- Распределённые базы данных

Содержание
- 2. Московский авиационный институт (национальный исследовательский университет) ПРОЕТИРОВАНИЕ БАЗ ДАННЫХ Направление подготовки: Прикладная математика и информатика Факультет
- 3. Лекция 10 Распределённые базы данных Учебные вопросы: 10.1 Общие понятия распределённых баз данных 10.2 Архитектура распределенных
- 4. 10.1 Общие понятия распределённых баз данных
- 5. Мы можем определить распределенные базы данных как совокупность множества логически взаимосвязанных баз данных, распределенных в вычислительной
- 6. Способы реализации распределенных БД: - распределенные многопроцессорные системы; - разделяемая общая память для нескольких вычислительных систем;
- 11. Распределённые базы в локальной сети
- 13. Особенности РБД Уровни независимости: • Управление распределенными базами данных и репликациями • Распределенные приложения • Сетевая
- 14. Факторы сложности РБД • Три основных фактора добавляют сложности реализации РБД: – Возможное решение на основе
- 15. Проблемные области • Разработка распределенных баз данных: - не реплицированные (распределение без повторов на различных сайтах
- 16. Проблемные области • Управление распределенными блокировками. Механизм синхронизации управления ресурсами (данными) построен на блокировках. • Надежность
- 17. 10.2 Архитектура распределенных СУБД
- 18. Архитектура распределенных СУБД Взаимосвязь между архитектурой систем и референтной моделью этой системы, основывается на трех подходах:
- 19. ANSI/SPARC architecture – отчет 1978 года, который определил основную архитектуру СУБД и БД в области стандартизации,
- 21. Автономия. Этот термин относится к управлению распределением, а не к данным. Он показывает степень в рамках
- 22. Альтернативы архитектуры Для идентификации архитектуры мы используем нотацию основанную на трех измерениях: А ( автономия), D
- 23. • (A0, D2, H0) – полностью распределенная однородная СУБД; • (A2, D2, H1) – распределенная в
- 24. • (A1, D0, H1) – полностью распределенная неоднородная СУБД, которую можно назвать еще и неоднородная федеративная
- 25. • Клиент/серверные системы; • Распределенная по равноправным узлам БД; • Системы мультибазданных. Архитектура распределенных СУБД
- 27. Клиент/серверные системы • Клиент – это любой процесс, который запрашивает определенные ресурсы или сервисы от других
- 28. Клиент/серверные системы • Клиент/серверные системы делятся на двухзвенные и трехзвенные; • Двухзвенные – клиент запрашивает сервисы
- 29. Ожидания специалистов ИТ от клиент/серверных технологий: - сокращение стоимости разработки и реализации; - уменьшение времени на
- 30. Ожидания бизнеса от клиент/серверных технологий: - гибкость и адаптивность; - повышение производительности труда сотрудников; - оптимизация
- 31. • Клиент – любой процесс компьютера, который запрашивает сервис от сервера. Клиент называется интерфейсным приложением, что
- 32. Независимость от оборудования; Независимость от ПО: Правила архитектуры «клиент/сервер» – операционной системы; – сетевой системы; –
- 33. Компоненты клиента: • Мощное оборудование; • Операционная система с возможностью много задачной обработки информации; • Графический
- 34. Характеристики серверного оборудования • Быстрый процессор; • Высокая отказоустойчивость (двойное питание, резервный ИБП, обнаружение и исправлении
- 35. Компоненты ППО базы данных • Программный интерфейс приложения (API). Открыт для клиентского приложения. Программист взаимодействует с
- 37. Типичное размещение сервисов • логика представления всегда размещается на стороне клиента, т.к. предполагает взаимодействие с конечным
- 38. Проблемы реализации клиент/серверных систем • От частных систем к открытым системам (системы должны объединятся и быть
- 40. Скачать презентацию

Московский авиационный институт
(национальный исследовательский университет)
ПРОЕТИРОВАНИЕ БАЗ ДАННЫХ
Направление подготовки: Прикладная математика и
Московский авиационный институт
(национальный исследовательский университет)
ПРОЕТИРОВАНИЕ БАЗ ДАННЫХ
Направление подготовки: Прикладная математика и

Лекция 10 Распределённые базы данных
Учебные вопросы:
10.1 Общие понятия распределённых баз данных
10.2
Лекция 10 Распределённые базы данных
Учебные вопросы:
10.1 Общие понятия распределённых баз данных
10.2

10.1 Общие понятия распределённых баз данных
10.1 Общие понятия распределённых баз данных

Мы можем определить распределенные базы данных как совокупность множества логически взаимосвязанных
Мы можем определить распределенные базы данных как совокупность множества логически взаимосвязанных

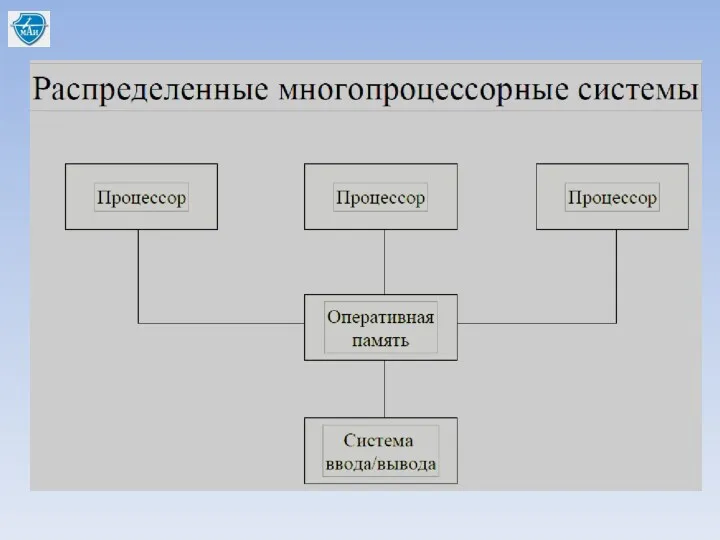
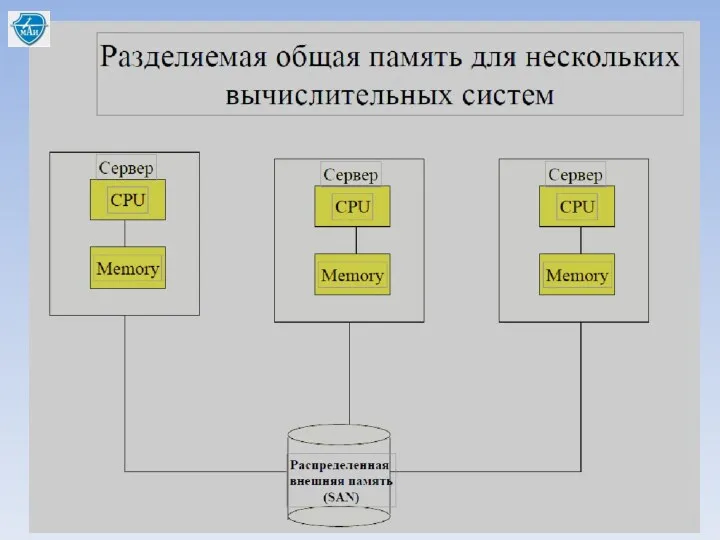
Способы реализации распределенных БД:
- распределенные многопроцессорные системы;
- разделяемая общая память для
Способы реализации распределенных БД:
- распределенные многопроцессорные системы;
- разделяемая общая память для
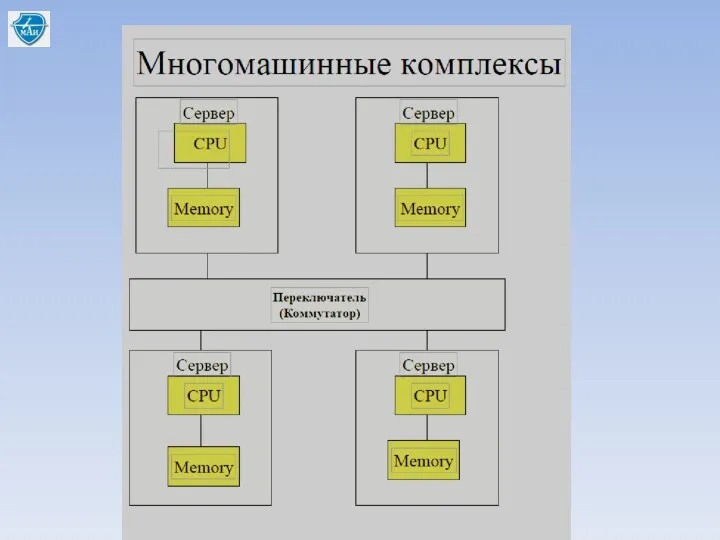
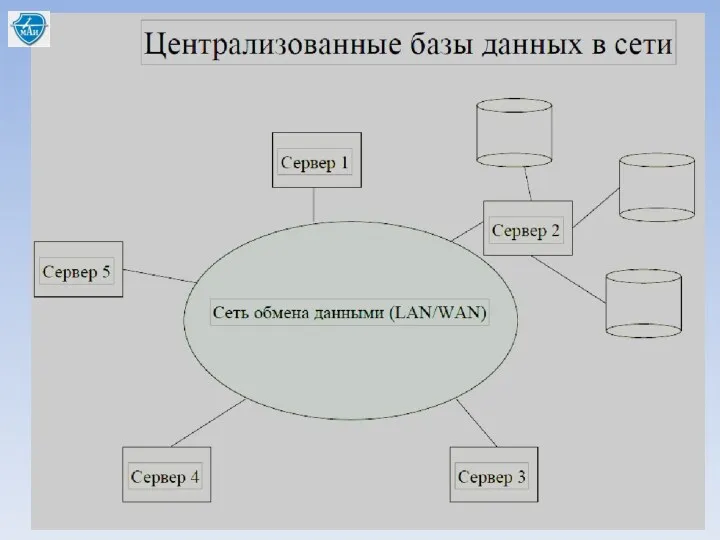
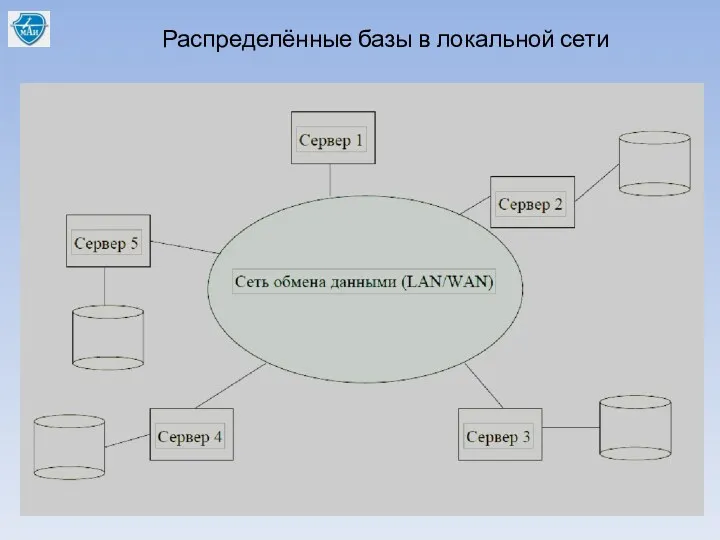
Распределённые базы в локальной сети
Распределённые базы в локальной сети

Особенности РБД
Уровни независимости:
• Управление распределенными базами данных и репликациями
• Распределенные приложения
•
Особенности РБД
Уровни независимости:
• Управление распределенными базами данных и репликациями
• Распределенные приложения
•

Факторы сложности РБД
• Три основных фактора добавляют сложности реализации РБД:
– Возможное решение
Факторы сложности РБД
• Три основных фактора добавляют сложности реализации РБД:
– Возможное решение

Проблемные области
• Разработка распределенных баз данных:
- не реплицированные (распределение без повторов
Проблемные области
• Разработка распределенных баз данных:
- не реплицированные (распределение без повторов

Проблемные области
• Управление распределенными блокировками.
Механизм синхронизации управления ресурсами (данными) построен
Проблемные области
• Управление распределенными блокировками.
Механизм синхронизации управления ресурсами (данными) построен

10.2 Архитектура распределенных СУБД
10.2 Архитектура распределенных СУБД

Архитектура распределенных СУБД
Взаимосвязь между архитектурой систем и референтной моделью этой системы,
Архитектура распределенных СУБД
Взаимосвязь между архитектурой систем и референтной моделью этой системы,
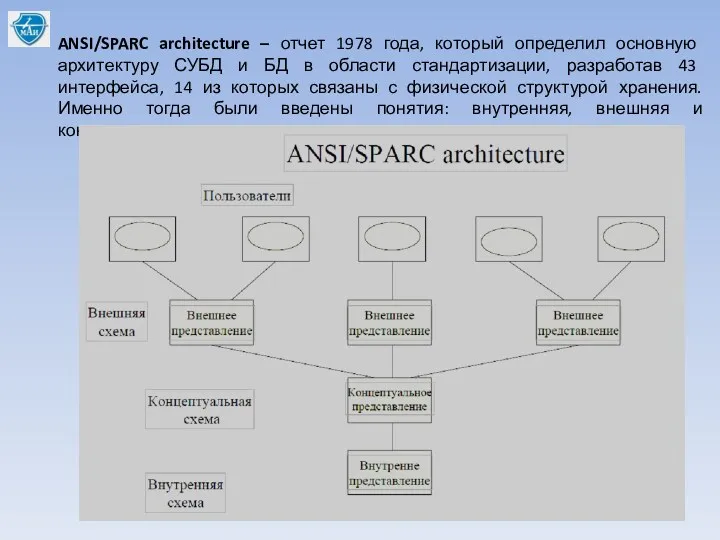
ANSI/SPARC architecture – отчет 1978 года, который определил основную архитектуру СУБД
ANSI/SPARC architecture – отчет 1978 года, который определил основную архитектуру СУБД


Автономия. Этот термин относится к управлению распределением, а не к данным.
Автономия. Этот термин относится к управлению распределением, а не к данным.

Альтернативы архитектуры
Для идентификации архитектуры мы используем нотацию основанную на трех измерениях:
Альтернативы архитектуры
Для идентификации архитектуры мы используем нотацию основанную на трех измерениях:

• (A0, D2, H0) – полностью распределенная однородная СУБД;
• (A2, D2,
• (A0, D2, H0) – полностью распределенная однородная СУБД;
• (A2, D2,

• (A1, D0, H1) – полностью распределенная неоднородная СУБД, которую можно назвать
• (A1, D0, H1) – полностью распределенная неоднородная СУБД, которую можно назвать

• Клиент/серверные системы;
• Распределенная по равноправным узлам БД;
• Системы мультибазданных.
Архитектура распределенных
• Клиент/серверные системы;
• Распределенная по равноправным узлам БД;
• Системы мультибазданных.
Архитектура распределенных
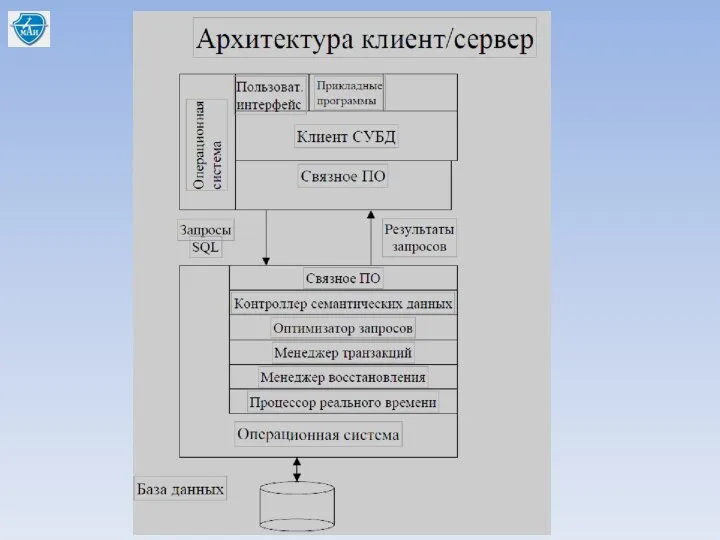

Клиент/серверные системы
• Клиент – это любой процесс, который запрашивает определенные ресурсы
Клиент/серверные системы
• Клиент – это любой процесс, который запрашивает определенные ресурсы

Клиент/серверные системы
• Клиент/серверные системы делятся на двухзвенные и трехзвенные;
• Двухзвенные –
Клиент/серверные системы
• Клиент/серверные системы делятся на двухзвенные и трехзвенные;
• Двухзвенные –

Ожидания специалистов ИТ от клиент/серверных технологий:
- сокращение стоимости разработки и реализации;
-
Ожидания специалистов ИТ от клиент/серверных технологий:
- сокращение стоимости разработки и реализации;
-

Ожидания бизнеса от клиент/серверных технологий:
- гибкость и адаптивность;
- повышение производительности труда
Ожидания бизнеса от клиент/серверных технологий:
- гибкость и адаптивность;
- повышение производительности труда

• Клиент – любой процесс компьютера, который запрашивает сервис от сервера. Клиент
• Клиент – любой процесс компьютера, который запрашивает сервис от сервера. Клиент

Независимость от оборудования;
Независимость от ПО:
Правила архитектуры «клиент/сервер»
– операционной системы;
– сетевой системы;
– приложений.
Открытый доступ к
Независимость от оборудования;
Независимость от ПО:
Правила архитектуры «клиент/сервер»
– операционной системы;
– сетевой системы;
– приложений.
Открытый доступ к

Компоненты клиента:
• Мощное оборудование;
• Операционная система с возможностью много задачной обработки
Компоненты клиента:
• Мощное оборудование;
• Операционная система с возможностью много задачной обработки

Характеристики серверного оборудования
• Быстрый процессор;
• Высокая отказоустойчивость (двойное питание, резервный ИБП,
Характеристики серверного оборудования
• Быстрый процессор;
• Высокая отказоустойчивость (двойное питание, резервный ИБП,

Компоненты ППО базы данных
• Программный интерфейс приложения (API). Открыт для клиентского
Компоненты ППО базы данных
• Программный интерфейс приложения (API). Открыт для клиентского
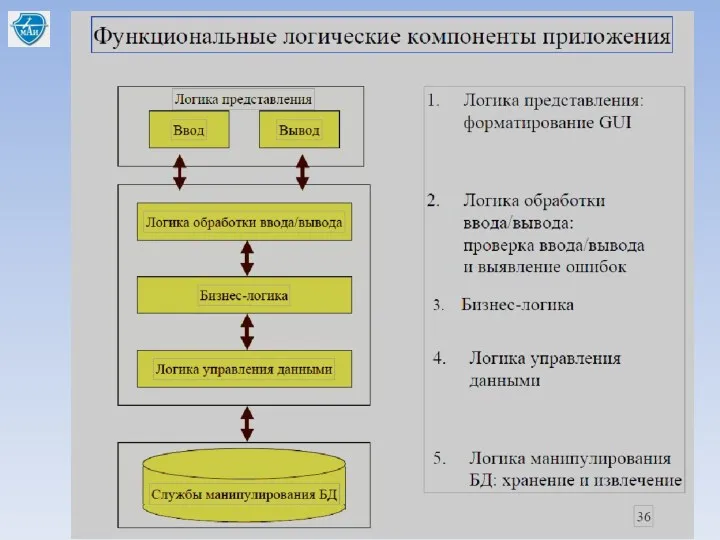

Типичное размещение сервисов
• логика представления всегда размещается на стороне клиента, т.к.
Типичное размещение сервисов
• логика представления всегда размещается на стороне клиента, т.к.

Проблемы реализации клиент/серверных систем
• От частных систем к открытым системам (системы
Проблемы реализации клиент/серверных систем
• От частных систем к открытым системам (системы
 Особый правовой режим информации
Особый правовой режим информации Install USB driver
Install USB driver М-файлдар
М-файлдар Методическая разработка внеклассного мероприятия (интеллектуальная игра) по физике и информатике для учащихся 5-11 классов Кто хочет стать отличником
Методическая разработка внеклассного мероприятия (интеллектуальная игра) по физике и информатике для учащихся 5-11 классов Кто хочет стать отличником Информация и информационные процессы в живой и неживой природе
Информация и информационные процессы в живой и неживой природе Платформа Android
Платформа Android Информационные технологии в электроэнергетике и электротехнике
Информационные технологии в электроэнергетике и электротехнике Руководство пользователя по работе в SAP SRM
Руководство пользователя по работе в SAP SRM Проектирование связей между таблицами баз данных
Проектирование связей между таблицами баз данных Программирование на языке Си
Программирование на языке Си Электронные таблицы. Решение задач
Электронные таблицы. Решение задач Технология RMI. Java. (Лекция 15)
Технология RMI. Java. (Лекция 15) ГИП. Диалоги
ГИП. Диалоги открытый урок Реализация логических операций в компьютере
открытый урок Реализация логических операций в компьютере Презентация к уроку информатики по теме Интернет: вред или польза?
Презентация к уроку информатики по теме Интернет: вред или польза? Современные технологии в помощь обучению иностранным языкам. Rosetta Stone
Современные технологии в помощь обучению иностранным языкам. Rosetta Stone Настройки и удаление Retail Demo
Настройки и удаление Retail Demo Передача информации. Схема передачи информации. Электронная почта
Передача информации. Схема передачи информации. Электронная почта The state of techniques for solving large imperfect-information games
The state of techniques for solving large imperfect-information games Определение жизненного цикла программных средств
Определение жизненного цикла программных средств Краткая инструкция по работе с новой учетной системой 1С 8.3
Краткая инструкция по работе с новой учетной системой 1С 8.3 Разработка консольного приложения с элементами ООП. Интернет магазин продуктов
Разработка консольного приложения с элементами ООП. Интернет магазин продуктов Правовые нормы, относящиеся к информации, правонарушения в информационной сфере, меры их предупреждения
Правовые нормы, относящиеся к информации, правонарушения в информационной сфере, меры их предупреждения Інформаційна гігієна
Інформаційна гігієна Parallel programming technologies on hybrid architectures
Parallel programming technologies on hybrid architectures Количество информации
Количество информации Разработка информационной системы для туристической фирмы
Разработка информационной системы для туристической фирмы Ежемесячные интернет пакеты
Ежемесячные интернет пакеты