- Разработка параллельных программ для GPU. Обзор CUDA API

Содержание
- 2. ОСОБЕННОСТИ CUDA APIs Виды CUDA APIs и возможности CUDA-устройств
- 3. Виды CUDA APIs CUDA Driver API Ручная инициализация контекста GPU Отсутствуют CUDA-расширения для C++ Код CPU
- 4. Выбор CUDA API CUDA Driver API Больше гибкости ( + ) Сложность кода ( – )
- 5. Совместимость CUDA API Имеется обратная совместимость версий
- 6. Вычислительные возможности GPU Capability – это версия архитектуры CUDA GPU, которая указывает на его вычислительные возможности
- 7. ОЦЕНКА ПРОИЗВОДИТЕЛЬНОСТИ Способы оценки эффективности приложений CUDA
- 8. Время выполнения Общее время вычислений на GPU Время выполнения участка кода GPU
- 9. Таймеры CPU Таймеры CPU позволяют замерять общее время выполнения вычислений на GPU
- 10. Таймеры CUDA Таймеры CUDA позволяют замерять время выполнения участка кода GPU
- 11. Скорость передачи данных Теоретическая пропускная способность FDDRAM * (RDDRAM/8) * sizeof(float), где FDDRAM – частота, RDDRAM
- 12. ОПТИМИЗАЦИЯ РАБОТЫ С ПАМЯТЬЮ Способы оптимизации работы с памятью CUDA GPU
- 13. Архитектура CUDA GPU
- 14. Типы памяти устройства Streaming Multiprocessor Регистровая память Разделяемая память Память констант Texture Processing Cluster Память текстур
- 15. Передача данных Host/Device Является дорогостоящей операцией Возможна асинхронная передача cudaMemcpy() cudaMemcpyAsync()
- 16. Асинхронная передача данных Копирование данных и выполнение ядра можно осуществлять параллельно
- 17. Возможная оптимизация Синхронная передача данных в GPU Асинхронная передача данных в GPU
- 18. Нулевое копирование (Zero Copy) Прямое обращение к памяти Host’а Встроенные видеокарты Использование кэша CPU
- 19. Объединенное чтение DDRAM Выравнивание исходных данных по границе слова Потоки warp’а должны осуществлять одновременное чтение DDRAM
- 20. Разделяемая память и конфликты Общая для всех потоков блока Распределяется между блоками Разбивается на банки (32-битные
- 21. Регистровое давление Регистры жестко распределяются между потоками мультипроцессора При большом количестве потоков возникает конфликт доступа к
- 22. ВЫБОР ОПТИМАЛЬНОЙ ТОПОЛОГИИ Методы оценки топологии вычислений CUDA
- 23. Степень покрытия Степень покрытия мультипроцессора – это отношение числа активных warp'ов к максимально возможному числу активных
- 24. Определение степени покрытия CUDA GPU: 8192 регистра 768 потоков на мультипроцессор Топология: 12 регистров на ядро
- 25. ОПТИМИЗАЦИЯ КОДА Оптимизация инструкций CUDA
- 26. Регистровая зависимость Инструкция использует регистр, значение которого было получено при выполнении предыдущей инструкции register = instruction1();
- 27. Float vs Double Арифметические операции с float-числами осуществляются быстрей, чем с double-числами Рекомендуется использовать суффикс «f»
- 28. Деление чисел При делении чисел на степень двойки рекомендуется использовать оператор сдвига X / N →
- 29. Степень числа Для известных целых значений степеней рекомендуется использовать явное умножение вместо вызова pow() pow(X, 2)
- 30. Часто используемые функции Обратный квадратный корень rsqrtf() / rsqrt() Прочие арифметические операции expf2() / exp2() –
- 31. Точность vs Скорость Аппаратные аналоги функций __sinf() / sinf() __cosf() / cosf() __expf() / expf() Совмещенные
- 32. УПРАВЛЕНИЕ ПОТОКОМ КОМАНД Общие рекомендации по написанию кода
- 33. Операторы ветвления Инструкции управления потоком команд (if, switch, for, while, do-while) отрицательно сказываются на производительности В
- 34. Предикативная запись
- 35. ОТЛАДКА И ПРОФИЛИРОВАНИЕ Отладка и профилирование приложений CUDA
- 36. Существующие утилиты Linux CUDA-GDB http://developer.nvidia.com/cuda-gdb Windows Vista & Windows 7 NVIDIA Parallel Nsight http://developer.nvidia.com/nvidia-parallel-nsight
- 37. АППАРАТНЫЕ ОСОБЕННОСТИ GPU Краткий обзор архитектурных особенностей GPU
- 38. Причины рассогласования Основные причины рассогласования результатов вычислений на GPU и CPU Усечение double чисел до float
- 39. Литература NVIDIA Developer Zone http://developer.nvidia.com/cuda NVIDIA Parallel Nsight http://developer.nvidia.com/cuda-gdb CUDA C Best Practices Guide http://developer.download.nvidia.com/compute/cuda/4_0/toolkit/docs/CUDA_C_Best_Practices_Guide.pdf
- 41. Скачать презентацию

ОСОБЕННОСТИ CUDA APIs
Виды CUDA APIs и возможности CUDA-устройств
ОСОБЕННОСТИ CUDA APIs
Виды CUDA APIs и возможности CUDA-устройств

Виды CUDA APIs
CUDA Driver API
Ручная инициализация контекста GPU
Отсутствуют CUDA-расширения для C++
Код
Виды CUDA APIs
CUDA Driver API
Ручная инициализация контекста GPU
Отсутствуют CUDA-расширения для C++
Код

Выбор CUDA API
CUDA Driver API
Больше гибкости ( + )
Сложность кода (
Выбор CUDA API
CUDA Driver API
Больше гибкости ( + )
Сложность кода (
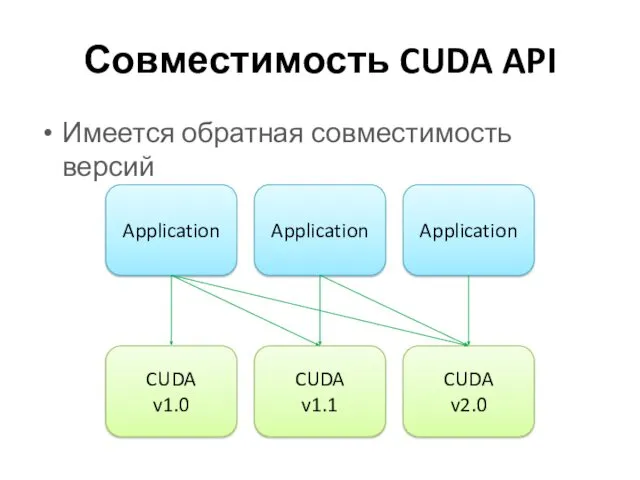
Совместимость CUDA API
Имеется обратная совместимость версий
Совместимость CUDA API
Имеется обратная совместимость версий

Вычислительные возможности GPU
Capability – это версия архитектуры CUDA GPU, которая указывает
Вычислительные возможности GPU
Capability – это версия архитектуры CUDA GPU, которая указывает

ОЦЕНКА ПРОИЗВОДИТЕЛЬНОСТИ
Способы оценки эффективности приложений CUDA
ОЦЕНКА ПРОИЗВОДИТЕЛЬНОСТИ
Способы оценки эффективности приложений CUDA

Время выполнения
Общее время вычислений на GPU
Время выполнения участка кода GPU
Время выполнения
Общее время вычислений на GPU
Время выполнения участка кода GPU

Таймеры CPU
Таймеры CPU позволяют замерять общее время выполнения вычислений на GPU
Таймеры CPU
Таймеры CPU позволяют замерять общее время выполнения вычислений на GPU

Таймеры CUDA
Таймеры CUDA позволяют замерять время выполнения участка кода GPU
Таймеры CUDA
Таймеры CUDA позволяют замерять время выполнения участка кода GPU

Скорость передачи данных
Теоретическая пропускная способность
FDDRAM * (RDDRAM/8) * sizeof(float),
где FDDRAM –
Скорость передачи данных
Теоретическая пропускная способность
FDDRAM * (RDDRAM/8) * sizeof(float),
где FDDRAM –

ОПТИМИЗАЦИЯ РАБОТЫ С ПАМЯТЬЮ
Способы оптимизации работы с памятью CUDA GPU
ОПТИМИЗАЦИЯ РАБОТЫ С ПАМЯТЬЮ
Способы оптимизации работы с памятью CUDA GPU
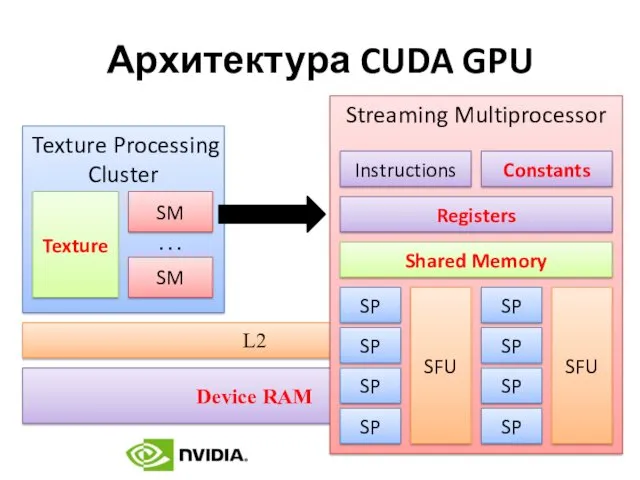
Архитектура CUDA GPU
Архитектура CUDA GPU

Типы памяти устройства
Streaming Multiprocessor
Регистровая память
Разделяемая память
Память констант
Texture Processing Cluster
Память текстур
DDRAM
Локальная память
Глобальная
Типы памяти устройства
Streaming Multiprocessor
Регистровая память
Разделяемая память
Память констант
Texture Processing Cluster
Память текстур
DDRAM
Локальная память
Глобальная

Передача данных Host/Device
Является дорогостоящей операцией
Возможна асинхронная передача
cudaMemcpy()
cudaMemcpyAsync()
Передача данных Host/Device
Является дорогостоящей операцией
Возможна асинхронная передача
cudaMemcpy()
cudaMemcpyAsync()

Асинхронная передача данных
Копирование данных и выполнение ядра можно осуществлять параллельно
Асинхронная передача данных
Копирование данных и выполнение ядра можно осуществлять параллельно

Возможная оптимизация
Синхронная передача данных в GPU
Асинхронная передача данных в GPU
Возможная оптимизация
Синхронная передача данных в GPU
Асинхронная передача данных в GPU

Нулевое копирование (Zero Copy)
Прямое обращение к памяти Host’а
Встроенные видеокарты
Использование кэша CPU
Нулевое копирование (Zero Copy)
Прямое обращение к памяти Host’а
Встроенные видеокарты
Использование кэша CPU

Объединенное чтение DDRAM
Выравнивание исходных данных по границе слова
Потоки warp’а должны осуществлять
Объединенное чтение DDRAM
Выравнивание исходных данных по границе слова
Потоки warp’а должны осуществлять

Разделяемая память и конфликты
Общая для всех потоков блока
Распределяется между блоками
Разбивается на
Разделяемая память и конфликты
Общая для всех потоков блока
Распределяется между блоками
Разбивается на

Регистровое давление
Регистры жестко распределяются между потоками мультипроцессора
При большом количестве потоков возникает
Регистровое давление
Регистры жестко распределяются между потоками мультипроцессора
При большом количестве потоков возникает

ВЫБОР ОПТИМАЛЬНОЙ ТОПОЛОГИИ
Методы оценки топологии вычислений CUDA
ВЫБОР ОПТИМАЛЬНОЙ ТОПОЛОГИИ
Методы оценки топологии вычислений CUDA

Степень покрытия
Степень покрытия мультипроцессора – это отношение числа активных warp'ов к
Степень покрытия
Степень покрытия мультипроцессора – это отношение числа активных warp'ов к

Определение степени покрытия
CUDA GPU:
8192 регистра
768 потоков на мультипроцессор
Топология:
12 регистров на ядро
128
Определение степени покрытия
CUDA GPU:
8192 регистра
768 потоков на мультипроцессор
Топология:
12 регистров на ядро
128

ОПТИМИЗАЦИЯ КОДА
Оптимизация инструкций CUDA
ОПТИМИЗАЦИЯ КОДА
Оптимизация инструкций CUDA

Регистровая зависимость
Инструкция использует регистр, значение которого было получено при выполнении предыдущей
Регистровая зависимость
Инструкция использует регистр, значение которого было получено при выполнении предыдущей

Float vs Double
Арифметические операции с float-числами осуществляются быстрей, чем с double-числами
Рекомендуется
Float vs Double
Арифметические операции с float-числами осуществляются быстрей, чем с double-числами
Рекомендуется

Деление чисел
При делении чисел на степень двойки рекомендуется использовать оператор сдвига
X
Деление чисел
При делении чисел на степень двойки рекомендуется использовать оператор сдвига
X

Степень числа
Для известных целых значений степеней рекомендуется использовать явное умножение вместо
Степень числа
Для известных целых значений степеней рекомендуется использовать явное умножение вместо

Часто используемые функции
Обратный квадратный корень
rsqrtf() / rsqrt()
Прочие арифметические операции
expf2() / exp2() –
Часто используемые функции
Обратный квадратный корень
rsqrtf() / rsqrt()
Прочие арифметические операции
expf2() / exp2() –

Точность vs Скорость
Аппаратные аналоги функций
__sinf() / sinf()
__cosf() / cosf()
__expf() / expf()
Совмещенные
Точность vs Скорость
Аппаратные аналоги функций
__sinf() / sinf()
__cosf() / cosf()
__expf() / expf()
Совмещенные

УПРАВЛЕНИЕ ПОТОКОМ КОМАНД
Общие рекомендации по написанию кода
УПРАВЛЕНИЕ ПОТОКОМ КОМАНД
Общие рекомендации по написанию кода

Операторы ветвления
Инструкции управления потоком команд (if, switch, for, while, do-while) отрицательно
Операторы ветвления
Инструкции управления потоком команд (if, switch, for, while, do-while) отрицательно

Предикативная запись
Предикативная запись

ОТЛАДКА И ПРОФИЛИРОВАНИЕ
Отладка и профилирование приложений CUDA
ОТЛАДКА И ПРОФИЛИРОВАНИЕ
Отладка и профилирование приложений CUDA
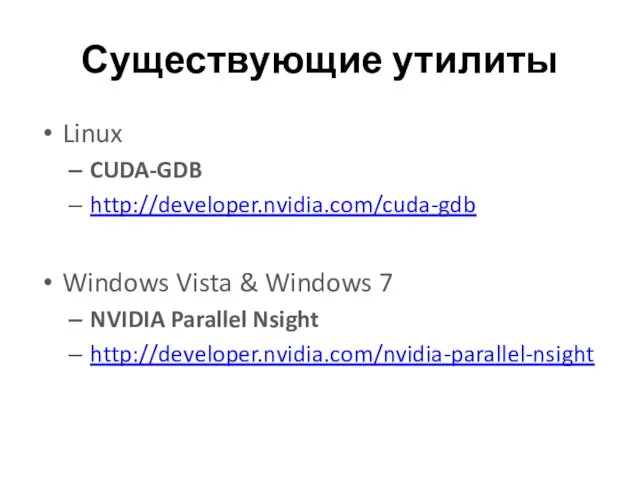
Существующие утилиты
Linux
CUDA-GDB
http://developer.nvidia.com/cuda-gdb
Windows Vista & Windows 7
NVIDIA Parallel Nsight
http://developer.nvidia.com/nvidia-parallel-nsight
Существующие утилиты
Linux
CUDA-GDB
http://developer.nvidia.com/cuda-gdb
Windows Vista & Windows 7
NVIDIA Parallel Nsight
http://developer.nvidia.com/nvidia-parallel-nsight

АППАРАТНЫЕ ОСОБЕННОСТИ GPU
Краткий обзор архитектурных особенностей GPU
АППАРАТНЫЕ ОСОБЕННОСТИ GPU
Краткий обзор архитектурных особенностей GPU

Причины рассогласования
Основные причины рассогласования результатов вычислений на GPU и CPU
Усечение double
Причины рассогласования
Основные причины рассогласования результатов вычислений на GPU и CPU
Усечение double

Литература
NVIDIA Developer Zone
http://developer.nvidia.com/cuda
NVIDIA Parallel Nsight
http://developer.nvidia.com/cuda-gdb
CUDA C Best Practices Guide
http://developer.download.nvidia.com/compute/cuda/4_0/toolkit/docs/CUDA_C_Best_Practices_Guide.pdf
Литература
NVIDIA Developer Zone
http://developer.nvidia.com/cuda
NVIDIA Parallel Nsight
http://developer.nvidia.com/cuda-gdb
CUDA C Best Practices Guide
http://developer.download.nvidia.com/compute/cuda/4_0/toolkit/docs/CUDA_C_Best_Practices_Guide.pdf
 Проблемы информационной безопасности. Лекция №8
Проблемы информационной безопасности. Лекция №8 Помощник проектировщика
Помощник проектировщика Программы, которые используются в строительстве: AutoCAD, ArchiCAD, Revit, SketchUp, Blender
Программы, которые используются в строительстве: AutoCAD, ArchiCAD, Revit, SketchUp, Blender Основы работы в сети интернет
Основы работы в сети интернет Теоретический лицей. Образец сайта
Теоретический лицей. Образец сайта Основы логики
Основы логики Составление наборов тестовых данных для структурного тестирования. Стратегия белого ящика
Составление наборов тестовых данных для структурного тестирования. Стратегия белого ящика Информация. Измерение количества информации
Информация. Измерение количества информации Компьютерная графика (Autodesk 3ds max). Модификаторы. (Лекция 3.2)
Компьютерная графика (Autodesk 3ds max). Модификаторы. (Лекция 3.2) Программирование на языке C++
Программирование на языке C++ Различные системы счисления
Различные системы счисления Мультимедиа в журналистике. А нужно ли? И как?
Мультимедиа в журналистике. А нужно ли? И как? Краткие сведения о препроцессоре Си
Краткие сведения о препроцессоре Си Інформатизація процесів методичної діяльності кафедри
Інформатизація процесів методичної діяльності кафедри Основы научных исследований. Поиск научных статей и монографий в базе данных IEEE Xplore. Тема 5
Основы научных исследований. Поиск научных статей и монографий в базе данных IEEE Xplore. Тема 5 Презентация Профессии, по которым необходимы знания по программе Microsoft Access
Презентация Профессии, по которым необходимы знания по программе Microsoft Access Знакомство со средой Scratch
Знакомство со средой Scratch Создание документов в текстовых редакторах. 10 класс
Создание документов в текстовых редакторах. 10 класс Образовательные информационные ресурсы
Образовательные информационные ресурсы Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Uso práctico de la aplicación La Rueda De La Vida
Uso práctico de la aplicación La Rueda De La Vida Концепции MRP, MRP II, ERP
Концепции MRP, MRP II, ERP Международная школа программирования для детей Unity 2D
Международная школа программирования для детей Unity 2D Кодирование звуковой информации
Кодирование звуковой информации Ғаламдық есептеуші жүйелер. Модем. Факс-модем
Ғаламдық есептеуші жүйелер. Модем. Факс-модем Разработка консольного приложения с элементами ООП. Интернет магазин продуктов
Разработка консольного приложения с элементами ООП. Интернет магазин продуктов World Wide Web. История создания и современность
World Wide Web. История создания и современность Компьютерные сети
Компьютерные сети