- PostgreSQL. День 1. Курс PostgreSQL разработка (5 дней)

Содержание
- 2. Введение в PostgreSQL Последняя версия 15 Наш стенд на версии 13
- 3. Конфигурация стенда вм с Postgresql OC – Debian 11 XFCE Postgresql 13.8 psql – командная строка
- 4. Общая конфигурация пользователей Пользователь student - обычный пользователь в ОС с паролем и правом входа и
- 5. Подключение пользователем postgres Входим в ОС как student Открываем терминал student$ sudo su – postgres Или
- 6. Подключение пользователем postgres sudo -u postgres psql без переключения на пользователя postgres (остаемся в командной строке
- 7. Подключение PGAdmin 4 Оконное приложение При запуске Пароль на связку ключей (keyring) - Pa$$w0rd12 Master пароль
- 8. Демо 1 Подключение psql Подключение PGAdmin 4 Основные действия в VirtualBox
- 9. Система типов PostgreSQL Целочисленные типы Числа с плавающей запятой Числа с плавающей запятой заданной точности Монетарный
- 10. Целочисленные типы
- 11. Целочисленные типы CREATE TABLE cities ( city_id serial PRIMARY KEY, city_name VARCHAR (255) NOT NULL, population
- 12. Numeric и decimal Числа фиксированной точности представлены двумя типами — numeric и decimal. Они одинаковы по
- 13. Numeric и decimal Округления производятся стандартно по правилам математики Ввод значения с превышающей точностью вызовет ошибку
- 14. Real и double precisiom Представителями типов данных с плавающей точкой являются типы real и double precision
- 15. Infinity -Infinity и NaN Они представляют особые значения, описанные в IEEE 754, соответственно «бесконечность», «минус бесконечность»
- 16. Float – стандарт ANSI SQL PostgreSQL поддерживает также тип данных float, определенный в стандарте SQL. В
- 17. Денежные типы
- 18. Money Тип money хранит денежную сумму с фиксированной дробной частью; определяется на уровне базы данных параметром
- 19. Строковые (символьные) типы
- 20. Особенности строковых типов char(n) и varchar(n) дают ошибку при вводе строки длиной больше n Исключение –
- 21. Особенности задания строкового типа -- одинарные кавычки SELECT 'PostgreSQL'; -- удвоение кавычки для спецсимвола SELECT 'PGDAY''17';
- 22. Бинарный тип
- 23. Бинарный тип - особенности Двоичные строки представляют собой последовательность октетов (байт) и имеют два отличия от
- 24. Типы даты-времени
- 25. Date Занимает 4 байта Диапазон дат 4713 до н.э. - 5874897 н.э. Для хранения используется формат
- 26. Функции для типа date --получение типа date SELECT NOW()::date; SELECT CURRENT_DATE; --Форматирование вывода даты, возвращает тип
- 27. Вычисление интервала дат minus (-) operator SELECT first_name, last_name, now() - hire_date as diff FROM employees;
- 28. Функции преобразования типов
- 29. Функции преобразования типов
- 30. Age() AGE(timestamp,timestamp); Вычитает второй аргумент из первого, возвращает тип interval AGE(timestamp); Первый аргумент current_date
- 31. Time column_name TIME(precision); -- задание типа в таблице Precision до 6 цифр Точность времени HH:MI HH:MI:SS
- 32. TIME with time zone type column TIME with time zone – определение типа TIME with time
- 33. Функции для time SELECT CURRENT_TIME; --возвращает тип time with time zone SELECT CURRENT_TIME(5); -- задаем точность
- 34. Как посмотреть возвращаемый тип SELECT LOCALTIME; SELECT pg_typeof(LOCALTIME); https://www.postgresql.org/docs/15/functions-datetime.html
- 35. Тип interval interval data type - периоды years, months, days, hours, minutes, seconds 16 bytes storage
- 36. Timestamp Временная метка – дата + время +(часовой пояс) timestamp: a timestamp without timezone one. timestamptz:
- 37. Функции для timestamp --timestamp with time zone SELECT NOW(); SELECT CURRENT_TIMESTAMP; SELECT CURRENT_TIME; --time with time
- 38. At time zone SET TIME ZONE 'UTC'; SELECT '2020-01-01 00:00:00+00'::timestamptz AT TIME ZONE ‘Europe/Moscow’; SET TIME
- 39. Фокусы стандарта POSIX SELECT '2020-01-01 00:00:00+00' AT TIME ZONE 'Etc/GMT+3’, '2020-01-01 00:00:00+00' AT TIME ZONE 'Etc/GMT-3',
- 40. Летнее время и «так исторически сложилось…» SET TimeZone = 'UTC'; SELECT TIMESTAMPTZ '2022-04-01 12:00:00 Europe/Vienna'; timestamptz
- 41. Булевский тип Тройная, а не двойная логика в языках стандарта ANSI SQL TRUE, FALSE, NULL
- 42. Синтаксис
- 43. Тип UUID Тип данных uuid сохраняет универсальные уникальные идентификаторы (Universally Unique Identifiers, UUID), определённые в RFC
- 44. Тип перечисления Типы перечислений (enum) определяют статический упорядоченный набор значений, так же как и типы enum,
- 45. Составной тип - структура Составной тип представляет структуру табличной строки или записи; по сути это просто
- 46. Массивы - array PostgreSQL позволяет создавать в таблицах столбцы, в которых будут содержаться не скалярные значения,
- 47. Псевдотип serial - счетчик CREATE TABLE table_name( id SERIAL); В фоне создается sequence и default для
- 48. Закадровые действия для serial CREATE SEQUENCE table_name_id_seq; CREATE TABLE table_name ( id integer NOT NULL DEFAULT
- 49. Три псевдотипа для serial
- 50. Serial – особенности реализации
- 51. Serial – особенности реализации
- 52. Как изменить seed и increment? CREATE TABLE teams2 ( id SERIAL UNIQUE, name VARCHAR(90) ); --
- 53. Тип json Поддерживается с версии 9.2 Операторы operator -> возращает JSON object field как ключ operator
- 54. Тип xml CREATE TABLE test ( ..., data xml, ...); INSERT INTO test VALUES (... ,
- 55. Создаем xml Выражение xmlelement создаёт XML-элемент с заданным именем, атрибутами и содержимым. SELECT xmlelement(name foo); xmlelement
- 56. Экспорт xml Data export: table_to_xml query_to_xml cursor_to_xml Schema export: table_to_xmlschema query_to_xmlschema cursor_to_xmlschema
- 57. XPath Всегда возвращает XML массив! Даже в случае одного элемента Для получения скаляра надо взять нужный
- 58. XMLTABLE PASSING – определяет xml колонку в таблице откуда берем данные для преобразования в реляционную таблицу
- 59. XMLTABLE SELECT xmltable.* FROM hoteldata, XMLTABLE ('/hotels/hotel/rooms/room' PASSING hotels COLUMNS id FOR ORDINALITY, hotel_name text PATH
- 60. Другие типы данных Геометрия Сетевые адреса Диапазоны Pg_lsn Псевдотипы https://postgrespro.ru/docs/postgrespro/14/datatype https://postgrespro.ru/docs/postgresql/15/datatype
- 61. Приведение типов Приведение типа определяет преобразование данных из одного типа в другой. PostgreSQL воспринимает две равносильные
- 62. Приведение типов при вызове функции Также можно записать приведение типа как вызов функции: имя_типа ( выражение
- 63. Написание запросов на языке SQL
- 64. Язык SQL История названия и произношение Эскуэль или Сиквел? Как SEQL стал SQL? – промышленный шпионаж
- 65. ANSI SQL
- 66. Общепринятая терминология языка SQL DQL DML DDL DCL
- 67. DQL и DML Команды на работу с данными в таблицах DQL – SELECT DML – INSERT,
- 68. DCL Административные команды для раздачи прав доступа к объектам БД GRANT DENY REVOKE
- 69. DDL Команды на создание, модификацию и удаление объектов БД CREATE ALTER DROP
- 70. Кластер При инициализации кластера создается 3 базы данных postgres template0 template1
- 71. Схемы Пространство имен для объектов базы данных tables, views, indexes, data types, functions, stored procedures и
- 72. lowercase для имен Имена таблиц и колонок хранятся в нижнем регистре! Для различия регистров case-sensitive нужно
- 73. Логическая структура кластера
- 74. Путь поиска Объекты с одинаковыми именами могут находиться в разных схемах Обращение к объекту по полному
- 75. search_path SELECT current_schema(); SELECT current_schemas(true); SHOW search_path; CREATE SCHEMA sales;
- 76. Специальные схемы public по умолчанию входит в путь поиска если ничего не менять, все объекты будут
- 77. Локализация В операционной системе сервера должны быть установлены локали с поддержкой русского языка: student$ locale -a|grep
- 78. Локали Postgresql SELECT name, setting, context FROM pg_settings WHERE name LIKE 'lc%'; name | setting |
- 79. Локализация на клиенте SET client_encoding = 'UTF8’; SET lc_time = 'ru_RU.UTF8’; SELECT to_char(current_date, 'TMDay, DD TMMonth
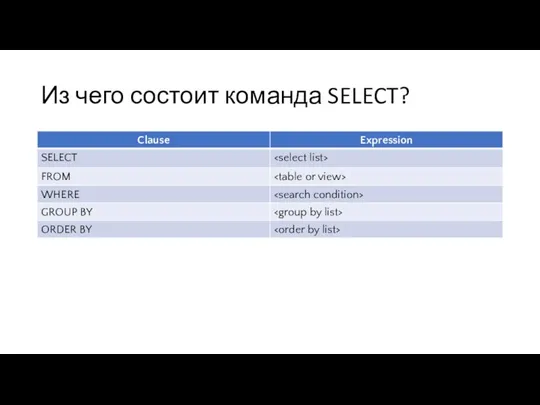
- 80. Из чего состоит команда SELECT?
- 81. Select list SELECT first_name FROM customer; SELECT first_name, last_name, email FROM customer; SELECT * FROM customer;
- 82. FROM Указывает на источник данных (таблицу, любой объект возвращающий таблицу – вью, функция, вложенный запрос) Источником
- 83. JOIN Соединение двух и более таблиц с целью получения новой структуры выборки и отбора записей в
- 84. Виды JOIN
- 85. Cross Join SELECT * FROM T1 CROSS JOIN T2; Картезианское произведение множест – все со всеми
- 86. Inner Join SELECT c.customer_id, first_name, last_name, email, amount, payment_date FROM customer c INNER JOIN payment p
- 87. Inner join 3 таблицы SELECT c.customer_id, c.first_name customer_first_name, c.last_name customer_last_name, s.first_name staff_first_name, s.last_name staff_last_name, amount, payment_date
- 88. Предложение USING в join Если обе таблицы имеют одноименную колонку SELECT customer_id, first_name, last_name, amount, payment_date
- 89. Варианты запросов SELECT film.film_id, title, inventory_id FROM film LEFT JOIN inventory ON inventory.film_id = film.film_id ORDER
- 90. Outer join – left и right SELECT review, title FROM films RIGHT JOIN film_reviews ON film_reviews.film_id
- 91. Natural Join Имплицитно соединяет таблицы по одноименным колонкам Может давать неожиданные результаты Лучше не использовать Замена
- 92. Natural Join --natural SELECT * FROM products NATURAL JOIN categories; --using SELECT * FROM products INNER
- 93. Псевдонимы для таблиц Для удобства написания join, но необязательны Для ряда других вычислительных операций могут быть
- 94. Псевдонимы для колонок SELECT column_name AS alias_name FROM table_name; SELECT column_name alias_name FROM table_name; Необходимы для
- 95. Подзапросы Запрос внутри запроса Вложенные Lateral
- 96. Вложенный подзапрос - скаляр SELECT film_id, title, rental_rate FROM film WHERE rental_rate > ( SELECT AVG
- 97. IN – список значений SELECT film_id, title FROM film WHERE film_id IN ( SELECT inventory.film_id FROM
- 98. EXISTS – выборка не пуста SELECT first_name, last_name FROM customer WHERE EXISTS ( SELECT 1 FROM
- 99. Lateral При использовании Lateral подзапрос может ссылаться на поля внешнего запроса SELECT * FROM foo, LATERAL
- 100. where – фильтрация данных в запросе Предложение (фильтр) WHERE использует ПРЕДИКАТЫ Предикат – логическое выражение Логическое
- 101. where SELECT last_name, first_name FROM customer WHERE first_name = 'Jamie';
- 102. GROUP BY Создает группы в выборке на основании уникальных комбинаций значений в GROUP BY Вычисляет агрегат
- 103. Правила запроса с группировкой HAVING, SELECT и ORDER BY должны возвращать скалярное значение для каждой группы
- 104. Примеры GROUP BY SELECT customer_id, SUM (amount) FROM payment GROUP BY customer_id; SELECT customer_id, staff_id, SUM(amount)
- 105. Фильтрация результатов группировки HAVING Обрабатывается после GROUP BY Отбирает значения предикатов с результатом TRUE (аналогично WHERE
- 106. Пример HAVING SELECT customer_id, SUM (amount) FROM payment GROUP BY customer_id HAVING SUM (amount) > 200;
- 107. Сортировка выборки Изначально выборка, таблица не сортирована Результат гарантированно отсортирован в нужном порядке только при применении
- 108. Особенности применения ORDER BY Обрабатывается последним Все NULL считает одинаковыми Можно сортировать по любой колонке, даже
- 109. Примеры ORDER BY SELECT first_name, last_name FROM customer ORDER BY first_name; SELECT first_name, last_name FROM customer
- 110. Order by и NULL ORDER BY sort_expresssion [ASC | DESC] [NULLS FIRST | NULLS LAST]
- 111. Limit и Offset Взять первые N записей выборки SELECT film_id, title, release_year FROM film ORDER BY
- 112. Union и UNION ALL -- исключит дубли SELECT * FROM top_rated_films UNION SELECT * FROM most_popular_films;
- 113. CASE выражение Разбор по веткам Это выражение, а не оператор
- 114. Тройная логика: NULL Что такое NULL и откуда он берется Сравнение двух NULL Проблема: неоднозначность результатов
- 115. Пример запросов SELECT custid, city, region, country FROM customers WHERE region IS NULL; SELECT custid, city,
- 116. Представления View Объект базы данных Определяется одним селектом в теле объекта Не принимает параметры Может использоваться
- 117. View CREATE VIEW view_name AS query; Select * from view_name;
- 119. Скачать презентацию

Введение в PostgreSQL
Последняя версия 15
Наш стенд на версии 13
Введение в PostgreSQL
Последняя версия 15
Наш стенд на версии 13

Конфигурация стенда вм с Postgresql
OC – Debian 11
XFCE
Postgresql 13.8
psql – командная
Конфигурация стенда вм с Postgresql
OC – Debian 11
XFCE
Postgresql 13.8
psql – командная

Общая конфигурация пользователей
Пользователь student - обычный пользователь в ОС с паролем
Общая конфигурация пользователей
Пользователь student - обычный пользователь в ОС с паролем

Подключение пользователем postgres
Входим в ОС как student
Открываем терминал
student$ sudo su –
Подключение пользователем postgres
Входим в ОС как student
Открываем терминал
student$ sudo su –

Подключение пользователем postgres
sudo -u postgres psql
без переключения на пользователя postgres
Подключение пользователем postgres
sudo -u postgres psql
без переключения на пользователя postgres

Подключение PGAdmin 4
Оконное приложение
При запуске
Пароль на связку ключей (keyring) - Pa$$w0rd12
Подключение PGAdmin 4
Оконное приложение
При запуске
Пароль на связку ключей (keyring) - Pa$$w0rd12

Демо 1
Подключение psql
Подключение PGAdmin 4
Основные действия в VirtualBox
Демо 1
Подключение psql
Подключение PGAdmin 4
Основные действия в VirtualBox

Система типов PostgreSQL
Целочисленные типы
Числа с плавающей запятой
Числа с плавающей запятой заданной
Система типов PostgreSQL
Целочисленные типы
Числа с плавающей запятой
Числа с плавающей запятой заданной
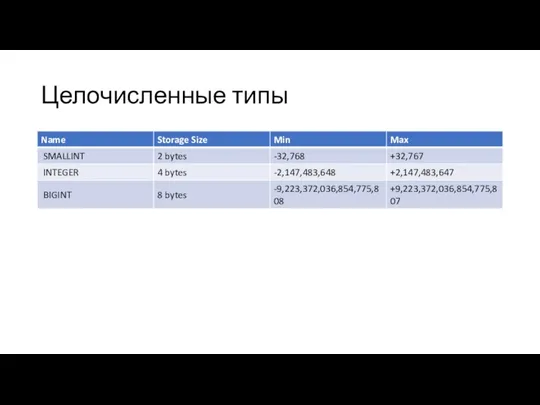
Целочисленные типы
Целочисленные типы

Целочисленные типы
CREATE TABLE cities (
city_id serial PRIMARY KEY,
city_name VARCHAR (255) NOT
Целочисленные типы
CREATE TABLE cities (
city_id serial PRIMARY KEY,
city_name VARCHAR (255) NOT

Numeric и decimal
Числа фиксированной точности представлены двумя типами — numeric и
Numeric и decimal
Числа фиксированной точности представлены двумя типами — numeric и

Numeric и decimal
Округления производятся стандартно по правилам математики
Ввод значения с превышающей
Numeric и decimal
Округления производятся стандартно по правилам математики
Ввод значения с превышающей

Real и double precisiom
Представителями типов данных с плавающей точкой являются типы
Real и double precisiom
Представителями типов данных с плавающей точкой являются типы

Infinity -Infinity и NaN
Они представляют особые значения, описанные в IEEE 754,
Infinity -Infinity и NaN
Они представляют особые значения, описанные в IEEE 754,

Float – стандарт ANSI SQL
PostgreSQL поддерживает также тип данных float, определенный
Float – стандарт ANSI SQL
PostgreSQL поддерживает также тип данных float, определенный

Денежные типы
Денежные типы

Money
Тип money хранит денежную сумму с фиксированной дробной частью; определяется на
Money
Тип money хранит денежную сумму с фиксированной дробной частью; определяется на

Строковые (символьные) типы
Строковые (символьные) типы

Особенности строковых типов
char(n) и varchar(n) дают ошибку при вводе строки длиной
Особенности строковых типов
char(n) и varchar(n) дают ошибку при вводе строки длиной

Особенности задания строкового типа
-- одинарные кавычки
SELECT 'PostgreSQL';
-- удвоение кавычки для спецсимвола
SELECT
Особенности задания строкового типа
-- одинарные кавычки
SELECT 'PostgreSQL';
-- удвоение кавычки для спецсимвола
SELECT

Бинарный тип
Бинарный тип

Бинарный тип - особенности
Двоичные строки представляют собой последовательность октетов (байт) и
Бинарный тип - особенности
Двоичные строки представляют собой последовательность октетов (байт) и
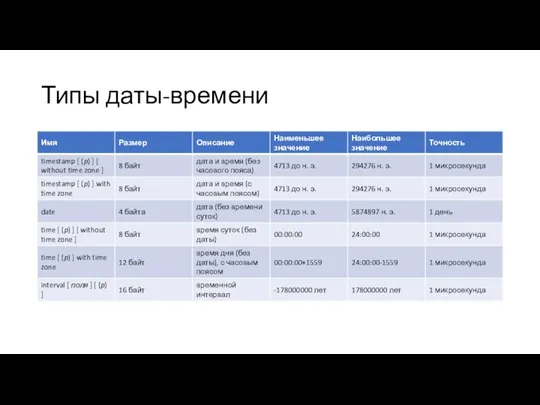
Типы даты-времени
Типы даты-времени

Date
Занимает 4 байта
Диапазон дат 4713 до н.э. - 5874897 н.э.
Для
Date
Занимает 4 байта
Диапазон дат 4713 до н.э. - 5874897 н.э.
Для

Функции для типа date
--получение типа date
SELECT NOW()::date;
SELECT CURRENT_DATE;
--Форматирование вывода даты, возвращает
Функции для типа date
--получение типа date
SELECT NOW()::date;
SELECT CURRENT_DATE;
--Форматирование вывода даты, возвращает

Вычисление интервала дат
minus (-) operator
SELECT first_name, last_name, now() - hire_date as diff
FROM employees;
AGE() function
SELECT employee_id, first_name, last_name, AGE(birth_date)
FROM employees;
EXTRACT()
Вычисление интервала дат
minus (-) operator
SELECT first_name, last_name, now() - hire_date as diff
FROM employees;
AGE() function
SELECT employee_id, first_name, last_name, AGE(birth_date)
FROM employees;
EXTRACT()

Функции преобразования типов
Функции преобразования типов

Функции преобразования типов
Функции преобразования типов

Age()
AGE(timestamp,timestamp);
Вычитает второй аргумент из первого, возвращает тип interval
AGE(timestamp);
Первый аргумент
Age()
AGE(timestamp,timestamp);
Вычитает второй аргумент из первого, возвращает тип interval
AGE(timestamp);
Первый аргумент

Time
column_name TIME(precision); -- задание типа в таблице
Precision до 6 цифр
Точность
Time
column_name TIME(precision); -- задание типа в таблице
Precision до 6 цифр
Точность

TIME with time zone type
column TIME with time zone – определение
TIME with time zone type
column TIME with time zone – определение

Функции для time
SELECT CURRENT_TIME; --возвращает тип time with time zone
SELECT CURRENT_TIME(5);
Функции для time
SELECT CURRENT_TIME; --возвращает тип time with time zone
SELECT CURRENT_TIME(5);

Как посмотреть возвращаемый тип
SELECT LOCALTIME;
SELECT pg_typeof(LOCALTIME);
https://www.postgresql.org/docs/15/functions-datetime.html
Как посмотреть возвращаемый тип
SELECT LOCALTIME;
SELECT pg_typeof(LOCALTIME);
https://www.postgresql.org/docs/15/functions-datetime.html

Тип interval
interval data type - периоды years, months, days, hours, minutes,
Тип interval
interval data type - периоды years, months, days, hours, minutes,

Timestamp
Временная метка – дата + время +(часовой пояс)
timestamp: a timestamp without
Timestamp
Временная метка – дата + время +(часовой пояс)
timestamp: a timestamp without

Функции для timestamp
--timestamp with time zone
SELECT NOW();
SELECT CURRENT_TIMESTAMP;
SELECT CURRENT_TIME;
Функции для timestamp
--timestamp with time zone
SELECT NOW();
SELECT CURRENT_TIMESTAMP;
SELECT CURRENT_TIME;

At time zone
SET TIME ZONE 'UTC';
SELECT '2020-01-01 00:00:00+00'::timestamptz AT TIME
At time zone
SET TIME ZONE 'UTC';
SELECT '2020-01-01 00:00:00+00'::timestamptz AT TIME

Фокусы стандарта POSIX
SELECT
'2020-01-01 00:00:00+00' AT TIME ZONE 'Etc/GMT+3’,
'2020-01-01 00:00:00+00' AT
Фокусы стандарта POSIX
SELECT
'2020-01-01 00:00:00+00' AT TIME ZONE 'Etc/GMT+3’,
'2020-01-01 00:00:00+00' AT

Летнее время и «так исторически сложилось…»
SET TimeZone = 'UTC';
SELECT TIMESTAMPTZ '2022-04-01
Летнее время и «так исторически сложилось…»
SET TimeZone = 'UTC';
SELECT TIMESTAMPTZ '2022-04-01

Булевский тип
Тройная, а не двойная логика в языках стандарта ANSI SQL
TRUE,
Булевский тип
Тройная, а не двойная логика в языках стандарта ANSI SQL
TRUE,
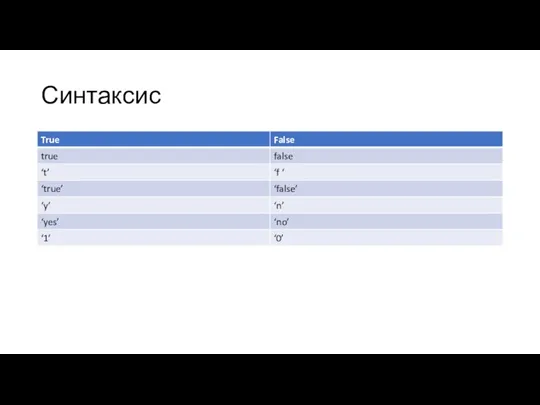
Синтаксис
Синтаксис

Тип UUID
Тип данных uuid сохраняет универсальные уникальные идентификаторы (Universally Unique Identifiers,
Тип UUID
Тип данных uuid сохраняет универсальные уникальные идентификаторы (Universally Unique Identifiers,

Тип перечисления
Типы перечислений (enum) определяют статический упорядоченный набор значений, так же
Тип перечисления
Типы перечислений (enum) определяют статический упорядоченный набор значений, так же

Составной тип - структура
Составной тип представляет структуру табличной строки или записи;
Составной тип - структура
Составной тип представляет структуру табличной строки или записи;

Массивы - array
PostgreSQL позволяет создавать в таблицах столбцы, в которых будут
Массивы - array
PostgreSQL позволяет создавать в таблицах столбцы, в которых будут

Псевдотип serial - счетчик
CREATE TABLE table_name( id SERIAL);
В фоне создается sequence
Псевдотип serial - счетчик
CREATE TABLE table_name( id SERIAL);
В фоне создается sequence

Закадровые действия для serial
CREATE SEQUENCE table_name_id_seq;
CREATE TABLE table_name (
id integer
Закадровые действия для serial
CREATE SEQUENCE table_name_id_seq;
CREATE TABLE table_name (
id integer
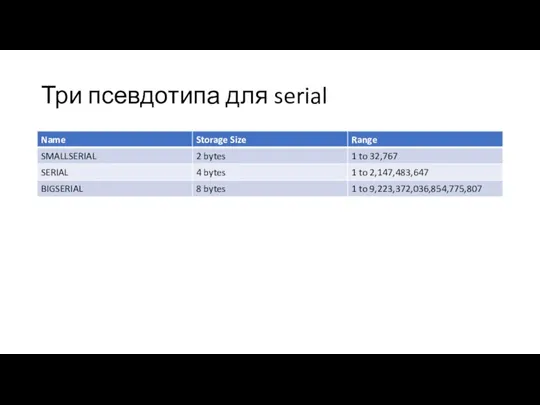
Три псевдотипа для serial
Три псевдотипа для serial
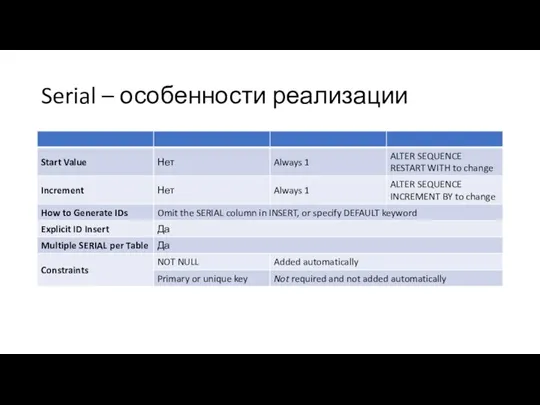
Serial – особенности реализации
Serial – особенности реализации
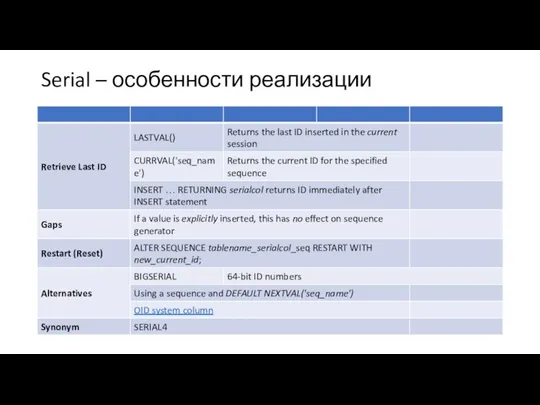
Serial – особенности реализации
Serial – особенности реализации

Как изменить seed и increment?
CREATE TABLE teams2
(
id SERIAL
Как изменить seed и increment?
CREATE TABLE teams2
(
id SERIAL

Тип json
Поддерживается с версии 9.2
Операторы
operator -> возращает JSON object field
Тип json
Поддерживается с версии 9.2
Операторы
operator -> возращает JSON object field

Тип xml
CREATE TABLE test (
...,
data xml,
...);
INSERT INTO test VALUES (... ,
Тип xml
CREATE TABLE test (
...,
data xml,
...);
INSERT INTO test VALUES (... ,

Создаем xml
Выражение xmlelement создаёт XML-элемент с заданным именем, атрибутами и содержимым.
Создаем xml
Выражение xmlelement создаёт XML-элемент с заданным именем, атрибутами и содержимым.

Экспорт xml
Data export:
table_to_xml
query_to_xml
cursor_to_xml
Schema export:
table_to_xmlschema
query_to_xmlschema
cursor_to_xmlschema
Экспорт xml
Data export:
table_to_xml
query_to_xml
cursor_to_xml
Schema export:
table_to_xmlschema
query_to_xmlschema
cursor_to_xmlschema

XPath
Всегда возвращает XML массив! Даже в случае одного элемента
Для получения скаляра
XPath
Всегда возвращает XML массив! Даже в случае одного элемента
Для получения скаляра

XMLTABLE
PASSING – определяет xml колонку в таблице откуда берем данные для
XMLTABLE
PASSING – определяет xml колонку в таблице откуда берем данные для

XMLTABLE
SELECT xmltable.*
FROM hoteldata,
XMLTABLE ('/hotels/hotel/rooms/room' PASSING hotels
COLUMNS
id FOR
XMLTABLE
SELECT xmltable.*
FROM hoteldata,
XMLTABLE ('/hotels/hotel/rooms/room' PASSING hotels
COLUMNS
id FOR

Другие типы данных
Геометрия
Сетевые адреса
Диапазоны
Pg_lsn
Псевдотипы
https://postgrespro.ru/docs/postgrespro/14/datatype
https://postgrespro.ru/docs/postgresql/15/datatype
Другие типы данных
Геометрия
Сетевые адреса
Диапазоны
Pg_lsn
Псевдотипы
https://postgrespro.ru/docs/postgrespro/14/datatype
https://postgrespro.ru/docs/postgresql/15/datatype

Приведение типов
Приведение типа определяет преобразование данных из одного типа в другой.
Приведение типов
Приведение типа определяет преобразование данных из одного типа в другой.

Приведение типов при вызове функции
Также можно записать приведение типа как вызов
Приведение типов при вызове функции
Также можно записать приведение типа как вызов

Написание запросов на языке SQL
Написание запросов на языке SQL

Язык SQL
История названия и произношение
Эскуэль или Сиквел?
Как SEQL стал SQL? –
Язык SQL
История названия и произношение
Эскуэль или Сиквел?
Как SEQL стал SQL? –
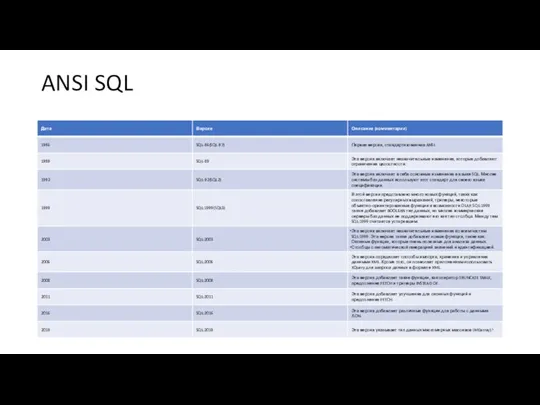
ANSI SQL
ANSI SQL

Общепринятая терминология языка SQL
DQL
DML
DDL
DCL
Общепринятая терминология языка SQL
DQL
DML
DDL
DCL

DQL и DML
Команды на работу с данными в таблицах
DQL – SELECT
DML
DQL и DML
Команды на работу с данными в таблицах
DQL – SELECT
DML

DCL
Административные команды для раздачи прав доступа к объектам БД
GRANT
DENY
REVOKE
DCL
Административные команды для раздачи прав доступа к объектам БД
GRANT
DENY
REVOKE

DDL
Команды на создание, модификацию и удаление объектов БД
CREATE
ALTER
DROP
DDL
Команды на создание, модификацию и удаление объектов БД
CREATE
ALTER
DROP

Кластер
При инициализации кластера создается 3 базы данных
postgres
template0
template1
Кластер
При инициализации кластера создается 3 базы данных
postgres
template0
template1

Схемы
Пространство имен для объектов базы данных
tables, views, indexes, data types, functions,
Схемы
Пространство имен для объектов базы данных
tables, views, indexes, data types, functions,

lowercase для имен
Имена таблиц и колонок хранятся в нижнем регистре!
Для различия
lowercase для имен
Имена таблиц и колонок хранятся в нижнем регистре!
Для различия
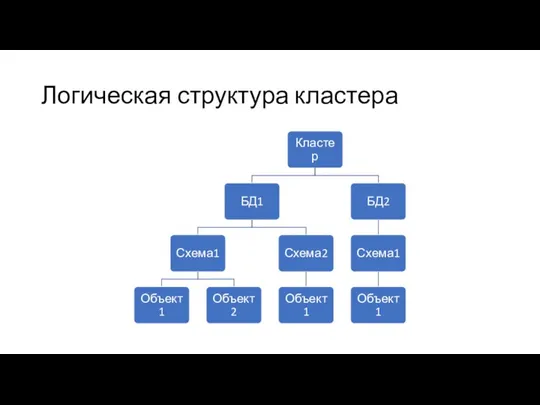
Логическая структура кластера
Логическая структура кластера

Путь поиска
Объекты с одинаковыми именами могут находиться в разных схемах
Обращение к
Путь поиска
Объекты с одинаковыми именами могут находиться в разных схемах
Обращение к

search_path
SELECT current_schema();
SELECT current_schemas(true);
SHOW search_path;
CREATE SCHEMA sales;
search_path
SELECT current_schema();
SELECT current_schemas(true);
SHOW search_path;
CREATE SCHEMA sales;

Специальные схемы
public
по умолчанию входит в путь поиска
если ничего не менять, все
Специальные схемы
public
по умолчанию входит в путь поиска
если ничего не менять, все

Локализация
В операционной системе сервера должны быть установлены локали с поддержкой русского
Локализация
В операционной системе сервера должны быть установлены локали с поддержкой русского

Локали Postgresql
SELECT name, setting, context FROM pg_settings WHERE name LIKE 'lc%';
Локали Postgresql
SELECT name, setting, context FROM pg_settings WHERE name LIKE 'lc%';

Локализация на клиенте
SET client_encoding = 'UTF8’;
SET lc_time = 'ru_RU.UTF8’;
SELECT to_char(current_date, 'TMDay,
Локализация на клиенте
SET client_encoding = 'UTF8’;
SET lc_time = 'ru_RU.UTF8’;
SELECT to_char(current_date, 'TMDay,
Из чего состоит команда SELECT?
Из чего состоит команда SELECT?

Select list
SELECT first_name FROM customer;
SELECT first_name, last_name, email FROM customer;
SELECT *
Select list
SELECT first_name FROM customer;
SELECT first_name, last_name, email FROM customer;
SELECT *

FROM
Указывает на источник данных (таблицу, любой объект возвращающий таблицу – вью,
FROM
Указывает на источник данных (таблицу, любой объект возвращающий таблицу – вью,

JOIN
Соединение двух и более таблиц с целью получения новой структуры выборки
JOIN
Соединение двух и более таблиц с целью получения новой структуры выборки

Виды JOIN
Виды JOIN

Cross Join
SELECT * FROM T1 CROSS JOIN T2;
Картезианское произведение множест –
Cross Join
SELECT * FROM T1 CROSS JOIN T2;
Картезианское произведение множест –

Inner Join
SELECT c.customer_id, first_name, last_name, email, amount, payment_date
FROM customer c
INNER JOIN payment p
ON p.customer_id = c.customer_id
WHERE
Inner Join
SELECT c.customer_id, first_name, last_name, email, amount, payment_date
FROM customer c
INNER JOIN payment p
ON p.customer_id = c.customer_id
WHERE

Inner join 3 таблицы
SELECT c.customer_id, c.first_name customer_first_name, c.last_name customer_last_name, s.first_name staff_first_name, s.last_name staff_last_name, amount, payment_date
FROM customer c
INNER JOIN
Inner join 3 таблицы
SELECT c.customer_id, c.first_name customer_first_name, c.last_name customer_last_name, s.first_name staff_first_name, s.last_name staff_last_name, amount, payment_date
FROM customer c
INNER JOIN

Предложение USING в join
Если обе таблицы имеют одноименную колонку
SELECT customer_id, first_name, last_name, amount, payment_date
FROM customer
INNER
Предложение USING в join
Если обе таблицы имеют одноименную колонку
SELECT customer_id, first_name, last_name, amount, payment_date
FROM customer
INNER

Варианты запросов
SELECT film.film_id, title, inventory_id
FROM film
LEFT JOIN inventory
ON inventory.film_id = film.film_id
ORDER BY
Варианты запросов
SELECT film.film_id, title, inventory_id
FROM film
LEFT JOIN inventory
ON inventory.film_id = film.film_id
ORDER BY

Outer join – left и right
SELECT review, title
FROM films
RIGHT JOIN
Outer join – left и right
SELECT review, title
FROM films
RIGHT JOIN

Natural Join
Имплицитно соединяет таблицы по одноименным колонкам
Может давать неожиданные результаты
Лучше не
Natural Join
Имплицитно соединяет таблицы по одноименным колонкам
Может давать неожиданные результаты
Лучше не

Natural Join
--natural
SELECT * FROM products NATURAL JOIN categories;
--using
SELECT * FROM products
INNER
Natural Join
--natural
SELECT * FROM products NATURAL JOIN categories;
--using
SELECT * FROM products
INNER

Псевдонимы для таблиц
Для удобства написания join, но необязательны
Для ряда других вычислительных
Псевдонимы для таблиц
Для удобства написания join, но необязательны
Для ряда других вычислительных

Псевдонимы для колонок
SELECT column_name AS alias_name
FROM table_name;
SELECT column_name alias_name
FROM table_name;
Необходимы для
Псевдонимы для колонок
SELECT column_name AS alias_name
FROM table_name;
SELECT column_name alias_name
FROM table_name;
Необходимы для

Подзапросы
Запрос внутри запроса
Вложенные
Lateral
Подзапросы
Запрос внутри запроса
Вложенные
Lateral

Вложенный подзапрос - скаляр
SELECT film_id, title, rental_rate
FROM film
WHERE rental_rate >
( SELECT AVG (rental_rate) FROM film );
Вложенный подзапрос - скаляр
SELECT film_id, title, rental_rate
FROM film
WHERE rental_rate >
( SELECT AVG (rental_rate) FROM film );

IN – список значений
SELECT film_id, title
FROM film WHERE film_id IN
( SELECT inventory.film_id FROM rental INNER JOIN inventory
IN – список значений
SELECT film_id, title
FROM film WHERE film_id IN
( SELECT inventory.film_id FROM rental INNER JOIN inventory

EXISTS – выборка не пуста
SELECT first_name, last_name
FROM customer WHERE EXISTS
( SELECT 1 FROM payment WHERE payment.customer_id = customer.customer_id );
EXISTS – выборка не пуста
SELECT first_name, last_name
FROM customer WHERE EXISTS
( SELECT 1 FROM payment WHERE payment.customer_id = customer.customer_id );

Lateral
При использовании Lateral подзапрос может ссылаться на поля внешнего запроса
SELECT *
Lateral
При использовании Lateral подзапрос может ссылаться на поля внешнего запроса SELECT *

where – фильтрация данных в запросе
Предложение (фильтр) WHERE использует ПРЕДИКАТЫ
Предикат –
where – фильтрация данных в запросе
Предложение (фильтр) WHERE использует ПРЕДИКАТЫ
Предикат –

where
SELECT last_name, first_name
FROM customer
WHERE first_name = 'Jamie';
where
SELECT last_name, first_name
FROM customer
WHERE first_name = 'Jamie';

GROUP BY
Создает группы в выборке на основании уникальных комбинаций значений в
GROUP BY
Создает группы в выборке на основании уникальных комбинаций значений в

Правила запроса с группировкой
HAVING, SELECT и ORDER BY должны возвращать скалярное
Правила запроса с группировкой
HAVING, SELECT и ORDER BY должны возвращать скалярное

Примеры GROUP BY
SELECT customer_id, SUM (amount)
FROM payment
GROUP BY customer_id;
SELECT customer_id, staff_id, SUM(amount)
FROM payment
GROUP
Примеры GROUP BY
SELECT customer_id, SUM (amount)
FROM payment
GROUP BY customer_id;
SELECT customer_id, staff_id, SUM(amount)
FROM payment
GROUP

Фильтрация результатов группировки
HAVING
Обрабатывается после GROUP BY
Отбирает значения предикатов с результатом TRUE
Фильтрация результатов группировки
HAVING
Обрабатывается после GROUP BY
Отбирает значения предикатов с результатом TRUE

Пример HAVING
SELECT customer_id, SUM (amount)
FROM payment
GROUP BY customer_id
HAVING SUM (amount) > 200;
Пример HAVING
SELECT customer_id, SUM (amount)
FROM payment
GROUP BY customer_id
HAVING SUM (amount) > 200;

Сортировка выборки
Изначально выборка, таблица не сортирована
Результат гарантированно отсортирован в нужном порядке
Сортировка выборки
Изначально выборка, таблица не сортирована
Результат гарантированно отсортирован в нужном порядке

Особенности применения ORDER BY
Обрабатывается последним
Все NULL считает одинаковыми
Можно сортировать по любой
Особенности применения ORDER BY
Обрабатывается последним
Все NULL считает одинаковыми
Можно сортировать по любой

Примеры ORDER BY
SELECT first_name, last_name
FROM customer
ORDER BY first_name;
SELECT first_name, last_name
FROM customer
ORDER BY first_name DESC;
Примеры ORDER BY
SELECT first_name, last_name
FROM customer
ORDER BY first_name;
SELECT first_name, last_name
FROM customer
ORDER BY first_name DESC;
![Order by и NULL ORDER BY sort_expresssion [ASC | DESC] [NULLS FIRST | NULLS LAST]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/599249/slide-109.jpg)
Order by и NULL
ORDER BY sort_expresssion [ASC | DESC] [NULLS FIRST
Order by и NULL
ORDER BY sort_expresssion [ASC | DESC] [NULLS FIRST

Limit и Offset
Взять первые N записей выборки
SELECT film_id, title, release_year FROM film ORDER BY film_id LIMIT
Limit и Offset
Взять первые N записей выборки
SELECT film_id, title, release_year FROM film ORDER BY film_id LIMIT

Union и UNION ALL
-- исключит дубли
SELECT * FROM top_rated_films
UNION
SELECT * FROM
Union и UNION ALL
-- исключит дубли
SELECT * FROM top_rated_films
UNION
SELECT * FROM

CASE выражение
Разбор по веткам
Это выражение, а не оператор
CASE выражение
Разбор по веткам
Это выражение, а не оператор

Тройная логика: NULL
Что такое NULL и откуда он берется
Сравнение двух NULL
Проблема:
Тройная логика: NULL
Что такое NULL и откуда он берется
Сравнение двух NULL
Проблема:

Пример запросов
SELECT custid, city, region, country
FROM customers
WHERE region IS NULL;
SELECT custid,
Пример запросов
SELECT custid, city, region, country
FROM customers
WHERE region IS NULL;
SELECT custid,

Представления View
Объект базы данных
Определяется одним селектом в теле объекта
Не принимает
Представления View
Объект базы данных
Определяется одним селектом в теле объекта
Не принимает

View
CREATE VIEW view_name AS query;
Select * from view_name;
View
CREATE VIEW view_name AS query;
Select * from view_name;
 Стратегия решения задачи
Стратегия решения задачи Функционирование маршрутизаторов. (Тема 3.4)
Функционирование маршрутизаторов. (Тема 3.4) Программное управление работой компьютера Алгоритмы. Программирование
Программное управление работой компьютера Алгоритмы. Программирование Переход на 1С:ERP
Переход на 1С:ERP Основы работы с Power Point. Cоздание слайдов
Основы работы с Power Point. Cоздание слайдов Веб-сервис по анализу цен интернет-магазинов
Веб-сервис по анализу цен интернет-магазинов Создание Web-сайтов в программе Microsoft FrontPage
Создание Web-сайтов в программе Microsoft FrontPage Работа с интерактивной доской StarBoard
Работа с интерактивной доской StarBoard 앱_요구사항_정의서 (20190525)
앱_요구사항_정의서 (20190525) Техника безопасности при работе на компьютере
Техника безопасности при работе на компьютере Метод интервью в социологических исследованиях
Метод интервью в социологических исследованиях Умовні оператори
Умовні оператори Adobe Illustrator программасының интерфейсі
Adobe Illustrator программасының интерфейсі Учебная практика в фотосалоне ИП Нечаева Е.А
Учебная практика в фотосалоне ИП Нечаева Е.А Массивы в C#. Лекция 6
Массивы в C#. Лекция 6 Информатика 8 сынып
Информатика 8 сынып Электронная таблица Microsoft Excel
Электронная таблица Microsoft Excel Основные понятия в тестировании. Ручное тестирование. Урок 1
Основные понятия в тестировании. Ручное тестирование. Урок 1 История сети Интернет
История сети Интернет Алгоритмы основные понятия, свойства и виды
Алгоритмы основные понятия, свойства и виды Шаблоны STL
Шаблоны STL Автоматизация службы охраны труда
Автоматизация службы охраны труда Оператор цикла While. ОТП, 6 класс, урок 2
Оператор цикла While. ОТП, 6 класс, урок 2 Язык HTML
Язык HTML What is Web of Science
What is Web of Science Динамические расчеты в системе SCAD
Динамические расчеты в системе SCAD iSpring Suite
iSpring Suite Social network
Social network