- Интеллектуальные информационные системы управления. Лекция 5

Содержание
- 2. 1. Основные понятия и определения теории интеллектуальных информационных систем управления.
- 6. Искусственный интеллект Искусственный интеллект – это область исследований, в рамках которых разрабатываются модели и методы решения
- 7. Краткая история искусственного интеллекта
- 8. Интеллектуальные информационные системы
- 9. Структура системы искусственного интеллекта (СИИ)
- 10. Понятие «знания» Понятие «знания» рассматривается с различных точек зрения. В соответствии с этим имеется много определений
- 11. Данными называют информацию фактического характера, описывающую объекты, процессы и явления предметной области, а также их свойства.
- 12. Основные отличия знаний от данных Знания по сравнению с данными обладают избыточными возможностями, помимо собственно данных
- 13. Характеристики представления знаний
- 14. Процессы получения знаний Следует различать два различных процесса получения знаний. Первый - это «извлечение» их из
- 15. 2. Структура и назначение экспертных систем. Экспертная система (ЭС) – это программный продукт, позволяющий имитировать творческую
- 16. Структура экспертных систем Статическая экспертная система
- 17. Структура экспертных систем Динамическая экспертная система В динамической ЭС по сравнению со статической вводятся два компонента:
- 18. Режимы работы экспертной системы
- 19. Модели представления знаний в экспертных системах К основным моделям представления знаний относятся: логические модели; продукционные модели;
- 20. Модели представления знаний в экспертных системах Продукционные модели Продукции являются наиболее популярными средствами представления знаний. В
- 21. Модели представления знаний в экспертных системах Сетевые модели В основе моделей этого типа лежит конструкция называемая
- 22. Модели представления знаний в экспертных системах Фреймовые модели В отличие от моделей других типов во фреймовых
- 23. 3. Добыча знаний (Data Mining) Определение добычи знаний (Data Mining) Data Mining переводится как "добыча" или
- 24. Области применения Data mining
- 25. Типы закономерностей, выявляемых методами Data Mining
- 26. Методы Data Mining 1. Нейронные сети Нейронные сети представляют большой класс систем, условно имитирующих нервную ткань
- 27. Методы Data Mining 1. Нейронные сети (продолжение) В одной из распространенных архитектур, двухслойном персептроне, имитируется работа
- 28. Нейросетевые технологии Модель персептрона Многослойная нейронная сеть
- 29. Проблемы практического использования нейросетей Определение оптимальной архитектуры сети. Выбор активационной функции и алгоритма обучения. Место нейросетевых
- 30. Аналитическая платформа Deductor Возможности, структура и схема обработки данных. Методы обработки: извлечение, очистка, манипулирование, моделиро-вание, прогнозирование,
- 31. Методы Data Mining 2. Деревья решений Деревья решений являются одним из наиболее популярных подходов к решению
- 32. Методы Data Mining 3. Системы рассуждений на основе аналогичных случаев (case based reasoning - CBR) Идея
- 33. Методы Data Mining 4. Генетические алгоритмы Методы генетических алгоритмов в какой-то степени имитирует процесс естественного отбора
- 34. Методы Data Mining 5. Эволюционное программирование Эволюционное программирование – сегодня самая молодая и наиболее перспективная ветвь
- 35. Методы Data Mining 6. Нечеткая логика (fuzzy logic) В окружающем нас мире очень редко приходится сталкиваться
- 36. Методы Data Mining 7. Статистические пакеты Последние версии почти всех известных статистических пакетов включают наряду с
- 37. Визуализация инструментов Data Mining Каждый из алгоритмов Data Mining использует определенный подход к визуализации. В ходе
- 39. Скачать презентацию

1. Основные понятия и определения теории интеллектуальных информационных систем управления.
1. Основные понятия и определения теории интеллектуальных информационных систем управления.




Искусственный интеллект
Искусственный интеллект – это область исследований, в рамках которых разрабатываются
Искусственный интеллект
Искусственный интеллект – это область исследований, в рамках которых разрабатываются
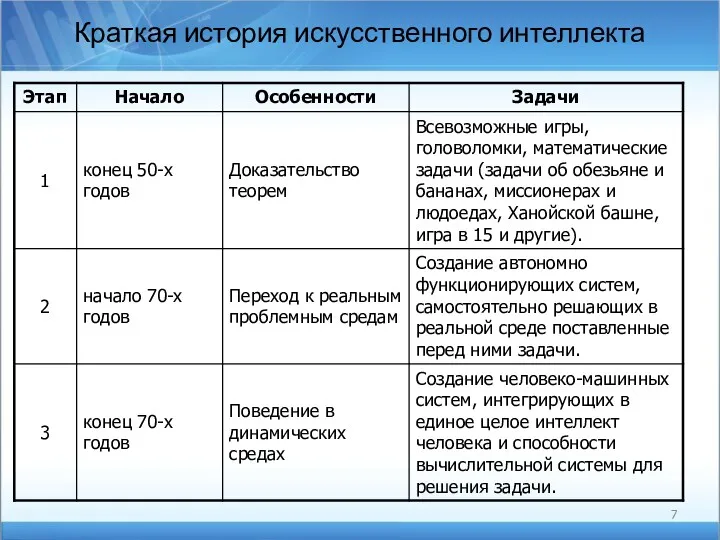
Краткая история искусственного интеллекта
Краткая история искусственного интеллекта
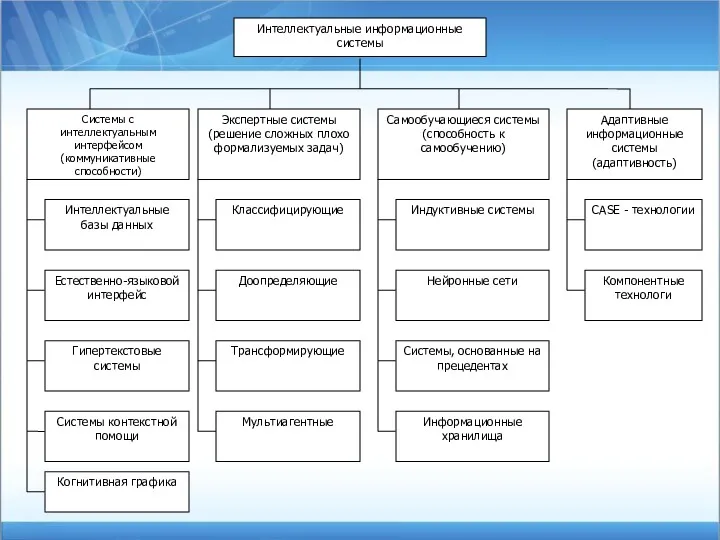
Интеллектуальные информационные системы
Интеллектуальные информационные системы
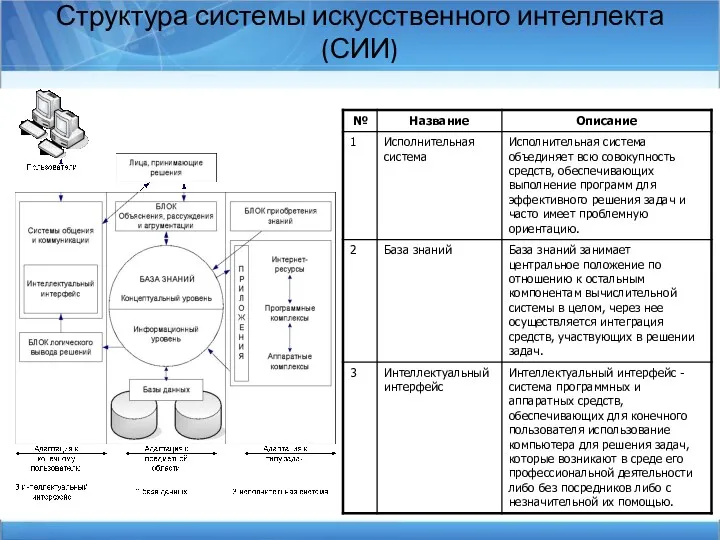
Структура системы искусственного интеллекта (СИИ)
Структура системы искусственного интеллекта (СИИ)
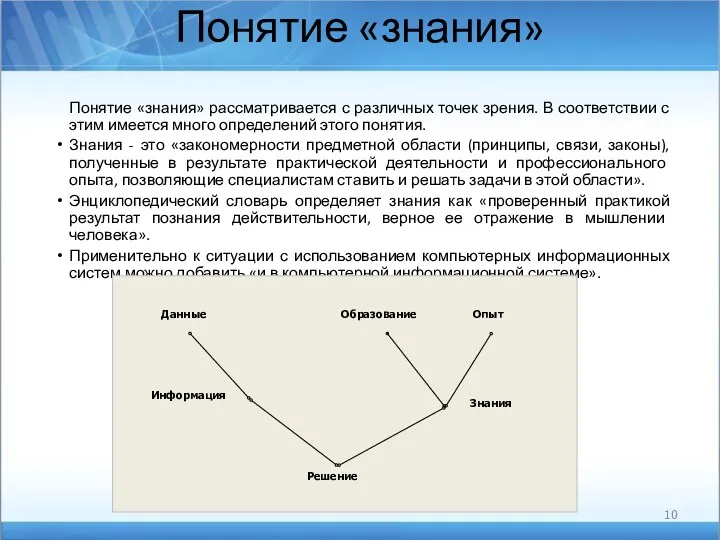
Понятие «знания»
Понятие «знания» рассматривается с различных точек зрения. В соответствии
Понятие «знания»
Понятие «знания» рассматривается с различных точек зрения. В соответствии

Данными называют информацию фактического характера, описывающую объекты, процессы и явления предметной
Данными называют информацию фактического характера, описывающую объекты, процессы и явления предметной
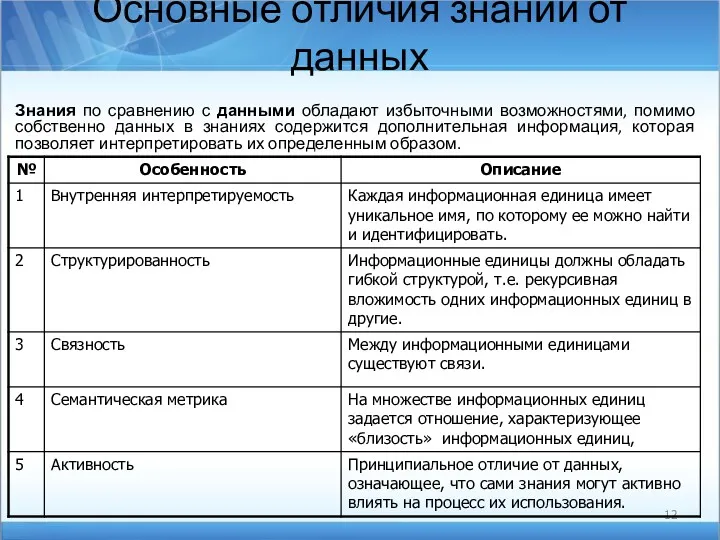
Основные отличия знаний от данных
Знания по сравнению с данными обладают избыточными
Основные отличия знаний от данных
Знания по сравнению с данными обладают избыточными
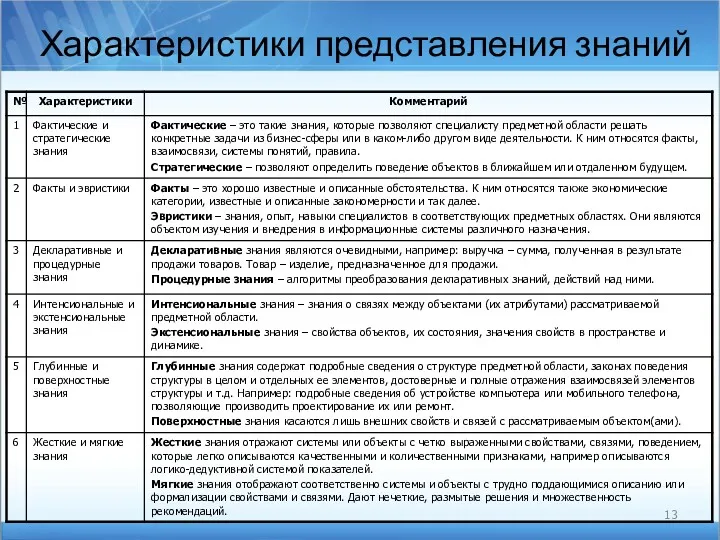
Характеристики представления знаний
Характеристики представления знаний

Процессы получения знаний
Следует различать два различных процесса получения знаний.
Первый -
Процессы получения знаний
Следует различать два различных процесса получения знаний.
Первый -

2. Структура и назначение экспертных систем.
Экспертная система (ЭС) – это
2. Структура и назначение экспертных систем.
Экспертная система (ЭС) – это
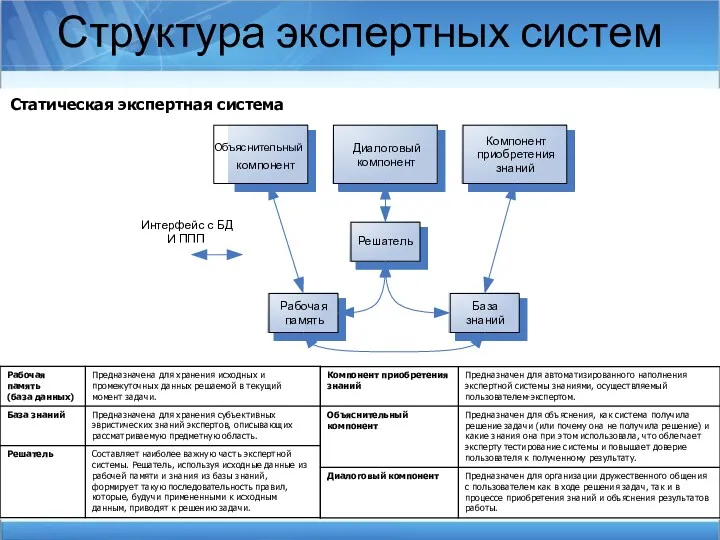
Структура экспертных систем
Статическая экспертная система
Структура экспертных систем
Статическая экспертная система
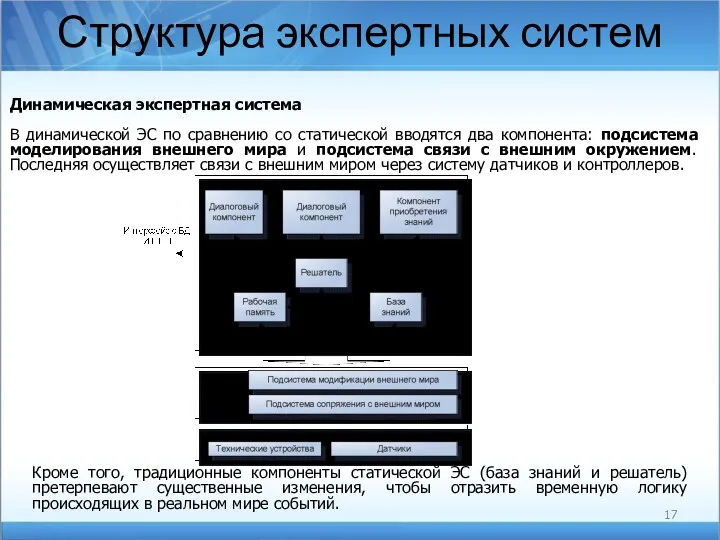
Структура экспертных систем
Динамическая экспертная система
В динамической ЭС по сравнению со
Структура экспертных систем
Динамическая экспертная система
В динамической ЭС по сравнению со

Режимы работы экспертной системы
Режимы работы экспертной системы

Модели представления знаний в экспертных системах
К основным моделям представления знаний относятся:
Модели представления знаний в экспертных системах
К основным моделям представления знаний относятся:

Модели представления знаний в экспертных системах
Продукционные модели
Продукции являются наиболее популярными средствами
Модели представления знаний в экспертных системах
Продукционные модели
Продукции являются наиболее популярными средствами
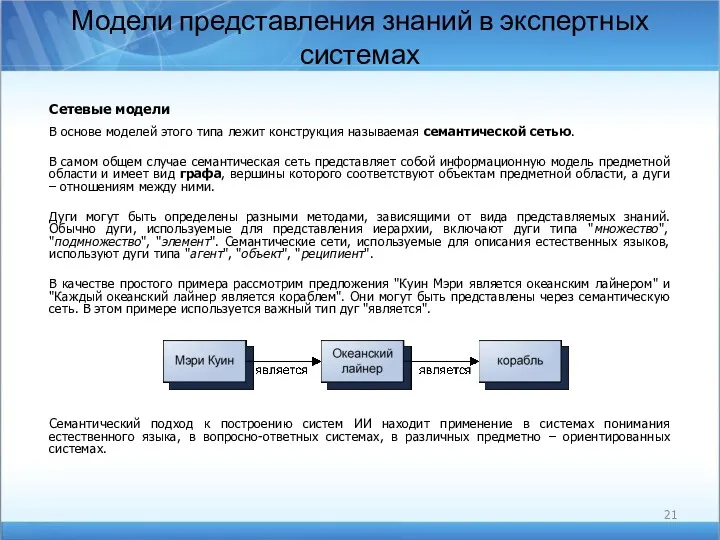
Модели представления знаний в экспертных системах
Сетевые модели
В основе моделей этого
Модели представления знаний в экспертных системах
Сетевые модели
В основе моделей этого

Модели представления знаний в экспертных системах
Фреймовые модели
В отличие от моделей
Модели представления знаний в экспертных системах
Фреймовые модели
В отличие от моделей

3. Добыча знаний (Data Mining)
Определение добычи знаний (Data Mining)
Data Mining переводится
3. Добыча знаний (Data Mining)
Определение добычи знаний (Data Mining)
Data Mining переводится
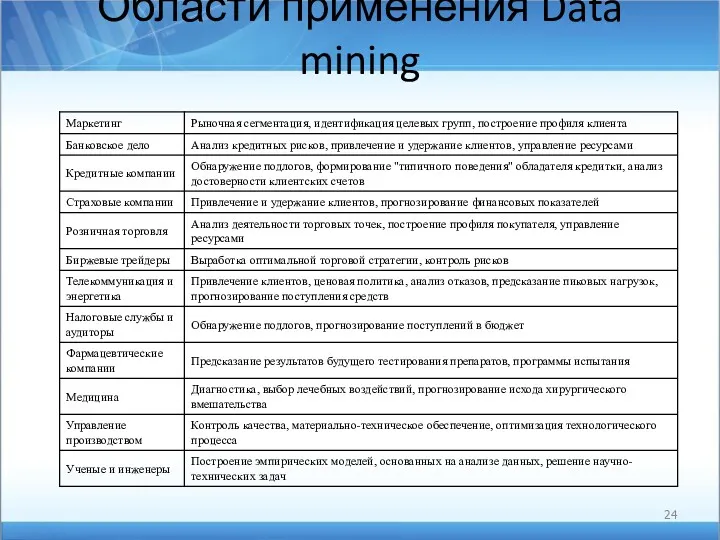
Области применения Data mining
Области применения Data mining
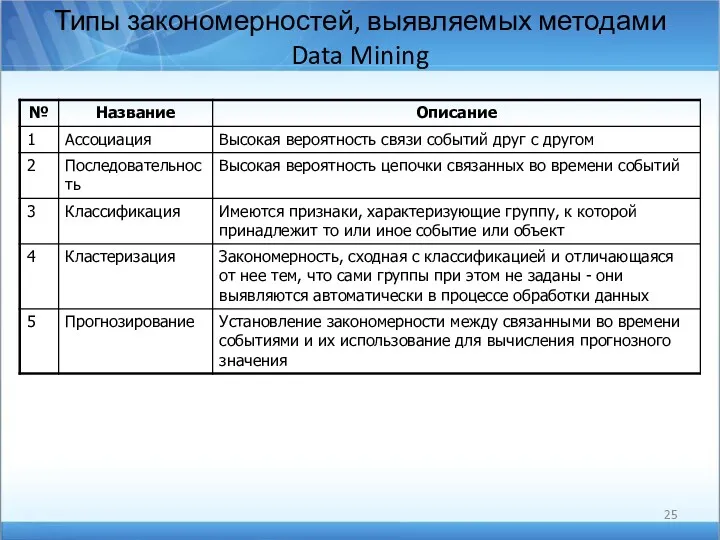
Типы закономерностей, выявляемых методами Data Mining
Типы закономерностей, выявляемых методами Data Mining

Методы Data Mining
1. Нейронные сети
Нейронные сети представляют большой класс систем,
Методы Data Mining
1. Нейронные сети
Нейронные сети представляют большой класс систем,

Методы Data Mining
1. Нейронные сети (продолжение)
В одной из распространенных архитектур,
Методы Data Mining
1. Нейронные сети (продолжение)
В одной из распространенных архитектур,
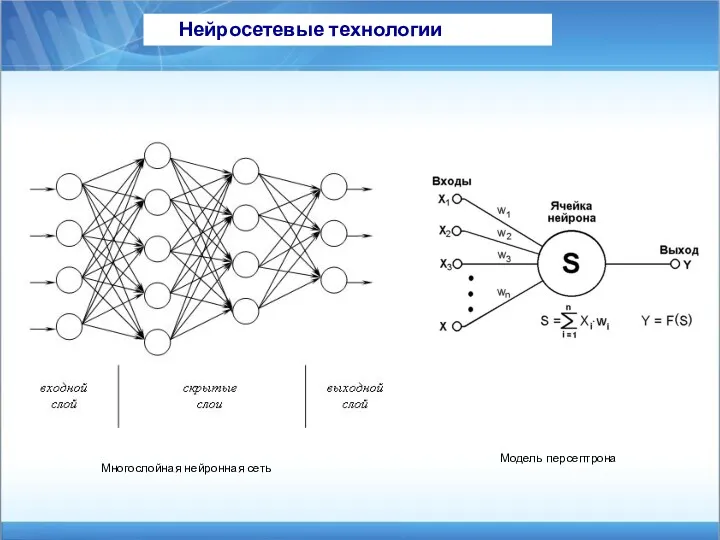
Нейросетевые технологии
Модель персептрона
Многослойная нейронная сеть
Нейросетевые технологии
Модель персептрона
Многослойная нейронная сеть
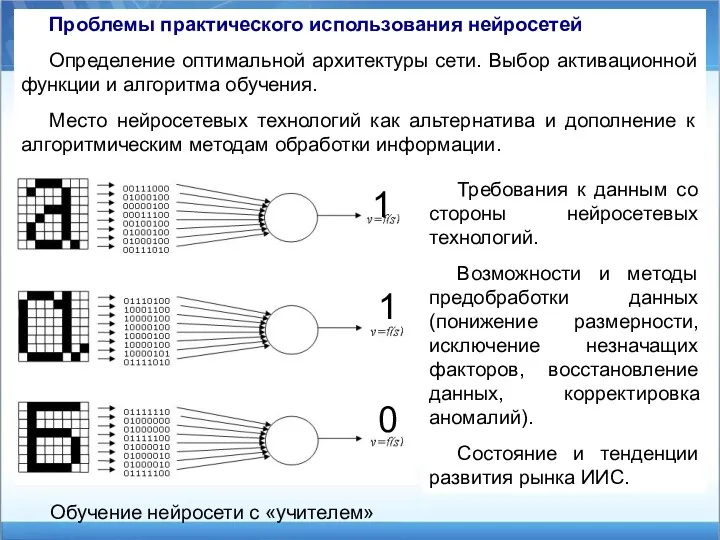
Проблемы практического использования нейросетей
Определение оптимальной архитектуры сети. Выбор активационной функции и
Проблемы практического использования нейросетей
Определение оптимальной архитектуры сети. Выбор активационной функции и
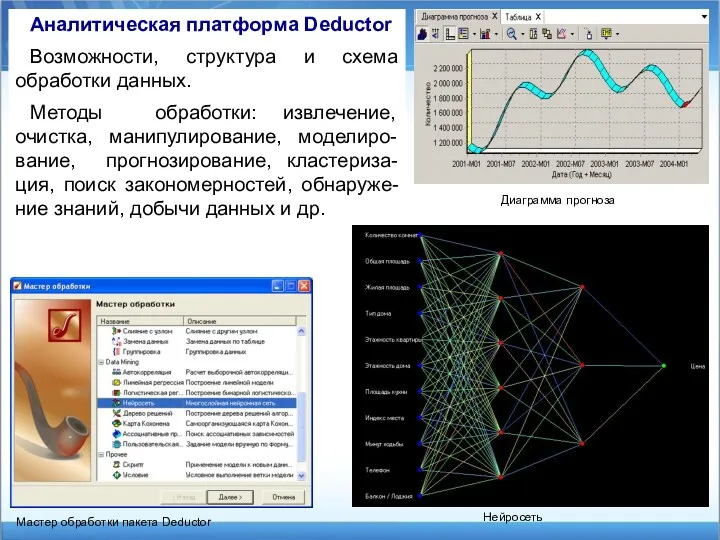
Аналитическая платформа Deductor
Возможности, структура и схема обработки данных.
Методы обработки: извлечение, очистка,
Аналитическая платформа Deductor
Возможности, структура и схема обработки данных.
Методы обработки: извлечение, очистка,
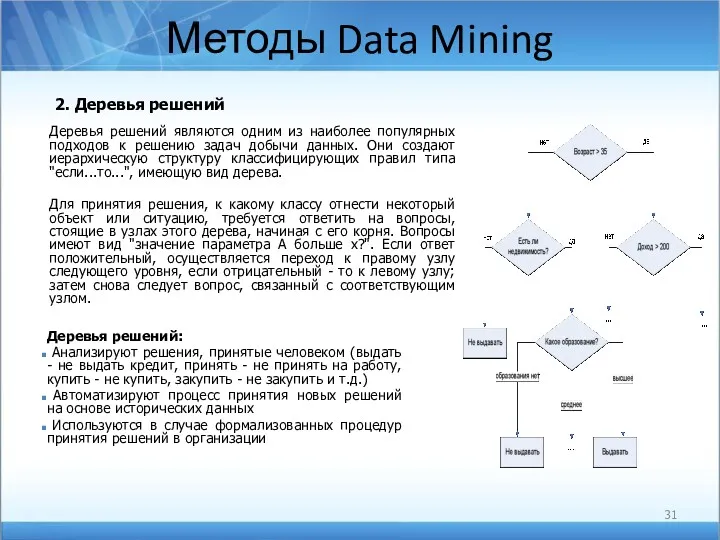
Методы Data Mining
2. Деревья решений
Деревья решений являются одним из наиболее
Методы Data Mining
2. Деревья решений
Деревья решений являются одним из наиболее

Методы Data Mining
3. Системы рассуждений на основе аналогичных случаев (case
Методы Data Mining
3. Системы рассуждений на основе аналогичных случаев (case
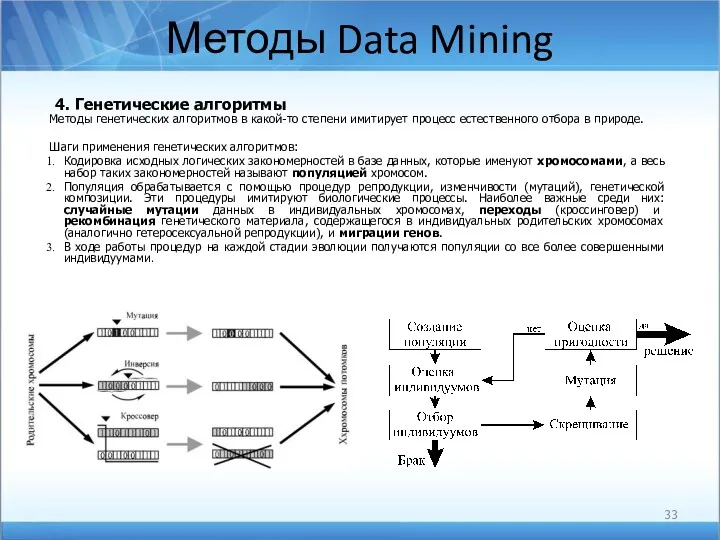
Методы Data Mining
4. Генетические алгоритмы
Методы генетических алгоритмов в какой-то степени
Методы Data Mining
4. Генетические алгоритмы
Методы генетических алгоритмов в какой-то степени

Методы Data Mining
5. Эволюционное программирование
Эволюционное программирование – сегодня самая молодая
Методы Data Mining
5. Эволюционное программирование
Эволюционное программирование – сегодня самая молодая

Методы Data Mining
6. Нечеткая логика (fuzzy logic)
В окружающем нас мире
Методы Data Mining
6. Нечеткая логика (fuzzy logic)
В окружающем нас мире
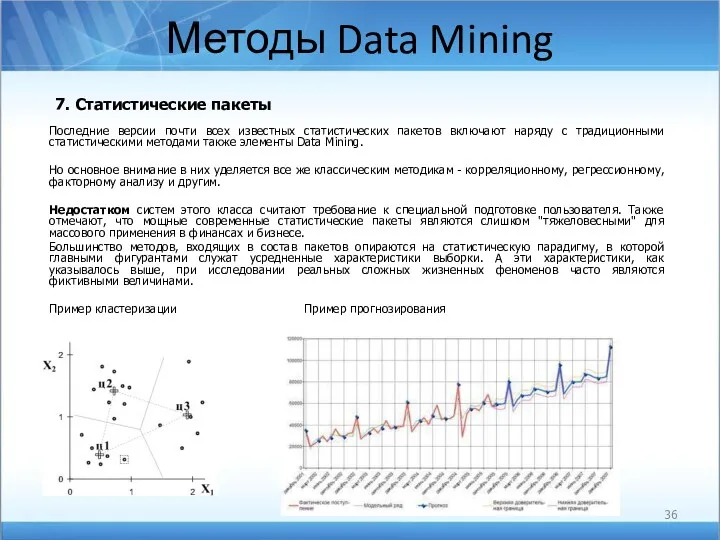
Методы Data Mining
7. Статистические пакеты
Последние версии почти всех известных статистических
Методы Data Mining
7. Статистические пакеты
Последние версии почти всех известных статистических

Визуализация инструментов Data Mining
Каждый из алгоритмов Data Mining использует определенный
Визуализация инструментов Data Mining
Каждый из алгоритмов Data Mining использует определенный
 Внеклассное мероприятие по информатике для начальной школы Кодировщики
Внеклассное мероприятие по информатике для начальной школы Кодировщики Алгоритмы информационного поиска и сортировки
Алгоритмы информационного поиска и сортировки Введение в Python
Введение в Python Оформление списка литературы. Библиографические БД
Оформление списка литературы. Библиографические БД Понятие информационная безопасность. Составляющие ИБ
Понятие информационная безопасность. Составляющие ИБ Блочные алгоритмы. Блочное шифрование. Сравнение блочных и поточных шифров. Предпосылки создания шифра Фейстеля
Блочные алгоритмы. Блочное шифрование. Сравнение блочных и поточных шифров. Предпосылки создания шифра Фейстеля Виды компьютерной графики. Понятие растровой графики
Виды компьютерной графики. Понятие растровой графики Работа в текстовом редакторе Microsoft Word 2010. Редактирование текста
Работа в текстовом редакторе Microsoft Word 2010. Редактирование текста Информатика. Инструкция к тестированию
Информатика. Инструкция к тестированию Методология научно-исследовательских и опытно-конструкторских работ. Термины и определения. (Лекция 1)
Методология научно-исследовательских и опытно-конструкторских работ. Термины и определения. (Лекция 1) Компьютерная графика. Графический редактор. Устройства ввода графической информации
Компьютерная графика. Графический редактор. Устройства ввода графической информации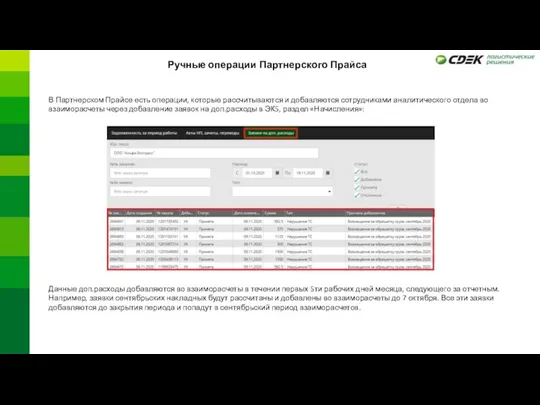 Ручные операции Партнерского Прайса
Ручные операции Партнерского Прайса Розрахунок показників надійності по специфічним даним
Розрахунок показників надійності по специфічним даним Вкладені алгоритмічні структури повторення з передумовою та лічильником
Вкладені алгоритмічні структури повторення з передумовою та лічильником Сравнение множеств.
Сравнение множеств. Модернизация мультисервисной сети на базе сетей будущего поколения NGN
Модернизация мультисервисной сети на базе сетей будущего поколения NGN Спільне використання ресурсів локальної мережі
Спільне використання ресурсів локальної мережі Циклы. Основные понятия
Циклы. Основные понятия Базы данных
Базы данных Глобальная компьютерная сеть Интернет
Глобальная компьютерная сеть Интернет Конрад Цузе
Конрад Цузе Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов ЗВ при механической обработке металлов
Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов ЗВ при механической обработке металлов Принципы проектирования локальных и глобальных сетей
Принципы проектирования локальных и глобальных сетей Шкільна бібліотека – інформаційний центр навчального закладу
Шкільна бібліотека – інформаційний центр навчального закладу Материалды сараптауға дайындау
Материалды сараптауға дайындау Современные проблемы информационной эпохи: новые вызовы для человека и общества
Современные проблемы информационной эпохи: новые вызовы для человека и общества Категории каналов
Категории каналов Кодирование и обработка звуковой информации
Кодирование и обработка звуковой информации