Повышение эффективности работы баз данных. Обработка транзакций OLTP-OLAP системы мониторы транзакций презентация
- Повышение эффективности работы баз данных. Обработка транзакций OLTP-OLAP системы мониторы транзакций

Содержание
- 2. Индексы в стандарте языка Индекс – это набор ссылок, упорядоченных по определенному столбцу таблицы, который в
- 3. индексы В СРЕДЕ SQL SERVER РЕАЛИЗОВАНО НЕСКОЛЬКО ТИПОВ ИНДЕКСОВ: КЛАСТЕРНЫЕ ИНДЕКСЫ ; НЕКЛАСТЕРНЫЕ ИНДЕКСЫ ; УНИКАЛЬНЫЕ
- 4. Некластерный индекс Некластерные индексы – наиболее типичные представители семейства индексов. В отличие от кластерных, они не
- 5. Кластерный индекс Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов рекомендуется по возможности свести
- 6. Уникальный индекс Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и
- 7. OLAP и OLTP системы OLTP – оперативная транзакционная обработка данных OLAP – оперативная аналитическая обработка данных
- 8. Характеристики OLTP системы ∙ Большой объем информации ∙ Часто различные БД для разных подразделений ∙ Нормализованная
- 9. Основной способ логического представления данных – МНОГОМЕРНЫЕ КУБЫ (OLAP – кубы)
- 10. OLAP – куб и срезы данных
- 11. Правила Кодда для реляционных БД 1. Правило информации. 2. Правило гарантированного доступа. 3. Правило поддержки недействительных
- 12. Правила Кодда для OLAP 1. Концептуальное многомерное представление. 2. Прозрачность. 3. Доступность. 4. Постоянная производительность при
- 13. Реализация OLAP Типы OLAP - серверов MOLAP (Multidimensional OLAP) - и детальные данные, и агрегаты хранятся
- 14. OLTP схема базы данных Моделируются оптовые продажи на склад Объекты Склады Категории товаров (модель) Производители Товары
- 15. Оперативная схема БД оптовых продаж на склады
- 16. ROLAP – схема типа звезда
- 17. Особенности ROLAP – схемы типа звезда Одна таблица фактов, которая сильно денормализована Несколько таблиц измерений, которые
- 18. ROLAP – схема типа снежинка с нормализованными измерениями
- 19. ROLAP – схема типа снежинка с выделением агрегированных таблиц
- 20. ROLAP – схема типа снежинка с выделением агрегированных таблиц и нормализованными измерениями
- 21. Агрегирование по производителю и модели товара
- 22. Состав хранилищ данных Метаданные Исходные данные Предварительно просуммированные данные Основные метаданные OLAP Куб Факты Измерения Уровни
- 23. Общая структура хранилища данных Источники данных Процедуры выгрузки, преобразования и загрузки данных Хранилище данных Витрины данных
- 25. Скачать презентацию

Индексы в стандарте языка
Индекс – это набор ссылок, упорядоченных по определенному столбцу таблицы, который
Индексы в стандарте языка
Индекс – это набор ссылок, упорядоченных по определенному столбцу таблицы, который

индексы
В СРЕДЕ SQL SERVER РЕАЛИЗОВАНО НЕСКОЛЬКО ТИПОВ ИНДЕКСОВ:
КЛАСТЕРНЫЕ ИНДЕКСЫ ;
НЕКЛАСТЕРНЫЕ ИНДЕКСЫ
индексы
В СРЕДЕ SQL SERVER РЕАЛИЗОВАНО НЕСКОЛЬКО ТИПОВ ИНДЕКСОВ:
КЛАСТЕРНЫЕ ИНДЕКСЫ ;
НЕКЛАСТЕРНЫЕ ИНДЕКСЫ
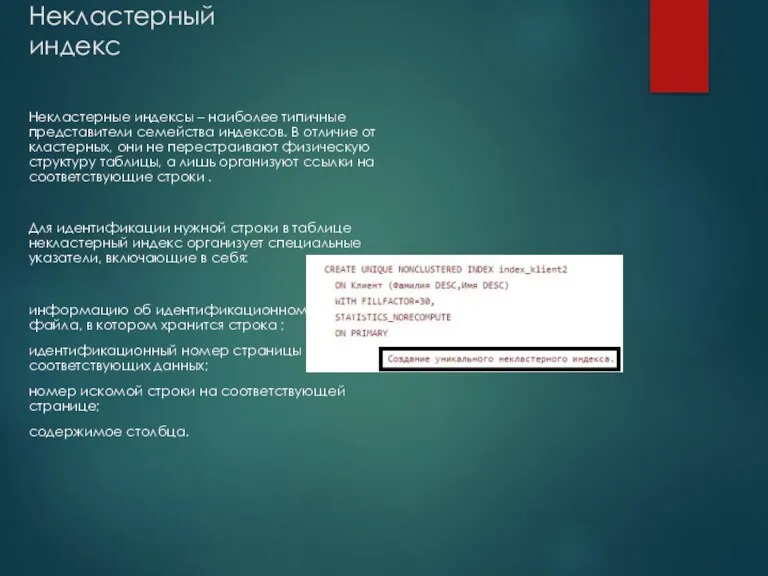
Некластерный индекс
Некластерные индексы – наиболее типичные представители семейства индексов. В отличие
Некластерный индекс
Некластерные индексы – наиболее типичные представители семейства индексов. В отличие
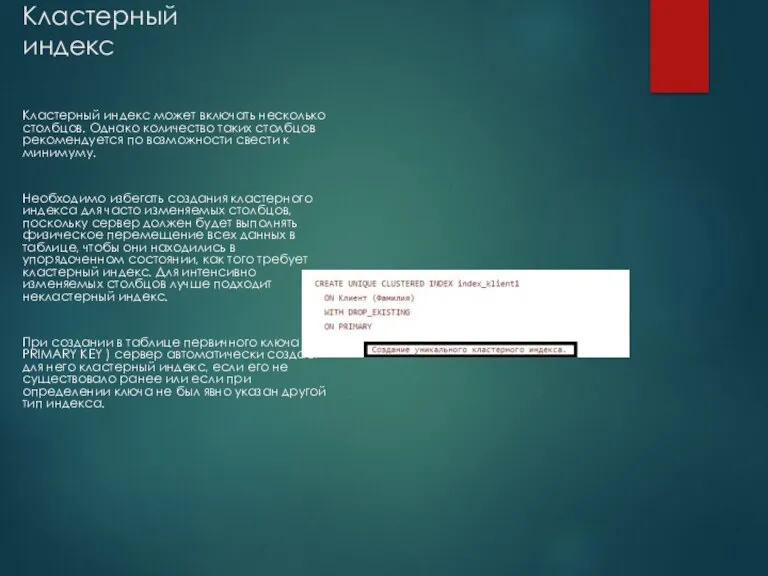
Кластерный индекс
Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов
Кластерный индекс
Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов

Уникальный индекс
Уникальный индекс является своеобразной надстройкой и может быть реализован как
Уникальный индекс
Уникальный индекс является своеобразной надстройкой и может быть реализован как

OLAP и OLTP системы
OLTP –
оперативная транзакционная обработка данных
OLAP –
оперативная аналитическая
OLAP и OLTP системы
OLTP –
оперативная транзакционная обработка данных
OLAP –
оперативная аналитическая

Характеристики OLTP системы
∙ Большой объем информации
∙ Часто различные БД для разных
Характеристики OLTP системы
∙ Большой объем информации
∙ Часто различные БД для разных
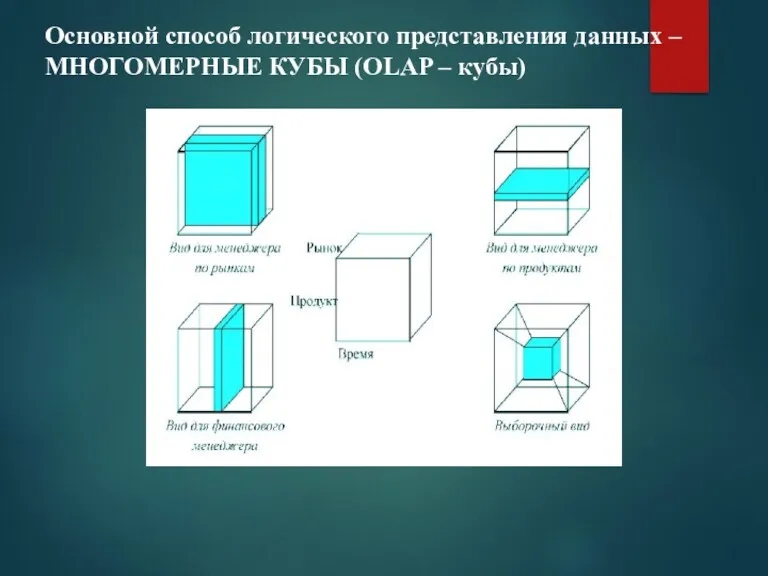
Основной способ логического представления данных –
МНОГОМЕРНЫЕ КУБЫ (OLAP – кубы)
Основной способ логического представления данных –
МНОГОМЕРНЫЕ КУБЫ (OLAP – кубы)

OLAP – куб и срезы данных
OLAP – куб и срезы данных

Правила Кодда для реляционных БД
1. Правило информации.
2. Правило гарантированного доступа.
Правила Кодда для реляционных БД
1. Правило информации.
2. Правило гарантированного доступа.

Правила Кодда для OLAP
1. Концептуальное многомерное представление.
2. Прозрачность.
3. Доступность.
4. Постоянная производительность
Правила Кодда для OLAP
1. Концептуальное многомерное представление.
2. Прозрачность.
3. Доступность.
4. Постоянная производительность

Реализация OLAP
Типы OLAP - серверов
MOLAP (Multidimensional OLAP) - и детальные данные,
Реализация OLAP
Типы OLAP - серверов
MOLAP (Multidimensional OLAP) - и детальные данные,

OLTP схема базы данных
Моделируются оптовые продажи на склад
Объекты
Склады
Категории товаров (модель)
Производители
Товары
Продавцы
Оптовые продажи
OLTP схема базы данных
Моделируются оптовые продажи на склад
Объекты
Склады
Категории товаров (модель)
Производители
Товары
Продавцы
Оптовые продажи
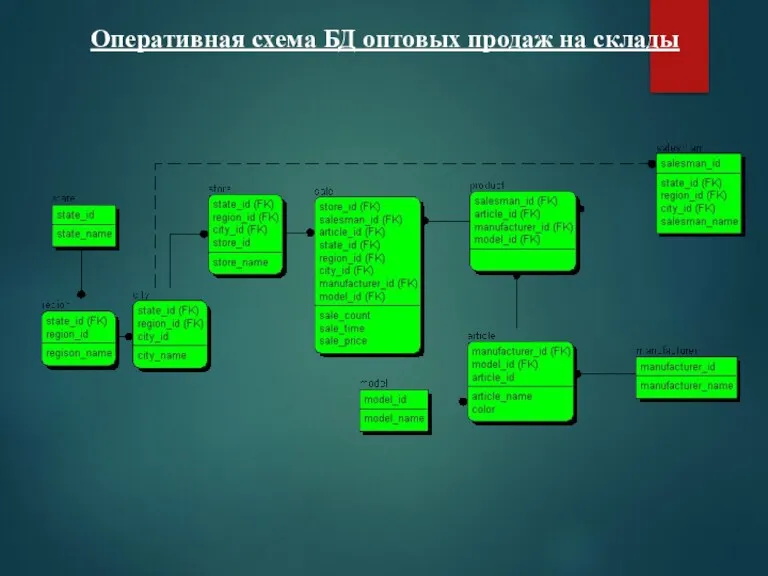
Оперативная схема БД оптовых продаж на склады
Оперативная схема БД оптовых продаж на склады
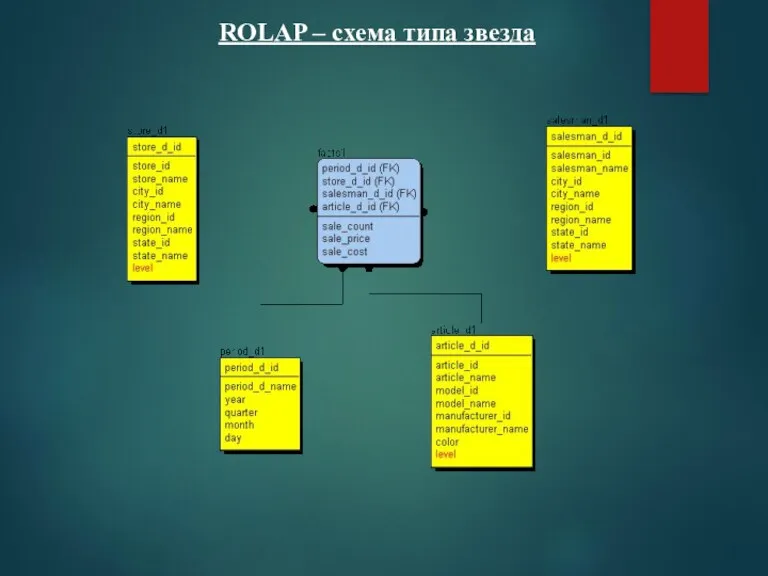
ROLAP – схема типа звезда
ROLAP – схема типа звезда

Особенности ROLAP – схемы типа звезда
Одна таблица фактов, которая сильно денормализована
Несколько
Особенности ROLAP – схемы типа звезда
Одна таблица фактов, которая сильно денормализована
Несколько
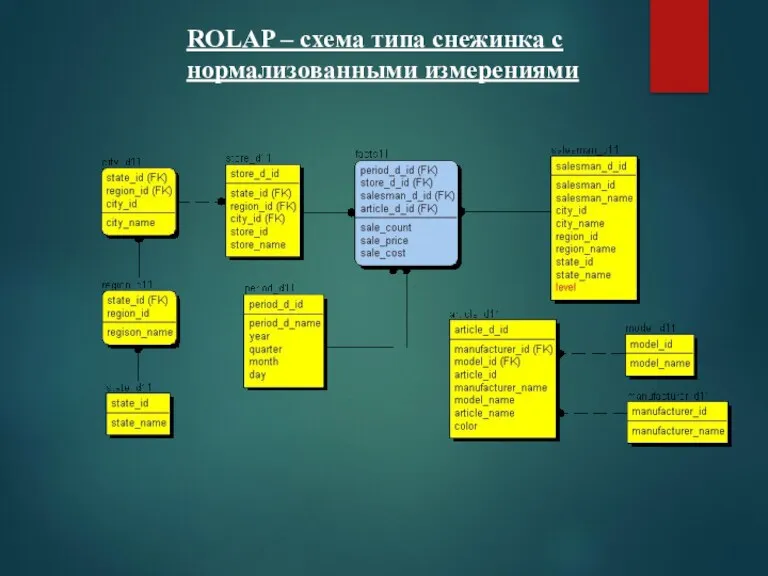
ROLAP – схема типа снежинка с
нормализованными измерениями
ROLAP – схема типа снежинка с
нормализованными измерениями
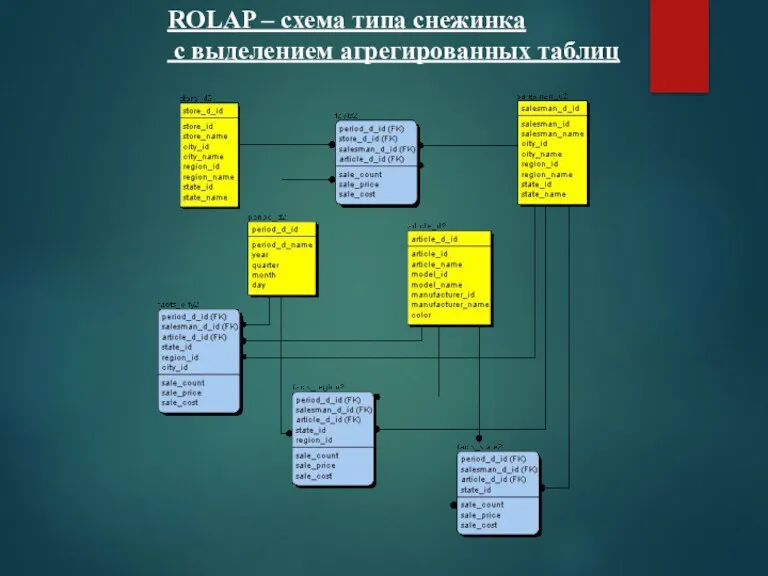
ROLAP – схема типа снежинка
с выделением агрегированных таблиц
ROLAP – схема типа снежинка
с выделением агрегированных таблиц
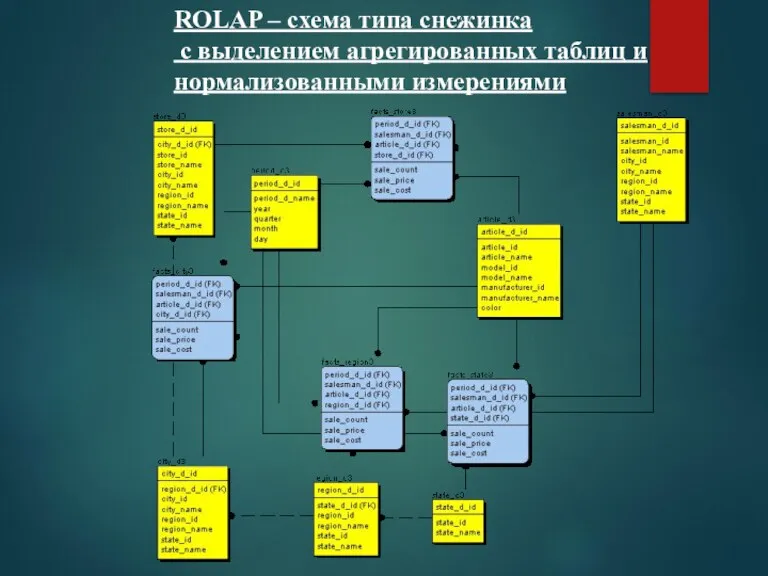
ROLAP – схема типа снежинка
с выделением агрегированных таблиц и
нормализованными
ROLAP – схема типа снежинка
с выделением агрегированных таблиц и
нормализованными
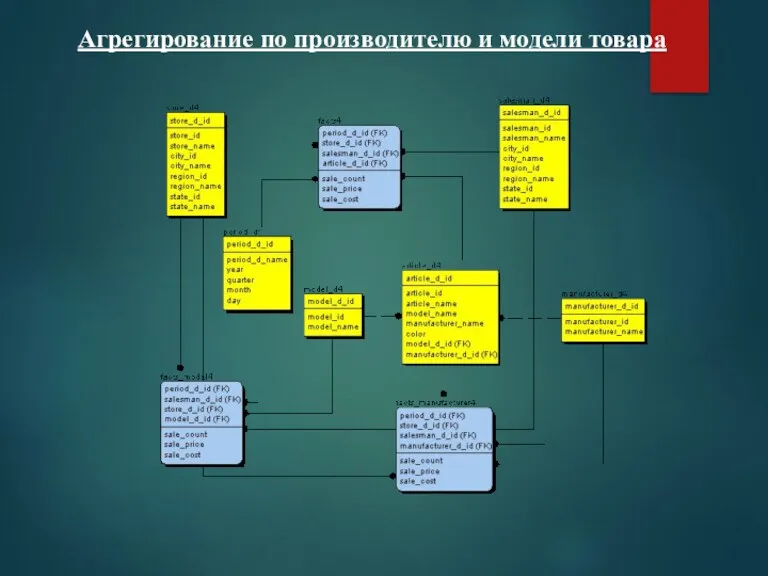
Агрегирование по производителю и модели товара
Агрегирование по производителю и модели товара

Состав хранилищ данных
Метаданные
Исходные данные
Предварительно просуммированные данные
Основные метаданные OLAP
Куб
Факты
Измерения
Уровни
Иерархии
Атрибуты
Состав хранилищ данных
Метаданные
Исходные данные
Предварительно просуммированные данные
Основные метаданные OLAP
Куб
Факты
Измерения
Уровни
Иерархии
Атрибуты
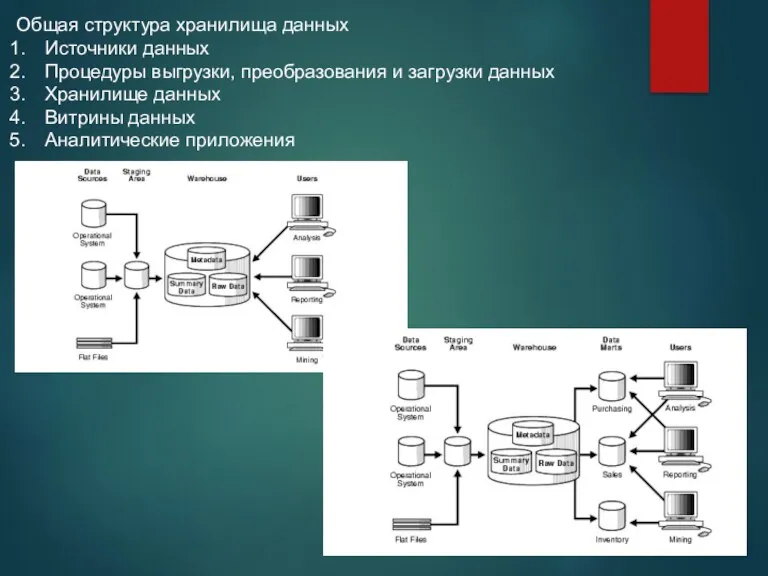
Общая структура хранилища данных
Источники данных
Процедуры выгрузки, преобразования и загрузки данных
Хранилище данных
Витрины
Общая структура хранилища данных
Источники данных
Процедуры выгрузки, преобразования и загрузки данных
Хранилище данных
Витрины
 Продукты IBM для разработки программных приложений. (Тема 9)
Продукты IBM для разработки программных приложений. (Тема 9) Основы программирования на C++
Основы программирования на C++ Единая сеть электросвязи РФ
Единая сеть электросвязи РФ Построение и исследование физической модели
Построение и исследование физической модели Базовые требования при подготовке презентаций
Базовые требования при подготовке презентаций Максимально эффективное использование ScienceDirect
Максимально эффективное использование ScienceDirect Подготовка школьников к ЕГЭ по информатике
Подготовка школьников к ЕГЭ по информатике Презентация к уроку Цикл с постусловием
Презентация к уроку Цикл с постусловием История серии видеоигры: Grand Theft Auto
История серии видеоигры: Grand Theft Auto Основы программирования на Python
Основы программирования на Python Онлайн сервис
Онлайн сервис Django. Запись данных. Урок 11
Django. Запись данных. Урок 11 Презентация к уроку Тексты в компьютерной памяти
Презентация к уроку Тексты в компьютерной памяти Информационная модель объекта
Информационная модель объекта Инструмент гарантированного доступа к госзакупкам. Портал поставщиков
Инструмент гарантированного доступа к госзакупкам. Портал поставщиков Обзор вариантов установки программ
Обзор вариантов установки программ конспект урока по информатике 9 класс по теме: Операторы ветвления+презентация
конспект урока по информатике 9 класс по теме: Операторы ветвления+презентация класс. 04.02.22
класс. 04.02.22 Вероятностный подход к определению количества информации
Вероятностный подход к определению количества информации Сети мобильной связи нового поколения. Лекция 7. Подсистема IP-мультимедиа (IMS)
Сети мобильной связи нового поколения. Лекция 7. Подсистема IP-мультимедиа (IMS) Программа курса “Введение в тестирование ПО”. Динамическое тестирование
Программа курса “Введение в тестирование ПО”. Динамическое тестирование Модели объектов. Моделирование
Модели объектов. Моделирование Мобильные вирусы и антивирусы
Мобильные вирусы и антивирусы Графикалық редакциялау
Графикалық редакциялау Проектирование программных средств
Проектирование программных средств 10 Useful, Weird or Entertaining Websites to Waste Time On
10 Useful, Weird or Entertaining Websites to Waste Time On Компьютерная графика
Компьютерная графика Программирование на языке Си
Программирование на языке Си