- Работа в СУБД PostgreSQL. Индексы и оптимизация запросов

Содержание
- 2. Устранение дубликатов Приведение информации к унифицированному виду (типичный пример – написание названия одной страны разными способами,
- 3. Строковые функции UPPER – преобразует все символы строки в верхний регистр. LOWER – преобразует все символы
- 4. Строковые функции SUBSTR – извлекает подстроку из строки REPLACE – заменяет последовательность символов в строке другим
- 5. Регулярные выражения regexp_match regexp_matches regexp_replace
- 6. Регулярные выражения regexp_split_to_table
- 7. Регулярные выражения split_part substring
- 8. Регулярные выражения ^ — начало строки; $ — конец строки; . — любой символ; * –
- 10. Регулярные выражения Специальные метасимволы, ими можно заменить некоторые готовые конструкции: \b — обозначает не символ, а
- 14. Пример Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите
- 15. Пример выбора фамилии и города select regexp_substr(t.dt,'[^,]+',1,1) f, regexp_substr(t.dt,'[^,]+',1,3) city from regtest t
- 16. Иерархические запросы Данные, которые находятся в таблице, могут быть иерархически упорядочены, например, иметь порядок Начальник-Подчинённый. Запросы,
- 17. Порядок строк это хорошо, но нам было бы трудно понять, две строки рядом это родитель и
- 18. Файловые менеджеры обычно пишут путь к каталогу, в котором вы находитесь: /home/maovrn/documents/ и т.п. Используем функцию
- 19. Оператор PRIOR ссылался к родительской записи Помимо него есть другой унарный оператор CONNECT_BY_ROOT, который ссылается на
- 20. Воспользовавшись методом regexp_substr в сочетании с командой CONNECT by можно преобразовать каждую подстроку с разделителями в
- 21. ССЫЛКА НА САЙТ https://tproger.ru/articles/regexp-for-beginners/
- 22. Задание Перейти на сайт и составить краткий конспект по основам синтаксиса регулярных выражений Использование регулярных выражений
- 23. Задание для самостоятельного выполнения Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть #
- 24. Этапы выполнения запроса Запрос, поступающий̆ серверу на выполнение, проходит несколько этапов: Разбор Трансформация Планирование Выполнение
- 25. Разбор Лексический анализатор разбирает текст запроса на лексемы (такие как ключевые слова, строковые и числовые литералы
- 26. Разобранный̆ запрос представляется в виде абстрактного синтаксического дерева Для него в памяти обслуживающего процесса будет построено
- 27. Семантический̆ разбор Задача семантического анализа — определить, есть ли в базе данных таблицы и другие объекты,
- 28. Трансформация Далее запрос может трансформироваться (переписываться) Трансформации используются ядром для нескольких целей̆, одна из них —
- 29. Планирование SQL — декларативный̆ язык: запрос определяет, какие данные надо получить, но не говорит, как именно
- 30. Дерево плана План выполнения также представляется в виде дерева, но его узлы содержат не логические, а
- 31. Основные узлы дерева выведены на рисунке (слайд ранее) В выводе команды EXPLAIN они отмечены стрелочками. -
- 32. Перебор планов PostgreSQL использует стоимостной̆ оптимизатор Оптимизатор рассматривает всевозможные планы и оценивает предполагаемое количество ресурсов, необходимых
- 33. Для сокращения вариантов перебора Общие табличные выражения обычно оптимизируются отдельно от основного запроса; в версии 12
- 34. Оптимизатор Один и тот же оператор SQL можно выполнить несколькими способами, и задача оптимизатора запросов состоит
- 35. План запроса Чтобы разработать наилучший план выполнения любого оператора SQL, оптимизатор Оценивает возможные пути доступа, порядки
- 36. Оптимизация запроса Для оптимизации запроса обычно проделывают следующие действия: 1. Проверить что запрос написан правильно (условия
- 37. Для такого запроса планировщик будет рассматривать все возможные порядки соединения SELECT ... FROM a, b JOIN
- 38. Выполнение Оптимизированный̆ запрос выполняется в соответствии с планом В памяти обслуживающего процесса создается портал — объект,
- 39. Пример /*+ NestLoop(t1 t2) */ /*+ MergeJoin(t1 t2) */ /*+ Leading(t1 t2) */
- 40. EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN [ ANALYZE ] [ VERBOSE ]
- 41. ANALYZE собирает статистику о базе данных ANALYZE [ VERBOSE ] [ table_name [ ( column_name [,
- 43. Физические операции соединения
- 44. МЕТОДЫ СОЕДИНЕНИЙ Соединение вложенных циклов Соединение вложенными циклами. Встречаются очень часто. Выполняют довольно эффективное соединение относительно
- 45. Соединение слиянием. Редко встречаются в реальных запросах, как правило, являются наиболее эффективными из операторов логического соединения.
- 46. Операция используется всегда, когда невозможно применить другие виды соединения. Она выбираются оптимизатором запросов по одной из
- 47. Расширенные запросы Неудобство простого способа выполнения запросов состоит в том, что клиент получает всю выборку сразу,
- 48. Подготовка На этапе подготовки запрос разбирается и трансформируется обычным образом, но полученное дерево разбора сохраняется в
- 49. Планирование и выполнение В некоторых случаях планировщик запоминает не только дерево разбора, но и план запроса,
- 50. Получение результатов Протокол расширенных запросов позволяет клиенту получать не все результирующие строки сразу, а выбирать данные
- 51. ИНДЕКСЫ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
- 52. Доступ к данным По уникальному идентификатору По индексу Полное сканирование таблицы
- 53. ИНДЕКСЫ индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы
- 54. Применение индексов Индексы обеспечивают быстрый доступ к строкам таблиц в базе данных, сохраняя отсортированные значения указанных
- 55. Виды индексов Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце — обычно вроде номера
- 56. Индексы и ключи Индекс (англ. index) — объект базы данных, создаваемый с целью повышения производительности поиска
- 57. Рекомендации по созданию эффективных индексов в базе данных Индексация имеет смысл, если нужно обеспечить доступ одновременно
- 58. Рекомендации по созданию эффективных индексов в базе данных Избегайте создания индексов для сравнительно небольших таблиц. Для
- 59. Рекомендации по созданию эффективных индексов в базе данных Индексируйте столбцы, участвующие в многотабличных операциях соединения Индексируйте
- 60. Рекомендации по созданию эффективных индексов в базе данных Oracle Столбцы, состоящие из длинно-символьных строк, обычно плохие
- 61. Создание индекса CREATE INDEX ИмяИндекса ON ИмяТаблицы(ИндексируемыеПоля)
- 62. Способы создание индексов CREATE INDEX ALTER TABLE table_name ADD INDEX [index_name] (index_col_name,...) Имя индекса должны быть
- 63. ДЗ Написать инструкции SQL для создания индекса в таблице базы данных ИЗ (по выбору), инструкцию для
- 64. Статистика Базовая статистика уровня отношения хранится в системном каталоге в таблице pg_class К ней относятся: число
- 65. Статистика работы PostgreSQL PostgreSQL собирает статистику с помощью фонового процесса “stats collector” (коллектор статистики) Эта статистика
- 66. Просмотр статистики для одной таблицы seq_scan – сколько раз выполнялось последовательное чтение всей таблицы;
- 67. relid – идентификатор базы; schemaname – имя схемы; relname – имя таблицы; seq_scan – сколько раз
- 68. ПРОСМОТР СТАТИСТИКИ ПО БАЗЕ ДАННЫХ tup_inserted – сколько строк было вставлено; tup_updated – сколько строк было
- 69. ПАРТИЦИОНИРОВАНИЕ Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным
- 70. Методы секционирования Повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы достигается за счет того,
- 71. Фрагментация - разделение таблицы или индекса на несколько логически связанных частей , фрагментов, секций с неким
- 72. select * from таблица partition (фрагмент); С помощью оператора SELECT есть возможность выбирать как все данные
- 73. Пример Предположим, что мы создаём базу данных для большой компании, торгующей мороженым. Компания учитывает максимальную температуру
- 74. Создание секций В нашем примере каждая секция должна содержать данные за один месяц, чтобы данные можно
- 75. Если вы хотите реализовать вложенное секционирование, дополнительно укажите предложение PARTITION BY в командах, создающих отдельные секции,
- 76. Обслуживание секций Обычно набор секций, образованный изначально при создании таблиц, не предполагается сохранять неизменным. Чаще наоборот,
- 77. Ограничения С секционированными таблицами связаны следующие ограничения: Ограничения уникальности (а значит и первичные ключи) в секционированных
- 78. Секционирование с использованием наследования Добавим в дочерние таблицы неперекрывающиеся ограничения, определяющие допустимые значения ключей для каждой
- 79. Перенаправление добавляемых строк в соответствующую дочернюю таблицу можно реализовать определив триггер для главной таблицы или правила
- 80. Оптимизация запросов к секционным таблицам Устранение секций — это приём оптимизации запросов, который ускоряет работу с
- 81. Оптимизация запросов к секционным таблицам Исключение по ограничению — приём оптимизации запросов, подобный устранению секций. Прежде
- 83. Скачать презентацию

Устранение дубликатов
Приведение информации к унифицированному виду (типичный пример – написание названия
Устранение дубликатов
Приведение информации к унифицированному виду (типичный пример – написание названия

Строковые функции
UPPER – преобразует все символы строки в верхний регистр.
LOWER
Строковые функции
UPPER – преобразует все символы строки в верхний регистр.
LOWER

Строковые функции
SUBSTR – извлекает подстроку из строки
REPLACE – заменяет последовательность символов
Строковые функции
SUBSTR – извлекает подстроку из строки
REPLACE – заменяет последовательность символов
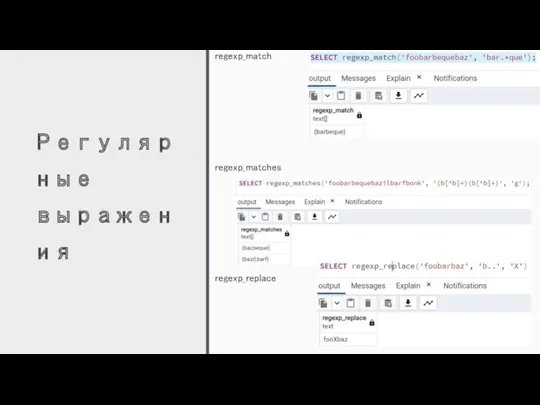
Регулярные выражения
regexp_match
regexp_matches
regexp_replace
Регулярные выражения
regexp_match
regexp_matches
regexp_replace
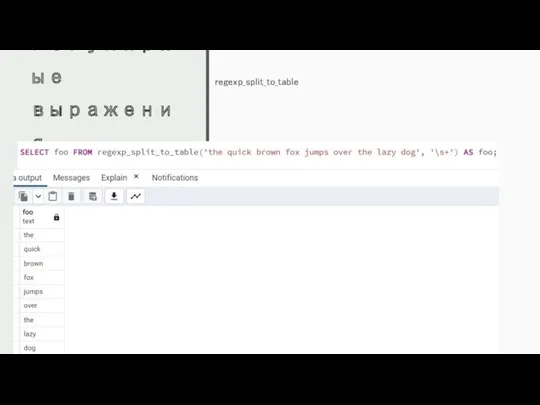
Регулярные выражения
regexp_split_to_table
Регулярные выражения
regexp_split_to_table
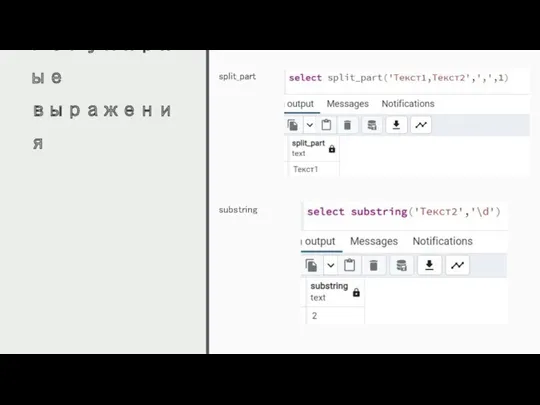
Регулярные выражения
split_part
substring
Регулярные выражения
split_part
substring

Регулярные выражения
^ — начало строки;
$ — конец строки;
. — любой символ;
*
Регулярные выражения
^ — начало строки;
$ — конец строки;
. — любой символ;
*

Регулярные выражения
Специальные метасимволы, ими можно заменить некоторые готовые конструкции:
\b — обозначает
Регулярные выражения
Специальные метасимволы, ими можно заменить некоторые готовые конструкции:
\b — обозначает
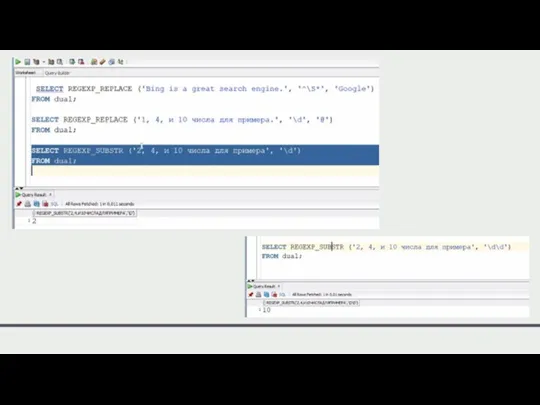
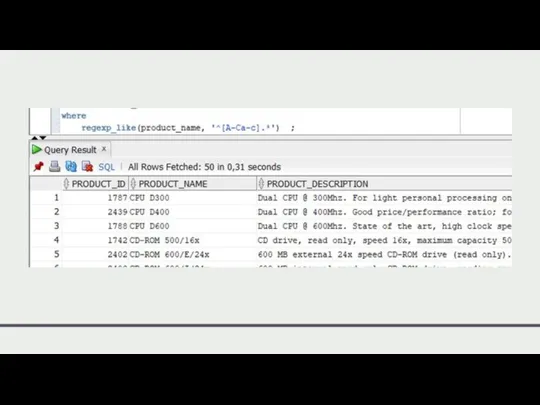
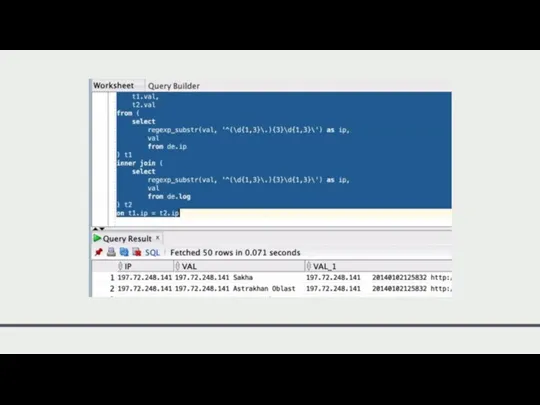
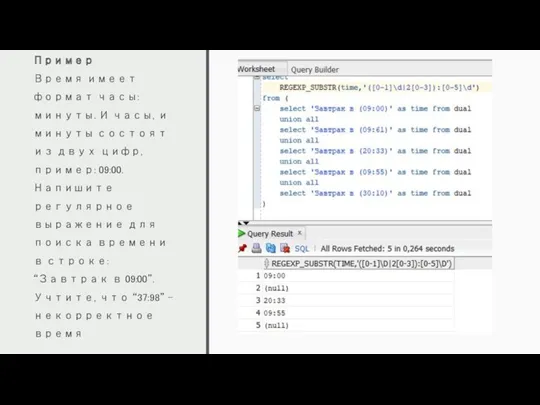
Пример
Время имеет формат часы:минуты. И часы, и минуты состоят из двух
Пример Время имеет формат часы:минуты. И часы, и минуты состоят из двух
![Пример выбора фамилии и города select regexp_substr(t.dt,'[^,]+',1,1) f, regexp_substr(t.dt,'[^,]+',1,3) city from regtest t](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/601770/slide-14.jpg)
Пример выбора фамилии и города
select
regexp_substr(t.dt,'[^,]+',1,1) f, regexp_substr(t.dt,'[^,]+',1,3) city from
regtest
Пример выбора фамилии и города
select
regexp_substr(t.dt,'[^,]+',1,1) f, regexp_substr(t.dt,'[^,]+',1,3) city from
regtest
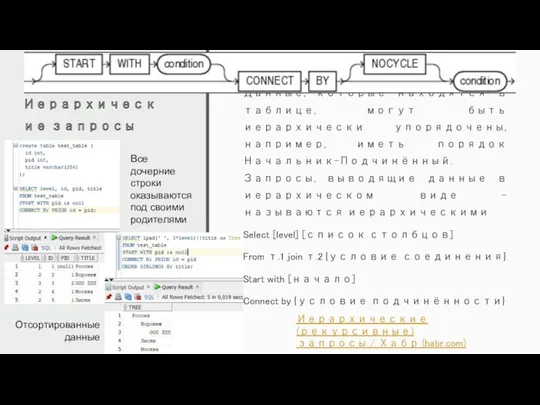
Иерархические запросы
Данные, которые находятся в таблице, могут быть иерархически упорядочены, например,
Иерархические запросы
Данные, которые находятся в таблице, могут быть иерархически упорядочены, например,
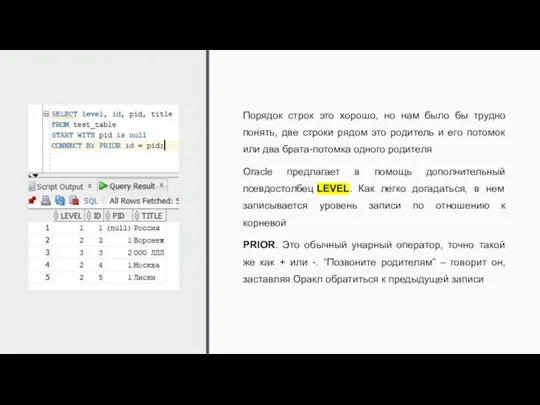
Порядок строк это хорошо, но нам было бы трудно понять, две
Порядок строк это хорошо, но нам было бы трудно понять, две
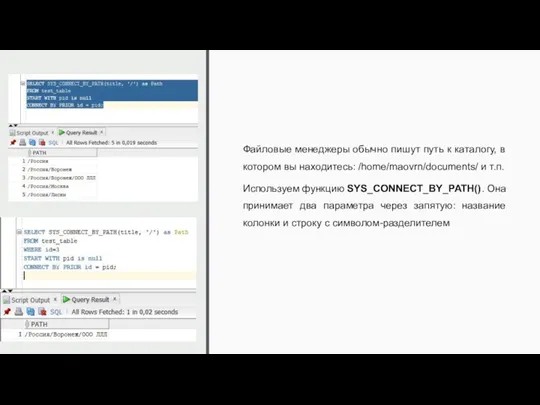
Файловые менеджеры обычно пишут путь к каталогу, в котором вы находитесь:
Файловые менеджеры обычно пишут путь к каталогу, в котором вы находитесь:
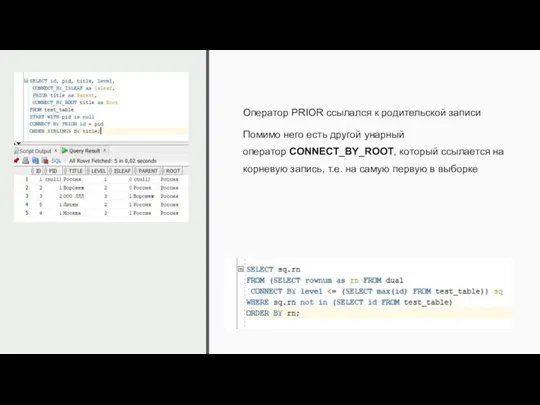
Оператор PRIOR ссылался к родительской записи
Помимо него есть другой унарный оператор CONNECT_BY_ROOT,
Оператор PRIOR ссылался к родительской записи
Помимо него есть другой унарный оператор CONNECT_BY_ROOT,
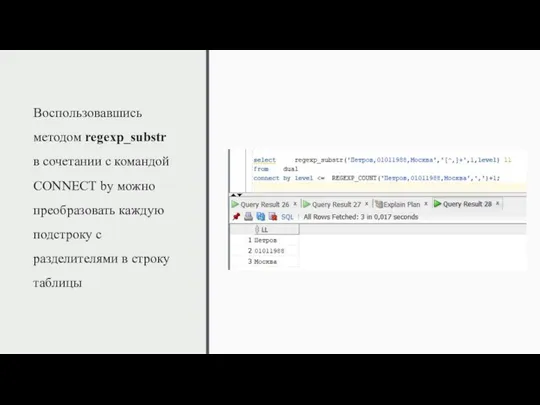
Воспользовавшись методом regexp_substr в сочетании с командой CONNECT by можно преобразовать
Воспользовавшись методом regexp_substr в сочетании с командой CONNECT by можно преобразовать

ССЫЛКА НА САЙТ
https://tproger.ru/articles/regexp-for-beginners/
ССЫЛКА НА САЙТ
https://tproger.ru/articles/regexp-for-beginners/

Задание
Перейти на сайт и составить краткий конспект по основам синтаксиса регулярных
Задание
Перейти на сайт и составить краткий конспект по основам синтаксиса регулярных

Задание для самостоятельного выполнения
Напишите регулярное выражение для поиска HTML-цвета, заданного как
Задание для самостоятельного выполнения
Напишите регулярное выражение для поиска HTML-цвета, заданного как

Этапы выполнения запроса
Запрос, поступающий̆ серверу на выполнение, проходит несколько этапов:
Разбор
Трансформация
Планирование
Выполнение
Этапы выполнения запроса
Запрос, поступающий̆ серверу на выполнение, проходит несколько этапов:
Разбор
Трансформация
Планирование
Выполнение

Разбор
Лексический анализатор разбирает текст запроса на лексемы (такие как ключевые слова, строковые и числовые
Разбор
Лексический анализатор разбирает текст запроса на лексемы (такие как ключевые слова, строковые и числовые
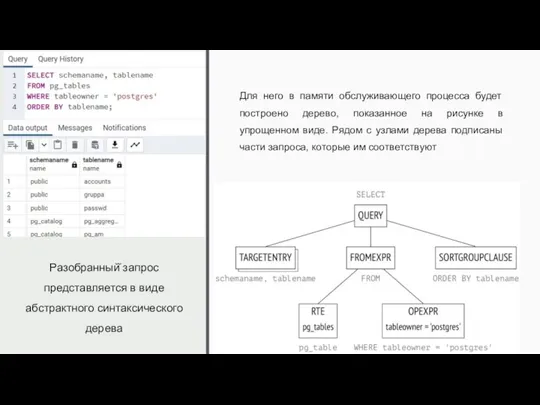
Разобранный̆ запрос представляется в виде абстрактного синтаксического дерева
Для него в памяти
Разобранный̆ запрос представляется в виде абстрактного синтаксического дерева
Для него в памяти

Семантический̆ разбор
Задача семантического анализа — определить, есть ли в базе данных таблицы и
Семантический̆ разбор
Задача семантического анализа — определить, есть ли в базе данных таблицы и
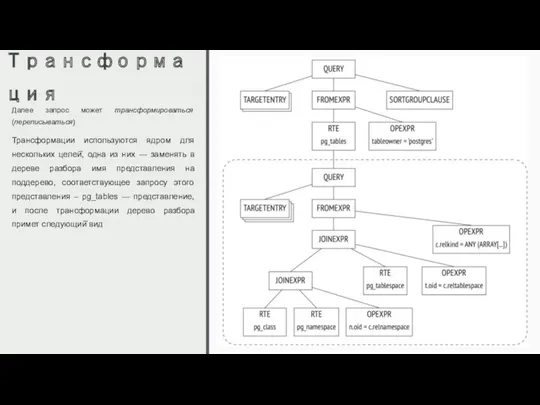
Трансформация
Далее запрос может трансформироваться (переписываться)
Трансформации используются ядром для нескольких целей̆, одна
Трансформация
Далее запрос может трансформироваться (переписываться)
Трансформации используются ядром для нескольких целей̆, одна

Планирование
SQL — декларативный̆ язык: запрос определяет, какие данные надо получить, но не говорит, как
Планирование
SQL — декларативный̆ язык: запрос определяет, какие данные надо получить, но не говорит, как
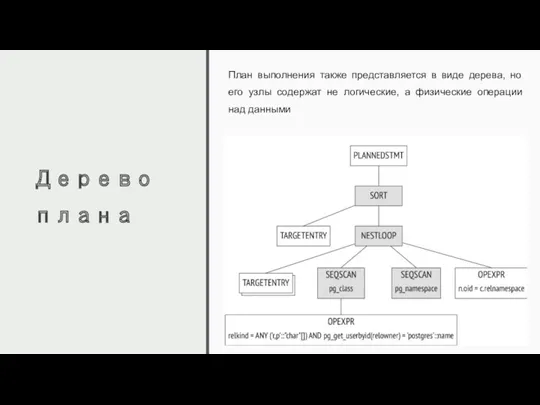
Дерево плана
План выполнения также представляется в виде дерева, но его узлы
Дерево плана
План выполнения также представляется в виде дерева, но его узлы
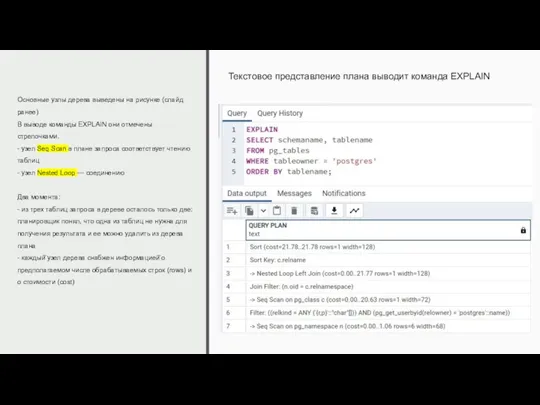
Основные узлы дерева выведены на рисунке (слайд ранее)
В выводе команды EXPLAIN
Основные узлы дерева выведены на рисунке (слайд ранее) В выводе команды EXPLAIN

Перебор планов
PostgreSQL использует стоимостной̆ оптимизатор
Оптимизатор рассматривает всевозможные планы и оценивает предполагаемое
Перебор планов
PostgreSQL использует стоимостной̆ оптимизатор
Оптимизатор рассматривает всевозможные планы и оценивает предполагаемое

Для сокращения вариантов перебора
Общие табличные выражения обычно оптимизируются отдельно от
Для сокращения вариантов перебора
Общие табличные выражения обычно оптимизируются отдельно от

Оптимизатор
Один и тот же оператор SQL можно выполнить несколькими способами, и
Оптимизатор
Один и тот же оператор SQL можно выполнить несколькими способами, и

План запроса
Чтобы разработать наилучший план выполнения любого оператора SQL, оптимизатор
Оценивает
План запроса
Чтобы разработать наилучший план выполнения любого оператора SQL, оптимизатор
Оценивает

Оптимизация запроса
Для оптимизации запроса обычно проделывают следующие действия:
1. Проверить что запрос
Оптимизация запроса
Для оптимизации запроса обычно проделывают следующие действия:
1. Проверить что запрос
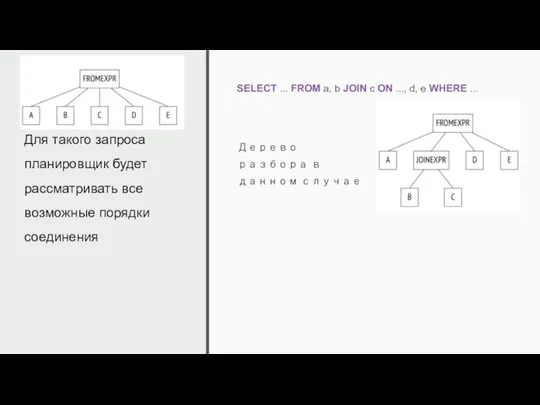
Для такого запроса планировщик будет рассматривать все возможные порядки соединения
SELECT ...
Для такого запроса планировщик будет рассматривать все возможные порядки соединения
SELECT ...

Выполнение
Оптимизированный̆ запрос выполняется в соответствии с планом
В памяти обслуживающего процесса создается портал — объект, хранящий̆
Выполнение
Оптимизированный̆ запрос выполняется в соответствии с планом
В памяти обслуживающего процесса создается портал — объект, хранящий̆
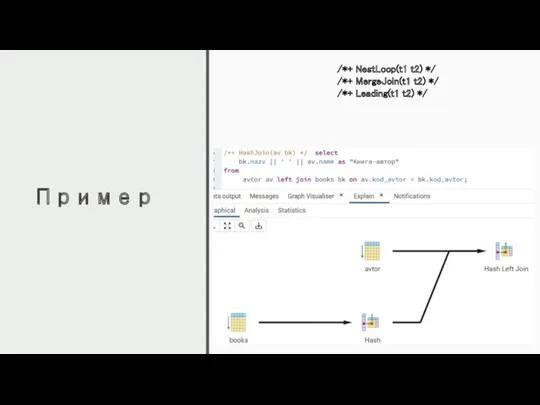
Пример
/*+ NestLoop(t1 t2) */
/*+ MergeJoin(t1 t2) */
/*+ Leading(t1 t2)
Пример
/*+ NestLoop(t1 t2) */ /*+ MergeJoin(t1 t2) */ /*+ Leading(t1 t2)
![EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/601770/slide-39.jpg)
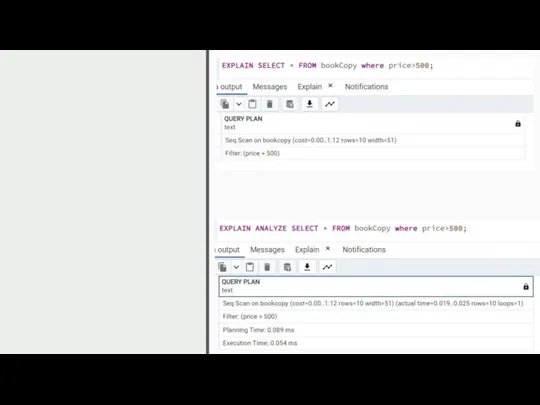
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE
EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN [ ANALYZE
![ANALYZE собирает статистику о базе данных ANALYZE [ VERBOSE ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/601770/slide-40.jpg)
ANALYZE собирает статистику о базе данных
ANALYZE [ VERBOSE ] [ table_name
ANALYZE собирает статистику о базе данных
ANALYZE [ VERBOSE ] [ table_name
Физические операции соединения
Физические операции соединения

МЕТОДЫ СОЕДИНЕНИЙ
Соединение вложенных циклов
Соединение вложенными циклами. Встречаются очень часто. Выполняют довольно
МЕТОДЫ СОЕДИНЕНИЙ
Соединение вложенных циклов
Соединение вложенными циклами. Встречаются очень часто. Выполняют довольно

Соединение слиянием. Редко встречаются в реальных запросах, как правило, являются наиболее
Соединение слиянием. Редко встречаются в реальных запросах, как правило, являются наиболее

Операция используется всегда, когда невозможно применить другие виды соединения. Она выбираются
Операция используется всегда, когда невозможно применить другие виды соединения. Она выбираются

Расширенные запросы
Неудобство простого способа выполнения запросов состоит в том, что клиент
Расширенные запросы
Неудобство простого способа выполнения запросов состоит в том, что клиент
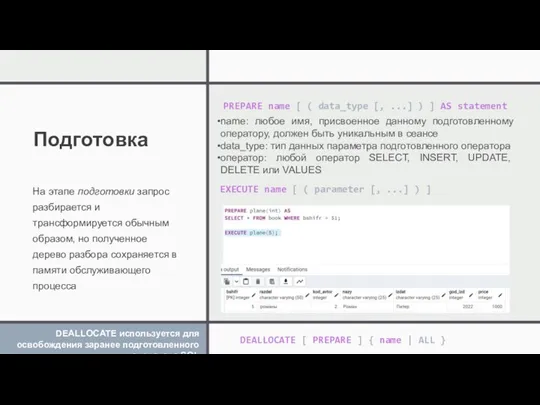
Подготовка
На этапе подготовки запрос разбирается и трансформируется обычным образом, но полученное дерево разбора
Подготовка
На этапе подготовки запрос разбирается и трансформируется обычным образом, но полученное дерево разбора

Планирование и выполнение
В некоторых случаях планировщик запоминает не только дерево разбора,
Планирование и выполнение
В некоторых случаях планировщик запоминает не только дерево разбора,
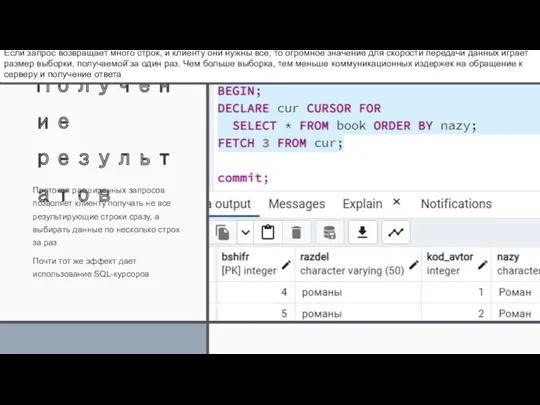
Получение результатов
Протокол расширенных запросов позволяет клиенту получать не все результирующие строки
Получение результатов
Протокол расширенных запросов позволяет клиенту получать не все результирующие строки
ИНДЕКСЫ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
ИНДЕКСЫ И ОПТИМИЗАЦИЯ ЗАПРОСОВ

Доступ к данным
По уникальному идентификатору
По индексу
Полное сканирование таблицы
Доступ к данным
По уникальному идентификатору
По индексу
Полное сканирование таблицы
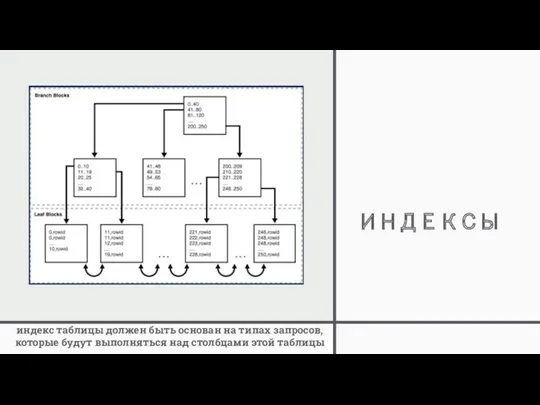
ИНДЕКСЫ
индекс таблицы должен быть основан на типах запросов, которые будут выполняться
ИНДЕКСЫ
индекс таблицы должен быть основан на типах запросов, которые будут выполняться

Применение индексов
Индексы обеспечивают быстрый доступ к строкам таблиц в базе данных,
Применение индексов
Индексы обеспечивают быстрый доступ к строкам таблиц в базе данных,

Виды индексов
Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце
Виды индексов
Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце

Индексы и ключи
Индекс (англ. index) — объект базы данных, создаваемый с
Индексы и ключи
Индекс (англ. index) — объект базы данных, создаваемый с

Рекомендации по созданию эффективных индексов в базе данных
Индексация имеет смысл, если
Рекомендации по созданию эффективных индексов в базе данных
Индексация имеет смысл, если

Рекомендации по созданию эффективных индексов в базе данных
Избегайте создания индексов для
Рекомендации по созданию эффективных индексов в базе данных
Избегайте создания индексов для

Рекомендации по созданию эффективных индексов в базе данных
Индексируйте столбцы, участвующие в
Рекомендации по созданию эффективных индексов в базе данных
Индексируйте столбцы, участвующие в

Рекомендации по созданию эффективных индексов в базе данных Oracle
Столбцы, состоящие из
Рекомендации по созданию эффективных индексов в базе данных Oracle
Столбцы, состоящие из

Создание индекса
CREATE INDEX ИмяИндекса ON ИмяТаблицы(ИндексируемыеПоля)
Создание индекса
CREATE INDEX ИмяИндекса ON ИмяТаблицы(ИндексируемыеПоля)

Способы создание индексов
CREATE INDEX
ALTER TABLE table_name ADD INDEX [index_name] (index_col_name,...)
Имя индекса
Способы создание индексов
CREATE INDEX
ALTER TABLE table_name ADD INDEX [index_name] (index_col_name,...)
Имя индекса
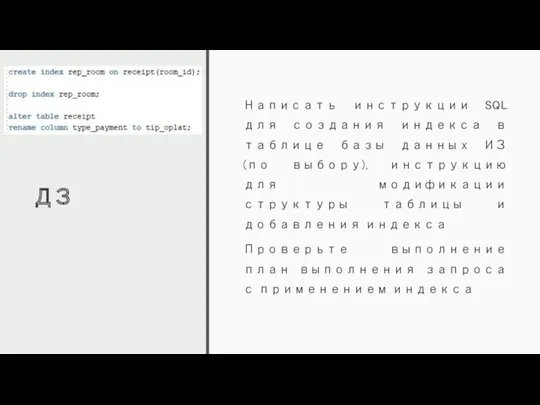
ДЗ
Написать инструкции SQL для создания индекса в таблице базы данных ИЗ
ДЗ
Написать инструкции SQL для создания индекса в таблице базы данных ИЗ

Статистика
Базовая статистика уровня отношения хранится в системном каталоге в таблице pg_class
К
Статистика
Базовая статистика уровня отношения хранится в системном каталоге в таблице pg_class
К

Статистика работы PostgreSQL
PostgreSQL собирает статистику с помощью фонового процесса “stats collector”
Статистика работы PostgreSQL
PostgreSQL собирает статистику с помощью фонового процесса “stats collector”
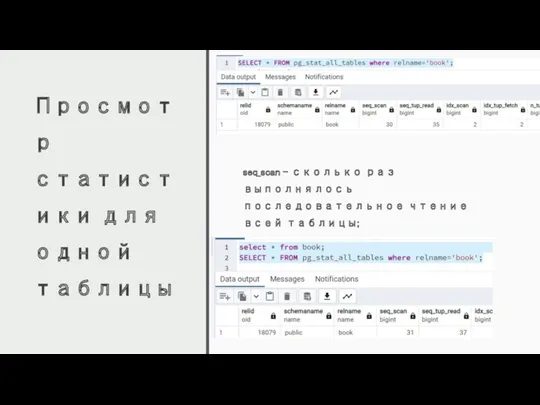
Просмотр статистики для одной таблицы
seq_scan – сколько раз выполнялось последовательное чтение
Просмотр статистики для одной таблицы
seq_scan – сколько раз выполнялось последовательное чтение

relid – идентификатор базы;
schemaname – имя схемы;
relname – имя таблицы;
seq_scan –
relid – идентификатор базы; schemaname – имя схемы; relname – имя таблицы; seq_scan –
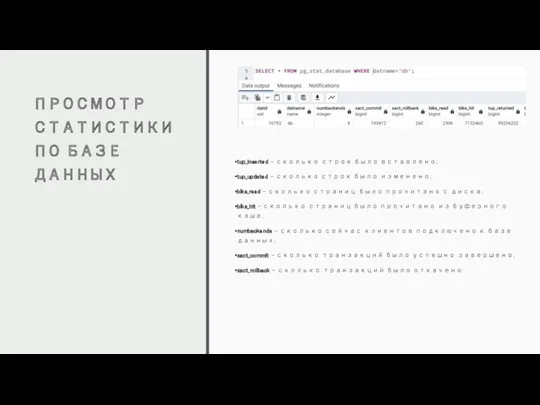
ПРОСМОТР СТАТИСТИКИ ПО БАЗЕ ДАННЫХ
tup_inserted – сколько строк было вставлено;
tup_updated – сколько строк
ПРОСМОТР СТАТИСТИКИ ПО БАЗЕ ДАННЫХ
tup_inserted – сколько строк было вставлено;
tup_updated – сколько строк

ПАРТИЦИОНИРОВАНИЕ
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким
ПАРТИЦИОНИРОВАНИЕ
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким

Методы секционирования
Повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы
Методы секционирования
Повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы

Фрагментация - разделение таблицы или индекса на несколько логически связанных частей
Фрагментация - разделение таблицы или индекса на несколько логически связанных частей

select * from таблица partition
(фрагмент);
С помощью оператора SELECT есть возможность выбирать как все
select * from таблица partition
(фрагмент);
С помощью оператора SELECT есть возможность выбирать как все

Пример
Предположим, что мы создаём базу данных для большой компании, торгующей мороженым.
Пример
Предположим, что мы создаём базу данных для большой компании, торгующей мороженым.

Создание секций
В нашем примере каждая секция должна содержать данные за один
Создание секций
В нашем примере каждая секция должна содержать данные за один
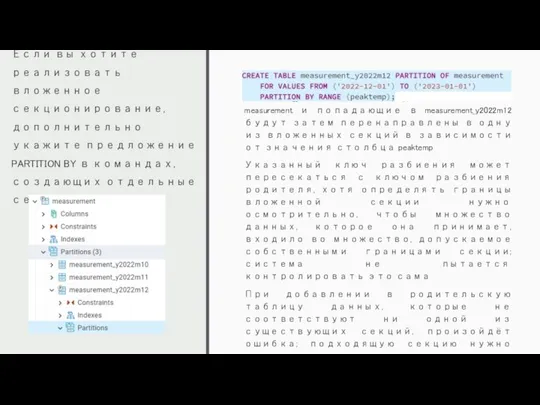
Если вы хотите реализовать вложенное секционирование, дополнительно укажите предложение PARTITION BY
Если вы хотите реализовать вложенное секционирование, дополнительно укажите предложение PARTITION BY
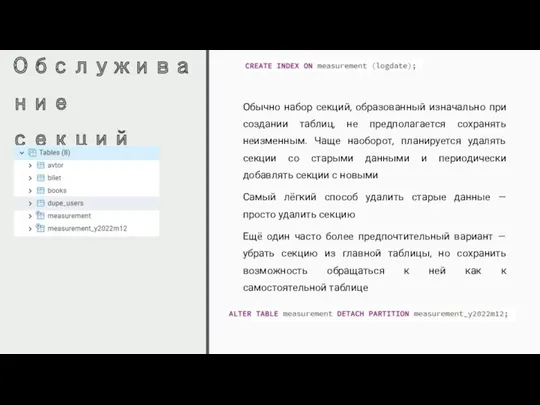
Обслуживание секций
Обычно набор секций, образованный изначально при создании таблиц, не предполагается
Обслуживание секций
Обычно набор секций, образованный изначально при создании таблиц, не предполагается

Ограничения
С секционированными таблицами связаны следующие ограничения:
Ограничения уникальности (а значит и первичные
Ограничения
С секционированными таблицами связаны следующие ограничения:
Ограничения уникальности (а значит и первичные

Секционирование с использованием наследования
Добавим в дочерние таблицы неперекрывающиеся ограничения, определяющие допустимые
Секционирование с использованием наследования
Добавим в дочерние таблицы неперекрывающиеся ограничения, определяющие допустимые
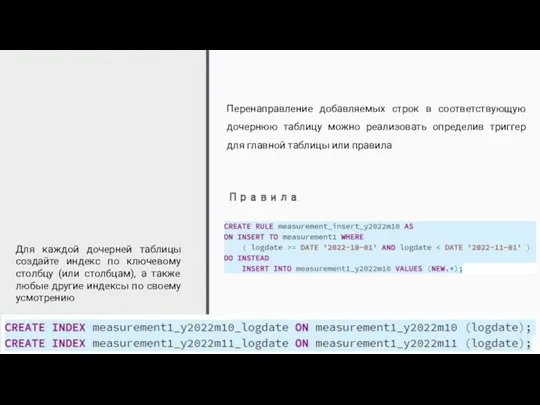
Перенаправление добавляемых строк в соответствующую дочернюю таблицу можно реализовать определив триггер
Перенаправление добавляемых строк в соответствующую дочернюю таблицу можно реализовать определив триггер
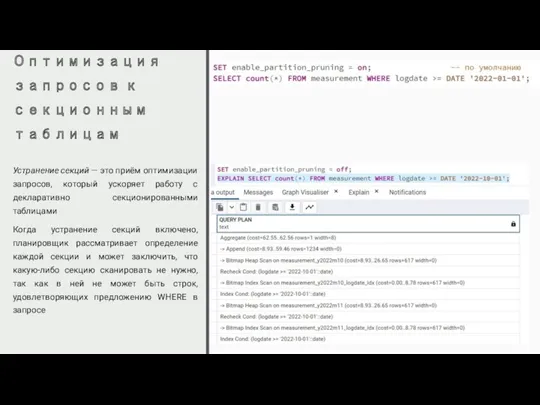
Оптимизация запросов к секционным таблицам
Устранение секций — это приём оптимизации запросов, который
Оптимизация запросов к секционным таблицам
Устранение секций — это приём оптимизации запросов, который

Оптимизация запросов к секционным таблицам
Исключение по ограничению — приём оптимизации запросов, подобный
Оптимизация запросов к секционным таблицам
Исключение по ограничению — приём оптимизации запросов, подобный
 Развитие вычислительной техники и архитектура персонального компьютера. (Лекция 2)
Развитие вычислительной техники и архитектура персонального компьютера. (Лекция 2) Организация RAID массивов
Организация RAID массивов Информационные системы менеджмента
Информационные системы менеджмента Расчет параметров полнодоступных систем РИ с ожиданием
Расчет параметров полнодоступных систем РИ с ожиданием Алгоритм распознавания цифр в речи
Алгоритм распознавания цифр в речи Научно-техническая информация
Научно-техническая информация Happy New Year! By Slidesgo. Here is where your presentation begins
Happy New Year! By Slidesgo. Here is where your presentation begins Університетське інтернет-телебачення
Університетське інтернет-телебачення Работа с файлами. Аргументы командной строки
Работа с файлами. Аргументы командной строки ЕЦУР: основные проблемы у ОМСУ и их решение
ЕЦУР: основные проблемы у ОМСУ и их решение Табличные виды данных. Одномерный массив
Табличные виды данных. Одномерный массив Бүгінгі күнгі Visual Basic және Delphi программалары
Бүгінгі күнгі Visual Basic және Delphi программалары Интеллектуальные информационные системы. (Лекция 1)
Интеллектуальные информационные системы. (Лекция 1) Интернет-этикет сетикет или по-другому нетикет
Интернет-этикет сетикет или по-другому нетикет Сравнение нотаций ВS с ARIS и BPMN 2022
Сравнение нотаций ВS с ARIS и BPMN 2022 PAYPASS. Инструкция проведений операций на POS-терминале. ЗАО КРЕДИТ ЕВРОПА БАНК
PAYPASS. Инструкция проведений операций на POS-терминале. ЗАО КРЕДИТ ЕВРОПА БАНК Свойства логических операций
Свойства логических операций Дистанционные методы исследования. Обработка данных MODIS в ENVI
Дистанционные методы исследования. Обработка данных MODIS в ENVI Параллельное программирование
Параллельное программирование Комп’ютерна дискретна математика. Відношення та їх властивості. (Лекція 3)
Комп’ютерна дискретна математика. Відношення та їх властивості. (Лекція 3) Инструкция по поиску информации в базе данных zbMATH
Инструкция по поиску информации в базе данных zbMATH Компьютерная графика. Классификации, характеристики и примеры
Компьютерная графика. Классификации, характеристики и примеры Мессенджеры и приложения как новый вид прессы
Мессенджеры и приложения как новый вид прессы Кунделик. Единая образовательная сеть
Кунделик. Единая образовательная сеть ძებნის ორობითი ხეები
ძებნის ორობითი ხეები SMM и контент-маркетинг
SMM и контент-маркетинг Разработка проекта обучающего web-сайта по информационным технологиям. Курсовая работа
Разработка проекта обучающего web-сайта по информационным технологиям. Курсовая работа Обработка и передача информации
Обработка и передача информации