Паттерны параллельного проектирования приложений, выполнение части программ на GPU. Лекция 3.3 презентация
- Паттерны параллельного проектирования приложений, выполнение части программ на GPU. Лекция 3.3

Содержание
- 2. «Низкоуровневые» шаблоны, учитывающие специфику конкретного языка программиро-вания, называются идиомами. На наивысшем уровне существуют архитек-турные шаблоны, они
- 3. Типы шаблонов проектирования 1.Основные 2.Частные Основные шаблоны (Fundamental) Шаблон делегирования (Delegation pattern) Объект внешне выражает некоторое
- 4. -Шаблон функционального дизайна (Functional design) Гарантирует, что каждый модуль компьютер-ной программы имеет только одну обязан-ность и
- 5. -Интерфейс (Interface) Общий метод для структурирования компью-терных программ для того, чтобы их было проще понять. -Интерфейс-маркер
- 6. -Контейнер свойств (Property container) Позволяет добавлять дополнительные свойст-ва для класса в контейнер (внутри класса), вме-сто расширения
- 7. 1. Порождающие шаблоны (Creational) Шаблоны проектирования, которые абстраги-руют процесс инстанцирования. Они позволя-ют сделать систему независимой от
- 8. -Абстрактная фабрика (Abstract factory) Класс, который представляет собой интер-фейс для создания компонентов системы. -Строитель (Builder) Класс,
- 9. -Отложенная инициализация (Lazy initialization) Объект, инициализируемый во время первого обращения к нему. -Мультитон (Multiton) Гарантирует, что
- 10. -Прототип (Prototype) Определяет интерфейс создания объекта через клонирование другого объекта вместо создания через конструктор. -Получение ресурса
- 11. 2. Структурные шаблоны (Structural) определяют различные сложные структуры, которые изменяют интерфейс уже существую-щих объектов или его
- 12. -Адаптер (Adapter / Wrapper) Объект, обеспечивающий взаимодействие двух других объектов, один из которых ис-пользует, а другой
- 13. -Декоратор или Wrapper/Обёртка (Decorator) Класс, расширяющий функциональность дру-гого класса без использования наследования. -Фасад (Facade) Объект, который
- 14. -Приспособленец (Flyweight) Это объект, представляющий себя как уни-кальный экземпляр в разных местах програм-мы, но фактически не
- 15. 3. Поведенческие шаблоны (Behavioral) Определяют взаимодействие между объек-тами, увеличивая таким образом гибкость.
- 16. -Цепочка обязанностей (Chain of responsibility) Предназначен для организации в системе уровней ответственности. -Команда, Action, Transaction (Command)
- 17. -Итератор, Cursor (Iterator) Представляет собой объект, позволяющий получить последовательный доступ к элемен-там объекта-агрегата без использования опи-саний
- 18. -Хранитель (Memento) Позволяет не нарушая инкапсуляцию зафикси-ровать и сохранить внутренние состояния объ-екта так, чтобы позднее восстановить
- 19. -Слуга (Servant) Используется для обеспечения общей функци-ональности группе классов. -Состояние (State) Используется,когда во время выполнения про-граммы
- 20. -Шаблонный метод (Template method) Определяет основу алгоритма и позволяет наследникам переопределять некоторые шаги алгоритма, не изменяя
- 21. Частные шаблоны параллельного программирования (Concurrency) Concurrency — Параллелизм Используются для более эффективного напи-сания многопоточных программ, и
- 22. -Active Object (Active object) Служит для отделения потока выполнения ме-тода от потока, в котором он был
- 23. -Блокировка с двойной проверкой (Double checked locking) Предназначен для уменьшения накладных ра-сходов, связанных с получением блокировки.
- 24. -Reactor (Reactor) Предназначен для синхронной передачи зап-росов сервису от одного или нескольких источников. -Read/write lock (Read/write
- 25. -Однопоточное выполнение (Single thread execution) Препятствует конкурентному вызову метода, тем самым запрещая параллельное выполне-ние этого метода.
- 26. Другие типы шаблонов Также на сегодняшний день существует ряд других шаблонов: -Carrier Rider Mapper описывают предоставле-ние
- 27. -Коммуникационные шаблоны описывают процесс общения между отдельными участниками/сотрудниками организации. -Организационные шаблоны описывают организационную иерархию предприятия/фирмы -Антипаттерны
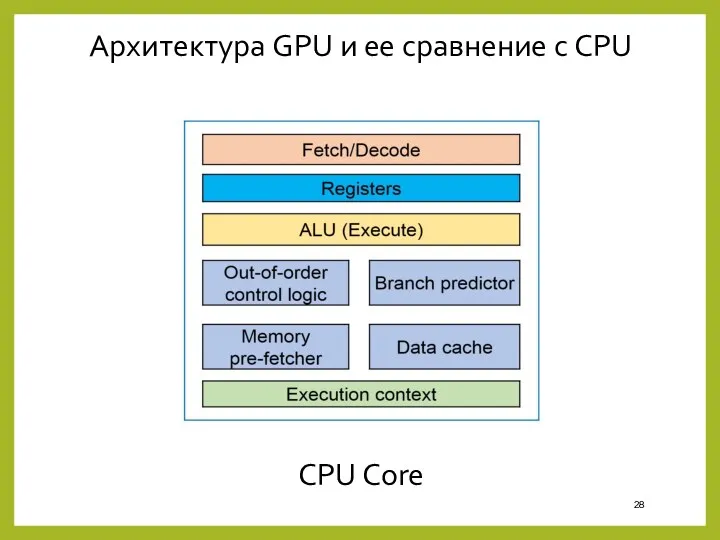
- 28. Архитектура GPU и ее сравнение с CPU CPU Core
- 29. GPU Core
- 30. Ограничения и возможности при работе с GPU Ограничения: -При выполнении расчетов на GPU, будет выделен целый
- 31. -GPU очень не любит ветвлений, да и в целом сложной логики в алгоритмах. Возможности: Собственно, ускорение
- 32. Наиболее распространены две технологии, которые можно использовать для программи-рования под GPU: OpenCL CUDA OpenCL – это
- 33. CUDA – это проприетарная технология и SDK от компании NVIDIA. Писать можно на C/C++ или использовать
- 34. -Более продвинутое API; -Проще синтаксис и инициализация карты; -Подпрограмма, выполняемая на GPU, является частью исходных текстов
- 35. Результаты выполнения алгоритмов на GPU Для тестирования GPU взят инстанс в AWS с видеокартой Tesla k80,
- 36. Трансформация Время выполнения трансформации на GPU и CPU в мс
- 37. Агрегация Время выполнения агрегации на GPU и CPU в мс
- 38. Сортировка Время выполнения сортировки на GPU и CPU в мс
- 39. Оверхед на пересылку данных Время пересылки данных на GPU, сортировки и пересылки данных обратно в RAM
- 40. HtoD – передаем данные на видеокарту GPU Execution – сортировка на видеокарте DtoH – копирование данных
- 41. Оверхед для большого объема данных Время пересылки данных на GPU, сортировки и пересылки данных обратно в
- 42. Серверное использование Пример игровой и серверной видеокарт
- 43. Основные отличия серверной (NVIDIA) и игро-вой карты: -Гарантия производителя (игровая карта не рассчитана на серверное использование).
- 44. -Количество параллельных потоков (не CUDA ядер) или поддержка Hyper-Q, которая позво-ляет из нескольких потоков на CPU
- 45. Многопоточность Время выполнения математических расчетов на GPU и CPU c матрицами размером 1000 x 60 в
- 46. Время выполнения математических расчетов на GPU и CPU c матрицами 10 000 x 60 в мс
- 47. Ограничение ресурсов Как мы уже говорили, два основных ресурса видеокарты – это вычислительные ядра и па-мять.
- 48. Контейнеры и GPU А если в сервере несколько видеокарт? Опять же, можно на уровне приложения ре-шать,
- 49. Работа в кластере Другой вопрос, что делать, если вы хотите выполнять одну задачу на нескольких GPU
- 50. Рекомендации Если вы размышляете об использовании GPU в своих проектах, то GPU, скорее всего, вам подойдет
- 51. Заранее также стоит задаться вопросами: -Сколько будет параллельных запросов; -На какое latency вы рассчитываете; -Достаточно ли
- 53. Скачать презентацию

«Низкоуровневые» шаблоны, учитывающие специфику конкретного языка программиро-вания, называются идиомами.
На наивысшем уровне
«Низкоуровневые» шаблоны, учитывающие специфику конкретного языка программиро-вания, называются идиомами.
На наивысшем уровне

Типы шаблонов проектирования
1.Основные
2.Частные
Основные шаблоны (Fundamental)
Шаблон делегирования (Delegation pattern)
Объект внешне выражает некоторое
Типы шаблонов проектирования
1.Основные
2.Частные
Основные шаблоны (Fundamental)
Шаблон делегирования (Delegation pattern)
Объект внешне выражает некоторое

-Шаблон функционального дизайна (Functional design)
Гарантирует, что каждый модуль компьютер-ной программы
-Шаблон функционального дизайна (Functional design)
Гарантирует, что каждый модуль компьютер-ной программы

-Интерфейс (Interface)
Общий метод для структурирования компью-терных программ для того, чтобы
-Интерфейс (Interface)
Общий метод для структурирования компью-терных программ для того, чтобы

-Контейнер свойств (Property container)
Позволяет добавлять дополнительные свойст-ва для класса в контейнер
-Контейнер свойств (Property container)
Позволяет добавлять дополнительные свойст-ва для класса в контейнер

1. Порождающие шаблоны (Creational)
Шаблоны проектирования, которые абстраги-руют процесс инстанцирования. Они позволя-ют сделать
1. Порождающие шаблоны (Creational)
Шаблоны проектирования, которые абстраги-руют процесс инстанцирования. Они позволя-ют сделать

-Абстрактная фабрика (Abstract factory)
Класс, который представляет собой интер-фейс для создания компонентов
-Абстрактная фабрика (Abstract factory)
Класс, который представляет собой интер-фейс для создания компонентов

-Отложенная инициализация (Lazy initialization)
Объект, инициализируемый во время первого обращения к нему.
-Мультитон
-Отложенная инициализация (Lazy initialization)
Объект, инициализируемый во время первого обращения к нему.
-Мультитон

-Прототип (Prototype)
Определяет интерфейс создания объекта через клонирование другого объекта вместо создания
-Прототип (Prototype)
Определяет интерфейс создания объекта через клонирование другого объекта вместо создания

2. Структурные шаблоны (Structural)
определяют различные сложные структуры, которые изменяют интерфейс уже существую-щих объектов
2. Структурные шаблоны (Structural)
определяют различные сложные структуры, которые изменяют интерфейс уже существую-щих объектов

-Адаптер (Adapter / Wrapper)
Объект, обеспечивающий взаимодействие двух других объектов, один из
-Адаптер (Adapter / Wrapper)
Объект, обеспечивающий взаимодействие двух других объектов, один из

-Декоратор или Wrapper/Обёртка (Decorator)
Класс, расширяющий функциональность дру-гого класса без использования наследования.
-Фасад (Facade)
Объект,
-Декоратор или Wrapper/Обёртка (Decorator)
Класс, расширяющий функциональность дру-гого класса без использования наследования.
-Фасад (Facade)
Объект,

-Приспособленец (Flyweight)
Это объект, представляющий себя как уни-кальный экземпляр в разных местах
-Приспособленец (Flyweight)
Это объект, представляющий себя как уни-кальный экземпляр в разных местах

3. Поведенческие шаблоны (Behavioral)
Определяют взаимодействие между объек-тами, увеличивая таким образом гибкость.
3. Поведенческие шаблоны (Behavioral)
Определяют взаимодействие между объек-тами, увеличивая таким образом гибкость.

-Цепочка обязанностей (Chain of responsibility)
Предназначен для организации в системе уровней ответственности.
-Команда,
-Цепочка обязанностей (Chain of responsibility)
Предназначен для организации в системе уровней ответственности.
-Команда,

-Итератор, Cursor (Iterator)
Представляет собой объект, позволяющий получить последовательный доступ к элемен-там объекта-агрегата
-Итератор, Cursor (Iterator)
Представляет собой объект, позволяющий получить последовательный доступ к элемен-там объекта-агрегата

-Хранитель (Memento)
Позволяет не нарушая инкапсуляцию зафикси-ровать и сохранить внутренние состояния объ-екта
-Хранитель (Memento)
Позволяет не нарушая инкапсуляцию зафикси-ровать и сохранить внутренние состояния объ-екта

-Слуга (Servant)
Используется для обеспечения общей функци-ональности группе классов.
-Состояние (State)
Используется,когда во время
-Слуга (Servant)
Используется для обеспечения общей функци-ональности группе классов.
-Состояние (State)
Используется,когда во время

-Шаблонный метод (Template method)
Определяет основу алгоритма и позволяет наследникам переопределять некоторые
-Шаблонный метод (Template method)
Определяет основу алгоритма и позволяет наследникам переопределять некоторые

Частные шаблоны параллельного программирования (Concurrency)
Concurrency — Параллелизм
Используются для более эффективного напи-сания многопоточных программ, и
Частные шаблоны параллельного программирования (Concurrency)
Concurrency — Параллелизм
Используются для более эффективного напи-сания многопоточных программ, и

-Active Object (Active object)
Служит для отделения потока выполнения ме-тода от потока,
-Active Object (Active object)
Служит для отделения потока выполнения ме-тода от потока,

-Блокировка с двойной проверкой (Double checked locking)
Предназначен для уменьшения накладных ра-сходов,
-Блокировка с двойной проверкой (Double checked locking)
Предназначен для уменьшения накладных ра-сходов,

-Reactor (Reactor)
Предназначен для синхронной передачи зап-росов сервису от одного или нескольких
-Reactor (Reactor)
Предназначен для синхронной передачи зап-росов сервису от одного или нескольких

-Однопоточное выполнение (Single thread execution)
Препятствует конкурентному вызову метода, тем самым запрещая
-Однопоточное выполнение (Single thread execution)
Препятствует конкурентному вызову метода, тем самым запрещая

Другие типы шаблонов
Также на сегодняшний день существует ряд других шаблонов:
-Carrier Rider
Другие типы шаблонов
Также на сегодняшний день существует ряд других шаблонов:
-Carrier Rider

-Коммуникационные шаблоны описывают процесс общения между отдельными участниками/сотрудниками организации.
-Организационные шаблоны описывают организационную иерархию
-Коммуникационные шаблоны описывают процесс общения между отдельными участниками/сотрудниками организации.
-Организационные шаблоны описывают организационную иерархию
Архитектура GPU и ее сравнение с CPU
CPU Core
Архитектура GPU и ее сравнение с CPU
CPU Core
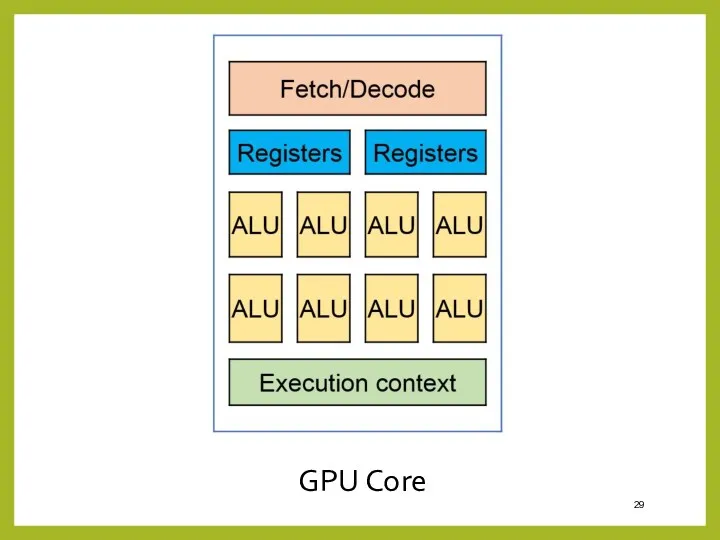
GPU Core
GPU Core

Ограничения и возможности при работе с GPU
Ограничения:
-При выполнении расчетов на GPU,
Ограничения и возможности при работе с GPU
Ограничения:
-При выполнении расчетов на GPU,

-GPU очень не любит ветвлений, да и в целом сложной логики
-GPU очень не любит ветвлений, да и в целом сложной логики

Наиболее распространены две технологии, которые можно использовать для программи-рования под GPU:
OpenCL
CUDA
OpenCL
Наиболее распространены две технологии, которые можно использовать для программи-рования под GPU:
OpenCL
CUDA
OpenCL

CUDA – это проприетарная технология и SDK от компании NVIDIA. Писать
CUDA – это проприетарная технология и SDK от компании NVIDIA. Писать

-Более продвинутое API;
-Проще синтаксис и инициализация карты;
-Подпрограмма, выполняемая на GPU, является
-Более продвинутое API;
-Проще синтаксис и инициализация карты;
-Подпрограмма, выполняемая на GPU, является

Результаты выполнения алгоритмов на GPU
Для тестирования GPU взят инстанс в AWS
Результаты выполнения алгоритмов на GPU
Для тестирования GPU взят инстанс в AWS
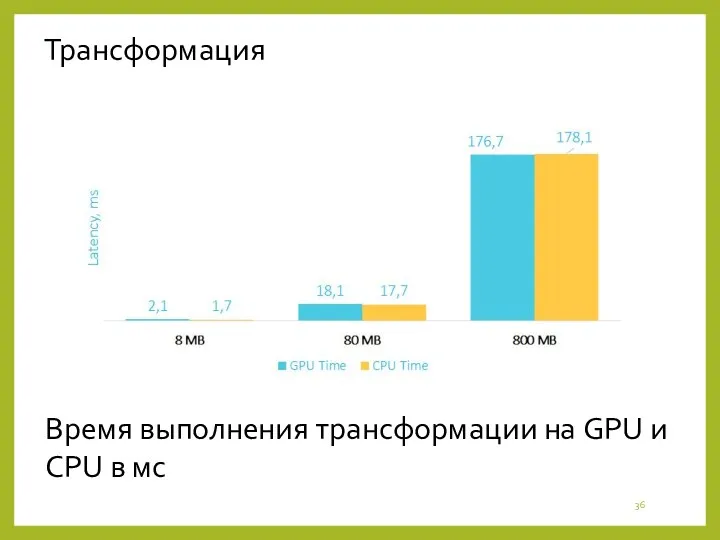
Трансформация
Время выполнения трансформации на GPU и CPU в мс
Трансформация
Время выполнения трансформации на GPU и CPU в мс
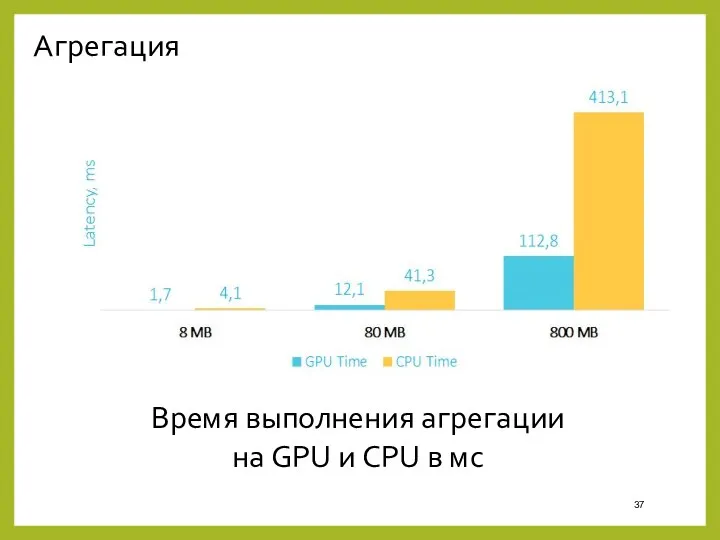
Агрегация
Время выполнения агрегации
на GPU и CPU в мс
Агрегация
Время выполнения агрегации
на GPU и CPU в мс
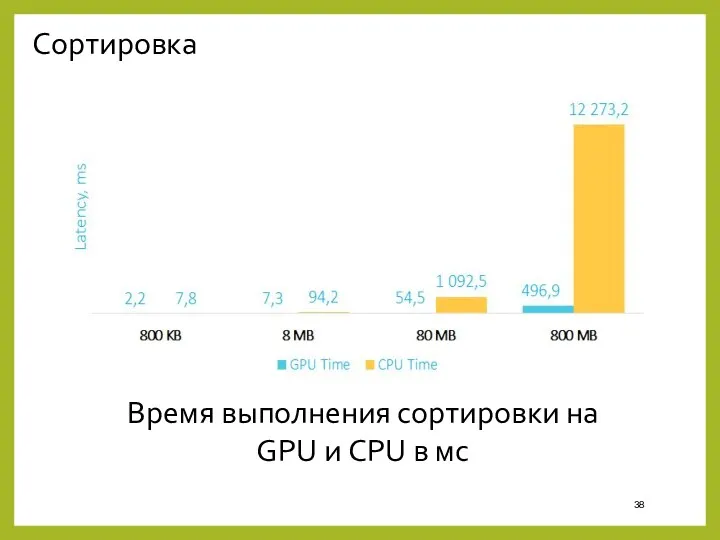
Сортировка
Время выполнения сортировки на
GPU и CPU в мс
Сортировка
Время выполнения сортировки на
GPU и CPU в мс
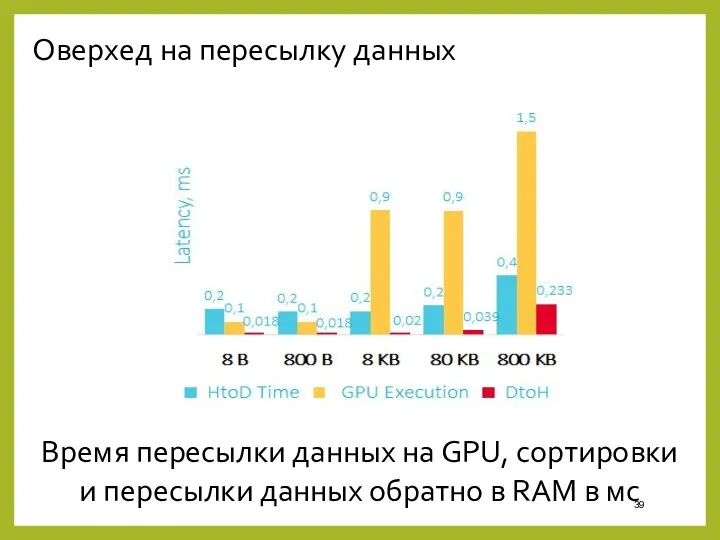
Оверхед на пересылку данных
Время пересылки данных на GPU, сортировки и пересылки
Оверхед на пересылку данных
Время пересылки данных на GPU, сортировки и пересылки

HtoD – передаем данные на видеокарту
GPU Execution – сортировка на видеокарте
DtoH
HtoD – передаем данные на видеокарту GPU Execution – сортировка на видеокарте DtoH
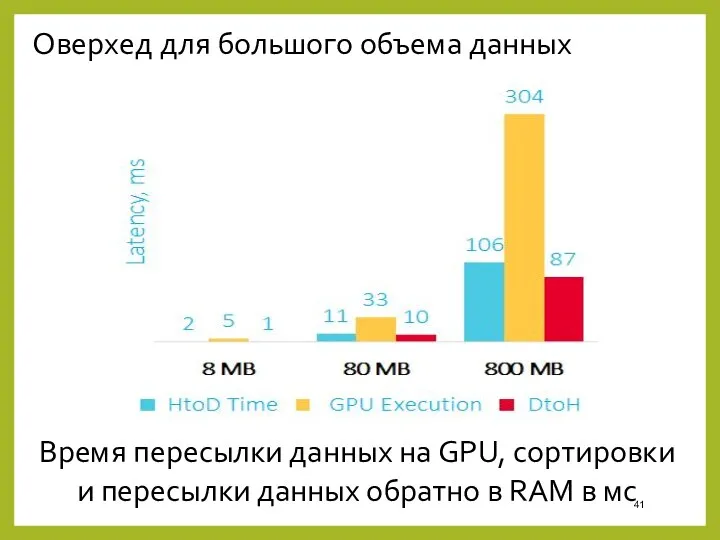
Оверхед для большого объема данных
Время пересылки данных на GPU, сортировки и
Оверхед для большого объема данных
Время пересылки данных на GPU, сортировки и

Серверное использование
Пример игровой и серверной видеокарт
Серверное использование
Пример игровой и серверной видеокарт

Основные отличия серверной (NVIDIA) и игро-вой карты:
-Гарантия производителя (игровая карта не рассчитана
Основные отличия серверной (NVIDIA) и игро-вой карты:
-Гарантия производителя (игровая карта не рассчитана

-Количество параллельных потоков (не CUDA ядер) или поддержка Hyper-Q, которая позво-ляет
-Количество параллельных потоков (не CUDA ядер) или поддержка Hyper-Q, которая позво-ляет
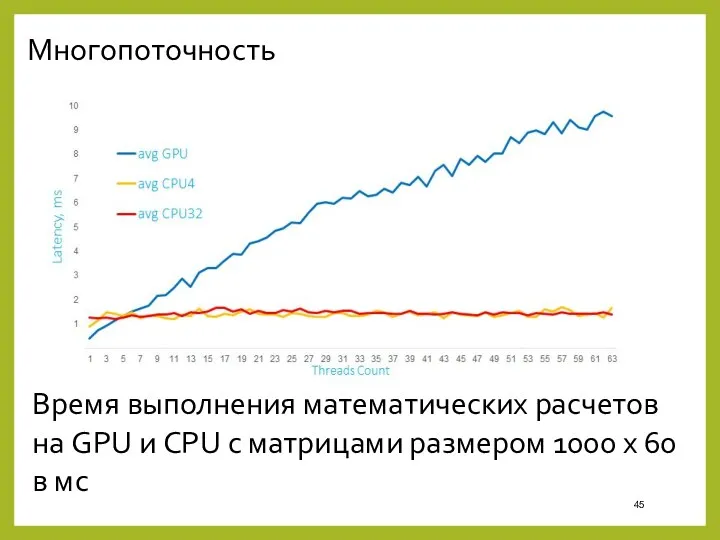
Многопоточность
Время выполнения математических расчетов на GPU и CPU c матрицами размером
Многопоточность
Время выполнения математических расчетов на GPU и CPU c матрицами размером
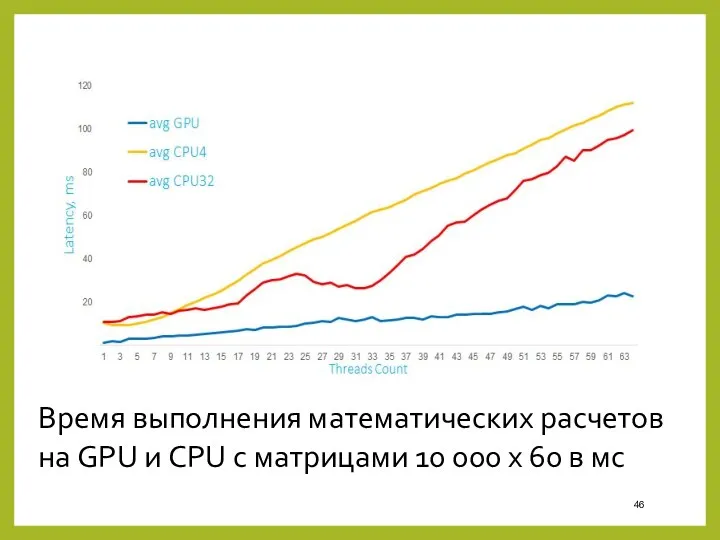
Время выполнения математических расчетов на GPU и CPU c матрицами 10
Время выполнения математических расчетов на GPU и CPU c матрицами 10

Ограничение ресурсов
Как мы уже говорили, два основных ресурса видеокарты – это
Ограничение ресурсов
Как мы уже говорили, два основных ресурса видеокарты – это

Контейнеры и GPU
А если в сервере несколько видеокарт?
Опять же, можно на
Контейнеры и GPU
А если в сервере несколько видеокарт?
Опять же, можно на

Работа в кластере
Другой вопрос, что делать, если вы хотите выполнять одну
Работа в кластере
Другой вопрос, что делать, если вы хотите выполнять одну

Рекомендации
Если вы размышляете об использовании GPU в своих проектах, то GPU,
Рекомендации
Если вы размышляете об использовании GPU в своих проектах, то GPU,

Заранее также стоит задаться вопросами:
-Сколько будет параллельных запросов;
-На какое latency вы
Заранее также стоит задаться вопросами:
-Сколько будет параллельных запросов;
-На какое latency вы
 Система доменных имён (DNS)
Система доменных имён (DNS) Интернет-магазин Лидер-март
Интернет-магазин Лидер-март Friar SlidesCarnival
Friar SlidesCarnival Database 5.1
Database 5.1 Оқыту мен оқуда ақпараттық коммуникациялық технологияларды пайдалану
Оқыту мен оқуда ақпараттық коммуникациялық технологияларды пайдалану Склеивание мешков цепочек
Склеивание мешков цепочек Алгоритми. Лекция 1
Алгоритми. Лекция 1 Создание и редактирование фона. Работа с сенсорами. Создание собственного мини-проекта
Создание и редактирование фона. Работа с сенсорами. Создание собственного мини-проекта Бесплатный онлайн квест по автоматизации бизнеса в соцсетях
Бесплатный онлайн квест по автоматизации бизнеса в соцсетях Безопасность и эргономика. Защита информации
Безопасность и эргономика. Защита информации Всемирная паутина, поисковые системы
Всемирная паутина, поисковые системы Пользовательский интерфейс
Пользовательский интерфейс Создание структуры базы данных. Семинар 3. Лекция 1. Первое знакомство с базами данных
Создание структуры базы данных. Семинар 3. Лекция 1. Первое знакомство с базами данных Современные компьютерные технологии социального моделирования
Современные компьютерные технологии социального моделирования Разработка урока с использованием сингапурской методики по теме Операторы челочисленного деления и деления по модулю
Разработка урока с использованием сингапурской методики по теме Операторы челочисленного деления и деления по модулю Читаем в школе и дома. Внеклассное чтение для детей младшего и среднего школьного возраста. Путешествие по сайтам
Читаем в школе и дома. Внеклассное чтение для детей младшего и среднего школьного возраста. Путешествие по сайтам Файловая система NTFS
Файловая система NTFS Уровни резервирования ArchestrA System Platform
Уровни резервирования ArchestrA System Platform Особенности работы с библиотечной программой MARC SQL
Особенности работы с библиотечной программой MARC SQL Поняття звіту. Автоматичне створення звіту
Поняття звіту. Автоматичне створення звіту Информационный бизнес
Информационный бизнес Комментарии для дизайнеров
Комментарии для дизайнеров Хакерство и его проявление в сфере информационных технологий
Хакерство и его проявление в сфере информационных технологий Специфика письменного общения в сети Интернет
Специфика письменного общения в сети Интернет Тесты 6 класс
Тесты 6 класс Геоинформационные системы для будущего Тольятти: взгляд горожанина
Геоинформационные системы для будущего Тольятти: взгляд горожанина Процедуры
Процедуры Inheritance (Vorislik). Lesson 14
Inheritance (Vorislik). Lesson 14