- The state of techniques for solving large imperfect-information games

Содержание
- 2. Incomplete-information game tree Information set 0.3 0.5 0.2 0.5 0.5 Strategy, beliefs
- 3. Tackling such games Domain-independent techniques Techniques for complete-info games don’t apply Challenges Unknown state Uncertainty about
- 4. Most real-world games are like this Negotiation Multi-stage auctions (FCC ascending, combinatorial) Sequential auctions of multiple
- 5. Poker Recognized challenge problem in AI since 1992 [Billings, Schaeffer, …] Hidden information (other players’ cards)
- 6. Our approach [Gilpin & Sandholm EC-06, J. of the ACM 2007…] Now used basically by all
- 7. Lossless abstraction [Gilpin & Sandholm EC-06, J. of the ACM 2007]
- 8. Information filters Observation: We can make games smaller by filtering the information a player receives Instead
- 9. Solved Rhode Island Hold’em poker AI challenge problem [Shi & Littman 01] 3.1 billion nodes in
- 10. Lossy abstraction
- 11. Texas Hold’em poker 2-player Limit has ~1014 info sets 2-player No-Limit has ~10161 info sets Losslessly
- 12. Important ideas for practical game abstraction 2007-13 Integer programming [Gilpin & Sandholm AAMAS-07] Potential-aware [Gilpin, Sandholm
- 13. Leading practical abstraction algorithm: Potential-aware imperfect-recall abstraction with earth-mover’s distance [Ganzfried & Sandholm AAAI-14] Bottom-up pass
- 14. Techniques used to develop Tartanian7, program that won the heads-up no-limit Texas Hold’em ACPC-14 [Brown, Ganzfried,
- 15. Lossy Game Abstraction with Bounds
- 16. Lossy game abstraction with bounds Tricky due to abstraction pathology [Waugh et al. AAMAS-09] Prior lossy
- 17. Bounding abstraction quality Main theorem: where ε=max i∈Players εi Reward error Set of heights for player
- 18. Hardness results Determining whether two subtrees are “extensive-form game-tree isomorphic” is graph isomorphism complete Computing the
- 19. Extension to imperfect recall Merge information sets Allows payoff error Allows chance error Going to imperfect-recall
- 20. Role in modeling All modeling is abstraction These are the first results that tie game modeling
- 21. Nash equilibrium Nash equilibrium Original game Abstracted game Automated abstraction Custom equilibrium-finding algorithm Reverse model
- 22. Scalability of (near-)equilibrium finding in 2-player 0-sum games
- 23. Scalability of (near-)equilibrium finding in 2-player 0-sum games… GS3 [Gilpin, Sandholm & Sørensen] Hyperborean [Bowling et
- 24. Leading equilibrium-finding algorithms for 2-player 0-sum games Counterfactual regret (CFR) Based on no-regret learning Most powerful
- 25. Better first-order methods [Kroer, Waugh, Kılınç-Karzan & Sandholm EC-15] New prox function for first-order methods such
- 26. Computing equilibria by leveraging qualitative models Theorem. Given F1, F2, and a qualitative model, we have
- 27. Simultaneous Abstraction and Equilibrium Finding in Games [Brown & Sandholm IJCAI-15 & new manuscript]
- 28. Problems solved Cannot solve without abstracting, and cannot principally abstract without solving SAEF abstracts and solves
- 29. OPPONENT EXPLOITATION
- 30. Traditionally two approaches Game theory approach (abstraction+equilibrium finding) Safe in 2-person 0-sum games Doesn’t maximally exploit
- 31. Let’s hybridize the two approaches Start playing based on pre-computed (near-)equilibrium As we learn opponent(s) deviate
- 32. Other modern approaches to opponent exploitation ε-safe best response [Johanson, Zinkevich & Bowling NIPS-07, Johanson &
- 33. Safe opponent exploitation Definition. Safe strategy achieves at least the value of the (repeated) game in
- 34. Exploitation algorithms Risk what you’ve won so far Risk what you’ve won so far in expectation
- 35. STATE OF TOP POKER PROGRAMS
- 36. Rhode Island Hold’em Bots play optimally [Gilpin & Sandholm EC-06, J. of the ACM 2007]
- 37. Heads-Up Limit Texas Hold’em Bots surpassed pros in 2008 [U. Alberta Poker Research Group] “Essentially solved”
- 38. Heads-Up No-Limit Texas Hold’em Annual Computer Poker Competition --> Claudico Tartanian7 Statistical significance win against every
- 39. “BRAINS VS AI” EVENT
- 40. Claudico against each of 4 of the top-10 pros in this game 4 * 20,000 hands
- 42. Humans’ $100,000 participation fee distributed based on performance
- 43. Overall performance Pros won by 91 mbb/hand Not statistically significant (at 95% confidence) Perspective: Dong Kim
- 44. Observations about Claudico’s play Strengths (beyond what pros typically do): Small bets & huge all-ins Perfect
- 45. Multiplayer poker Bots aren’t very strong (at least not yet) Exception: programs are very close to
- 46. Conclusions Domain-independent techniques Abstraction Automated lossless abstraction—exactly solves games with billions of nodes Best practical lossy
- 47. Current & future research Lossy abstraction with bounds Scalable algorithms With structure With generated abstract states
- 49. Скачать презентацию
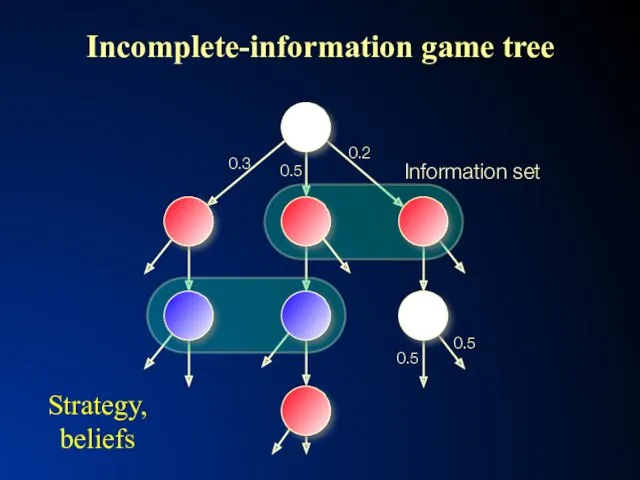
Incomplete-information game tree
Information set
0.3
0.5
0.2
0.5
0.5
Strategy,
beliefs
Incomplete-information game tree
Information set
0.3
0.5
0.2
0.5
0.5
Strategy,
beliefs

Tackling such games
Domain-independent techniques
Techniques for complete-info games don’t apply
Challenges
Unknown state
Uncertainty about
Tackling such games
Domain-independent techniques
Techniques for complete-info games don’t apply
Challenges
Unknown state
Uncertainty about

Most real-world games are like this
Negotiation
Multi-stage auctions (FCC ascending, combinatorial)
Sequential auctions
Most real-world games are like this
Negotiation
Multi-stage auctions (FCC ascending, combinatorial)
Sequential auctions

Poker
Recognized challenge problem in AI since 1992 [Billings, Schaeffer, …]
Hidden information
Poker
Recognized challenge problem in AI since 1992 [Billings, Schaeffer, …]
Hidden information
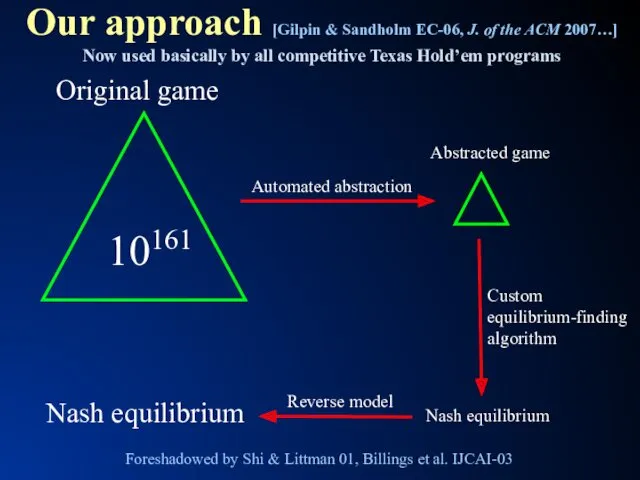
Our approach [Gilpin & Sandholm EC-06, J. of the ACM 2007…]
Now
Our approach [Gilpin & Sandholm EC-06, J. of the ACM 2007…] Now
![Lossless abstraction [Gilpin & Sandholm EC-06, J. of the ACM 2007]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/12865/slide-6.jpg)
Lossless abstraction
[Gilpin & Sandholm EC-06, J. of the ACM 2007]
Lossless abstraction
[Gilpin & Sandholm EC-06, J. of the ACM 2007]

Information filters
Observation: We can make games smaller by filtering the information
Information filters
Observation: We can make games smaller by filtering the information

Solved Rhode Island Hold’em poker
AI challenge problem [Shi & Littman 01]
3.1
Solved Rhode Island Hold’em poker
AI challenge problem [Shi & Littman 01]
3.1

Lossy abstraction
Lossy abstraction

Texas Hold’em poker
2-player Limit has ~1014 info sets
2-player No-Limit has ~10161
Texas Hold’em poker
2-player Limit has ~1014 info sets
2-player No-Limit has ~10161

Important ideas for practical
game abstraction 2007-13
Integer programming [Gilpin & Sandholm
Important ideas for practical
game abstraction 2007-13
Integer programming [Gilpin & Sandholm

Leading practical abstraction algorithm:
Potential-aware imperfect-recall abstraction with earth-mover’s distance
[Ganzfried & Sandholm
Leading practical abstraction algorithm: Potential-aware imperfect-recall abstraction with earth-mover’s distance [Ganzfried & Sandholm

Techniques used to develop Tartanian7, program that won the heads-up no-limit
Techniques used to develop Tartanian7, program that won the heads-up no-limit

Lossy Game Abstraction with Bounds
Lossy Game Abstraction with Bounds

Lossy game abstraction with bounds
Tricky due to abstraction pathology [Waugh et
Lossy game abstraction with bounds
Tricky due to abstraction pathology [Waugh et

Bounding abstraction quality
Main theorem:
where ε=max i∈Players εi
Reward error
Set of heights
Bounding abstraction quality
Main theorem:
where ε=max i∈Players εi
Reward error
Set of heights

Hardness results
Determining whether two subtrees are “extensive-form game-tree isomorphic” is graph
Hardness results
Determining whether two subtrees are “extensive-form game-tree isomorphic” is graph

Extension to imperfect recall
Merge information sets
Allows payoff error
Allows chance error
Going to
Extension to imperfect recall
Merge information sets
Allows payoff error
Allows chance error
Going to

Role in modeling
All modeling is abstraction
These are the first results that
Role in modeling
All modeling is abstraction
These are the first results that
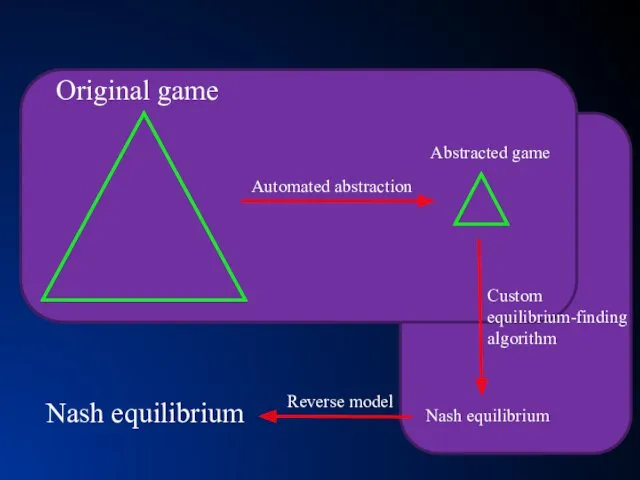
Nash equilibrium
Nash equilibrium
Original game
Abstracted game
Automated abstraction
Custom
equilibrium-finding
algorithm
Reverse model
Nash equilibrium
Nash equilibrium
Original game
Abstracted game
Automated abstraction
Custom
equilibrium-finding
algorithm
Reverse model
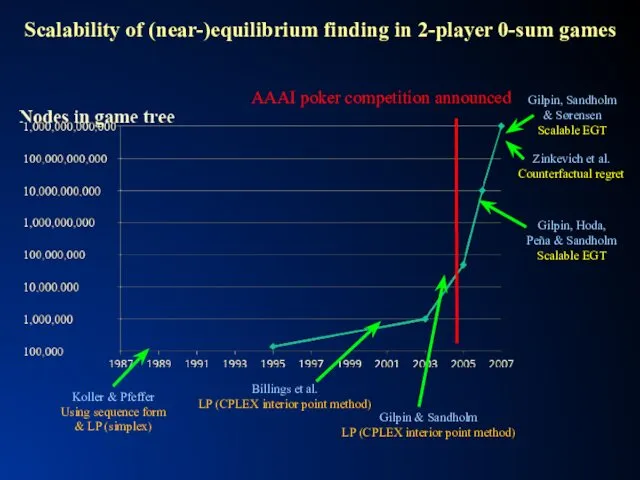
Scalability of (near-)equilibrium finding in 2-player 0-sum games
Scalability of (near-)equilibrium finding in 2-player 0-sum games
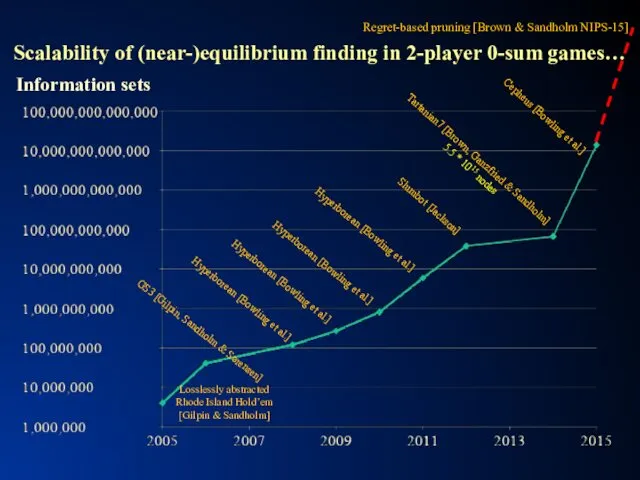
Scalability of (near-)equilibrium finding in 2-player 0-sum games…
GS3 [Gilpin, Sandholm &
Scalability of (near-)equilibrium finding in 2-player 0-sum games…
GS3 [Gilpin, Sandholm &

Leading equilibrium-finding algorithms
for 2-player 0-sum games
Counterfactual regret (CFR)
Based on no-regret
Leading equilibrium-finding algorithms
for 2-player 0-sum games
Counterfactual regret (CFR)
Based on no-regret
![Better first-order methods [Kroer, Waugh, Kılınç-Karzan & Sandholm EC-15] New](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/12865/slide-24.jpg)
Better first-order methods
[Kroer, Waugh, Kılınç-Karzan & Sandholm EC-15]
New prox function for
Better first-order methods
[Kroer, Waugh, Kılınç-Karzan & Sandholm EC-15]
New prox function for

Computing equilibria by leveraging qualitative models
Theorem. Given F1, F2, and a
Computing equilibria by leveraging qualitative models
Theorem. Given F1, F2, and a
![Simultaneous Abstraction and Equilibrium Finding in Games [Brown & Sandholm IJCAI-15 & new manuscript]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/12865/slide-26.jpg)
Simultaneous Abstraction and Equilibrium Finding in Games
[Brown & Sandholm IJCAI-15 &
Simultaneous Abstraction and Equilibrium Finding in Games
[Brown & Sandholm IJCAI-15 &

Problems solved
Cannot solve without abstracting, and cannot principally abstract without solving
SAEF
Problems solved
Cannot solve without abstracting, and cannot principally abstract without solving
SAEF

OPPONENT EXPLOITATION
OPPONENT EXPLOITATION

Traditionally two approaches
Game theory approach (abstraction+equilibrium finding)
Safe in 2-person 0-sum games
Doesn’t
Traditionally two approaches
Game theory approach (abstraction+equilibrium finding)
Safe in 2-person 0-sum games
Doesn’t

Let’s hybridize the two approaches
Start playing based on pre-computed (near-)equilibrium
As we
Let’s hybridize the two approaches
Start playing based on pre-computed (near-)equilibrium
As we

Other modern approaches to
opponent exploitation
ε-safe best response
[Johanson, Zinkevich &
Other modern approaches to
opponent exploitation
ε-safe best response [Johanson, Zinkevich &

Safe opponent exploitation
Definition. Safe strategy achieves at least the value of
Safe opponent exploitation
Definition. Safe strategy achieves at least the value of

Exploitation algorithms
Risk what you’ve won so far
Risk what you’ve won so
Exploitation algorithms
Risk what you’ve won so far
Risk what you’ve won so

STATE OF TOP POKER PROGRAMS
STATE OF TOP POKER PROGRAMS
![Rhode Island Hold’em Bots play optimally [Gilpin & Sandholm EC-06, J. of the ACM 2007]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/12865/slide-35.jpg)
Rhode Island Hold’em
Bots play optimally
[Gilpin & Sandholm EC-06, J. of the
Rhode Island Hold’em
Bots play optimally
[Gilpin & Sandholm EC-06, J. of the

Heads-Up Limit Texas Hold’em
Bots surpassed pros in 2008
[U. Alberta Poker
Heads-Up Limit Texas Hold’em
Bots surpassed pros in 2008 [U. Alberta Poker

Heads-Up No-Limit Texas Hold’em
Annual Computer Poker Competition
--> Claudico
Tartanian7
Statistical significance win against
Heads-Up No-Limit Texas Hold’em
Annual Computer Poker Competition
--> Claudico
Tartanian7
Statistical significance win against

“BRAINS VS AI” EVENT
“BRAINS VS AI” EVENT

Claudico against each of 4 of the top-10 pros in this
Claudico against each of 4 of the top-10 pros in this

Humans’ $100,000 participation fee distributed based on performance
Humans’ $100,000 participation fee distributed based on performance

Overall performance
Pros won by 91 mbb/hand
Not statistically significant (at 95% confidence)
Perspective:
Overall performance
Pros won by 91 mbb/hand
Not statistically significant (at 95% confidence)
Perspective:

Observations about Claudico’s play
Strengths (beyond what pros typically do):
Small bets &
Observations about Claudico’s play
Strengths (beyond what pros typically do):
Small bets &

Multiplayer poker
Bots aren’t very strong (at least not yet)
Exception: programs are
Multiplayer poker
Bots aren’t very strong (at least not yet)
Exception: programs are

Conclusions
Domain-independent techniques
Abstraction
Automated lossless abstraction—exactly solves games with billions of nodes
Best practical
Conclusions
Domain-independent techniques
Abstraction
Automated lossless abstraction—exactly solves games with billions of nodes
Best practical

Current & future research
Lossy abstraction with bounds
Scalable algorithms
With structure
With generated abstract
Current & future research
Lossy abstraction with bounds
Scalable algorithms
With structure
With generated abstract
 Текстовая информация
Текстовая информация использование игр на уроке информатики в начальной школе
использование игр на уроке информатики в начальной школе Spatial Data Structures
Spatial Data Structures Применение ИКТ на уроках музыки
Применение ИКТ на уроках музыки Людина у світі інформації
Людина у світі інформації Организация вычислений в электронных таблицах. Обработка числовой информации в электронных таблицах. Информатика. 9 класс
Организация вычислений в электронных таблицах. Обработка числовой информации в электронных таблицах. Информатика. 9 класс Презентация Решение олимпиадных задач. Игра Баше
Презентация Решение олимпиадных задач. Игра Баше Социальные сети для бизнеса
Социальные сети для бизнеса Testing Throughout the Software Life Cycle: Test Levels. Types of Software Testing (Topic 4)
Testing Throughout the Software Life Cycle: Test Levels. Types of Software Testing (Topic 4) Включение системы. Настройка и контроль системы перед отправлением
Включение системы. Настройка и контроль системы перед отправлением Онлайн-кассы
Онлайн-кассы Шаблоны параллельного проектирования
Шаблоны параллельного проектирования 9 класс Презентации к урокам
9 класс Презентации к урокам Управление данными
Управление данными Инновационный проект
Инновационный проект Основы логики.
Основы логики. Общие и отличительные свойства объектов
Общие и отличительные свойства объектов Основы теории коммуникации
Основы теории коммуникации Киберспорт - это спорт?
Киберспорт - это спорт? HTML программалау тілі
HTML программалау тілі Графический редактор Paint
Графический редактор Paint Объекты JavaScript
Объекты JavaScript Ақпараттық қауіпсіздікті қамтамасыз ету комплексті тәсілі. Ақпараттық қауіпсіздік негізгі ұғымдары
Ақпараттық қауіпсіздікті қамтамасыз ету комплексті тәсілі. Ақпараттық қауіпсіздік негізгі ұғымдары Формализация понятия алгоритма
Формализация понятия алгоритма Культура использования информации. Библиографическое оформление результатов поиска информации
Культура использования информации. Библиографическое оформление результатов поиска информации Solid - принципы с примерами PHP
Solid - принципы с примерами PHP Организация интернет-СМИ
Организация интернет-СМИ Разработка информационного обеспечения для поддержки деятельности предприятия сферы услуг
Разработка информационного обеспечения для поддержки деятельности предприятия сферы услуг