- Символы и строки в Си. Работа с текстовыми файлами

Содержание
- 2. Тип char char – это «очень короткий» целый тип #include void main() { char ch =
- 3. Тип char (2) char – это символьный тип #include void main() { char ch = 32;
- 4. Тип char (3) unsigned char = [0 .. 255] #include void main() { unsigned char ch
- 5. Тип char (4) signed char = [-128 .. +127] #include void main() { signed char ch
- 6. Тип char (5) Загадка: Тип char == signed char ИЛИ Тип char == unsigned char ?
- 7. Тип char (6) http://stackoverflow.com/questions/2054939/is-char-signed-or-unsigned-by-default The standard does not specify if plain char is signed or unsigned…
- 8. ASCII https://ru.wikipedia.org/wiki/ASCII ASCII (англ. American standard code for information interchange) — название таблицы (кодировки, набора), в
- 9. ASCIIZ http://stackoverflow.com/questions/7783044/whats-the-difference-between-asciiz-vs-ascii In computing, a C string is a character sequence terminated with a null character
- 10. null-terminated string void main() { char s1[8] = "Hi!\n"; int i; for (i = 0; i
- 11. Инициализация строки как массива символов void main() { char s1[8] = { 'H', 'i', '!', '\n',
- 12. Инициализация строки как строки void main() { char s2[] = "%c(%d), "; int i; for (i
- 13. Простейшие алгоритмы обработки строк (как массива символов с ‘\0’ в конце) Все цифры заменить на символ
- 14. Используем функции из ctype.h Все цифры заменить на символ «#» #include #include void main() { char
- 15. Используем функции из ctype.h Все ????? заменить на символ «#» void main() { char s3[] =
- 16. Используем функции из ctype.h Все ????? заменить на символ «#» void main() { char s3[] =
- 17. Используем функции из ctype.h Все ????? заменить на символ «#» void main() { char s3[] =
- 18. Используем функции из ctype.h Все ????? заменить на символ «#» void main() { char s3[] =
- 19. Используем функции из ctype.h Все ????? заменить на ?????? void main() { char s3[] = "I
- 20. Используем функции из ctype.h Все ????? заменить на ?????? void main() { char s3[] = "I
- 21. Стандартные функции обработки строк strlen(s) - Возвращает длину строки без завершающей литеры '\0'. strcmp(s1, s2) –
- 22. strlen() #include void main() { char s[10] = "Hi!"; printf("len = %d\n", strlen(s)); s[3] = '
- 23. strlen() #include void main() { char s[10] = "Hi!"; printf("len = %d\n", strlen(s)); s[3] = '
- 24. Сравнение строк – НЕ ДЕЛАЙТЕ ТАК НИКОГДА!!! void main() { char s1[] = "Button"; char s2[]
- 25. Сравнение строк через strcmp int strcmp(const char *str1, const char *str2); int strcmp(char str1[], char str2[]);
- 26. Сравнение строк через strcmp void main() { char s1[] = "Button"; char s2[] = "We"; char
- 27. Копирование строк void main() { char src[] = "Button"; char dest[10]; printf("src = %s, dest =
- 28. Конкатенация строк void main() { char src[] = "Button"; char dest[10] = " "; printf("src =
- 29. Еще раз - int strlen(char s[]) int strlen(char s[]) { int len; … return len; }
- 30. Собственная реализация strlen int strlen_my(char s[]) { int len; … return len; } Нужно написать код
- 31. Собственная реализация strlen int strlen_my(char s[]) { int len = 0; while (s[len] != '\0‘) len++;
- 32. int strcmp(char s1[], char s2[]) int strcmp(const char *str1, const char *str2); Функция strcmp() сравнивает в
- 33. Собственная реализация strcmp /* s1 s1 == s2 : 0 s1 > s2 : >0 */
- 34. Собственная реализация strcmp /* s1 s1 == s2 : 0 s1 > s2 : >0 */
- 35. Трассировка strcmp /* s1 s1 == s2 : 0 s1 > s2 : >0 */ int
- 36. [Домашнее] задание Написать собственную версию strcpy_my(dest, src) Написать собственную версию strcat(dest, src)
- 37. Текстовый файл Текстовый файл содержит последовательность символов (в основном печатных знаков, принадлежащих тому или иному набору
- 38. Перевод строки Перевод строки, или разрыв строки — продолжение печати текста с новой строки, то есть
- 39. Перевод строки – в разных ОС (“\n”) LF (ASCII 0x0A) используется в Multics, UNIX, UNIX-подобных операционных
- 40. Чтение из текстового файла - feof Проверяет поток на достижение конца файла. int feof( FILE *stream
- 41. Чтение из текстового файла - fgets Считывание строки из потока. char *fgets( char *str, int n,
- 42. Чтение из текстового файла построчно char filename[] = "d:\\temp\\text_in.txt"; FILE * fin; char s[MAX_LEN]; fin =
- 43. Задача шифрования текста На входе текстовый файл in.txt (содержащий слова, разделители и знаки препинания). Необходимо сохранив
- 44. Шифрование одной строки #define MAX_LEN 80 #define KEY +3 #define KEY2 -3 void convert(char * str)
- 45. Шифрование одного символа int encode(int ch, int key) { //char smallLetters[] ="abcdefghijklmnopqrstuvwxyz"; //char bigLetters[] ="ABCDEGGHIJKLMNOPQRSTUVWXYZ"; int
- 46. Многомодульные проекты
- 47. Структура многомодульного проекта
- 48. Main.c
- 49. Main.c #define _CRT_SECURE_NO_WARNINGS #include #include #include "Caesar.h" #define MAX_LEN 80 void main() { … fin =
- 50. Caesar.h
- 51. Caesar.h #pragma once #define KEY +3 #define KEY2 -3 void convert(char * str); //int encode(int ch,
- 52. Caesar.c
- 53. Caesar.c #include "Caesar.h" int encode(int ch, int key) { //char smallLetters[] ="abcdefghijklmnopqrstuvwxyz"; //char bigLetters[] ="ABCDEGGHIJKLMNOPQRSTUVWXYZ"; int
- 54. Caesar.c void convert(char * str) { int i; for (i = 0; str[i] != '\0'; i++)
- 55. Работа со словами (файлы)
- 56. Задача выделения слов На входе текстовый файл, содержащий большой текст (книга) на английском языке. Нужно создать
- 57. Чтение посимвольно - getc Считывает символ из потока. int getc( FILE *stream ); Параметры stream Входной
- 58. Код программы #define _CRT_SECURE_NO_WARNINGS #include #include #include void main() { printf("Start\n"); FILE *fin = fopen("D:\\temp\\Files\\Lec12\\alice.txt", "rt");
- 59. Код программы (2) while ((ch = getc(fin)) != EOF) { if (isalpha((unsigned char)ch)) { if (!is_letter)
- 60. Код программы (3) else { // if (!isalpha(ch)) { if (is_letter) { word[word_len] = '\0'; if
- 61. Код программы (4) fclose(fin); fclose(fout); printf("Done!\n"); { int x; scanf("%d", &x); } }
- 62. Граф состояний
- 63. Итог работы программы
- 64. Работа с русским языком
- 65. Задача 1 - создать файл в русской кодировке #include #include void main() { SetConsoleCP(1251); SetConsoleOutputCP(1251); char
- 67. Скачать презентацию
Тип char
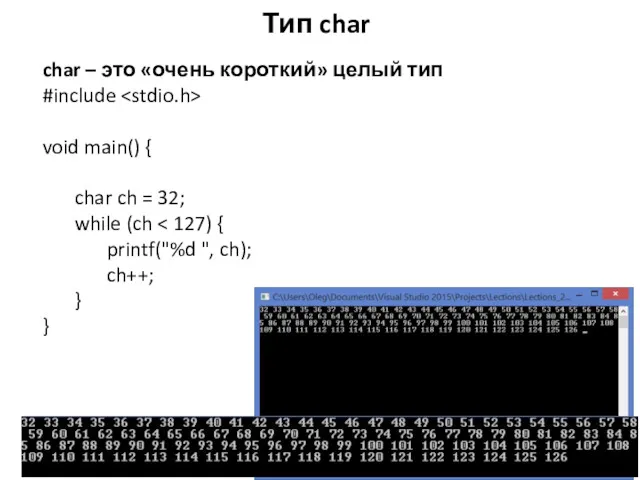
char – это «очень короткий» целый тип
#include
void main() {
char
Тип char
char – это «очень короткий» целый тип
#include
void main() {
char
Тип char (2)
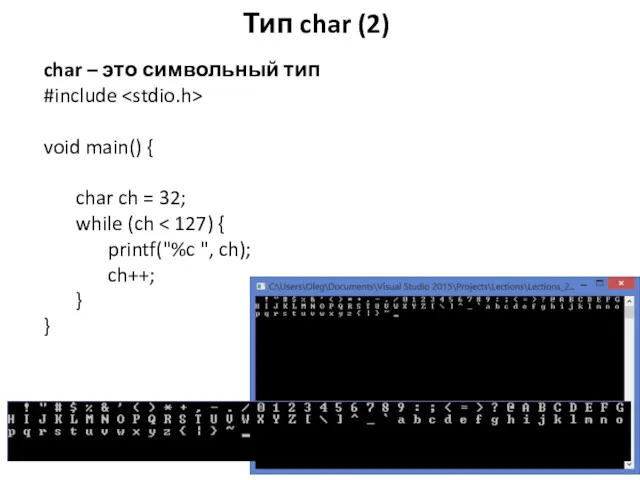
char – это символьный тип
#include
void main() {
char ch
Тип char (2)
char – это символьный тип
#include
void main() {
char ch
![Тип char (3) unsigned char = [0 .. 255] #include](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-3.jpg)
Тип char (3)
unsigned char = [0 .. 255]
#include
void main() {
unsigned
Тип char (3)
unsigned char = [0 .. 255]
#include
void main() {
unsigned
![Тип char (4) signed char = [-128 .. +127] #include](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-4.jpg)
Тип char (4)
signed char = [-128 .. +127]
#include
void main() {
signed
Тип char (4)
signed char = [-128 .. +127]
#include
void main() {
signed
Тип char (5)
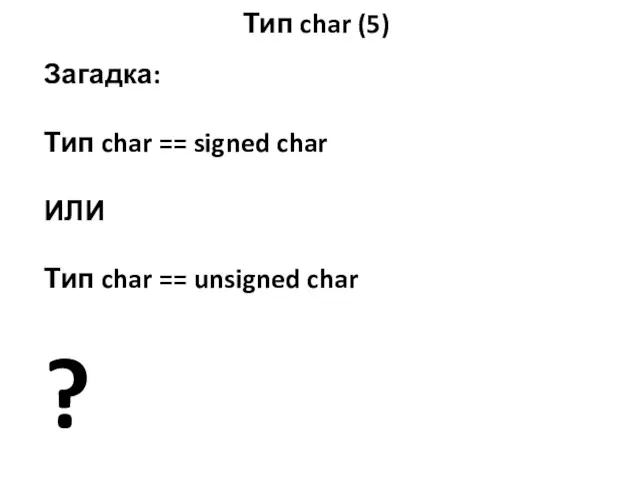
Загадка:
Тип char == signed char
ИЛИ
Тип char == unsigned
Тип char (5)
Загадка:
Тип char == signed char
ИЛИ
Тип char == unsigned

Тип char (6)
http://stackoverflow.com/questions/2054939/is-char-signed-or-unsigned-by-default
The standard does not specify if plain char is
Тип char (6)
http://stackoverflow.com/questions/2054939/is-char-signed-or-unsigned-by-default
The standard does not specify if plain char is

ASCII
https://ru.wikipedia.org/wiki/ASCII
ASCII (англ. American standard code for information interchange) — название таблицы (кодировки, набора),
ASCII
https://ru.wikipedia.org/wiki/ASCII
ASCII (англ. American standard code for information interchange) — название таблицы (кодировки, набора),

ASCIIZ
http://stackoverflow.com/questions/7783044/whats-the-difference-between-asciiz-vs-ascii
In computing, a C string is a character sequence terminated
ASCIIZ
http://stackoverflow.com/questions/7783044/whats-the-difference-between-asciiz-vs-ascii
In computing, a C string is a character sequence terminated
![null-terminated string void main() { char s1[8] = "Hi!\n"; int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-9.jpg)
null-terminated string
void main() {
char s1[8] = "Hi!\n";
int i;
for (i =
null-terminated string
void main() {
char s1[8] = "Hi!\n";
int i;
for (i =
![Инициализация строки как массива символов void main() { char s1[8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-10.jpg)
Инициализация строки как массива символов
void main() {
char s1[8] = { 'H',
Инициализация строки как массива символов
void main() {
char s1[8] = { 'H',
![Инициализация строки как строки void main() { char s2[] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-11.jpg)
Инициализация строки как строки
void main() {
char s2[] = "%c(%d), ";
int i;
for
Инициализация строки как строки
void main() {
char s2[] = "%c(%d), ";
int i;
for

Простейшие алгоритмы обработки строк
(как массива символов с ‘\0’ в конце)
Все
Простейшие алгоритмы обработки строк
(как массива символов с ‘\0’ в конце)
Все

Используем функции из ctype.h
Все цифры заменить на символ «#»
#include
#include
void
Используем функции из ctype.h
Все цифры заменить на символ «#»
#include
#include
void

Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char
Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char

Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char
Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char

Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char
Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char

Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char
Используем функции из ctype.h
Все ????? заменить на символ «#»
void main() {
char

Используем функции из ctype.h
Все ????? заменить на ??????
void main() {
char s3[]
Используем функции из ctype.h
Все ????? заменить на ??????
void main() {
char s3[]

Используем функции из ctype.h
Все ????? заменить на ??????
void main() {
char s3[]
Используем функции из ctype.h
Все ????? заменить на ??????
void main() {
char s3[]

Стандартные функции обработки строк
strlen(s) - Возвращает длину строки без завершающей литеры
Стандартные функции обработки строк
strlen(s) - Возвращает длину строки без завершающей литеры
![strlen() #include void main() { char s[10] = "Hi!"; printf("len](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-21.jpg)
strlen()
#include
void main() {
char s[10] = "Hi!";
printf("len = %d\n", strlen(s));
s[3] =
strlen()
#include
void main() {
char s[10] = "Hi!";
printf("len = %d\n", strlen(s));
s[3] =
![strlen() #include void main() { char s[10] = "Hi!"; printf("len](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-22.jpg)
strlen()
#include
void main() {
char s[10] = "Hi!";
printf("len = %d\n", strlen(s));
s[3] =
strlen()
#include
void main() {
char s[10] = "Hi!";
printf("len = %d\n", strlen(s));
s[3] =

Сравнение строк – НЕ ДЕЛАЙТЕ ТАК НИКОГДА!!!
void main() {
char s1[] =
Сравнение строк – НЕ ДЕЛАЙТЕ ТАК НИКОГДА!!!
void main() {
char s1[] =

Сравнение строк через strcmp
int strcmp(const char *str1, const char *str2);
int strcmp(char
Сравнение строк через strcmp
int strcmp(const char *str1, const char *str2);
int strcmp(char
![Сравнение строк через strcmp void main() { char s1[] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-25.jpg)
Сравнение строк через strcmp
void main() {
char s1[] = "Button";
char s2[] =
Сравнение строк через strcmp
void main() {
char s1[] = "Button";
char s2[] =
![Копирование строк void main() { char src[] = "Button"; char](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-26.jpg)
Копирование строк
void main() {
char src[] = "Button";
char dest[10];
printf("src = %s, dest
Копирование строк
void main() {
char src[] = "Button";
char dest[10];
printf("src = %s, dest
![Конкатенация строк void main() { char src[] = "Button"; char](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-27.jpg)
Конкатенация строк
void main() {
char src[] = "Button";
char dest[10] = "<>";
printf("src =
Конкатенация строк
void main() {
char src[] = "Button";
char dest[10] = "<>";
printf("src =
![Еще раз - int strlen(char s[]) int strlen(char s[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-28.jpg)
Еще раз - int strlen(char s[])
int strlen(char s[]) {
int len;
…
return len;
}
Возвращает
Еще раз - int strlen(char s[])
int strlen(char s[]) {
int len;
…
return len;
}
Возвращает
![Собственная реализация strlen int strlen_my(char s[]) { int len; …](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-29.jpg)
Собственная реализация strlen
int strlen_my(char s[]) {
int len;
…
return len;
}
Нужно написать код функции
Собственная реализация strlen
int strlen_my(char s[]) {
int len;
…
return len;
}
Нужно написать код функции
![Собственная реализация strlen int strlen_my(char s[]) { int len =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-30.jpg)
Собственная реализация strlen
int strlen_my(char s[])
{
int len = 0;
while (s[len] != '\0‘)
len++;
return
Собственная реализация strlen
int strlen_my(char s[])
{
int len = 0;
while (s[len] != '\0‘)
len++;
return
![int strcmp(char s1[], char s2[]) int strcmp(const char *str1, const](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-31.jpg)
int strcmp(char s1[], char s2[])
int strcmp(const char *str1, const char *str2);
Функция
int strcmp(char s1[], char s2[])
int strcmp(const char *str1, const char *str2);
Функция

Собственная реализация strcmp
/*
s1 < s2 : <0
s1 == s2 : 0
s1
Собственная реализация strcmp
/*
s1 < s2 : <0
s1 == s2 : 0
s1

Собственная реализация strcmp
/*
s1 < s2 : <0
s1 == s2 : 0
s1
Собственная реализация strcmp
/*
s1 < s2 : <0
s1 == s2 : 0
s1

Трассировка strcmp
/*
s1 < s2 : <0
s1 == s2 : 0
s1 >
Трассировка strcmp
/*
s1 < s2 : <0
s1 == s2 : 0
s1 >
![[Домашнее] задание Написать собственную версию strcpy_my(dest, src) Написать собственную версию strcat(dest, src)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-35.jpg)
[Домашнее] задание
Написать собственную версию strcpy_my(dest, src)
Написать собственную версию
strcat(dest,
[Домашнее] задание
Написать собственную версию strcpy_my(dest, src)
Написать собственную версию
strcat(dest,

Текстовый файл
Текстовый файл содержит последовательность символов (в основном печатных знаков, принадлежащих
Текстовый файл
Текстовый файл содержит последовательность символов (в основном печатных знаков, принадлежащих

Перевод строки
Перевод строки, или разрыв строки — продолжение печати текста с новой
Перевод строки
Перевод строки, или разрыв строки — продолжение печати текста с новой

Перевод строки – в разных ОС
(“\n”) LF (ASCII 0x0A) используется в Multics,
Перевод строки – в разных ОС
(“\n”) LF (ASCII 0x0A) используется в Multics,

Чтение из текстового файла - feof
Проверяет поток на достижение конца файла.
Чтение из текстового файла - feof
Проверяет поток на достижение конца файла.

Чтение из текстового файла - fgets
Считывание строки из потока.
char *fgets(
Чтение из текстового файла - fgets
Считывание строки из потока.
char *fgets(
![Чтение из текстового файла построчно char filename[] = "d:\\temp\\text_in.txt"; FILE](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/122030/slide-41.jpg)
Чтение из текстового файла построчно
char filename[] = "d:\\temp\\text_in.txt";
FILE * fin;
char s[MAX_LEN];
fin
Чтение из текстового файла построчно
char filename[] = "d:\\temp\\text_in.txt";
FILE * fin;
char s[MAX_LEN];
fin

Задача шифрования текста
На входе текстовый файл in.txt (содержащий слова, разделители и
Задача шифрования текста
На входе текстовый файл in.txt (содержащий слова, разделители и

Шифрование одной строки
#define MAX_LEN 80
#define KEY +3
#define KEY2 -3
void convert(char *
Шифрование одной строки
#define MAX_LEN 80
#define KEY +3
#define KEY2 -3
void convert(char *

Шифрование одного символа
int encode(int ch, int key) {
//char smallLetters[] ="abcdefghijklmnopqrstuvwxyz";
//char bigLetters[]
Шифрование одного символа
int encode(int ch, int key) {
//char smallLetters[] ="abcdefghijklmnopqrstuvwxyz";
//char bigLetters[]

Многомодульные проекты
Многомодульные проекты
Структура многомодульного проекта
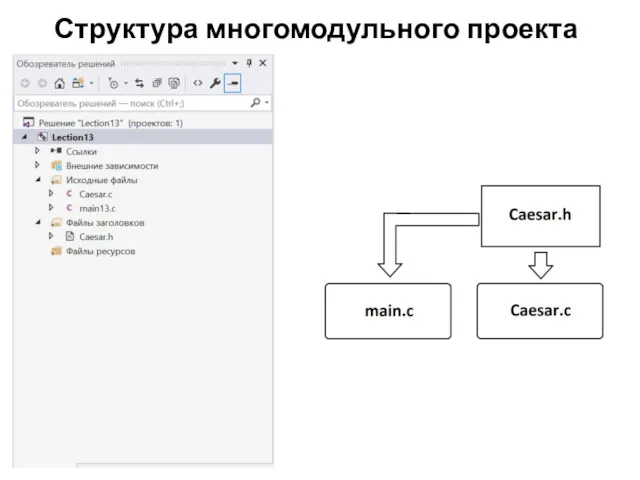
Структура многомодульного проекта
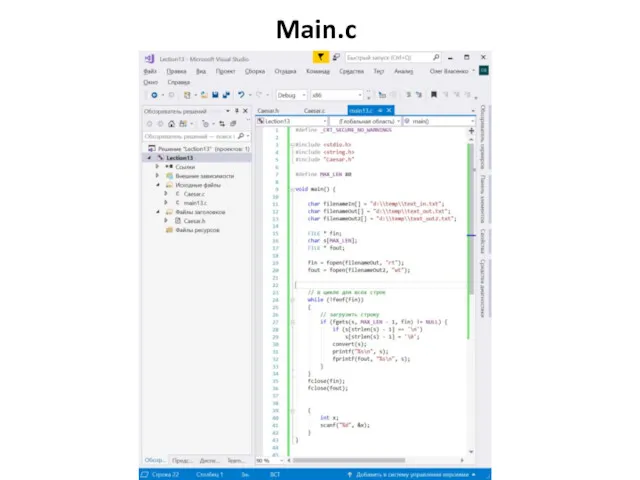
Main.c
Main.c

Main.c
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include "Caesar.h"
#define MAX_LEN 80
void main() {
…
fin = fopen(filenameOut,
Main.c
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include "Caesar.h"
#define MAX_LEN 80
void main() {
…
fin = fopen(filenameOut,
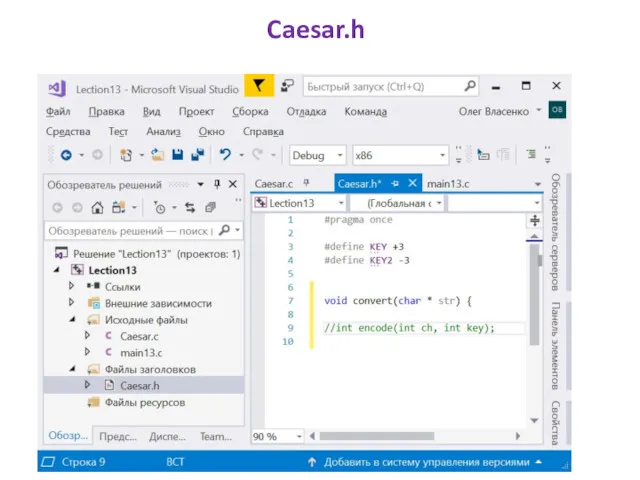
Caesar.h
Caesar.h

Caesar.h
#pragma once
#define KEY +3
#define KEY2 -3
void convert(char * str);
//int encode(int ch,
Caesar.h
#pragma once
#define KEY +3
#define KEY2 -3
void convert(char * str);
//int encode(int ch,
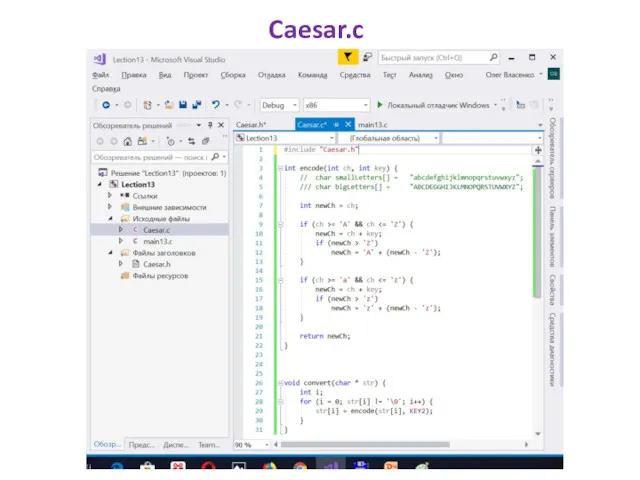
Caesar.c
Caesar.c

Caesar.c
#include "Caesar.h"
int encode(int ch, int key) {
//char smallLetters[] ="abcdefghijklmnopqrstuvwxyz";
//char bigLetters[] ="ABCDEGGHIJKLMNOPQRSTUVWXYZ";
int
Caesar.c
#include "Caesar.h"
int encode(int ch, int key) {
//char smallLetters[] ="abcdefghijklmnopqrstuvwxyz";
//char bigLetters[] ="ABCDEGGHIJKLMNOPQRSTUVWXYZ";
int

Caesar.c
void convert(char * str) {
int i;
for (i = 0; str[i] !=
Caesar.c
void convert(char * str) {
int i;
for (i = 0; str[i] !=

Работа со словами (файлы)
Работа со словами (файлы)

Задача выделения слов
На входе текстовый файл, содержащий большой текст (книга) на
Задача выделения слов
На входе текстовый файл, содержащий большой текст (книга) на

Чтение посимвольно - getc
Считывает символ из потока.
int getc( FILE *stream
Чтение посимвольно - getc
Считывает символ из потока.
int getc( FILE *stream

Код программы
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include
void main() {
printf("Start\n");
FILE *fin = fopen("D:\\temp\\Files\\Lec12\\alice.txt",
Код программы
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include
void main() {
printf("Start\n");
FILE *fin = fopen("D:\\temp\\Files\\Lec12\\alice.txt",

Код программы (2)
while ((ch = getc(fin)) != EOF)
{
if (isalpha((unsigned char)ch)) {
if
Код программы (2)
while ((ch = getc(fin)) != EOF)
{
if (isalpha((unsigned char)ch)) {
if

Код программы (3)
else { // if (!isalpha(ch)) {
if (is_letter) {
word[word_len] =
Код программы (3)
else { // if (!isalpha(ch)) {
if (is_letter) {
word[word_len] =

Код программы (4)
fclose(fin);
fclose(fout);
printf("Done!\n");
{
int x;
scanf("%d", &x);
}
}
Код программы (4)
fclose(fin);
fclose(fout);
printf("Done!\n");
{
int x;
scanf("%d", &x);
}
}

Граф состояний
Граф состояний
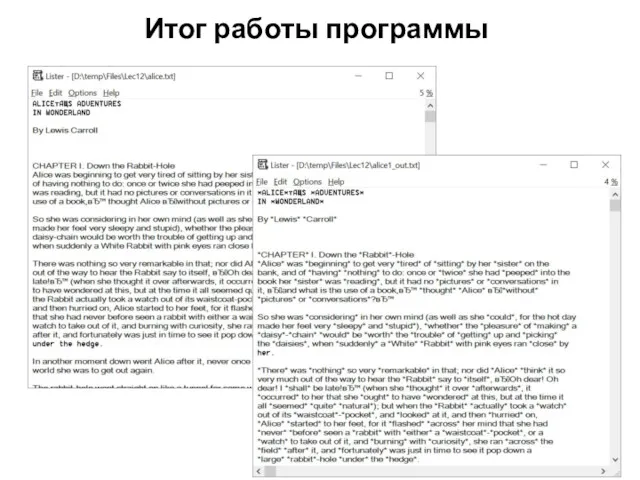
Итог работы программы
Итог работы программы

Работа с русским языком
Работа с русским языком

Задача 1 - создать файл в русской кодировке
#include
#include
void main()
Задача 1 - создать файл в русской кодировке
#include
#include
void main()
 История компьютера: от абака до INTERNET
История компьютера: от абака до INTERNET Социальные сети как основная модель общения в XXI веке
Социальные сети как основная модель общения в XXI веке Основы информационной безопасности и защиты информации. Информационная безопасность в бизнесе
Основы информационной безопасности и защиты информации. Информационная безопасность в бизнесе Коллекции в Java
Коллекции в Java Запросы к нескольким таблицам. Работа с SQL
Запросы к нескольким таблицам. Работа с SQL Программное обеспечение технологий документооборота
Программное обеспечение технологий документооборота Вероятностная обработка лингвистической информации
Вероятностная обработка лингвистической информации Презентация Циклический алгоритм
Презентация Циклический алгоритм Безопасность в Интернете
Безопасность в Интернете Извлечение данных из таблиц. Семинар 2
Извлечение данных из таблиц. Семинар 2 Programming and Programs (сhapters 1 & 2)
Programming and Programs (сhapters 1 & 2) Компьютерные сети
Компьютерные сети Шаблон презентаций для сейлзкитов
Шаблон презентаций для сейлзкитов Технические средства и методы защиты информации
Технические средства и методы защиты информации Фанатские переводы видеоигр
Фанатские переводы видеоигр Количество информации. Решение задач
Количество информации. Решение задач Разработка программного модуля для автоматизации работы менеджера автостоянки
Разработка программного модуля для автоматизации работы менеджера автостоянки Informatika va axborot texnologiyalari darslarida o‘quvchilarning bilim va ko‘nikmalarini shakllantirish uslubiyoti
Informatika va axborot texnologiyalari darslarida o‘quvchilarning bilim va ko‘nikmalarini shakllantirish uslubiyoti Жесткий диск
Жесткий диск Правила перевода чисел из одной системы счисления в другую
Правила перевода чисел из одной системы счисления в другую Мастер-класс по письму
Мастер-класс по письму Анимированные ребусы (презентация)
Анимированные ребусы (презентация) Разработка программы по шифрованию и дешифрованию осмысленного текста с ключом
Разработка программы по шифрованию и дешифрованию осмысленного текста с ключом Система виртуализации VirtualBox
Система виртуализации VirtualBox Excel— работа с числами. Часть 2
Excel— работа с числами. Часть 2 Пересечение множеств
Пересечение множеств Расчет параметров полнодоступных систем РИ с ожиданием
Расчет параметров полнодоступных систем РИ с ожиданием Текстовый процессор Microsoft Word 2010
Текстовый процессор Microsoft Word 2010