- Применение методов глубокого обучения к задаче конкурирующей перколяции

Содержание
- 2. Перколяция - процесс распространения текучего вещества в пористой среде Фазовый переход - наличие/отсутствие соединяющего кластера Формулы,
- 3. Понятие о конкурирующей перколяции вводится на основе пошаговой настольной игры Hex: 1. Игроки ходят по очереди
- 4. Monte Carlo Tree Search - алгоритм принятия решений, часто используемый в играх в качестве основы искусственного
- 5. Value Policy Обучение нейронной сети происходит согласно следующему алгоритму: 1. Накопление обучающей выборки, с импользованием алгоритма
- 6. Основные позиции в Hex - список некоторых теоретических позиций, на которые мы будем ссылаться при анализе
- 7. Результат обучения нейронной сети на примере размерности игрового поля Hex 4x4: На графике слева изображена зависимость
- 8. Результат обучения нейронной сети на примере размерности игрового поля Hex 5x5: - распределение нод по количеству
- 9. Материал про решетку Hex 6x6
- 11. Скачать презентацию

Перколяция - процесс распространения текучего вещества в пористой среде
Фазовый переход -
Перколяция - процесс распространения текучего вещества в пористой среде
Фазовый переход -

Понятие о конкурирующей перколяции вводится на основе пошаговой настольной игры Hex:
1. Игроки
Понятие о конкурирующей перколяции вводится на основе пошаговой настольной игры Hex:
1. Игроки

Monte Carlo Tree Search - алгоритм принятия решений, часто используемый в
Monte Carlo Tree Search - алгоритм принятия решений, часто используемый в

Value Policy
Обучение нейронной сети происходит согласно следующему алгоритму:
1. Накопление обучающей
Value Policy
Обучение нейронной сети происходит согласно следующему алгоритму:
1. Накопление обучающей
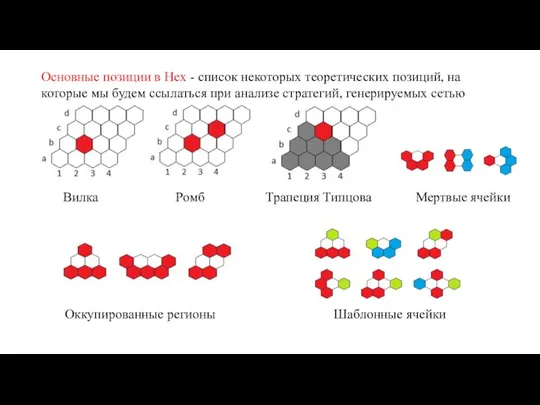
Основные позиции в Hex - список некоторых теоретических позиций, на которые
Основные позиции в Hex - список некоторых теоретических позиций, на которые
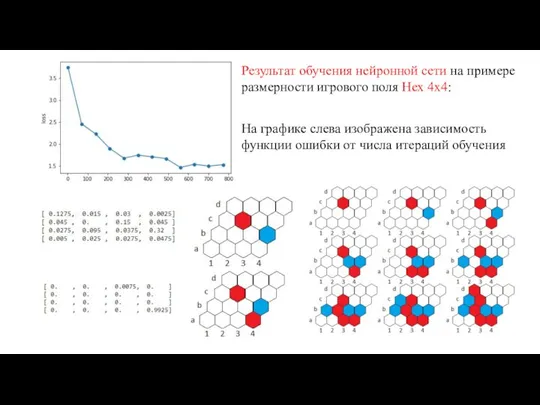
Результат обучения нейронной сети на примере размерности игрового поля Hex 4x4:
На
Результат обучения нейронной сети на примере размерности игрового поля Hex 4x4:
На
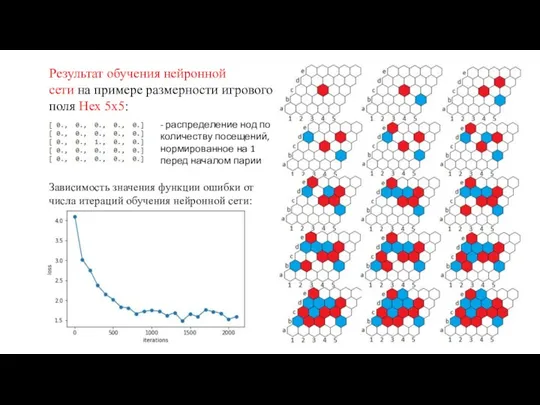
Результат обучения нейронной сети на примере размерности игрового поля Hex 5x5:
- распределение нод по
Результат обучения нейронной сети на примере размерности игрового поля Hex 5x5:
- распределение нод по

Материал про решетку Hex 6x6
Материал про решетку Hex 6x6
 Основы программирования. Основы языка программирования С/С++
Основы программирования. Основы языка программирования С/С++ Основные понятия информатики
Основные понятия информатики Коммуникациялық технологиялар
Коммуникациялық технологиялар Сервисно-ориентированные архитектуры. Анализ интересов клиента. Выбор вариантов решений
Сервисно-ориентированные архитектуры. Анализ интересов клиента. Выбор вариантов решений Роль и функции IT-инфраструктуры в деятельности организации. Стандарты и методики управления IT-инфраструктурой
Роль и функции IT-инфраструктуры в деятельности организации. Стандарты и методики управления IT-инфраструктурой Основы программирования. Введение
Основы программирования. Введение Количественные параметры информационных объектов. Задания
Количественные параметры информационных объектов. Задания Presentation template
Presentation template Растровая графика – рисование в Paint
Растровая графика – рисование в Paint B и Красно-Черные деревья
B и Красно-Черные деревья Технология WEB страниц
Технология WEB страниц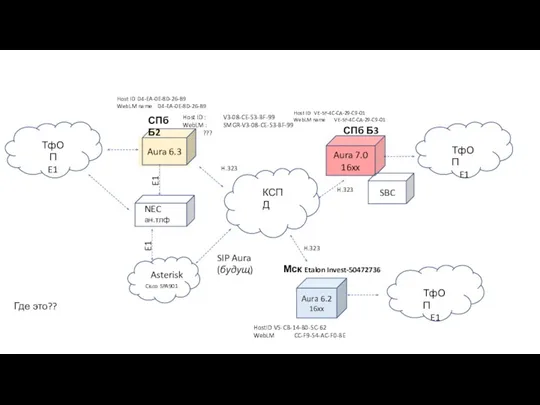 Одна распределённая станция Avaya, все сервисы через SIP. Миграция сервисов NEC и Asterisk на Avaya Aura
Одна распределённая станция Avaya, все сервисы через SIP. Миграция сервисов NEC и Asterisk на Avaya Aura Операторы графики языка программирования QBasic.
Операторы графики языка программирования QBasic. Интеллектуальные информационные системы. Искусственный интеллект
Интеллектуальные информационные системы. Искусственный интеллект Продвижение в Instagram
Продвижение в Instagram Introduction to the course. Managing the application life cycle
Introduction to the course. Managing the application life cycle Открытый урок в 5 классе по теме Кодирование информации
Открытый урок в 5 классе по теме Кодирование информации Инструкция по обновлению BIOS Для win8
Инструкция по обновлению BIOS Для win8 Системы счисления (1, 10, 16)
Системы счисления (1, 10, 16) Разработка приложений в среде MS Office. Лекция 1
Разработка приложений в среде MS Office. Лекция 1 Классификация инженерно-технических средств безопасности
Классификация инженерно-технических средств безопасности Strings. Класс String в Java
Strings. Класс String в Java Ecommerce. Shopping on the Internet
Ecommerce. Shopping on the Internet Алгоритмы обработки массивов
Алгоритмы обработки массивов Использование голосового помощника Маруся в образовании
Использование голосового помощника Маруся в образовании Сетевые информационные системы
Сетевые информационные системы Искусственный интеллект
Искусственный интеллект Бездротові мережі
Бездротові мережі