Распределенные реляционные базы данных. SQL и распределенные базы данных. NoSQL базы данных. New SQL базы данных презентация
- Распределенные реляционные базы данных. SQL и распределенные базы данных. NoSQL базы данных. New SQL базы данных

Содержание
- 2. Реляционная модель данных Обобщение Реляционная модель есть представление БД в виде совокупности упорядоченных нормализованных отношений Для
- 3. Достоинства и недостатки РМД Достоинства РМД: простота представления и формирования базы данных универсальностью и удобством обработки
- 4. Базовые операции SQL Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять
- 5. SQL - развитие обеспечиваются возможности описания и управления новыми хранимыми объектами (например, индексы, представления, триггеры и
- 6. прямой (direct) SQL конструкции языка используются при "прямом" взаимодействии пользователя с СУБД является базовым уровнем встроенный
- 7. SQL и распределенные базы данных распределенные БД определяют сегодня развитие технологий реляционных баз данных и языка
- 8. SQL и распределенные базы данных проблемы: план выполнения статического оператора SQL: встроенная статическая инструкция SQL компилируется
- 9. SQL и распределенные базы данных Проблема оптимизации: в распределенных БД нельзя применять обычные правила оптимизации инструкций
- 10. SQL и распределенные базы данных Проблема совместимости данных в различных вычислительных системах существуют разные типы данных
- 11. SQL и облачные вычисления Задачи проекция традиционного SQL на облако: решить проблему масштабирования (произвольного увеличения количества
- 12. NoSQL и SQL концепция NoSQL (англ. not only SQL, не только SQL): расширить возможности БД там,
- 13. NoSQL и SQL методологические обоснования – основа - теорема CAP: в распределённой системе невозможно одновременно обеспечить:
- 14. NoSQL и SQL предлагается: обеспечить высокую доступность и устойчивости к разделению не фокусироваться на средствах обеспечения
- 15. Что такое NoSQL? Предпосылки развития NoSQL технологий Появление в начале 2000-х Google - поисковые системы Facebook
- 16. Что такое NoSQL(not only SQL) СУБД? специализация БД для конкретной области применения (позволяет обеспечить более высокую
- 17. Виды NoSQL Все NoSQL СУБД разделяются на несколько категорий: Key-value stores / Хранилища типа «ключ-значение» Column
- 18. На рисунке схематично обозначены объемы используемых данных и сложность этих данных в этих видах NoSQL
- 19. Языки запросов баз NoSQL В качестве языка запросов баз NoSQL используется либо специализированные программные продукты (например,
- 21. Анализ таблицы: реляционные базы данных реляционные базы данных предназначены для хранения структурированной информации в виде двумерных
- 22. Анализ таблицы: категории NoSQL баз данных Первая категория — это базы данных (ключ значение). это очень
- 23. Что такое key-value БД? Этот тип БД работает с данными типа ключ-значение. Здесь нет места ни
- 24. Зачем нужно такое решение, если есть MySQL, PostgreSQL, Oracle...? Решая такую простую задачу, как сохранение/чтение значений
- 25. Пример на основе авторизации пользователя Сейчас все представили себе стандартное решение — таблица в MySQL на
- 26. Пример на основе авторизации пользователя Давайте ту же задачу рассмотрим в приближении БД ключ-значение: Регистрация. У
- 29. Хранилища типа ключ-значение ориентированы на работу с записями Это значит, что вся информация, относящаяся к данной
- 30. Доступ к данным
- 31. Доступ к данным
- 32. Хранилища типа ключ-значение: преимущества РСУБД (RDBMS) слишком медленные, имеют тяжелую прослойку SQL движков, тяжело масштабируются РСУБД
- 33. Хранилища типа ключ-значение: недостатки Преимущество реляционных БД заключается в том, что они вынуждают вас пройти через
- 34. Хранилища типа ключ-значение: недостатки Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам
- 35. Выводы Экономя время на анализе во время разработки, вы теряете время и деньги, масштабируя решения, которые
- 36. Такие базы немного напоминают базы (ключ-значение), но в данном случае, база данных знает, что из себя
- 37. Графовые базы данных В особую категорию относят базы, данных построенные на графах. Такие базы ориентированы на
- 38. Объектно-ориентированные базы данных Также существует еще одна категория, которую обычно не относят к NoSQL. Это -
- 39. Преимущества постреляционных БД Кроме отказа от нормализации, постреляционные СУБД позволяют хранить в полях отношений данные абстрактных,
- 40. Объектно-ориентированные базы данных (ООБД) ООБД - базы данных, в которых информация представлена в виде объектов, в
- 41. Объектно-ориентированная парадигма Термин "объект" в программной индустрии впервые был введен в языке Simula (1967 г.) и
- 42. Объектно-ориентированная парадигма "Данные" состоят из компонентов произвольного типа, называемых "атрибутами". Характеристики объекта моделируются его атрибутами. Каждая
- 43. Объекты, обладающие одинаковыми свойствами, составляют классы (например, курица, пингвин и чайка - объекты класса "птицы"). Обычно
- 44. Схема представления класса объектов
- 45. Структура объектной модели Структура объектной модели описываются с помощью трех ключевых понятий: инкапсуляция – свойство объекта
- 46. Характеристики ООБД Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих
- 47. Преимущества ООБД Объектно-ориентированный подход предоставляет мощные средства конструирования типов данных Эти средства устраняют три важных недостатка
- 48. Преимущества ООБД РБД предлагают набор примитивных встроенных типов в качестве доменов столбцов отношений, без всяких средств
- 49. Преимущества ООБД Инкапсуляция объектов в ООБД не накладывает никаких ограничений на типы. В объектно-ориентированных языках тип
- 50. Преимущества ООБД Инкапсуляция объектов - основа для хранения и управления программами как объектами, средствами баз данных.
- 51. Преимущества ООБД Сила объектно-ориентированных концепций проистекает из объединения инкапсуляции и наследования. Поскольку наследование делает возможным совместное
- 52. Преимущества ООБД На этом основывается объектно-ориентированный интерфейс пользователя современных оконных систем. Один и тот же набор
- 53. Недостатки ООБД Отсутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных
- 54. Недостатки ООБД Оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя
- 55. Подход Стоунбрейкера Стоунбрейкер — главный архитектор Ingres и Postgres, активный участник разработки многих других систем. Он
- 56. Подход Стоунбрейкера: реабилитация SQL баз данных Реляционные СУБД — действительно «вымирающий вид»,. Однако виноваты в этом
- 57. Подход Стоунбрейкера: реабилитация SQL баз данных Медлительность баз данных можно отнести на счет нескольких факторов: реляционные
- 58. Причины перехода к NoSQL базам данным Реляционные базы данных не обладают необходимой гибкостью. Их архитектура, разработанная
- 59. Причины перехода к NoSQL базам данным Реляционные базы данных плохо масштабируются за пределами одиночного сервера. Когда
- 60. Недостатки NoSQL баз данных Ввиду отсутствия поддержки SQL такие системы лишены способности выполнять структурированные запросы с
- 61. Недостатки NoSQL баз данных Средства обеспечения соответствия ACID можно реализовать на уровне приложения, однако написание соответствующего
- 62. Выход – NewSQL базы данных NewSQL обеспечивает гарантии качества выполнения транзакций, свойственные SQL-системам, и при этом
- 63. NewSQL базы должны удовлетворять следующим критериям: поддержка реляционной модели и транзакционности SQL как основной интерфейс доступа
- 64. Технические характеристики решений NewSQL SQL как основной механизм для взаимодействия. ACID поддержка транзакций. Механизм управления без
- 65. Классификация NewSQL Новые базы данных Новый движок базы данных MySQL Прозрачное объединение в кластеры Данная Классификация
- 66. Новые базы данных NewSQL система разрабатывается полностью с нуля с целью достижения масштабируемости и производительности. Одним
- 67. Новые базы данных Многие NewSQL БД — это in-memory БД. Они хранят все данные в оперативной
- 68. Новый движок базы данных MySQL Чтобы преодолеть проблемы масштабируемости MySQL, было создано ряд движков основанных на
- 69. Новый движок базы данных MySQL Самый популярный — TokuDB — движок для MySQL. Он использует индексы
- 70. Прозрачное объединение в кластеры Обычные SQL базы объединяются в кластере из нескольких физических узлов для хранения
- 71. Прозрачное объединение в кластеры БД Schooner MySQL, Continuent Tungsten и ScalArc следуют первому подходу, тогда как
- 72. Прозрачное объединение в кластеры Сюда можно отнести также MySQL Cluster, Postgres-XC, Oracle RAC и прочие. Все
- 74. Скачать презентацию

Реляционная модель данных
Обобщение
Реляционная модель есть представление БД в виде совокупности
Реляционная модель данных
Обобщение
Реляционная модель есть представление БД в виде совокупности

Достоинства и недостатки РМД
Достоинства РМД:
простота представления и формирования базы данных
Достоинства и недостатки РМД
Достоинства РМД:
простота представления и формирования базы данных

Базовые операции SQL
Изначально, SQL был основным способом работы пользователя с базой
Базовые операции SQL
Изначально, SQL был основным способом работы пользователя с базой

SQL - развитие
обеспечиваются возможности описания и управления новыми хранимыми объектами (например,
SQL - развитие
обеспечиваются возможности описания и управления новыми хранимыми объектами (например,
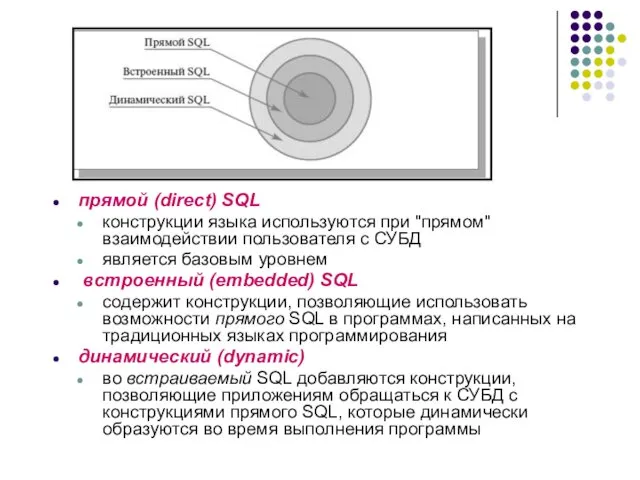
прямой (direct) SQL
конструкции языка используются при "прямом" взаимодействии пользователя с СУБД
является
прямой (direct) SQL
конструкции языка используются при "прямом" взаимодействии пользователя с СУБД
является

SQL и распределенные базы данных
распределенные БД определяют сегодня развитие технологий реляционных
SQL и распределенные базы данных
распределенные БД определяют сегодня развитие технологий реляционных

SQL и распределенные базы данных
проблемы:
план выполнения статического оператора SQL:
встроенная статическая инструкция
SQL и распределенные базы данных
проблемы:
план выполнения статического оператора SQL:
встроенная статическая инструкция

SQL и распределенные базы данных
Проблема оптимизации:
в распределенных БД нельзя применять
SQL и распределенные базы данных
Проблема оптимизации:
в распределенных БД нельзя применять

SQL и распределенные базы данных
Проблема совместимости данных
в различных вычислительных системах
SQL и распределенные базы данных
Проблема совместимости данных
в различных вычислительных системах

SQL и облачные вычисления
Задачи проекция традиционного SQL на облако:
решить проблему масштабирования
SQL и облачные вычисления
Задачи проекция традиционного SQL на облако:
решить проблему масштабирования

NoSQL и SQL
концепция NoSQL (англ. not only SQL, не только SQL):
расширить
NoSQL и SQL
концепция NoSQL (англ. not only SQL, не только SQL):
расширить

NoSQL и SQL
методологические обоснования – основа - теорема CAP:
в распределённой системе
NoSQL и SQL
методологические обоснования – основа - теорема CAP:
в распределённой системе

NoSQL и SQL
предлагается:
обеспечить высокую доступность и устойчивости к разделению
не фокусироваться
NoSQL и SQL
предлагается:
обеспечить высокую доступность и устойчивости к разделению
не фокусироваться

Что такое NoSQL? Предпосылки развития NoSQL технологий
Появление в начале 2000-х
Google -
Что такое NoSQL? Предпосылки развития NoSQL технологий
Появление в начале 2000-х
Google -

Что такое NoSQL(not only SQL) СУБД?
специализация БД для конкретной области применения
Что такое NoSQL(not only SQL) СУБД?
специализация БД для конкретной области применения

Виды NoSQL
Все NoSQL СУБД разделяются на несколько категорий:
Key-value stores / Хранилища
Виды NoSQL
Все NoSQL СУБД разделяются на несколько категорий:
Key-value stores / Хранилища
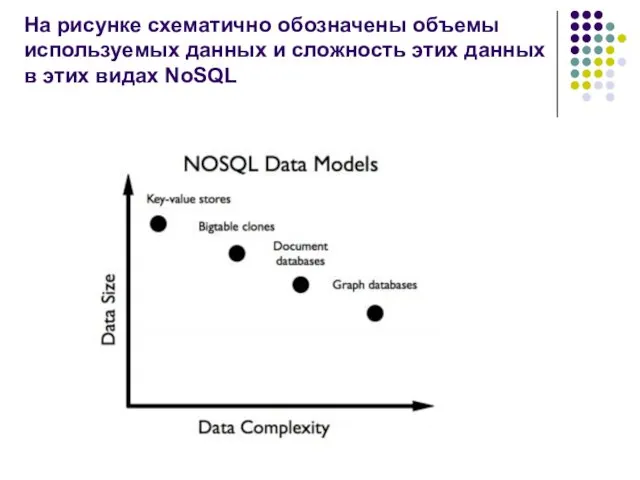
На рисунке схематично обозначены объемы используемых данных и сложность этих данных
На рисунке схематично обозначены объемы используемых данных и сложность этих данных

Языки запросов баз NoSQL
В качестве языка запросов баз NoSQL используется
Языки запросов баз NoSQL
В качестве языка запросов баз NoSQL используется
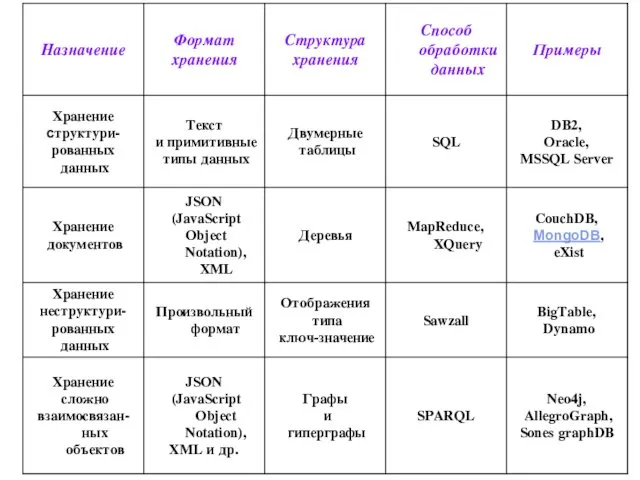

Анализ таблицы: реляционные базы данных
реляционные базы данных предназначены для хранения структурированной
Анализ таблицы: реляционные базы данных
реляционные базы данных предназначены для хранения структурированной

Анализ таблицы: категории NoSQL баз данных
Первая категория — это базы данных
Анализ таблицы: категории NoSQL баз данных
Первая категория — это базы данных

Что такое key-value БД?
Этот тип БД работает с данными типа ключ-значение.
Что такое key-value БД?
Этот тип БД работает с данными типа ключ-значение.

Зачем нужно такое решение, если есть MySQL, PostgreSQL, Oracle...?
Решая такую простую
Зачем нужно такое решение, если есть MySQL, PostgreSQL, Oracle...?
Решая такую простую

Пример на основе авторизации пользователя
Сейчас все представили себе стандартное решение —
Пример на основе авторизации пользователя
Сейчас все представили себе стандартное решение —

Пример на основе авторизации пользователя
Давайте ту же задачу рассмотрим в приближении
Пример на основе авторизации пользователя
Давайте ту же задачу рассмотрим в приближении


Хранилища типа ключ-значение ориентированы на работу с записями
Это значит, что вся
Хранилища типа ключ-значение ориентированы на работу с записями
Это значит, что вся

Доступ к данным
Доступ к данным

Доступ к данным
Доступ к данным

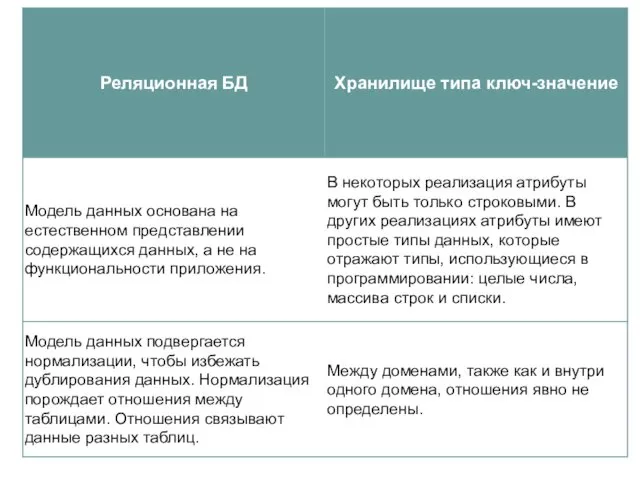
Хранилища типа ключ-значение: преимущества
РСУБД (RDBMS) слишком медленные, имеют тяжелую прослойку SQL
Хранилища типа ключ-значение: преимущества
РСУБД (RDBMS) слишком медленные, имеют тяжелую прослойку SQL

Хранилища типа ключ-значение: недостатки
Преимущество реляционных БД заключается в том, что они
Хранилища типа ключ-значение: недостатки
Преимущество реляционных БД заключается в том, что они

Хранилища типа ключ-значение: недостатки
Если ошибки в правильно спроектированной реляционной БД обычно
Хранилища типа ключ-значение: недостатки
Если ошибки в правильно спроектированной реляционной БД обычно

Выводы
Экономя время на анализе во время разработки, вы теряете время и
Выводы
Экономя время на анализе во время разработки, вы теряете время и

Такие базы немного напоминают базы (ключ-значение), но в данном случае, база
Такие базы немного напоминают базы (ключ-значение), но в данном случае, база

Графовые базы данных
В особую категорию относят базы, данных построенные на графах.
Графовые базы данных
В особую категорию относят базы, данных построенные на графах.

Объектно-ориентированные базы данных
Также существует еще одна категория, которую обычно не относят
Объектно-ориентированные базы данных
Также существует еще одна категория, которую обычно не относят

Преимущества постреляционных БД
Кроме отказа от нормализации, постреляционные СУБД позволяют хранить в
Преимущества постреляционных БД
Кроме отказа от нормализации, постреляционные СУБД позволяют хранить в

Объектно-ориентированные
базы данных (ООБД)
ООБД - базы данных, в которых информация
Объектно-ориентированные
базы данных (ООБД)
ООБД - базы данных, в которых информация

Объектно-ориентированная парадигма
Термин "объект" в программной индустрии впервые был введен в языке
Объектно-ориентированная парадигма
Термин "объект" в программной индустрии впервые был введен в языке

Объектно-ориентированная парадигма
"Данные" состоят из компонентов произвольного типа, называемых "атрибутами".
Характеристики объекта
Объектно-ориентированная парадигма
"Данные" состоят из компонентов произвольного типа, называемых "атрибутами".
Характеристики объекта

Объекты, обладающие одинаковыми свойствами, составляют классы (например, курица, пингвин и чайка
Объекты, обладающие одинаковыми свойствами, составляют классы (например, курица, пингвин и чайка
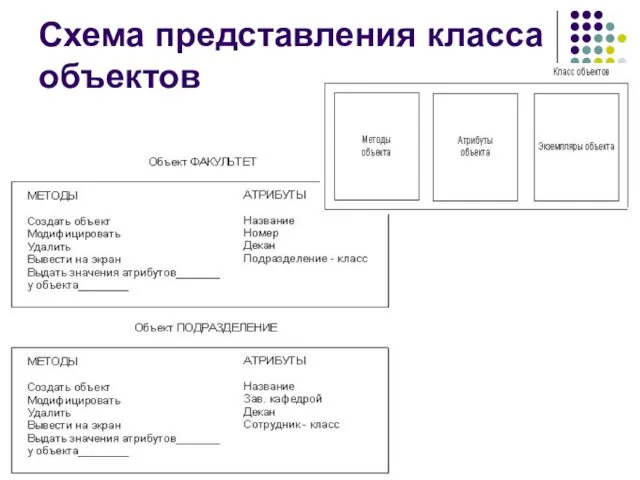
Схема представления класса объектов
Схема представления класса объектов

Структура объектной модели
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция
Структура объектной модели
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция

Характеристики ООБД
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется
Характеристики ООБД
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется

Преимущества ООБД
Объектно-ориентированный подход предоставляет мощные средства конструирования типов данных
Эти средства устраняют
Преимущества ООБД
Объектно-ориентированный подход предоставляет мощные средства конструирования типов данных
Эти средства устраняют

Преимущества ООБД
РБД предлагают набор примитивных встроенных типов в качестве доменов столбцов
Преимущества ООБД
РБД предлагают набор примитивных встроенных типов в качестве доменов столбцов

Преимущества ООБД
Инкапсуляция объектов в ООБД не накладывает никаких ограничений на типы.
В
Преимущества ООБД
Инкапсуляция объектов в ООБД не накладывает никаких ограничений на типы.
В

Преимущества ООБД
Инкапсуляция объектов - основа для хранения и управления программами как
Преимущества ООБД
Инкапсуляция объектов - основа для хранения и управления программами как

Преимущества ООБД
Сила объектно-ориентированных концепций проистекает из объединения инкапсуляции и наследования.
Поскольку наследование
Преимущества ООБД
Сила объектно-ориентированных концепций проистекает из объединения инкапсуляции и наследования.
Поскольку наследование

Преимущества ООБД
На этом основывается объектно-ориентированный интерфейс пользователя современных оконных систем. Один
Преимущества ООБД
На этом основывается объектно-ориентированный интерфейс пользователя современных оконных систем. Один

Недостатки ООБД
Отсутствуют мощные непроцедурные средства извлечения объектов из базы.
Все запросы
Недостатки ООБД
Отсутствуют мощные непроцедурные средства извлечения объектов из базы.
Все запросы

Недостатки ООБД
Оба эти недостатка связаны с отсутствием развитых средств манипулирования данными.
Эта
Недостатки ООБД
Оба эти недостатка связаны с отсутствием развитых средств манипулирования данными.
Эта

Подход Стоунбрейкера
Стоунбрейкер — главный архитектор Ingres и Postgres, активный участник разработки
Подход Стоунбрейкера
Стоунбрейкер — главный архитектор Ingres и Postgres, активный участник разработки

Подход Стоунбрейкера: реабилитация SQL баз данных
Реляционные СУБД — действительно «вымирающий вид»,.
Подход Стоунбрейкера: реабилитация SQL баз данных
Реляционные СУБД — действительно «вымирающий вид»,.

Подход Стоунбрейкера: реабилитация SQL баз данных
Медлительность баз данных можно отнести на
Подход Стоунбрейкера: реабилитация SQL баз данных
Медлительность баз данных можно отнести на

Причины перехода к NoSQL базам данным
Реляционные базы данных не обладают необходимой
Причины перехода к NoSQL базам данным
Реляционные базы данных не обладают необходимой

Причины перехода к NoSQL базам данным
Реляционные базы данных плохо масштабируются за
Причины перехода к NoSQL базам данным
Реляционные базы данных плохо масштабируются за

Недостатки NoSQL баз данных
Ввиду отсутствия поддержки SQL такие системы лишены способности
Недостатки NoSQL баз данных
Ввиду отсутствия поддержки SQL такие системы лишены способности

Недостатки NoSQL баз данных
Средства обеспечения соответствия ACID можно реализовать на уровне
Недостатки NoSQL баз данных
Средства обеспечения соответствия ACID можно реализовать на уровне

Выход – NewSQL базы данных
NewSQL обеспечивает гарантии качества выполнения транзакций, свойственные
Выход – NewSQL базы данных
NewSQL обеспечивает гарантии качества выполнения транзакций, свойственные

NewSQL базы должны удовлетворять следующим критериям:
поддержка реляционной модели и транзакционности
SQL
NewSQL базы должны удовлетворять следующим критериям:
поддержка реляционной модели и транзакционности
SQL

Технические характеристики решений NewSQL
SQL как основной механизм для взаимодействия.
ACID поддержка
Технические характеристики решений NewSQL
SQL как основной механизм для взаимодействия.
ACID поддержка

Классификация NewSQL
Новые базы данных
Новый движок базы данных MySQL
Прозрачное объединение в
Классификация NewSQL
Новые базы данных
Новый движок базы данных MySQL
Прозрачное объединение в

Новые базы данных
NewSQL система разрабатывается полностью с нуля с целью
Новые базы данных
NewSQL система разрабатывается полностью с нуля с целью

Новые базы данных
Многие NewSQL БД — это in-memory БД.
Они
Новые базы данных
Многие NewSQL БД — это in-memory БД.
Они

Новый движок базы данных MySQL
Чтобы преодолеть проблемы масштабируемости MySQL, было
Новый движок базы данных MySQL
Чтобы преодолеть проблемы масштабируемости MySQL, было

Новый движок базы данных MySQL
Самый популярный — TokuDB — движок
Новый движок базы данных MySQL
Самый популярный — TokuDB — движок

Прозрачное объединение в кластеры
Обычные SQL базы объединяются в кластере из
Прозрачное объединение в кластеры
Обычные SQL базы объединяются в кластере из

Прозрачное объединение в кластеры
БД Schooner MySQL, Continuent Tungsten и ScalArc
Прозрачное объединение в кластеры
БД Schooner MySQL, Continuent Tungsten и ScalArc

Прозрачное объединение в кластеры
Сюда можно отнести также MySQL Cluster, Postgres-XC,
Прозрачное объединение в кластеры
Сюда можно отнести также MySQL Cluster, Postgres-XC,
 Установка и настройка DNS-сервера
Установка и настройка DNS-сервера Дошкольник за компьютером
Дошкольник за компьютером Электронная почта
Электронная почта В мире кодов QR код
В мире кодов QR код Дополнительные возможности текстового процессора. 8 класс
Дополнительные возможности текстового процессора. 8 класс Сети Ethernet городского уровня (Metro Ethernet). Протоколы канального уровня
Сети Ethernet городского уровня (Metro Ethernet). Протоколы канального уровня Полиморфизм (C#, лекция 3)
Полиморфизм (C#, лекция 3) Использование информационных технологий в школе
Использование информационных технологий в школе Биологическая нейронная сеть
Биологическая нейронная сеть Задачи на кодирование
Задачи на кодирование Поточные системы шифрования
Поточные системы шифрования История создания персонального компьютера и его компоненты
История создания персонального компьютера и его компоненты Мобільний застосунок мессенджер із використанням сучасних технологій
Мобільний застосунок мессенджер із використанням сучасних технологій Компьютерные сети, Интернет и мультимедиа технологии. Архитектура сетей
Компьютерные сети, Интернет и мультимедиа технологии. Архитектура сетей Этапы подготовки презентации
Этапы подготовки презентации Тера с вопросами о книге
Тера с вопросами о книге Информационная культура студента
Информационная культура студента Рисуем в WORD
Рисуем в WORD Новости в Молдове. Новости в мире
Новости в Молдове. Новости в мире Операционная система Ms-Dos
Операционная система Ms-Dos Интеллектуальные информационные системы управления. Лекция 5
Интеллектуальные информационные системы управления. Лекция 5 Применение опросного метода сбора информации
Применение опросного метода сбора информации Онлайн-игра World of Tanks
Онлайн-игра World of Tanks Профессиональные стандарты в области ИТ
Профессиональные стандарты в области ИТ Прохождение учебной практики
Прохождение учебной практики Система сбора и анализа сведений о преподавателях
Система сбора и анализа сведений о преподавателях Введение в курс информатики
Введение в курс информатики Подготовка эффективных презентаций
Подготовка эффективных презентаций