- Синхронизация в распределенных системах. Взаимное исключение

Содержание
- 2. Background Synchronization: coordination of actions between processes. Processes are usually asynchronous, (operate independent of events in
- 3. Introduction Synchronization in centralized systems is primarily accomplished through shared memory Event ordering is clear because
- 4. Основные механизмы синхронизации в распределенных системах Синхронизация часов Логические часы Глобальное состояние Алгоритмы голосования Взаимное исключение
- 5. Синхронизация времени
- 6. Роль системных часов Некоторые приложения основываются на реальном порядке событий происходящих в системе Например команда make
- 7. Физические часы Солнечные часы (песочные, водяные, огненные и т.п.) Механические часы Электронные часы Системные часы ЭВМ
- 8. Солнечная секунда и время по Гринвичу Солнечная секунда (solar second) определяется как 1/86 400 солнечного дня.
- 9. Архитектура и принцип работы часов реального времени RTC и CMOS памяти. В состав IBM PC AT
- 10. Глобальное время пор атомным часам В 1948 году были изобретены атомные часы. Физики определили секунду как
- 11. Универсальное согласованное время (UTC) Международное бюро решило эту проблему, используя потерянные секунды (leap seconds) всякий раз,
- 12. Источники точного времени UTC National Institute of Standard Time, NIST) имеет коротковолновую радиостанцию с позывными WWV
- 13. Способы синхронизации часов в распределенных системах Если одна машина имеет приемник WWV, то задачей является синхронизация
- 14. Сдвиг системных часов машин Все алгоритмы имеют одну базовую модель системы. Считается, что каждая машина имеет
- 15. Отстающие и спешащие часы Если двое часов уходят от UTC в разные стороны за время А^
- 16. Три философии (цели) синхронизации часов Попытаться обеспечить как можно более точную синхронизацию с реальным временем UTC.
- 17. Алгоритмы синхронизации часов Network Time Protocol (NTP): Цель: обеспечить синхронизацию всех часов по UTC в пределах
- 18. NTP NTP-серверы работают в иерархической сети, каждый уровень иерархии называется ярусом (stratum). Ярус 0 представлен эталонными
- 19. Алгоритм Беркли Демон времени (исполняющийся процесс на сервере времени) запрашивает у всех остальных машин значения их
- 20. Алгоритм Кристиана Машину с приемником WWV назовем сервером времени. Периодически, гарантировано не реже, чем каждые 2r·Δt
- 21. Задержка при передачи значения времени по сети По Кристиану, метод решения проблемы состоит в измерении величины
- 22. Множественные внешние источники точного времени Для систем, которым необходима особо точная синхронизация по UTC, можно предложить
- 23. Использование синхронизированных часов Благодаря новым технологиям сегодня можно синхронизировать миллионы системных часов с точностью до нескольких
- 24. Логические часы Для работы программы make, например, достаточно, чтобы все машины считали, что сейчас 10:00, даже
- 25. Отметки времени Лампорта Для синхронизации логических часов Лампорт определил отношение под названием «происходит раньше». Выражение а→b
- 26. Алгоритмы выборов
- 27. Алгоритмы голосования Многие распределенные алгоритмы требуют, чтобы один из процессов был координатором, инициатором или выполнял другую
- 28. Алгоритм забияки Когда один из процессов замечает, что координатор больше не отвечает на запросы, он инициирует
- 29. Голосование по алгоритму забияки Ранее коордршатором был процесс 7, но он завис. Процесс 4 первым замечает
- 30. Кольцевой алгоритм Этот алгоритм голосования основан на использовании логического кольца - процессы физически или логически упорядочены,
- 31. Взаимное исключение
- 32. Понятие критической области при работе с ресурсами Системы, состоящие из множества процессов, обычно проще всего программировать,
- 33. Взаимные исключения в распределенных системах Наиболее простой способ организации взаимных исключений в распределенных системах состоит в
- 34. Распределенный алгоритм (1) Рассматриваемый алгоритм требуют наличия полной упорядоченности событий в системе. То есть в любой
- 35. Распределенный алгоритм (продолжение) Можно выделить три варианта: Если получатель не находится в критической области и не
- 36. Работа алгоритма распределенного исключения Представим себе, что два процесса пытаются одновременно войти в одну и ту
- 37. Проблемы распределенного алгоритма Если какой-либо из процессов «рухнет», он не сможет ответить на запрос. Это молчание
- 38. Алгоритм маркерного кольца Программно создается логическое кольцо, в котором каждому процессу назначается его положение в кольце.
- 39. Распределенные транзакции
- 40. Распределенные транзакции Концепция транзакций тесно связана с концепцией взаимных исключений. Алгоритмы взаимного исключения обеспечивают одновременный доступ
- 41. Модель транзакций Свойство транзакций «все или ничего» — это лишь одно из характерных свойств транзакции. Говоря
- 42. Классификация транзакций Плоская транзакция - серия операций, удовлетворяющая свойствам ACID. Плоские транзакции имеют одно ограничение -
- 43. Способы реализации транзакций Обычно используются два метода: Закрытое рабочее пространство. Журнал с упреждающей записью.
- 44. Закрытое рабочее пространство Концептуально, когда процесс начинает транзакцию, он получает закрытое рабочее пространство, содержащее все файлы,
- 45. Журнал с упреждающей записью Согласно этому методу файлы действительно модифицируются там же, где находятся, но перед
- 46. Управление параллельным выполнением транзакций Цель управления параллельным выполнением транзакций состоит в том, чтобы позволить нескольким транзакциям
- 47. Менеджеры транзакций Менеджер транзакций отвечает, прежде всего, за атомарность и долговечность. Он обрабатывает примитивы транзакций, преобразуя
- 48. Изолированность Основная задача алгоритмов управления параллельным выполнением — гарантировать возможность одновременного выполнения многочисленных транзакций до тех
- 49. Двухфазная блокировка Самый старый и наиболее широко используемый алгоритм управления параллельным выполнением транзакций — это блокировка
- 51. Скачать презентацию

Background
Synchronization: coordination of actions between processes.
Processes are usually asynchronous, (operate
Background
Synchronization: coordination of actions between processes.
Processes are usually asynchronous, (operate

Introduction
Synchronization in centralized systems is primarily accomplished through shared memory
Event ordering
Introduction
Synchronization in centralized systems is primarily accomplished through shared memory
Event ordering

Основные механизмы синхронизации в распределенных системах
Синхронизация часов
Логические часы
Глобальное состояние
Алгоритмы голосования
Взаимное исключение
Распределенные
Основные механизмы синхронизации в распределенных системах
Синхронизация часов
Логические часы
Глобальное состояние
Алгоритмы голосования
Взаимное исключение
Распределенные

Синхронизация времени
Синхронизация времени

Роль системных часов
Некоторые приложения основываются на реальном порядке событий происходящих в
Роль системных часов
Некоторые приложения основываются на реальном порядке событий происходящих в

Физические часы
Солнечные часы (песочные, водяные, огненные и т.п.)
Механические часы
Электронные часы
Системные
Физические часы
Солнечные часы (песочные, водяные, огненные и т.п.)
Механические часы
Электронные часы
Системные

Солнечная секунда и время по Гринвичу
Солнечная секунда (solar second) определяется как
Солнечная секунда и время по Гринвичу
Солнечная секунда (solar second) определяется как
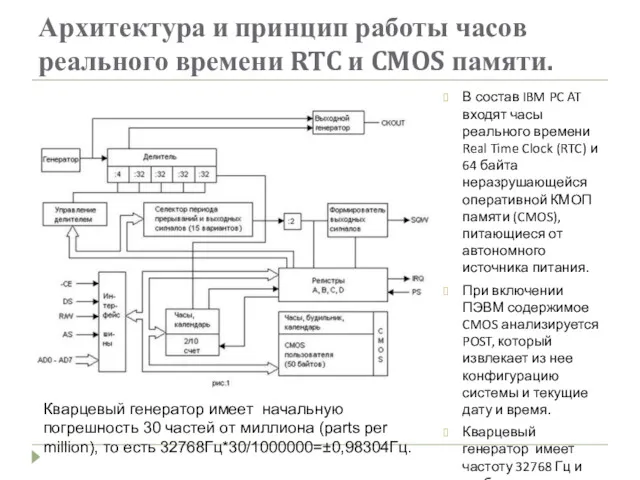
Архитектура и принцип работы часов реального времени RTC и CMOS памяти.
Архитектура и принцип работы часов реального времени RTC и CMOS памяти.

Глобальное время пор атомным часам
В 1948 году были изобретены атомные часы.
Глобальное время пор атомным часам
В 1948 году были изобретены атомные часы.

Универсальное согласованное время (UTC)
Международное бюро решило эту проблему, используя потерянные секунды
Универсальное согласованное время (UTC)
Международное бюро решило эту проблему, используя потерянные секунды

Источники точного времени UTC
National Institute of Standard Time, NIST) имеет коротковолновую
Источники точного времени UTC
National Institute of Standard Time, NIST) имеет коротковолновую

Способы синхронизации часов в распределенных системах
Если одна машина имеет приемник WWV,
Способы синхронизации часов в распределенных системах
Если одна машина имеет приемник WWV,

Сдвиг системных часов машин
Все алгоритмы имеют одну базовую модель системы.
Считается, что
Сдвиг системных часов машин
Все алгоритмы имеют одну базовую модель системы.
Считается, что
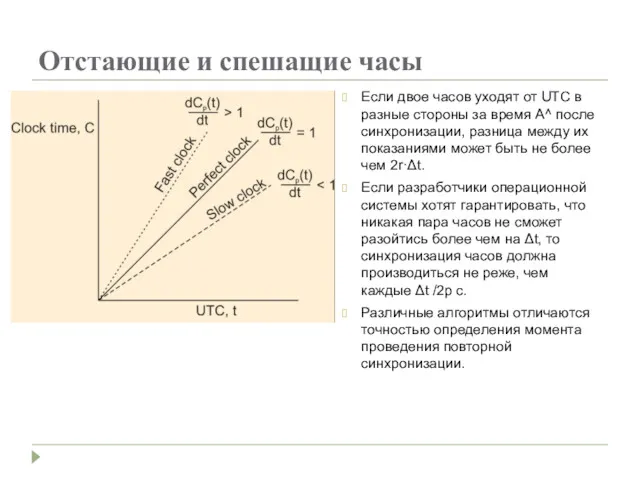
Отстающие и спешащие часы
Если двое часов уходят от UTC в разные
Отстающие и спешащие часы
Если двое часов уходят от UTC в разные

Три философии (цели) синхронизации часов
Попытаться обеспечить как можно более точную синхронизацию
Три философии (цели) синхронизации часов
Попытаться обеспечить как можно более точную синхронизацию

Алгоритмы синхронизации часов
Network Time Protocol (NTP):
Цель: обеспечить синхронизацию всех часов по
Алгоритмы синхронизации часов
Network Time Protocol (NTP):
Цель: обеспечить синхронизацию всех часов по
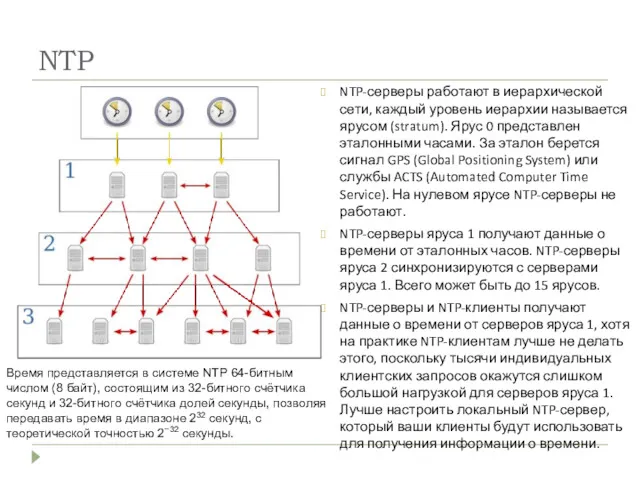
NTP
NTP-серверы работают в иерархической сети, каждый уровень иерархии называется ярусом (stratum).
NTP
NTP-серверы работают в иерархической сети, каждый уровень иерархии называется ярусом (stratum).
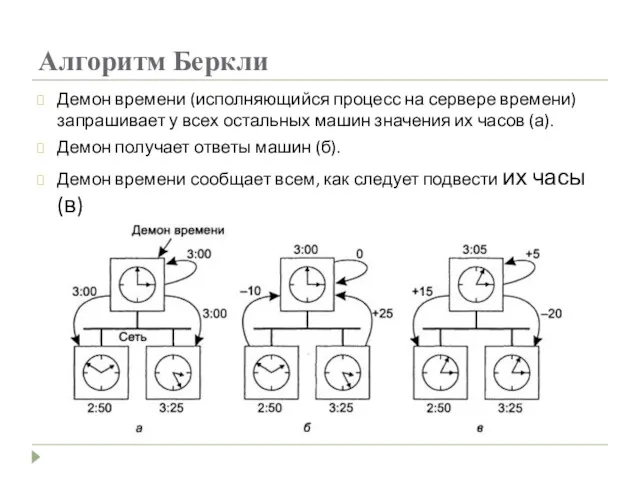
Алгоритм Беркли
Демон времени (исполняющийся процесс на сервере времени) запрашивает у всех
Алгоритм Беркли
Демон времени (исполняющийся процесс на сервере времени) запрашивает у всех

Алгоритм Кристиана
Машину с приемником WWV назовем сервером времени.
Периодически, гарантировано не реже,
Алгоритм Кристиана
Машину с приемником WWV назовем сервером времени.
Периодически, гарантировано не реже,
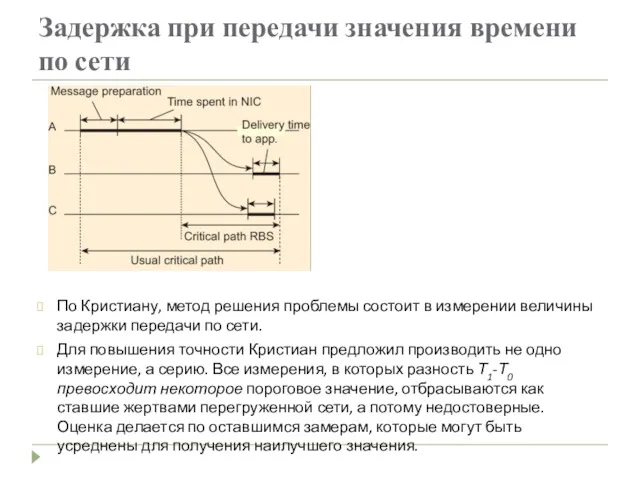
Задержка при передачи значения времени по сети
По Кристиану, метод решения проблемы
Задержка при передачи значения времени по сети
По Кристиану, метод решения проблемы

Множественные внешние источники точного времени
Для систем, которым необходима особо точная синхронизация
Множественные внешние источники точного времени
Для систем, которым необходима особо точная синхронизация

Использование синхронизированных часов
Благодаря новым технологиям сегодня можно синхронизировать миллионы системных часов
Использование синхронизированных часов
Благодаря новым технологиям сегодня можно синхронизировать миллионы системных часов

Логические часы
Для работы программы make, например, достаточно, чтобы все машины считали,
Логические часы
Для работы программы make, например, достаточно, чтобы все машины считали,

Отметки времени Лампорта
Для синхронизации логических часов Лампорт определил отношение под названием
Отметки времени Лампорта
Для синхронизации логических часов Лампорт определил отношение под названием

Алгоритмы выборов
Алгоритмы выборов

Алгоритмы голосования
Многие распределенные алгоритмы требуют, чтобы один из процессов был координатором,
Алгоритмы голосования
Многие распределенные алгоритмы требуют, чтобы один из процессов был координатором,

Алгоритм забияки
Когда один из процессов замечает, что координатор больше не отвечает
Алгоритм забияки
Когда один из процессов замечает, что координатор больше не отвечает
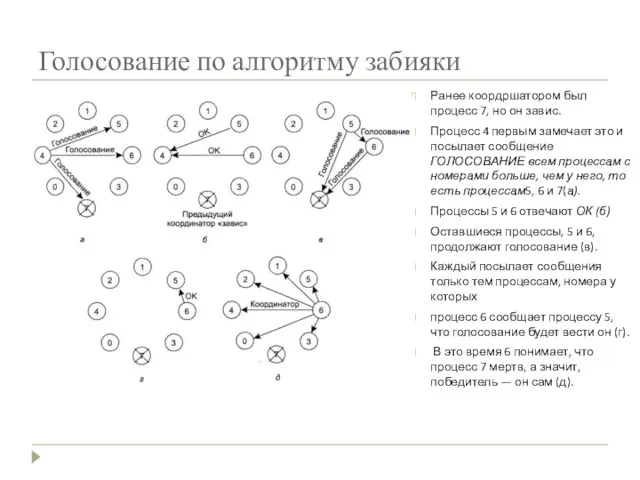
Голосование по алгоритму забияки
Ранее коордршатором был процесс 7, но он завис.
Голосование по алгоритму забияки
Ранее коордршатором был процесс 7, но он завис.

Кольцевой алгоритм
Этот алгоритм голосования основан на использовании логического кольца - процессы
Кольцевой алгоритм
Этот алгоритм голосования основан на использовании логического кольца - процессы

Взаимное исключение
Взаимное исключение

Понятие критической области при работе с ресурсами
Системы, состоящие из множества процессов,
Понятие критической области при работе с ресурсами
Системы, состоящие из множества процессов,

Взаимные исключения в распределенных системах
Наиболее простой способ организации взаимных исключений в
Взаимные исключения в распределенных системах
Наиболее простой способ организации взаимных исключений в

Распределенный алгоритм (1)
Рассматриваемый алгоритм требуют наличия полной упорядоченности событий в системе.
Распределенный алгоритм (1)
Рассматриваемый алгоритм требуют наличия полной упорядоченности событий в системе.

Распределенный алгоритм (продолжение)
Можно выделить три варианта:
Если получатель не находится в критической
Распределенный алгоритм (продолжение)
Можно выделить три варианта:
Если получатель не находится в критической
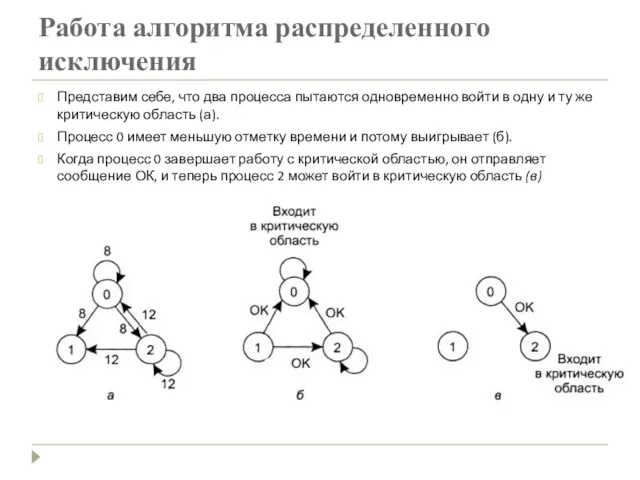
Работа алгоритма распределенного исключения
Представим себе, что два процесса пытаются одновременно войти
Работа алгоритма распределенного исключения
Представим себе, что два процесса пытаются одновременно войти

Проблемы распределенного алгоритма
Если какой-либо из процессов «рухнет», он не сможет ответить
Проблемы распределенного алгоритма
Если какой-либо из процессов «рухнет», он не сможет ответить
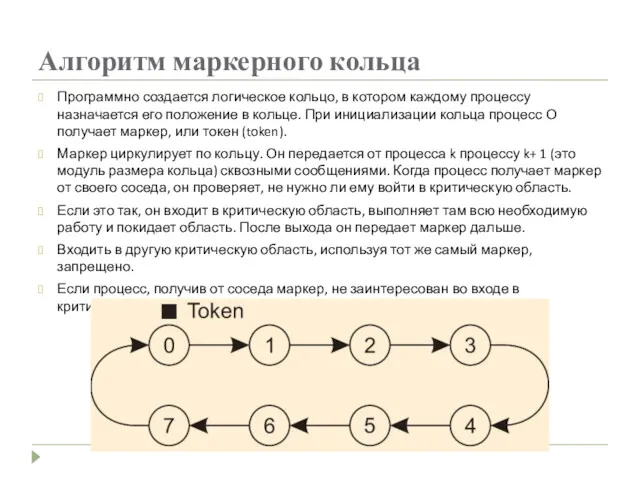
Алгоритм маркерного кольца
Программно создается логическое кольцо, в котором каждому процессу назначается
Алгоритм маркерного кольца
Программно создается логическое кольцо, в котором каждому процессу назначается

Распределенные транзакции
Распределенные транзакции

Распределенные транзакции
Концепция транзакций тесно связана с концепцией взаимных исключений.
Алгоритмы взаимного
Распределенные транзакции
Концепция транзакций тесно связана с концепцией взаимных исключений.
Алгоритмы взаимного

Модель транзакций
Свойство транзакций «все или ничего» — это лишь одно из
Модель транзакций
Свойство транзакций «все или ничего» — это лишь одно из
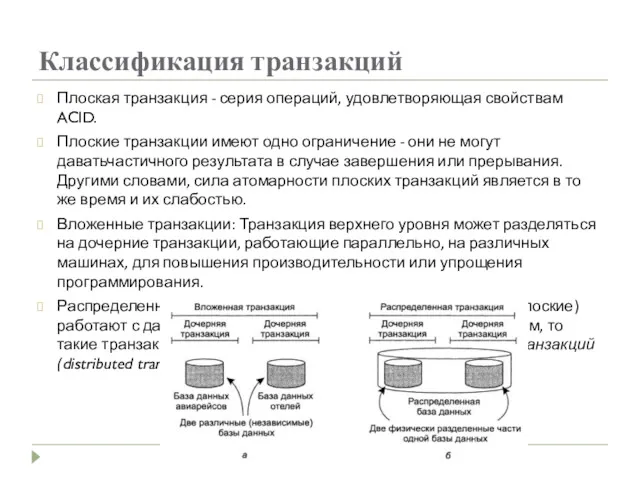
Классификация транзакций
Плоская транзакция - серия операций, удовлетворяющая свойствам ACID.
Плоские транзакции имеют
Классификация транзакций
Плоская транзакция - серия операций, удовлетворяющая свойствам ACID.
Плоские транзакции имеют

Способы реализации транзакций
Обычно используются два метода:
Закрытое рабочее пространство.
Журнал с упреждающей записью.
Способы реализации транзакций
Обычно используются два метода:
Закрытое рабочее пространство.
Журнал с упреждающей записью.
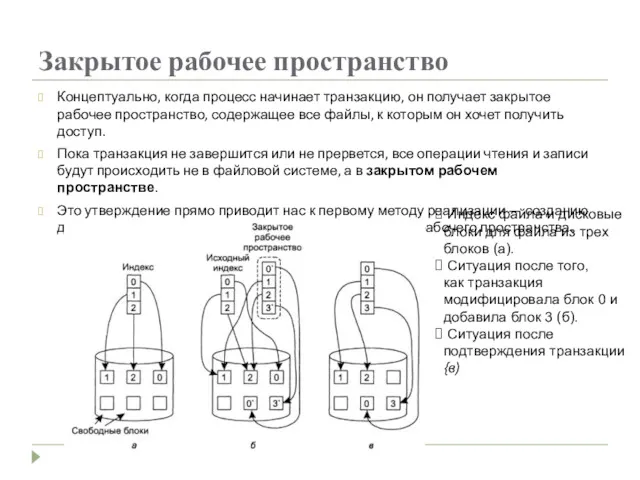
Закрытое рабочее пространство
Концептуально, когда процесс начинает транзакцию, он получает закрытое рабочее
Закрытое рабочее пространство
Концептуально, когда процесс начинает транзакцию, он получает закрытое рабочее

Журнал с упреждающей записью
Согласно этому методу файлы действительно модифицируются там же,
Журнал с упреждающей записью
Согласно этому методу файлы действительно модифицируются там же,
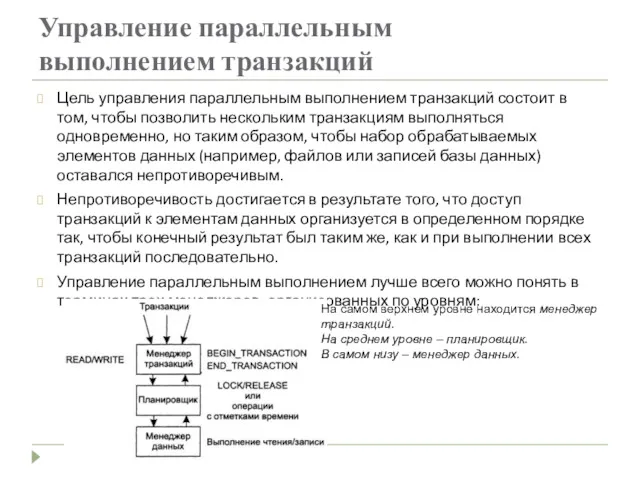
Управление параллельным
выполнением транзакций
Цель управления параллельным выполнением транзакций состоит в том, чтобы
Управление параллельным
выполнением транзакций
Цель управления параллельным выполнением транзакций состоит в том, чтобы
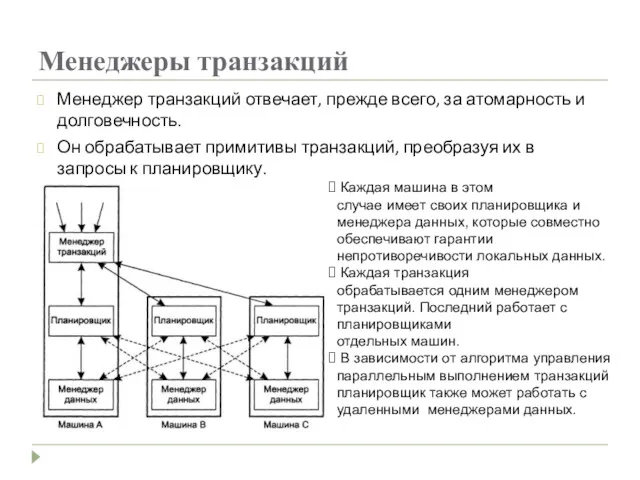
Менеджеры транзакций
Менеджер транзакций отвечает, прежде всего, за атомарность и долговечность.
Он
Менеджеры транзакций
Менеджер транзакций отвечает, прежде всего, за атомарность и долговечность.
Он

Изолированность
Основная задача алгоритмов управления параллельным выполнением — гарантировать возможность одновременного выполнения
Изолированность
Основная задача алгоритмов управления параллельным выполнением — гарантировать возможность одновременного выполнения

Двухфазная блокировка
Самый старый и наиболее широко используемый алгоритм управления параллельным выполнением
Двухфазная блокировка
Самый старый и наиболее широко используемый алгоритм управления параллельным выполнением
 ВКР: Основные характеристики технологии PON
ВКР: Основные характеристики технологии PON Методологические принципы построения автоматизированных систем (лекция 1)
Методологические принципы построения автоматизированных систем (лекция 1) Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Об’єкт event. Обробка подій
Об’єкт event. Обробка подій Захист від клавіатурних шпигунів. (Лекція 1.2)
Захист від клавіатурних шпигунів. (Лекція 1.2) Криптографічний захист інформації. Захист електронного листування за допомогою системи PGP
Криптографічний захист інформації. Захист електронного листування за допомогою системи PGP Разработчик видеоигр
Разработчик видеоигр Объектные привилегии
Объектные привилегии Метод проектов-инновационная педагогическая технология, фактор повышения качества образования
Метод проектов-инновационная педагогическая технология, фактор повышения качества образования Определение понятия проектирование. (Лекция 4)
Определение понятия проектирование. (Лекция 4) Бағдарламалық жасақтаманың жалпы құру түсініктемесі. Лекция 13
Бағдарламалық жасақтаманың жалпы құру түсініктемесі. Лекция 13 Модель специалиста библиотечно-информационной сферы
Модель специалиста библиотечно-информационной сферы Понятие модели. Назначение и свойства моделей
Понятие модели. Назначение и свойства моделей AVT. Audiovisual Translation
AVT. Audiovisual Translation What is a computer?
What is a computer? Информатизация образования в современных условиях
Информатизация образования в современных условиях Операционная система Linux. Знакомство с операционной системой
Операционная система Linux. Знакомство с операционной системой Кодирование звуковой информации
Кодирование звуковой информации Сетевые структуры в современной мировой политике. Сетевой терроризм
Сетевые структуры в современной мировой политике. Сетевой терроризм An Introduction to Computer Networking
An Introduction to Computer Networking Измерение информации. Семантический подход к измерению количества информации
Измерение информации. Семантический подход к измерению количества информации Подготовка к ГИА (часть А1). Умение оценивать количественные параметры информационных объектов. Задача 1
Подготовка к ГИА (часть А1). Умение оценивать количественные параметры информационных объектов. Задача 1 Разработка и реализация базы данных Телефонная станция
Разработка и реализация базы данных Телефонная станция Analiza și modelarea funcționalități jocului Leaguie of legends
Analiza și modelarea funcționalități jocului Leaguie of legends Типы данных
Типы данных Системы искусственного интелекта
Системы искусственного интелекта Кодирование информации
Кодирование информации Умный Дом
Умный Дом