- Процессоры. Принципы работы

Содержание
- 2. ОУ состоят из ОЭ, которые могут работать одновременно Команда (инструкция) – совокупность операций, н-р, сложение векторов
- 3. Работа проц. циклична Командный цикл 1 2 3 4 5
- 4. 1- извлечение команд из памяти, 2- их декодирование 3- извлечение данных, 4- выполнение, 5- запись результата
- 5. Исполняемая команда помещается в регистр команд Декодирование команды – её разбиение на (микро)операции – раздача заданий
- 6. Адрес следующей команды хранится в регистре «указатель инструкций» (instruction pointer) Как изменяется адрес: если текущая команда
- 7. Адреса данных и сами данные хранятся в регистрах общего назначения Н-р, в архитектуре x86
- 8. 2. Типы команд по типу ячеек (R-reg., M-mem.) - R1,R2->R3 - M1,M2->M3 - R1->M1 - …………………
- 9. по типу операндов - скалярные: число - векторные: массив чисел Векторные команды дают экономию на 1,2
- 10. 3. «Одновременное» выполнение задач (программ) Однопотоковый ЦП «создаёт иллюзию» одновременности ОС вычисляет кванты времени для задачи
- 11. ЦП по прерываниям от таймера периодически сохраняет в кэше содержимое регистров, доступных текущей задаче переключается на
- 12. Многопотоковый процессор имеет несколько декодеров команд регистров команд IP АЛУ Много конвейеров и/или ядер Брахма
- 13. Ядро – часть процессора, выполняющая хотя бы 2-4 этапы командного цикла Общие кэш высокого уровня системная
- 14. Виртуальная машина – это программная среда, позволяющая запускать несколько ОС (одинаковых или разных) квазипараллельно
- 15. 4. Пути повышения производительности SpeedDaemon – за счёт роста частоты Brainiac – поумнение УУ, кэша, паралл.
- 16. Конвейеризация (pipelining) Процессорный цикл разбит на простые операции
- 17. Если программа не оптимизирована под данный конвейер, то появляются холостые такты Можно увеличить частоту Но! Эффективная
- 18. Суперскалярность – динамическое расщепление потока операций
- 19. Предсказание переходов – УУ прогнозирует направление условного перехода и, не дожидаясь его, выполняет 1 и 2
- 20. Предсказание Статическое – на основе «опыта предков», зашито в УУ Динамическое – на основе текущей статистики
- 21. Если предсказание сбылось (98-99 % !), то ЦП не зря работал без «перерыва» Экономия времени до
- 22. Исполнение по предположению (speculative execution) – выполняются все этапы! Но при неудаче конвейер очищается много тактов
- 23. Внеочередное исполнение – порядок исполнения команд может меняться если их результаты независимы Но в СШ результаты
- 24. Переименование регистров – если команды одновременно обращаются к одному регистру, его можно «размножить», используя запасные регистры
- 26. Скачать презентацию

ОУ состоят из ОЭ, которые могут работать одновременно
Команда (инструкция)
ОУ состоят из ОЭ, которые могут работать одновременно
Команда (инструкция)
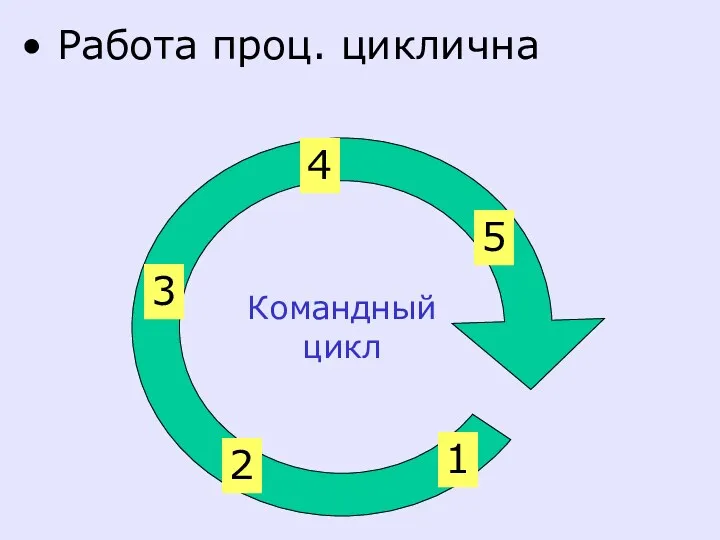
Работа проц. циклична
Командный
цикл
1
2
3
4
5
Работа проц. циклична
Командный
цикл
1
2
3
4
5

1- извлечение команд из памяти,
2- их декодирование
3- извлечение данных,
4- выполнение,
5- запись
1- извлечение команд из памяти,
2- их декодирование
3- извлечение данных,
4- выполнение,
5- запись

Исполняемая команда помещается в регистр команд
Декодирование команды – её разбиение на
Исполняемая команда помещается в регистр команд
Декодирование команды – её разбиение на

Адрес следующей команды хранится в регистре «указатель инструкций» (instruction pointer)
Как изменяется
Адрес следующей команды хранится в регистре «указатель инструкций» (instruction pointer)
Как изменяется

Адреса данных и сами данные хранятся в регистрах общего назначения
Н-р, в
Адреса данных и сами данные хранятся в регистрах общего назначения
Н-р, в

2. Типы команд
по типу ячеек (R-reg., M-mem.)
- R1,R2->R3
-
2. Типы команд
по типу ячеек (R-reg., M-mem.)
- R1,R2->R3
-

по типу операндов
- скалярные: число
- векторные: массив чисел
Векторные
по типу операндов
- скалярные: число
- векторные: массив чисел
Векторные

3. «Одновременное» выполнение задач (программ)
Однопотоковый ЦП «создаёт иллюзию» одновременности
ОС вычисляет кванты
3. «Одновременное» выполнение задач (программ)
Однопотоковый ЦП «создаёт иллюзию» одновременности
ОС вычисляет кванты

ЦП по прерываниям от таймера периодически
сохраняет в кэше содержимое регистров,
ЦП по прерываниям от таймера периодически
сохраняет в кэше содержимое регистров,

Многопотоковый процессор имеет несколько
декодеров команд
регистров команд
IP
АЛУ
Много конвейеров
Многопотоковый процессор имеет несколько
декодеров команд
регистров команд
IP
АЛУ
Много конвейеров

Ядро – часть процессора, выполняющая хотя бы 2-4 этапы командного цикла
Общие
Ядро – часть процессора, выполняющая хотя бы 2-4 этапы командного цикла
Общие

Виртуальная машина – это программная среда,
позволяющая запускать несколько ОС (одинаковых
Виртуальная машина – это программная среда,
позволяющая запускать несколько ОС (одинаковых
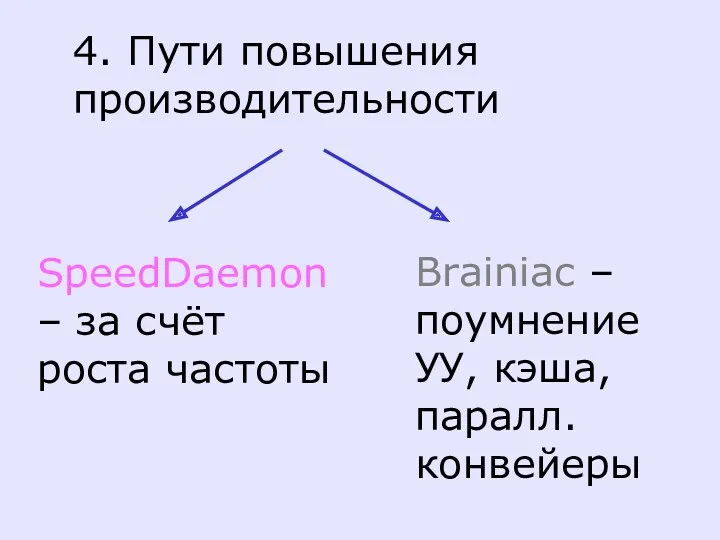
4. Пути повышения производительности
SpeedDaemon
– за счёт роста частоты
Brainiac – поумнение УУ,
4. Пути повышения производительности
SpeedDaemon
– за счёт роста частоты
Brainiac – поумнение УУ,
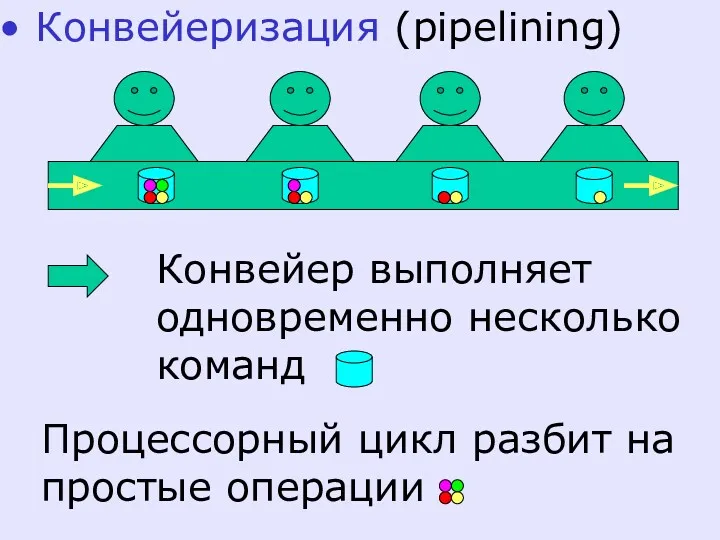
Конвейеризация (pipelining)
Процессорный цикл разбит на простые операции
Конвейеризация (pipelining)
Процессорный цикл разбит на простые операции

Если программа не оптимизирована под данный конвейер, то появляются холостые такты
Можно
Если программа не оптимизирована под данный конвейер, то появляются холостые такты
Можно
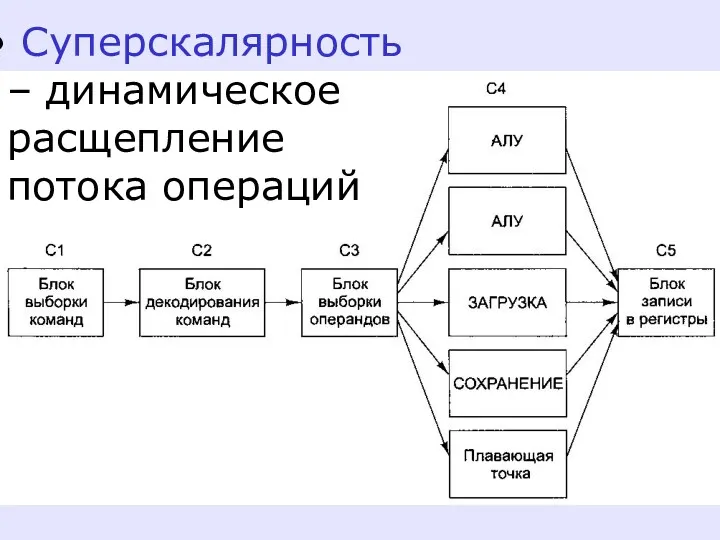
Суперскалярность – динамическое расщепление потока операций
Суперскалярность – динамическое расщепление потока операций
Предсказание переходов – УУ прогнозирует направление условного перехода и, не
Предсказание переходов – УУ прогнозирует направление условного перехода и, не
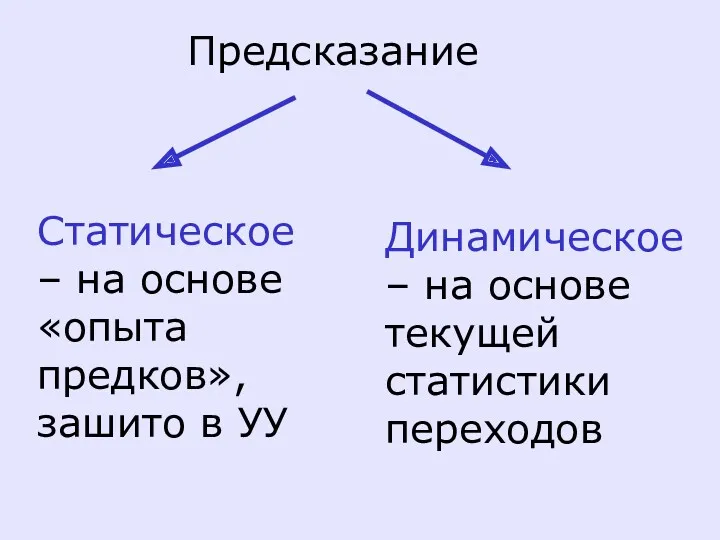
Предсказание
Статическое – на основе «опыта предков», зашито в УУ
Динамическое –
Предсказание
Статическое – на основе «опыта предков», зашито в УУ
Динамическое –

Если предсказание сбылось (98-99 % !), то ЦП не зря работал
Если предсказание сбылось (98-99 % !), то ЦП не зря работал

Исполнение по предположению (speculative execution) – выполняются все этапы!
Но при
Исполнение по предположению (speculative execution) – выполняются все этапы!
Но при

Внеочередное исполнение – порядок исполнения команд может меняться если их
Внеочередное исполнение – порядок исполнения команд может меняться если их

Переименование регистров – если команды одновременно обращаются к одному регистру,
Переименование регистров – если команды одновременно обращаются к одному регистру,
 Угадай и отгадай!
Угадай и отгадай! Своя игра по информатике, 9 класс
Своя игра по информатике, 9 класс Организация глобальных сетей
Организация глобальных сетей Компания ООО Отдел ИТ
Компания ООО Отдел ИТ ПрезентацияПоGpss №10
ПрезентацияПоGpss №10 Принцип построения логической пирамиды при создании деловых документов. (Тема 9)
Принцип построения логической пирамиды при создании деловых документов. (Тема 9) Код. Кодирование.
Код. Кодирование. Операции и стандартные функции Turbo Pascal 7.0
Операции и стандартные функции Turbo Pascal 7.0 Формы представления чисел в ЭВМ
Формы представления чисел в ЭВМ Цели, задачи, этапы и объекты ревьюирования. Лекция №2
Цели, задачи, этапы и объекты ревьюирования. Лекция №2 Types and basic structures data in R
Types and basic structures data in R Университет Дубна. Библиографический поиск и описание при подготовке рефератов, курсовых и дипломных работ
Университет Дубна. Библиографический поиск и описание при подготовке рефератов, курсовых и дипломных работ Alfa Factory. Application Rulesets
Alfa Factory. Application Rulesets Процесс создания игры
Процесс создания игры Правовые нормы, относящиеся к информации, правонарушения в информационной сфере, меры их предупреждения
Правовые нормы, относящиеся к информации, правонарушения в информационной сфере, меры их предупреждения презентация к уроку Информационные технологии з класс
презентация к уроку Информационные технологии з класс Стан та перспективи розвитку електронної комерції у світі. Особливості інтернет-торгівлі у Китаї
Стан та перспективи розвитку електронної комерції у світі. Особливості інтернет-торгівлі у Китаї Антивирусные программы
Антивирусные программы Вёрстка и дизайн газетной статьи
Вёрстка и дизайн газетной статьи Введение в Python. Как используется?
Введение в Python. Как используется? MS DOS операциялық жүйесі
MS DOS операциялық жүйесі Технология ATM. (Лекция 3)
Технология ATM. (Лекция 3) Межсетевые экраны
Межсетевые экраны Защита медицинской информации
Защита медицинской информации Методика обучения информатике в школе с использованием образовательных онлайн платформ
Методика обучения информатике в школе с использованием образовательных онлайн платформ Wi-Fi с авторизацией
Wi-Fi с авторизацией От скуки на все руки
От скуки на все руки Компьютерная арифметика (§ 26 - § 30)
Компьютерная арифметика (§ 26 - § 30)