- Распределенная обработка данных

Содержание
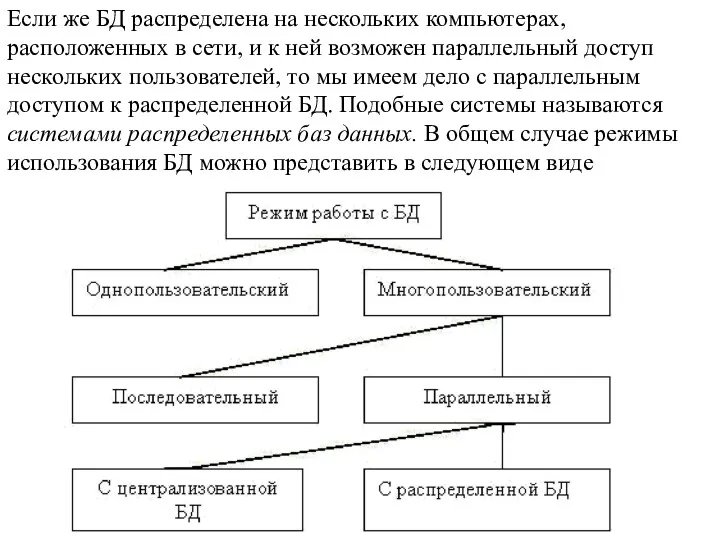
- 2. Если же БД распределена на нескольких компьютерах, расположенных в сети, и к ней возможен параллельный доступ
- 3. Терминология Запрос — процесс обращения пользователя к БД с целью ввода, получения или изменения информации в
- 4. Возможность реализации удаленной транзакции — обработка одной транзакции, состоящей из множества SQL-запросов на одном удаленном узле.
- 5. Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных
- 6. Общая тенденция движения от отдельных mainframe-систем к открытым распределенным системам, объединяющим компьютеры среднего класса, получила название
- 7. Модели «клиент—сервер» в технологии баз данных Вычислительная модель «клиент—сервер» исходно связана с парадигмой открытых систем, которая
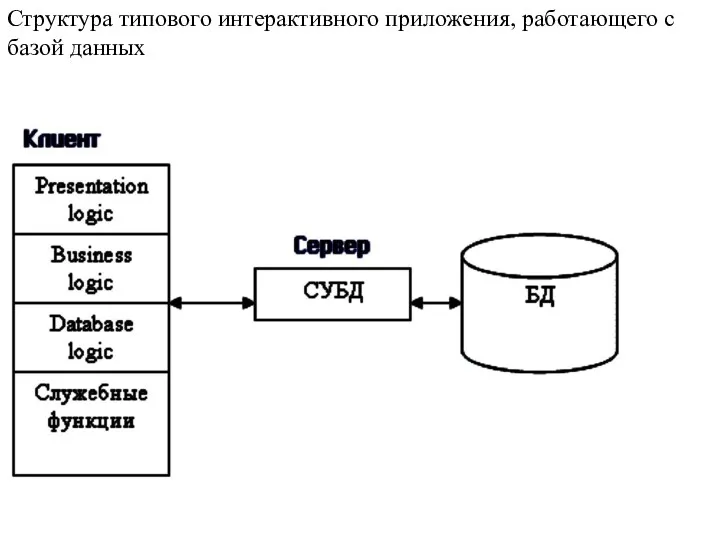
- 8. Основной принцип технологии «клиент—сервер» применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения
- 9. Структура типового интерактивного приложения, работающего с базой данных
- 10. Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь видит на своем экране, когда
- 11. Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть кода приложения, которая определяет собственно
- 12. В зависимости от характера распределения можно выделить следующие модели распределений : - распределенная презентация (Distribution presentation,
- 13. Двухуровневые модели Двухуровневая модель фактически является результатом распределения пяти указанных функций между двумя процессами, которые выполняются
- 14. Модель файлового сервера Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на
- 15. Алгоритм выполнения запроса клиента: Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность
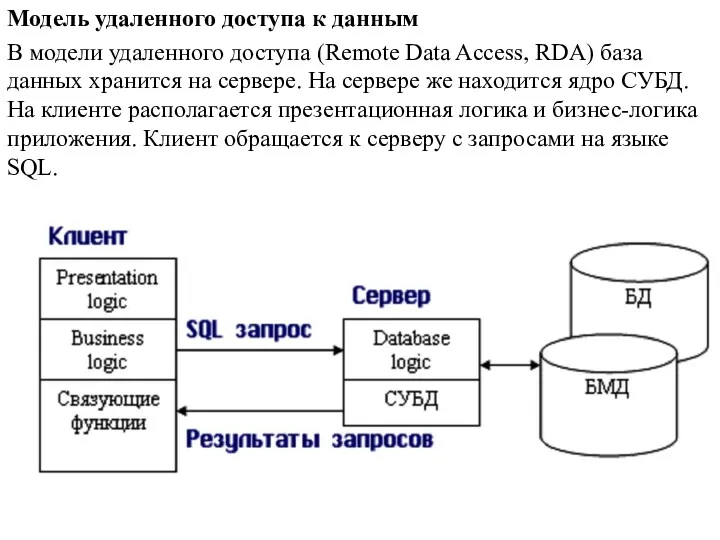
- 16. Модель удаленного доступа к данным В модели удаленного доступа (Remote Data Access, RDA) база данных хранится
- 17. Преимущества данной модели; -перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД,
- 18. Недостатки: -все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть; -так
- 19. Модель сервера баз данных Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены
- 20. 4. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной
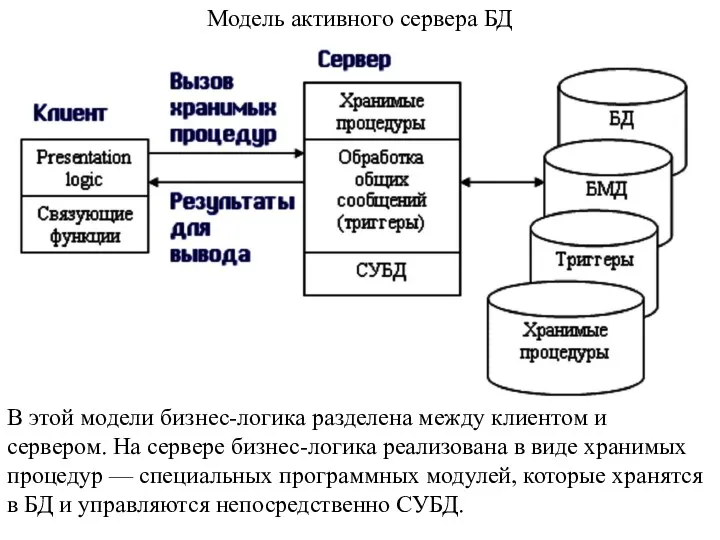
- 21. Модель активного сервера БД В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика
- 22. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и
- 23. Механизм использования триггеров предполагает, что при срабаты-вании одного триггера могут возникнуть события, которые вызовут срабатывание других
- 24. Недостатком данной модели является очень большая загрузка сервера. Сервер выполняет следующие функции: - осуществляет мониторинг событий,
- 25. Модель сервера приложений Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень
- 26. Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения общих неза-гружаемых функций для клиентов.
- 27. Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений
- 28. Модели серверов баз данных В современных СУБД «клиент-сервер» является фактически основополагающим механизмом организации взаимодействия процессов типа
- 29. Выделение сервера в отдельную программу было революционным шагом, который позволил, поместить сервер на одну машину, а
- 30. Взаимодействие пользовательских и клиентских процессов в модели «один-к-одному» Проблемы модели «один-к-одному» решаются в архитектуре «систем с
- 31. Многопотоковая односерверная архитектура Возможность взаимодействия с одним сервером многих клиентов позволяет в полной мере использовать разделяемые
- 32. Недостатки: т.к. сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для
- 33. В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который
- 34. Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в
- 36. Скачать презентацию
Если же БД распределена на нескольких компьютерах, расположенных в сети, и
Если же БД распределена на нескольких компьютерах, расположенных в сети, и

Терминология
Запрос — процесс обращения пользователя к БД с целью ввода, получения
Терминология
Запрос — процесс обращения пользователя к БД с целью ввода, получения

Возможность реализации удаленной транзакции — обработка одной транзакции, состоящей из множества
Возможность реализации удаленной транзакции — обработка одной транзакции, состоящей из множества

Системы распределенной обработки данных в основном связаны с первым поколением БД,
Системы распределенной обработки данных в основном связаны с первым поколением БД,

Общая тенденция движения от отдельных mainframe-систем к открытым распределенным системам, объединяющим
Общая тенденция движения от отдельных mainframe-систем к открытым распределенным системам, объединяющим

Модели «клиент—сервер» в технологии баз данных
Вычислительная модель «клиент—сервер» исходно связана с
Модели «клиент—сервер» в технологии баз данных
Вычислительная модель «клиент—сервер» исходно связана с

Основной принцип технологии «клиент—сервер» применительно к технологии баз данных заключается в
Основной принцип технологии «клиент—сервер» применительно к технологии баз данных заключается в
Структура типового интерактивного приложения, работающего с базой данных
Структура типового интерактивного приложения, работающего с базой данных

Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь
Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь

Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть
Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть

В зависимости от характера распределения можно выделить следующие модели распределений :
-
В зависимости от характера распределения можно выделить следующие модели распределений :
-

Двухуровневые модели
Двухуровневая модель фактически является результатом распределения пяти указанных функций между
Двухуровневые модели
Двухуровневая модель фактически является результатом распределения пяти указанных функций между

Модель файлового сервера
Достоинства этой модели в том, что мы уже имеем
Модель файлового сервера
Достоинства этой модели в том, что мы уже имеем

Алгоритм выполнения запроса клиента:
Запрос клиента формулируется в командах ЯМД. СУБД переводит
Алгоритм выполнения запроса клиента:
Запрос клиента формулируется в командах ЯМД. СУБД переводит
Модель удаленного доступа к данным
В модели удаленного доступа (Remote Data Access,
Модель удаленного доступа к данным
В модели удаленного доступа (Remote Data Access,

Преимущества данной модели;
-перенос компонента представления и прикладного компонента на клиентский компьютер
Преимущества данной модели;
-перенос компонента представления и прикладного компонента на клиентский компьютер

Недостатки:
-все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут
Недостатки:
-все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут

Модель сервера баз данных
Для того чтобы избавиться от недостатков модели удаленного
Модель сервера баз данных
Для того чтобы избавиться от недостатков модели удаленного

4. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно
4. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно
Модель активного сервера БД
В этой модели бизнес-логика разделена между клиентом и
Модель активного сервера БД
В этой модели бизнес-логика разделена между клиентом и

Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а
Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а

Механизм использования триггеров предполагает, что при срабаты-вании одного триггера могут возникнуть
Механизм использования триггеров предполагает, что при срабаты-вании одного триггера могут возникнуть

Недостатком данной модели является очень большая загрузка сервера. Сервер выполняет следующие
Недостатком данной модели является очень большая загрузка сервера. Сервер выполняет следующие

Модель сервера приложений
Эта модель является расширением двухуровневой модели и в ней
Модель сервера приложений
Эта модель является расширением двухуровневой модели и в ней

Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения
Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения

Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее
Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее

Модели серверов баз данных
В современных СУБД «клиент-сервер» является фактически основополагающим механизмом
Модели серверов баз данных
В современных СУБД «клиент-сервер» является фактически основополагающим механизмом

Выделение сервера в отдельную программу было революционным шагом, который позволил, поместить
Выделение сервера в отдельную программу было революционным шагом, который позволил, поместить

Взаимодействие пользовательских и клиентских процессов в модели «один-к-одному»
Проблемы модели «один-к-одному» решаются
Взаимодействие пользовательских и клиентских процессов в модели «один-к-одному»
Проблемы модели «один-к-одному» решаются

Многопотоковая односерверная архитектура
Возможность взаимодействия с одним сервером многих клиентов позволяет в
Многопотоковая односерверная архитектура
Возможность взаимодействия с одним сервером многих клиентов позволяет в
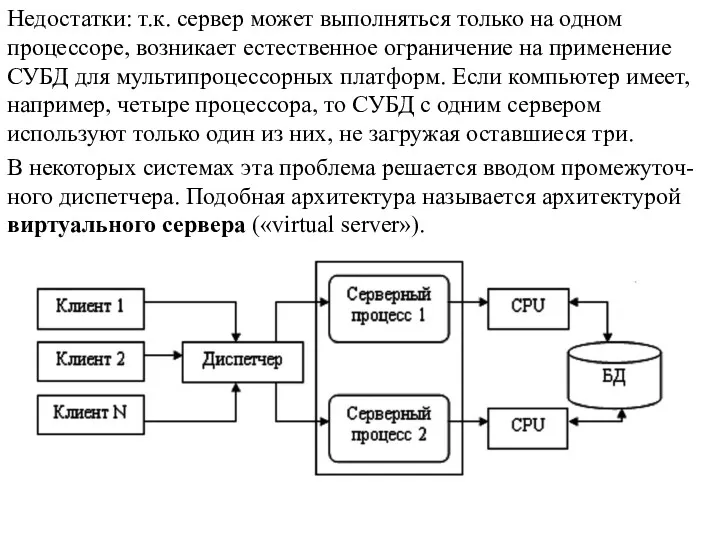
Недостатки: т.к. сервер может выполняться только на одном процессоре, возникает естественное
Недостатки: т.к. сервер может выполняться только на одном процессоре, возникает естественное

В этой архитектуре клиенты подключаются не к реальному серверу, а к
В этой архитектуре клиенты подключаются не к реальному серверу, а к
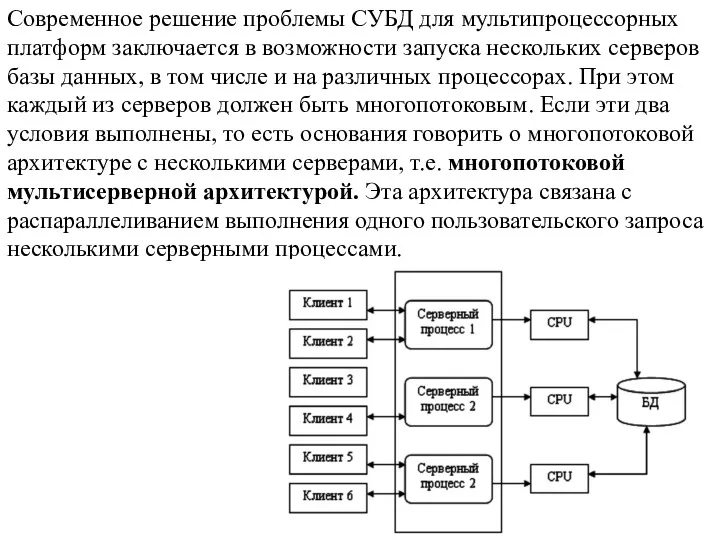
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска
 Создание сайта
Создание сайта Пакеты по поисковому продвижению
Пакеты по поисковому продвижению Регистрация на сайте SPE и получения ID номера
Регистрация на сайте SPE и получения ID номера Учебный курс Управление внедрением информационных систем
Учебный курс Управление внедрением информационных систем Функции. Прототип функции. Локальные, глобальные переменные. Формальные параметры (язык C)
Функции. Прототип функции. Локальные, глобальные переменные. Формальные параметры (язык C) Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Программы и программное обеспечение
Программы и программное обеспечение Компьютердің программалық қамтамасыздандырылуы
Компьютердің программалық қамтамасыздандырылуы Программирование на языке Java
Программирование на языке Java Технологический процесс тестирования. Тестовые артефакты. (Занятие 5)
Технологический процесс тестирования. Тестовые артефакты. (Занятие 5) Пресс-служба МВД
Пресс-служба МВД Моя будущая профессия - веб-дизайнер
Моя будущая профессия - веб-дизайнер Презентация Древняя Финикия
Презентация Древняя Финикия Конспект урока по теме Информация и знания.
Конспект урока по теме Информация и знания. 1C:Предприятие 8. Автосервис
1C:Предприятие 8. Автосервис Порівняльна характеристика 5 офіційних сайтів **** готелів Львова
Порівняльна характеристика 5 офіційних сайтів **** готелів Львова Основные понятия и определения по информатике
Основные понятия и определения по информатике Системы счисления. Математические основы информатики
Системы счисления. Математические основы информатики Using objects in JavaScript. Accessing DOM in JavaScript
Using objects in JavaScript. Accessing DOM in JavaScript Analyzing Semi-structured Decision Support Systems
Analyzing Semi-structured Decision Support Systems Информационно-поисковые системы
Информационно-поисковые системы Тематические медиаповестки. Социальная журналистика: концепции и стратегии
Тематические медиаповестки. Социальная журналистика: концепции и стратегии Как настроить контекст и не слить весь бюджет за один день
Как настроить контекст и не слить весь бюджет за один день Massenmedien
Massenmedien Науковедение, наукометрия, библиометрия
Науковедение, наукометрия, библиометрия Роль журналиста в обществе
Роль журналиста в обществе Основные сведения. Предпосылки появления баз данных
Основные сведения. Предпосылки появления баз данных Учет продукции и оборудования для водоснабжения склада УкрДонсервис
Учет продукции и оборудования для водоснабжения склада УкрДонсервис