Синтаксический анализ языков программирования. Распознаватели. Задача разбора. (Глава 4) презентация
- Синтаксический анализ языков программирования. Распознаватели. Задача разбора. (Глава 4)

Содержание
- 2. 4.1 РАСПОЗНАВАТЕЛИ. ЗАДАЧА РАЗБОРА Синтаксический анализ
- 3. 4.1.1 Общая схема распознавателя Распознаватель – это специальный алгоритм, который позволяет определить принадлежность цепочки символов некоторому
- 4. 4.1.1 Общая схема распознавателя В процессе работы распознаватель может выполнять некоторые элементарные операции: Чтение очередного символа
- 5. 4.1.1 Общая схема распознавателя Конфигурация распознавателя определяется: состоянием устройства управления; содержимым цепочки символов и положением считывающей
- 6. 4.1.1 Общая схема распознавателя Заключительная конфигурация: устройство управления находится в одном из состояний, принадлежащем заранее выделенному
- 7. 4.1.2 Классификация распознавателей по видам считывающих устройств односторонние двусторонние по видам УУ детерминированные недетерминированные по виду
- 8. 4.1.2 Классификация распознавателей Распознавателем языка с фразовой структурой является недетерминированный двусторонний автомат с неограниченной памятью (машина
- 9. 4.1.3 Задача разбора На основе имеющейся грамматики некоторого формального языка построить распознаватель этого языка. Для КС,
- 10. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат) МП –автомат можно представить следующим образом R
- 11. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
- 12. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат) МП-автомат называется недерминированным, если возможен переход из
- 13. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат) На каждом шаге МП-автомат выполняет операции: ↑
- 14. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат) Разработать автомат с магазинной памятью для разбора
- 15. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
- 16. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
- 17. 4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат) Д\З. Разобрать работу МП-автомата α = ()())
- 18. 4.3 Синтаксический разбор Если попытаться формализовать задачу на уровне элементарного метаязыка, то она будет ставиться следующим
- 19. Классификация методов организации синтаксического разбора
- 20. 4.3.1 Методы разбора Нисходящий разбор заключается в построении дерева разбора, от корневой вершины. Разбор заключается в
- 21. 4.3.1 Методы разбора G = ({S}, {a, +, *}, P, S), S -> a S ->
- 22. Нисходящий разбор слева-направо Нисходящий разбор справа-налево
- 23. Нисходящий произвольный разбор
- 24. 4.3.1 Методы разбора При восходящем разборе дерево начинает строиться от терминальных листьев путем подстановки правил, применимых
- 25. Восходящий разбор слева-направо Восходящий разбор справа-налево
- 26. Восходящий произвольный разбор
- 27. 4.3.1 Методы разбора Комбинированный разбор может быть реализован тогда, когда процесс распознавания разбивается на два этапа.
- 28. Пример комбинированного разбора
- 29. 4.3.2 Последовательность разбора Повышение эффективности разбора осуществляется разработкой грамматик, специально поддерживающих согласованные между собой метод и
- 30. 4.3.3 Использование просмотра вперед В грамматиках могут встречаться альтернативные правила, начинающиеся с одинаковых цепочек символов. Возникающая
- 31. 4.3.4 Использование возврата Синтаксический разбор с возвратами выполняется аналогично тому, как осуществляется непрямой лексический анализ. Возвраты
- 32. 4.3.4 Использование возврата Рассмотрим КС-грамматику. L = {an bn | n>0} ab n=1 aabb n=2 aaabbb
- 33. 4.4 НИСХОДЯЩИЕ РАСПОЗНАВАТЕЛИ С ВОЗВРАТАМИ Синтаксический анализ
- 34. Вообразим, что на любом этапе разбора, в каждом узле уже построенной части дерева находится по одному
- 35. Некоему человеку надлежит провести разбор предложения ω. Ему необходимо отыскать вывод S =>+ ω, где S
- 36. Как ему определить, правильно он выбрал непосредственный вывод S ::= X1 X2 .. Xn? Если вывод
- 37. Тогда его отец усыновит M2, чтобы тот нашел вывод X2=> *x2, где ω = x1x2... и
- 38. Как же действует каждый из Mi? Положим, целью Mi является терминал t, такой, что ω =x1
- 39. Если отец просит Mi найти другой вывод, а целью является терминальный символ, то Mi сообщает о
- 40. 4.5 РЕАЛИЗАЦИЯ НИСХОДЯЩЕГО РАСПОЗНАВАТЕЛЯ С ВОЗВРАТАМИ Синтаксический анализ
- 41. Форма, которая будет использоваться для записи правил G = ({i, +, *, (, )}, {S, Е,
- 42. Принятые обозначения char input []; - строка содержит входную цепочку символов; char grammar []; - массив
- 43. Принятые обозначения Понятия относящиеся к человеку, работающему в данный момент (находится на уровне с) #define GOAL
- 44. Структура "семьи"
- 45. Алгоритм в псевдокоде Начальная установка: S(l) = ('S', 0, 0, 0, 0); с = 1; v
- 46. Алгоритм в псевдокоде // очередная установка v++; S(v) = (grammar[I], 0, c, 0, SON); SON =
- 47. Пример S # E E T F * i i T + T F F i
- 48. 4.6 Нисходящие распознаватели без возвратов Алгоритм работы МП-автомата не требует возврата на предыдущий шаг и обладает
- 49. 4.6.1 Левосторонний разбор по методу рекурсивного спуска Для каждого A є VN, строится своя процедура разбора,
- 50. 4.6.2 Условия применимости РС-метода либо A -> α, где α ∈ (VT ∪ VN)* и это
- 51. 4.6.3 Пример реализации РС-метода G ({a,b,c}, {A,B,C,S}, P, S) P: 1) S -> aA 2) S
- 52. // 1) S -> aA // 2) S -> bB int S () { int rc=0;
- 53. // 6) B -> b // 7) B -> aB // 8) B -> cC int
- 54. 4.8 Преобразование КС грамматик Для КС-грамматик невозможно проверить их однозначность и эквивалентность. Правила КС-грамматик преобразовывают к
- 55. 4.8.1 Приведенные грамматики Приведенные КС-грамматики – это КС-грамматики, которые не содержат недостижимых и бесполезных символов, циклов,
- 56. 4.8.2 Удаление бесполезных символов Символ A ∈ VN называется бесполезным в грамматике G = (VT, VN,
- 57. Алгоритм удаления бесполезных символов Вход: КС-грамматика G = (VT, VN, P, S). Выход: КС-грамматика G' =
- 58. G=({a,b}, {S,A,B,C},S,P) P: S -> aA | bB A -> bAa B -> aB | bS
- 59. 4.8.3 Удаление недостижимых символов Символ x ∈ (VT ∪ VN) называется недостижимым в грамматике G =
- 60. Алгоритм удаления недостижимых символов Вход: КС-грамматика G = (VT, VN, P, S) Выход: КС-грамматика G' =
- 61. Пример G = ( {a,b,c,d}, {A, B, C, D, E, F, G, S}, P, S) P:
- 62. Пример работы алгоритма N0 = ∅, i=1 N1 = {B, D}, i=2, V0 ≠ V1 N2
- 63. 4.8.5 Устранение ε-правил Грамматика G называется грамматикой без ε-правил, если в ней не существует правил вида
- 64. 4.8.5 Устранение ε-правил Алгоритм. 1. V0 = {A | (A -> ε) ∈ P}; i =
- 65. Пример G ( {a, b, c}, {A, B, C, S}, P, S) P: S -> AaB
- 66. 4.8.6 Устранение цепных правил Циклом или циклическим выводом грамматики G называется вывод A =>* A, A
- 67. Пример G ( {a, b, c}, {A, B, C, S}, P, S) P: S - >
- 68. Д/З ДЗ. Дана грамматика арифметических выражений, устранить цепные правила. G ( {a, b, +, *, (,
- 69. 4.8.7 Устранение левой рекурсии Нетерминальный символ A грамматики G называется рекурсивным, если для него существует вывод
- 70. 4.8.7 Устранение левой рекурсии 1. N = { A1, A2 … An} i=1, n – количество
- 71. 4.8.7 Устранение левой рекурсии 3. Для устранения косвенной левой рекурсии. 4. Для символа Aj во множестве
- 72. Пример G = ({a, b, +, *, (, )}, {F, T, E}, P, E) P: E
- 73. 4.8.8 Устранение левой факторизации Если в грамматике существуют правила вида A -> aα1 | aα2 |
- 75. Скачать презентацию

4.1 РАСПОЗНАВАТЕЛИ. ЗАДАЧА РАЗБОРА
Синтаксический анализ
4.1 РАСПОЗНАВАТЕЛИ. ЗАДАЧА РАЗБОРА
Синтаксический анализ
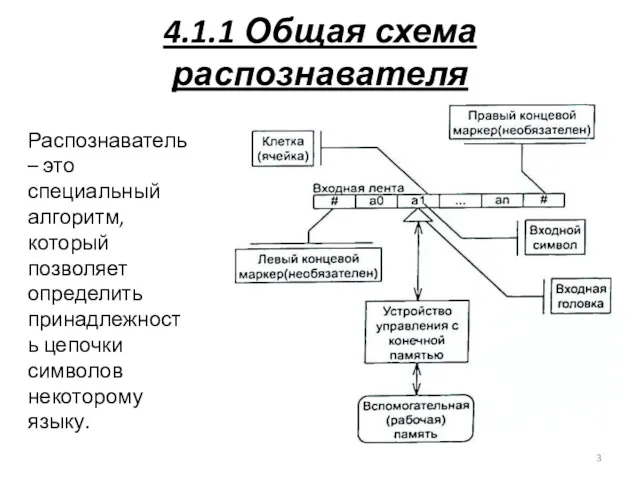
4.1.1 Общая схема распознавателя
Распознаватель – это специальный алгоритм, который позволяет определить
4.1.1 Общая схема распознавателя
Распознаватель – это специальный алгоритм, который позволяет определить

4.1.1 Общая схема распознавателя
В процессе работы распознаватель может выполнять некоторые элементарные
4.1.1 Общая схема распознавателя
В процессе работы распознаватель может выполнять некоторые элементарные

4.1.1 Общая схема распознавателя
Конфигурация распознавателя определяется:
состоянием устройства управления;
содержимым цепочки символов и
4.1.1 Общая схема распознавателя
Конфигурация распознавателя определяется:
состоянием устройства управления;
содержимым цепочки символов и

4.1.1 Общая схема распознавателя
Заключительная конфигурация:
устройство управления находится в одном из состояний,
4.1.1 Общая схема распознавателя
Заключительная конфигурация:
устройство управления находится в одном из состояний,

4.1.2 Классификация распознавателей
по видам считывающих устройств
односторонние
двусторонние
по видам УУ
детерминированные
недетерминированные
по виду внешней памяти
без
4.1.2 Классификация распознавателей
по видам считывающих устройств
односторонние
двусторонние
по видам УУ
детерминированные
недетерминированные
по виду внешней памяти
без

4.1.2 Классификация распознавателей
Распознавателем языка с фразовой структурой является недетерминированный двусторонний автомат
4.1.2 Классификация распознавателей
Распознавателем языка с фразовой структурой является недетерминированный двусторонний автомат

4.1.3 Задача разбора
На основе имеющейся грамматики некоторого формального языка построить распознаватель
4.1.3 Задача разбора
На основе имеющейся грамматики некоторого формального языка построить распознаватель

4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
МП –автомат можно
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
МП –автомат можно
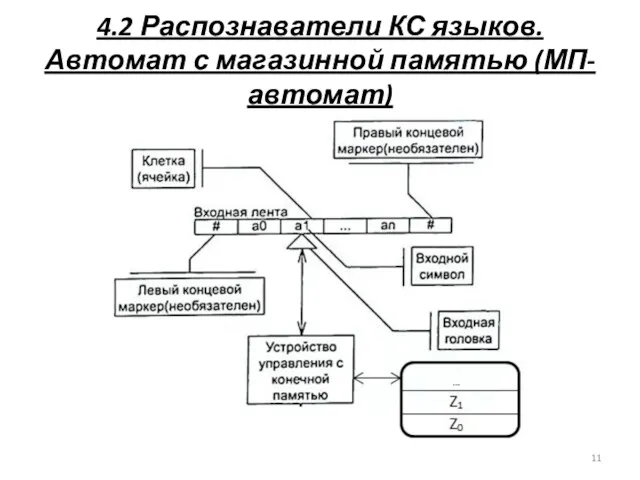
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)

4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
МП-автомат называется недерминированным,
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
МП-автомат называется недерминированным,

4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
На каждом шаге
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
На каждом шаге

4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
Разработать автомат с
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
Разработать автомат с

4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
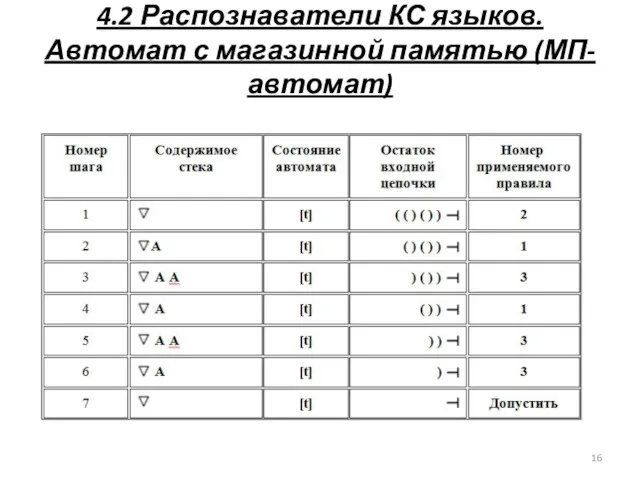
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)

4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
Д\З. Разобрать работу
4.2 Распознаватели КС языков. Автомат с магазинной памятью (МП-автомат)
Д\З. Разобрать работу

4.3 Синтаксический разбор
Если попытаться формализовать задачу на уровне элементарного метаязыка, то
4.3 Синтаксический разбор
Если попытаться формализовать задачу на уровне элементарного метаязыка, то
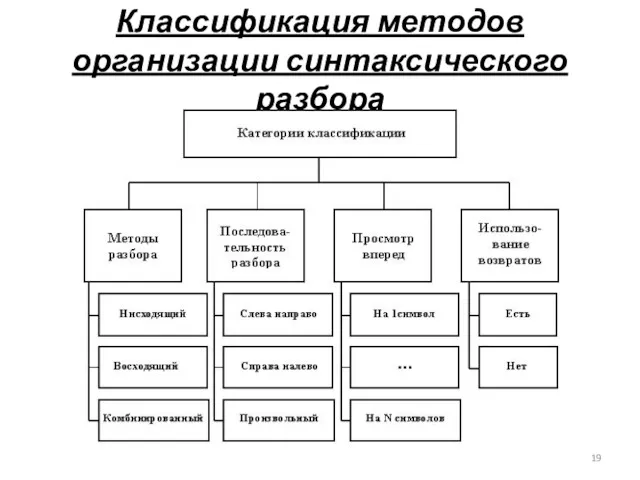
Классификация методов организации синтаксического разбора
Классификация методов организации синтаксического разбора

4.3.1 Методы разбора
Нисходящий разбор заключается в построении дерева разбора, от корневой
4.3.1 Методы разбора
Нисходящий разбор заключается в построении дерева разбора, от корневой

4.3.1 Методы разбора
G = ({S}, {a, +, *}, P, S),
S -> a
S -> S + S
S -> S
4.3.1 Методы разбора
G = ({S}, {a, +, *}, P, S),
S -> a
S -> S + S
S -> S
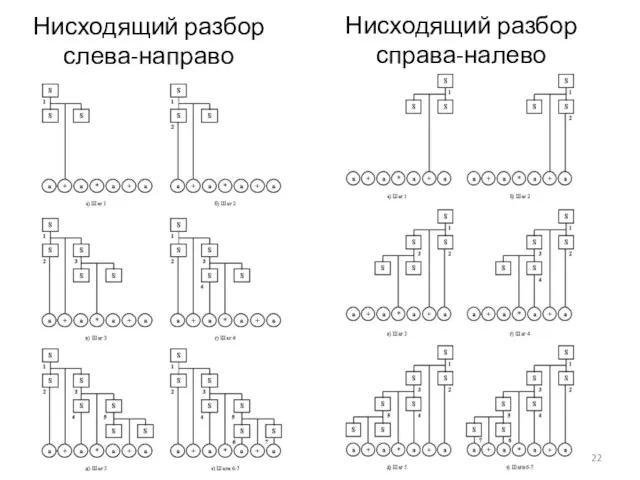
Нисходящий разбор слева-направо
Нисходящий разбор справа-налево
Нисходящий разбор слева-направо
Нисходящий разбор справа-налево
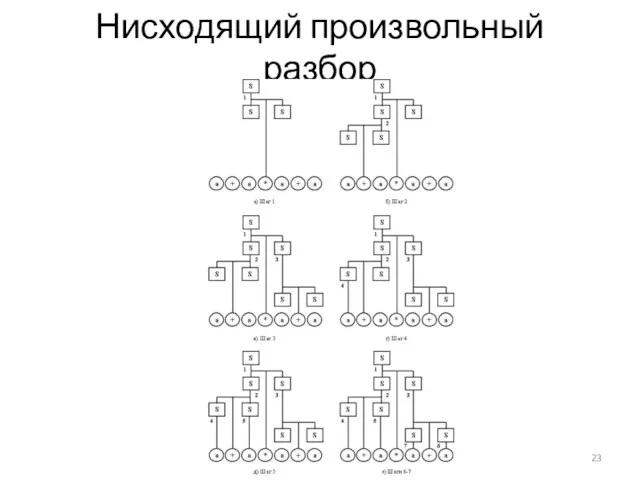
Нисходящий произвольный разбор
Нисходящий произвольный разбор

4.3.1 Методы разбора
При восходящем разборе дерево начинает строиться от терминальных листьев
4.3.1 Методы разбора
При восходящем разборе дерево начинает строиться от терминальных листьев
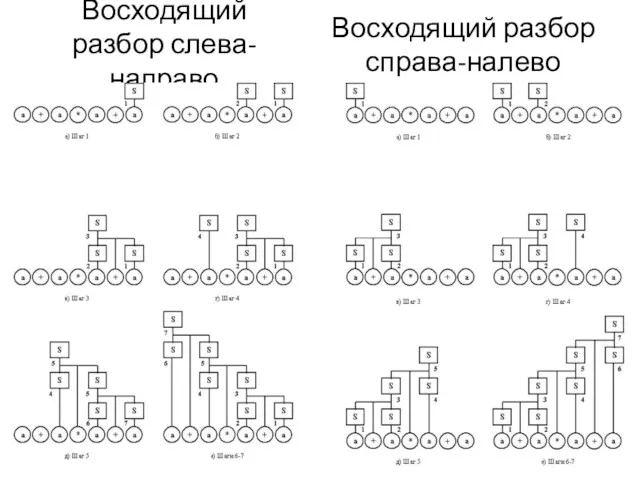
Восходящий разбор слева-направо
Восходящий разбор справа-налево
Восходящий разбор слева-направо
Восходящий разбор справа-налево
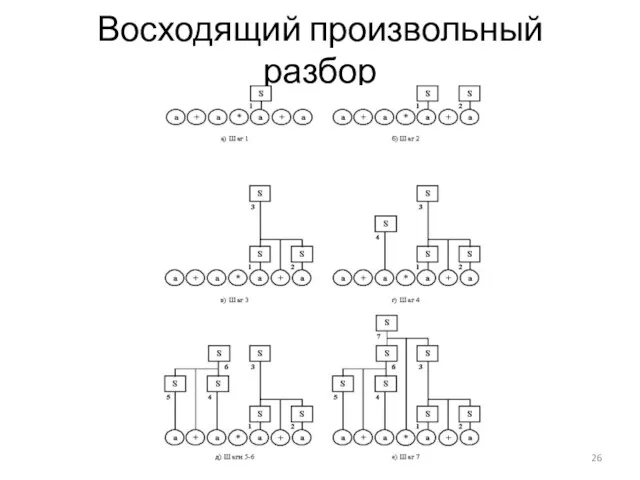
Восходящий произвольный разбор
Восходящий произвольный разбор

4.3.1 Методы разбора
Комбинированный разбор может быть реализован тогда, когда процесс распознавания
4.3.1 Методы разбора
Комбинированный разбор может быть реализован тогда, когда процесс распознавания
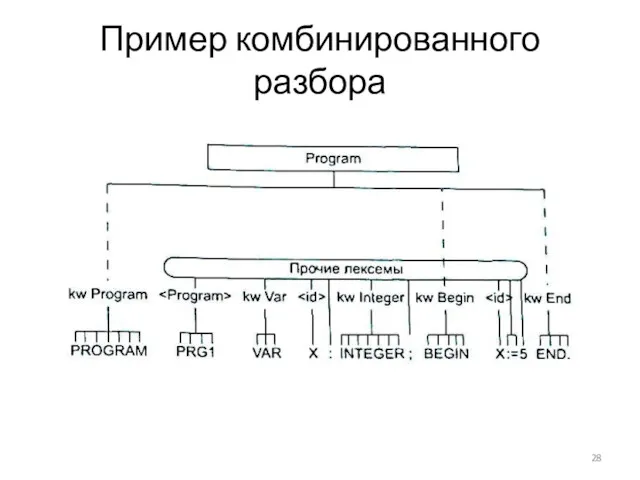
Пример комбинированного разбора
Пример комбинированного разбора

4.3.2 Последовательность разбора
Повышение эффективности разбора осуществляется разработкой грамматик, специально поддерживающих согласованные
4.3.2 Последовательность разбора
Повышение эффективности разбора осуществляется разработкой грамматик, специально поддерживающих согласованные

4.3.3 Использование просмотра вперед
В грамматиках могут встречаться альтернативные правила, начинающиеся с
4.3.3 Использование просмотра вперед
В грамматиках могут встречаться альтернативные правила, начинающиеся с

4.3.4 Использование возврата
Синтаксический разбор с возвратами выполняется аналогично тому, как осуществляется
4.3.4 Использование возврата
Синтаксический разбор с возвратами выполняется аналогично тому, как осуществляется

4.3.4 Использование возврата
Рассмотрим КС-грамматику.
L = {an bn | n>0}
ab n=1
aabb n=2
aaabbb n=3
S -> ASB
4.3.4 Использование возврата
Рассмотрим КС-грамматику.
L = {an bn | n>0}
ab n=1
aabb n=2
aaabbb n=3
S -> ASB

4.4 НИСХОДЯЩИЕ РАСПОЗНАВАТЕЛИ С ВОЗВРАТАМИ
Синтаксический анализ
4.4 НИСХОДЯЩИЕ РАСПОЗНАВАТЕЛИ С ВОЗВРАТАМИ
Синтаксический анализ
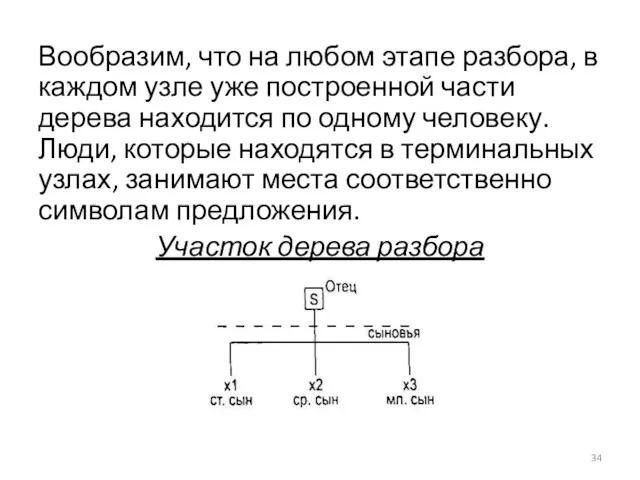
Вообразим, что на любом этапе разбора, в каждом узле уже построенной
Вообразим, что на любом этапе разбора, в каждом узле уже построенной

Некоему человеку надлежит провести разбор предложения ω.
Ему необходимо отыскать вывод
Некоему человеку надлежит провести разбор предложения ω.
Ему необходимо отыскать вывод

Как ему определить, правильно он выбрал непосредственный вывод S ::= X1
Как ему определить, правильно он выбрал непосредственный вывод S ::= X1

Тогда его отец усыновит M2, чтобы тот нашел вывод X2=> *x2,
Тогда его отец усыновит M2, чтобы тот нашел вывод X2=> *x2,

Как же действует каждый из Mi?
Положим, целью Mi является терминал
Как же действует каждый из Mi?
Положим, целью Mi является терминал

Если отец просит Mi найти другой вывод, а целью является терминальный
Если отец просит Mi найти другой вывод, а целью является терминальный

4.5 РЕАЛИЗАЦИЯ НИСХОДЯЩЕГО РАСПОЗНАВАТЕЛЯ С ВОЗВРАТАМИ
Синтаксический анализ
4.5 РЕАЛИЗАЦИЯ НИСХОДЯЩЕГО РАСПОЗНАВАТЕЛЯ С ВОЗВРАТАМИ
Синтаксический анализ
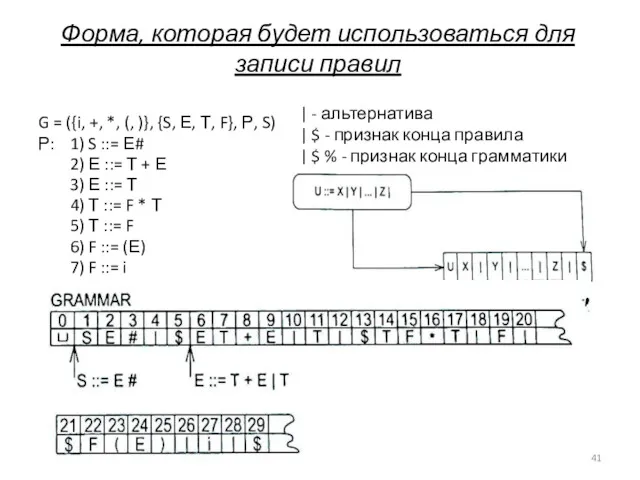
Форма, которая будет использоваться для записи правил
G = ({i, +, *,
Форма, которая будет использоваться для записи правил
G = ({i, +, *,
![Принятые обозначения char input []; - строка содержит входную цепочку](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/152160/slide-41.jpg)
Принятые обозначения
char input []; - строка содержит входную цепочку символов;
char grammar
Принятые обозначения
char input []; - строка содержит входную цепочку символов;
char grammar

Принятые обозначения
Понятия относящиеся к человеку, работающему в данный момент (находится на
Принятые обозначения
Понятия относящиеся к человеку, работающему в данный момент (находится на
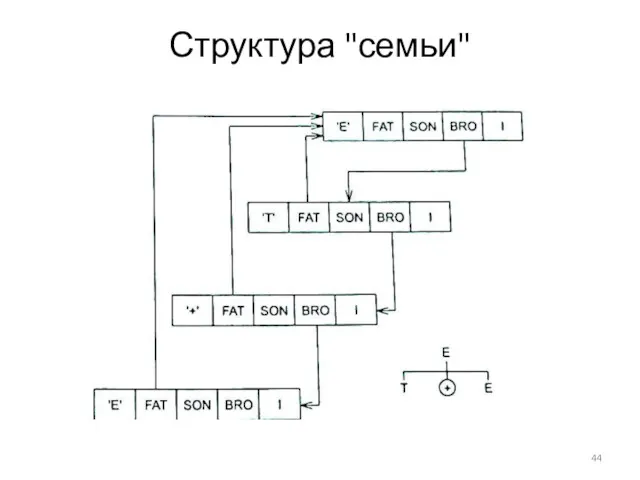
Структура "семьи"
Структура "семьи"

Алгоритм в псевдокоде
Начальная установка:
S(l) = ('S', 0, 0, 0, 0); с
Алгоритм в псевдокоде
Начальная установка:
S(l) = ('S', 0, 0, 0, 0); с
![Алгоритм в псевдокоде // очередная установка v++; S(v) = (grammar[I],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/152160/slide-45.jpg)
Алгоритм в псевдокоде
// очередная установка
v++;
S(v) = (grammar[I], 0, c, 0, SON);
Алгоритм в псевдокоде
// очередная установка
v++;
S(v) = (grammar[I], 0, c, 0, SON);
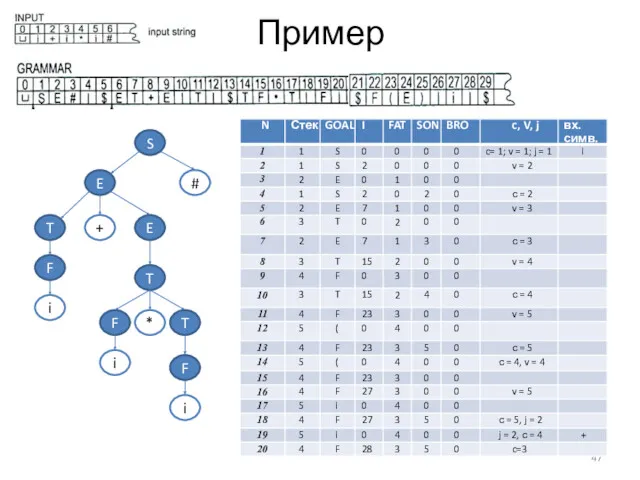
Пример
S
#
E
E
T
F
*
i
i
T
+
T
F
F
i
Пример
S
#
E
E
T
F
*
i
i
T
+
T
F
F
i

4.6 Нисходящие распознаватели без возвратов
Алгоритм работы МП-автомата не требует возврата на
4.6 Нисходящие распознаватели без возвратов
Алгоритм работы МП-автомата не требует возврата на

4.6.1 Левосторонний разбор по методу рекурсивного спуска
Для каждого A є VN,
4.6.1 Левосторонний разбор по методу рекурсивного спуска
Для каждого A є VN,

4.6.2 Условия применимости РС-метода
либо A -> α, где α ∈ (VT
4.6.2 Условия применимости РС-метода
либо A -> α, где α ∈ (VT

4.6.3 Пример реализации РС-метода
G ({a,b,c}, {A,B,C,S}, P, S)
P: 1) S ->
4.6.3 Пример реализации РС-метода
G ({a,b,c}, {A,B,C,S}, P, S)
P: 1) S ->

// 1) S -> aA
// 2) S -> bB
int S
// 1) S -> aA
// 2) S -> bB
int S

// 6) B -> b
// 7) B -> aB
// 8) B
// 6) B -> b
// 7) B -> aB
// 8) B

4.8 Преобразование КС грамматик
Для КС-грамматик невозможно проверить их однозначность и эквивалентность.
4.8 Преобразование КС грамматик
Для КС-грамматик невозможно проверить их однозначность и эквивалентность.

4.8.1 Приведенные грамматики
Приведенные КС-грамматики – это КС-грамматики, которые не содержат недостижимых
4.8.1 Приведенные грамматики
Приведенные КС-грамматики – это КС-грамматики, которые не содержат недостижимых

4.8.2 Удаление бесполезных символов
Символ A ∈ VN называется бесполезным в грамматике
4.8.2 Удаление бесполезных символов
Символ A ∈ VN называется бесполезным в грамматике

Алгоритм удаления бесполезных символов
Вход: КС-грамматика G = (VT, VN, P, S).
Выход:
Алгоритм удаления бесполезных символов
Вход: КС-грамматика G = (VT, VN, P, S).
Выход:

G=({a,b}, {S,A,B,C},S,P)
P: S -> aA | bB
A -> bAa
B -> aB
G=({a,b}, {S,A,B,C},S,P)
P: S -> aA | bB
A -> bAa
B -> aB

4.8.3 Удаление недостижимых символов
Символ x ∈ (VT ∪ VN) называется недостижимым
4.8.3 Удаление недостижимых символов
Символ x ∈ (VT ∪ VN) называется недостижимым

Алгоритм удаления недостижимых символов
Вход: КС-грамматика G = (VT, VN, P, S)
Выход:
Алгоритм удаления недостижимых символов
Вход: КС-грамматика G = (VT, VN, P, S)
Выход:

Пример
G = ( {a,b,c,d}, {A, B, C, D, E, F, G,
Пример
G = ( {a,b,c,d}, {A, B, C, D, E, F, G,

Пример работы алгоритма
N0 = ∅, i=1
N1 = {B, D}, i=2, V0
Пример работы алгоритма
N0 = ∅, i=1
N1 = {B, D}, i=2, V0

4.8.5 Устранение ε-правил
Грамматика G называется грамматикой без ε-правил, если в ней
4.8.5 Устранение ε-правил
Грамматика G называется грамматикой без ε-правил, если в ней

4.8.5 Устранение ε-правил
Алгоритм.
1. V0 = {A | (A -> ε) ∈
4.8.5 Устранение ε-правил
Алгоритм.
1. V0 = {A | (A -> ε) ∈

Пример
G ( {a, b, c}, {A, B, C, S}, P, S)
P:
Пример
G ( {a, b, c}, {A, B, C, S}, P, S)
P:

4.8.6 Устранение цепных правил
Циклом или циклическим выводом грамматики G называется вывод
4.8.6 Устранение цепных правил
Циклом или циклическим выводом грамматики G называется вывод

Пример
G ( {a, b, c}, {A, B, C, S}, P, S)
P: S
Пример
G ( {a, b, c}, {A, B, C, S}, P, S)
P: S

Д/З
ДЗ. Дана грамматика арифметических выражений, устранить цепные правила.
G ( {a,
Д/З
ДЗ. Дана грамматика арифметических выражений, устранить цепные правила.
G ( {a,

4.8.7 Устранение левой рекурсии
Нетерминальный символ A грамматики G называется рекурсивным, если
4.8.7 Устранение левой рекурсии
Нетерминальный символ A грамматики G называется рекурсивным, если

4.8.7 Устранение левой рекурсии
1. N = { A1, A2 … An}
4.8.7 Устранение левой рекурсии
1. N = { A1, A2 … An}

4.8.7 Устранение левой рекурсии
3. Для устранения косвенной левой рекурсии.
4. Для символа
4.8.7 Устранение левой рекурсии
3. Для устранения косвенной левой рекурсии.
4. Для символа

Пример
G = ({a, b, +, *, (, )}, {F, T, E},
Пример
G = ({a, b, +, *, (, )}, {F, T, E},

4.8.8 Устранение левой факторизации
Если в грамматике существуют правила вида
A -> aα1
4.8.8 Устранение левой факторизации
Если в грамматике существуют правила вида
A -> aα1
 История развития вычислительной техники
История развития вычислительной техники Обеспечение безопасности сетевых операционных систем
Обеспечение безопасности сетевых операционных систем Эволюция операционных систем
Эволюция операционных систем Моя будущая профессия - веб-дизайнер
Моя будущая профессия - веб-дизайнер JS Tools. Grunt Gulp Bower
JS Tools. Grunt Gulp Bower Исполнитель Чертежник. Вспомогательные алгоритмы
Исполнитель Чертежник. Вспомогательные алгоритмы Применение нейронных сетей в задачах машинного обучения. Нейронные сети прямого и обратного распространения
Применение нейронных сетей в задачах машинного обучения. Нейронные сети прямого и обратного распространения Поняття про об’єкт у програмуванні. Властивості об’єкта
Поняття про об’єкт у програмуванні. Властивості об’єкта Почему вашему мобильному устройству нужна защита
Почему вашему мобильному устройству нужна защита Основные инструменты графического редактора
Основные инструменты графического редактора ER-диаграммы. Связи
ER-диаграммы. Связи Управление исполнителем чертёжник
Управление исполнителем чертёжник Өз ойыным. 4 класс
Өз ойыным. 4 класс МДК 02.02. Web-программирование. Язык РНР. Работа с формой
МДК 02.02. Web-программирование. Язык РНР. Работа с формой QR-кодирование. Что такое QR-код?
QR-кодирование. Что такое QR-код? IP-телефония мен стримингтік технологиялар негіздері
IP-телефония мен стримингтік технологиялар негіздері Основы безопасности жизнедеятельности в сети Интернет
Основы безопасности жизнедеятельности в сети Интернет Автоматическая текстонезависимая идентификация диктора с использованием спектральных коэффициентов
Автоматическая текстонезависимая идентификация диктора с использованием спектральных коэффициентов Применение облачных технологий в образовательном процессе профессиональной образовательной организации
Применение облачных технологий в образовательном процессе профессиональной образовательной организации Чат-бот ВКонтакте
Чат-бот ВКонтакте Графы. Информация и информационные процессы
Графы. Информация и информационные процессы Игра Остров сокровищ
Игра Остров сокровищ Знакомство с компонентами Power BI. Создание первых запросов. Занятие 1
Знакомство с компонентами Power BI. Создание первых запросов. Занятие 1 Автоматизированная система управления космодромом
Автоматизированная система управления космодромом Стандарты и методология разработки корпоративных инфокоммуникационых систем
Стандарты и методология разработки корпоративных инфокоммуникационых систем Сапр - системы автоматизированного проектирования
Сапр - системы автоматизированного проектирования Компьютерные презентации
Компьютерные презентации Новая игра. Тактический шутер Valorant
Новая игра. Тактический шутер Valorant