

Проблемы при параллельном выполнении
Выделение порций работ, которые могут быть выполнены
Проблемы при параллельном выполнении
Выделение порций работ, которые могут быть выполнены

Синхронизация и обмен данными
Синхронизация — это процесс, при помощи которого
Синхронизация и обмен данными
Синхронизация — это процесс, при помощи которого

Мертвая блокировка (Deadlock)
Мертвая блокировка происходит тогда, когда поток заблокирован в ожидании
Мертвая блокировка (Deadlock)
Мертвая блокировка происходит тогда, когда поток заблокирован в ожидании

Балансировка и масштабируемость
Балансировка нагрузки — распределение работы между несколькими программными потоками
Балансировка и масштабируемость
Балансировка нагрузки — распределение работы между несколькими программными потоками

Пример гонки данных
int i = 0; // переменная, видимая из двух
Пример гонки данных
int i = 0; // переменная, видимая из двух
Пример гонки данных
Пример гонки данных

Уровни распараллеливания
Распараллелить решение задачи можно на нескольких уровнях.
Классификация методов деления
Уровни распараллеливания
Распараллелить решение задачи можно на нескольких уровнях.
Классификация методов деления

Классификация методов распараллеливания алгоритмов
Классификация методов распараллеливания алгоритмов
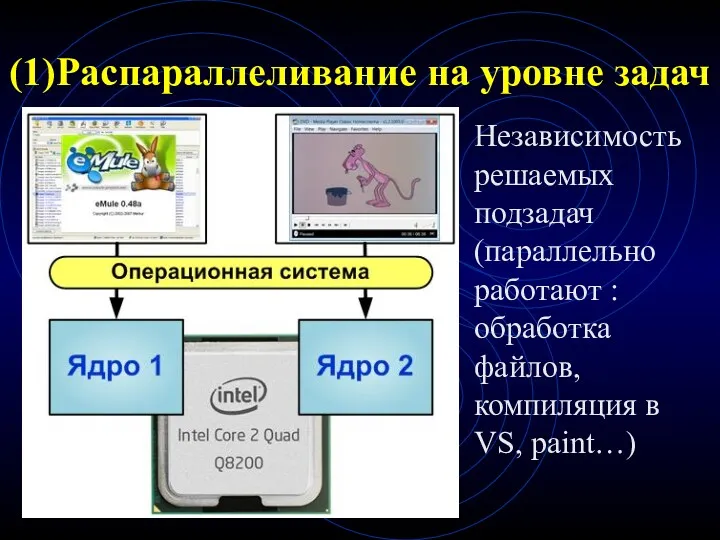
(1)Распараллеливание на уровне задач
Независимость решаемых подзадач (параллельно работают : обработка файлов,
(1)Распараллеливание на уровне задач
Независимость решаемых подзадач (параллельно работают : обработка файлов,
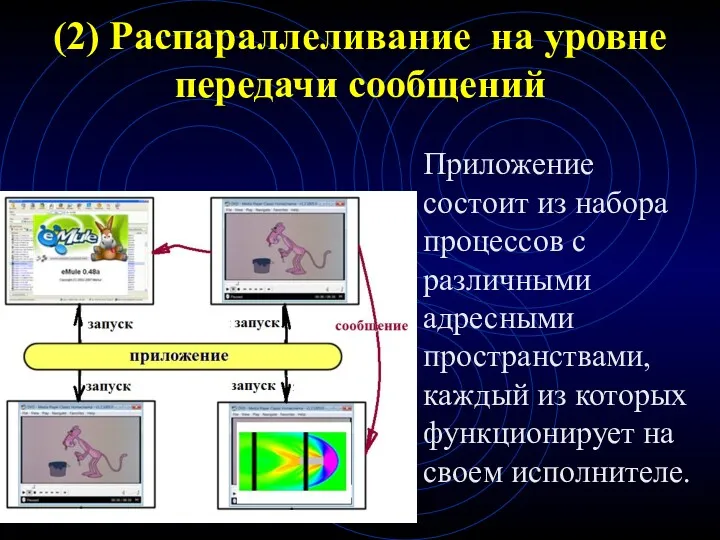
(2) Распараллеливание на уровне передачи сообщений
Приложение состоит из набора процессов с
(2) Распараллеливание на уровне передачи сообщений
Приложение состоит из набора процессов с
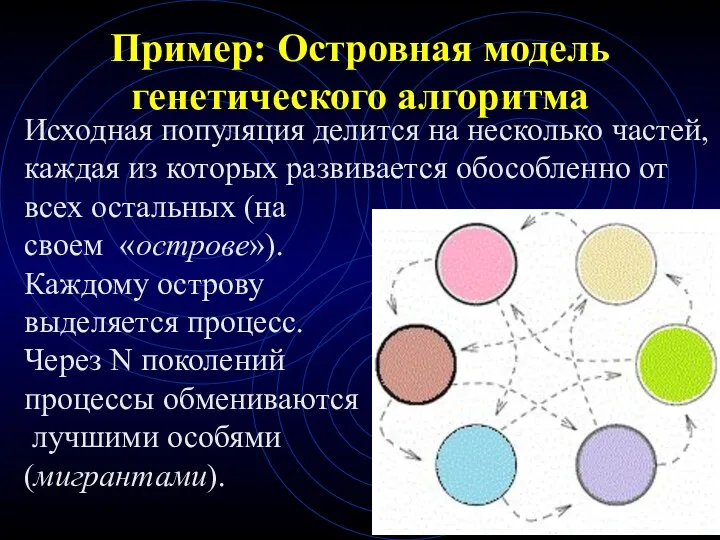
Пример: Островная модель генетического алгоритма
Исходная популяция делится на несколько частей, каждая
Пример: Островная модель генетического алгоритма
Исходная популяция делится на несколько частей, каждая

Островная модель генетического алгоритма
Островная модель не просто предоставляет способ распараллеливания вычислений,
Островная модель генетического алгоритма
Островная модель не просто предоставляет способ распараллеливания вычислений,

Зернистость при реализации системы на уровне передачи сообщений
Зернистость – это
Зернистость при реализации системы на уровне передачи сообщений
Зернистость – это

(3) Распараллеливание на уровне разделяемой памяти
Приложение состоит из набора нитей исполнения,
(3) Распараллеливание на уровне разделяемой памяти
Приложение состоит из набора нитей исполнения,

(4) Распараллеливание на уровне данных (декомпозиция по данным)
Применение одной и
(4) Распараллеливание на уровне данных (декомпозиция по данным)
Применение одной и

(4a) Частный случай распараллеливания по данным – геометрический параллелизм
1- необходимо передавать
(4a) Частный случай распараллеливания по данным – геометрический параллелизм
1- необходимо передавать
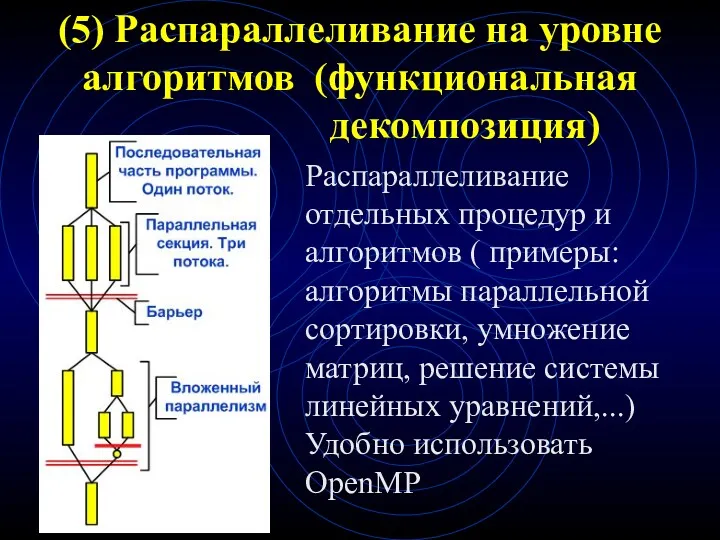
(5) Распараллеливание на уровне алгоритмов (функциональная декомпозиция)
Распараллеливание отдельных процедур и алгоритмов
(5) Распараллеливание на уровне алгоритмов (функциональная декомпозиция)
Распараллеливание отдельных процедур и алгоритмов
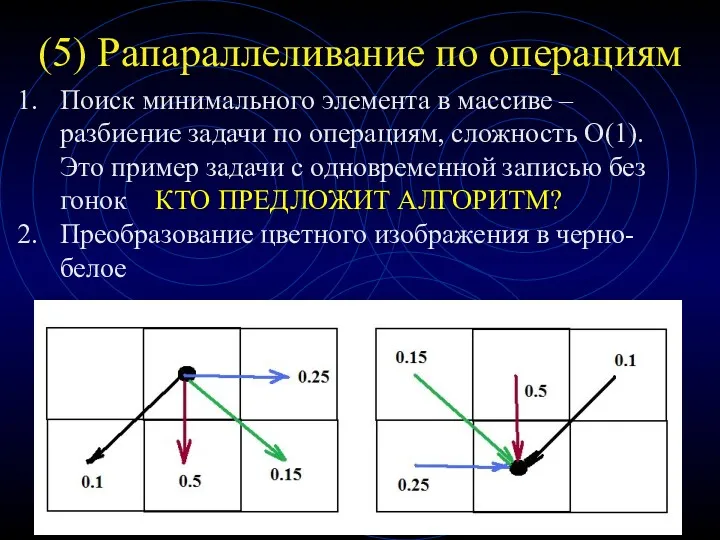
(5) Рапараллеливание по операциям
Поиск минимального элемента в массиве – разбиение задачи
(5) Рапараллеливание по операциям
Поиск минимального элемента в массиве – разбиение задачи

(7) Параллелизм на уровне инструкций
Осуществляется на уровне параллельной обработки процессором нескольких
(7) Параллелизм на уровне инструкций
Осуществляется на уровне параллельной обработки процессором нескольких
Параллельные алгоритмы и их анализ
Dependency Graphs – граф зависимостей
Mapping – отображение
Параллельные алгоритмы и их анализ Dependency Graphs – граф зависимостей Mapping – отображение
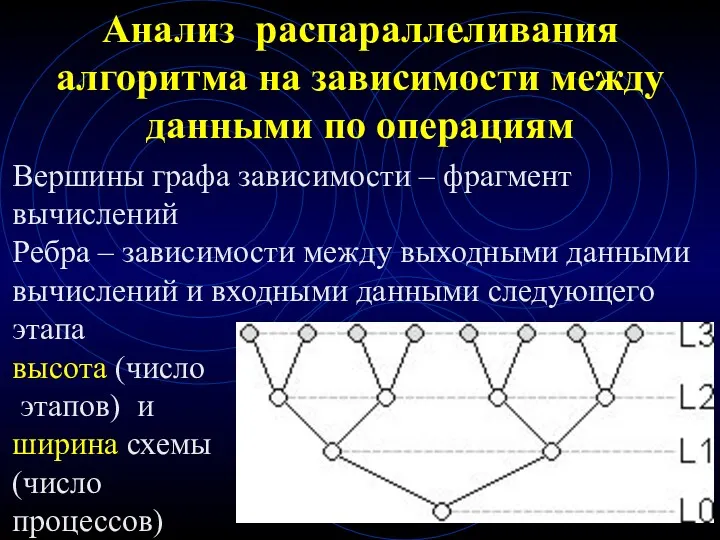
Анализ распараллеливания алгоритма на зависимости между данными по операциям
Вершины графа зависимости
Анализ распараллеливания алгоритма на зависимости между данными по операциям
Вершины графа зависимости

Декомпозиция по данным
Умножение матрицы на вектор – декомпозиция на N задач,
Декомпозиция по данным
Умножение матрицы на вектор – декомпозиция на N задач,
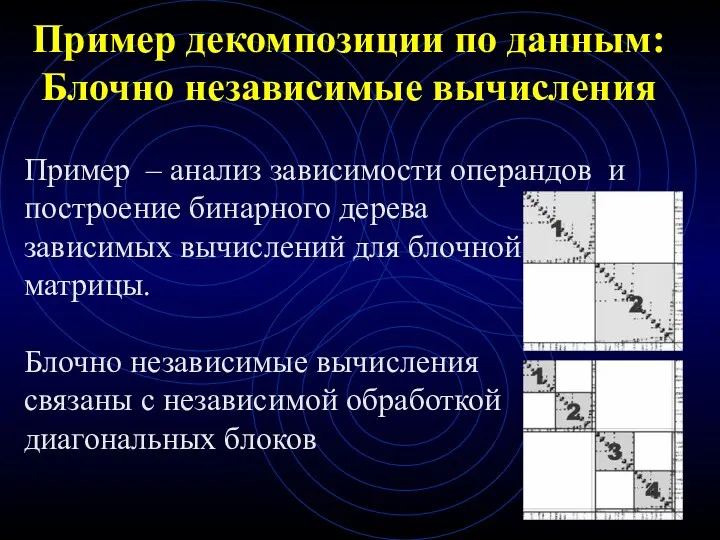
Пример декомпозиции по данным: Блочно независимые вычисления
Пример – анализ зависимости операндов
Пример декомпозиции по данным: Блочно независимые вычисления
Пример – анализ зависимости операндов

Ленточный алгоритм умножения матриц O(2N^3/p)
В процессе вычислений i-ый процессор умножает i-
Ленточный алгоритм умножения матриц O(2N^3/p)
В процессе вычислений i-ый процессор умножает i-

Метод сдваивания
(задача свертки – reduce problem)
Найти произведение a1*a2*…*a8
Уровень
0 a1 a2
Метод сдваивания
(задача свертки – reduce problem)
Найти произведение a1*a2*…*a8
Уровень
0 a1 a2
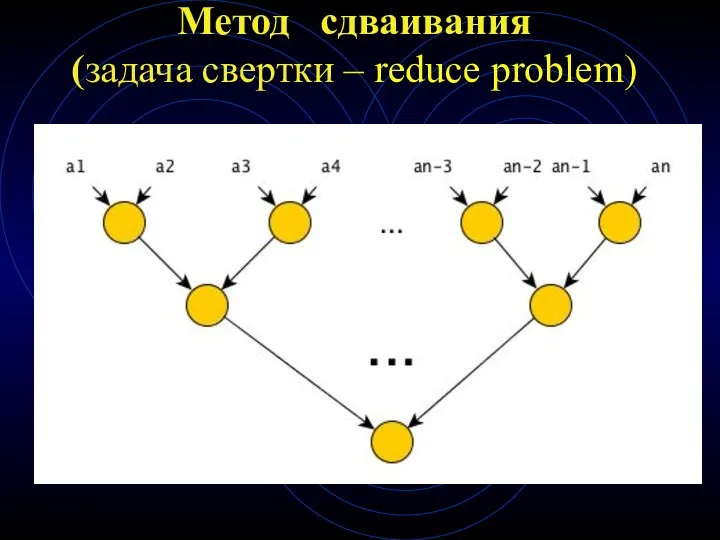
Метод сдваивания
(задача свертки – reduce problem)
Метод сдваивания
(задача свертки – reduce problem)
![Чет - нечетная сортировка Шаг 1 –сортировка a[i] и a[i+1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/212814/slide-46.jpg)
Чет - нечетная сортировка
Шаг 1 –сортировка a[i] и a[i+1]
Шаг 2 –сортировка
Чет - нечетная сортировка
Шаг 1 –сортировка a[i] и a[i+1]
Шаг 2 –сортировка

Чет - нечетная сортировка
Чет - нечетная сортировка

Обработка списков за log2N
(пример – найти свой номер от конца)
Подготовка: myNumber
Обработка списков за log2N
(пример – найти свой номер от конца)
Подготовка: myNumber
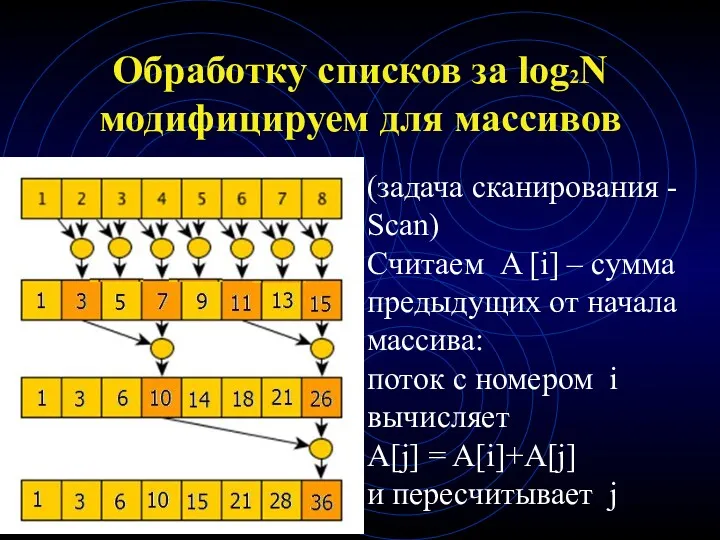
Обработку списков за log2N
модифицируем для массивов
(задача сканирования - Scan)
Считаем A
Обработку списков за log2N
модифицируем для массивов
(задача сканирования - Scan)
Считаем A
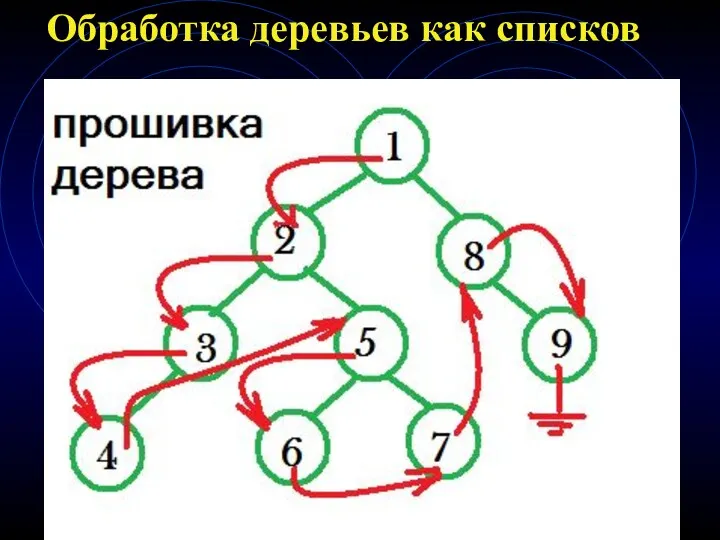
Обработка деревьев как списков
Обработка деревьев как списков

Обработка деревьев как списков за log2N
Преобразуем дерево в список
длины 3*N
Обрабатываем
Обработка деревьев как списков за log2N
Преобразуем дерево в список
длины 3*N
Обрабатываем
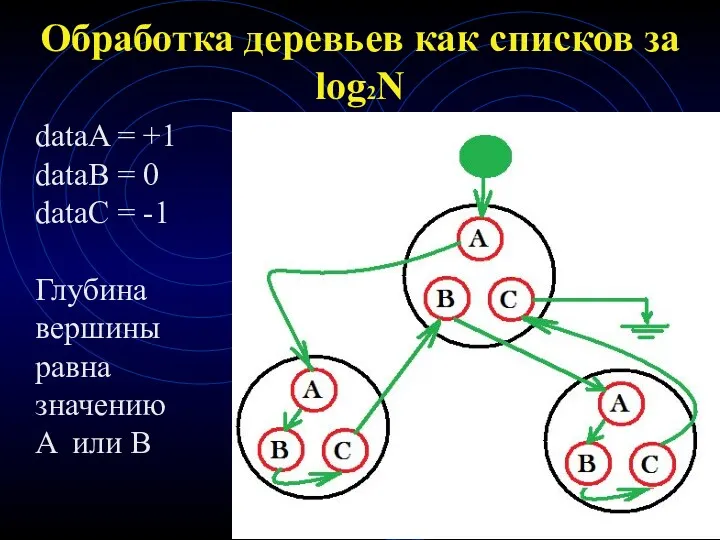
Обработка деревьев как списков за log2N
dataA = +1
dataB = 0
dataC =
Обработка деревьев как списков за log2N
dataA = +1
dataB = 0
dataC =

Задачи на графах – минимальное остовное дерево
(алгоритм Прима – последовательная
Задачи на графах – минимальное остовное дерево (алгоритм Прима – последовательная

Задачи на графах – минимальное остовное дерево (алгоритм Прима – параллельная
Задачи на графах – минимальное остовное дерево (алгоритм Прима – параллельная
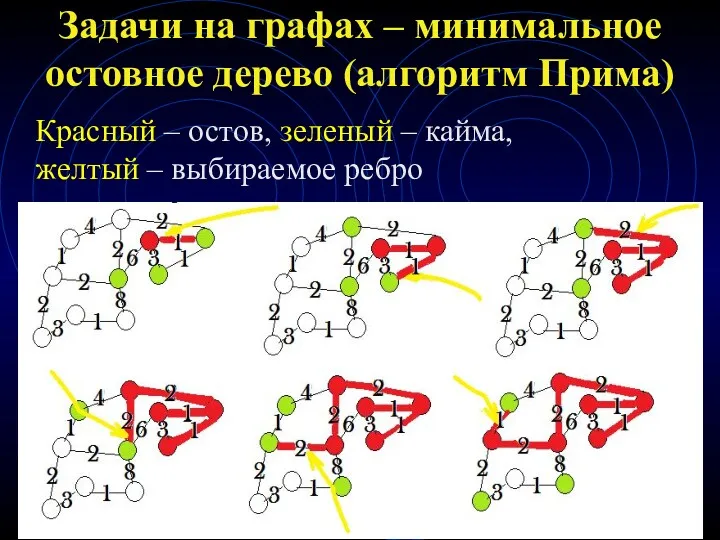
Задачи на графах – минимальное остовное дерево (алгоритм Прима)
Красный –
Задачи на графах – минимальное остовное дерево (алгоритм Прима)
Красный –

Задачи на графах – поиск кратчайшего пути
1 – строится матрица D[N][N]
Задачи на графах – поиск кратчайшего пути
1 – строится матрица D[N][N]

Параллельный алгоритм вычисления рекурсии
Реализация рекурсии – каскадные алгоритмы. Пример – вычисление
Параллельный алгоритм вычисления рекурсии
Реализация рекурсии – каскадные алгоритмы. Пример – вычисление

Проблемы компьютерного зрения
Сегментация изображений – выделение областей, представляющие собой целые объекты
Проблемы компьютерного зрения
Сегментация изображений – выделение областей, представляющие собой целые объекты

Потоки :
создание и барьеры
.
Потоки :
создание и барьеры
.

Создание потока
static HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpsa,
//параметры защиты
// NULL
Создание потока
static HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpsa,
//параметры защиты
// NULL

Пример – описание тела потока
struct Param{int start, fin, indexResult;};
Пример – описание тела потока
struct Param{int start, fin, indexResult;};

Пример – создание двух потоков
int main (){
HANDLE threadFirst, threadSecond;
DWORD dwNetThreadIdFirst, dwNetThreadIdSecond;
int
Пример – создание двух потоков
int main (){
HANDLE threadFirst, threadSecond;
DWORD dwNetThreadIdFirst, dwNetThreadIdSecond;
int

Барьер
Барьер - метод синхронизации, при помощи которого потоки из одного набора
Барьер
Барьер - метод синхронизации, при помощи которого потоки из одного набора

Барьер
WaitForMultipleObjects(k, threadProducer, true, INFINITE);
//ждем завершения всех потоков в
Барьер
WaitForMultipleObjects(k, threadProducer, true, INFINITE);
//ждем завершения всех потоков в

Параллельное программирование
в Visual Studio 2017
(Библиотека параллельных шаблонов PPL)
Параллельное программирование
в Visual Studio 2017
(Библиотека параллельных шаблонов PPL)

Возможности PPL
Предоставляет универсальные безопасные алгоритмы и контейнеры, работающие параллельно:
Параллелизм задач:
Возможности PPL
Предоставляет универсальные безопасные алгоритмы и контейнеры, работающие параллельно:
Параллелизм задач:

Параллельные алгоритмы
Алгоритм parallel_for
Алгоритм parallel_for_each
Алгоритм parallel_invoke
Алгоритмы parallel_transform и parallel_reduce
Алгоритм parallel_transform
Алгоритм parallel_reduce
Секции
Параллельная Сортировка
Параллельные алгоритмы
Алгоритм parallel_for
Алгоритм parallel_for_each
Алгоритм parallel_invoke
Алгоритмы parallel_transform и parallel_reduce
Алгоритм parallel_transform
Алгоритм parallel_reduce
Секции
Параллельная Сортировка

Лабораторная работа 2
«Параллельные вычислительные алгоритмы»
Написать программу для последовательного алгоритма
Вычислить теоретическую временную
Лабораторная работа 2
«Параллельные вычислительные алгоритмы»
Написать программу для последовательного алгоритма
Вычислить теоретическую временную

Литература по дисциплине
Эхтер Ш., Робертс Дж. Многоядерное программирование. – СПб.: Питер.
Литература по дисциплине
Эхтер Ш., Робертс Дж. Многоядерное программирование. – СПб.: Питер.
 Математические и логические основы информатики. Системы счисления
Математические и логические основы информатики. Системы счисления Функциональные зависимости в реляционной модели данных. Декомпозиция. Нормальные формы
Функциональные зависимости в реляционной модели данных. Декомпозиция. Нормальные формы Основы защиты информации. Тема 7
Основы защиты информации. Тема 7 Исполнители алгоритмов. Формальное исполнение алгоритмов
Исполнители алгоритмов. Формальное исполнение алгоритмов Основы мобильной грамотности и безопасности
Основы мобильной грамотности и безопасности Настройка службы DHCP SERVER
Настройка службы DHCP SERVER Ведомости. Деловая газета
Ведомости. Деловая газета Программирование на языке Паскаль Циклы
Программирование на языке Паскаль Циклы Информационные технологии перевернувшие нашу жизнь
Информационные технологии перевернувшие нашу жизнь Язык PHP
Язык PHP Подготовка к ГИА по информатике 9 класс
Подготовка к ГИА по информатике 9 класс Электронные деньги
Электронные деньги Объектно-ориентированное программирование. Введение
Объектно-ориентированное программирование. Введение Основы алгоритмизации и программирования на языках высокого уровня
Основы алгоритмизации и программирования на языках высокого уровня Многопользовательские БД. Распределенные БД. Архитектура клиент-сервер. Лекция 6
Многопользовательские БД. Распределенные БД. Архитектура клиент-сервер. Лекция 6 Даркнет. Как войти в Даркнет
Даркнет. Как войти в Даркнет Структурные паттерны
Структурные паттерны Дети и компьютер
Дети и компьютер Передача информации. Локальные компьютерные сети
Передача информации. Локальные компьютерные сети Понятие операционной системы. Основные функции ОС
Понятие операционной системы. Основные функции ОС призентация
призентация Microinvest Склад Pro. Установка сервера MS SQL 2008R2 Express
Microinvest Склад Pro. Установка сервера MS SQL 2008R2 Express Основні концепції реляційної бази даних
Основні концепції реляційної бази даних Структура HTML-документа
Структура HTML-документа Информационные технологии в менеджменте
Информационные технологии в менеджменте Среда разработки CodeBlocks. Разработка консольных приложений на C/C++
Среда разработки CodeBlocks. Разработка консольных приложений на C/C++ GitHub Account Creation Request Form
GitHub Account Creation Request Form Визитная карточка
Визитная карточка